
[LangChain] LangChain 14. LangGraph의 핵심 기능들에 대해서 알아보자
1. LangGraph 개요
LangGraph는 “상태 기반의 다중 에이전트 오케스트레이션”으로 LLM 애플리케이션에 상태 유지(Stateful) 및 순환 그래프(Cyclic Graph) 구조를 도입한 라이브러리입니다.
- Directed Acyclic Graph(DAG)의 한계를 넘어, 루프(Loop)를 허용합니다.
- State(상태) 객체를 통해 노드 간의 데이터를 공유하고 관리합니다.
- 에이전트의 행동을 세밀하게 제어(Control Flow)할 수 있어, 복잡한 커스텀 에이전트 설계에 최적화 되어 있습니다.
2. LangGraph에 자주 등장하는 Python 문법
2.1 TypedDict
TypedDict는 Python 표준 라이브러리(typing)에서 제공하는 기능으로, 딕셔너리의 키(Key)와 값(Value)의 타입을 명시적으로 지정하는 도구입니다.
LangGraph에서 TypedDict를 사용하는 이유는 LangGraph의 모든 노드(Node)는 State라고 불리는 이 TypedDict를 공유합니다.
- 데이터 일관성: 어떤 노드에서 어떤 데이터(질문, 답변, 검색 결과 등)가 오가는지 명확하게 정의합니다.
- 업데이트 규칙(Annotated): 특정 키의 값을 덮어쓸지, 혹은 기존 값에 추가(
operator.add)할지를 결정할 수 있습니다.
아래는 TypedDict 사용 예시입니다.
from typing import TypedDict
class Person(TypedDict):
name: str
age: int
job: str
typed_dict: Person = {"name": "셜리", "age": 25, "job": "디자이너"}
typed_dict["age"] = 35 # 정수형으로 올바르게 사용
typed_dict["age"] = "35" # 타입 체커가 오류를 감지함
typed_dict["new_field"] = (
"추가 정보" # 타입 체커가 정의되지 않은 키라고 오류를 발생시킴
)
2.2 Annotated
Annotated는 Python 3.9 버전부터 도입된 기능으로, 기존 타입에 부가적인 정보(Metadata)를 덧붙일 때 사용합니다.
단순히 “이 변수는 리스트야”라고 선언하는 것을 넘어, “이 리스트는 나중에 새로운 데이터가 들어오면 기존 데이터 뒤에 합쳐줘(Append)”와 같은 특별한 지시사항을 적어두는 용도라고 생각하면 쉽게 이해가 됩니다.
Annotated를 사용하는 이유는 추가 정보 제공(타입 힌트) / 문서화 때문입니다.
- 추가 정보 제공: 타입 힌트에 메타데이터를 추가하여 더 상세한 정보를 제공합니다.
- 문서화: 코드 자체에 추가 설명을 포함시켜 문서화 효과를 얻을 수 있습니다.
- 유효성 검사: 특정 라이브러리(예: Pydantic)와 함께 사용하여 데이터 유효성 검사를 수행할 수 있습니다.
- 프레임워크 지원: 일부 프레임워크(예: LangGraph)에서는
Annotated를 사용하여 특별한 동작을 정의합니다.
2.2.1 Annotated 사용 예시
from typing import Annotated, List
from pydantic import Field, BaseModel, ValidationError
class Employee(BaseModel):
id: Annotated[int, Field(..., description="직원 ID")]
name: Annotated[str, Field(..., min_length=3, max_length=50, description="이름")]
age: Annotated[int, Field(gt=18, lt=65, description="나이 (19-64세)")]
salary: Annotated[
float, Field(gt=0, lt=10000, description="연봉 (단위: 만원, 최대 10억)")
]
skills: Annotated[
List[str], Field(min_items=1, max_items=10, description="보유 기술 (1-10개)")
]
# 유효한 데이터로 인스턴스 생성
try:
valid_employee = Employee(
id=1, name="테디노트", age=30, salary=5000, skills=["Python", "LangChain"]
)
print("유효한 직원 데이터:", valid_employee)
except ValidationError as e:
print("유효성 검사 오류:", e)
# 유효하지 않은 데이터로 인스턴스 생성 시도
try:
invalid_employee = Employee(
name="테디", # 이름이 너무 짧음
age=17, # 나이가 범위를 벗어남
salary=20000, # 급여가 범위를 벗어남
skills="Python", # 리스트가 아님
)
except ValidationError as e:
print("유효성 검사 오류:")
for error in e.errors():
print(f"- {error['loc'][0]}: {error['msg']}")
Output:
유효한 직원 데이터: id=1 name='테디노트' age=30 salary=5000.0 skills=['Python', 'LangChain']
유효성 검사 오류:
- id: Field required
- name: String should have at least 3 characters
- age: Input should be greater than 18
- salary: Input should be less than 10000
- skills: Input should be a valid list
/tmp/ipython-input-1430983608.py:12: PydanticDeprecatedSince20: `min_items` is deprecated and will be removed, use `min_length` instead. Deprecated in Pydantic V2.0 to be removed in V3.0. See Pydantic V2 Migration Guide at https://errors.pydantic.dev/2.12/migration/
List[str], Field(min_items=1, max_items=10, description="보유 기술 (1-10개)")
/tmp/ipython-input-1430983608.py:12: PydanticDeprecatedSince20: `max_items` is deprecated and will be removed, use `max_length` instead. Deprecated in Pydantic V2.0 to be removed in V3.0. See Pydantic V2 Migration Guide at https://errors.pydantic.dev/2.12/migration/
List[str], Field(min_items=1, max_items=10, description="보유 기술 (1-10개)")
참고 사항으로
Annotated는 Python 3.9 이상에서 사용 가능합니다.- 런타임에는
Annotated가 무시되므로, 실제 동작에는 영향을 주지 않습니다. - 타입 검사 도구나 IDE가
Annotated를 지원해야 그 효과를 볼 수 있습니다.
2.3 add_messages
add_messages는 LangGraph에서 메시지를 리스트에 추가하는 함수입니다.
messages키는 add_messages 리듀서 함수로 주석이 달려 있으며, 이는 LangGraph에게 기존 목록에서 새 메시지를 추가하도록 지시합니다.
주석이 없는 상태 키는 각 업데이트에 의해 덮어쓰여져 가장 최근의 값이 저장됩니다.
add_messages 함수는 2개의 인자(left, right)를 받으며, 좌, 우 메시지를 병합하는 방식으로 동작합니다.
주요 기능
- 두 개의 메시지 리스트를 병합합니다.
- 기본적으로 “append-only” 상태를 유지합니다.
- 동일한 ID를 가진 메시지가 있을 경우, 새 메시지로 기존 메시지를 대체합니다.
동작 방식
right의 메시지 중left에 동일한 ID를 가진 메시지가 있으면,right의 메시지로 대체됩니다.- 그 외의 경우
right의 메시지가left에 추가됩니다.
매개 변수
left(Messages): 기본 메시지 리스트right(Messages): 병합할 메시지 리스트 또는 단일 메시지
반환 값
Messages:right의 메시지들이left에 병합된 새로운 메시지 리스트
from langchain_core.messages import AIMessage, HumanMessage
from langgraph.graph import add_messages
# 기본 사용 예시
msgs1 = [HumanMessage(content="안녕하세요?", id="1")]
msgs2 = [AIMessage(content="반갑습니다~", id="2")]
result1 = add_messages(msgs1, msgs2)
print(result1)
Output:
[HumanMessage(content='안녕하세요?', additional_kwargs={}, response_metadata={}, id='1'), AIMessage(content='반갑습니다~', additional_kwargs={}, response_metadata={}, id='2', tool_calls=[], invalid_tool_calls=[])]
동일한 ID를 가진 Message가 있을 경우 대체됩니다.
# 동일한 ID를 가진 메시지 대체 예시
msgs1 = [HumanMessage(content="안녕하세요?", id="1")]
msgs2 = [HumanMessage(content="반갑습니다~", id="1")]
result2 = add_messages(msgs1, msgs2)
print(result2)
Output:
[HumanMessage(content='반갑습니다~', additional_kwargs={}, response_metadata={}, id='1')]
3. LangGraph를 활용한 챗봇 구축
핵심 기능 익히기에는 실습 만한 것이 없다고 생각합니다. 그러므로 LangGraph를 이용한 간단한 챗봇을 구축해 보면서 LangGraph의 기본 적인 핵심 기능들에 대해서 알아가 보도록 하겠습니다.
실습 코드 실행에 앞서 코드 실행에 필요한 라이브러리 설치부터 진행해 줍니다.
!pip install langchain-openai langchain-teddynote
3.1 상태(State) 정의
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
# 메시지 정의(list, type이며 add_messages 함수를 사용하여 메시지를 추가)
messages: Annotated[list, add_messages]
3.2 노드(Node) 정의
chatbot 노드를 추가합니다. 노드는 작업의 단위를 나타내며, 일반적으로 정규 Python 함수입니다.
from langchain_openai import ChatOpenAI
# LLM 정의
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 챗봇 함수 정의
def chatbot(state: State):
# 메시지 호출 및 반환
return {"messages": [llm.invoke(state["messages"])]}
3.3 그래프(Graph) 정의, 노드 추가
-
chatbot노드 함수는 현재State를 입력으로 받아 “messages”라는 키 아래에 업데이트된messages목록을 포함하는 TypedDict를 반환합니다. -
State의add_messages함수는 이미 상태에 있는 메시지에 llm의 응답 메시지를 추가합니다.
# 그래프 생성
graph_builder = StateGraph(State)
# 노드 이름, 함수 혹은 callable 객체를 인자로 받아 노드를 추가
graph_builder.add_node("chatbot", chatbot)
3.4 그래프 엣지(Edge) 추가
# 시작 노드에서 챗봇 노드로의 엣지 추가
graph_builder.add_edge(START, "chatbot")
# 그래프에 엣지 추가
graph_builder.add_edge("chatbot", END)
3.5 그래프 컴파일
마지막으로, 그래프를 실행할 수 있어야 합니다. 이를 위해 그래프 빌더에서 compile()을 호출합니다. 이렇게 하면 상태에서 호출할 수 있는 CompiledGraph가 생성됩니다.
# 그래프 컴파일
graph = graph_builder.compile()
3.6 그래프 시각화
from langchain_teddynote.graphs import visualize_graph
# 그래프 시각화
visualize_graph(graph)
3.7 그래프 실행
이제 LangGraph로 정의한 챗봇을 실행해 보도록 하겠습니다.
question = "서울의 유명한 맛집 TOP 10 추천해줘"
# 그래프 이벤트 스트리밍
for event in graph.stream({"messages": [("user", question)]}):
# 이벤트 값 출력
for value in event.values():
print("Assistant:", value["messages"][-1].content)
Output:
Assistant: 서울에는 다양한 맛집이 많아서 선택하기가 쉽지 않지만, 다음은 서울에서 유명한 맛집 TOP 10을 추천해 드립니다. 각 식당은 고유의 매력을 가지고 있으니 참고해 보세요!
1. **광장시장** - 전통 시장으로, 빈대떡, 마약김밥, 떡볶이 등 다양한 길거리 음식을 즐길 수 있습니다.
2. **이태원 부대찌개** - 부대찌개로 유명한 이곳은 푸짐한 양과 깊은 맛으로 많은 사랑을 받고 있습니다.
3. **명동교자** - 칼국수와 만두가 유명한 곳으로, 항상 많은 사람들이 줄 서서 기다리는 인기 맛집입니다.
4. **삼청동 수제비** - 수제비와 전통 한식을 즐길 수 있는 아늑한 분위기의 식당입니다.
5. **한남동 고기리 막창** - 신선한 막창과 다양한 고기 요리를 제공하는 곳으로, 고기 애호가들에게 추천합니다.
6. **을지로 골뱅이** - 골뱅이 무침과 소주가 잘 어울리는 곳으로, 분위기도 좋고 맛도 뛰어납니다.
7. **홍대 돈부리** - 일본식 덮밥 전문점으로, 다양한 종류의 돈부리를 맛볼 수 있습니다.
8. **신사동 가로수길** - 다양한 카페와 레스토랑이 모여 있는 곳으로, 특히 브런치 카페가 많아 인기가 높습니다.
9. **종로 통인시장** - 전통 시장으로, 다양한 먹거리를 즐길 수 있으며, 특히 찐빵과 떡이 유명합니다.
10. **압구정 로데오거리** - 고급 레스토랑과 카페가 많은 지역으로, 다양한 세계 요리를 맛볼 수 있습니다.
각 식당은 예약이 필요할 수 있으니 방문 전에 확인해 보시는 것이 좋습니다. 맛있는 식사 되세요!
4. LangGraph를 활용한 Agent 구축
이번에는 웹 검색 도구를 통해 챗봇에 웹 검색 기능을 수행하는 Agent를 추가해 보도록 하겠습니다. LLM에 도구를 바인딩하여 LLM에 입력된 요청에 따라 필요시 웹 검색 도구(Tool)를 호출하는 Agent를 구축합니다. 뿐만 아니라, 조건부 엣지를 통해 도구 호출 여부에 따라 다른 노드로 라우팅하는 방법도 함께 배워보도록 하겠습니다.
4.1 도구 정의하기
웹 검색 도구로는 항상 사용하던 Tavily Search를 사용합니다. TavilySearchResults를 이용해 웹 검색 도구를 정의해 줍니다.
from langchain_teddynote.tools.tavily import TavilySearch
# 검색 도구 생성
tool = TavilySearch(max_results=3)
# 도구 목록에 추가
tools = [tool]
이번에는 LLM에 bind_tools로 “LLM+도구”를 구성합니다.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
# State 정의
class State(TypedDict):
# list 타입에 add_messages 적용
messages: Annotated[list, add_messages]
from langchain_openai import ChatOpenAI
# LLM 초기화
llm = ChatOpenAI(model="gpt-4o-mini")
# LLM에 도구 바인딩
llm_with_tools = llm.bind_tools(tools)
노드를 정의합니다.
# 노드 함수 정의
def chatbot(state: State):
answer = llm_with_tools.invoke(state["messages"])
# 메시지 목록 반환
return {"messages": [answer]}
그래프 생성 및 노드를 추가합니다.
from langgraph.graph import StateGraph
# 상태 그래프 초기화
graph_builder = StateGraph(State)
# 노드 추가
graph_builder.add_node("chatbot", chatbot)
4.2 도구 노드
이제 도구가 호출될 경우 실제로 실행할 수 있는 함수를 만들어야 합니다. 이를 위해 새로운 노드에 도구를 추가합니다. 가장 최근의 메시지를 확인하고 메시지에 tools_calls가 포함되어 있으면 도구를 호출하는 BasicToolNode 클래스를 구현합니다. 이번엔 직접 구현하지만, 나중에는 LangGraph의 pre-built 되어 있는 ToolNode로 대체할 수 있습니다.
import json
from langchain_core.messages import ToolMessage
class BasicToolNode:
"""Run tools requested in the last AIMessage node"""
def __init__(self, tools:list) -> None:
# 도구 리스트
self.tools_list = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
# 도구 호출 결과
outputs = []
for tool_call in message.tool_calls:
# 도구 호출 후 결과 저장
tool_result = self.tools_list[tool_call["name"]].invoke(tool_call["args"])
outputs.append(
# 도구 호출 결과를 메시지로 저장
ToolMessage(
content=json.dumps(
tool_result, ensure_ascii=False
), # 도구 호출 결과를 문자열로 반환
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
# 도구 노드 생성
tool_node = BasicToolNode(tools = [tool])
# 그래프에 도구 노드 추가
graph_builder.add_node("tools", tool_node)
4.3 조건부 엣지
도구 노드가 추가되면 conditional_edges를 정의할 수 있습니다. Edges는 한 노드에서 다음 노드로 제어 흐름을 라우팅합니다. Conditional edges는 일반적으로 “if”문을 포함하여 현재 그래프 상태에 따라 다른 노드로 라우팅합니다. 이러한 함수는 현재 그래프 state를 받아 다음에 호출할 Node를 나타내는 문자열 또는 문자열 목록을 반환합니다.
아래 예제에서는 route_tools라는 라우터 함수를 정의하여 챗봇의 출력에서 tool_calls를 확인합니다. 이 함수는 add_conditional_edges를 호출하여 그래프에 제공하면, chatbot 노드가 완료될 때마다 이 함수를 확인하여 다음에 어디로 갈지 결정합니다. 조건은 도구 호출이 있으면 tools로 없으면 END로 라우팅됩니다.
add_conditional_edges 메서드는 시작 노드에서 여러 대상 노드로의 조건부 엣지를 추가합니다.
매개변수는 다음과 같습니다.
source(str): 시작 노드 이 노드를 나갈 때 조건부 엣지가 실행됩니다.path(Union[Callable, Runnable]): 다음 노드를 결정하는 호출 가능한 객체 또는 Runnable.path_map을 지정하지 않으면 하나 이상의 노드를 반환해야 합니다.END를 반환하면 그래프 실행이 중지됩니다.path_map(Optional[Union[dict[Hashable, str], list[str]]]): 경로와 노드 이름 간의 매핑 생략하면path가 반환하는 값이 노드 이름이어야 합니다.then(Optional[str]):path로 선택된 노드 실행 후 실행할 노드의 이름
반환값
- Self: 메서드 체이닝을 위해 자기 자신을 반환합니다.
주요 기능
- 조건부 엣지를 그래프에 추가합니다.
path_map을 딕셔너리로 변환합니다.path함수의 반환 타입을 분석하여 자동으로path_map을 생성할 수 있습니다 .- 조건부 분기를 그래프에 저장합니다.
조건부 엣지는 단일 노드에서 시작해야 하며, 이는 그래프에 chatbot 노드가 실행될 때마다 도구를 호출하면 “tools”로 이동하고, 직접 응답하면 루프를 종료하라는 의미입니다.
사전 구축된 tools_condition처럼, 함수는 도구 호출이 없을 경우 END 문자열을 반환(그래프 종료)합니다. 그래프가 END로 전환되면 더 이상 완료할 작업이 없으며 실행을 중지합니다.
from langgraph.graph import START, END
def route_tools(
state: State,):
if messages := state.get("messages", []):
# 가장 최근 AI 메시지 추출
ai_message = messages[-1]
else:
# 입력 상태에 메시지가 없는 경우 예외 발생
raise ValueError(f"No messages found in input state to tool_edge: {state}")
# AI 메시지에 도구 호출이 있는 경우 "tools" 반환
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
# 도구 호출이 있는 경우 "tools" 반환
return "tools"
# 도구 호출이 없는 경우 "END" 반환
return END
# 'tools_condition' 함수는 챗봇이 도구 사용을 요청하면 "tools"를 반환하고, 직접 응답이 가능한 경우 "END"를 반환
graph_builder.add_conditional_edges(
source="chatbot",
path=route_tools,
# route_tools의 반환값이 "tools"인 경우 "tools" 노드로, 그렇지 않으면 END 노드로 라우팅
path_map={"tools": "tools", END: END},
)
# tools > chatbot
graph_builder.add_edge("tools", "chatbot")
# START > chatbot
graph_builder.add_edge(START, "chatbot")
# 그래프 컴파일
graph = graph_builder.compile()
만든 그래프를 시각화 하면 다음과 같습니다.
from langchain_teddynote.graphs import visualize_graph
# 그래프 시각화
visualize_graph(graph)
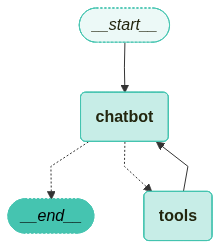
이제 챗봇에게 질문을 던지면 웹 검색을 수행한 결과를 토대로 답변을 해주게 됩니다.
