
[LLM/RAG] LangChain - 11. LangChain 을 이용한 RAG
머리말
이번 포스트는 그간 배웠던 LangChain을 이용한 RAG의 기초에 대해서 돌아보는 시간을 가져보고자 작성하게 되었습니다. 그간 우리는 LangChain을 이용해 가장 기초적인 RAG 시스템을 구성하는 여러 요소들을 알아보았고, 구현에 대해서도 알아보았습니다. 그래서 여태까지 알아본 내용들의 통합을 한 번 진행해 보았습니다. 이번 포스트에서 구현해보는 RAG 시스템들은 입력 문서별로 구현해 보았습니다.
1. RAG 기본 구조 이해하기
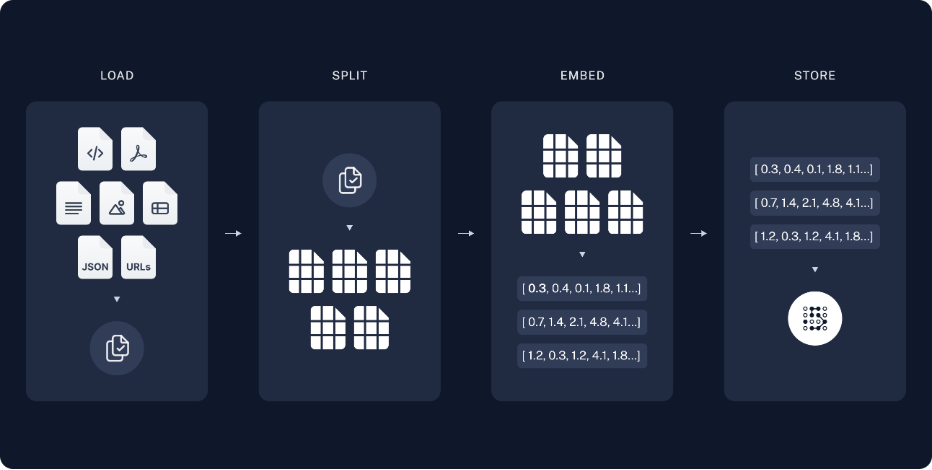
1. 사전작업(Pre-processing) - 1~4 단계
- 1단계 문서로드(Document Load): 문서 내용을 불러옵니다.
- 2단계 분할(Text Split): 문서를 특정 기준(Chunk)으로 분할합니다.
- 3단계 임베딩(Embedding): 분할된(Chunk) 문서를 임베딩화 합니다.
- 4단계 벡터DB 저장: 임베딩된 Chunk를 DB에 저장합니다.

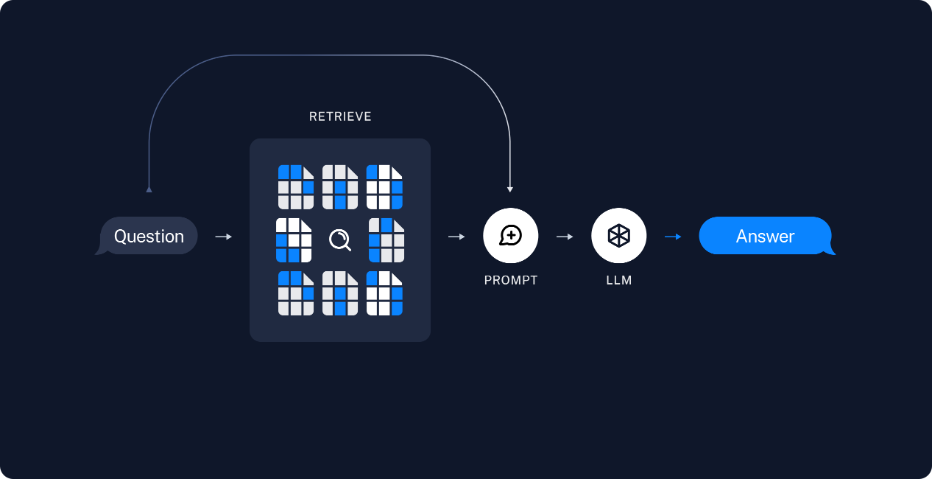
2. RAG 수행(RunTime) - 5~8단계
- 5단계 검색기(Retriver): 쿼리(Query)를 바탕으로 DB에서 검색하여 결과를 가져오기 위하여 검색기를 정의합니다. 검색기는 검색 알고리즘이며(Dense, Spase) 검색기로 나뉘게 됩니다.
