
[Deeplearning] 파이토치로 알아보는 합성곱 신경망
이번엔 합성곱 신경망(Convolutional Neural Network) 줄여서 CNN 에 대해서 알아보도록 하겠습니다. 일반적으로 CNN 은 이미지 데이터를 처리할 때 주로 사용되는 모델인데 요즘엔 멀티 모달이 대세기 때문에 알아두면 좋을 것 같아 파이토치 기초에 대해서 공부하면서 다뤄보는게 좋겠다고 생각해서 알아보고자 합니다.
1. 합성곱 연산과 풀링 연산
1. 이미지 데이터
이미지는 픽셀이라는 기본 단위가 존재합니다. 따라서 이미지 데이터는 기본 단위로 구성된 행렬입니다. 예를 들어 크기가 128x128 이미지는 128x128 행렬로 표현되며, 색깔에 따라 각 성분의 값이 결정됩니다. 좀 더 자세히 설명하면 흑백 이미지는 하나의 행렬로 색을 표현할 수 있으므로, 이미지 크기는 128x128x1 이며 1을 채널(Channel)이라고 합니다. 즉 채널은 이미지 하나가 몇 장으로 구성되어 있는지를 나타내며, 대표적으로 널리 쓰이는 RGB 이미지는 빨강(R), 초록(G), 파랑(B) 채널의 값들이 적절히 합쳐져 색을 결정하는 형태로써 128x128x3 이미지라고 할 수 있습니다. 물론 3채널 이상의 이미지도 존재하며, RGB 가 아닌 H(색상), S(채도), V(명도)로 표현된 HSV 이미지 등의 다른 표현 방식들도 있습니다. 여기서 강조하고 싶은 것은 이미지도 숫자로 이루어져 있다는 것입니다. 일반적으로 사용되는 RGB 이미지는 기본적으로 0 이상 255 이하의 값이며 그 이미지 값을 이용해 이미지 크기 조정, 값의 스케일링, 이미지 변환, 노이즈 제거 등 다양한 연구들이 진행되고 있습니다. 이러한 것들을 이미지 처리(Image processing)라고 하며 수학적으로는 행렬과 벡터의 연산입니다.
2. MLP 와 이미지 처리
이전 포스트에서 다루었던 MLP 구조를 생각해 보면 입력층이 일렬 형태라는 것을 알 수 있습니다. 따라서 MLP 구조를 이용하여 사각형 모양의 사진을 처리하려면 이미지를 일렬 형태로 변환 후 모델에 입력시켜야만 합니다. 예를 들어 3x3 이미지 행렬은 9x1 벡터가 되어 모델에 들어가게 되고 모델은 일렬 형태의 이미지 벡터를 통해 학습을 합니다. 실제로 단순한 이미지 분류 문제에서는 MLP 도 좋은 성능을 보이지만 일반적으로 좋은 성능을 내기 어렵습니다. 그 이유는 행렬 성분을 순서대로 일렬로 붙여 벡터화 하기 때문에 이미지 내에 같은 객체가 있다고 하더라도 그 위치나 크기가 조금만 달라져도 벡터는 크게 변화할 수 있기 때문입니다. 즉, 같은 객체라도 완전히 다른 벡터로 변환되어 객체의 공통된 특성을 뽑아낼 수 없을 가능성이 커집니다. 따라서 전체 이미지를 벡터화 하지 않고 이미지의 일부분을 하나씩 살펴 보면서 전체 이미지를 해석할 필요가 있습니다. 이것이 바로 CNN 의 기본 개념이자 핵심 포인트입니다.
3. 합성곱 연산과 풀링 연산
앞서 강조했듯이 이미지의 일부분을 차례대로 훑어 보면서 이미지 전체를 파악하는 것이 CNN 의 기본 메커니즘입니다. 예를 들어 아래 그림과 같이 5x3 빨간 상자를 만들어 내부를 보고 다음 부분으로 이동을 시키면서 전체 부분을 살펴볼 수 있습니다. 따라서 부분들에서 얻어진 정보를 모아 이미지 한 장을 해석하기 때문에 이미지를 벡터로 만들었을 때보다 객체의 크기와 위치에 덜 민감합니다.