from langchain_teddynote.messages import display_message_tree
question = "테디노트 YouTube"
for event in graph.stream({"messages": [("user", question)]}):
for key, value in event.items():
print(f"\n==============\nSTEP: {key}\n==============\n")
display_message_tree(value["messages"][-1])
Output:
==============
STEP: chatbot
==============
content: ""
additional_kwargs: {"refusal": None}
response_metadata:
token_usage:
completion_tokens: 22
prompt_tokens: 97
total_tokens: 119
completion_tokens_details: {"accepted_prediction_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 0, "rejected_prediction_tokens": 0}
prompt_tokens_details: {"audio_tokens": 0, "cached_tokens": 0}
model_provider: "openai"
model_name: "gpt-4o-mini-2024-07-18"
system_fingerprint: "fp_6c0d1490cb"
id: "chatcmpl-D7bcq3T4SADiDn7XPJJ3P8Lx3QL9g"
service_tier: "default"
finish_reason: "tool_calls"
logprobs: None
type: "ai"
name: None
id: "lc_run--019c4642-a7e4-79a0-b034-c6b9140cf93b-0"
tool_calls:
index [0]
name: "tavily_web_search"
args: {"query": "테디노트 YouTube"}
id: "call_3C93FykeMqVTnWAT1GdfXgOO"
type: "tool_call"
invalid_tool_calls:
usage_metadata:
input_tokens: 97
output_tokens: 22
total_tokens: 119
input_token_details: {"audio": 0, "cache_read": 0}
output_token_details: {"audio": 0, "reasoning": 0}
==============
STEP: tools
==============
content: "[{"url": "https://www.youtube.com/@teddynote/streams", "title": "테디노트 TeddyNote - YouTube", "content": "### [[#langchain x 테디노트] LangChain 본사 엔지니어와 신규 출시된 LangGraph V1 신규소개 & Live Q&A + 핸즈온 합니다!](https://www.youtube.com/watch? ### [[Upstage AI x 테디노트] Document Intelligence 파헤치기 🔥](https://www.youtube.com/watch? 저자 X 테디노트] 여섯 명의 개발자가 기록한 AI 시대의 생존 전략](https://www.youtube.com/watch? ### [[빅스터 이현종 대표 X 테디노트] 생성형 AI 다음은 #판단 AI(Decisive AI)](https://www.youtube.com/watch? ### [[조우철 X 테디노트] 프로덕션을 위한 #LLM #엔지니어링 🔥](https://www.youtube.com/watch? ### [[VESSL AI X 테디노트] #Agent 시대의 Infra, Ops 그리고 #MCP 🔥](https://www.youtube.com/watch? ### [[Sionic AI 박진형, 김혜원 X 테디노트] 엔터프라이즈 환경의 AI #Agent & #RAG 도입 끝장내기 🔥](https://www.youtube.com/watch? ### [[전현준 X 테디노트] \"MCP, A2A\" 진짜 엔터프라이즈 적용할 수 있을지 집중탐구 + #바이브코딩 🔥](https://www.youtube.com/watch? ### [[OneLineAI 손규진 X 테디노트] 비전공자에서 AI 연구원이 되기까지, Reasoning Model 이 열어줄 새로운 가능성 🔥](https://www.youtube.com/watch? ### [[모두의AI 케인 X 테디노트] 큰 그림으로 살펴보는 AI 산업 동향 (feat.팔란티어 온톨로지) 🔥](https://www.youtube.com/watch? ### [[KAIST, MARKR.AI 이승유 X 테디노트] Reasoning 모델 & Test Time Scaling 심층탐구🔥](https://www.youtube.com/watch? ### [[GraphRAG 정이태 X 테디노트] GraphRAG, 실무에 적용하기 위한 고려요소 심층탐구 🔥](https://www.youtube.com/watch? ### [[KAIST 장동인 교수 X 테디노트] AI 시대, 개발자의 미래](https://www.youtube.com/watch?", "score": 0.8585411, "raw_content": "테디노트 TeddyNote - YouTube\n===============\n\n Back [](https://www.youtube.com/ \"YouTube Home\")\n\nSkip navigation\n\n Search \n\n Search with your voice \n\n[](https://www.youtube.com/@teddynote/streams)\n\n[Sign in](https://accounts.google.com/ServiceLogin?service=youtube&uilel=3&passive=true&continue=https%3A%2F%2Fwww.youtube.com%2Fsignin%3Faction_handle_signin%3Dtrue%26app%3Ddesktop%26hl%3Den%26next%3Dhttps%253A%252F%252Fwww.youtube.com%252F%2540teddynote%252Fstreams&hl=en&ec=65620)\n\n[](https://www.youtube.com/ \"YouTube Home\")\n\n[Home Home](https://www.youtube.com/ \"Home\")[Shorts Shorts](https://www.youtube.com/shorts/ \"Shorts\")[Subscriptions Subscriptions](https://www.youtube.com/feed/subscriptions \"Subscriptions\")[You You](https://www.youtube.com/feed/you \"You\")\n\n\n\n\n\n테디노트 TeddyNote\n==============\n\n@teddynote\n\n•\n\n50.2K subscribers•285 videos\n\n데이터 분석, 머신러닝, 딥러닝, LLM 에 대한 내용을 다룹니다. 연구보다는 개발에 관심이 많습니다 🙇♂️ ...more 데이터 분석, 머신러닝, 딥러닝, LLM 에 대한 내용을 다룹니다. 연구보다는 개발에 관심이 많습니다 🙇♂️ ...more...more[fastcampus.co.kr/data_online_teddy](https://www.youtube.com/redirect?event=channel_header&redir_token=QUFFLUhqazBXUDk4Mk9jUHdvN2w3UVhscmpSWHNZeHJad3xBQ3Jtc0ttUTM4Qy15R3JXT2RrLVdfY2R3SjRUTm94N3Npd3JUQk9TS1lYM3hjVkkzUG10WkFRdzJqT2FNd19KanN1bEMtSGhBWnl2V0twZW1LUU1pTkFYQkE4eDV3NGNSemZ1WDkwb2tGMjFIZTIwcWl6RUhoSQ&q=https%3A%2F%2Ffastcampus.co.kr%2Fdata_online_teddy)[and 2 more links](javascript:void(0);)\n\nSubscribe\n\nJoin\n\nHome\n\nVideos\n\nShorts\n\nLive\n\nPlaylists\n\nPosts\n\nSearch \n\n Previous \n\nLatest\n\nPopular\n\nOldest\n\n Next \n\n[ 1:54:41 1:54:41 Now playing](https://www.youtube.com/watch?v=SKqCA-43nPM)[1:54:41 1:54:41 1:54:41 Now playing](https://www.youtube.com/watch?v=SKqCA-43nPM)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[전현준 x 테디노트] #Context Engineering 을 위한 #DeepAgents 와 #Agentic Coding(Claude Code)](https://www.youtube.com/watch?v=SKqCA-43nPM \"[전현준 x 테디노트] #Context Engineering 을 위한 #DeepAgents 와 #Agentic Coding(Claude Code)\")\n\n•\n\n•\n\n3.9K views Streamed 2 weeks ago\n\n[ 3:46:55 3:46:55 Now playing](https://www.youtube.com/watch?v=QAMDYNaDegM)[3:46:55 3:46:55 3:46:55 Now playing](https://www.youtube.com/watch?v=QAMDYNaDegM)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[#langchain x 테디노트] LangChain 본사 엔지니어와 신규 출시된 LangGraph V1 신규소개 & Live Q&A + 핸즈온 합니다!](https://www.youtube.com/watch?v=QAMDYNaDegM \"[#langchain x 테디노트] LangChain 본사 엔지니어와 신규 출시된 LangGraph V1 신규소개 & Live Q&A + 핸즈온 합니다!\")\n\n•\n\n•\n\n2.4K views Streamed 1 month ago\n\n[ 2:48:16 2:48:16 Now playing](https://www.youtube.com/watch?v=BSSzgEtIUp0)[2:48:16 2:48:16 2:48:16 Now playing](https://www.youtube.com/watch?v=BSSzgEtIUp0)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[Upstage AI x 테디노트] Document Intelligence 파헤치기 🔥](https://www.youtube.com/watch?v=BSSzgEtIUp0 \"[Upstage AI x 테디노트] Document Intelligence 파헤치기 🔥\")\n\n•\n\n•\n\n2.8K views Streamed 1 month ago\n\n[ 2:19:25 2:19:25 Now playing](https://www.youtube.com/watch?v=qq8HxJxy7gE)[2:19:25 2:19:25 2:19:25 Now playing](https://www.youtube.com/watch?v=qq8HxJxy7gE)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[DocentPro x 테디노트] 실리콘밸리 AI Travel 대표와 함께하는 커리어 & 개발 관련 무물(AMA)!](https://www.youtube.com/watch?v=qq8HxJxy7gE \"[DocentPro x 테디노트] 실리콘밸리 AI Travel 대표와 함께하는 커리어 & 개발 관련 무물(AMA)!\")\n\n•\n\n•\n\n1.2K views Streamed 2 months ago\n\n[ 2:17:15 2:17:15 Now playing](https://www.youtube.com/watch?v=wDUl7KjV7KI)[2:17:15 2:17:15 2:17:15 Now playing](https://www.youtube.com/watch?v=wDUl7KjV7KI)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[AI 개발자가 되고 싶으세요? 저자 X 테디노트] 여섯 명의 개발자가 기록한 AI 시대의 생존 전략](https://www.youtube.com/watch?v=wDUl7KjV7KI \"[AI 개발자가 되고 싶으세요? 저자 X 테디노트] 여섯 명의 개발자가 기록한 AI 시대의 생존 전략\")\n\n•\n\n•\n\n3.3K views Streamed 2 months ago\n\n[ 3:12:00 3:12:00 Now playing](https://www.youtube.com/watch?v=eQfhOfmbJJI)[3:12:00 3:12:00 3:12:00 Now playing](https://www.youtube.com/watch?v=eQfhOfmbJJI)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[빅스터 이현종 대표 X 테디노트] 생성형 AI 다음은 #판단 AI(Decisive AI)](https://www.youtube.com/watch?v=eQfhOfmbJJI \"[빅스터 이현종 대표 X 테디노트] 생성형 AI 다음은 #판단 AI(Decisive AI)\")\n\n•\n\n•\n\n2.5K views Streamed 3 months ago\n\n[ 2:03:06 2:03:06 Now playing](https://www.youtube.com/watch?v=VpIBx1CzEdQ&pp=0gcJCZEKAYcqIYzv)[2:03:06 2:03:06 2:03:06 Now playing](https://www.youtube.com/watch?v=VpIBx1CzEdQ&pp=0gcJCZEKAYcqIYzv)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[이승유 X 테디노트] 2025 ICLR, NeurIPS 페이퍼 리뷰 및 LLM Calibration](https://www.youtube.com/watch?v=VpIBx1CzEdQ&pp=0gcJCZEKAYcqIYzv \"[이승유 X 테디노트] 2025 ICLR, NeurIPS 페이퍼 리뷰 및 LLM Calibration\")\n\n•\n\n•\n\n1.6K views Streamed 3 months ago\n\n[ 2:32:41 2:32:41 Now playing](https://www.youtube.com/watch?v=793bvM1Mrtg)[2:32:41 2:32:41 2:32:41 Now playing](https://www.youtube.com/watch?v=793bvM1Mrtg)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[정이태 X 테디노트] 과연 #온톨로지 가 #GraphRAG 에 도움이 될까? 👀](https://www.youtube.com/watch?v=793bvM1Mrtg \"[정이태 X 테디노트] 과연 #온톨로지 가 #GraphRAG 에 도움이 될까? 👀\")\n\n•\n\n•\n\n5.6K views Streamed 5 months ago\n\n[ 2:19:35 2:19:35 Now playing](https://www.youtube.com/watch?v=g2QjywBXODk)[2:19:35 2:19:35 2:19:35 Now playing](https://www.youtube.com/watch?v=g2QjywBXODk)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[조우철 X 테디노트] 프로덕션을 위한 #LLM #엔지니어링 🔥](https://www.youtube.com/watch?v=g2QjywBXODk \"[조우철 X 테디노트] 프로덕션을 위한 #LLM #엔지니어링 🔥\")\n\n•\n\n•\n\n2.5K views Streamed 5 months ago\n\n[ 2:10:40 2:10:40 Now playing](https://www.youtube.com/watch?v=tqOkjsVzoSo)[2:10:40 2:10:40 2:10:40 Now playing](https://www.youtube.com/watch?v=tqOkjsVzoSo)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[강병진 X 테디노트] #AI 를 회사에서 언제 어떻게 활용하면 좋을까? 🔥](https://www.youtube.com/watch?v=tqOkjsVzoSo \"[강병진 X 테디노트] #AI 를 회사에서 언제 어떻게 활용하면 좋을까? 🔥\")\n\n•\n\n•\n\n5.2K views Streamed 5 months ago\n\n[ 2:04:20 2:04:20 Now playing](https://www.youtube.com/watch?v=-7jZoe__kBE)[2:04:20 2:04:20 2:04:20 Now playing](https://www.youtube.com/watch?v=-7jZoe__kBE)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[Sionic AI 박진형, 김혜원 X 테디노트] 엔터프라이즈 환경의 AI #Agent & #RAG 도입 끝장내기 🔥](https://www.youtube.com/watch?v=-7jZoe__kBE \"[Sionic AI 박진형, 김혜원 X 테디노트] 엔터프라이즈 환경의 AI #Agent & #RAG 도입 끝장내기 🔥\")\n\n•\n\n•\n\n4.3K views Streamed 6 months ago\n\n[ 2:52:15 2:52:15 Now playing](https://www.youtube.com/watch?v=WIqo3Fmxjqk)[2:52:15 2:52:15 2:52:15 Now playing](https://www.youtube.com/watch?v=WIqo3Fmxjqk)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[배휘동,임동준 X 테디노트] \"바이브 코딩을 하는 것과 잘 하는 것, 점점 더 잘 하는 것은 다릅니다\" #바이브코딩 🔥](https://www.youtube.com/watch?v=WIqo3Fmxjqk \"[배휘동,임동준 X 테디노트] \\\"바이브 코딩을 하는 것과 잘 하는 것, 점점 더 잘 하는 것은 다릅니다\\\" #바이브코딩 🔥\")\n\n•\n\n•\n\n6.8K views Streamed 6 months ago\n\n[ 2:53:01 2:53:01 Now playing](https://www.youtube.com/watch?v=z2rnK9COhuQ)[2:53:01 2:53:01 2:53:01 Now playing](https://www.youtube.com/watch?v=z2rnK9COhuQ)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[전현준 X 테디노트] \"MCP, A2A\" 진짜 엔터프라이즈 적용할 수 있을지 집중탐구 + #바이브코딩 🔥](https://www.youtube.com/watch?v=z2rnK9COhuQ \"[전현준 X 테디노트] \\\"MCP, A2A\\\" 진짜 엔터프라이즈 적용할 수 있을지 집중탐구 + #바이브코딩 🔥\")\n\n•\n\n•\n\n5.4K views Streamed 7 months ago\n\n[ 2:15:40 2:15:40 Now playing](https://www.youtube.com/watch?v=YShTiM-_ygU)[2:15:40 2:15:40 2:15:40 Now playing](https://www.youtube.com/watch?v=YShTiM-_ygU)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[Github Klaire 님 X 테디노트] 실리콘밸리 개발자 문화, 주니어 개발자를 위한 조언 🔥](https://www.youtube.com/watch?v=YShTiM-_ygU \"[Github Klaire 님 X 테디노트] 실리콘밸리 개발자 문화, 주니어 개발자를 위한 조언 🔥\")\n\n•\n\n•\n\n2.5K views Streamed 7 months ago\n\n[ 2:29:16 2:29:16 Now playing](https://www.youtube.com/watch?v=po0Li4cDlEc)[2:29:16 2:29:16 2:29:16 Now playing](https://www.youtube.com/watch?v=po0Li4cDlEc)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[OneLineAI 손규진 X 테디노트] 비전공자에서 AI 연구원이 되기까지, Reasoning Model 이 열어줄 새로운 가능성 🔥](https://www.youtube.com/watch?v=po0Li4cDlEc \"[OneLineAI 손규진 X 테디노트] 비전공자에서 AI 연구원이 되기까지, Reasoning Model 이 열어줄 새로운 가능성 🔥\")\n\n•\n\n•\n\n3.4K views Streamed 8 months ago\n\n[ 56:23 56:23 Now playing](https://www.youtube.com/watch?v=ZjjSqfv1Ypk)[56:23 56:23 56:23 Now playing](https://www.youtube.com/watch?v=ZjjSqfv1Ypk)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [LangChain Interrupt 샌프란시스코 마지막날 뒷풀이 토크 (w/ 랭체인 오픈튜토리얼 팀)](https://www.youtube.com/watch?v=ZjjSqfv1Ypk \"LangChain Interrupt 샌프란시스코 마지막날 뒷풀이 토크 (w/ 랭체인 오픈튜토리얼 팀)\")\n\n•\n\n•\n\n1.8K views Streamed 8 months ago\n\n[ 3:46:25 3:46:25 Now playing](https://www.youtube.com/watch?v=2eKd4UbSXy0)[3:46:25 3:46:25 3:46:25 Now playing](https://www.youtube.com/watch?v=2eKd4UbSXy0)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[모두의AI 케인 X 테디노트] 큰 그림으로 살펴보는 AI 산업 동향 (feat.팔란티어 온톨로지) 🔥](https://www.youtube.com/watch?v=2eKd4UbSXy0 \"[모두의AI 케인 X 테디노트] 큰 그림으로 살펴보는 AI 산업 동향 (feat.팔란티어 온톨로지) 🔥\")\n\n•\n\n•\n\n7K views Streamed 8 months ago\n\n[ 2:46:00 2:46:00 Now playing](https://www.youtube.com/watch?v=YcfM6maLiWo&pp=0gcJCZEKAYcqIYzv)[2:46:00 2:46:00 2:46:00 Now playing](https://www.youtube.com/watch?v=YcfM6maLiWo&pp=0gcJCZEKAYcqIYzv)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[VESSL AI X 테디노트] #Agent 시대의 Infra, Ops 그리고 #MCP 🔥](https://www.youtube.com/watch?v=YcfM6maLiWo&pp=0gcJCZEKAYcqIYzv \"[VESSL AI X 테디노트] #Agent 시대의 Infra, Ops 그리고 #MCP 🔥\")\n\n•\n\n•\n\n3.4K views Streamed 9 months ago\n\n[ 2:34:36 2:34:36 Now playing](https://www.youtube.com/watch?v=eKsrya-v-04)[2:34:36 2:34:36 2:34:36 Now playing](https://www.youtube.com/watch?v=eKsrya-v-04)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[벨루가 X 테디노트] 벨루가 멀티 RAG 아키텍처: LangGraph 활용 파이프라인🔥](https://www.youtube.com/watch?v=eKsrya-v-04 \"[벨루가 X 테디노트] 벨루가 멀티 RAG 아키텍처: LangGraph 활용 파이프라인🔥\")\n\n•\n\n•\n\n2.4K views Streamed 9 months ago\n\n[ 2:38:15 2:38:15 Now playing](https://www.youtube.com/watch?v=VsCU6jTffec)[2:38:15 2:38:15 2:38:15 Now playing](https://www.youtube.com/watch?v=VsCU6jTffec)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[KAIST, MARKR.AI 이승유 X 테디노트] Reasoning 모델 & Test Time Scaling 심층탐구🔥](https://www.youtube.com/watch?v=VsCU6jTffec \"[KAIST, MARKR.AI 이승유 X 테디노트] Reasoning 모델 & Test Time Scaling 심층탐구🔥\")\n\n•\n\n•\n\n2.9K views Streamed 9 months ago\n\n[ 3:00:16 3:00:16 Now playing](https://www.youtube.com/watch?v=zHN2jDZHvI0)[3:00:16 3:00:16 3:00:16 Now playing](https://www.youtube.com/watch?v=zHN2jDZHvI0)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[GraphRAG 정이태 X 테디노트] GraphRAG, 실무에 적용하기 위한 고려요소 심층탐구 🔥](https://www.youtube.com/watch?v=zHN2jDZHvI0 \"[GraphRAG 정이태 X 테디노트] GraphRAG, 실무에 적용하기 위한 고려요소 심층탐구 🔥\")\n\n•\n\n•\n\n7.6K views Streamed 10 months ago\n\n[ 2:43:55 2:43:55 Now playing](https://www.youtube.com/watch?v=0vFV3GRUbSM)[2:43:55 2:43:55 2:43:55 Now playing](https://www.youtube.com/watch?v=0vFV3GRUbSM)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[양파 X 테디노트] 생성형 AI 로 RAG 시스템 만드는 실무자에게 Ask Me Anything! \"진로 상담 환영\"](https://www.youtube.com/watch?v=0vFV3GRUbSM \"[양파 X 테디노트] 생성형 AI 로 RAG 시스템 만드는 실무자에게 Ask Me Anything! \\\"진로 상담 환영\\\"\")\n\n•\n\n•\n\n3.7K views Streamed 10 months ago\n\n[ 2:24:11 2:24:11 Now playing](https://www.youtube.com/watch?v=UaJ7_kloQUQ)[2:24:11 2:24:11 2:24:11 Now playing](https://www.youtube.com/watch?v=UaJ7_kloQUQ)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[문라이트 X 테디노트] 논문, 너도 읽을 수 있어! – 연구의 장벽을 낮추는 #Moonlight](https://www.youtube.com/watch?v=UaJ7_kloQUQ \"[문라이트 X 테디노트] 논문, 너도 읽을 수 있어! – 연구의 장벽을 낮추는 #Moonlight\")\n\n•\n\n•\n\n5.3K views Streamed 10 months ago\n\n[ 3:07:40 3:07:40 Now playing](https://www.youtube.com/watch?v=Z-ELkZ_azYM)[3:07:40 3:07:40 3:07:40 Now playing](https://www.youtube.com/watch?v=Z-ELkZ_azYM)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[노토랩 변형호 X 테디노트] LLM의 새로운 전환점, Reasoning 모델 이해하기 (Feat. DeepSeek R1)](https://www.youtube.com/watch?v=Z-ELkZ_azYM \"[노토랩 변형호 X 테디노트] LLM의 새로운 전환점, Reasoning 모델 이해하기 (Feat. DeepSeek R1)\")\n\n•\n\n•\n\n5.7K views Streamed 11 months ago\n\n[ 2:40:50 2:40:50 Now playing](https://www.youtube.com/watch?v=4cFEWqlALdo)[2:40:50 2:40:50 2:40:50 Now playing](https://www.youtube.com/watch?v=4cFEWqlALdo)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[KAIST 장동인 교수 X 테디노트] AI 시대, 개발자의 미래](https://www.youtube.com/watch?v=4cFEWqlALdo \"[KAIST 장동인 교수 X 테디노트] AI 시대, 개발자의 미래\")\n\n•\n\n•\n\n4.1K views Streamed 11 months ago\n\n[ 2:26:40 2:26:40 Now playing](https://www.youtube.com/watch?v=SVIxfMueeiE)[2:26:40 2:26:40 2:26:40 Now playing](https://www.youtube.com/watch?v=SVIxfMueeiE)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[엄마표AI코딩 이호정 X 테디노트] 지금은 어떤 AI를 써 볼까? 나의 생산성을 높여줄 모든 AI](https://www.youtube.com/watch?v=SVIxfMueeiE \"[엄마표AI코딩 이호정 X 테디노트] 지금은 어떤 AI를 써 볼까? 나의 생산성을 높여줄 모든 AI\")\n\n•\n\n•\n\n2.3K views Streamed 11 months ago\n\n[ 3:23:21 3:23:21 Now playing](https://www.youtube.com/watch?v=PKaSOnYLiHg)[3:23:21 3:23:21 3:23:21 Now playing](https://www.youtube.com/watch?v=PKaSOnYLiHg)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[전현준, 손규진 X 테디노트] 실무자가 말하는 #sLM & #LangGraph 활용](https://www.youtube.com/watch?v=PKaSOnYLiHg \"[전현준, 손규진 X 테디노트] 실무자가 말하는 #sLM & #LangGraph 활용\")\n\n•\n\n•\n\n5.2K views Streamed 1 year ago\n\n[ 2:12:16 2:12:16 Now playing](https://www.youtube.com/watch?v=7m5Xzfd95hw&pp=0gcJCZEKAYcqIYzv)[2:12:16 2:12:16 2:12:16 Now playing](https://www.youtube.com/watch?v=7m5Xzfd95hw&pp=0gcJCZEKAYcqIYzv)\n\n[](https://www.youtube.com/@teddynote/streams \"undefined\")\n\n### [[AIFactory 김태영 대표 X 테디노트] 어시웍스 - 생성형AI부터 에이전틱AI까지 비개발자도 뚝딱 🤖](https://www.youtube.com/watch?v=7m5Xzfd95hw&pp=0gcJCZEKAYcqIYzv \"[AIFactory 김태영 대표 X 테디노트] 어시웍스 - 생성형AI부터 에이전틱AI까지 비개발자도 뚝딱 🤖\")\n\n•\n\n•\n\n2.8K views Streamed 1 year ago\n\n\n\n[](https://www.youtube.com/@teddynote/streams)\n\n[](https://www.youtube.com/@teddynote/streams)\n\n[](https://www.youtube.com/@teddynote/streams)\n\n[](https://www.youtube.com/@teddynote/streams)\n\n[](https://www.youtube.com/@teddynote/streams)\n\n[](https://www.youtube.com/@teddynote/streams)\n\nTap to unmute\n\n2x\n\n[](https://www.youtube.com/@teddynote/streams)\n\n[](https://www.youtube.com/@teddynote/streams)\n\nSearch\n\nInfo\n\nShopping\n\n\n\n[](https://www.youtube.com/@teddynote/streams)\n\nIf playback doesn't begin shortly, try restarting your device.\n\n•\n\nYou're signed out\n\nVideos you watch may be added to the TV's watch history and influence TV recommendations. To avoid this, cancel and sign in to YouTube on your computer.\n\nCancel Confirm\n\n[](https://www.youtube.com/@teddynote/streams)\n\nShare\n\n[](https://www.youtube.com/@teddynote/streams \"Share link\")- [x] Include playlist \n\nAn error occurred while retrieving sharing information. Please try again later.