- 6단계 프롬프트: RAG를 수행하기 위한 프롬프트를 생성합니다. 프롬프트의 context에는 문서에서 검색된 내용이 입력됩니다. 프롬프트 엔지니어링을 통하여 답변의 형식을 지정할 수 있습니다.
- 7단계 LLM 모델 정의: 답변에 사용할 LLM 모델을 정의합니다.
- 8단계 Chain: 프롬프트 - LLM - 출력에 이르는 체인을 생성합니다.

2. 문서별 실습
2.1 PDF 문서 기반 QA(Question-Answer)
2.1.1 실습에 활용한 문서
실습에 활용한 문서는 소프트웨어정책연구소(SPRi) 2023년 12월호 PDF 파일을 사용했습니다.
- 저자: 유재홍(AI정책연구실 책임연구원), 이지수(AI정책연구실 위촉연구원)
- 링크: https://spri.kr/posts/view/23669
- 파일명:
SPRI_AI_Brief_2023년12월호_F.pdf
실습을 위해 파일을 다운로드 받아주시기 바랍니다.
2.1.2 환경 설정
저는 코랩을 활용했으며, 예제 실행을 위해 다음 라이브러리들 설치를 진행했습니다.
!pip install langchain-text-splitters langchain langchain-core langchain-openai langchain-community pymupdf sentence-transformers faiss-cpu
2.1.3 실습
우선 문서 로드를 먼저 진행해 줍니다. PyMuPDFLoader를 활용해 문서 로드를 진행해 주고, 문서의 페이지 수를 출력해 봅니다.
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import PromptTemplate
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# 1 단계: 문서 로드(Load Documents)
loader = PyMuPDFLoader("/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf")
docs = loader.load()
print(f"문서의 페이지수: {len(docs)}")
Output:
문서의 페이지수: 23
로드한 문서의 분할을 진행합니다. 분할에는 일반적으로 많이 사용되는 RecursiveCharacterTextSplitter를 사용합니다. 그리고 분할된 청크의 수를 출력해 봅니다.
# 2 단계: 문서 분할(Split Documents)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
split_documents = text_splitter.split_documents(docs)
print(f"분할된 청크의 수: {len(split_documents)}")
Output:
분할된 청크의 수: 43
임베딩 모델을 정의하고, 벡터 스토어를 생성하고 검색기를 정의합니다. 그리고 검색기를 이용해 질문과 관련성있는 문서를 출력해 봅니다.
# 3 단계: 임베딩(Embedding) 생성
embeddings = HuggingFaceEmbeddings(
model_name="Laseung/klue-roberta-base-klue-sts-mrc-mnr-finetuned",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# 4 단계: 벡터 DB 생성 및 저장
# 벡터 스토어를 생성합니다.
vectorstore = FAISS.from_documents(documents=split_documents, embedding=embeddings)
# 5 단계: 검색기(Retriever) 생성
# 문서에 포함되어 있는 정보를 생성합니다.
retriever = vectorstore.as_retriever()
# 검색기에 쿼리를 날려 검색된 chunk 결과를 확인합니다.
retriever.invoke("삼성전자가 자체 개발한 AI 이름은?")