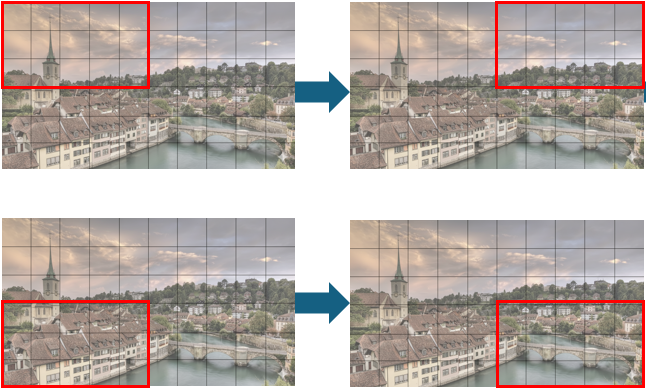
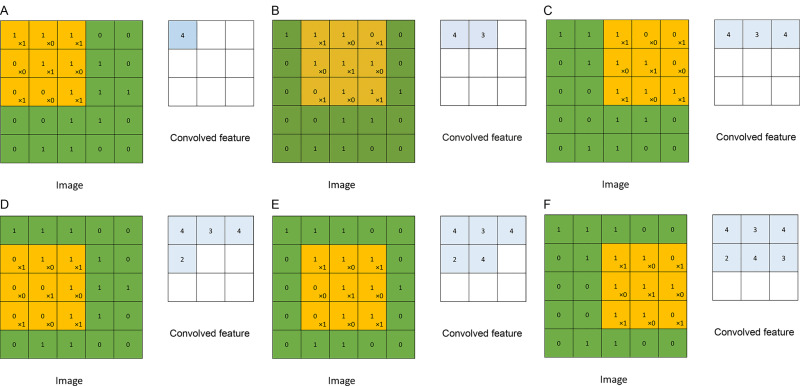
이 때 빨간 부분을 어떻게 보는지가 중요한데, 기본적으로 합성곱(Convolution)과 풀링(Pooling)이라는 방법을 통해 해당 부분을 해석하게 됩니다. 합성곱은 특정 값을 지닌 빨간 상자를 가지고 해당 부분의 이미지 값과 연산하는 방법으로써 빨간 상자를 필터(Filter) 혹은 커널(Kernel)이라고 합니다. 따라서 필터에 따라 추출되는 특성이 다르기 때문에 모델 최적화를 통해 적절한 필터의 값을 찾는 것이 목표가 됩니다.
합성곱 연산 - nn.Conv2d, torch.nn.functional.conv2d
합성곱은 필터가 위치한 부분에서 동일한 위치의 성분끼리 곱하여 전체를 더하는 것입니다. 필터가 움직이는 보폭(Stride)을 정할 수 있으며 이미지 밖을 특정 값으로 둘러싸는 패딩(Padding)을 이용할 수도 있습니다.
풀링 연산 - nn.AvgPool2d, torch.nn.functional.avg_pool2d / nn.MaxPool2d, torch.nn.functional.max_pool2d
풀링은 앞서 언급한 합성곱과 같은 방법으로 진행됩니다. 다만 커널 안에서의 연산이 다를 뿐입니다. 일반적으로 영역 내에서 최댓값을 뽑아내는 최댓값 풀링(Max pooling)과 평균값을 뽑아내는 평균값 풀링(Average pooling)이 많이 사용됩니다. 또한 기본적으로 풀링은 커널의 크기와 보폭을 같게 함으로써 이동하는 커널이 같은 부분을 중복 계산하지 않게 합니다. 즉, 영역별 대표값을 하나씩 뽑아내는 연산이며 주로 컨볼루션 층 다음에 배치합니다.
2. AlexNet
AlexNet 은 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 2012 대회에서 우승을 차지한 CNN 이며 가장 기본적인 CNN 모델이라고 할 수 있습니다. 원 논문에서는 현재는 쓰이지 않는 기술들이 적용되어 파이토치에서는 이런 부분들을 수정하여 모델을 제공하고 있습니다. 이번엔 파이토치에서 제공하는 모델을 사용하지 않고 직접 해당 모델을 구현해 보도록 하겠습니다.
2.1 라이브러리 불러오기
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
2.2 CIFAR10 데이터 세트 불러오기
transforms.Normalize 은 특정 평균과 표준편차를 따르는 정규분포를 통해 이미지를 표준화하는 방법입니다. CIFAR10 은 3채널 컬러 이미지이므로 각 장의 평균과 표준편차를 정합니다. 첫 번째 (0.5, 0.5, 0.5)는 각 채널 당 평균을 할당한 것이고 튜플로 입력합니다. 두 번째 (0.5, 0.5, 0.5)는 각 채널의 표준편차를 기입한 것입니다. 평균과 표준편차는 학습 전에 가지고 있는 이미지로부터 계산하지만 이번 예시에서는 임의의 값 0.5를 기입합니다.