\n\nWatch later\n\nShare\n\nCopy link\n\n\n\n0:00\n\n[](https://www.youtube.com/@teddynote/streams)[](https://www.youtube.com/@teddynote/streams \"Next (SHIFT+n)\")\n\n / \n\nLive\n\n•Watch full video\n\n•\n\n•\n\n[](https://www.youtube.com/@teddynote/streams)\n\n[](https://www.youtube.com/@teddynote/streams)\n\nNaN / NaN\n\n[[](https://www.youtube.com/@teddynote/streams)](https://www.youtube.com/@teddynote/streams)"}, {"url": "https://www.youtube.com/channel/UCt2wAAXgm87ACiQnDHQEW6Q", "title": "테디노트 TeddyNote - YouTube", "content": "TermsPrivacyPolicy & SafetyHow YouTube worksTest new featuresNFL Sunday Ticket. #RAG 의 동작 과정 쉽게 이해하기! Videos you watch may be added to the TV's watch history and influence TV recommendations. To avoid this, cancel and sign in to YouTube on your computer. Easily understand the operation process of #RAG! \\*This video is an edited version of the \"RAG Secret Notes\" lecture, available on [Fast Campus]. ⭐️ Fast Campus RAG Secret Notes [20% Discount Event] ⭐️. 🔆 Discount Code: Teddy Note RAG. ✅ Course Link: https://buly.kr/90aYONY. 📘 Langchain Tutorial Free Ebook (wikidocs). https://wikidocs.net/book/14314. ✅ Langchain Korean Tutorial Code Repository (GitHub). https://github.com/teddylee777/langch... 📍 \"Teddy Note's RAG Secret Notes\" Langchain Lecture: https://fastcampus.co.kr/data\\_online\\_... 📝 Teddy Note (GitHub Blog): https://teddylee777.github.io. ## Videos. ### Introducing Deep Agent Builder, an agent builder built with natural language. ### LangSmith Agent Builder, the first #no-code agent builder by #langchain. ### Exploring the Possibilities of #MCP X #A2A Enterprise-Oriented Security Design Architecture. ### 🔥How to make RAG into #MCP (claude desktop, cursor)🔥🔥\").", "score": 0.83452857, "raw_content": "Back\n\n[About](https://www.youtube.com/about/)[Press](https://www.youtube.com/about/press/)[Copyright](https://www.youtube.com/about/copyright/)[Contact us](/t/contact_us/)[Creators](https://www.youtube.com/creators/)[Advertise](https://www.youtube.com/ads/)[Developers](https://developers.google.com/youtube)\n\n[Terms](/t/terms)[Privacy](/t/privacy)[Policy & Safety](https://www.youtube.com/about/policies/)[How YouTube works](https://www.youtube.com/howyoutubeworks?utm_campaign=ytgen&utm_source=ythp&utm_medium=LeftNav&utm_content=txt&u=https%3A%2F%2Fwww.youtube.com%2Fhowyoutubeworks%3Futm_source%3Dythp%26utm_medium%3DLeftNav%26utm_campaign%3Dytgen)[Test new features](/new)[NFL Sunday Ticket](https://tv.youtube.com/learn/nflsundayticket)\n\n© 2026 Google LLC\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n[EP01. #RAG 의 동작 과정 쉽게 이해하기!](https://www.youtube.com/watch?v=zybyszetEcE)\n\n2x\n\n[Includes paid promotion](https://support.google.com/youtube?p=ppp&nohelpkit=1)\n\nIf playback doesn't begin shortly, try restarting your device.\n\n•\n\nYou're signed out\n\nVideos you watch may be added to the TV's watch history and influence TV recommendations. To avoid this, cancel and sign in to YouTube on your computer.\n\nCancelConfirm\n\n테디노트 TeddyNote\n\nSubscribe\n\nUnsubscribe\n\nShare\n\nAn error occurred while retrieving sharing information. Please try again later.\n\nWatch later\n\nShare\n\nCopy link\n\n0:00\n\n0:00 / 23:58\n\nLive\n\n•Watch full video\n\n•\n\n•\n\n[EP01. Easily understand the operation process of #RAG!](/watch?v=zybyszetEcE)\n\n\n•\n\n•\n\n81,590 views\n1 year ago\n\n\\*This video is an edited version of the \"RAG Secret Notes\" lecture, available on [Fast Campus].\nA more detailed lecture curriculum can be found at the link below.\n⭐️ Fast Campus RAG Secret Notes [20% Discount Event] ⭐️\n🔆 Discount Code: Teddy Note RAG\n✅ Course Link: [https://buly.kr/90aYONY](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqa3V6X0FiMHZ6VTE1ZEJQQzBIeFRudmtrQjkyZ3xBQ3Jtc0tuOFk3ZEFfTW50UU1VbVVxd1RhOUdSVlgtYkR6Y1hoWlZQMVZpYkVoTGZjS2xfRVEwaV9FV0pvNEtQYmt1SDRxMW41Zzd3bjFoOXBpcDZfSWswNlJKR19Hc0NvbXpndUN0Ym9HRWVnNUpGYXQ2OEVVZw&q=https%3A%2F%2Fbuly.kr%2F90aYONY)\n- Length: Approximately 70 hours\n- How to Use Coupon Code: Register for Course → Enter Coupon Code in Coupon Selection Window → Register Coupon\n🔥 Link Collection 🔥\n[https://linktr.ee/teddynote](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqbnJNYm1ib3ZMM2lsZUN6QUFHV2gzMlZQX2diQXxBQ3Jtc0tucWJxcHFTLVpJUy1NbGxBTmh5cnpfTVVmY2IwZHd1dEJyeENkamNNWTQ0cGRGbl9NRXZZbXlyTk52aG41V1BRZmdlV0hFWGRNTDlneVI5Y25TTFFCZUM5aDFuOWNSdm03dlZxTktrcWRwT0c4U25TUQ&q=https%3A%2F%2Flinktr.ee%2Fteddynote)\n📘 Langchain Tutorial Free Ebook (wikidocs)\n[https://wikidocs.net/book/14314](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqbHZ4bnNVSUJuRWF5Qi1EU21RdVgzWTloYnl3QXxBQ3Jtc0trZ2ZEMEVqX3ZLU3FucEUyNVRQUExMVVVHSEJDY21NSEZLMG9Xc0x5MzFqbzlrTEF2dzByN0dfSFoydnVWR3VkTG1oRmVnQ0FlajRXTm1VcjZlLU9sdkRSSG14Zm11azlwamY0bi1uRlpWYzVEQTJOTQ&q=https%3A%2F%2Fwikidocs.net%2Fbook%2F14314)\n✅ Langchain Korean Tutorial Code Repository (GitHub)\n[https://github.com/teddylee777/langch...](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqbnVvUFFMaVZvQmdsQkk4bm0wOW56N3g5czlpd3xBQ3Jtc0trLXNjUWxHTEVBTHBfX2ZIOUEySkhiZkUyNl9QOXc0a2FnZWNLUXc0Y3JRV1YxRmRmbVJfN1hyOTZxNTRKQjFqQVZQZ0xRNko5SC1LaGNqR2RrNjU1SmFKOUhxblNsWTZEN0lXaTVrQnlKTWt6V0Q5WQ&q=https%3A%2F%2Fgithub.com%2Fteddylee777%2Flangchain-kr)\n---\n📍 \"Teddy Note's RAG Secret Notes\" Langchain Lecture: [https://fastcampus.co.kr/data\\_online\\_...](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqbGtzX2JOaERBWHFlNmZldGZpSlNzNVBVZ0d0d3xBQ3Jtc0tuYVdrQVkwTE1mNFVMU2Z3T2NpRGtIcjBRbGlySUdYV2ZKcTZwMWg4cUoyazQ0VGkxTEQ1cmdwRjNoYTZ4cHZyeUlQTXctY3U5RFJQb3NoMVh4WjZjZExzTXZQdE1iQ1lGY3lSRmNCcVRvWHo4TEFnRQ&q=https%3A%2F%2Ffastcampus.co.kr%2Fdata_online_teddy)\n📘 Langchain Korean Tutorial (Free Ebook): [https://wikidocs.net/book/14314](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqblZJNzdMQkNlUUl1MnFVOVI0alQ1V0hqQmliQXxBQ3Jtc0traDVWTlpKdHB3QXk1NHdna28yU2lCYjAwaUdZN25CSExjTkN2QkZ6QXY0NlFVWjR3ejFvWks4RzR2d1REaXBuMm15aEpDSWdEODB1LUJTQmtuSHhXZl9zQjhxRDI2ejNUR25FejVfVzhiR05tRXA3MA&q=https%3A%2F%2Fwikidocs.net%2Fbook%2F14314)\n📝 Teddy Note (GitHub Blog): [https://teddylee777.github.io](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqbmtTT1RlU2VJRkFJamZuRVdvVWRZMmNRYi02Z3xBQ3Jtc0tsdzdLaUVUTll4V2MwdzNRWU41aHJTMWVpa0VSLXFyUExjbDc3UVgySklLd2swbUFEdzNocDU0RjFQZDJVWElUZ21qYlp1ZGxVNXRRSUlVYmhiT0FJakN5MDRkRlJ1RFhxbVVTaW5wbTlKQS0tWGFESQ&q=https%3A%2F%2Fteddylee777.github.io%2F)\n💻 GitHub Source Code Repository: [https://github.com/teddylee777](https://www.youtube.com/redirect?event=video_description&redir_token=QUFFLUhqbG1BdXNjTVplS05rTlozLTUzdS1wSWxhZExWUXxBQ3Jtc0tsNndxVTRCTkRPd3R6WjlzTGRmNThSS3UtbDZoaHhQNm1BSTYwOHVrRW1DTjg4OGJQeVNYZkxQempzanh0WExaR1RMWVlyQ3JPU3VUMEZoa3dNeHJIUV9odDRqdXg2RmwzQzRPWjl4QWRUREZOaTNnQQ&q=https%3A%2F%2Fgithub.com%2Fteddylee777)\n\n\n\n[Read more](/watch?v=zybyszetEcE)\n\nOur members\nThank you, channel members!\n\nJoin\n\n## [Videos](/@teddynote/videos?view=0&sort=dd&shelf_id=2)\n\n### [Introducing Deep Agent Builder, an agent builder built with natural language.](/watch?v=QI2KVJ2ciiY \"Introducing Deep Agent Builder, an agent builder built with natural language.\")\n\n### [LangSmith Agent Builder, the first #no-code agent builder by #langchain](/watch?v=DGgvu-ALJx0 \"LangSmith Agent Builder, the first #no-code agent builder by #langchain\")\n\n### [Custom chatbot interface for LangGraph builder](/watch?v=DMQXpZXdNJ8 \"Custom chatbot interface for LangGraph builder\")\n\n### [#MCP #A2A What are the selection criteria when developing?](/watch?v=1guF3c-jWBk \"#MCP #A2A What are the selection criteria when developing?\")\n\n### [Exploring the Possibilities of #MCP X #A2A Enterprise-Oriented Security Design Architecture](/watch?v=ENLQA0GH36g&pp=0gcJCZEKAYcqIYzv \"Exploring the Possibilities of #MCP X #A2A Enterprise-Oriented Security Design Architecture\")\n\n### [🔥How to make RAG into #MCP (claude desktop, cursor)🔥](/watch?v=0etZjVebcu4 \"🔥How to make RAG into #MCP (claude desktop, cursor)🔥\")"}, {"url": "https://www.youtube.com/@teddynote/videos", "title": "테디노트 TeddyNote - YouTube", "content": "TermsPrivacyPolicy & SafetyHow YouTube worksTest new featuresNFL Sunday Ticket. ### Introducing Deep Agent Builder, an agent builder built with natural language. ### LangSmith Agent Builder, the first #no-code agent builder by #langchain. ### Custom chatbot interface for LangGraph builder. ### Previewing the Future of AI Agents with #Palantir #Ontology. ### 🔥 Instead of Cursor AI, create your own #MCP agent app! We've taken a look! And we've prepared a #tutorial, too🔥. ### #teddyflow 로 dify, langgraph, n8n 을 한 번에 연결해서 사용하기. ### Building a #dify custom tool (#upstage parser)\"). ### How to use the #Upstage document parser (server, client) built with #LangGraph built with #LangGraph\"). 혼자\\_떠들기.mp4 - YouTube 라이브편. ### Building an Agentic AI System Using #LangGraph (Agentic AI Meetup 2025 Q1)\"). ### #I connected #dify to #Obsidian and applied RAG / Agent / Workflow to Obsidian Note. ### I automated the title, metadata, and summary tasks in my #Obsidian notes. ### 새해 시작은 NO코드 #RAG #Agent #Workflow 구축해보기!", "score": 0.8106142, "raw_content": "Back\n\n[Sign in](https://accounts.google.com/ServiceLogin?service=youtube&uilel=3&passive=true&continue=https%3A%2F%2Fwww.youtube.com%2Fsignin%3Faction_handle_signin%3Dtrue%26app%3Ddesktop%26hl%3Den%26next%3Dhttps%253A%252F%252Fwww.youtube.com%252F%2540teddynote%252Fvideos&hl=en&ec=65620)\n\n[About](https://www.youtube.com/about/)[Press](https://www.youtube.com/about/press/)[Copyright](https://www.youtube.com/about/copyright/)[Contact us](/t/contact_us/)[Creators](https://www.youtube.com/creators/)[Advertise](https://www.youtube.com/ads/)[Developers](https://developers.google.com/youtube)\n\n[Terms](/t/terms)[Privacy](/t/privacy)[Policy & Safety](https://www.youtube.com/about/policies/)[How YouTube works](https://www.youtube.com/howyoutubeworks?utm_campaign=ytgen&utm_source=ythp&utm_medium=LeftNav&utm_content=txt&u=https%3A%2F%2Fwww.youtube.com%2Fhowyoutubeworks%3Futm_source%3Dythp%26utm_medium%3DLeftNav%26utm_campaign%3Dytgen)[Test new features](/new)[NFL Sunday Ticket](https://tv.youtube.com/learn/nflsundayticket)\n\n© 2026 Google LLC\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n[36:19\n\n36:19\n\nNow playing](/watch?v=QI2KVJ2ciiY)\n[36:19\n\n36:19\n\n36:19\n\nNow playing](/watch?v=QI2KVJ2ciiY)\n\n### [Introducing Deep Agent Builder, an agent builder built with natural language.](/watch?v=QI2KVJ2ciiY \"Introducing Deep Agent Builder, an agent builder built with natural language.\")\n\n•\n\n•\n\n3K views\n7 days ago\n\n[13:55\n\n13:55\n\nNow playing](/watch?v=DGgvu-ALJx0)\n[13:55\n\n13:55\n\n13:55\n\nNow playing](/watch?v=DGgvu-ALJx0)\n\n### [LangSmith Agent Builder, the first #no-code agent builder by #langchain](/watch?v=DGgvu-ALJx0 \"LangSmith Agent Builder, the first #no-code agent builder by #langchain\")\n\n•\n\n•\n\n4.3K views\n2 months ago\n\n[9:22\n\n9:22\n\nNow playing](/watch?v=DMQXpZXdNJ8)\n[9:22\n\n9:22\n\n9:22\n\nNow playing](/watch?v=DMQXpZXdNJ8)\n\n### [Custom chatbot interface for LangGraph builder](/watch?v=DMQXpZXdNJ8 \"Custom chatbot interface for LangGraph builder\")\n\n•\n\n•\n\n3.4K views\n2 months ago\n\n[10:07\n\n10:07\n\nNow playing](/watch?v=1guF3c-jWBk)\n[10:07\n\n10:07\n\n10:07\n\nNow playing](/watch?v=1guF3c-jWBk)\n\n### [#MCP #A2A What are the selection criteria when developing?](/watch?v=1guF3c-jWBk \"#MCP #A2A What are the selection criteria when developing?\")\n\n•\n\n•\n\n3.6K views\n6 months ago\n\n[33:59\n\n33:59\n\nNow playing](/watch?v=ENLQA0GH36g)\n[33:59\n\n33:59\n\n33:59\n\nNow playing](/watch?v=ENLQA0GH36g)\n\n### [Exploring the Possibilities of #MCP X #A2A Enterprise-Oriented Security Design Architecture](/watch?v=ENLQA0GH36g \"Exploring the Possibilities of #MCP X #A2A Enterprise-Oriented Security Design Architecture\")\n\n•\n\n•\n\n2.1K views\n6 months ago\n\n[16:26\n\n16:26\n\nNow playing](/watch?v=0etZjVebcu4)\n[16:26\n\n16:26\n\n16:26\n\nNow playing](/watch?v=0etZjVebcu4)\n\n### [🔥How to make RAG into #MCP (claude desktop, cursor)🔥](/watch?v=0etZjVebcu4 \"🔥How to make RAG into #MCP (claude desktop, cursor)🔥\")\n\n•\n\n•\n\n13K views\n7 months ago\n\n[23:16\n\n23:16\n\nNow playing](/watch?v=GKOWbcNidjo)\n[23:16\n\n23:16\n\n23:16\n\nNow playing](/watch?v=GKOWbcNidjo)\n\n### [Reasoning, RAG, 추론 모델의 현재와 미래](/watch?v=GKOWbcNidjo \"Reasoning, RAG, 추론 모델의 현재와 미래\")\n\n•\n\n•\n\n6.9K views\n7 months ago\n\n[12:41\n\n12:41\n\n12:41\n\nNow playing](/watch?v=6Zd7d1iqk5I&pp=0gcJCZEKAYcqIYzv)\n\n### [지식을 생산하는 AI, 인간 연구자의 역할은?](/watch?v=6Zd7d1iqk5I&pp=0gcJCZEKAYcqIYzv \"지식을 생산하는 AI, 인간 연구자의 역할은?\")\n\n•\n\n•\n\n2.3K views\n7 months ago\n\n[10:00\n\n10:00\n\n10:00\n\nNow playing](/watch?v=nyZnrKVaIXU)\n\n### [에이전트 시스템에서 #A2A 와 #MCP 의 의미](/watch?v=nyZnrKVaIXU \"에이전트 시스템에서 #A2A 와 #MCP 의 의미\")\n\n•\n\n•\n\n15K views\n8 months ago\n\n[14:57\n\n14:57\n\n14:57\n\nNow playing](/watch?v=ctKz2bkgkPQ)\n\n### [Previewing the Future of AI Agents with #Palantir #Ontology](/watch?v=ctKz2bkgkPQ \"Previewing the Future of AI Agents with #Palantir #Ontology\")\n\n•\n\n•\n\n22K views\n8 months ago\n\n[31:31\n\n31:31\n\n31:31\n\nNow playing](/watch?v=Zk3ipzTMe1g)\n\n### [2025 Document Parser Comparison! Synap DocuAnalyzer vs. Upstage Document Parse](/watch?v=Zk3ipzTMe1g \"2025 Document Parser Comparison! Synap DocuAnalyzer vs. Upstage Document Parse\")\n\n•\n\n•\n\n7.4K views\n9 months ago\n\n[2:57:06\n\n2:57:06\n\n2:57:06\n\nNow playing](/watch?v=W_uwR_yx4-c)\n\n### [🔥 #LangGraph 개념 완전 정복 몰아보기(3시간) 🔥](/watch?v=W_uwR_yx4-c \"🔥 #LangGraph 개념 완전 정복 몰아보기(3시간) 🔥\")\n\n•\n\n•\n\n114K views\n9 months ago\n\n[12:19\n\n12:19\n\n12:19\n\nNow playing](/watch?v=s-rDDqcGymk)\n\n### [#MCP 에이전트 공개(동적 도구 설정 대시보드, 시스템 프롬프트 설정, 다양한 모델)](/watch?v=s-rDDqcGymk \"#MCP 에이전트 공개(동적 도구 설정 대시보드, 시스템 프롬프트 설정, 다양한 모델)\")\n\n•\n\n•\n\n6.1K views\n9 months ago\n\n[10:11\n\n10:11\n\n10:11\n\nNow playing](/watch?v=A31X4gdGbKw)\n\n### [🔥 #langgraph 에이전트 + #mcp 도구 서버로 띄우고 프론트와 쉽게 연결하기🔥](/watch?v=A31X4gdGbKw \"🔥 #langgraph 에이전트 + #mcp 도구 서버로 띄우고 프론트와 쉽게 연결하기🔥\")\n\n•\n\n•\n\n9.9K views\n10 months ago\n\n[19:06\n\n19:06\n\n19:06\n\nNow playing](/watch?v=ISrYHGg2C2c&pp=0gcJCZEKAYcqIYzv)\n\n### [🔥 Instead of Cursor AI, create your own #MCP agent app! 🔥](/watch?v=ISrYHGg2C2c&pp=0gcJCZEKAYcqIYzv \"🔥 Instead of Cursor AI, create your own #MCP agent app! 🔥\")\n\n•\n\n•\n\n50K views\n10 months ago\n\n[29:29\n\n29:29\n\n29:29\n\nNow playing](/watch?v=VKIl0TIDKQg&pp=0gcJCZEKAYcqIYzv)\n\n### [🔥 Why is #MCP so popular? We've taken a look! And we've prepared a #tutorial, too🔥](/watch?v=VKIl0TIDKQg&pp=0gcJCZEKAYcqIYzv \"🔥 Why is #MCP so popular? We've taken a look! And we've prepared a #tutorial, too🔥\")\n\n•\n\n•\n\n98K views\n10 months ago\n\n[5:28\n\n5:28\n\n5:28\n\nNow playing](/watch?v=BkJ6hiZSnR0)\n\n### [#teddyflow 로 dify, langgraph, n8n 을 한 번에 연결해서 사용하기](/watch?v=BkJ6hiZSnR0 \"#teddyflow 로 dify, langgraph, n8n 을 한 번에 연결해서 사용하기\")\n\n•\n\n•\n\n4.5K views\n10 months ago\n\n[15:13\n\n15:13\n\n15:13\n\nNow playing](/watch?v=xWG4nYBZTsE)\n\n### [Building a #dify custom tool (#upstage parser)](/watch?v=xWG4nYBZTsE \"Building a #dify custom tool (#upstage parser)\")\n\n•\n\n•\n\n4.3K views\n10 months ago\n\n[10:35\n\n10:35\n\n10:35\n\nNow playing](/watch?v=gEjAq3Jnu94)\n\n### [How to use the #Upstage document parser (server, client) built with #LangGraph](/watch?v=gEjAq3Jnu94 \"How to use the #Upstage document parser (server, client) built with #LangGraph\")\n\n•\n\n•\n\n5.3K views\n10 months ago\n\n[7:26\n\n7:26\n\n7:26\n\nNow playing](/watch?v=iUazlZsVzhw)\n\n### [EP01. 혼자\\_떠들기.mp4 - YouTube 라이브편](/watch?v=iUazlZsVzhw \"EP01. 혼자_떠들기.mp4 - YouTube 라이브편\")\n\n•\n\n•\n\n1.5K views\n10 months ago\n\n[38:48\n\n38:48\n\n38:48\n\nNow playing](/watch?v=edsshVochqM)\n\n### [Building an Agentic AI System Using #LangGraph (Agentic AI Meetup 2025 Q1)](/watch?v=edsshVochqM \"Building an Agentic AI System Using #LangGraph (Agentic AI Meetup 2025 Q1)\")\n\n•\n\n•\n\n17K views\n10 months ago\n\n[19:56\n\n19:56\n\n19:56\n\nNow playing](/watch?v=-Jym-zji7YI)\n\n### [#LangSmith Playground 로 프롬프트 실험하는 방법(스키마, Tool, Canvas)](/watch?v=-Jym-zji7YI \"#LangSmith Playground 로 프롬프트 실험하는 방법(스키마, Tool, Canvas)\")\n\n•\n\n•\n\n3.6K views\n11 months ago\n\n[8:13\n\n8:13\n\n8:13\n\nNow playing](/watch?v=dhwhAiGPe9c&pp=0gcJCZEKAYcqIYzv)\n\n### [#GTC 이벤트 참여하고 RTX 4080 의 주인공이 되세요!](/watch?v=dhwhAiGPe9c&pp=0gcJCZEKAYcqIYzv \"#GTC 이벤트 참여하고 RTX 4080 의 주인공이 되세요!\")\n\n•\n\n•\n\n1.7K views\n11 months ago\n\n[8:41\n\n8:41\n\nNow playing](/watch?v=1OKglcbftY8)\n\n### [❤️[책 소개+출간 이벤트] 일잘러의 비밀, 챗GPT와 GPTs로 나만의 AI 챗봇 만들기❤️](/watch?v=1OKglcbftY8 \"❤️[책 소개+출간 이벤트] 일잘러의 비밀, 챗GPT와 GPTs로 나만의 AI 챗봇 만들기❤️\")\n\n[14:30\n\n14:30\n\nNow playing](/watch?v=zdEev8vT_zg)\n\n### [#I connected #dify to #Obsidian and applied RAG / Agent / Workflow to Obsidian Note.](/watch?v=zdEev8vT_zg \"#I connected #dify to #Obsidian and applied RAG / Agent / Workflow to Obsidian Note.\")\n\n[6:55\n\n6:55\n\nNow playing](/watch?v=z5Zo6vrYdFk)\n\n### [I automated the title, metadata, and summary tasks in my #Obsidian notes. (Free template sharing)](/watch?v=z5Zo6vrYdFk \"I automated the title, metadata, and summary tasks in my #Obsidian notes. (Free template sharing)\")\n\n[21:06\n\n21:06\n\nNow playing](/watch?v=9XQDpIlB3jk)\n\n### [코딩 과외 선생님을 만들어 봤습니다.](/watch?v=9XQDpIlB3jk \"코딩 과외 선생님을 만들어 봤습니다.\")\n\n[26:40\n\n26:40\n\nNow playing](/watch?v=OTsf94r_BkQ)\n\n### [새해 시작은 NO코드 #RAG #Agent #Workflow 구축해보기!](/watch?v=OTsf94r_BkQ \"새해 시작은 NO코드 #RAG #Agent #Workflow 구축해보기!\")"}]"
additional_kwargs: {}
response_metadata: {}
type: "tool"
name: "tavily_web_search"
id: "f9623249-518c-4fa0-a77b-458dd292bad1"
tool_call_id: "call_3C93FykeMqVTnWAT1GdfXgOO"
artifact: None
status: "success"
==============
STEP: chatbot
==============
content: "테디노트(TeddyNote)는 데이터 분석, 머신러닝, 딥러닝, LLM(대형 언어 모델)에 관한 다양한 내용을 다루는 유튜브 채널입니다. 이 채널은 개발 중심의 콘텐츠를 제공하며, 구독자는 50.2K명입니다. 최근 로Streamed 비디오로 다양한 AI 관련 토픽을 다루고 있습니다.
