
[Deeplearning] 파이토치로 알아보는 순환 신경망
파이토치를 이용해 순환 신경망인 RNN 에 대해서 알아보도록 하겠습니다.
1. 기본 순환 신경망
1.1 시계열 데이터
시계열 데이터란 일정 시간 간격으로 배치된 데이터입니다. 대표적으로 시간에 따른 온도, 주식, 신호, 변화 등의 데이터가 있고, 추가적으로 음성, 대화 등의 데이터와 같이 단어가 나열된 형태로 연속적으로 관계가 있는 데이터라고 볼 수 있습니다.
1.2 기본 인공 신경망과 순환 신경망
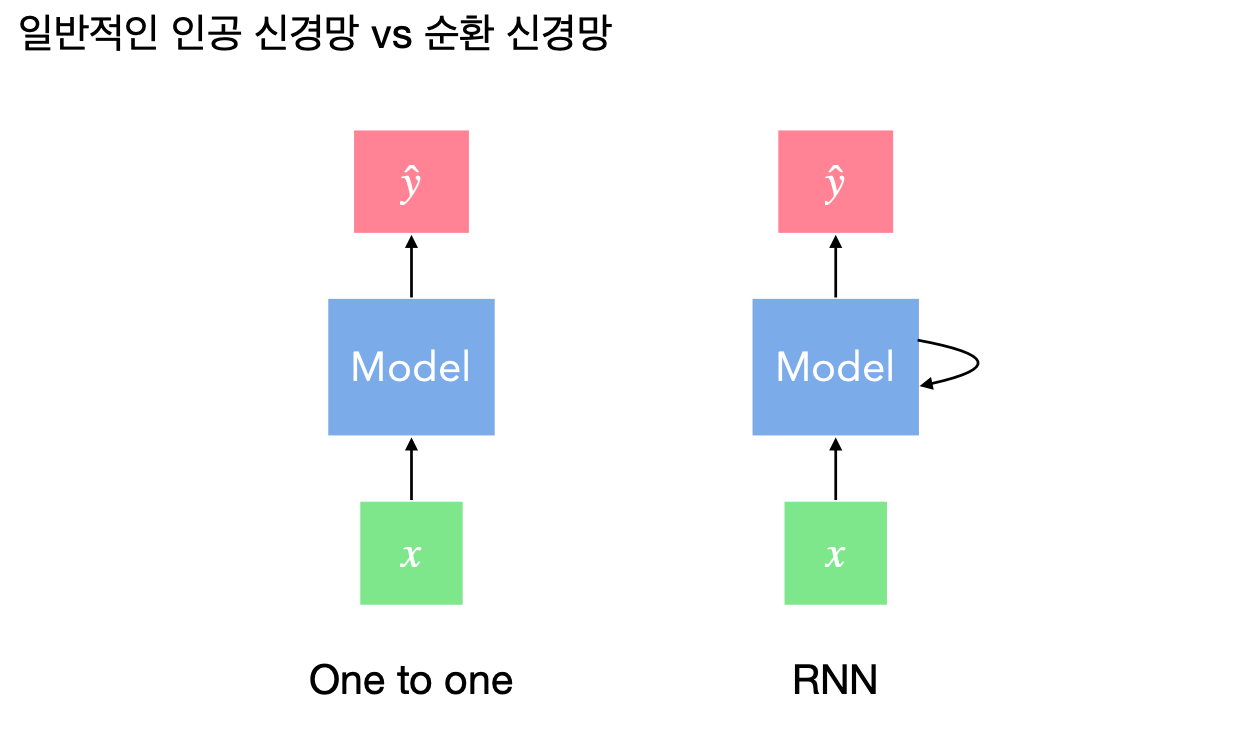
순환 신경망(Recurrent Neural Network)은 시퀀스 데이터를 예측하기 위해 만들어진 모델로 시계열 예측 기술의 근간이라고 할 수 있습니다. 기본적인 인공 신경망은 입력값 하나가 들어오면 출력값 하나를 산출하며 이전 입력값과 다음 입력값의 관계는 고려하지 않습니다. 이를 개선하기 위해 아래 그림과 같이 이전 단계에서 계산된 정보를 가공해서 다음 단계의 계산에 반영하는 것이 순환 신경망입니다.
1.3 순환 신경망의 다양한 형태
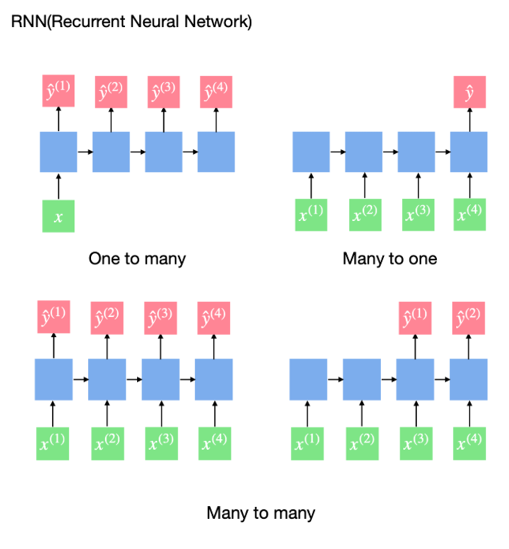
순환 신경망은 다양한 구조가 있습니다. One to Many 방식은 하나의 입력값을 받아 순차적으로 출력값을 산출합니다. Many to one 방식은 여러 시간에 대한 데이터를 받아 하나의 출력값을 산출합니다. Many to many 방식은 여러 개의 시계열 데이터를 받아 여러 개의 출력값을 산출합니다.
