
[Deeplearning] BERT 개념 정리부터 실제 활용까지
이번엔 Transformer 를 이용한 다운스트림 태스크에 활용되는 BERT 에 대해서 개념 정리부터 실제 활용까지 알아보았고, 추후에 참고하고자 포스트로 정리하는 작업도 진행해 보았습니다.
활용은 파인 튜닝 학습을 통해 다운스트림 작업을 위한 데이터를 이용해 진행을 하였으며, 사전 학습은 학습할 여건이 충분치 않아 다음에 다뤄보도록 하고자 합니다.
1. BERT 란?
BERT(Bidirectional Encoder Representations from Transformers)는 구글이 2018년에 발표한 사전 학습 기반 언어 모델입니다. BERT 이전까지의 NLP 모델들은 대부분 특정 태스크에 맞춰 모델 구조나 학습 방식을 새로 설계해야 했습니다. 하지만 BERT 는 대규로 unlabeled 텍스트를 사용해 사전 학습을 진행하고 이후 labeled 데이터로 간단히 fine-tuning 해 자연어처리 분야의 다양한 다운스트림 태스크를 하나의 모델로 처리할 수 있도록 하는 범용 딥러닝 모델을 만들고자 해서 고안된 딥러닝 모델입니다. 그리고 기존의 단방향 언어 모델과 달리 양방향(Bidirectional) 문백을 모두 활용할 수 있어 많은 자연어 처리(NLP) 태스크에서 혁신적인 성능 향상을 이끌었습니다.
2. BERT 이전의 NLP 모델들
BERT 이전에는 주로 사용된 딥러닝 모델로는 LSTM 이 주로 사용되었고, 모델의 입력 임베딩으로는 랜덤 임베딩 대신 Word2Vec, GloVe 와 같은 정적 임베딩 방식이 주류를 이루었습니다. 하지만 이들은 문맥을 잘 반영하지 못하는 문제가 있었고, 무엇보다 Transformer 와 같이 일괄적으로 처리하는 방식이 아닌 시퀀스를 처리하기 위한 반복을 진행해야 했기 때문에 모델 학습과 결과를 출력하는데 오랜 시간이 걸리는 문제가 존재한다는 한계가 있었습니다.
3. BERT 의 주요 아이디어
3.1 Masked LM=MLM(Bidirectional)
BERT 는 문장의 왼쪽과 오른쪽 문맥을 동시에 고려하여 언어를 이해합니다. 기존 언어 모델은 일반적으로 left-to-right 혹은 right-to-left 방향으로만 문맥을 고려했습니다. 하지만 이러한 단방향 언어 모델은 문장의 전체 맥락을 충분히 활용할 수 없었습니다.
BERT 는 MLM을 활용함으로써, 양방향 문맥(Bidirectional Context)을 동시에 학습합니다. BERT 는 사전 학습 시 Transformer 모델에 사용되는 사전 학습 데이터와는 달리 학습할 데이터의 입력 문장에서 임의의 토큰 15% 를 [MASK] 토큰으로 바꾼 데이터를 사용하게 됩니다. BERT 는 사전 학습을 하면서 [MASK] 된 토큰들을 예측할 때 그 앞뒤의 모든 단어 정보를 사용하기 때문에 양방향 학습이 된다고 합니다. 이를 예시를 통해 설명하자면 다음과 같습니다.
예시
입력 문장 : 나는 [MASK]을 좋아합니다.
- 기존 단방향 모델 : “나는”까지만 보고 [MASK]를 예측
- BERT : “나는”, “을 좋아합니다” 모두 보고 [MASK]를 예측
이러한 접근은 문장의 의미를 더 정확하게 파악할 수 있게 해줍니다.
MLM 특징
MLM 은 위에서 언급한 것과 같이 입력 문장에서 임의의 토큰 15% 를 [MASK] 토큰으로 바꾼 뒤, 해당 토큰이 원래 무엇이었는지 예측하는 태스크입니다.
- 양방향 문맥 정보를 모두 활용
- 사전 학습 시 대규모 코퍼스를 통해 일반적인 언어 패턴 학습
- WordPiece 단위로 토큰화 되어 희귀 단어도 유연하게 처리 가능
3.2 Next Sentence Prediction (NSP)
NSP 는 문장 간 관계 학습을 위한 태스크입니다. BERT 에서 NSP 사전 학습을 진행하는 이유는 QA(Question/Answering) 과 같은 문장 간 관계에 중점을 두는 다운스트림 태스크에 필요한 능력을 모델이 갖추도록 돕기 때문입니다. 즉, NSP 는 BERT 가 문장 간 논리적 연결을 이해하도록 만드는 것이 학습 목표이며, 이로 인해 BERT 는 문장-문장 관계 기반 다운스트림 태스크에 성능 향상을 가져왔습니다. 문장-문장 관계 기반 다운스트림 태스크는 다음과 같은 것들이 있습니다.
- QA 에서 질문과 문서의 특정 문장 관계 파악
- 자연어 추론(NLI)에서 문장 간 entailment/contradiction 관계 파악
- 문서 요약 및 문장 유사도에서 문맥적 연결성 인식
BERT 는 이러한 NSP 학습을 위해서 NSP 용 사전 학습 데이터를 통해 학습을 진행했습니다.