몇 가지 비디오 예시:
1. [Deep Agents와 Agentic Coding에 대한 강연](https://www.youtube.com/watch?v=SKqCA-43nPM)
2. [LangChain과의 연계된 Q&A 세션](https://www.youtube.com/watch?v=QAMDYNaDegM)
3. [AI 개발의 미래에 대한 논의](https://www.youtube.com/watch?v=qq8HxJxy7gE)
채널 링크: [테디노트 유튜브](https://www.youtube.com/@teddynote/streams)
더 많은 비디오와 정보를 보려면 채널을 방문해 보세요!"
additional_kwargs: {"refusal": None}
response_metadata:
token_usage:
completion_tokens: 223
prompt_tokens: 16922
total_tokens: 17145
completion_tokens_details: {"accepted_prediction_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 0, "rejected_prediction_tokens": 0}
prompt_tokens_details: {"audio_tokens": 0, "cached_tokens": 0}
model_provider: "openai"
model_name: "gpt-4o-mini-2024-07-18"
system_fingerprint: "fp_6c0d1490cb"
id: "chatcmpl-D7bcw0ZVQDKojFQfMzeY4CYWdzs5R"
service_tier: "default"
finish_reason: "stop"
logprobs: None
type: "ai"
name: None
id: "lc_run--019c4642-c1bb-7750-9e6a-0c784a435ada-0"
tool_calls:
invalid_tool_calls:
usage_metadata:
input_tokens: 16922
output_tokens: 223
total_tokens: 17145
input_token_details: {"audio": 0, "cache_read": 0}
output_token_details: {"audio": 0, "reasoning": 0}
5. Agent에 메모리 추가
현재까지 만든 챗봇은 과거 상호작용을 스스로 기억할 수 없어 일관된 다중 턴 대화를 진행하는 데 제한이 있습니다. 이번 예제에서는 이를 해결하기 위해 메모리를 추가해 보고자 합니다.
이번에는 pre-built 되어 있는 ToolNode와 tools_condition을 활용합니다. 이전 항목까지 만들어 봤던 챗봇은 이제 도구를 사용하여 사용자 질문에 답할 수 있지만, 이전 상호작용의 context를 기억하지 못합니다. 이는 멀티턴(multiturn) 대화를 진행하는 능력을 제한합니다.
LangGraph는 persistent checkpointing을 통해 이 문제를 해결합니다.
그래프를 컴파일할 때 checkpointer를 제공하고 그래프를 호출할 때 thread_id를 제공하면, LangGraph는 각 단계 후 상태를 자동으로 저장합니다. 동일한 thread_id를 사용하여 그래프를 다시 호출하면, 그래프는 저장된 상태를 로드하여 챗봇이 이전에 중단한 지점에서 대화를 이어갈 수 있게 합니다.
예제 코드 실행에 앞서 코드 실행에 필요한 라이브러리 설치를 먼저 진행해 줍니다.
!pip install -U langchain-openai langchain-teddynote langchain-core
우선 MemorySaver checkpointer를 생성합니다.
from langgraph.checkpoint.memory import MemorySaver
# 메모리 저장소 생성
memory = MemorySaver()
이번 예제에서는 in-memory checkcpointer를 사용합니다.
from typing import Annotated
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langchain_teddynote.tools.tavily import TavilySearch
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
## 1. 상태 정의
class State(TypedDict):
# 메시지 목록 주석 추가
messages: Annotated[list, add_messages]
## 2. 도구 정의 및 바인딩
tool = TavilySearch(max_results=3)
tools = [tool]
# LLM 초기화
llm = ChatOpenAI(model="gpt-4o-mini")
# 도구와 LLM 결합
llm_with_tools = llm.bind_tools(tools)
## 3. 노드 추가
# 챗봇 함수 정의
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 상태 그래프 생성
graph_builder = StateGraph(State)
# 챗봇 노드 추가
graph_builder.add_node("chatbot", chatbot)
# 도구 노드 생성 및 추가
tool_node = ToolNode(tools=[tool])
# 도구 노드 추가
graph_builder.add_node("tools", tool_node)
# 조건부 엣지
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
## 4. 엣지 추가
# tools -> chatbot
graph_builder.add_edge("tools", "chatbot")
# START -> chatbot
graph_builder.add_edge(START, "chatbot")
# chatbot -> END
graph_builder.add_edge("chatbot", END)
마지막으로, 제공된 checkpointer를 사용하여 그래프를 컴파일 합니다.
# 그래프 빌더 컴파일
graph = graph_builder.compile(checkpointer=memory)
5.1 RunnableConfig 설정
RunnableConfig을 정의하고 recursion_limit과 thread_id를 설정합니다.
recursion_limit: 최대 방문할 노드 수, 그 이상은 RecursionError 발생thread_id: 스레드 ID 설정
thread_id는 대화 세션을 구분하는데 사용됩니다. 즉, 메모리의 저장은 thread_id에 따라 개별적으로 이루어집니다.
from langchain_core.runnables import RunnableConfig
config = RunnableConfig(
recursion_limit = 10, # 최대 10개의 노드까지 방문, 그 이상은 RecursionError 발생
configurable={"thread_id": "1"} # 스레드 ID 설정, 딕셔너리 형태로 수정
)
question = (
"내 이름은 `테디노트` 입니다. YouTube 채널을 운영하고 있어요. 만나서 반가워요"
)
for event in graph.stream({"messages": [("user", question)]}, config=config):
for value in event.values():
value["messages"][-1].pretty_print()
Output:
================================== Ai Message ==================================
안녕하세요, 테디노트님! 만나서 반갑습니다. YouTube 채널에 대해 좀 더 알려주실 수 있나요? 어떤 내용을 다루고 계신지 궁금합니다!
# 이어지는 질문
question = "제 이름이 뭐라고 했죠?"
for event in graph.stream({"messages": [("user", question)]}, config=config):
for value in event.values():
value["messages"][-1].pretty_print()
Output:
================================== Ai Message ==================================
당신의 이름은 테디노트입니다!
이번엔 RunnableConfig의 thread_id를 변경한 뒤, 이전 대화 내용을 기억하고 있는지 물어보도록 하겠습니다.
from langchain_core.runnables import RunnableConfig
question = "제 이름이 뭐라고 했죠?"
config = RunnableConfig(
recursion_limit =10,
configurable={"thread_id": "2"},
)
for event in graph.stream({"messages": [("user", question)]}, config=config):
for value in event.values():
value["messages"][-1].pretty_print()
Output:
================================== Ai Message ==================================
죄송하지만, 이전 대화 내용을 기억할 수 없어서 귀하의 이름을 알 수 없습니다. 다시 말씀해 주실 수 있나요?
5.2 스냅샷: 저장된 State 확인
LangGraph의 Snapshot은 그래프의 특정 시점의 상태(State)를 그대로 사진 찍듯 저장해두는 기능입니다. 이 기능은 단순히 데이터를 저장하는 것을 넘어, 복잡한 AI 에이전트를 제어하는 데 있어 필수적인 역할을 합니다.
LangGraph의 Snapshot 기능이 주로 사용되는 곳은 다음과 같습니다.
-
체크포인트(checkpointing)를 통한 상태 복구
에이전트가 작업을 수행하다가 오류가 나거나 서버가 다운될 수 있습니다. 이때 스냅샷이 있다면 처음부터 다시 시작할 필요 없이 마지막으로 성공적으로 저장된 스냅샷 지점부터 작업을 재개하도록 할 수 있습니다.
-
타임머신 기능 (Time Travel & Debugging)
개발 과정에서 에이전트가 왜 이상한 답변을 했는지 파악해야 할 때가 있습니다.
- 활용: 과거 특정 시점의 스냅샷으로 돌아가서 당시의 상태값(변수, 대화 기록 등)을 확인합니다.
- 장점: 복잡한 루프 구조 내에서 발생한 논리적 오류를 추적하기가 쉬워집니다.
-
사람의 승인 단계 (Human-in-the-loop)
중요한 작업(예: 이메일 발송, 결제, 데이터 삭제)을 수행하기 전, 에이전트를 ‘일시 정지’ 시켜야 할 때 사용합니다.
-
상태 수정 및 재시도 (State Modification)
과거의 상태로 돌아가는 것뿐만 아니라, 그 상태의 내용을 살짝 수정해서 다시 실행해 볼 수 있습니다.
Checkpoint에는 현재 상태 값, 해당 구성, 그리고 처리할 next 노드가 포함되어 있습니다. 주어진 설정에서 그래프의 state를 검사하려면 언제든지 get_state(config)를 호출하여 설정하면 됩니다.
from langchain_core.runnables import RunnableConfig
config = RunnableConfig(
configurable={"thread_id": "1"} # 스레드 ID 설정
)
# 그래프 상태 스냅샷 생성
snapshot = graph.get_state(config)
snapshot.values["messages"]
Output:
[HumanMessage(content='내 이름은 `테디노트` 입니다. YouTube 채널을 운영하고 있어요. 만나서 반가워요', additional_kwargs={}, response_metadata={}, id='e54e310e-2a41-43bd-a6c7-8200088a117f'),
AIMessage(content='안녕하세요, 테디노트님! 만나서 반갑습니다. YouTube 채널에 대해 좀 더 알려주실 수 있나요? 어떤 내용을 다루고 계신지 궁금합니다!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 43, 'prompt_tokens': 118, 'total_tokens': 161, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_f4ae844694', 'id': 'chatcmpl-D7chAViMqCzuEd7x5jnpAuwuenRGO', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019c4681-6593-7640-abe7-3151f9b051b2-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 118, 'output_tokens': 43, 'total_tokens': 161, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
HumanMessage(content='제 이름이 뭐라고 했죠?', additional_kwargs={}, response_metadata={}, id='9d28957e-a10f-4917-b0ac-945bfc01bd6e'),
AIMessage(content='당신의 이름은 테디노트입니다!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 12, 'prompt_tokens': 176, 'total_tokens': 188, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_f4ae844694', 'id': 'chatcmpl-D7chaALKD0VdcmXuPFCE5kQ38ia1S', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019c4681-d054-7e02-a1be-025e5bbbf8c5-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 176, 'output_tokens': 12, 'total_tokens': 188, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]
6. LangGraph 노드의 단계별 스트리밍 출력
노드별 스트리밍 출력 기능은 실제 프로덕션 환경의 LLM 서비스를 구축할 때 필수적인 핵심 기능입니다. 그 이유는 다음과 같습니다.
- 사용자 경험(UX)의 혁신: “기다림을 소통으로”
LLM 에이전트가 복잡한 추론을 하거나 여러 도구(Tool)를 실행할 때, 전체 결과가 나올 때까지 빈 화면만 보여주는 것은 최악의 UX라고 볼 수 있습니다.
- 시각적 피드백: 노드별 스트리밍을 사용하면 “에이전트가 지금 검색 중입니다…”, “결과를 요약하고 있습니다…“와 같은 진행 상황을 실시간으로 보여줄 수 있습니다.
- 체감 대기 시간 감소: 사용자는 결과가 한꺼번에 쏟아지는 것보다 조금씩 출력되는 과정을 볼 때 훨씬 더 서비스가 빠르고 신뢰할 수 있다고 느낍니다.
- 디버깅과 관찰 가능성 (Observability)
개발자 입장에서 LangGraph는 여러 노드가 얽혀 있는 복잡한 시스템입니다.
- 중간 과정 추적: 어떤 노드에서 시간이 오래 걸리는지, 어떤 노드에서 잘못된 데이터가 생성되는지 스트리밍을 통해 실시간으로 모니터링 할 수 있습니다.
- 상태 변화 확인:
astream_events같은 기능을 사용하면 노드 사이에서State가 어떻게 변하는지 (TypedDict에 데이터가 어떻게 쌓이는지) 실시간으로 파악되어 문제 해결 속도가 비약적으로 빨라집니다.
- 복합 에이전트 제어 (Multi-Agent Interaction)
여러 에이전트가 협업하는 구조에서 스트리밍은 시스템 간의 ‘심박수’를 체크하는 것과 같습니다.
- 중간 개입 가능성: 스트리밍되는 출력을 보고 있다가, 에이전트가 엉뚱한 방향으로 가고 있다면 즉시 프로세스를 중단 시키거나 수정할 수 있는 기반이 됩니다.
실습 코드 실행에 필요한 라이브러리 설치를 진행해 줍니다.
!pip install -U langchain-teddynote langchain-openai langchain-core
우선 이전에 진행했었던 도구와 LLM 그리고 Graph를 그대로 사용하고자 합니다.
from typing import Annotated, List, Dict
from typing_extensions import TypedDict
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_teddynote.graphs import visualize_graph
from langchain_teddynote.tools import GoogleNews
## 1. 상태 정의
class State(TypedDict):
messages: Annotated[list, add_messages]
dummy_data: Annotated[str, "dummy"]
## 2. 도구 정의 및 바인딩
# 키워드로 뉴스 검색하는 도구 생성
news_tool = GoogleNews()
@tool
def search_keyword(query: str) -> List[Dict[str, str]]:
"""Look up news by keyword"""
news_tool = GoogleNews()
return news_tool.search_by_keyword(query, k=5)
tools = [search_keyword]
# LLM 초기화
llm = ChatOpenAI(model="gpt-4o-mini")
# 도구와 LLM 결합
llm_with_tools = llm.bind_tools(tools)
## 3. 노드 추가
# 챗봇 함수 정의
def chatbot(state: State):
return {
"messages": [llm_with_tools.invoke(state["messages"])],
"dummy_data": "[chatbot] 호출, dummy data",
}
# 상태 그래프 생성
graph_builder = StateGraph(State)
# 챗봇 노드 추가
graph_builder.add_node("chatbot", chatbot)
# 도구 노드 생성 및 추가
tool_node = ToolNode(tools=tools)
# 도구 노드 추가
graph_builder.add_node("tools", tool_node)
# 조건부 엣지
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
## 4. 엣지 추가
# tools -> chatbot
graph_builder.add_edge("tools", "chatbot")
# START -> chatbot
graph_builder.add_edge(START, "chatbot")
# chatbot -> END
graph_builder.add_edge("chatbot", END)
## 5. 그래프 컴파일
graph = graph_builder.compile()
6.1 StateGraph의 stream 메서드
stream 메서드는 단일 입력에 대한 그래프 단계를 스트리밍하는 기능을 제공합니다.
매개변수는 다음과 같습니다.
input(Union[dict[str, Any], Any]): 그래프에 대한 입력config(Optional[RunnableConfig]): 실행 구성stream_mode(Optional[Union[StreamMode, list[StreamMode]]]): 출력 스트리밍 모드output_keys(Optional[Union[str, Sequence[str]]]): 스트리밍할 키interuupt_before(Optional[Union[All, Sequence[str]]]): 실행 전에 중단할 노드interrupt_after(Optional[Union[All, Sequence[str]]]): 실행 후에 중단할 노드debug(Optional[bool]): 디버그 정보 출력 여부subgraphs(bool): 하위 그래프 스트리밍 여부
반환값은 다음과 같습니다.
- Iterator[Union[dict[str, Any], Any]]: 그래프의 각 단계 출력, 출력 형태는
stream_mode에 따라 다름
주요 기능
- 입력된 설정에 따라 그래프 실행을 스트리밍 방식으로 처리
- 다양한 스트리밍 모드 지원(values, updates, debug)
- 콜백 관리 및 오류 처리
- 재귀 제한 및 중단 조건 처리
6.1.1 output_keys 옵션
output_keys 옵션은 스트리밍할 키를 지정하는데 사용됩니다. list 형식으로 지정할 수 있으며, channels에 정의된 키 중 하나여야 합니다.
매 단계마다 출력되는 State key가 많은 경우, 일부만 스트리밍하고 싶은 경우에 유용합니다.
# channels에 정의된 키 목록을 출력합니다.
print(list(graph.channels.keys()))
output_keys에 channels에 있는 키 중 하나인 dummy_data를 넣어보도록 하겠습니다.
question = "2025년 노벨 문학상 관련 뉴스를 알려주세요."
# 초기 입력 State 를 정의
input = State(dummy_data="테스트 문자열", messages=[("user", question)])
# config 설정
config = RunnableConfig(
recursion_limit=10, # 최대 10개의 노드까지 방문. 그 이상은 RecursionError 발생
configurable={"thread_id": "1"}, # 스레드 ID 설정
tags=["my-rag"], # Tag
)
for event in graph.stream(
input=input,
config=config,
output_keys=["dummy_data"],):
for key, value in event.items():
print(f"\n[{key}]\n")
# dummy_data가 존재하는 경우
if value:
print(value.keys())
if "dummy_data" in value:
print(value["dummy_data"])
출력을 해보면 dummy_data만 출력되는 것을 확인할 수 있습니다.
Output:
[chatbot]
dict_keys(['dummy_data'])
[chatbot] 호출, dummy data
[tools]
[chatbot]
dict_keys(['dummy_data'])
[chatbot] 호출, dummy data
6.1.2 stream_mode 옵션
LangGraph는 크게 두 가지 방식의 스트리밍을 지원합니다. stream_mode 옵션은 스트리밍 출력 모드를 지정하는데 사용됩니다.
- Values Streaming(stream_mode=”values”):
- 노드가 실행될 때마다 전체 상태(State) 값을 출력합니다. 현재 데이터가 어떻게 바뀌었는지 한 눈에 보기 좋습니다.
- Updates Streaming(stream_mode=”updates”):
- 해당 노드에서 새롭게 업데이트된 값만 출력합니다. 어떤 노드가 어떤 일을 했는지 명확히 알 수 있습니다.
우선 Values Streaming 예제부터 살펴보도록 하겠습니다.
question = "2025년 노벨 문학상 관련 뉴스를 알려주세요."
input = State(dummy_data="테스트 문자열", messages=[("user", question)])
config = RunnableConfig(
recursion_limit=10,
configurable={"thread_id": "1"},
tags=["my-tag"],
)
# values 모드로 스트리밍 출력
for event in graph.stream(
input=input,
stream_mode="values", # 기본값
):
for key, value in event.items():
# key 는 state 의 key 값
print(f"\n[ {key} ]\n")
if key == "messages":
print(f"메시지 개수: {len(value)}")
# print(value)
print("===" * 10, " 단계 ", "===" * 10)
Output:
[ messages ]
메시지 개수: 1
[ dummy_data ]
============================== 단계 ==============================
[ messages ]
메시지 개수: 2
[ dummy_data ]
============================== 단계 ==============================
[ messages ]
메시지 개수: 3
[ dummy_data ]
============================== 단계 ==============================
[ messages ]
메시지 개수: 4
[ dummy_data ]
============================== 단계 ==============================
다음으로는 Updates Streaming 입니다.