1.4 기본 순환 신경망
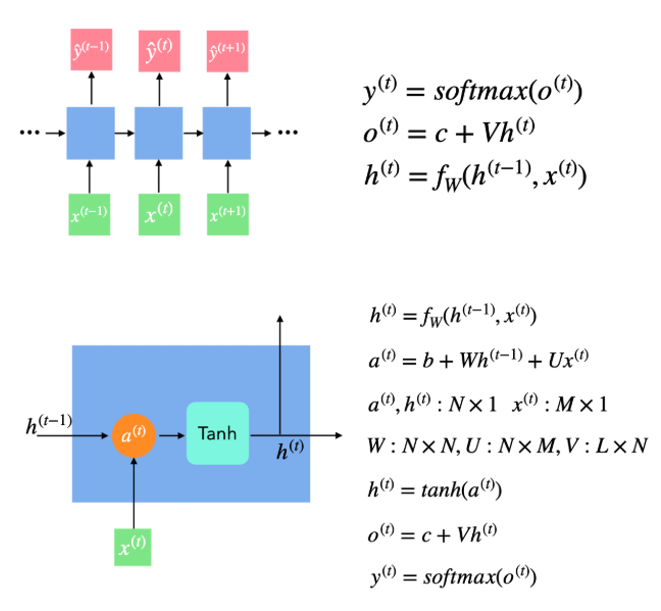
이전 데이터로부터 얻은 정보를 다음 계산에 어떻게 반영할 것인지에 따라 종류가 나눠지는데, 기본적인 순환 신경망은 아래 그림에 있는 수식으로 연산이 진행됩니다. 입력값이 하나 들어오면 이전 정보와 입력값을 연산하여 $h$ 라는 은닉 상태를 구합니다. 이 때 얻은 $h$ 값은 선형식을 거쳐 $o$ 를 만든 후 활성화 함수를 통해 $y$ 를 산출합니다. 다음 입력값이 들어오면 이전에 계산했던 $h$ 값을 이용하여 동일한 계산을 거치게 됩니다.
1.5 기본 순환 신경망 구현
라이브러리 및 데이터 불러오기
주가 데이터를 이용해 실습합니다. 데이터는 일자, 시작가, 고가, 저가, 종가, 보정된 종가, 거래량으로 구성된 csv 파일입니다.
필요한 모듈들을 import 합니다.
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
pandas 를 이용해서 csv 파일을 데이터프레임 형태로 불러옵니다. 데이터는 보정된 종가를 제외한 나머지를 사용하며 일자를 제외하고 MinMax 스케일을 사용하여 데이터를 가공합니다
df = pd.read_csv("/content/drive/MyDrive/pytorch/data/kospi.csv")
scaler = MinMaxScaler()
df[["Open","High","Low","Close","Volume"]] = scaler.fit_transform(df[["Open","High","Low","Close","Volume"]])
데이터프레임에서 .head() 는 상위 5개 항목에 대한 테이블을 출력해 줍니다. 일자와 보정된 종가를 제외한 나머지가 스케일링된 것을 볼 수 있습니다.
df.head()
Output:
Date Open High Low Close Adj Close Volume
0 2019-01-30 0.722898 0.732351 0.745525 0.759235 2206.199951 0.242113
1 2019-01-31 0.763058 0.750069 0.769089 0.757866 2204.850098 0.274771
2 2019-02-01 0.751894 0.745714 0.769280 0.756456 2203.459961 0.241609
3 2019-02-07 0.755809 0.742538 0.764596 0.756415 2203.419922 0.215603
4 2019-02-08 0.731584 0.717777 0.739548 0.729669 2177.050049 0.197057
텐서 데이터 만들기
사용할 데이터는 인스턴스가 431개이고 피쳐가 4개(Open, High, Low, Volume)이고 타깃값은 종가(Close)입니다. 즉 431x4 시계열 데이터를 가지고 있습니다. 이 단계에서 고려해야 할 점은 며칠을 사용하여 다음 날 종가를 예측하느냐는 것과 학습 데이터와 평가 데이터의 비율입니다.