Output:
[Document(id='dfcd1d70-ffb3-4233-b2dd-35b939075ba9', metadata={'producer': 'Hancom PDF 1.3.0.542', 'creator': 'Hwp 2018 10.0.0.13462', 'creationdate': '2023-12-08T13:28:38+09:00', 'source': '/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf', 'file_path': '/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf', 'total_pages': 23, 'format': 'PDF 1.4', 'title': '', 'author': 'dj', 'subject': '', 'keywords': '', 'moddate': '2023-12-08T13:28:38+09:00', 'trapped': '', 'modDate': "D:20231208132838+09'00'", 'creationDate': "D:20231208132838+09'00'", 'page': 12}, page_content='2024년부터 가우스를 탑재한 삼성 스마트폰이 메타의 라마(Llama)2를 탑재한 퀄컴 기기 및 구글 \n어시스턴트를 적용한 구글 픽셀(Pixel)과 경쟁할 것으로 예상\n☞ 출처 : 삼성전자, ‘삼성 AI 포럼’서 자체 개발 생성형 AI ‘삼성 가우스’ 공개, 2023.11.08.\n삼성전자, ‘삼성 개발자 콘퍼런스 코리아 2023’ 개최, 2023.11.14.\nTechRepublic, Samsung Gauss: Samsung Research Reveals Generative AI, 2023.11.08.'),
Document(id='24be2c92-6400-42ed-86c4-425764e9b577', metadata={'producer': 'Hancom PDF 1.3.0.542', 'creator': 'Hwp 2018 10.0.0.13462', 'creationdate': '2023-12-08T13:28:38+09:00', 'source': '/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf', 'file_path': '/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf', 'total_pages': 23, 'format': 'PDF 1.4', 'title': '', 'author': 'dj', 'subject': '', 'keywords': '', 'moddate': '2023-12-08T13:28:38+09:00', 'trapped': '', 'modDate': "D:20231208132838+09'00'", 'creationDate': "D:20231208132838+09'00'", 'page': 12}, page_content='SPRi AI Brief | \n2023-12월호\n10\n삼성전자, 자체 개발 생성 AI ‘삼성 가우스’ 공개\nn 삼성전자가 온디바이스에서 작동 가능하며 언어, 코드, 이미지의 3개 모델로 구성된 자체 개발 생성 \nAI 모델 ‘삼성 가우스’를 공개\nn 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획으로, 온디바이스 작동이 가능한 \n삼성 가우스는 외부로 사용자 정보가 유출될 위험이 없다는 장점을 보유\nKEY Contents\n£ 언어, 코드, 이미지의 3개 모델로 구성된 삼성 가우스, 온디바이스 작동 지원\nn 삼성전자가 2023년 11월 8일 열린 ‘삼성 AI 포럼 2023’ 행사에서 자체 개발한 생성 AI 모델 \n‘삼성 가우스’를 최초 공개\n∙정규분포 이론을 정립한 천재 수학자 가우스(Gauss)의 이름을 본뜬 삼성 가우스는 다양한 상황에 \n최적화된 크기의 모델 선택이 가능\n∙삼성 가우스는 라이선스나 개인정보를 침해하지 않는 안전한 데이터를 통해 학습되었으며, \n온디바이스에서 작동하도록 설계되어 외부로 사용자의 정보가 유출되지 않는 장점을 보유\n∙삼성전자는 삼성 가우스를 활용한 온디바이스 AI 기술도 소개했으며, 생성 AI 모델을 다양한 제품에 \n단계적으로 탑재할 계획\nn 삼성 가우스는 △텍스트를 생성하는 언어모델 △코드를 생성하는 코드 모델 △이미지를 생성하는 \n이미지 모델의 3개 모델로 구성\n∙언어 모델은 클라우드와 온디바이스 대상 다양한 모델로 구성되며, 메일 작성, 문서 요약, 번역 업무의 \n처리를 지원\n∙코드 모델 기반의 AI 코딩 어시스턴트 ‘코드아이(code.i)’는 대화형 인터페이스로 서비스를 제공하며 \n사내 소프트웨어 개발에 최적화\n∙이미지 모델은 창의적인 이미지를 생성하고 기존 이미지를 원하는 대로 바꿀 수 있도록 지원하며 \n저해상도 이미지의 고해상도 전환도 지원\nn IT 전문지 테크리퍼블릭(TechRepublic)은 온디바이스 AI가 주요 기술 트렌드로 부상했다며,'),
... 생략 ...