NSP 과정
- 50% 확률로 문장 B 를 실제 이어지는 문장으로
- 50% 확률로 문장 B 를 임의로 샘플링한 문장으로
모델은 이를 이진 분류(True/False)로 학습합니다.
예시
문장 A: 나는 아침에 조깅을 한다. 문장 B: 그래서 기분이 상쾌하다. → IsNext 문장 B (랜덤): 파리는 프랑스의 수도이다. → NotNext
NSP 혼동되는 부분
1) NSP 는 unsupervised? supervised?
저보다 공부를 오래 혹은 많이 하셨거나 똑똑하신 분들은 제가 혼란스러워 하는 부분에 대해서 왜 혼란스러워 하지? 하실 수도 있습니다. 하지만 저는 labeled 데이터는 supervised 학습에 사용되는 데이터라고 배웠고 NSP 는 label 이 있는 데이터이므로 supervised 학습인거 같은데? 라고 조금 혼동이 왔습니다. 또한 논문에서도 이에 대해서 세세하게 설명하지 않고 있고 있고 단순히 “Self-supervised learning: the model learns from labels it creates itself.” 라고만 하고 있습니다. 그래서 이 부분에 대해서 찾아보니 학계에서는 supervised 학습은 사람이 만든 데이터를 이용해야만 supervised 학습이라고 하고 있고, BERT 의 NSP 에서 사용하는 데이터는 사람이 생성한 것이 아니라 모델이 생성한 것이므로 unsupervised 라고 보시면 됩니다.
2) NSP 학습을 위한 label 데이터는 어떻게 생성하지?
논문을 보면 저자가 명확하게 표현을 하지 않아 간혹 BERT 모델에서 자동으로 NSP 데이터를 생성한다고 오해할 수 있습니다. 이렇게 오해를 하게 되면 BERT 모델을 학습 하기 위해선 label 데이터가 필요한데 label 데이터 없이 어떻게 학습을 한다는거지? 라는 오해도 하게 됩니다. 하지만 BERT 모델이 생성하는 것이 아니라 BERT 모델에 적용하기 위한 데이터를 전처리 작업을 통해 생성하는 것으로 이해를 하시면 앞의 오해들이 풀리게 됩니다.
4. BERT 의 구조
BERT 의 구조는 Transformer 아키텍처의 Encoder 만 사용합니다. 그래서 구조는 Transformer 의 Encoder 구조와 동일합니다. 다만 기존 Transformer 에서 사용했던 파라미터 수의 차이가 있습니다.
4.1 모델 크기에 따른 파라매터 정리
$BERT_{BASE}$
- L(Layer) : 12
- H(Hidden) : 768
- A(slef-attention-head) : 12
- Total Parameters = 110M
$BERT_{LARGE}$
- L(Layer) : 24
- H(Hidden) : 1024
- A(slef-attention-head) : 16
- Total Parameters = 340M
4.2 BERT 의 입력
BERT 의 입력은 다음 세 가지 임베딩의 합으로 구성됩니다.
- Token Embedding: WordPiece 토큰 단위로 변환된 토큰 임베딩
- Segment Embedding: 문장 A, B를 구분하기 위한 임베딩
- Position Embedding: 위치 정보를 담는 임베딩
입력 예시:
[CLS] 나 는 학생 이다 . [SEP] 학교 에 간다 . [SEP]
4.3 BertTokenizer
BertTokenizer 는 BERT 에서 입력 문장을 처리하기 위해 사용하는 토크나이저(Tokenization) 도구 입니다. 최종적으로 텍스트를 모델이 이해할 수 있는 숫자 시퀀스로 변환하는 핵심 역할을 합니다. 예전에 제가 처음 BERT 를 공부했을 때 논문에서는 단순히 WordPiece 로 분리를 한다고만 하고 어떻게 분리를 하는지 설명이 없어 이해하기가 어려웠고, 특히 한국어 데이터를 BERT 에 학습 시키고자 했지만 이 토크나이저 때문에 큰 어려움이 있었습니다. 그래서 당시에도 ETRI 가 기업과 함께 KoBERT 모델 구축을 진행하면서 기존 BERT 의 토크나이저를 토대로 한국어도 비슷하게 토크나이저를 하도록 하기 위해 별도로 개발을 진행한 것으로 알고 있습니다. 지금은 단순히 이 토크나이저가 일종의 전처리기로써 크게 다루지 않는 분도 계시지만 사실 BERT 모델은 모델에 학습하도록 하는 데이터의 굉장히 중요하기 때문에 저는 이 토크나이저가 굉장히 중요하다고 보고 있습니다. 또한 파인 튜닝 학습을 진행하기 위한 데이터도 이 토크나이저를 이용한 토큰화 된 데이터를 사용해야 하기 때문에 저는 별도로 토크나이저 파트를 추가했습니다.