# 질문
question = "2025년 노벨 문학상 관련 뉴스를 알려주세요."
# 초기 입력 State 를 정의
input = State(dummy_data="테스트 문자열", messages=[("user", question)])
# config 설정
config = RunnableConfig(
recursion_limit=10, # 최대 10개의 노드까지 방문. 그 이상은 RecursionError 발생
configurable={"thread_id": "1"}, # 스레드 ID 설정
tags=["my-rag"], # Tag
)
# updates 모드로 스트리밍 출력
for event in graph.stream(
input=input,
stream_mode="updates", # 기본값
):
for key, value in event.items():
# key 는 노드 이름
print(f"\n[ {key} ]\n")
# value 는 노드의 출력값
print(value.keys())
# value 에는 state 가 dict 형태로 저장(values 의 key 값)
if "messages" in value:
print(f"메시지 개수: {len(value['messages'])}")
# print(value["messages"])
print("===" * 10, " 단계 ", "===" * 10)
이전의 Values Streaming 방식과는 다르게 출력되는 것이 적은 것을 확인할 수 있습니다. 노드에서 업데이트가 일어날 때마다 출력을 하기 때문에 그렇습니다.
Output:
[ chatbot ]
dict_keys(['messages', 'dummy_data'])
메시지 개수: 1
============================== 단계 ==============================
[ tools ]
dict_keys(['messages'])
메시지 개수: 1
============================== 단계 ==============================
[ chatbot ]
dict_keys(['messages', 'dummy_data'])
메시지 개수: 1
============================== 단계 ==============================
6.1.3 Token-level Streaming
노드 내부의 LLM이 생성하는 단어(토큰) 하나하나를 실시간으로 출력합니다. 우리가 Chat-GPT에서 보는 효과입니다.
question = "2025년 노벨 문학상 관련 뉴스를 알려주세요."
input = State(dummy_data="테스트 문자열", messages=[("user", question)])
config = RunnableConfig(
recursion_limit=10,
configurable={"thread_id": "1"},
tags=["my-tag"],
)
async for event in graph.astream_events(input, version="v2"):
kind = event["event"]
if kind == "on_chat_model_stream":
content = event["data"]["chunk"].content
if content:
print(content, end="|", flush=True)
| 각 토큰 뒤에 “ | “이 출력되도록 했습니다. 직접 실행을 해보면 토큰 하나 하나 출력되는 것을 확인할 수 있으며 모두 출력되면 아래 결과와 같이 각 토큰 뒤에 “ | “이 같이 출력된 결과를 볼 수 있습니다. |
Output:
202|5|년| 노|벨| 문|학|상|에| 관한| 주요| 뉴스|는| 다음|과| 같습니다|:
|1|.| **|헝|가|리| 작|가| 크|러스|너|호|르|커|이| 라|슬|로| 수|상|**|:| 크|러스|너|호|르|커|이| 라|슬|로|가| |202|5|년| 노|벨| 문|학|상을| 수|상|했습니다|.| [|뉴스|1|](|https|://|news|.google|.com|/rss|/articles|/|CB|Mi|W|k|FV|X|3|lx|TE|5|l|Y|ml|IQ|T|VO|Z|y|1|z|U|j|Z|r|N|0|t|Nb|V|d|PQ|j|J|1|MW|5|t|WU|hr|Uk|V|KV|j|RQ|TV|Q|3|em|tt|Rl|Y|4|T|1|gt|b|V|83|Q|y|1|ST|G|g|5|e|HY|0|d|Ux|6|c|DF|QM|2|F|OV|m|9|p|VG|x|X|Q|3|A|5|a|Gc|5|LV|Y|3|QQ|?|oc|=|5|)
|2|.| **|올|해| 노|벨| 문|학|상| 연|설|**|:| 문|학|이나| 소|설|에| 대한| 언|급| 없이| "|반|란|"|을| 꾀|한| 올해|의| 노|벨| 문|학|상| 연|설|이| 있|었습니다|.| [|한|겨|레|](|https|://|news|.google|.com|/rss|/articles|/|CB|Mi|Y|0|FV|X|3|lx|TE|1|QQ|0|RX|R|2|Z|ya|Gt|se|T|Q|4|U|j|J|4|Q|lg|3|N|El|p|Z|3|V|3|RT|M|3|c|3|Z|5|Q|z|ht|Zj|R|Z|b|TJ|m|M|054|OE|1|UM|V|9|n|R|21|Rc|G|ti|WG|Vi|X|z|M|4|MW|V|OV|29|Bd|E|J|x|LW|d|BV|1|VV|WT|gte|Dd|Y|d|0|x|Q|bl|FH|dm|1|x|Zw|?|oc|=|5|)
|3|.| **|문|학|계|와| 영화|광|들|**|:| |202|5|년| 노|벨| 문|학|상이| 문|학|계|보다| 영화|광|들| 사이|에서| 더| 많은| 환|호|를| 받|았|다는| 이야|기가| 있습니다|.| [|뉴스|와|이어|](|https|://|news|.google|.com|/rss|/articles|/|CB|Mi|X|0|FV|X|3|lx|TE|1|B|dk|Rm|W|kl|TW|l|I|0|MW|N|ub|1|N|Pa|Ux|ud|0|J|HR|j|V|h|W|l|BC|Y|zd|2|Y|1|RX|U|0|l|W|bk|9|f|Y|V|Z|SW|FF|Y|OS|1|GN|W|pv|Zj|ll|X|3|d|NX|3|dua|V|h|C|ck|d|J|dll|q|UE|t|U|Q|VN|ub|1|Za|OW|1|CO|Ug|0|OD|dj|?|oc|=|5|)
|4|.| **|크|러스|너|호|르|커|이|의| 문|학|적| 업|적|**|:| 헝|가|리| 작|가| 크|러스|너|호|르|커|이가| "|묵|시|록| 문|학|의| 거|장|"|으로| 평가|받|고| 있습니다|.| [|조|선|일보|](|https|://|news|.google|.com|/rss|/articles|/|CB|Mil|AF|B|VV|95|c|Ux|OM|m|5|p|N|0|py|Sz|N|1|T|0|da|Nk|ty|ej|R|xb|k|96|ak|F|EM|3|F|5|b|2|h|XN|3|h|TX|01|GT|n|RT|TV|FW|cm|Z|4|RW|04|b|E|45|M|3|Bs|N|FR|Mam|5|j|Vk|NI|b|GF|UW|V|d|X|RG|5|BM|H|had|E|1|MU|ER|GN|Fc|5|OW|t|4|RV|lx|US|1|p|W|VU|0|OE|JWT|3|dw|Z|2|RY|cz|Bs|Nz|ls|bl|N|LR|V|Fp|Q|1|B|2|b|2|R|ae|Fg|1|NT|RE|LU|dw|Y|V|9|NZ|j|I|0|M|1|N|f|0|g|Go|AU|FV|X|3|lx|TE|5|a|VW|FO|YX|lf|SG|Y|t|N|2|hr|UE|h|U|OH|p|L|ck|Nk|Uz|dx|W|DI|4|Y|0|Y|yc|W|FX|UX|NL|TX|V|OND|J|kd|FFD|bl|N|n|Z|mt|BZ|k|4|x|NU|t|SQ|09|D|dk|Ju|NT|dr|d|G|0|yd|z|NR|a|E|1|W|c|TRL|TX|l|HY|2|Z|QM|k|42|MU|h|RM|0|J|f|Z|3|Nu|T|j|RQ|b|W|sy|QU|ls|Y|k|01|Tm|Fp|VT|d|0|Z|Wh|HN|0|Vy|NG|F|ne|UJ|l|aj|Rp|TG|t|3|RW|l|OW|jl|Tb|DR|Sb|Hl|za|1|F|DT|FF|N|ZX|Na|ND|N|JU|W|Vm|Sw|?|oc|=|5|)
|더| 자세|한| 내용을| 원|하|시면| 각| 링크|를| 클릭|하여| 확인|하|실| 수| 있습니다|.|
6.1.4 interuupt_before와 interrupt_after 옵션
interuupt_before와 interuupt_after 옵션은 스트리밍 중단 시점을 지정하는 데 사용됩니다.
이 옵션들이 중요한 이유는 단순한 챗봇은 입력하면 결과가 나올 때까지 쭉 실행되지만, 실제 업무용 에이전트는 그렇지 않습니다.
- 인적 승인(Human-in-the-loop): 결제를 진행하거나, 중요 이메일을 발송하기 전, 반드시 사람의 확인을 받아야 합니다.
- 안전 장치: AI가 위험한 도구(DB 삭제 등)을 실행하기 직전에 멈춰 세워야 합니다.
- 협업: AI가 초안을 작성하면 사람이 수정하고, 수정한 상태에서 다시 AI가 작업을 이어가야 합니다.
interrupt 옵션은 바로 이런 일시정지와 개입을 가능하게 합니다.
interrupt_before: 지정된 노드 이전에 스트리밍 중단interrupt_after: 지정된 노드 이후에 스트리밍 중단
7. 중간단계 개입 되돌림을 통한 상태 수정과 Replay
7.1 중간 단계의 상태(State) 수동 업데이트
LangGraph는 중간 단계의 상태를 수동으로 업데이트 할 수 있는 방안을 제공하고 있습니다. 상태를 업데이트하면 에이전트의 행동을 수정하여 경로를 제어할 수 있으며, 심지어 과거를 수정할 수도 있습니다. 이 기능은 에이전트의 실수를 수정 하거나, 대체 경로를 탐색하거나, 특정 목표에 따라 에이전트의 동작을 변경할 때 특히 유용합니다.
이번 예제도 이전에 사용했던 동일한 그래프를 사용합니다.
from typing import Annotated
from typing_extensions import TypedDict
from langchain_teddynote.tools.tavily import TavilySearch
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_teddynote.graphs import visualize_graph
########## 1. 상태 정의 ##########
# 상태 정의
class State(TypedDict):
# 메시지 목록 주석 추가
messages: Annotated[list, add_messages]
########## 2. 도구 정의 및 바인딩 ##########
# 도구 초기화
tool = TavilySearch(max_results=3)
# 도구 목록 정의
tools = [tool]
# LLM 초기화
llm = ChatOpenAI(model="gpt-4o-mini")
# 도구와 LLM 결합
llm_with_tools = llm.bind_tools(tools)
########## 3. 노드 추가 ##########
# 챗봇 함수 정의
def chatbot(state: State):
# 메시지 호출 및 반환
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 상태 그래프 생성
graph_builder = StateGraph(State)
# 챗봇 노드 추가
graph_builder.add_node("chatbot", chatbot)
# 도구 노드 생성 및 추가
tool_node = ToolNode(tools=tools)
# 도구 노드 추가
graph_builder.add_node("tools", tool_node)
# 조건부 엣지
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
########## 4. 엣지 추가 ##########
# tools > chatbot
graph_builder.add_edge("tools", "chatbot")
# START > chatbot
graph_builder.add_edge(START, "chatbot")
# chatbot > END
graph_builder.add_edge("chatbot", END)
########## 5. 그래프 컴파일 ##########
# 메모리 저장소 초기화
memory = MemorySaver()
# 그래프 빌더 컴파일
graph = graph_builder.compile(checkpointer=memory)
from langchain_core.runnables import RunnableConfig
question = "LangGraph가 무엇인지 조사하여 알려주세요!"
# 초기 입력 상태를 정의
input = State(messages=[("user", question)])
# config 설정
config = RunnableConfig(
configurable={"thread_id": "1"}, # 스레드 ID 설정
)
채널 목록을 출력하여 interrupt_before와 interrupt_after를 적용할 수 있는 목록을 출력합니다.
# 그래프 채널 목록 출력
list(graph.channels)
Output:
['messages',
'__start__',
'__pregel_tasks',
'branch:to:chatbot',
'branch:to:tools']
이제 여기서 “tools” 노드 전에 멈추도록 interrupt_before 값에 “tools”를 넣어주도록 하겠습니다.
# 그래프 스트림 호출
events = graph.stream(
input=input,
config=config,
interrupt_before=["tools"],
stream_mode="values"
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
Output:
================================ Human Message =================================
LangGraph가 무엇인지 조사하여 알려주세요!
================================== Ai Message ==================================
Tool Calls:
tavily_web_search (call_B0nxGSYnBcp991t3VpISa9cX)
Call ID: call_B0nxGSYnBcp991t3VpISa9cX
Args:
query: LangGraph
현재 단계는 ToolNode에 의해 중단되었습니다. 가장 최근 메시지를 확인하면 ToolNode가 검색을 수행하기 전 query를 포함하고 있음을 알 수 있습니다.
여기서는 query가 단순하게 LangGraph라는 단어만을 포함하고 있습니다. 당연하게도 웹 검색 결과가 우리가 원하는 결과와 다를 수 있습니다.
# 그래프 상태 스냅샷 생성
snapshot = graph.get_state(config)
# 가장 최근 메시지 추출
last_message = snapshot.values["messages"][-1]
# 메시지 출력
last_message.pretty_print()
Output:
================================== Ai Message ==================================
Tool Calls:
tavily_web_search (call_B0nxGSYnBcp991t3VpISa9cX)
Call ID: call_B0nxGSYnBcp991t3VpISa9cX
Args:
query: LangGraph
7.2 사람의 개입(Human-in-the-loop)
만약, 사람이 중간에 개입하여 웹 검색 도구인 Tavily Tool의 검색 결과인 ToolMessage를 수정하여 LLM에게 전달하고 싶다면 어떻게 해야 할까요?
아래는 원래의 웹 검색 결과와는 조금 다른 수정한 가상의 웹 검색 결과를 만들어 보았습니다.
modified_search_result = """[수정된 웹 검색 결과]
LangGraph는 상태 기반의 다중 액터 애플리케이션을 LLM을 활용해 구축할 수 있도록 지원합니다.
LangGraph는 사이클 흐름, 제어 가능성, 지속성, 클라우드 배포 기능을 제공하는 오픈 소스 라이브러리입니다.
자세한 튜토리얼은 [LangGraph 튜토리얼](https://langchain-ai.github.io/langgraph/tutorials/) 과
테디노트의 [랭체인 한국어 튜토리얼](https://wikidocs.net/233785) 을 참고하세요."""
다음으로 수정한 검색 결과를 ToolMessage에 주입합니다. 여기서 메시지를 수정하려면 수정하고자 하는 Message와 일치하는 tool_call_id를 지정해야 합니다.
# 수정하고자 하는 'ToolMessage'의 'tool_call_id' 추출
tool_call_id = last_message.tool_calls[0]["id"]
print(tool_call_id)
Output:
call_B0nxGSYnBcp991t3VpISa9cX
from langchain_core.messages import AIMessage, ToolMessage
new_messages = [
# LLM API 도구 호출과 일치하는 ToolMessage 필요
ToolMessage(
content = modified_search_result,
tool_call_id=tool_call_id,
),
]
new_messages[-1].pretty_print()
Output:
================================= Tool Message =================================
[수정된 웹 검색 결과]
LangGraph는 상태 기반의 다중 액터 애플리케이션을 LLM을 활용해 구축할 수 있도록 지원합니다.
LangGraph는 사이클 흐름, 제어 가능성, 지속성, 클라우드 배포 기능을 제공하는 오픈 소스 라이브러리입니다.
자세한 튜토리얼은 [LangGraph 튜토리얼](https://langchain-ai.github.io/langgraph/tutorials/) 과
테디노트의 [랭체인 한국어 튜토리얼](https://wikidocs.net/233785) 을 참고하세요.
7.2.1 StateGraph의 update_state 메서드
update_state 메서드는 주어진 값으로 그래프의 상태를 업데이트합니다. 이 메서드는 마치 as_node에서 값이 온 것처럼 동작합니다.
매개변수는 다음과 같습니다.
config(RunnableConfig): 실행 구성values(Optional[Union[dict[str, Any], Any]]): 업데이트할 값들as_node(Optional[str]): 값의 출처로 간주할 노드 이름 기본 값은 None
반환값
- RunnableConfig
주요 기능
- 체크포인터를 통해 이전 상태를 로드하고 새로운 상태를 저장합니다.
- 서브그래프에 대한 상태 업데이트를 처리합니다.
as_node가 지정되지 않은 경우, 마지막으로 상태를 업데이트한 노드를 찾습니다.- 지정된 노드의 writer들을 실행하여 상태를 업데이트합니다.
- 업데이트된 상태를 체크포인트에 저장합니다.
주요 로직
- 체크포인터를 확인하고, 없으면 ValueError를 발생시킵니다.
- 서브그래프에 대한 업데이트인 경우, 해당 서브그래프의
update_state메서드를 호출합니다. - 이전 체크포인트를 로드하고, 필요한 경우
as_node를 결정합니다. - 지정된 노드의 writer들을 사용하여 상태를 업데이트합니다.
- 업데이트된 상태를 새로운 체크포인트로 저장합니다.
update_state 메서드 참고 사항
- 이 메서드는 그래프의 상태를 수동으로 업데이트 할 때 사용됩니다.
- 체크포인터를 사용하여 상태의 버전 관리와 지속성을 보장합니다.
as_node를 지정하지 않으면 자동으로 결정되지만, 모호한 경우 오류가 발생할 수 있습니다.- 상태 업데이트 중 SharedValues에 쓰기 작업은 허용되지 않습니다.
graph.update_state(
# 업데이트할 상태 지정
config,
# 제공할 업데이트된 값. 'State'의 메시지는 "추가 전용"으로 기존 상태에 추가됨
{"messages": new_messages},
as_node="tools",
)
print("(최근 1개의 메시지 출력)\n")
print(graph.get_state(config).values["messages"][-1])
Output:
(최근 1개의 메시지 출력)
content='[수정된 웹 검색 결과] \nLangGraph는 상태 기반의 다중 액터 애플리케이션을 LLM을 활용해 구축할 수 있도록 지원합니다.\nLangGraph는 사이클 흐름, 제어 가능성, 지속성, 클라우드 배포 기능을 제공하는 오픈 소스 라이브러리입니다.\n\n자세한 튜토리얼은 [LangGraph 튜토리얼](https://langchain-ai.github.io/langgraph/tutorials/) 과\n테디노트의 [랭체인 한국어 튜토리얼](https://wikidocs.net/233785) 을 참고하세요.' id='c8604646-cd73-40d8-8e98-2ebaf85fd5d5' tool_call_id='call_B0nxGSYnBcp991t3VpISa9cX'
최종 응답 메시지를 제공했기 때문에 그래프가 완성되었습니다. 상태 업데이트는 그래프 단계를 시뮬레이션하므로, 해당하는 traces도 생성합니다.
messages를 사전 정의된 add_messages 함수로 Annotated 처리했습니다. (이는 그래프에 기존 목록을 직접 덮어쓰지 않고 항상 값을 추가합니다.)
동일한 논리가 여기에도 적용되어, update_state에 전달된 메시지가 동일한 방식으로 메시지가 추가되게 됩니다.
update_state 함수는 마치 그래프의 노드 중 하나인 것처럼 작동합니다. 기본적으로 업데이트 작업은 마지막으로 실행된 노드를 사용하지만, 아래에서 수동으로 지정할 수 있습니다. 업데이트를 추가하고 그래프에 “chatbot”에서 온 것처럼 처리하도록 지시해 보도록 하겠습니다.
snapshot = graph.get_state(config)
events = graph.stream(None, config, stream_mode="values")
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
Output:
================================= Tool Message =================================
[수정된 웹 검색 결과]
LangGraph는 상태 기반의 다중 액터 애플리케이션을 LLM을 활용해 구축할 수 있도록 지원합니다.
LangGraph는 사이클 흐름, 제어 가능성, 지속성, 클라우드 배포 기능을 제공하는 오픈 소스 라이브러리입니다.
자세한 튜토리얼은 [LangGraph 튜토리얼](https://langchain-ai.github.io/langgraph/tutorials/) 과
테디노트의 [랭체인 한국어 튜토리얼](https://wikidocs.net/233785) 을 참고하세요.
================================== Ai Message ==================================
LangGraph는 상태 기반의 다중 액터 애플리케이션을 대규모 언어 모델(LLM)을 활용하여 구축할 수 있도록 지원하는 오픈 소스 라이브러리입니다. 이 라이브러리는 사이클 흐름, 제어 가능성, 지속성 및 클라우드 배포 기능 등을 제공합니다.
자세한 튜토리얼은 [LangGraph 튜토리얼](https://langchain-ai.github.io/langgraph/tutorials/)과 [랭체인 한국어 튜토리얼](https://wikidocs.net/233785)을 참고하실 수 있습니다.
현재 상태를 이전과 같이 점검하여 체크포인트가 수동 업데이트를 반영하는지 확인합니다.
# 그래프 상태 스냅샷 생성
snapshot = graph.get_state(config)
# 최근 세 개의 메시지 출력
for message in snapshot.values["messages"]:
message.pretty_print()
Output:
================================ Human Message =================================
LangGraph가 무엇인지 조사하여 알려주세요!
================================== Ai Message ==================================
Tool Calls:
tavily_web_search (call_B0nxGSYnBcp991t3VpISa9cX)
Call ID: call_B0nxGSYnBcp991t3VpISa9cX
Args:
query: LangGraph
================================= Tool Message =================================
[수정된 웹 검색 결과]
LangGraph는 상태 기반의 다중 액터 애플리케이션을 LLM을 활용해 구축할 수 있도록 지원합니다.
LangGraph는 사이클 흐름, 제어 가능성, 지속성, 클라우드 배포 기능을 제공하는 오픈 소스 라이브러리입니다.
자세한 튜토리얼은 [LangGraph 튜토리얼](https://langchain-ai.github.io/langgraph/tutorials/) 과
테디노트의 [랭체인 한국어 튜토리얼](https://wikidocs.net/233785) 을 참고하세요.
================================== Ai Message ==================================
LangGraph는 상태 기반의 다중 액터 애플리케이션을 대규모 언어 모델(LLM)을 활용하여 구축할 수 있도록 지원하는 오픈 소스 라이브러리입니다. 이 라이브러리는 사이클 흐름, 제어 가능성, 지속성 및 클라우드 배포 기능 등을 제공합니다.