우선 RAG가 제대로 적용되는지 확인을 하기 위해 llm에 질문만 먼저 던져보고 결과를 확인해 봅니다.
# RAG 적용하지 않고 llm에게 질문해 보기
reponse = llm.invoke("삼성전자가 자체 개발한 AI의 이름은?")
print(reponse.content)
출력 결과를 보면 RAG를 적용하지 않았을 때에는 삼성전자에서 개발한 AI 이름을 “네온”으로 알려주고 있습니다.
삼성전자가 자체 개발한 AI의 이름은 "네온(NEON)"입니다. 네온은 가상의 인간을 생성하고, 다양한 감정과 반응을 표현할 수 있는 AI 기술입니다.
그럼 이제 RAG를 적용하기 위한 남은 단계들을 적용해 주도록 하겠습니다.
# 6 단게: 프롬프트 생성(Create Prompt)
# 프롬프트를 생성합니다.
prompt = PromptTemplate.from_template(
"""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Answer in Korean.
#Question:
{question}
#Context:
{context}
#Answer:"""
)
# 7 단계: 언어모델 생성
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# 8 단계: 체인(Chain) 생성
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 체인 실행
# 문서에 대한 질의를 입력하고, 답변을 출력합니다.
question = "삼성전자가 자체 개발한 AI의 이름은?"
response = chain.invoke(question)
print(response)
2023년 SPRi의 12월호에서는 삼성전자에서 개발 중인 AI의 이름은 가우스였으며, 가우스는 현재 개발이 중단된 상태라고 합니다. RAG를 적용해 주어진 문서에 맞게 답변을 해주는 것을 확인할 수 있습니다.
삼성전자가 자체 개발한 AI의 이름은 '삼성 가우스'입니다.
2.2 네이버 뉴스기사 QA(Question-Answer)
이번엔 네이버 뉴스기사를 이용한 RAG 시스템을 만들어 보도록 하겠습니다. 우선 실행에 필요한 라이브러리 설치부터 진행해 줍시다.
!pip install langchain langchain-core langchain-community langchain-openai langchain-text-splitters faiss-cpu sentence-transformers langchain-teddynote
실행에 필요한 라이브러리들을 임포트부터 해줍니다.
import bs4
from langchain_classic import hub
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
from langchain_community.embeddings import HuggingFaceEmbeddings
웹페이지의 내용을 로드하고, 텍스트를 청크로 나누어 인덱싱하는 과정을 거친 후, 관련된 텍스트 스니펫을 검색하여 새로운 내용을 생성하는 과정을 구현합니다.
bs4.SoupStrainer(
"div",
attrs={"class": ["newsct_article _article_body", "media_end_head_title"]},
)