4.3.1 Tokenization 과정 요약
BertTokenizer는 다음 과정을 거쳐 입력을 처리합니다
- Basic Tokenization
- 공백 및 구두점 기준으로 문장을 분리
- 소문자화(lower-casing,
do_lower_case=True옵션)
- WordPiece Tokenization
- 어휘 사전에 없는 단어를 더 작은 서브워드로 분리
- 드물거나 신조어도 처리 가능
예시
단어: "playing" Token: ["play", "##ing"]
## 표시는 서브워드가 앞의 토큰에 이어지는 조각임을 나타냅니다.
4.3.2 Special Tokens
BERT 입력에는 반드시 특수 토큰(Special Tokens)이 포함됩니다:
[CLS]: 문장의 시작을 나타내는 토큰 (Classification)[SEP]: 문장 구분 토큰 (Segment A/B)[PAD]: 길이 맞추기를 위한 패딩 토큰[MASK]: MLM 학습 시 마스킹 토큰
예시 입력:
[CLS] 나는 사과를 좋아합니다 [SEP] 당신은요? [SEP]
4.3.3 Tokenizer 사용 예제
아래 예시는 Hugging Face transformers 라이브러리에서 BertTokenizer를 사용하는 기본 예제입니다.
from transformers import BertTokenizer
# 사전 학습된 토크나이저 불러오기
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# 문장 토크나이즈
text = "Transformers are amazing!"
tokens = tokenizer.tokenize(text)
print("Tokens:", tokens)
# 숫자 인덱스로 변환
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print("Input IDs:", input_ids)
# encode()는 한 번에 처리 (CLS, SEP 포함)
encoded = tokenizer.encode(text, add_special_tokens=True)
print("Encoded IDs:", encoded)
5. BERT 의 한계점과 개선 모델
BERT 는 이전에 사용되던 NLP 모델들 보다 성능이 좋긴했지만 그래도 여러가지 한계점 들이 존재했습니다. 여러 한계점들 중에서 제가 생각했을 때 중요한 몇 가지만 알아보고 한계점을 개선한 모델들에 대해서도 간단히 알아보도록 하겠습니다.
5.1 사전 학습과 추론의 불일치(Pre-training vs. Fine-tuning Gap)
-
BERT 는 사전 학습에서 MLM 을 사용해 입력 문장의 일부 단어를
[MASK]로 가립니다. 문제는 실제 추론할 때는[MASK]가 전혀 등장하지 않아 Distribution Mismatch 가 발생합니다. 이는 학습과 추론 간에 입력 데이터 분포가 달라 성능에 영향을 줄 수 있습니다. -
개선 시도: RoBERTa 에서는
[MASK]를 그대로 쓰면서도 데이터와 epoch 을 늘려 이 영향을 줄였고, ELECTRA 에서는 Masking 대신 Replaced Token Detection 을 도입하여 개선하였습니다.
5.2 NSP 의 한계
- BERT 논문에서는 NSP 가 문장 간 관계 학습에 효과적이라고 주장했지만, 후속 연구에서는 효영성이 크지 않다는 결과가 잇따랐습니다.
- RoBERTa 연구에서는 NSP 를 완전히 제거했을 때 오히려 성능이 향상됨
- 대규모 데이터와 학습 Step 수가 더 중요한 영향을 준다는 사실이 드러남.
- 개선 시도 : RoBERTa 는 NSP 를 삭제했고, ALBERT 는 더 정교한 Sentece Order Prediction 을 사용했습니다.
5.3 대규모 데이터와 자원이 필요함
- BERT 는 Wikipedia 와 BooksCorpus 약 33억 단어 규모의 데이터를 사전 학습에 사용했습니다.
- 자원이 없는 연구자나 기업은 사전 학습 모델을 활용할 수 밖에 없습니다.
6. 실습
실습은 구글 코랩에서 허깅페이스의 사전 학습된 BERT 모델을 이용했으며, CoLA 데이터를 이용해 문법적 수용성 분류 태스크 파인 튜닝 학습을 진행해서 문법적 수용성 분류 작업을 수행하는 BERT 모델 만들기를 진행했습니다.
6.1 데이터셋 설명
6.1.1 CoLA
CoLA 데이터셋 개요
CoLA 는 Corpus of Linguistic Acceptability 의 줄임말로 2018년 Warstadt, Singh, Bowman 이 발표한 데이터셋으로, 자연어 문장이 문법적으로 자연스러운지 어색한지를 판별하는 문법적 수용성 분류 태스크를 위한 데이터셋입니다.
CoLA 는 BERT 논문에서 GLUE 벤치마크 의 한 과제로 채택되었고, 이후 문장 수준의 문법 판단 태스크의 표준 데이터셋이 되었습니다.
데이터셋 구성
- 데이터 파일 형식
일반적으로 tsv(Tab-Separated Values) 파일로 제공됩니다. 파일 예시는 다음과 같습니다.
*가 붙은 문장은 문법이 틀린 문장입니다.
| index | label | source | sentence |
|---|---|---|---|
| 0 | 1 | Books1 | Our friends won’t buy this car. |
| 1 | 0 | Books1 | *Our friend won’t buys this car. |
| 2 | 1 | Books1 | They are not going. |
각 컬럼의 의미는 다음과 같습니다.
- index : 샘플 번호
- label:
- 1 : Acceptable
- 0 : Unacceptable
- source : 문장이 발췌된 출처(논문/책 이름)
- sentence : 문장 텍스트
- 데이터 분할
- 훈련 데이터(train.tsv) : 약 8,551 문장
- 개발 데이터(dev.tsv) : 약 1,043 문장
- 테스트 데이터(test.tsv) : 라벨이 숨겨져 있고 평가 서버에서만 점수를 받을 수 있음
6.2 평가 지표
평가 지표로는 처음엔 정확도(Accuracy) 를 사용했고, BERT 논문의 CoLA 에서는 MCC(Matthews Correlation Coefficient) 를 사용했다고 하여 해당 평가지표를 사용했습니다.