# 데이터의 형태를 텐서로 바꾸고 transforms.Normalize 를 이용해 정규화를 진행하는 전처리기를 정의
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# CIFAR-10 데이터셋을 다운로드 받아온다
trainset = torchvision.datasets.CIFAR10(root="./data", train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
testset = torchvision.datasets.CIFAR10(root="./data", train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)
2.3 GPU 연산 체크하기
일반적으로 CNN 은 깊고 복잡합니다. 따라서 다수의 필터를 계산하고 업데이트해야 하기 때문에 GPU 가 필수적인 요소입니다. 따라서 GPU 연산이 활성화되어 있는지 확인해야합니다. 만약 비활성화 상태라면 코랩에서 GPU 연산으로 옵션을 변경합니다. 그리고 torch.device 를 통해 GPU 가 가능한 텐서로 연산을 수행할 수 있습니다.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"{device} is available")
cuda:0 is available 은 GPU 를 사용할 수 있다는 의미입니다.
Output: cuda:0 is available
2.4 AlexNet 구축하기
본래 AlexNet 은 ImageNet 데이터를 위해 만들어졌습니다. ImageNet 은 1000개의 클래스로 분류되어 있는 256x256 또는 224x224 크기를 갖는 이미지입니다. 따라서 크기가 32x32 인 CIFAR10 이미지는 제대로 동작 안 할 수 있습니다. 따라서 데이터에 맞게 필터의 크기와 보폭의 수를 조정해 모델을 구축합니다.
nn.Sequential 를 이용하면 순차적으로 행해지는 연산을 한 번에 묶을 수 있습니다. nn.Sequential 의 괄호 안은 작성 순서대로 연산이 수행됩니다.
self.features 는 합성곱 연산과 풀링 연산이 행해지는 특징추출(Feature extraction) 부분입니다.
CIFAR10 은 RGB 컬러 이미지입니다. 따라서 입력 채널의 수가 3이므로 반드시 nn.Conv2d 에서 입력 채널 수에 3을 입력해야 합니다(즉, nn.Conv2d(3(입력 채널 수), 64(출력 채널 수), 3(필터의 크기))). 채널의 출력크기는 임의로 정해줍니다. 보폭은 별도로 지정하지 않았으므로 기본값 1로 진행됩니다. 다음 활성화 함수 nn.ReLU 를 적용합니다.
2x2 크기의 필터를 2칸씩 이동하는 최댓값 풀링 nn.MaxPool2d(필터의 크기, 보폭)을 시행합니다.
위와 같은 방법으로 층을 쌓습니다(기본적으로 이전 층의 출력값과 다음 층의 입력값의 크기는 같아야 합니다). padding=1 은 해당 층의 입력 피쳐맵의 가장 외곽을 0으로 한 겹 둘러싼다는 의미입니다. 예를 들어 100x100 피쳐맵에 한 겹을 씌우면 102x102가 되며 가장 외곽의 값은 0이 됩니다. 또한 외곽을 0으로 채우는 영패드(Zero pad) 이외에도 padding_mode 를 통해 다른 패드를 사용할 수 있습니다. (zeros, reflect, replicate, circular).
self.classifier 는 Fully-connected layer 로 구성해 정의합니다.
self.classifier 의 첫 번째 Linear Layer 에서 유의할 점은 처음 들어오는 입력값의 크기와 self.features 에서 나온 피쳐맵을 일렬로 편 벡터의 크기가 같아야 합니다.
self.classifier 의 마지막 노드 수는 10이 되어야 합니다. 그 이유는 CIFAR10은 10개의 클래스를 가진 데이터여서 그렇습니다. 나머지 노드 수나 드롭아웃은 사용자가 임의로 정할 수 있습니다.