데이터프레임에서는 values 를 이용하여 넘파이 배열로 만들 수가 있습니다. 이를 이용해 입력 데이터와 타깃 데이터를 생성합니다.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
X = df[["Open","High","Low","Volume"]].values
Y = df[["Close"]].values
시퀀스 데이터를 만드는 함수를 생성합니다. 이 함수는 미리 정한 시퀀스 길이로 쪼개어 데이터를 저장합니다. 이 때 데이터는 for 문의 1회당 한 칸씩 움직여 저장합니다. 예를 들어 길이가 5면 처음 저장된 데이터는 0, 1, 2, 3, 4번째 데이터가 한 묶음이고, 다음은 1, 2, 3, 4, 5 그 다음은 2, 3, 4, 5, 6번째의 데이터가 한 묶음이 됩니다. y 데이터는 다음 날 값이 타깃값이기 때문에 입력값이 x[i:i+sequence_length]면 타깃값은 y[i+sequence_length]가 됩니다. 예를 들어 X 가 0, 1, 2, 3, 4번째 데이터가 묶일 때 6번 째 데이터의 y 값이 대응되는 타깃값이 됩니다. 마지막으로 GPU 용 텐서로 변환합니다. 여기서 y 데이터를 view(-1, 1)를 사용하여 2차원으로 바꿔주는데 바꿔주는 이유는 MSE Loss 가 기본적으로 2차원 타깃 데이터를 받기 때문입니다.
# 주가 데이터를 시퀀스 데이터로 만들기 위한 함수
def seq_data(x, y, sequence_length):
x_seq = []
y_seq = []
# 입력 데이터의 개수에서 정해둔 sequence_length 만큼 루프를 반복
for i in range(len(x) - sequence_length):
# sequence_length 가 5라면
# i = 0 -> [0, 1, 2, 3, 4]
# i = 1 -> [1, 2, 3, 4, 5]
x_seq.append(x[i:i+sequence_length])
# 주식 데이터이므로 이전 시퀀스의 다음 데이터가 정답 데이터가 되므로
# i+sequence_length index 에 있는 값을 사용함
y_seq.append(y[i+sequence_length])
return torch.FloatTensor(x_seq).to(device), torch.FloatTensor(y_seq).to(device).view(-1, 1)
시퀀스 길이를 5로 한다면 총 426개(431(전체데이터)-5(시퀀스 길이))의 시퀀스 데이터를 만들 수 있습니다. 200개 데이터는 학습 데이터로 사용하고 이후 데이터는 평가 데이터로 사용합니다.
split = 200
sequence_length = 5
x_seq, y_seq = seq_data(X, Y, sequence_length)
# 전체 데이터 중 200개의 데이터만 학습 데이터로 사용하고 나머지 데이터는 평가 데이터로 사용함
x_train_seq = x_seq[:split]
y_train_seq = y_seq[:split]
x_test_seq = x_seq[split:]
y_test_seq = y_seq[split:]
print(x_train_seq.size(), y_train_seq.size())
print(x_test_seq.size(), y_test_seq.size())
Ouput :
torch.Size([200, 5, 4]) torch.Size([200, 1])
torch.Size([226, 5, 4]) torch.Size([226, 1])
Dataset 과 DataLoader 를 이용해 배치 데이터를 만듭니다.
train = torch.utils.data.TensorDataset(x_train_seq, y_train_seq)
test = torch.utils.data.TensorDataset(x_test_seq, y_test_seq)
batch_size = 20
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test, batch_size=batch_size)
RNN 구축에 필요한 하이퍼 파라미터 정의하기
input_size 는 입력 변수의 개수, num_layers 는 은닉층의 개수, hidden_size 는 은닉 상태를 저장하는 벡터의 크기입니다.
RNN의 연산은 파이토치에서 제공하기 때문에 전체를 직접 구현하지 않아도 됩니다.
input_size = x_seq.size(2) # 4
num_layers = 2
hidden_size = 8
RNN 구축하기
nn.RNN 을 이용하면 한 줄로 모델이 정의됩니다. 이 때 주의할 점은 원래 nn.RNN 의 입력 데이터 크기는 시퀀스의 길이x배치사이즈x변수의크기 이기 때문에 (200, 5, 4) 크기의 데이터를 (5, 200, 4) 로 변경해야 합니다. 하지만 batch_first=True 를 적용하면 기존의 200x5x4 데이터를 그대로 사용할 수 있습니다.
self.fc 는 RNN 에서 나온 출력값을 FC 층 하나를 거쳐 하나의 예측값을 뽑을 수 있도록 하기 위해 사용합니다.
RNN 은 이전 h 를 받아 계산하기 때문에 첫 번째 계산 시 이전 h 가 없기 때문에 초깃값을 영텐서로 정의하여 h0 를 대입합니다.
정의된 self.rnn 을 사용합니다. 이 때 파이토치에서 제공하는 모델은 many to many 방법을 가지고 각 시간에 대한 예측값과 은닉 상태를 산출합니다. 이 예시에서는 은닉 상태를 사용하지 않기 때문에 out, _ 으로 예측값만을 받습니다.
out = out.reshape(out.shape[0], -1) 은 모든 출력값을 사용하기 위해 out 을 일렬로 만들어 self.fc 에 넣습니다.