6.2.1 Matthews Correlation Coefficient(MCC)
MCC 개요
Matthews Correlation Coefficient 를 사용한 이유는 CoLA 데이터는 문장의 문법적 수용 가능성을 분류하는 binary classification 과제이지만, 클래스 불균형이 심합니다. 즉 수용 가능과 수용 불가능 클래스의 비율이 매우 다릅니다. 이런 상황에서 일반적은 accuracy 는 모델 성능을 적절하게 반영하기 어렵습니다. 그래서 이 때 사용하는 것이 MCC 평가 지표로 MCC 는 클래스 불균형에 강인하게 대응하면서 전반적인 상관 관계를 평가해 주는 지표입니다.
MCC 정의
MCC 는 confusion matrix 의 네가지 값(True Positive, False Positive, True Negative, False Negative)을 모두 고려해서 계산하며 식은 다음과 같습니다.
\[\text{MCC} = \frac{ (TP \times TN) - (FP \times FN) } { \sqrt{ (TP + FP)(TP + FN)(TN + FP)(TN + FN) } }\]MCC 값은 -1 ~ +1 범위를 가집니다.
- +1 : 완벽하게 일치
- 0 : 무작위 예측 수준
- -1 : 완전히 반대 예측
6.3 코드 설명
6.3.1 Hugging Face Transformer 설치
!pip install -q transformers
!pip install --upgrade transformers
# transformer 버전 확인
import transformers
print(transformer.__version__)
6.3.2 모듈 import 하기
import torch # PyTorch 라이브러리 가져오기
import torch.nn as nn # torch.nn 모듈을 nn 이름으로 가져오기
# TensorDataset : 텐서 데이터셋을 만들어주는 클래스 (입력과 라벨을 묶음)
# DataLoader : 학습/평가 시 데이터를 배치 단위로 로딩하는 클래스
# RandomSampler : 데이터셋에서 무작위로 샘플링
# SequentialSampler : 순차적으로 샘플링
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
# Scikit-learn 의 train_test_split 함수를 가져옴
# 데이터를 훈련/테스트 셋으로 분할할 때 사용
from sklearn.model_selection import train_test_split
# Hugging Face trainsformer 라이브러리에서 가져옴
# BertTokenizer : 문장을 BERT 모델에 입력할 수 있도록 토큰화 해주는 도구
# BertConfg : BERT 모델의 하이퍼파라미터 구성을 관리하는 클래스
from transformers import BertTokenizer, BertConfig
# PyTorch 에서 AdamW 옵티마이저를 가져옵니다.
from torch.optim import AdamW
# BertForSequenceClassification : 문장 분류를 위한 BERT 모델
# get_linear_schedule_with_warmup : 학습률을 일정하게 워밍업 후 선형적으로 감소시키는 스케쥴러 생성 함수
from transformers import BertForSequenceClassification, get_linear_schedule_with_warmup
# tqdm : 진행 상황을 표시하는 함수
# trange : range 와 동일하지만 자동으로 진행 표시줄이 붙음
from tqdm import tqdm, trange
# pandas 라이브러리를 pd 이름으로 가져옴
# 데이터프레임으로 CSV/Excep 등의 데이터를 다룰 때 사용
import pandas as pd
import io
import numpy as np
# matplotlib 의 pyplot 모듈을 plt 라는 이름으로 가져옴
# matplotlib 은 데이터 시각화에 사용됨
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
!nvidia-smi
6.3.3 CoLA dataset 로드
import os
!curl -L https://raw.githubusercontent.com/Denis2054/Transformers-for-NLP-2nd-Edition/main/Chapter03/in_domain_train.tsv --output "in_domain_train.tsv"
!curl -L https://raw.githubusercontent.com/Denis2054/Transformers-for-NLP-2nd-Edition/main/Chapter03/out_of_domain_dev.tsv --output "out_of_domain_dev.tsv"
위 코드를 실행하면 아래와 같은 실행 결과가 출력됩니다. 그리고 코랩에서 연결된 세션에서 다운로드 됩니다. 이는 터미널로 확인이 가능합니다.

# pandas 를 이용해 data 로드
# delimiter : 구분자
# header : 헤어 행 번호
# names : 컬럼 이름 직접 지정 (헤더 무시)
df = pd.read_csv(
"in_domain_train.tsv", # 읽어올 파일명
delimiter='\t', # 컬럼 구분자로 탭을 사용
header=None, # 첫 번째 행을 데이터로 처리 (헤더 없음)
names=['sentence_source', # 첫 번째 컬럼: 문장의 출처
'label', # 두 번째 컬럼: 라벨
'label_notes', # 세 번째 컬럼: 라벨 관련 노트
'sentence'] # 네 번째 컬럼: 실제 문장 텍스트
)
# 데이터 프레임의 크기를 출력합니다 (행 수, 열 수)
print(df.shape)
# 데이터프레임에서 무작위로 10개의 행을 샘플링해서 출력합니다.
df.sample(10)
위 코드를 실행하면 아래와 같은 실행 결과가 출력됩니다.