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
# 특징 추출기
# 이미지를 스캔하여 주요 특징(feature)을 뽑아내는 부분입니다.
# nn.Sequential 을 사용하여 여러 레이어를 순차적으로 묶습니다.
# 입력 이미지: (Batch_size, 3, 32, 32)
self.features = nn.Sequential(
# nn.Conv2d(입력 채널 수, 출력 채널 수, 커널 크기)
# 1차 Conv: (32-3)/1 + 1 = 30
# (3, 32, 32) -> (64, 30, 30)
nn.Conv2d(3, 64, 3), nn.ReLU(),
# 1차 Pool : 30 / 2 = 15
# (64, 30, 30) -> (64, 15, 15)
nn.MaxPool2d(2, 2),
# 2차 Conv : (15-3 + 2x1)/1 + 1 = 15 (패딩(padding=1)으로 크기 유지)
# (64, 15, 15) -> (192, 15, 15)
nn.Conv2d(64, 192, 3, padding=1), nn.ReLU(),
# 2차 Pool : 15 / 2 = 7 (소수점 버림)
# (192, 15, 15) -> (192, 7, 7)
nn.MaxPool2d(2, 2),
# 3차 Conv : (7-3 + 2x1)/1 + 1 = 7 (패딩으로 크기 유지)
# (192, 7, 7) -> (384, 7, 7)
nn.Conv2d(192, 384, 3, padding=1), nn.ReLU(),
# 4차 Conv : (7-3 + 2x1)/1 + 1 = 7 (패딩으로 크기 유지)
# (384, 7, 7) -> (256, 7, 7)
nn.Conv2d(384, 256, 3, padding=1), nn.ReLU(),
# 5차 Conv : (7-1)/1 +1 = 7 (패딩으로 크기 유지)
# (256, 7, 7) -> (256, 7, 7)
nn.Conv2d(256, 256, 1), nn.ReLU(),
# 3차 Pool : 7/2 = 3 (소수점 버림)
# (256, 7, 7) -> (256, 3, 3)
nn.MaxPool2d(2, 2)
# self.features 의 최종 출력 텐서 형태 : (Batch_size, 256, 3, 3)
)
# 2. 분류기 (Fully Connected Layers)
# features 에서 추출된 (256, 3, 3) 크기의 특징 맵을 3차원 벡터로 펼쳐서(flatten) 분류를 수행
self.classifier = nn.Sequential(
nn.Dropout(0.5),
# 1차 FC : 입력 뉴런 수 = 256x3x3 = 2304
# (Batch_size, 2304) -> (Batch_size, 1024)
nn.Linear(256*3*3, 1024), nn.ReLU(),
nn.Dropout(0.5),
# 2차 FC : (Batch_size, 1024) -> (Batch_size, 512)
nn.Linear(1024, 512), nn.ReLU(),
# 3차 FC(최종 출력) : 10개의 클래스로 분류
# (Batch_size, 512) -> (Batch_size, 10)
nn.Linear(512, 10)
)
def forward(self, x):
"""
입력(x) 을 받아 모델을 통과시킨 후 결과를 반환하는 함수
x : 입력 이미지 텐서 (Batch_size, 3, 32, 32)
"""
# 1. 특징 추출
# x : (Batch_size, 3, 32, 32) -> (Batch_size, 256, 3, 3)
x = self.features(x)
# 2. 1차원으로 펼치기(Flatten)
# .view()를 사용하여 텐서의 모양을 (Batch_size, 256x3x3)으로 변경
# -1은 배치 크기를 자동으로 맞추라는 의미
# x: (Batch_size, 256, 3, 3) -> (Batch_size, 2304)
x = x.view(-1, 256*3*3)
# 3. 분류
# x: (Batch_size, 2304) -> (Batch_size, 10)
x = self.classifier(x)
# 최종 반환 값 : 10개 클래스에 대한 점수(logits)
return x
2.5 손실 함수 및 최적화 방법 정의하기
다중 분류 문제에서는 Cross Entropy Loss 를 기본으로 사용합니다. 파이토치에서 제공하는 Cross Entropy Loss 는 softmax 계산까지 포함되어 있으므로 모델의 마지막 출력값에 별도의 softmax 를 적용하지 않아도 됩니다. 그리고 GPU 연산을 위해 모델을 불러올 때 .to(device) 를 반드시 붙여줍니다.