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
"""
Args
input_size : 입력 특징의 차원 수
hidden_size : RNN 히든 레이어의 차원 수
sequence_length : 입력 시퀀스의 길이
num_layers : 쌓을 RNN 레이어의 수
device : CPU 혹은 GPU
"""
super(VanillaRNN, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
# RNN Layer
# batch_first=True : 입력/출력 텐서의 첫 번째 차원을 배치 크기로 설정
# (batch_size, sequence_length, input_size) -> (batch_size, 5, 4)
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
# 분류기 (Fully Connected Layer)
# 이 모델은 RNN 의 모든 시퀀스(5개)의 출력을 펼쳐서 분류에 사용함
# 입력 차원 : hidden_size * sequence_length = 40
# 출력 차원 : 1
# Sigmoid : 출력을 0과 1사이의 값(확률)으로 변환
self.fc = nn.Sequential(nn.Linear(hidden_size*sequence_length, 1), nn.Sigmoid())
def forward(self, x):
# 1. 초기 은닉 상태 (h0) 설정
# nn.RNN 은 (num_layers, batch_size, hidden_size) 크기의 초기 은닉 상태가 필요함
# 0으로 채운 텐서를 생성하고, 지정된 device 로 보냄
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
# 2. RNN 순전파
# 입력 :
# x: (B, 5, 4)
# h0: (2, B, 8)
# 출력 :
# out: 모든 시점(t=1~5)의 마지막 레이어(2번 째) 은닉 상태
# shape: (B, sequence_length, hidden_size) -> (B, 5, 8)
out, _ = self.rnn(x, h0)
# 3. 텐서 펼치기 (Flatten)
# FC 레이어에 넣기 위해 3D 텐서(out)를 2D 텐서로 변환
# (B, 5, 8) -> (B, 5*8) = (B, 40)
out = out.reshape(out.shape[0], -1)
# 4. 분류기 통과
# (B, 40) -> Linear(40, 1) -> (B, 1) -> Sigmoid -> (B, 1)
out = self.fc(out)
return out
RNN 모델 불러오기
입력값의 크기, 은닉 상태 크기, 시퀀스 길이, 은닉층 개수, gpu 연산을 위한 device 변수까지 모델에 넣어줍니다. 또한 GPU 연산을 위해 model 뒤에 .to(device)를 붙여줍니다.
model = VanillaRNN(input_size=input_size,
hidden_size=hidden_size,
sequence_length=sequence_length,
num_layers=num_layers,
device=device).to(device)
손실 함수 및 최적화 방법 정의
주가를 예측하는 것이므로 회귀문제입니다. 따라서 대표적인 MSE 손실 함수를 사용합니다. 학습은 301 회 진행하고, 최적화 방법은 Adam 을 사용합니다.
criterion = nn.MSELoss()
num_epochs = 301
optimizer = optim.Adam(model.parameters(), lr=1e-3)
모델 학습하기
loss_graph = []
n = len(train_loader)
for epoch in range(num_epochs):
running_loss = 0.0
for data in train_loader:
seq, target = data
out = model(seq)
loss = criterion(out, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
loss_graph.append(running_loss/n)
if epoch %100 == 0:
print("[epoch: %d] loss: %.4f" %(epoch, running_loss/n))
Output :
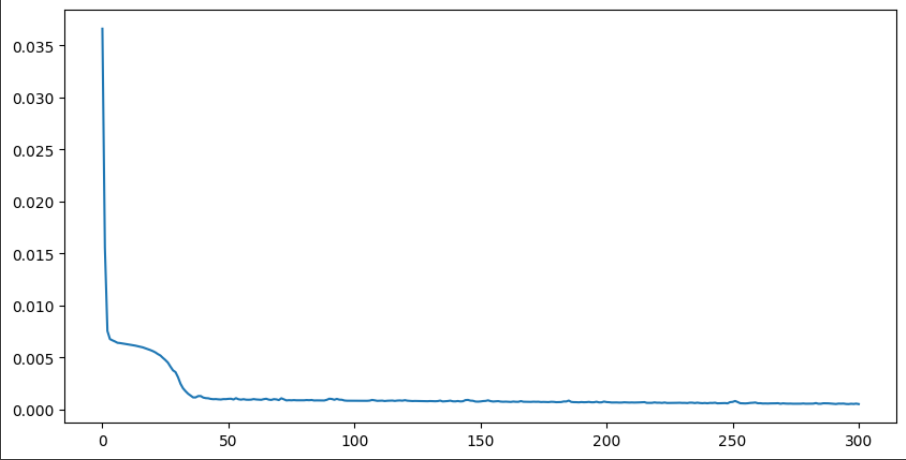
[epoch: 0] loss: 0.0366
[epoch: 100] loss: 0.0009
[epoch: 200] loss: 0.0007
[epoch: 300] loss: 0.0005
학습 손실 함수값 그리기
손실 함수를 통해 단편적으로 훈련이 잘 됐음을 확인할 수 있습니다.
plt.figure(figsize=(10, 5))
plt.plot(loss_graph)
plt.show()
주가 그리기
학습한 모델과 전체 데이터를 이용해 예측한 주가를 그래프로 그려보고, 테스트 데이터에 있는 정답 데이터와 비교해봅니다.