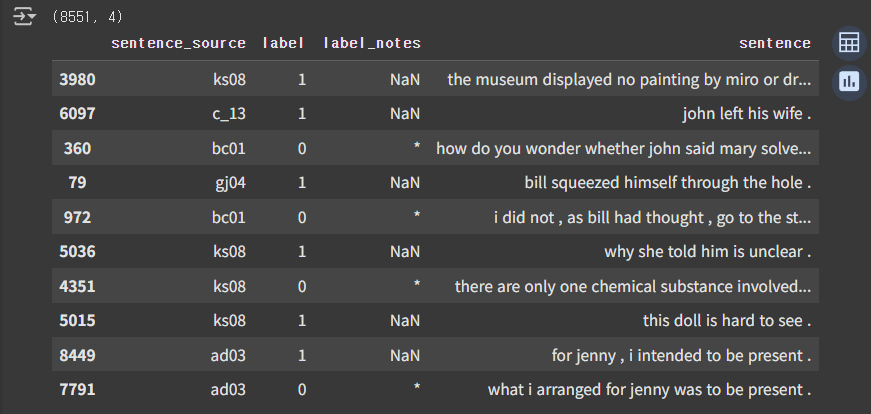
6.3.4 문장, 레이블 리스트 만들기, BERT token 추가하기
# sentence 컬럼에서 문장 데이터를 numpy 배열로 추출합니다.
sentences = df.sentence.values
# 각 문장 앞뒤에 [CLS]와 [SEP] 토큰을 붙여 BERT 입력 형식으로 만듭니다.
sentences = ["[CLS]" + sentence + " [SEP]" for sentence in sentences]
# label 컬럼에서 라벨 데이터를 numpy 배열로 추출합니다.
labels = df.label.values
6.3.5 Hugging Fafce BERT 모델의 토크나이저 다운로드
from transformers import BertTokenizer
try:
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)
print("Tokenizer downloaded successfully.")
except:
print("An error occurred while downloading the tokenizer.")
print(str(e))
import traceback
print(traceback.format_exc())
6.3.6 토크나이저를 이용해 문장을 토큰들로 분리하기
tokenized_texts=[tokenizer.tokenize(sent) for sent in sentences]
print("Tokenize the first sentence:")
print(tokenized_texts[0])
실행결과
Tokenize the first sentence:
['[CLS]', 'our', 'friends', 'wo', 'n', "'", 't', 'buy', 'this', 'analysis', ',', 'let', 'alone', 'the', 'next', 'one', 'we', 'propose', '.', '[SEP]']
6.3.7 데이터 처리하기
토큰들을 모델에서 사용하기 위한 숫자로 변환하는 과정입니다.
# 최대 시퀀스 길이를 설정합니다. 학습 데이터에서 가장 긴 시퀀스의 길이는 47이지만, 실제로는 최대 길이를 여유롭게 잡을 것입니다.
# 논문에서 저자는 512 길이를 사용했었습니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
MAX_LEN = 128
# 토큰을 BERT 사전의 인덱스 번호로 변환하기 위해서 BERT 토크나이저를 사용해야 합시다.
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
print(input_ids[0])
print([tokenizer.convert_ids_to_tokens(x) for x in input_ids[0]])
print(input_ids[1])
print([tokenizer.convert_ids_to_tokens(x) for x in input_ids[1]])
print("\n\n")
# 입력 토큰에 패딩을 추가해 줍니다.
input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, padding='post', dtype='long', truncating='post')
print(input_ids[0])
print(input_ids[1])
실행하면 다음과 같은 결과가 출력됩니다.
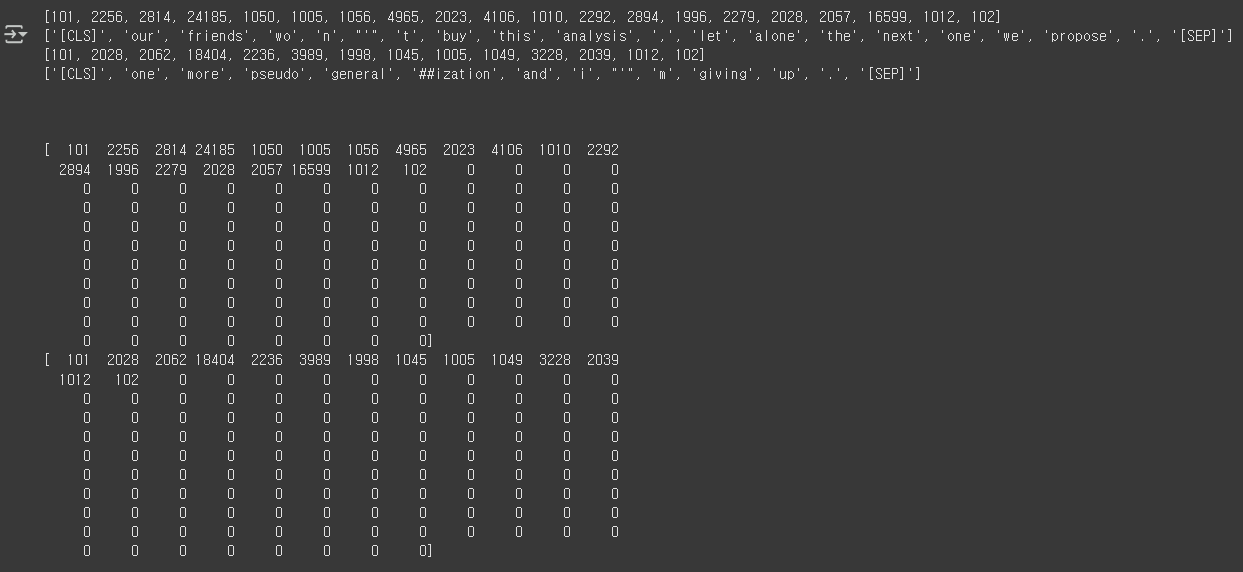
6.3.8 어텐션 마스크 생성하기
attention_masks = []