criterion = nn.CrossEntropyLoss()
alexnet = AlexNet().to(device)
optimizer = optim.Adam(alexnet.parameters(), lr=1e-3)
2.6 AlexNet 모델 학습하기
loss_ = []
n = len(trainloader)
for epoch in range(50):
running_loss = 0.0
for data in trainloader:
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = alexnet(inputs)
# 손실 함수 CrossEntropy 에는 softmax 가 적용되어 자동으로 10개의 벡터 중 가장 큰 값을 가진 벡터의 클래스를 뽑아줌
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
loss_.append(running_loss/n)
print("[%d] loss: %.3f" %(epoch+1, running_loss / len(trainloader)))
Output:
[1] loss: 1.657
[2] loss: 1.242
[3] loss: 1.060
[4] loss: 0.937
[5] loss: 0.858
[6] loss: 0.793
[7] loss: 0.732
[8] loss: 0.687
[9] loss: 0.645
[10] loss: 0.610
... 이하 생략 ...
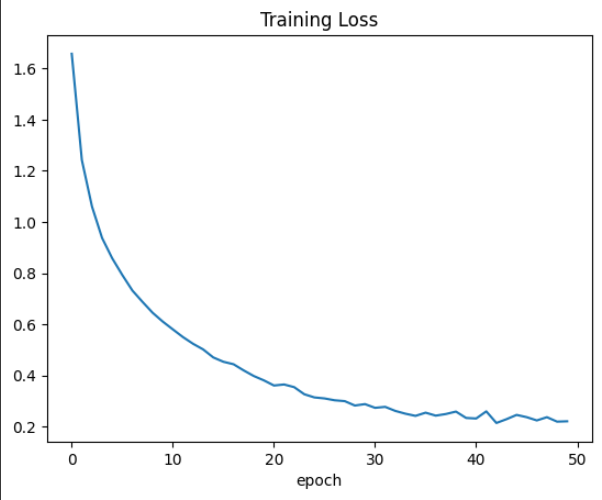
2.7 학습 손실 함수 그래프 그리기
plt.plot(loss_)
plt.title("Training Loss")
plt.xlabel("epoch")
plt.show()
2.8 파이토치 모델 저장 및 불러오기
평가가 잘 되었다면 추후 이어서 학습을 하거나 실험 자료를 남기기 위해 모델을 저장해야 합니다.
PATH = "/content/drive/MyDrive/pytorch/models/cifar_alexnet.pth"
torch.save(alexnet.state_dict(), PATH)
모델 저장은 모델을 통째로 저장하는 것이 아니고 모델 파라미터를 저장하는 것입니다. 따라서 저장된 모델을 불러올 때 모델이 선행적으로 선언되어 있어야 합니다. 그리고 새로 선언한 모델에 이전에 저장한 모델의 파라미터를 불러와 모델에 주입합니다.
alexnet = AlexNet().to(device)
alexnet.load_state_dict(torch.load(PATH))
2.9 평가하기
평가 시에는 requires_grad 를 비활성화 합니다.
평가 시에는 드롭아웃 등과 같은 정규화 작업을 시행해서는 안됩니다. 따라서 alexnet.eval() 을 선언하여 정규화 작업을 비활성화 합니다.
outputs 은 크기가 (배치 크기)x10 인 벡터 형태로 나옵니다. 따라서 열 기준으로 가장 큰 원소의 위치가 라벨이 되는 것이기 때문에 최댓값을 열(1) 기준으로 계산하여 예측값을 구합니다. torch.max 는 최댓값과 최댓값의 위치를 산출해주는데 여기서 우리는 최댓값은 필요가 없으므로 받지 않아도 됩니다. 따라서 _ 로 처리하여 해당 출력값은 저장하지 않습니다.
correct = 0
total = 0
with torch.no_grad():
alexnet.eval()
for data in testloader:
# 테스트 데이터에서 입력 이미지와 라벨을 추출
images, labels = data[0].to(device), data[1].to(device)
# 학습한 모델이 입력 이미지를 넣고 출력 벡터를 추출
outputs = alexnet(images)
# 모델로부터 추출한 출력 벡터에 torch.max 를 적용해 가장 큰 벡터 값을 가지는 index 를 클래스로 뽑음
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
# 예측 결과와 실제 라벨이 같은 경우에 correct 에 값 누적
correct += (predicted == labels).sum().item()
print("Test accuracy: %.2f %%" %(100 * correct / total))
Output:
Test accuracy: 75.08 %
3. ResNet
ResNet 은 ILSVRC(ImageNet LArge Scale Visual Recognition Challenge) 2015 대회에서 우승을 차지한 합성곱 신경망이며, 이후 CNN 에서 중요한 개념으로 자리 잡은 Residual block 을 제안한 모델입니다.