# 뉴스기사 내용을 로드하고, 청크로 나누고, 인덱싱합니다.
loader = WebBaseLoader(
web_paths=("https://n.news.naver.com/article/437/0000378416",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
"div",
attrs={"class": ["newsct_article _article_body", "media_end_head_title"]},
)
),
)
docs = loader.load()
print(f"문서의 수: {len(docs)}")
docs
Output:
문서의 수: 1
[Document(metadata={'source': 'https://n.news.naver.com/article/437/0000378416'}, page_content="\n출산 직원에게 '1억원' 쏜다…회사의 파격적 저출생 정책\n\n\n[앵커]올해 아이 낳을 계획이 있는 가족이라면 솔깃할 소식입니다. 정부가 저출생 대책으로 매달 주는 부모 급여, 0세 아이는 100만원으로 올렸습니다. 여기에 첫만남이용권, 아동수당까지 더하면 아이 돌까지 1년 동안 1520만원을 받습니다. 지자체도 경쟁하듯 지원에 나섰습니다. 인천시는 새로 태어난 아기, 18살될 때까지 1억원을 주겠다. 광주시도 17살될 때까지 7400만원 주겠다고 했습니다. 선거 때면 나타나서 아이 낳으면 현금 주겠다고 밝힌 사람이 있었죠. 과거에는 표만 노린 '황당 공약'이라는 비판이 따라다녔습니다. 그런데 지금은 출산율이 이보다 더 나쁠 수 없다보니, 이런 현금성 지원을 진지하게 정책화 하는 상황까지 온 겁니다. 게다가 기업들도 뛰어들고 있습니다. 이번에는 출산한 직원에게 단번에 1억원을 주겠다는 회사까지 나타났습니다.이상화 기자가 취재했습니다.[기자]한 그룹사가 오늘 파격적인 저출생 정책을 내놨습니다.2021년 이후 태어난 직원 자녀에 1억원씩, 총 70억원을 지원하고 앞으로도 이 정책을 이어가기로 했습니다.해당 기간에 연년생과 쌍둥이 자녀가 있으면 총 2억원을 받게 됩니다.[오현석/부영그룹 직원 : 아이 키우는 데 금전적으로 많이 힘든 세상이잖아요. 교육이나 생활하는 데 큰 도움이 될 거라 생각합니다.]만약 셋째까지 낳는 경우엔 국민주택을 제공하겠다는 뜻도 밝혔습니다.[이중근/부영그룹 회장 : 3년 이내에 세 아이를 갖는 분이 나올 것이고 따라서 주택을 제공할 수 있는 계기가 될 것으로 생각하고.][조용현/부영그룹 직원 : 와이프가 셋째도 갖고 싶어 했는데 경제적 부담 때문에 부정적이었거든요. (이제) 긍정적으로 생각할 수 있을 것 같습니다.]오늘 행사에서는, 회사가 제공하는 출산장려금은 받는 직원들의 세금 부담을 고려해 정부가 면세해달라는 제안도 나왔습니다.이같은 출산장려책은 점점 확산하는 분위기입니다.법정기간보다 육아휴직을 길게 주거나, 남성 직원의 육아휴직을 의무화한 곳도 있습니다.사내 어린이집을 밤 10시까지 운영하고 셋째를 낳으면 무조건 승진시켜 주기도 합니다.한 회사는 지난해 네쌍둥이를 낳은 직원에 의료비를 지원해 관심을 모았습니다.정부 대신 회사가 나서는 출산장려책이 사회적 분위기를 바꿀 거라는 기대가 커지는 가운데, 여력이 부족한 중소지원이 필요하다는 목소리도 나옵니다.[영상디자인 곽세미]\n\t\t\n")]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
splits = text_splitter.split_documents(docs)
len(splits)
Output:
3
벡터 DB에 사용할 임베딩 모델을 정의합니다. 저는 OpenAI의 사용 비용을 줄이기 위해 제가 직접 학습시킨 BERT 모델의 임베딩을 사용하였습니다.
# 임베딩 모델을 생성합니다.
embeddings = HuggingFaceEmbeddings(
model_name="Laseung/klue-roberta-base-klue-sts-mrc-mnr-finetuned",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
FAISS혹은 Chroma와 같은 vectorstore를 이용한 벡터 표현을 생성합니다.
# 벡터스토어를 생성합니다.
vectorstore = FAISS.from_documents(documents=splits, embedding=embeddings)
# 뉴스에 포함되어 있는 정보를 검색하고 생성합니다.
retriever = vectorstore.as_retriever()
llm 모델, prompt, OutputParser를 정의해 체인을 생성해 줍니다.
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다. 당신의 임무는 주어진 문맥(context) 에서 주어진 질문(question) 에 답하는 것입니다.
검색된 다음 문맥(context) 을 사용하여 질문(question) 에 답하세요. 만약, 주어진 문맥(context) 에서 답을 찾을 수 없다면, 답을 모른다면 `주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다` 라고 답하세요.
한글로 답변해 주세요. 단, 기술적인 용어나 이름은 번역하지 않고 그대로 사용해 주세요.
#Question:
{question}
#Context:
{context}
#Answer:"""
)
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# 체인을 생성합니다.