ConcatDataset 은 여러 개의 데이터 세트를 함께 사용할 수 있도록 도와줍니다. 입력값은 데이터 세트의 리스트를 받기 때문에 앞서 정의한 train, test 를 리스트 [train, test]로 넣어줍니다.
예측값을 저장할 빈 텐서 pred를 만듭니다. 예측값은 GPU 텐서입니다. 따라서 CPU 텐서로 변환 후 .tolist() 를 이용해 리스트로 만들어 순차적으로 리스트를 이어 붙입니다.
concatdata = torch.utils.data.ConcatDataset([train, test])
data_loader = torch.utils.data.DataLoader(dataset=concatdata, batch_size=100)
with torch.no_grad():
pred = []
model.eval()
for data in data_loader:
seq, target = data
out = model(seq)
pred += out.cpu().tolist()
plt.figure(figsize=(20, 10))
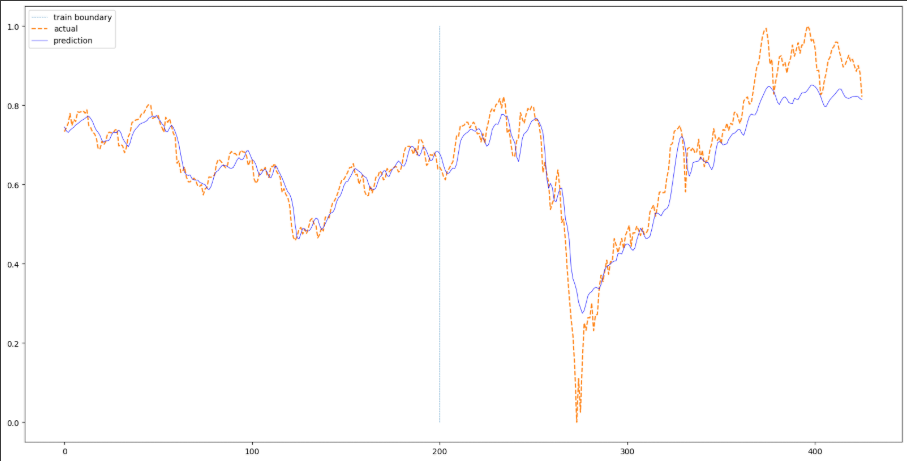
plt.plot(np.ones(100) * len(train), np.linspace(0,1,100), "--", linewidth=0.6)
plt.plot(df["Close"][sequence_length:].values, "--")
plt.plot(pred, 'b', linewidth=0.6)
plt.legend(["train boundary", "actual", "prediction"])
plt.show()
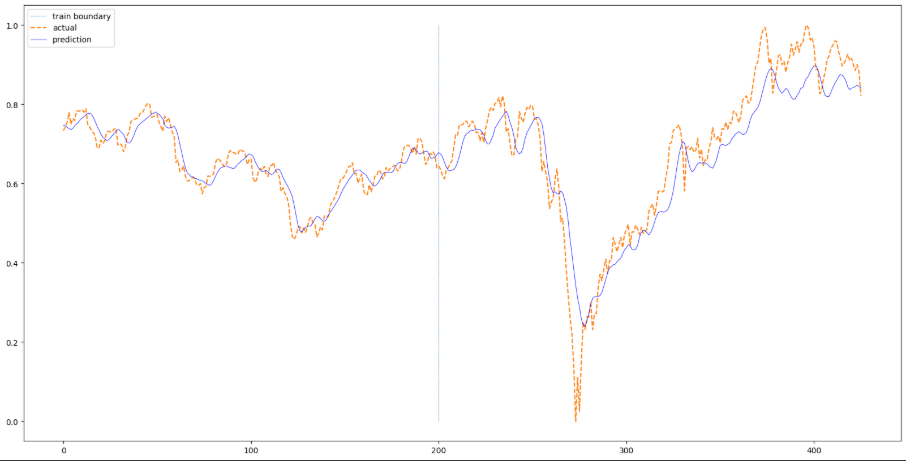
파란색 수직선을 기준으로 왼쪽을 훈련 데이터로 사용하고 오른쪽을 평가 데이터로 사용하였습니다. 따라서 훈련 데이터 부분은 학습이 잘 되어 실제값과 예측값이 잘 맞는다고 보여집니다. 평가 부분은 급락하는 부분을 잡아내지는 못합니다. 전체적으로 예측을 잘 하는 것처럼 보이지만 오른쪽으로 쉬프트된 현상을 볼 수 있습니다.
2. LSTM 과 GRU
RNN 은 시퀀스의 길이가 길거나 관련 정보들 간의 거리가 멀면 학습 능력이 크게 하락할 수 있습니다. 해당 단점을 보완하고자 LSTM 이 개발되었고, 획기적인 모델로 인정받으며 많은 모델에 응용되었습니다. 또한 LSTM 을 간소화한 GRU 가 개발되었습니다.