스킵 커넥션(Skip connection)이란 아래 그림과 같이 여러 레이어를 건너 뛰어 이전 정보를 더하는 것을 의미하며, 이 하나의 과정을 묶어 만든 것이 Residual block 입니다. Residual block 의 위치나 구조에 따라 성능이 달라질 수 있지만, 기본적으로 합성곱 층 2, 3 칸을 뛰어 넘어 더하는 방식을 사용합니다. ResNet 은 Residual block 여러 개를 붙여 놓은 모델이며, 모델명에 붙은 숫자는 층의 개수를 의미합니다. 즉, ResNet18 은 층이 18개이고, ResNet34 는 34개의 층을 가지고 있는 모델입니다.
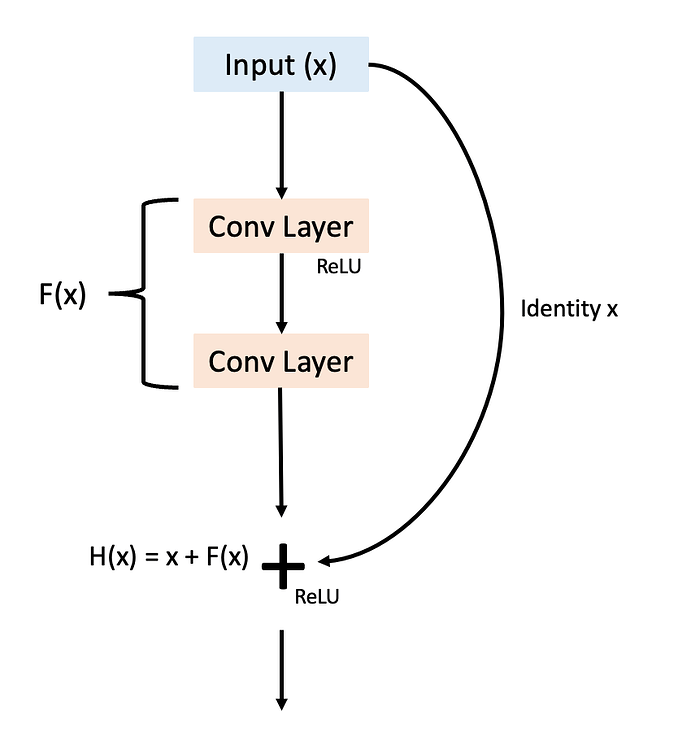
ImageNet 데이터에 맞춰진 ResNet 은 기본층에서 7x7 필터를 사용하는 합성곱과 3x3 맥스 풀링을 사용합니다. CIFAR10 은 이미지 사이즈가 ImageNet 이미지 보다 훨씬 작기 때문에 기본층의 합성곱 필터 사이즈를 3x3 으로 줄이고 맥스풀링을 생략합니다. 또한 ResNet18 과 ResNet34 는 동일한 블록을 사용하기 때문에 층을 조절하여 두 모델을 구현할 수 있습니다. 아래 그림은 ResNet18 과 ResNet34 의 층을 비교한 그림입니다.

3.1 Residual block 구축하기
nn.BatchNorm2d(self.out_channels) 는 학습을 빠르게 할 수 있는 배치 정규화입니다. 배치 정규화는 각 배치의 평균과 분산을 이용해서 데이터를 정규화하는 방법입니다.
ResNet 은 Residual Block 하나를 거칠 때마다 이미지 사이즈가 줄어들고 채널 수는 늘어나는 구조입니다. 따라서 처음 들어오는 x 값과 블록을 거친 출력값 out 의 크기가 같아야만 합니다. 따라서 차이가 나는 경우 출력값의 크기와 입력값의 크기를 동일하게 하기 위해 별도의 컨볼루션 연산을 진행하여 입력 크기를 출력 크기와 맞춰줍니다.
# ResNet 의 핵심 구성 요소 : ResidualBlock (잔차 블록)
# ResNet 은 "스킵 커넥션(Skip Connection)"을 통해 입력(x)을 연산(F(x))에 더해줌으로써 기울기 소실 문제를 완화하고 깊은 망을 학습할 수 있게 합니다.
class ResidualBlock(nn.Module):
"""
ResNet 의 기본 단위가 되는 잔차 블록(Residual Block)입니다.