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
RAG를 적용한 출력과의 비교를 위해 RAG를 적용하지 않고 오로지 질문만을 gpt-4o-mini에게 던졌을 때 어떤 답변을 주는지 확인해 봅니다.
# RAG를 적용하지 않고 llm에게 질문해 보기
response = llm.invoke("부영그룹의 출산 장려 정책에 대해 설명해 주세요.")
print(response.content)
print("="*50)
response = llm.invoke("부영그룹은 출산 직원에게 얼마의 지원을 제공하나요?")
print(response.content)
print("="*50)
response = llm.invoke("정부의 저출생 대책을 bullet points 형식으로 작성해 주세요.")
print(response.content)
print("="*50)
response = llm.invoke("부영그룹의 임직원 숫자는 몇명인가요?")
print(response.content)
print("="*50)
Output:
부영그룹은 출산 장려 정책을 통해 직원들의 출산과 육아를 지원하고 있습니다. 이 정책은 주로 다음과 같은 내용으로 구성되어 있습니다:
1. **출산 장려금**: 부영그룹은 직원이 자녀를 출산할 경우 일정 금액의 출산 장려금을 지급합니다. 이는 경제적 부담을 덜어주고 출산을 장려하기 위한 목적입니다.
2. **육아휴직**: 직원들이 육아에 전념할 수 있도록 육아휴직 제도를 운영하고 있으며, 이 기간 동안의 급여 지원도 제공됩니다.
3. **유연 근무제**: 육아와 일을 병행할 수 있도록 유연 근무제를 도입하여, 직원들이 자녀 양육과 직장 생활을 조화롭게 할 수 있도록 지원합니다.
4. **보육 시설 지원**: 회사 내에 보육 시설을 운영하거나, 보육비 지원을 통해 직원들이 자녀를 안전하게 맡길 수 있는 환경을 제공합니다.
5. **가족 친화적인 문화 조성**: 출산과 육아를 장려하는 기업 문화를 조성하여, 직원들이 가족과 함께하는 시간을 소중히 여길 수 있도록 합니다.
부영그룹의 이러한 출산 장려 정책은 직원들의 삶의 질을 향상시키고, 출산율 증가에 기여하기 위한 노력의 일환으로 볼 수 있습니다.
==================================================
부영그룹은 출산 직원에게 다양한 지원을 제공하고 있습니다. 일반적으로 출산휴가, 육아휴직, 출산 축하금, 육아 지원금 등의 혜택이 포함됩니다. 구체적인 금액이나 지원 내용은 회사의 정책에 따라 다를 수 있으므로, 가장 정확한 정보는 부영그룹의 공식 웹사이트나 인사부서에 문의하는 것이 좋습니다.
==================================================
정부의 저출생 대책은 다음과 같은 주요 사항으로 구성됩니다:
- **재정 지원 확대**: 출산 및 양육에 대한 직접적인 재정 지원을 강화하여 가계 부담 경감.
- **육아휴직 제도 개선**: 육아휴직 기간 연장 및 급여 인상, 아빠 육아휴직 장려.
- **보육 서비스 확대**: 공공 보육시설 확충 및 보육료 지원 확대, 질 높은 보육 서비스 제공.
- **주거 지원 정책**: 신혼부부 및 다자녀 가구를 위한 주택 지원 및 저렴한 주택 공급.
- **일과 가정의 양립 지원**: 유연근무제 도입 및 재택근무 활성화, 가족 친화적인 기업 문화 조성.
- **교육비 부담 경감**: 교육비 지원 확대 및 무상 교육 확대, 학습 지원 프로그램 강화.
- **건강 관리 지원**: 임신 및 출산 관련 건강 관리 서비스 제공, 산모 및 아동 건강 프로그램 운영.
- **사회 인식 개선**: 저출생 문제에 대한 사회적 인식 제고 및 캠페인 실시, 출산 장려 문화 조성.
- **다양한 가족 형태 지원**: 비혼 부모, 동성 커플 등 다양한 가족 형태에 대한 지원 정책 마련.