2.1 기본 RNN 의 문제
기울기 사라짐
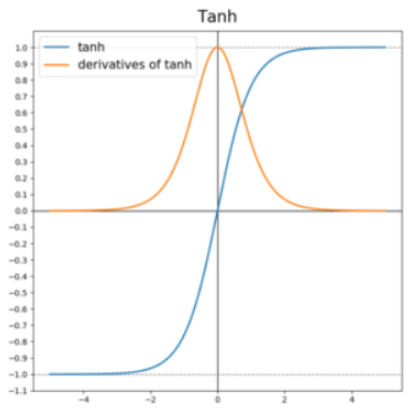
RNN 은 연속적으로 활성화 함수 Tanh 를 계산하는 형태입니다. 따라서 역전파를 진행할 때 Tanh 미분을 수행하는데, 중앙에서 밖으로 나갈 수록 값이 0에 가까워집니다. 따라서 미분을 이용하여 모델 변수를 업데이트하기 때문에 미분값이 0에 가까운 값들이 나오게 되면 적절한 변수를 찾기 어렵습니다.
장기 의존성
기본 RNN 의 경우 시퀀스가 너무 길다면 앞쪽의 타임 스텝의 정보가 후반 타임 스텝까지 충분히 전달되지 못하는 문제가 있습니다.
2.2 LSTM(Long Short-Term Memory)
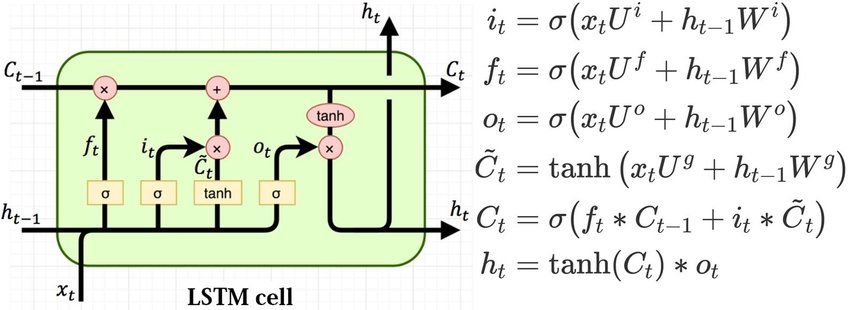
LSTM 은 기본 RNN 의 단점을 보완하고자 셀 상태 s 와 모든 값이 0과 1 사이인 입력 게이트 i, 망각 게이트 f, 출력 게이트 $o$ 를 추가하여 이전 정보와 현재 정보의 비중을 조율하여 예측에 반영되고 그 값이 다음 타임 스텝으로 전달됩니다. 파이토치에서 제공하는 nn.LSTM 을 사용하여 내부 계산을 별도로 할 필요는 없습니다. 즉 LSTM 의 모델 파라미터인 $W$ 와 $U$ 들이 자동으로 관리됩니다.
모델 구축하기
모델 구축 외 다른 부분은 RNN 코드와 동일합니다.
은닉 상태와 셀 상태의 초깃값은 0으로 하여 모델에 넣어줍니다.
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
"""
Args : 이전 vanillaRNN 과 동일
"""
super(LSTM, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size*sequence_length, 1)
def forward(self, x):
# 1. 초기 은닉 상태(h0) 및 셀 상태(c0) 설정
# LSTM 은 RNN 과 달리 (h, c) 두 개의 상태를 가짐
# h0 (Hidden_state) : (num_layers, B, hidden_size) -> (2, batch_size, 8)
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
# c0 (Cell state) : (num_layers, B, hidden_size) -> (2, B, 8)
c0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
out, _ = self.lstm(x, (h0, c0))
out = out.reshape(out.shape[0], -1)
out = self.fc(out)
return out
LSTM 을 이용하여 주가 그래프를 그려보면 아래와 같습니다. 학습 시 RNN 보다 loss 값이 빠르게 수렴하는 것을 제외하곤 RNN 과 큰 차이는 없습니다.
2.3 GRU(Gated Recurrent Units)
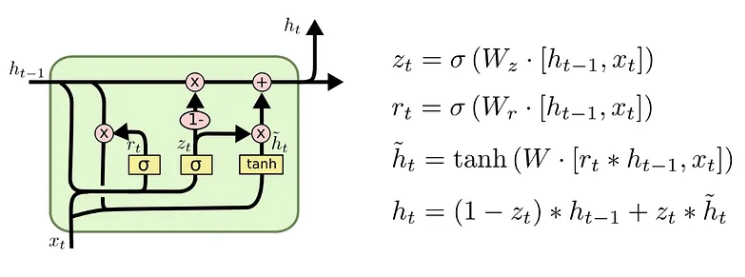
LSTM 은 기본 RNN 에서 추가로 셀 상태와 3개의 게이트를 사용하기 때문에 속도가 느립니다. 이를 해결하기 위해 셀 상태를 없애고 2개의 게이트만 사용하여 LSTM 을 간소화한 모델이 GRU 입니다. 아래 그림과 같이 업데이트 게이트 $z$ 와 리셋 게이트 $r$ 을 통해 현재 은닉 상태를 연산할 때 이전 은닉 상태를 얼마나 반영할 것인지를 조율합니다.