하나의 블록은 2개의 3x3 conv 레이어로 구성됩니다.
"""
def __init__(self, in_channels, out_channels, stride=1):
"""
Args:
in_channels (int): 이 블록으로 들어오는 입력 채널 수
out_channels (int): 이 블록에서 나가는 출력 채널 수
stride (int): 첫 번째 Conv 레이어의 보폭(stride) 1이면 크기 유지, 2이면 크기 절반으로 축소(다운샘플링)
"""
super(ResidualBlock, self).__init__()
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
# 2개의 3x3 Conv 와 BatchNorm, ReLU 로 구성
self.conv_block = nn.Sequential(
# 첫 번째 Conv: stride 에 따라 크기가 변할 수 있음
# 3x3, padding=1, stride=1 -> 크기 유지
# 3x3, padding=1, stride=2 -> 크기 절반
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(self.out_channels), nn.ReLU(),
# 두 번째 Conv: 항상 stride=1 (크기 유지)
nn.Conv2d(self.out_channels, self.out_channels, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(self.out_channels)
)
# 스킵 커넥션 부분
# 메인 경로(A) 의 출력과 스킵 커넥션을 더하려면 두 텐서의 차원(채널, 높이, 너비)이 동일해야 함
# 1. stride=2 라서 공간적 크기가 절반이 되었거나
# 2. 채널 수가 in_channels != out_channels로 변경된 경우,
# 스킵 커넥션(x)도 동일하게 다운샘플링 및 채널 변경을 해줘야 함
if self.stride != 1 or self.in_channels != self.out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(self.out_channels)
)
def forward(self, x):
# (A) 메인 경로 연산
out = self.conv_block(x)
# (B) 스킵 커넥션 처리
# 차원 변경이 필요한 경우 (stride=2 또는 채널 변경)
if self.stride != 1 or self.in_channels != self.out_channels:
x = self.downsample(x)
# (A) + (B) : 메인 경로의 출력과 스킵 커넥션의 출력을 더함
out = F.relu(x + out)
return out
3.2 ResNet 모델 구축하기
self.base 는 입력 이미지가 들어와 연산을 수행하는 기본층을 만듭니다.
기본층을 제외한 4개의 블록이 필요합니다. 따라서 self._make_layer 을 이용해 4개의 블록 묶음을 선언합니다.
self.gap = nn.AvgPool2d(4) 는 합성곱 층들을 지나면 최종적으로 크기가 4x4 인 피쳐맵 512개가 나옵니다. 크기가 4x4인 평균 풀링을 이용하면 각 피쳐맵 당 1개의 평균값이 나오기 때문에 성분이 512개인 벡터를 얻을 수 있습니다.
self.fc = nn.Linear(512, num_classes) 클래스가 10개인 이미지를 분류하는 것이므로 최종적으로 512개의 노드에서 10개의 노드로 가는 FC 를 정의합니다.
_make_layer ResidualBlock 을 불러와서 append 를 이용해 차례대로 붙여줍니다. 이 때 이전 출력 채널 크기와 다음 입력 채널 크기가 같아야 하므로 self.in_channels = out_channels 를 적용해 줍니다.
class ResNet(nn.Module):
def __init__(self, num_blocks, num_classes=10):
"""
Args:
num_blocks (list) : 4개 스테이지 각각에 들어갈 ResidualBlock의 수(e.g., ResNet18 = [2, 2, 2, 2])
num_classes (int) : 최종 분류할 클래스 수 (e.g., CIFAR-10 = 10)
"""
super(ResNet, self).__init__()