# 각 토큰에 대해 1 마스크를 생성하고 패딩에 대해 0 마스크를 생성합니다.
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)
6.3.9 데이터를 학습 및 검증 데이터셋으로 분리하기
# sklearn.model_selection 의 train_test_split을 사용해 데이터를 학습 및 검증 데이터셋으로 분리합니다.
train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(input_ids, labels, random_state=2018, test_size=0.1)
train_masks, validation_masks, _, _ = train_test_split(attention_masks, input_ids, random_state=2018, test_size=0.1)
6.3.10 모든 데이터를 토치 텐서로 변환하기
# 모델에 데이터를 입력하기 위해 토치 텐서 타입으로 변환해야 합니다
train_inputs = torch.tensor(train_inputs)
validation_inputs = torch.tensor(validation_inputs)
train_labels = torch.tensor(train_labels)
validation_labels = torch.tensor(validation_labels)
train_masks = torch.tensor(train_masks)
validation_masks = torch.tensor(validation_masks)
6.3.11 배치 사이즈 선택하기 및 이터레이터(Iterator) 생성하기
# 학습에 사용될 배치사이즈를 선택합시다. BERT 를 특정 테스크를 위해 미세 조정하기 위해서는 16 또는 32의 배치 사이즈를 추천합니다.
batch_size = 32
# 토치 DataLoader 를 사용해 데이터 이터레이터를 생성합니다. 이렇게 하면 학습 과정에서 루프를 사용하는 것보다 메모리 사용을 줄일 수 있습니다.
#이터레이터를 사용하면 전체 데이터를 메모리에 한 번에 로드할 필요가 없습니다.
train_data = TensorDataset(train_inputs, train_masks, train_labels)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)
validation_sampler = SequentialSampler(validation_data)
validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)
6.3.12 BERT 모델 설정하기
#BERT bert-base-uncased 설정 모델을 초기화하기
try:
import transformers
except:
print("Installing transformers")
!pip -qq install transformers
from transformers import BertModel, BertConfig
configuration = BertConfig()
# bert-base-uncased-style 설정을 사용해 모델을 초기화하기
model = BertModel(configuration)
# 모델 설정 불러오기
configuration = model.config
print(configuration)
위 코드를 실행하면 아래와 같이 현재 모델에 적용중인 config 값들을 확인할 수 있습니다.
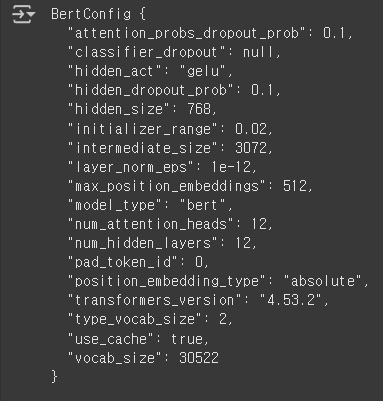
6.3.13 Hugging Face BERT uncased 모델 불러오기
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
model = nn.DataParallel(model)
model.to(device)
6.3.14 그룹 파라미터 최적화하기
param_optimizer = list(model.named_parameters())
no_decay=['bias', 'LayerNorm.weight']
# weight 파라미터를 bias 파라미터와 분리
# -weight 파라미터에 대해 weight_decay_rate 를 0.01 로 설정
# -bias 파라미터에 대해 weight_decay_rate 를 0.0 으로 설정
optimizer_grouped_parameters = [
{'params':[p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay_rate':0.1},
{'params':[p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay_rate':0.0}
]
print(optimizer_grouped_parameters)
6.3.15 학습 과정에 사용할 하이퍼파라미터 설정
epochs = 4
optimizer = AdamW(optimizer_grouped_parameters,
lr=2e-5, # args.learning_rate - default is 5e-5
eps = 1e-8 # args.adam_epsilon - default is 1e-8
)
# 전체 학습 스텝은 batch_size * epochs
# train_dataloader 에는 batch 작업이 처리된 데이터가 있으므로 전체 학습 스텝의 수는 train_dataloader 의 길이 * epochs 을 하면 됨
total_steps = len(train_dataloader) * epochs
# learning rate scheduler 만들기
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0,
num_training_steps = total_steps
)
6.3.16 정확도 측정 함수 만들기
# 정확도 측정 함수 만들기
# 라벨 대비 예측값의 정확도를 측정하기 위한 함수
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
6.3.17 학습 루프
t = []
# 그래프를 그리기 위해 손실 및 정확도를 저장합니다
train_loss_set = []