모델 구축하기
모델 구축외 다른 부분은 RNN, LSTM 과 동일합니다.
RNN, LSTM 과 마찬가지로 은닉 상태의 초기값은 0으로 합니다.
class GRU(nn.Module):
"""
vanillaRNN 과 동일
"""
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
super(GRU, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size*sequence_length, 1)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(self.device)
out, _ = self.gru(x, h0)
out = out.reshape(out.shape[0], -1)
out = self.fc(out)
return out
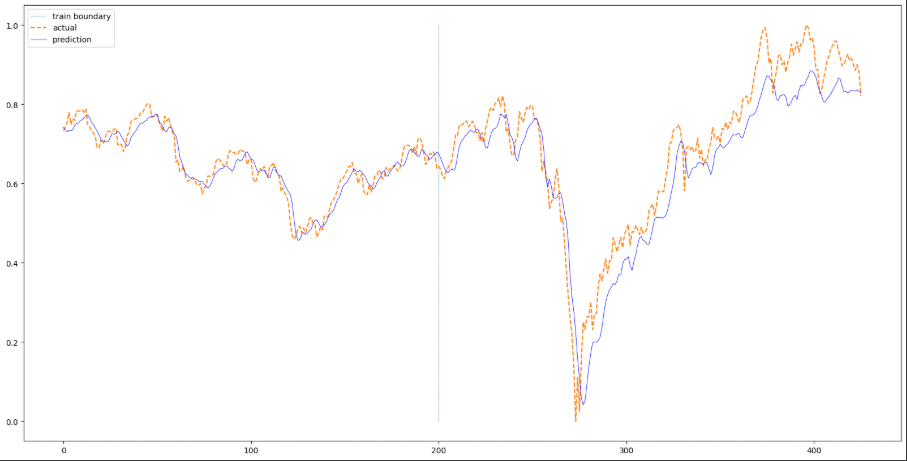
RNN, LSTM 과 달리 GRU 는 평가 데이터에서 갑자기 하향하는 부분을 캐치하여 갑자기 하향하는 부분에서 실제 평가 데이터와 동일한 모습을 보여주어 이번에 사용한 주가 데이터에서는 GRU 가 가장 성능이 좋은 듯 합니다.
3. Bi-LSTM
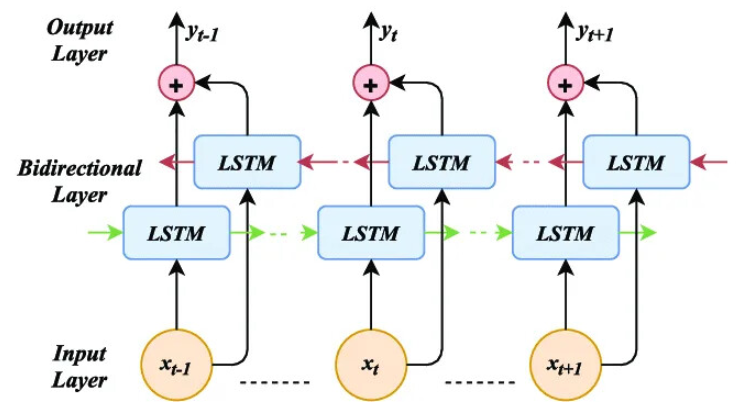
우리가 지금까지 다룬 순환 신경망은 이전 상태의 정보를 현재 상태로 넘겨주어 연산을 하는 방식입니다. 즉, 데이터 처리의 방향이 한 쪽으로 흐르는 정방향 연산임을 알 수 있습니다. 따라서 다음 상태를 현재 연산에 활용하기 위해 양방향 연산에 대한 구조를 만들 수 있습니다. 바로 양방향 LSTM(Bidirectional LSTM)은 순방향과 역방향의 연산을 담당하는 은닉층을 각각 두어 서로 다른 방향에 대해 계산을 수행하는 LSTM 입니다.
3.1 Bi-LSTM 구현하기
라이브러리 불러오기
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
MNIST 데이터 불러오기
이번 예제에서는 숫자 이미지 판별을 Bi-LSTM 을 이용해 예측 해보고자 합니다. 우리가 다루는 이미지는 주로(배치사이즈, 채널 수, 이미지 너비, 이미지 높이) 형태의 크기를 지니고 있습니다. MNIST 데이터의 채널 수는 1이고 이미지 크기가 28X28이므로 각 배치 데이터의 크기는 (배치사이즈, 1, 28, 28)입니다. 이 때 크기를 (배치사이즈, 28, 28)으로 생각할 수 있습니다. 또한 이미지 픽셀의 각 열을 하나의 벡터로 보고 행을 타임 스텝으로 본다면 (배치사이즈, 시계열의 길이, 벡터의 크기)를 가진 시계열 데이터로도 생각할 수 있습니다. 즉 순환 신경망도 이미지 처리에 활용될 수 있다는 것입니다.