- **정책 모니터링 및 평가**: 저출생 대책의 효과성을 지속적으로 모니터링하고, 필요시 정책 수정 및 보완.
이러한 대책들은 저출생 문제를 해결하고, 출산율을 높이기 위한 종합적인 접근을 목표로 하고 있습니다.
==================================================
부영그룹의 임직원 숫자는 정확한 시점에 따라 변동이 있을 수 있습니다. 2023년 기준으로 부영그룹의 임직원 수는 약 1만 명 이상으로 알려져 있습니다. 하지만 최신 정보는 부영그룹의 공식 웹사이트나 최근 보도자료를 통해 확인하는 것이 가장 정확합니다.
==================================================
그럼 이제 RAG가 적용된 출력을 확인해 보도록 하겠습니다.
answer = rag_chain.stream("부영그룹의 출산 장려 정책에 대해 설명해 주세요.")
stream_response(answer)
Output:
부영그룹은 출산 장려 정책으로 2021년 이후 태어난 직원 자녀에게 1억원씩 지원하기로 했습니다. 이 정책은 총 70억원 규모로, 연년생이나 쌍둥이 자녀가 있을 경우에는 총 2억원을 받을 수 있습니다. 또한, 셋째 자녀를 낳는 경우에는 국민주택을 제공하겠다는 계획도 밝혔습니다. 부영그룹 회장은 이 정책이 출산을 장려하고 주택 제공의 계기가 될 것이라고 언급했습니다. 이 외에도 출산장려금에 대한 세금 부담을 줄이기 위해 정부에 면세를 제안하기도 했습니다. 이러한 출산 장려책은 점점 확산되고 있으며, 육아휴직 기간을 늘리거나 남성 직원의 육아휴직을 의무화하는 등의 다양한 노력이 이루어지고 있습니다.
answer = rag_chain.stream("부영그룹은 출산 직원에게 얼마의 지원을 제공하나요?")
stream_response(answer)
Output:
부영그룹은 출산한 직원에게 1억원을 지원합니다. 2021년 이후 태어난 직원 자녀에 대해 총 70억원을 지원하며, 연년생이나 쌍둥이 자녀가 있을 경우 총 2억원을 받을 수 있습니다.
answer = rag_chain.stream("정부의 저출생 대책을 bullet points 형식으로 작성해 주세요.")
stream_response(answer)
Output:
- 부모 급여: 0세 아이에게 매달 100만원 지급
- 첫만남이용권 및 아동수당 포함 시, 아이 돌까지 1년 동안 총 1520만원 지원
- 지자체의 추가 지원: 인천시는 새로 태어난 아기에게 18살까지 1억원 지급, 광주시는 17살까지 7400만원 지급
- 기업의 출산 장려 정책: 일부 기업에서 출산한 직원에게 1억원 지급
- 연년생 및 쌍둥이 자녀에 대한 추가 지원: 총 2억원 지급
- 셋째 아이 출산 시 국민주택 제공
- 육아휴직 법정기간 연장 및 남성 직원의 육아휴직 의무화
- 사내 어린이집 운영 시간 연장 (밤 10시까지)
- 셋째 출산 시 승진 보장
- 의료비 지원 등 다양한 출산 장려책 확산
answer = rag_chain.stream("부영그룹의 임직원 숫자는 몇명인가요?")
stream_response(answer)
Output:
주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다.
마치며
이번 시간에 여태까지 하나씩 배웠던 전반적인 RAG 시스템을 통합하여 RAG 시스템이 전체적으로 어떻게 구성되는지 한 번 알아보았습니다. 이후로는 기본적인 RAG 시스템을 기반으로 Agent와 LangGraph 그리고 LCEL(LangChainExpression Language)에 대해서 알아보도록 하겠습니다.
긴 글 읽어주셔서 감사드리며 본문 내용 중 잘못된 내용이나 오타, 궁금하신 것이 있다면 댓글 달아주시기 바랍니다.
참조
- 테디노트 - LangChain 한국어 튜토리얼KR(https://wikidocs.net/book/14314)
Comments