# trange 는 파이썬의 range 함수에 대한 tqdm 래퍼(wrapper) 입니다.
for _ in trange(epochs, desc="Epoch"):
# Training
# model 을 학습 모드로 변경
model.train()
# 변수 추적
tr_loss = 0
nb_tr_examples, nb_tr_steps = 0, 0
# 한 에폭당 데이터 학습
for step, batch in enumerate(train_dataloader):
# GPU 에 배치 추가
batch = tuple(t.to(device) for t in batch)
# dataloader 로 부터 입력 데이터 추출
b_input_ids, b_input_mask, b_labels = batch
# gradients 초기화
optimizer.zero_grad()
# Forward pass
outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)
loss = outputs['loss']
train_loss_set.append(loss.item())
# Backward pass
loss.backward()
# 파라매터 업데이트
optimizer.step()
# learning rate 업데이트
scheduler.step()
# Update tracking variables
tr_loss += loss.item()
nb_tr_examples += b_input_ids.size(0)
nb_tr_steps += 1
print("Train loss : {}".format(tr_loss/nb_tr_steps))
# 평가
# model 을 평가 모드로 변환
model.eval()
# 변수 추적
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
# 한 에폭에 검증 데이터로 평가 진행
for batch in validation_dataloader:
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# 평가 시에는 역전파를 하지 않도록 설정
with torch.no_grad():
# Forward pass, calculate logit prewdictions
logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
# Move logits and labels to CPU
logits = logits['logits'].detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
print("Validation Accuracy: {}".format(eval_accuracy/nb_eval_steps))
위 코드를 실행하면 아래와 같이 진행 상태와 loss, Accuracy 값이 출력됩니다.
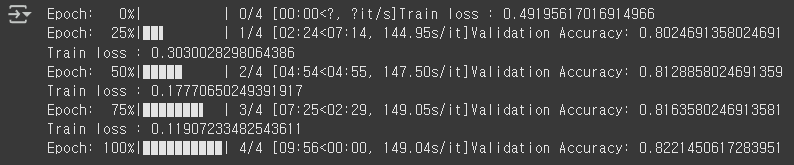
plt.figure(figsize=(15, 8))
plt.title("Training loss")
plt.xlabel("Batch")
plt.ylabel("Loss")
plt.plot(train_loss_set)
plt.show()
그리고 matplotlib 을 이용해 loss 값을 이미지로 나타내면 아래와 같습니다.
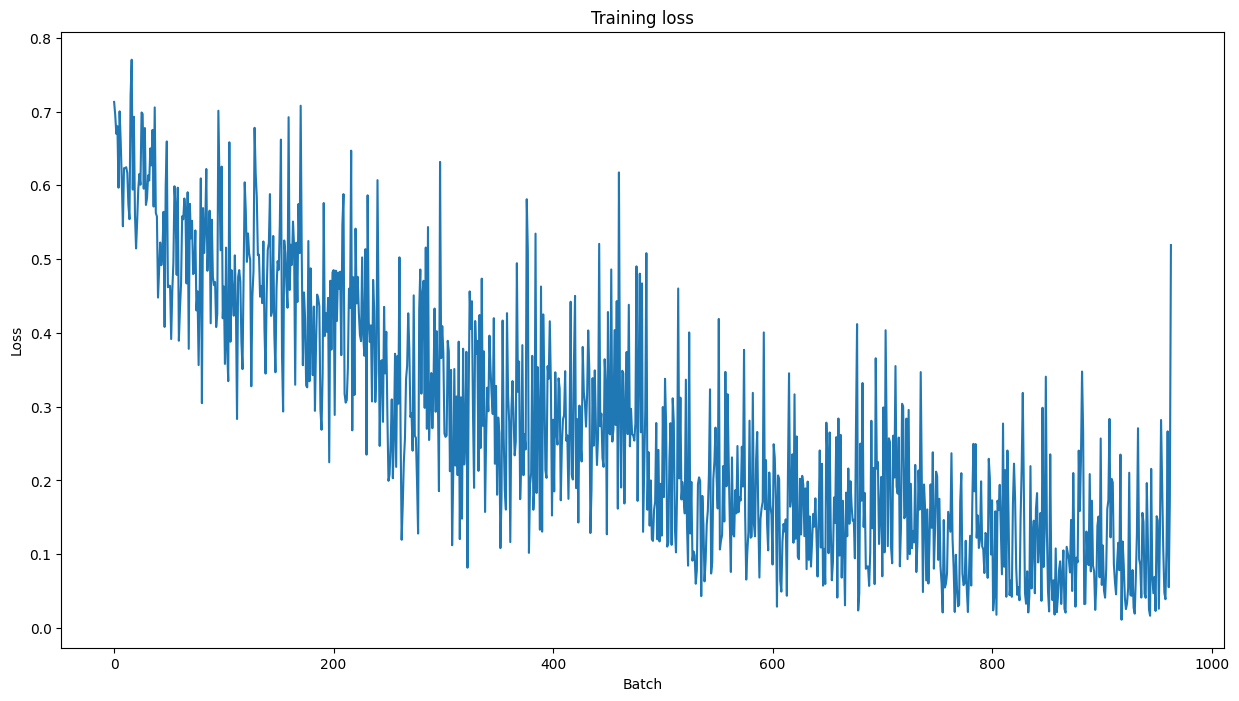
6.3.18 validation dataset 으로 평가
현재 공개되어 있는 CoLA 데이터셋은 학습과 검증 데이터만 오픈되어 있고 테스트 데이터를 오픈되어 있지 않아 학습 데이터를 이용해 검증 데이터를 만들고, 기존 검증 데이터를 테스트 데이터로 사용하였습니다.