tensor_mode = torchvision.transforms.ToTensor()
trainset = torchvision.datasets.MNIST(root="./data", train=True, transform=tensor_mode, download=True)
testset = torchvision.datasets.MNIST(root="./data", train=False, transform=tensor_mode, download=True)
trainloader = DataLoader(trainset, batch_size=128, shuffle=True)
testloader = DataLoader(testset, batch_size=128, shuffle=False)
Bi-LSTM 모델 구축하기
클래스를 초기화할 때 입력값의 크기(이미지의 열 크기), 은닉층의 노드 수, 은닉층의 개수, 시계열의 길이(이미지의 행 크기), 클래스 수, gpu 활용 여부에 대한 값을 받습니다.
self.lstm 에서 bidirectional=True 으로 활성화하여 양방향 LSTM 을 생성하고 batch_first = True 로 지정하여 크기가 (배치 사이즈, 시계열의 길이, 입력값의 크기)를 지닌 데이터를 활용할 수 있도록 합니다.
모든 타임 스텝에 대한 LSTM 결과를 분류에 사용합니다. 따라서 self.fc 의 입력값의 크기는 시계열의 길이*은닉층의 크기*2 입니다. 양방향 LSTM 은 정방향, 역방향에 대한 LSTM 을 계산한 후 합친 결과(concatenate)를 사용합니다. 따라서 각각의 은닉층 결과 2개가 합쳐지므로 2를 곱하는 것입니다.
모델에서 나온 out 의 크기는 배치사이즈, 시계열의 길이, 은닉층의 노드 수*2가 됩니다. 모든 데이터를 nn.Linear 에 사용하기 위해 reshape 를 하여 크기를 (배치 사이즈, 시계열의 길이*은닉층의 노드 수*2)로 변경합니다. 마지막으로 self.fc 를 거친 후 크기가 10(클래스 수)인 출력 벡터를 산출합니다.
class BiLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, seq_length, num_classes, device):
super(BiLSTM, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
self.seq_length = seq_length
# bidirectional=True : bi-LSTM 을 사용함
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, bidirectional=True)
self.fc = nn.Linear(seq_length*hidden_size*2, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(self.device)
c0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(self.device)
out, _ = self.lstm(x, (h0, c0))
out = out.reshape(-1, self.seq_length*self.hidden_size*2)
out = self.fc(out)
return out
하이퍼 파라미터 정의하기
모델에 필요한 변수를 정의합니다. 위에서 언급했듯이 이미지 데이터의 행을 시계열로 열을 입력 벡터로 활용합니다. 시계열의 길이는 trainset.data.size(1)이고 입력 벡터의 크기는 trainset.data.size(2)입니다. Bi-LSTM 의 은닉층 정보는 적절한 값을 넣어주고 클래스 수는 10으로 정의합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
sequence_length = trainset.data.size(1) # 28
input_size = trainset.data.size(2) # 28
num_layers = 2
hidden_size = 12
num_classes = 10
모델, 손실 함수, 최적화 기법 정의하기
model = BiLSTM(input_size, hidden_size, num_layers, sequence_length, num_classes, device)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=5e-3)
모델 학습하기
학습 방법은 지금까지 했던 모델과 동일하게 진행합니다.
for epoch in range(51):
correct = 0
total = 0
for data in trainloader:
optimizer.zero_grad()
# 입력 데이터에 squeeze 를 해주는 이유는 이미지 데이터기 때문에 중간에 채널 벡터를 없애주기 위해
# squeeze 를 진행함
inputs, labels = data[0].to(device).squeeze(1), data[1].to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, predicted = torch.max(outputs.detach(), 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("[%d] train acc: %.2f"%(epoch, 100*correct/total))
Output:
[0] train acc: 91.99
[1] train acc: 97.50
[2] train acc: 98.14
... 중략 ...
[50] train acc: 99.74
모델 평가하기
Bi-LSTM 을 이용해서 98% 의 평가 정확도를 달성했습니다. 이와 같이 순환 신경망을 이미지 처리에 사용할 수도 있습니다.
def accuracy(dataloader):
correct = 0
total = 0
with torch.no_grad():
model.eval()
for data in dataloader:
inputs, labels = data[0].to(device).squeeze(1), data[1].to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs,1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = 100 * correct/total
model.train()
return acc
train_acc = accuracy(trainloader)
test_acc = accuracy(testloader)
print("Train Acc: %.1f, Test Acc: %1.f" %(train_acc, test_acc))
Output:
Train Acc: 99.6, Test Acc: 98
마치며
순환 신경망에 대해서 알아보았습니다. 이번엔 주가 데이터나, 간단한 이미지 데이터를 사용했습니다만 다음엔 자연어처리에 순환 신경망을 적용한 예제도 다뤄보도록 하겠습니다. 긴 글 읽어주셔서 감사드리며, 잘못된 내용, 오타, 궁금하신 사항이 있으신 경우 댓글 달아주시기 바랍니다.
Comments