자세한 튜토리얼은 [LangGraph 튜토리얼](https://langchain-ai.github.io/langgraph/tutorials/)과 [랭체인 한국어 튜토리얼](https://wikidocs.net/233785)을 참고하실 수 있습니다.
진행할 다음 노드가 있는지 확인합니다. ()로 비어 있는 것을 확인할 수 있습니다. 즉, 모든 과정이 정상적으로 진행되었음을 알 수 있습니다.
# 다음 상태 출력
print(snapshot.next)
Output:
()
7.3 Interrupt 후 메시지 상태 업데이트 - 이어서 진행
이번에는 다음 노드로 진행하기 전 interrupt를 발생시켜 중단하고, 상태(State)를 갱신한 뒤 이어서 진행하는 방법을 살펴보도록 하겠습니다.
먼저 새로운 thread_id를 생성합니다. 여기서는 랜덤한 해시값을 생성하는 generate_random_hash 함수를 사용합니다.
from langchain_teddynote.graphs import generate_random_hash
thread_id = generate_random_hash()
print(f"thread_id: {thread_id}")
question = "LangGraph에 대해서 배워보고 싶습니다. 유용한 자료를 추천해 주세요!"
# 초기 입력 상태를 정의
input = State(messages=[("user", question)])
# 새로운 config 생성
config = {"configurable": {"thread_id": thread_id}}
events = graph.stream(
input=input,
config=config,
interrupt_before=["tools"],
stream_mode="values",
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
Output:
thread_id: cc0301
================================ Human Message =================================
LangGraph에 대해서 배워보고 싶습니다. 유용한 자료를 추천해 주세요!
================================== Ai Message ==================================
Tool Calls:
tavily_web_search (call_w4tXumRdOYov8FWwxYHXno7t)
Call ID: call_w4tXumRdOYov8FWwxYHXno7t
Args:
query: LangGraph 소개 및 자료
다음으로, 에이전트를 위한 도구 호출을 업데이트해 보겠습니다. 먼저 Message_id를 가져옵니다.
from langchain_core.messages import AIMessage
# config를 복사
config_copy = config.copy()
# 스냅샷 상태 가져오기
snapshot = graph.get_state(config)
# messages의 마지막 메시지 가져오기
existing_message = snapshot.values["messages"][-1]
# 메시지 ID 출력
print("Message ID", existing_message.id)
Output:
Message ID lc_run--019c4b10-0e03-76b2-8e0d-8d34dfa24edf-0
마지막 메시지는 tavily_web_search 도구 호출과 관련된 메시지입니다.
주요 속성은 다음과 같습니다.
name: 도구의 이름args: 검색 쿼리id: 도구 호출 IDtype: 도구 호출 유형(tool_call)
# 첫 번째 도구 호출 출력
print(existing_message.tool_calls[0])
Output:
{'name': 'tavily_web_search', 'args': {'query': 'LangGraph 소개 및 자료'}, 'id': 'call_w4tXumRdOYov8FWwxYHXno7t', 'type': 'tool_call'}
속성 값 중 args의 query를 업데이트 해 보겠습니다. 기존의 existing_message를 복사하여 새로운 도구인 new_tool_call을 생성합니다. copy() 메서드를 사용하여 복사하였기 때문에 모든 속성 값이 복사됩니다.
그런 다음, query 매개변수에 원하는 검색 쿼리를 입력합니다. 여기서 중요한 점은 id는 기존 메시지의 id를 그대로 사용합니다. (id가 달라지면 message 리듀서가 동작하여 메시지를 갱신하지 않고, 추가하게 됩니다.)
# tool_calls를 복사하여 새로운 도구 호출 생성
new_tool_call = existing_message.tool_calls[0].copy()
# 쿼리 매개변수 업데이트(갱신)
new_tool_call["args"] = {"query": "LangGraph site:teddylee777.github.io"}
new_tool_call
Output:
{'name': 'tavily_web_search',
'args': {'query': 'LangGraph site:teddylee777.github.io'},
'id': 'call_w4tXumRdOYov8FWwxYHXno7t',
'type': 'tool_call'}
# AIMessage 생성
new_message = AIMessage(
content=existing_message.content,
tool_calls = [new_tool_call],
# 중요! ID는 메시지를 상태에 추가하는 대신 교체하는 방법
id=existing_message.id,
)
print(new_message.id)
# 수정한 메시지 출력
new_message.pretty_print()
Output:
lc_run--019c4b10-0e03-76b2-8e0d-8d34dfa24edf-0
================================== Ai Message ==================================
Tool Calls:
tavily_web_search (call_w4tXumRdOYov8FWwxYHXno7t)
Call ID: call_w4tXumRdOYov8FWwxYHXno7t
Args:
query: LangGraph site:teddylee777.github.io
검색 쿼리가 갱신된 것을 확인할 수 있습니다.
# 업데이트된 도구 호출 출력
print(new_message.tool_calls[0])
# 메시지 ID 출력
print("\nMessage ID", new_message.id)
# 상태 업데이트
graph.update_state(config, {"messages": [new_message]})
Output:
{'name': 'tavily_web_search', 'args': {'query': 'LangGraph site:teddylee777.github.io'}, 'id': 'call_w4tXumRdOYov8FWwxYHXno7t', 'type': 'tool_call'}
Message ID lc_run--019c4b10-0e03-76b2-8e0d-8d34dfa24edf-0
{'configurable': {'thread_id': 'cc0301',
'checkpoint_ns': '',
'checkpoint_id': '1f10711f-caaa-697a-8002-49e2f66084de'}}
업데이트된 마지막 message의 tool_calls를 확인합니다. args의 query가 수정된 것을 확인할 수 있습니다.
# 마지막 메시지의 도구 호출 가져오기
graph.get_state(config).values["messages"][-1].tool_calls
Output:
[{'name': 'tavily_web_search',
'args': {'query': 'LangGraph site:teddylee777.github.io'},
'id': 'call_w4tXumRdOYov8FWwxYHXno7t',
'type': 'tool_call'}]
기존 설정과 None 입력을 사용하여 그래프 이어서 스트리밍 합니다.
# 그래프 스트림에서 이벤트 수신
events = graph.stream(None, config, stream_mode="values")
# 각 이벤트에 대한 처리
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
Output:
================================== Ai Message ==================================
Tool Calls:
tavily_web_search (call_w4tXumRdOYov8FWwxYHXno7t)
Call ID: call_w4tXumRdOYov8FWwxYHXno7t
Args:
query: LangGraph site:teddylee777.github.io
================================= Tool Message =================================
Name: tavily_web_search
[{"url": "https://teddylee777.github.io/langgraph/langgraph-multi-agent-collaboration/", "title": "LangGraph - Multi-Agent Collaboration(다중 협업 에이전트) 로 ...", "content": "LangGraph - Multi-Agent Collaboration(다중 협업 에이전트) 로 복잡한 테스크를 수행하는 LLM 어플리케이션 제작 · 실습 · 튜토리얼 영상 · 상태", "score": 0.9999553, "raw_content": null}, {"url": "https://teddylee777.github.io/langgraph/langgraph-agentic-rag/", "title": "LangGraph Retrieval Agent를 활용한 동적 문서 검색 및 처리 - 테디노트", "content": "LangGraph Retrieval Agent는 언어 처리, AI 모델 통합, 데이터베이스 관리, 그래프 기반 데이터 처리 등 다양한 기능을 제공하여 언어 기반 AI", "score": 0.9999517, "raw_content": null}, {"url": "https://teddylee777.github.io/", "title": "테디노트", "content": "LangGraph Retrieval Agent는 언어 처리, AI 모델 통합, 데이터베이스 관리, 그래프 기반 데이터 처리 등 다양한 기능을 제공하여 언어 기반 AI 애플리케이션 개발에", "score": 0.9999485, "raw_content": "\n\n### [Teddy](https://teddylee777.github.io/)\n\n💻 Creator & Data Lover\n\n# \n\n### 최근 포스트\n\n## [poetry 의 거의 모든것 (튜토리얼)](/poetry/poetry-tutorial/)\n\n2024년 03월 30일\n\n\n\n5 분 소요\n\nPython 개발에 있어서 poetry는 매우 강력한 도구로, 프로젝트의 의존성 관리와 패키지 배포를 간소화하는 데 큰 도움을 줍니다. 지금부터 poetry 활용 튜토리얼을 살펴 보겠습니다.\n\n## [LangGraph Retrieval Agent를 활용한 동적 문서 검색 및 처리](/langgraph/langgraph-agentic-rag/)\n\n2024년 03월 06일\n\n\n\n10 분 소요\n\nLangGraph Retrieval Agent는 언어 처리, AI 모델 통합, 데이터베이스 관리, 그래프 기반 데이터 처리 등 다양한 기능을 제공하여 언어 기반 AI 애플리케이션 개발에 필수적인 도구입니다.\n\n## [[Assistants API] Code Interpreter, Retrieval, Functions 활용법](/openai/openai-assistant-tutorial/)\n\n2024년 02월 13일\n\n\n\n34 분 소요\n\nOpenAI의 새로운 Assistants API는 대화와 더불어 강력한 도구 접근성을 제공합니다. 본 튜토리얼은 OpenAI Assistants API를 활용하는 내용을 다룹니다. 특히, Assistant API 가 제공하는 도구인 Code Interpreter, Retrieval...\n\n## [[LangChain] 에이전트(Agent)와 도구(tools)를 활용한 지능형 검색 시스템 구축 가이드](/langchain/langchain-agent/)\n\n2024년 02월 09일\n\n\n\n41 분 소요\n\n이 글에서는 LangChain 의 Agent 프레임워크를 활용하여 복잡한 검색과 데이터 처리 작업을 수행하는 방법을 소개합니다. LangSmith 를 사용하여 Agent의 추론 단계를 추적합니다. Agent가 활용할 검색 도구(Tavily Search), PDF 기반 검색 리트리버...\n\n## [LangChain RAG 파헤치기: 문서 기반 QA 시스템 설계 방법 - 심화편](/langchain/rag-tutorial/)\n\n2024년 02월 06일\n\n\n\n22 분 소요\n\nLangChain의 RAG 시스템을 통해 문서(PDF, txt, 웹페이지 등)에 대한 질문-답변을 찾는 과정을 정리하였습니다.\n\n## [LangChain으로 네이버 뉴스 기반 Q&A 애플리케이션 구축하기 - 기본편](/langchain/rag-naver-news-qa/)\n\n2024년 02월 06일\n\n\n\n7 분 소요\n\nLangChain을 활용하여 간단하게 네이버 뉴스기사를 바탕으로 Q&A 애플리케이션을 만드는 방법을 다룹니다.\n\n## [자동화된 메타데이터 태깅으로 문서의 메타데이터(metadata) 생성 및 자동 라벨링](/langchain/metadata-tagger/)\n\n2024년 02월 05일\n\n\n\n9 분 소요\n\n문서 관리를 위한 메타데이터 태깅은 필수적이지만 번거로울 수 있습니다. OpenAI 기반의 자동화된 메타데이터 태깅 방법을 통해 이 과정을 효율적으로 만드는 방법을 알아보도록 하겠습니다.\n\n## [LLMs를 활용한 문서 요약 가이드: Stuff, Map-Reduce, Refine 방법 총정리](/langchain/summarize-chain/)\n\n2024년 02월 04일\n\n\n\n21 분 소요\n\n이번 글은 LangChain 을 활용하여 문서를 요약하는 방법에 대하여 다룹니다. 특히, 문서 요약의 3가지 방식은 Stuff, Map-Reduce, Refine 방식에 대하여 알아보고, 각각의 방식 간의 차이점에 대하여 다룹니다.\n\n## [LangChain Expression Language(LCEL) 원리 이해와 파이프라인 구축 가이드](/langchain/langchain-lcel/)\n\n2024년 02월 03일\n\n\n\n3 분 소요\n\n이 블로그 글에서는 LangChain Expression Language(LCEL) 원리 이해와 LCEL 에 기반한 파이프라인 구축의 기본을 소개합니다.\n\n## [OpenAI API 모델 리스트 / 요금표](/openai/openai-models/)\n\n2024년 02월 02일\n\n\n\n2 분 소요\n\n최신 버전의 업데이트 된 OpenAI Model 리스트와 API 사용요금(Pricing) 입니다."}]
================================== Ai Message ==================================
LangGraph에 대한 유용한 자료를 몇 가지 추천드립니다:
1. **[LangGraph - Multi-Agent Collaboration(다중 협업 에이전트)](https://teddylee777.github.io/langgraph/langgraph-multi-agent-collaboration/)**
이 페이지에서는 LangGraph를 사용하여 복잡한 작업을 수행하는 LLM 애플리케이션을 만들기 위한 튜토리얼 및 실습 자료를 제공합니다.
2. **[LangGraph Retrieval Agent를 활용한 동적 문서 검색 및 처리](https://teddylee777.github.io/langgraph/langgraph-agentic-rag/)**
이 글에서는 LangGraph Retrieval Agent의 다양한 기능, 즉 언어 처리, AI 모델 통합, 데이터베이스 관리 및 그래프 기반 데이터 처리를 소개하고 있습니다.
이 외에도 LangGraph와 관련된 정보를 더 깊이 있게 알고 싶다면 관련 커뮤니티나 포럼에 참여해 보는 것도 좋습니다!
events = graph.stream(
{
"messages": (
"user",
"내가 지금까지 배운 내용에 대해서 매우 친절하고 정성스럽게 한국어로 답변해줘! 출처를 반드시 포함해줘!",
)
},
config,
stream_mode="values",
)
# 메시지 이벤트 처리
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
Output:
================================ Human Message =================================
내가 지금까지 배운 내용에 대해서 매우 친절하고 정성스럽게 한국어로 답변해줘! 출처를 반드시 포함해줘!
================================== Ai Message ==================================
당신이 LangGraph에 대해 배운 내용은 다음과 같습니다:
1. **LangGraph - Multi-Agent Collaboration(다중 협업 에이전트)**: 이 자료에서는 LangGraph를 활용하여 복잡한 작업을 수행할 수 있는 LLM(대규모 언어 모델) 애플리케이션을 만드는 방법을 배울 수 있습니다. 이 과정에는 실습과 튜토리얼 영상이 포함되어 있어, 실제 상황에서 LangGraph를 어떻게 활용할 수 있는지를 익힐 수 있습니다. 자세한 내용은 아래 링크에서 확인할 수 있습니다.
[LangGraph - Multi-Agent Collaboration](https://teddylee777.github.io/langgraph/langgraph-multi-agent-collaboration/)
2. **LangGraph Retrieval Agent**: 이 기능은 동적 문서 검색 및 처리와 관련이 있습니다. LangGraph Retrieval Agent는 언어 처리, AI 모델 통합, 데이터베이스 관리 및 그래프 기반 데이터 처리를 수행하는 데 있어 필수적인 도구로 기능합니다. 이러한 기능들은 언어 기반 AI 애플리케이션 개발에 매우 유용합니다. 관련 내용은 다음 링크에서 확인할 수 있습니다.
[LangGraph Retrieval Agent를 활용한 동적 문서 검색 및 처리](https://teddylee777.github.io/langgraph/langgraph-agentic-rag/)
이 자료들은 LangGraph의 다양한 기능과 활용 방법에 대한 깊이 있는 이해를 돕는 데 매우 유용합니다. LangGraph를 통해 어떻게 다양한 AI 모델 및 데이터 처리 기술을 통합할 수 있는지를 배워보세요!
최종 상태에서 messages의 마지막 메시지를 확인합니다.
graph.get_state(config).values["messages"][-1].pretty_print()
Output:
================================== Ai Message ==================================
당신이 LangGraph에 대해 배운 내용은 다음과 같습니다:
1. **LangGraph - Multi-Agent Collaboration(다중 협업 에이전트)**: 이 자료에서는 LangGraph를 활용하여 복잡한 작업을 수행할 수 있는 LLM(대규모 언어 모델) 애플리케이션을 만드는 방법을 배울 수 있습니다. 이 과정에는 실습과 튜토리얼 영상이 포함되어 있어, 실제 상황에서 LangGraph를 어떻게 활용할 수 있는지를 익힐 수 있습니다. 자세한 내용은 아래 링크에서 확인할 수 있습니다.
[LangGraph - Multi-Agent Collaboration](https://teddylee777.github.io/langgraph/langgraph-multi-agent-collaboration/)
2. **LangGraph Retrieval Agent**: 이 기능은 동적 문서 검색 및 처리와 관련이 있습니다. LangGraph Retrieval Agent는 언어 처리, AI 모델 통합, 데이터베이스 관리 및 그래프 기반 데이터 처리를 수행하는 데 있어 필수적인 도구로 기능합니다. 이러한 기능들은 언어 기반 AI 애플리케이션 개발에 매우 유용합니다. 관련 내용은 다음 링크에서 확인할 수 있습니다.
[LangGraph Retrieval Agent를 활용한 동적 문서 검색 및 처리](https://teddylee777.github.io/langgraph/langgraph-agentic-rag/)
이 자료들은 LangGraph의 다양한 기능과 활용 방법에 대한 깊이 있는 이해를 돕는 데 매우 유용합니다. LangGraph를 통해 어떻게 다양한 AI 모델 및 데이터 처리 기술을 통합할 수 있는지를 배워보세요!
7.4 지난 스냅샷의 결과 수정 및 Replay
이번에는 지난 스냅샷의 결과를 수정하여 Replay 하는 방법을 살펴보겠습니다.
지난 스냅샷을 확인 후 특정 노드로 되돌아가, 상태(State)를 수정한 뒤 해당 노드부터 다시 진행합니다. 이를 Replay라고 합니다. 먼저 지난 스냅샷의 상태를 가져옵니다.
to_replay_state = None
# 상태 기록 가져오기
for state in graph.get_state_history(config):
messages = state.values["messages"]
if len(messages) > 0:
print(state.values["messages"][-1].id)
# 메시지 수 및 다음 상태 출력
print("메시지 수:", len(state.values["messages"]), "다음 노드: ", state.next)
print("-"*80)
if len(state.values["messages"]) == 2:
to_replay_state = state
Output:
lc_run--019c4b61-b727-70e3-96a9-107113b9ce65-0
메시지 수: 6 다음 노드: ()
--------------------------------------------------------------------------------
4e5306f0-cff6-4d63-a359-e4cb8dbc9d00
메시지 수: 5 다음 노드: ('chatbot',)
--------------------------------------------------------------------------------
lc_run--019c4b5f-4f48-7621-80f4-b02ee203e9e6-0
메시지 수: 4 다음 노드: ('__start__',)
--------------------------------------------------------------------------------
lc_run--019c4b5f-4f48-7621-80f4-b02ee203e9e6-0
메시지 수: 4 다음 노드: ()
--------------------------------------------------------------------------------
cd8deb1f-8207-4498-9a9f-33efef8d68ab
메시지 수: 3 다음 노드: ('chatbot',)
--------------------------------------------------------------------------------
lc_run--019c4b10-0e03-76b2-8e0d-8d34dfa24edf-0
메시지 수: 2 다음 노드: ('tools',)
--------------------------------------------------------------------------------
lc_run--019c4b10-0e03-76b2-8e0d-8d34dfa24edf-0
메시지 수: 2 다음 노드: ('tools',)
--------------------------------------------------------------------------------
28d8295b-1ac7-411a-a0a7-6b471ecec504
메시지 수: 1 다음 노드: ('chatbot',)
--------------------------------------------------------------------------------
선택한 메시지의 내용을 확인합니다.
from langchain_teddynote.messages import display_message_tree
# 선택한 메시지 가져오기
existing_message = to_replay_state.values["messages"][-1]
# 메시지 트리 출력
display_message_tree(existing_message)
검색 쿼리를 업데이트 후 반영이 됐는지 확인합니다.
tool_call = existing_message.tool_calls[0].copy()
tool_call["args"] = {"query": "LangGraph human-in-the-loop workflow site:reddit.com"}
tool_call
args 속성의 query를 확인해 보면 변경된 것을 확인할 수 있습니다.
Output:
{'name': 'tavily_web_search',
'args': {'query': 'LangGraph human-in-the-loop workflow site:reddit.com'},
'id': 'call_w4tXumRdOYov8FWwxYHXno7t',
'type': 'tool_call'}
업데이트된 AIMessage를 생성합니다.
# AIMessage 생성
new_message = AIMessage(
content=existing_message.content,
tool_calls=[tool_call],
# 중요! ID는 메시지를 상태에 추가하는 대신 교체하는 방법
id=existing_message.id,
)
# 수정한 메시지 출력
new_message.tool_calls[0]["args"]
Output:
{'query': 'LangGraph human-in-the-loop workflow site:reddit.com'}
아래는 업데이트 되기 전의 메시지입니다.
# 업데이트 전 메시지 확인
graph.get_state(to_replay_state.config).values["messages"][-1].tool_calls
args의 query를 보시면 변경 전 내용인 것을 확인할 수 있습니다.
Output:
[{'name': 'tavily_web_search',
'args': {'query': 'LangGraph 소개 및 자료'},
'id': 'call_w4tXumRdOYov8FWwxYHXno7t',
'type': 'tool_call'}]
graph에 update_state 메서드를 사용하여 상태를 업데이트 합니다. 업데이트된 상태를 update_state에 저장합니다.
# 상태 업데이트
updated_state = graph.update_state(
to_replay_state.config,
{"messages": [new_message]},
)
updated_state
Output:
{'configurable': {'thread_id': 'cc0301',
'checkpoint_ns': '',
'checkpoint_id': '1f107165-e2c7-65ec-8002-11f2db393e2f'}}
이제 업데이트된 상태를 스트리밍 합니다. 여기서 입력은 None으로 주어 Replay 합니다.