#loading the holdout dataset
df = pd.read_csv("out_of_domain_dev.tsv", delimiter='\t', header=None, names=['sentence_source', 'label', 'label_notes', 'sentence'])
import numpy as np
import torch
# 결과 값을 확률 값으로 바꾸기 위한 softmax 함수
def softmax(logits):
e = np.exp(logits)
return e / np.sum(e)
# 문장과 label 리스트 생성
sentences = df.sentence.values
sentences = ["[CLS]" + sentence + "[SEP]" for sentence in sentences]
labels = df.label.values
tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]
MAX_LEN = 128
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")
attention_masks = []
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)
prediction_inputs = torch.tensor(input_ids)
prediction_masks = torch.tensor(attention_masks)
prediction_labels = torch.tensor(labels)
batch_size = 32
prediction_data = TensorDataset(prediction_inputs, prediction_masks, prediction_labels)
prediction_sampler = SequentialSampler(prediction_data)
prediction_dataloader = DataLoader(prediction_data, sampler=prediction_sampler, batch_size=batch_size)
# 학습된 모델을 이용해 테스트 데이터(검증 데이터)의 label 예측
# 모델 평가 모드로 설정
model.eval()
raw_predictions, predicted_classes, true_labels = [], [], []
for batch in prediction_dataloader:
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch
with torch.no_grad():
# 모델을 이용해 예측 결과를 얻어냄
outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
logits = outputs['logits'].detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# input_ids 에서 단어로 변환
b_input_ids = b_input_ids.to('cpu').numpy()
batch_sentences = [tokenizer.decode(input_ids, skip_special_tokens=True) for input_ids in b_input_ids]
# 소프트맥스 함수를 적용하여 로짓을 확률로 변환
probabilities = torch.nn.functional.softmax(torch.tensor(logits), dim=-1)
# argmax 적용해서 확률 값이 가장 큰 label 로 모델이 예측한 결과에 레이블 달기
batch_predictions = np.argmax(probabilities, axis=1)
# for i, sentence in enumerate(batch_sentences):
# print(f"Sentence: {sentence}")
# print(f"Prediction: {logits[i]}")
# print(f"Sofmax probabilities", softmax(logits[i]))
# print(f"Prediction: {batch_predictions[i]}")
# print(f"True label\n: {label_ids[i]}")
raw_predictions.append(logits)
predicted_classes.append(batch_predictions)
true_labels.append(label_ids)
6.3.19 Matthews Correlation Coefficient 를 이용해 평가하기
from sklearn.metrics import matthews_corrcoef
# 각 배치마다 Matthews correlation coefficient 값을 저장하기 위한 리스트 초기화
matthews_set = []
for i in range(len(true_labels)):
# sklearn.metrics 의 matthews_corrcoef 함수를 이용해 mcc 계산
matthews = matthews_corrcoef(true_labels[i], predicted_classes[i])
# 결과를 list 에 저장
matthews_set.append(matthews)
# true_labels 및 expected_classes 목록을 단일 목록으로 평면화합니다.
true_labels_flattened = [label for batch in true_labels for label in batch]
predicted_classes_flattened = [pred for batch in predicted_classes for pred in batch]
# 전체 데이터셋에 대한 mcc 값을 계산합니다.
mcc = matthews_corrcoef(true_labels_flattened, predicted_classes_flattened)
print(f"MCC: {mcc}")
실행 결과
MCC: 0.5187651504700211
BERT 논문에는 $BERT_{BASE}$ 모델 기준 MCC 값이 0.52로 되어 있습니다. 아마 논문에서 사용했던 모델과 그 모델에 적용된 여러 파라미터 차이로 인해 성능에 조금 오차가 있는 듯 합니다. 하지만 그래도 거의 비슷하게 나오는 것을 확인할 수 있습니다.
7. 마무리
BERT 에 대해서 알아보았고 실제 BERT 논문에서 사용한 데이터를 이용해 모델 학습까지 직접 진행해 보았습니다. 그리고 이후에 공부한 내용이 기억이 안날 때를 대비해 블로그에 정리까지 해보았습니다.
이번에 BERT 에 대해서 공부를 하면서 느낀 것은 BERT 는 Transformer 와 같이 획기적인 딥러닝 모델이라기 보다는 Transformer 모델에 사전 학습 방식을 이용한 방식이라 사실 Transformer 만 잘 이해하고 있다면 쉽다고 느껴졌습니다.
이번에 이렇게 BERT 에 대해서 공부를 했으므로 이후에 BERT 를 이용한 저만의 토이 프로젝트를 진행해 보려고 하며, 정리가 된다면 이번과 같이 포스트를 작성하도록 하겠습니다.
궁금하신 내용이나 잘못된 내용, 오타가 있을 경우 댓글로 알려주시길 바랍니다. 긴 글 읽어주셔서 감사합니다.
8. 참고 자료
Transformer 로 시작하는 자연어처리 저자, Denis Rothman
BERT 논문
Comments