# _make_layer 헬퍼 함수에서 다음 레이어의 입력 채널을 알 수 있도록 현재 레이어의 출력 채널을 추적하는 변수입니다.
self.in_channels = 64
# 3x32x32 입력 이미지 기준 (CIFAR-10)
# ResNet 의 첫 번째 레이어
# (3, 32, 32) -> (64, 32, 32) (stride=1, padding=1이므로 크기 유지)
self.base = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(64), nn.ReLU()
)
# --- 4개의 메인 스테이지 ---
# _make_layer(출력 채널, 블록 수, stride)
# Layer 1: (64, 32, 32) -> (64, 32, 32)
# 64 채널, stride=1 (크기 유지), 블록 num_blocks[0]개
self.layer1 = self._make_layer(64, num_blocks[0], stride=1)
# Layer 2 : (64, 32, 32) -> (128, 16, 16)
# 128 채널, stride=2 (크기 절반), 블록 num_blocks[1]개
self.layer2 = self._make_layer(128, num_blocks[1], stride=2)
# Layer 3: (128, 16, 16) -> (256, 8, 8)
# 256 채널, stride=2 (크기 절반), 블록 num_blocks[2]개
self.layer3 = self._make_layer(256, num_blocks[2], stride=2)
# Layer 4: (256, 8, 8) -> (512, 4, 4)
# 512 채널, stride=2 (크기 절반), 블록 num_blocks[3]개
self.layer4 = self._make_layer(512, num_blocks[3], stride=2)
# Global Average Pooling(GAP)
# Layer 4의 최종 출력(512, 4, 4)에 4x4 AvgPool 을 적용하여 (512, 1, 1)텐서로 만듭니다. (공간 정보를 채널 정보로 압축)
self.gap = nn.AvgPool2d(4)
# Fully Connected (FC) Layer
# (512, 1, 1)을 1차원으로 펼친 512개 입력을 받아 num_classes로 출력
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, out_channels, num_blocks, stride):
"""
ResidualBlock을 `num_blocks` 개수만큼 쌓아서 하나의 스테이지(레이어)를 만듭니다.
"""
# [stride, 1, 1, ..., 1] 형태의 리스트 생성
# 예시 : num_blocks=3, stride=2 -> [2, 1, 1]
# -> 첫 번째 블록만 stride=2 (다운샘플링)
# -> 나머지 블록은 stride=1 (크기 유지)
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
block = ResidualBlock(self.in_channels, out_channels, stride)
layers.append(block)
# 중요 : 다음 블록의 입력 채널(in_channels)은 방금 만든 블록의 출력 채널(out_channels)이 됩니다.
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
# x: (Batch_size, 3, 32, 32)
# Base
out = self.base(x) # (B, 64, 32, 32)
# Layers
out = self.layer1(out) # (B, 64, 32, 32)
out = self.layer2(out) # (B, 128, 16, 16)
out = self.layer3(out) # (B, 256, 8, 8)
out = self.layer4(out) # (B, 512,4, 4)
# GAP
out = self.gap(out) # (B, 512, 1, 1)
# Flatten
# (B, 512, 1, 1) -> (B,512)
out = out.view(out.size(0), -1)
# FC Layer
out = self.fc(out) # (B, num_classes)
return out
클래스를 불러오는 함수를 만듭니다. 각 모델마다 블록의 반복 횟수를 리스트로 정의하여 입력하도록 합니다.
# 모델 생성 헬퍼 함수
def modeltype(model):
"""
문자열을 입력받아 특정 ResNet 모델을 생성
"""
if model == "resnet18":
# ResNet18 = [2, 2, 2, 2] -> 각 스테이지에 블록 2개씩
return ResNet([2, 2, 2, 2])
elif model == "resnet34":
# ResNet34 = [3, 4, 6, 3]
return ResNet([3, 4, 6, 3])
3.3 ResNet18 학습 및 평가하기
AlexNet 평가에서 사용한 코드로 데이터 받아오기와 학습, 평가 과정을 동일하게 진행합니다. 결과적으로 ResNet18 의 평가 정확도는 82.98% 로 75.08% 이었던 AlexNet 보다 7.9%나 높은 것을 확인할 수 있었습니다.
Output: Test accuracy: 82.98 %
마치며
이번엔 CNN 에 대해서 알아보았습니다. 특히 AlexNet 과 ResNet 이라는 이전에 많이 사용되었던 CNN 을 이용한 모델들을 이용해 간단한 실제 데이터로 학습을 시켜보고 성능까지 측정해 보았습니다. 이번 포스트를 작성하면서 복잡한 모델들을 직접 구현해 보면서 다시 한 번 파이토치를 이용해 어떻게 하면 자신이 설계한 모델을 구현할 수 있는지 알게 되었습니다. 이번 포스트에는 CNN 의 자세한 동작 원리에 대해선 다루지 않았는데 조만간 기회가 되면 좀 더 기본적이고 자세한 CNN 의 동작 원리에 대해서도 다뤄보도록 하겠습니다. 긴 글 읽어주셔서 감사드리며, 잘못된 내용이나 오타 혹은 궁금하신 사항이 있을 경우 댓글 달아주시기 바랍니다.
Comments