# config 에는 updated_state 를 전달합니다. 이는 임의로 갱신한 상태를 전달하는 것입니다.
for event in graph.stream(None, updated_state, stream_mode="values"):
# 메시지가 이벤트에 포함된 경우
if "messages" in event:
# 마지막 메시지 출력
event["messages"][-1].pretty_print()
Output:
================================== Ai Message ==================================
Tool Calls:
tavily_web_search (call_w4tXumRdOYov8FWwxYHXno7t)
Call ID: call_w4tXumRdOYov8FWwxYHXno7t
Args:
query: LangGraph human-in-the-loop workflow site:reddit.com
================================= Tool Message =================================
Name: tavily_web_search
[{"url": "https://www.reddit.com/r/LangChain/comments/1ji4091/langgraph_humanintheloop_review/", "title": "LangGraph: Human-in-the-loop review : r/LangChain - Reddit", "content": "I just created a short demo showing how LangGraph supports human-in-the-loop interactions - both during and after an AI agent runs a task.", "score": 0.7785319, "raw_content": " \n\n \n \n \n\n[Go to LangChain](/r/LangChain/) \n\n[r/LangChain](/r/LangChain/) • \n\n[piotrekgrl](/user/piotrekgrl/)\n\n# LangGraph: Human-in-the-loop review\n\nSorry, something went wrong when loading this video.\n\n [View in app](https://reddit.app.link/?%24android_deeplink_path=reddit%2Fr%2FLangChain%2Fcomments%2F1ji4091%2Flanggraph_humanintheloop_review%2F&%24deeplink_path=%2Fr%2FLangChain%2Fcomments%2F1ji4091%2Flanggraph_humanintheloop_review%2F&%24og_redirect=https%3A%2F%2Fwww.reddit.com%2Fr%2FLangChain%2Fcomments%2F1ji4091%2Flanggraph_humanintheloop_review%2F&base_url=%2Fr%2FLangChain%2Fcomments%2F1ji4091%2Flanggraph_humanintheloop_review%2F&mweb_loid=t2_281enk4bh1&mweb_loid_created=1770792857063&referrer_domain=www.reddit.com&referrer_url=%2F&campaign=no_amp_test&utm_name=no_amp_test&channel=xpromo&utm_source=xpromo&feature=web3x&utm_medium=web3x&keyword=no_amp&utm_term=no_amp&tags=media_error_xpromo_post&utm_content=media_error)\n\nHey everone,\n\nI just created a short demo showing how LangGraph supports human-in-the-loop interactions - both *during* and *after* an AI agent runs a task.\n\nDuring task execution I tried `multitask_strategy` from LangGraph Server API:\n\n* **Interrupt** – Stop & re-run the task with a new prompt, keeping context.\n* **Enqueue** – Add a follow-up task to explore another direction.\n* **Rollback** – Scrap the task & start clean.\n* **Reject** – Prevent any task interruption - backen config\n\nAfter the task ends, I used `interrupt` with structured modes introduced in `HumanResponse` from LangGraph 0.3:\n\n* **Edit**, **respond**, **accept**, or **ignore** the output.\n\nMore details in the [post](https://www.linkedin.com/posts/piotrgoral_as-ai-agents-gain-access-to-powerfuldangerous-activity-7309404531535048705-a5nw?utm_source=share&utm_medium=member_desktop&rcm=ACoAABd6FscBh9RwzOtYQcJFPbfX_lNmQ7Pccjs).\n\nAgent code: <https://github.com/piotrgoral/open_deep_research-human-in-the-loop> \nReact.js App code: <https://github.com/piotrgoral/agent-chat-ui-human-in-the-loop>\n\n \n\n## Top Posts\n\n---\n\n* [reReddit: Top posts of March 23, 2025\n\n ---](https://www.reddit.com/posts/2025/march-23-1/global/)\n* [Reddit\n\n reReddit: Top posts of March 2025\n\n ---](https://www.reddit.com/posts/2025/march/global/)\n* [Reddit\n\n reReddit: Top posts of 2025\n\n ---](https://www.reddit.com/posts/2025/global/)\n\n[Reddit Rules](https://www.redditinc.com/policies/content-policy) [Privacy Policy](https://www.reddit.com/policies/privacy-policy) [User Agreement](https://www.redditinc.com/policies/user-agreement) [Your Privacy Choices](https://support.reddithelp.com/hc/articles/43980704794004) [Accessibility](https://support.reddithelp.com/hc/sections/38303584022676-Accessibility) [Reddit, Inc. © 2026. All rights reserved.](https://redditinc.com)\n\n "}, {"url": "https://www.reddit.com/r/LangChain/comments/1bjnmu4/human_intervention_in_agent_workflows/", "title": "Human intervention in agent workflows : r/LangChain - Reddit", "content": "I know there is a Human-in-the-loop component in LangGraph that will prompt the user for input. But what if I'm not creating a user-initiated", "score": 0.767429, "raw_content": " \n\n \n \n \n\n[Go to LangChain](/r/LangChain/) \n\n[r/LangChain](/r/LangChain/) • \n\n[tisi3000](/user/tisi3000/)\n\n# Human intervention in agent workflows\n\nWhen building LLM workflows with LangChain/LangGraph what's the best way to build a node in the workflow **where a human can validate/approve/reject** a flow? I know there is a Human-in-the-loop component in LangGraph that will prompt the user for input. But what if I'm not creating a user-initiated chat conversation, but a flow that reacts to e.g. incoming emails?\n\nI guess I'd have to design my UI so that it's not only a simple single-threaded chat interface, but some sort of inbox, right? Or is there any standard way that comes to mind?\n\n \n\n## Top Posts\n\n---\n\n* [reReddit: Top posts of March 20, 2024\n\n ---](https://www.reddit.com/posts/2024/march-20-1/global/)\n* [Reddit\n\n reReddit: Top posts of March 2024\n\n ---](https://www.reddit.com/posts/2024/march/global/)\n* [Reddit\n\n reReddit: Top posts of 2024\n\n ---](https://www.reddit.com/posts/2024/global/)\n\n[Reddit Rules](https://www.redditinc.com/policies/content-policy) [Privacy Policy](https://www.reddit.com/policies/privacy-policy) [User Agreement](https://www.redditinc.com/policies/user-agreement) [Accessibility](https://support.reddithelp.com/hc/sections/38303584022676-Accessibility) [Reddit, Inc. © 2026. All rights reserved.](https://redditinc.com)\n\n "}, {"url": "https://www.reddit.com/r/LangGraph/comments/1ldiqtg/i_am_struggling_with_langgraphs_humanintheloop/", "title": "I am Struggling with LangGraph's Human-in-the-Loop ... - Reddit", "content": "I'm building an agent that needs to pause for human approval before executing sensitive actions (like sending emails or making API calls).", "score": 0.7500592, "raw_content": " \n\n \n \n \n\n[Go to LangGraph](/r/LangGraph/) \n\n[r/LangGraph](/r/LangGraph/) • \n\n[techblooded](/user/techblooded/)\n\n# I am Struggling with LangGraph’s Human-in-the-Loop. Anyone Managed Reliable Approval Workflows?\n\nI’m building an agent that needs to pause for human approval before executing sensitive actions (like sending emails or making API calls). I’ve tried using LangGraph’s interrupt() and the HIL patterns, but I keep running into issues:\n\n-The graph sometimes resumes from the wrong point \n-State updates after resuming are inconsistent. \n-The API for handling interruptions is confusing and poorly documented\n\nHas anyone here managed to get a robust, production-ready HIL workflow with LangGraph? Any best practices or workarounds for these pain points? Would love to see code snippets or architecture diagrams if you’re willing to share!\n\n \n\n## Top Posts\n\n---\n\n* [reReddit: Top posts of June 17, 2025\n\n ---](https://www.reddit.com/posts/2025/june-17-1/global/)\n* [Reddit\n\n reReddit: Top posts of June 2025\n\n ---](https://www.reddit.com/posts/2025/june/global/)\n* [Reddit\n\n reReddit: Top posts of 2025\n\n ---](https://www.reddit.com/posts/2025/global/)\n\n[Reddit Rules](https://www.redditinc.com/policies/content-policy) [Privacy Policy](https://www.reddit.com/policies/privacy-policy) [User Agreement](https://www.redditinc.com/policies/user-agreement) [Your Privacy Choices](https://support.reddithelp.com/hc/articles/43980704794004) [Accessibility](https://support.reddithelp.com/hc/sections/38303584022676-Accessibility) [Reddit, Inc. © 2026. All rights reserved.](https://redditinc.com)\n\n "}]
================================== Ai Message ==================================
LangGraph에 대한 자료는 주로 Reddit에서 활발히 논의되고 있습니다. 아래는 LangGraph의 인간 참여(Human-in-the-loop) 기능에 관한 유용한 링크들입니다:
1. **[LangGraph: Human-in-the-loop review](https://www.reddit.com/r/LangChain/comments/1ji4091/langgraph_humanintheloop_review/)** - 이 글에서는 LangGraph가 어떻게 인간 참여 상호작용을 지원하는지에 대한 짧은 데모를 보여주며, 다양한 작업 중에 사용자가 개입할 수 있는 방법들을 설명합니다.
2. **[Human intervention in agent workflows](https://www.reddit.com/r/LangChain/comments/1bjnmu4/human_intervention_in_agent_workflows/)** - 이 글은 LLM 워크플로우 내에서 인간이 검증, 승인, 거부할 수 있는 노드 작성에 대해 논의하며, 사용자 주도 대화가 아닌 흐름을 어떻게 설계할 수 있는지에 대해 고민하고 있습니다.
3. **[I am Struggling with LangGraph's Human-in-the-Loop ...](https://www.reddit.com/r/LangGraph/comments/1ldiqtg/i_am_struggling_with_langgraphs_humanintheloop/)** - 사용자들이 LangGraph의 인간 참여 기능을 설정하는 데 경험하는 문제들에 대해 논의하고, 보다 견고한 승인을 위한 워크플로우를 구축하는 방법에 대한 정보와 팁을 공유하는 곳입니다.
이 자료들을 통해 LangGraph의 주요 기능과 활용법에 대해 깊이 이해할 수 있을 것입니다.
최종 결과를 출력해 봅니다. 이때 사용하는 config는 최종 상태를 가져오는 것이 아니라, 최종 상태를 가져오기 위한 초기 config입니다.
# 최종 결과 출력
for msg in graph.get_state(config).values["messages"]:
msg.pretty_print()
Output:
================================ Human Message =================================
LangGraph에 대해서 배워보고 싶습니다. 유용한 자료를 추천해 주세요!
================================== Ai Message ==================================
Tool Calls:
tavily_web_search (call_w4tXumRdOYov8FWwxYHXno7t)
Call ID: call_w4tXumRdOYov8FWwxYHXno7t
Args:
query: LangGraph human-in-the-loop workflow site:reddit.com
================================= Tool Message =================================
Name: tavily_web_search
[{"url": "https://www.reddit.com/r/LangChain/comments/1ji4091/langgraph_humanintheloop_review/", "title": "LangGraph: Human-in-the-loop review : r/LangChain - Reddit", "content": "I just created a short demo showing how LangGraph supports human-in-the-loop interactions - both during and after an AI agent runs a task.", "score": 0.7785319, "raw_content": " \n\n \n \n \n\n[Go to LangChain](/r/LangChain/) \n\n[r/LangChain](/r/LangChain/) • \n\n[piotrekgrl](/user/piotrekgrl/)\n\n# LangGraph: Human-in-the-loop review\n\nSorry, something went wrong when loading this video.\n\n [View in app](https://reddit.app.link/?%24android_deeplink_path=reddit%2Fr%2FLangChain%2Fcomments%2F1ji4091%2Flanggraph_humanintheloop_review%2F&%24deeplink_path=%2Fr%2FLangChain%2Fcomments%2F1ji4091%2Flanggraph_humanintheloop_review%2F&%24og_redirect=https%3A%2F%2Fwww.reddit.com%2Fr%2FLangChain%2Fcomments%2F1ji4091%2Flanggraph_humanintheloop_review%2F&base_url=%2Fr%2FLangChain%2Fcomments%2F1ji4091%2Flanggraph_humanintheloop_review%2F&mweb_loid=t2_281enk4bh1&mweb_loid_created=1770792857063&referrer_domain=www.reddit.com&referrer_url=%2F&campaign=no_amp_test&utm_name=no_amp_test&channel=xpromo&utm_source=xpromo&feature=web3x&utm_medium=web3x&keyword=no_amp&utm_term=no_amp&tags=media_error_xpromo_post&utm_content=media_error)\n\nHey everone,\n\nI just created a short demo showing how LangGraph supports human-in-the-loop interactions - both *during* and *after* an AI agent runs a task.\n\nDuring task execution I tried `multitask_strategy` from LangGraph Server API:\n\n* **Interrupt** – Stop & re-run the task with a new prompt, keeping context.\n* **Enqueue** – Add a follow-up task to explore another direction.\n* **Rollback** – Scrap the task & start clean.\n* **Reject** – Prevent any task interruption - backen config\n\nAfter the task ends, I used `interrupt` with structured modes introduced in `HumanResponse` from LangGraph 0.3:\n\n* **Edit**, **respond**, **accept**, or **ignore** the output.\n\nMore details in the [post](https://www.linkedin.com/posts/piotrgoral_as-ai-agents-gain-access-to-powerfuldangerous-activity-7309404531535048705-a5nw?utm_source=share&utm_medium=member_desktop&rcm=ACoAABd6FscBh9RwzOtYQcJFPbfX_lNmQ7Pccjs).\n\nAgent code: <https://github.com/piotrgoral/open_deep_research-human-in-the-loop> \nReact.js App code: <https://github.com/piotrgoral/agent-chat-ui-human-in-the-loop>\n\n \n\n## Top Posts\n\n---\n\n* [reReddit: Top posts of March 23, 2025\n\n ---](https://www.reddit.com/posts/2025/march-23-1/global/)\n* [Reddit\n\n reReddit: Top posts of March 2025\n\n ---](https://www.reddit.com/posts/2025/march/global/)\n* [Reddit\n\n reReddit: Top posts of 2025\n\n ---](https://www.reddit.com/posts/2025/global/)\n\n[Reddit Rules](https://www.redditinc.com/policies/content-policy) [Privacy Policy](https://www.reddit.com/policies/privacy-policy) [User Agreement](https://www.redditinc.com/policies/user-agreement) [Your Privacy Choices](https://support.reddithelp.com/hc/articles/43980704794004) [Accessibility](https://support.reddithelp.com/hc/sections/38303584022676-Accessibility) [Reddit, Inc. © 2026. All rights reserved.](https://redditinc.com)\n\n "}, {"url": "https://www.reddit.com/r/LangChain/comments/1bjnmu4/human_intervention_in_agent_workflows/", "title": "Human intervention in agent workflows : r/LangChain - Reddit", "content": "I know there is a Human-in-the-loop component in LangGraph that will prompt the user for input. But what if I'm not creating a user-initiated", "score": 0.767429, "raw_content": " \n\n \n \n \n\n[Go to LangChain](/r/LangChain/) \n\n[r/LangChain](/r/LangChain/) • \n\n[tisi3000](/user/tisi3000/)\n\n# Human intervention in agent workflows\n\nWhen building LLM workflows with LangChain/LangGraph what's the best way to build a node in the workflow **where a human can validate/approve/reject** a flow? I know there is a Human-in-the-loop component in LangGraph that will prompt the user for input. But what if I'm not creating a user-initiated chat conversation, but a flow that reacts to e.g. incoming emails?\n\nI guess I'd have to design my UI so that it's not only a simple single-threaded chat interface, but some sort of inbox, right? Or is there any standard way that comes to mind?\n\n \n\n## Top Posts\n\n---\n\n* [reReddit: Top posts of March 20, 2024\n\n ---](https://www.reddit.com/posts/2024/march-20-1/global/)\n* [Reddit\n\n reReddit: Top posts of March 2024\n\n ---](https://www.reddit.com/posts/2024/march/global/)\n* [Reddit\n\n reReddit: Top posts of 2024\n\n ---](https://www.reddit.com/posts/2024/global/)\n\n[Reddit Rules](https://www.redditinc.com/policies/content-policy) [Privacy Policy](https://www.reddit.com/policies/privacy-policy) [User Agreement](https://www.redditinc.com/policies/user-agreement) [Accessibility](https://support.reddithelp.com/hc/sections/38303584022676-Accessibility) [Reddit, Inc. © 2026. All rights reserved.](https://redditinc.com)\n\n "}, {"url": "https://www.reddit.com/r/LangGraph/comments/1ldiqtg/i_am_struggling_with_langgraphs_humanintheloop/", "title": "I am Struggling with LangGraph's Human-in-the-Loop ... - Reddit", "content": "I'm building an agent that needs to pause for human approval before executing sensitive actions (like sending emails or making API calls).", "score": 0.7500592, "raw_content": " \n\n \n \n \n\n[Go to LangGraph](/r/LangGraph/) \n\n[r/LangGraph](/r/LangGraph/) • \n\n[techblooded](/user/techblooded/)\n\n# I am Struggling with LangGraph’s Human-in-the-Loop. Anyone Managed Reliable Approval Workflows?\n\nI’m building an agent that needs to pause for human approval before executing sensitive actions (like sending emails or making API calls). I’ve tried using LangGraph’s interrupt() and the HIL patterns, but I keep running into issues:\n\n-The graph sometimes resumes from the wrong point \n-State updates after resuming are inconsistent. \n-The API for handling interruptions is confusing and poorly documented\n\nHas anyone here managed to get a robust, production-ready HIL workflow with LangGraph? Any best practices or workarounds for these pain points? Would love to see code snippets or architecture diagrams if you’re willing to share!\n\n \n\n## Top Posts\n\n---\n\n* [reReddit: Top posts of June 17, 2025\n\n ---](https://www.reddit.com/posts/2025/june-17-1/global/)\n* [Reddit\n\n reReddit: Top posts of June 2025\n\n ---](https://www.reddit.com/posts/2025/june/global/)\n* [Reddit\n\n reReddit: Top posts of 2025\n\n ---](https://www.reddit.com/posts/2025/global/)\n\n[Reddit Rules](https://www.redditinc.com/policies/content-policy) [Privacy Policy](https://www.reddit.com/policies/privacy-policy) [User Agreement](https://www.redditinc.com/policies/user-agreement) [Your Privacy Choices](https://support.reddithelp.com/hc/articles/43980704794004) [Accessibility](https://support.reddithelp.com/hc/sections/38303584022676-Accessibility) [Reddit, Inc. © 2026. All rights reserved.](https://redditinc.com)\n\n "}]
================================== Ai Message ==================================
LangGraph에 대한 자료는 주로 Reddit에서 활발히 논의되고 있습니다. 아래는 LangGraph의 인간 참여(Human-in-the-loop) 기능에 관한 유용한 링크들입니다:
1. **[LangGraph: Human-in-the-loop review](https://www.reddit.com/r/LangChain/comments/1ji4091/langgraph_humanintheloop_review/)** - 이 글에서는 LangGraph가 어떻게 인간 참여 상호작용을 지원하는지에 대한 짧은 데모를 보여주며, 다양한 작업 중에 사용자가 개입할 수 있는 방법들을 설명합니다.
2. **[Human intervention in agent workflows](https://www.reddit.com/r/LangChain/comments/1bjnmu4/human_intervention_in_agent_workflows/)** - 이 글은 LLM 워크플로우 내에서 인간이 검증, 승인, 거부할 수 있는 노드 작성에 대해 논의하며, 사용자 주도 대화가 아닌 흐름을 어떻게 설계할 수 있는지에 대해 고민하고 있습니다.
3. **[I am Struggling with LangGraph's Human-in-the-Loop ...](https://www.reddit.com/r/LangGraph/comments/1ldiqtg/i_am_struggling_with_langgraphs_humanintheloop/)** - 사용자들이 LangGraph의 인간 참여 기능을 설정하는 데 경험하는 문제들에 대해 논의하고, 보다 견고한 승인을 위한 워크플로우를 구축하는 방법에 대한 정보와 팁을 공유하는 곳입니다.
이 자료들을 통해 LangGraph의 주요 기능과 활용법에 대해 깊이 이해할 수 있을 것입니다.
8. 사람(Human)에게 물어보는 노드 추가
지금까지는 메시지들의 상태(State)에 의존해 왔습니다. 이런 상태 값들의 수정으로도 많은 것을 할 수 있지만, 메시지 목록에만 의존하지 않고 복잡한 동작을 정의하고자 한다면 상태에 추가 필드를 더할 수 있습니다. 이번 예제에서는 새로운 노드를 추가하여 챗봇을 확장하는 방법을 설명합니다.
이전 항목의 예제에서는 도구가 호출될 때마다 interrupt를 통해 그래프가 항상 중단 되도록 Human-in-the-loop를 구현하였습니다.
이번에는, 챗봇이 인간에 의존할지 선택할 수 있도록 하고 싶다고 가정해 보도록 하겠습니다.
이를 수행하는 한 가지 방법은 그래프가 항상 멈추는 “human”노드를 생성하는 것입니다. 이 노드는 LLM이 “human” 도구를 호출할 때만 실행됩니다. 편의를 위해, 그래프 상태에 “ask_human” 플래그를 포함시켜 LLM이 이 도구를 호출하면 플래그를 전환하도록 할 것입니다.
8.1 사람에게 의견을 묻는 노드 설정
우선 실행에 필요한 라이브러리들을 정의해 줍니다.
from typing import Annotated
from typing_extensions import TypedDict
from langchain_teddynote.tools.tavily import TavilySearch
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
이번에는 중간에 사람에게 질문할지 여부를 묻는 상태(ask_human)를 추가합니다.
class State(TypedDict):
# 메시지 목록
messages: Annotated[list, add_messages]
# 사람에게 질문하지 여부를 묻는 상태 추가
ask_human: bool
human에 대한 요청시 사용되는 스키마를 정의합니다.
from pydantic import BaseModel
class HumanRequest(BaseModel):
"""
Forward the conversation to an expert. Use when you cant't assist directly or the user needs assistance that exceeds your authority.
To use this function, pass the user's 'request' so that an expert can provide appropriate guidance.
"""
request: str
이제 챗봇 노드를 정의합니다. 여기서 주요 수정 사항은 챗봇이 RequestAssistance 플래그를 호출한 경우 ask_human 플래그를 전환하는 것입니다.
from langchain_openai import ChatOpenAI
# 도구 추가
tool = TavilySearch(max_results=1)
# 도구 목록 추가(HumanRequest 도구)
tools = [tool, HumanRequest]
# LLM 추가
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 도구 바인딩
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State):
# LLM 도구 호출을 통한 응답 생성
response = llm_with_tools.invoke(state["messages"])
# 사람에게 질문할지 여부 초기화
ask_human = False
# 도구 호출이 있고 이름이 'HumanRequest'인 경우
if response.tool_calls and response.tool_calls[0]["name"] == HumanRequest.__name__:
ask_human = True
# 메시지와 ask_human 상태 반환
return {"messages": [response], "ask_human": ask_human}
다음으로 그래프 빌더를 생성하고 이전과 동일하게 chatbot과 tools 노드를 그래프에 추가합니다.
# 상태 그래프 초기화
graph_builder = StateGraph (State)
# 챗봇 노드 추가
graph_builder.add_node("chatbot", chatbot)
# 도구 노드 추가
graph_builder.add_node("tools", ToolNode(tools=[tool]))
다음으로 human 노드를 생성합니다. 이 노드는 주로 그래프에서 인터럽트를 트리거하는 자리 표시자 역할을 합니다. 사용자가 interrupt 동안 수동으로 상태를 업데이트하지 않으면, LLM이 사용자가 요청을 받았지만 응답하지 않았음을 알 수 있도록 도구 메시지를 삽입합니다.
이 노드는 또한 ask_human 플래그를 해제하여 추가 요청이 없는 한 그래프가 노드를 다시 방문하지 않도록 합니다.
from langchain_core.messages import AIMessage, ToolMessage
# 응답 메시지 생성(ToolMessage 생성을 위한 함수)
def create_response(response: str, ai_message: AIMessage):
return ToolMessage(
content=response,
tool_call_id=ai_message.tool_calls[0]["id"]
)
# Human 노드 처리
def human_node(state: State):
new_messages = []
if not isinstance(state["messages"][-1], ToolMessage):
# 사람으로부터 응답이 없는 경우
new_messages.append(
create_response("No response from human.", state["messages"][-1])
)
return {
# 새 메시지 추가
"messages": new_messages,
# 플래그 해제
"ask_human": False,
}
# 그래프에 인간 노드 추가
graph_builder.add_node("human", human_node)
다음으로, 조건부 논리를 정의합니다.
select_next_node는 플래그가 설정된 경우 human 노드로 경로를 지정합니다. 그렇지 않으면, 사전 구축된 tools_condition 함수가 다음 노드를 선택하도록 합니다.
tools_condition 함수는 단순히 chatbot이 응답 메시지에서 tool_calls을 사용했는지 확인합니다. 사용한 경우, action 노드로 경로를 지정합니다. 그렇지 않으면, 그래프를 종료합니다.
from langgraph.graph import END
# 다음 노드 선택
def select_next_node(state: State):
# 인간에게 질문 여부 확인
if state["ask_human"]:
return "human"
# 이전과 동일한 경로 설정
return tools_condition(state)
# 조건부 엣지 추가
graph_builder.add_conditional_edges(
"chatbot",
select_next_node,
{"human": "human", "tools": "tools", END:END},
)
마지막으로 엣지를 연결하고 그래프를 컴파일합니다.
# 엣지 추가: 'tools'에서 'chatbot'으로
graph_builder.add_edge("tools", "chatbot")
# 엣지 추가: 'human'에서 'chatbot'으로
graph_builder.add_edge("human", "chatbot")
# 엣지 추가: START에서 'chatbot'으로
graph_builder.add_edge(START, "chatbot")
# 메모리 저장소 초기화
memory = MemorySaver()
# 그래프 컴파일: 메모리 체크포인터 사용
graph = graph_builder.compile(
checkpointer=memory,
# 'human' 이전에 인터럽트 설정
interrupt_before=["human"]
)
그래프를 시각화 합니다.
from langchain_teddynote.graphs import visualize_graph
visualize_graph(graph)

chatbot 노드는 다음과 같은 동작을 합니다.
- 챗봇은 인간에게 도움을 요청할 수 있으며 (chatbo->select->human)
- 검색 엔진 도구를 호출하거나 (chatbot->select->action)
- 직접 응답할 수 있습니다.(chatbot->select->end)
일단 행동이나 요청이 이루어지면, 그래프는 chatbot 노드로 다시 전환되어 작업을 계속합니다.
user_input = "이 AI 에이전트를 구축하기 위해 전문가의 도움이 필요합니다. 도움을 요청할 수 있나요?"
# config 설정
config = {"configurable": {"thread_id": 1}}
# 스트림 또는 호출의 두 번째 위치 인수로서의 구성
events = graph.stream(
{"messages": [("user", user_input)]}, config, stream_mode="values"
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
Output:
================================ Human Message =================================
이 AI 에이전트를 구축하기 위해 전문가의 도움이 필요합니다. 도움을 요청할 수 있나요?
================================== Ai Message ==================================
Tool Calls:
HumanRequest (call_eoNEoYH66ce5Cp5aEnr8FOMt)
Call ID: call_eoNEoYH66ce5Cp5aEnr8FOMt
Args:
request: AI 에이전트를 구축하는 데 필요한 전문가의 도움을 요청합니다.
LLM이 제공된 HumanRequest 도구를 호출했으며, 인터럽트가 설정되었습니다. 그래프 상태를 확인해 보도록 하겠습니다.
# 그래프 상태 스냅샷 생성
snapshot = graph.get_state(config)
# 다음 스냅샷 상태 접근
snapshot.next
Output:
('human',)
그래프 상태는 실제로 human 노드 이전에 중단됩니다.
이 시나리오에서 “전문가”로서 행동하고 입력을 사용하여 새로운 ToolMessage를 추가하여 상태를 수동으로 업데이트할 수 있습니다.
다음으로, 챗봇의 요청에 응답하려면 다음을 수행해야 합니다.
- 응답을 포함한
ToolMessage를 생성합니다. 이는chatbot에 다시 전달됩니다. update_state를 호출하여 그래프 상태를 수동으로 업데이트합니다.
# AI 메시지 추출
ai_message = snapshot.values["messages"][-1]
# 인간 응답 생성
human_response = (
"전문가들이 도와드리겠습니다! 에이전트 구축을 위해 LangGraph를 확인해 보시기를 적극 추천드립니다."
"단순한 자율 에이전트보다 훨씬 더 안정적이고 확장성이 뛰어납니다."
"https://wikidocs.net/233785 에서 더 많은 정보를 확인할 수 있습니다."
)
# 도구 메시지 생성
tool_message = create_response(human_response, ai_message)
# 그래프 상태 업데이트
graph.update_state(config, {"messages": [tool_message]})
Output:
{'configurable': {'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f10888b-68c6-66fb-8002-3990887436e5'}}
상태를 확인하여 응답이 추가되었는지 확인할 수 있습니다.
# 그래프 상태에서 메시지 값 가져오기
graph.get_state(config).values["messages"]
Output:
[HumanMessage(content='이 AI 에이전트를 구축하기 위해 전문가의 도움이 필요합니다. 도움을 요청할 수 있나요?', additional_kwargs={}, response_metadata={}, id='f32d492c-e42f-49a8-b885-c2c72e4cbc4d'),
AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 30, 'prompt_tokens': 172, 'total_tokens': 202, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_373a14eb6f', 'id': 'chatcmpl-D8desmu1xGtLhK6CXTVLmGEMYTvFq', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--019c54ee-7993-7612-965a-8353afbb1244-0', tool_calls=[{'name': 'HumanRequest', 'args': {'request': 'AI 에이전트를 구축하는 데 필요한 전문가의 도움을 요청합니다.'}, 'id': 'call_eoNEoYH66ce5Cp5aEnr8FOMt', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 172, 'output_tokens': 30, 'total_tokens': 202, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
ToolMessage(content='전문가들이 도와드리겠습니다! 에이전트 구축을 위해 LangGraph를 확인해 보시기를 적극 추천드립니다.단순한 자율 에이전트보다 훨씬 더 안정적이고 확장성이 뛰어납니다.https://wikidocs.net/233785 에서 더 많은 정보를 확인할 수 있습니다.', id='8c815d59-a1f9-4b31-bc0c-3b418d4eee55', tool_call_id='call_eoNEoYH66ce5Cp5aEnr8FOMt')]
이제 입력값으로 None을 사용하여 그래프를 resume 합니다.
# 그래프에서 이벤트 스트림 생성
events = graph.stream(None, config, stream_mode="values")
# 각 이벤트에 대한 처리
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
Output:
================================= Tool Message =================================
전문가들이 도와드리겠습니다! 에이전트 구축을 위해 LangGraph를 확인해 보시기를 적극 추천드립니다.단순한 자율 에이전트보다 훨씬 더 안정적이고 확장성이 뛰어납니다.https://wikidocs.net/233785 에서 더 많은 정보를 확인할 수 있습니다.
================================= Tool Message =================================
전문가들이 도와드리겠습니다! 에이전트 구축을 위해 LangGraph를 확인해 보시기를 적극 추천드립니다.단순한 자율 에이전트보다 훨씬 더 안정적이고 확장성이 뛰어납니다.https://wikidocs.net/233785 에서 더 많은 정보를 확인할 수 있습니다.
================================== Ai Message ==================================
전문가의 도움을 받았습니다! AI 에이전트를 구축하기 위해 LangGraph를 확인해 보시기를 추천드립니다. 이 플랫폼은 단순한 자율 에이전트보다 훨씬 더 안정적이고 확장성이 뛰어납니다. 더 많은 정보는 [여기](https://wikidocs.net/233785)에서 확인하실 수 있습니다.
최종 결과를 확인해 봅니다.
# 최종 상태 확인
state = graph.get_state(config)
# 단계별 메시지 출력
for message in state.values["messages"]:
message.pretty_print()
Output:
================================ Human Message =================================
이 AI 에이전트를 구축하기 위해 전문가의 도움이 필요합니다. 도움을 요청할 수 있나요?
================================== Ai Message ==================================
Tool Calls:
HumanRequest (call_eoNEoYH66ce5Cp5aEnr8FOMt)
Call ID: call_eoNEoYH66ce5Cp5aEnr8FOMt
Args:
request: AI 에이전트를 구축하는 데 필요한 전문가의 도움을 요청합니다.
================================= Tool Message =================================
전문가들이 도와드리겠습니다! 에이전트 구축을 위해 LangGraph를 확인해 보시기를 적극 추천드립니다.단순한 자율 에이전트보다 훨씬 더 안정적이고 확장성이 뛰어납니다.https://wikidocs.net/233785 에서 더 많은 정보를 확인할 수 있습니다.
================================== Ai Message ==================================
전문가의 도움을 받았습니다! AI 에이전트를 구축하기 위해 LangGraph를 확인해 보시기를 추천드립니다. 이 플랫폼은 단순한 자율 에이전트보다 훨씬 더 안정적이고 확장성이 뛰어납니다. 더 많은 정보는 [여기](https://wikidocs.net/233785)에서 확인하실 수 있습니다.
9. 메시지 삭제(RemoveMessage)
RemoveMessage는 LangGraph의 메시지 리스트(State)에서 특정 메시지를 삭제하도록 리듀서(Reducer)에게 보내는 삭제 명령서입니다.
일반적인 Python 리스트라면 del list[0] 처럼 직접 데이터를 지우겠지만, LangGraph는 상태의 변화를 추적하고 기록하는 불변성(Immutability)을 유지해야 합니다. 따라서 “이 메시지를 지워줘”라는 특수한 객체(RemoveMessage)를 기존 메시지 리스트에 보냄으로써 삭제를 수행합니다.
RemoveMessage가 중요한 이유는 다음과 같습니다.
-
토큰 제한(Content Window)의 효율적 관리 대화가 길어지면 메시지 리스트가 비대해집니다.
add_message리듀서는 데이터를 계속 쌓기만 하는데, 이때RemoveMessage를 사용하지 않으면 어느 순간 모델의 토큰 한도를 초과하거나, 불필요한 비용이 기하급수적으로 발생합니다. - 모델의 집중도 향상(Signal-to-Noise Ratio)
LLM은 너무 많은 정보가 입력되면 핵심 맥락을 놓치는 경향이 있습니다.
- 중간 단계 로그 삭제: 에이전트가 내부적으로 생각하는 과정(Chain of Thought)이나 불필요한 도구 호출 결과 등을 삭제하여, 최종 답변 생성 시 모델이 결과에만 집중하게 할 수 있습니다.
- 개인정보 및 보안(PII Masking) 사용자가 대화 중에 실수로 입력한 개인정보나 민감한 데이터를 그래프 실행 도중 혹은 저장 직전에 삭제하여 보안 가이드라인을 준수할 수 있습니다.
9.1 예제 진행을 위한 기본 LangGraph 구축
RemoveMessage 수정자를 사용하기 위해 필요한 기본 LangGraph를 구축합니다.
from typing import Literal
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import MessagesState, StateGraph, START, END
from langgraph.prebuilt import ToolNode, tools_condition
# 체크포인트 저장을 위한 메모리 객체 초기화
memory = MemorySaver()
# 웹 검색 기능을 모방하는 도구 함수 정의
@tool
def search(query: str):
"""Call to surf on the web."""
return "웹 검색 결과: LangGraph 한글 튜토리얼은 https://wikidocs.net/233785 에서 확인할 수 있습니다."
# 도구 목록 생성 및 도구 노드 초기화
tools = [search]
tool_node = ToolNode(tools)
# 모델 초기화 및 도구 바인딩
model = ChatOpenAI(model_name="gpt-4o-mini")
bound_model = model.bind_tools(tools)
# # 대화 상태에 따른 다음 실행 노드 결정 함수
def should_continue(state: MessagesState):
last_message = state["messages"][-1]
if not last_message.tool_calls:
return END
return "tool"
# LLM 모델 호출 및 응답 처리 함수
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
# 상태 기반 워크플로우 그래프 초기화
workflow = StateGraph(MessagesState)
# 에이전트와 액션 노드 추가
workflow.add_node("agent", call_model)
workflow.add_node("tool", tool_node)
# 시작점을 에이전트 노드로 설정
workflow.add_edge(START, "agent")
# 조건부 엣지 설정: 에이전트 노드 이후의 실행 흐름 정의
workflow.add_conditional_edges("agent", should_continue, {"tool": "tool", END: END})
# 도구 실행 후 에이전트로 돌아가는 엣지 추가
workflow.add_edge("tool", "agent")
# 체크포인터가 포함된 최종 실행 가능한 워크플로우 컴파일
app = workflow.compile(checkpointer=memory)
질문을 수행하여 메시지를 쌓아 봅니다.
from langchain_core.messages import HumanMessage
# 스레드 ID가 1인 기본 설정 객체 초기화
config = {"configurable": {"thread_id": 1}}
# 1번째 질문 수행
input_message = HumanMessage(
content="안녕하세요! 제 이름은 Teddy입니다. 잘 부탁드립니다."
)
# 스트림 모드로 메시지 처리 및 응답 출력, 마지막 메시지의 상세 정보 표시
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
event["messages"][-1].pretty_print()
Output:
================================ Human Message =================================
안녕하세요! 제 이름은 Teddy입니다. 잘 부탁드립니다.
================================== Ai Message ==================================
안녕하세요, Teddy님! 만나서 반갑습니다. 제가 도와드릴 수 있는 것이 있으면 언제든지 말씀해 주세요!
# 후속 질문 수행
input_message = HumanMessage(content = "내 이름이 뭐라고요?")
# 스트림 모드로 두 번째 메시지 처리 및 응답 출력
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
event["messages"][-1].pretty_print()
Output:
================================ Human Message =================================
내 이름이 뭐라고요?
================================== Ai Message ==================================
당신의 이름은 Teddy입니다!
# 단계별 상태 확인
messages = app.get_state(config).values["messages"]
for message in messages:
message.pretty_print()
Output:
================================ Human Message =================================
안녕하세요! 제 이름은 Teddy입니다. 잘 부탁드립니다.
================================== Ai Message ==================================
안녕하세요, Teddy님! 만나서 반갑습니다. 제가 도와드릴 수 있는 것이 있으면 언제든지 말씀해 주세요!
================================== Ai Message ==================================
안녕하세요, Teddy님! 만나서 반갑습니다. 제가 도와드릴 수 있는 것이 있으면 언제든지 말씀해 주세요!
================================ Human Message =================================
내 이름이 뭐라고요?
================================== Ai Message ==================================
당신의 이름은 Teddy입니다!
9.2 RemoveMessage 수정자를 사용하여 메시지 삭제
update_state를 호출하고 첫 번째 메시지의 id를 전달하면 해당 메시지가 삭제됩니다.
from langchain_core.messages import RemoveMessage
# 메시지 배열의 첫 번째 메시지를 ID 기반으로 제거하고 앱 상태 업데이트
app.update_state(config, {"messages": RemoveMessage(id=messages[0].id)})
Output:
{'configurable': {'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f1089b3-887d-6bc4-8008-4aaf94f23505'}}
이제 메시지들을 확인해보면 첫 번째 메시지가 삭제되었음을 확인할 수 있습니다.
# 앱 상태에서 메시지 목록 추출 및 저장된 대화 내역 조회
messages = app.get_state(config).values["messages"]
for message in messages:
message.pretty_print()
Output:
================================== Ai Message ==================================
안녕하세요, Teddy님! 만나서 반갑습니다. 제가 도와드릴 수 있는 것이 있으면 언제든지 말씀해 주세요!
================================== Ai Message ==================================
안녕하세요, Teddy님! 만나서 반갑습니다. 제가 도와드릴 수 있는 것이 있으면 언제든지 말씀해 주세요!
================================ Human Message =================================
내 이름이 뭐라고요?
================================== Ai Message ==================================
당신의 이름은 Teddy입니다!
9.3 더 많은 메시지를 동적으로 삭제
그래프 내부에서 프로그래밍 방식으로 메시지를 삭제할 수도 있습니다.
그래프 실행이 종료될 때 오래된 메시지(3개 이전의 메시지보다 더 이전의 메시지)를 삭제하도록 그래프를 수정하는 방법을 살펴보겠습니다.
from langchain_core.messages import RemoveMessage
from langgraph.graph import END
# 메시지 개수가 3개 초과 시 오래된 메시지 삭제 및 최신 메시지만 유지
def delete_messages(state):
messages = state["messages"]
if len(messages) > 3:
return {"messages": [RemoveMessage(id=m.id) for m in messages[:-3]]}
# 메시지 상태에 따른 다음 실행 노드 결정 로직
def should_continue(state: MessagesState) -> Literal["action", "delete_messages"]:
"""Return the next node to execute."""
last_message = state["messages"][-1]
# 함수 호출이 없는 경우 메시지 삭제 함수 실행
if not last_message.tool_calls:
return "delete_messages"
# 함수 호출이 있는 경우 액션 실행
return "action"
# 메시지 상태 기반 워크플로우 그래프 정의
workflow = StateGraph(MessagesState)
# 에이전트와 액션 노드 추가
workflow.add_node("agent", call_model)
workflow.add_node("action", tool_node)
# 메시지 삭제 노드 추가
workflow.add_node(delete_messages)
# 시작 노드에서 에이전트 노드로 연결
workflow.add_edge(START, "agent")
# 조건부 엣지 추가를 통한 노드간 흐름 제어
workflow.add_conditional_edges(
"agent",
should_continue,
)
# 액션 노드에서 에이전트 노드로 연결
workflow.add_edge("action", "agent")
# 메시지 삭제 노드에서 종료 노드로 연결
workflow.add_edge("delete_messages", END)
# 메모리 체크 포인터를 사용하여 워크플로우 컴파일
app = workflow.compile(checkpointer=memory)
그래프를 시각화 합니다.
from langchain_teddynote.graphs import visualize_graph
visualize_graph(app)
graph를 두번 호출한 다음 상태를 확인해 보도록 하겠습니다.
from langchain_core.messages import HumanMessage
config = {"configurable": {"thread_id": 2}}
# 1번째 질문 수행
input_message = HumanMessage(
content="안녕하세요! 제 이름은 Teddy입니다. 잘 부탁드립니다."
)
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
print([(message.type, message.content) for message in event["messages"]])
Output:
[('human', '안녕하세요! 제 이름은 Teddy입니다. 잘 부탁드립니다.')]
[('human', '안녕하세요! 제 이름은 Teddy입니다. 잘 부탁드립니다.'), ('ai', '안녕하세요, Teddy님! 만나서 반갑습니다. 어떻게 도와드릴까요?')]
# 2번째 질문 수행
input_message = HumanMessage(content="내 이름이 뭐라고요?")
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
print([(message.type, message.content) for message in event["messages"]])
Output:
[('human', '안녕하세요! 제 이름은 Teddy입니다. 잘 부탁드립니다.'), ('ai', '안녕하세요, Teddy님! 만나서 반갑습니다. 어떻게 도와드릴까요?'), ('human', '내 이름이 뭐라고요?')]
[('human', '안녕하세요! 제 이름은 Teddy입니다. 잘 부탁드립니다.'), ('ai', '안녕하세요, Teddy님! 만나서 반갑습니다. 어떻게 도와드릴까요?'), ('human', '내 이름이 뭐라고요?'), ('ai', '당신의 이름은 Teddy입니다. 맞나요?')]
[('ai', '안녕하세요, Teddy님! 만나서 반갑습니다. 어떻게 도와드릴까요?'), ('human', '내 이름이 뭐라고요?'), ('ai', '당신의 이름은 Teddy입니다. 맞나요?')]
최종 상태를 확인해보면 메시지가 단 세 개만 있는 것을 확인할 수 있습니다. 이는 이전 메시지들을 방금 삭제했기 때문입니다.
# 앱 상태에서 메시지 목록 추출 및 저장
messages = app.get_state(config).values["messages"]
# 메시지 목록 반환
for message in messages:
message.pretty_print()
Output:
================================== Ai Message ==================================
안녕하세요, Teddy님! 만나서 반갑습니다. 어떻게 도와드릴까요?
================================ Human Message =================================
내 이름이 뭐라고요?
================================== Ai Message ==================================
당신의 이름은 Teddy입니다. 맞나요?
10. 병렬 노드 실행을 위한 분기 생성 방법
노드의 병렬 실행은 전체 그래프 작업의 속도를 향상시키는데 필수적입니다. LangGraph는 노드의 병렬 실행을 기본적으로 지원하며, 이는 그래프 기반 워크플로우의 성능을 크게 향상시킬 수 있습니다.
이러한 병렬화는 fan-out과 fan-in 메커니즘을 통해 구현되며, 표준 엣지와 conditional_edges를 활용합니다.
10.1 병렬 노드 fan-out 및 fan-in
병렬 처리에서 fan-out과 fan-in은 작업을 나누고 모으는 과정을 설명하는 개념입니다.
-fan-out(확장): 큰 작업을 여러 작은 작업으로 쪼갭니다. 예를 들어, 피자를 만들 때 도우, 소스, 치즈 준비를 각각 별도로 할 수 있습니다. 이렇게 각각의 파트를 나눠 동시에 처리하는 것이 fan-out입니다.
-fan-in(수집): 나뉜 작은 작업들을 다시 하나로 합칩니다. 피자에 준비된 재료들을 모두 올려 완성 피자를 만드는 과정처럼, 여러 작업이 끝나면 결과를 모아 최종 작업을 완성하는 것이 fan-in입니다.
즉, fan-out으로 작업을 분산시키고, fan-in으로 결과를 합쳐 최종 결과를 얻는 흐름입니다.
아래 예제는 Node A에서 B and C로 팬아웃하고 D로 팬인하는 과정을 보여줍니다.
State에서는 reducer(add) 연산자를 지정합니다. 이는 State 내 특정 키의 기존 값을 단순히 덮어쓰는 대신 값들을 결합하거나 누적합니다. 리스트의 경우, 새로운 리스트를 기존 리스트와 연결하는 것을 의미합니다.
LangGraph는 State의 특정 키에 대한 reducer 함수를 지정하기 위해 Annotated 타입을 사용합니다. 이는 타입 검사를 위해 원래 타입(list)을 유지하면서도, 타입 자체를 변경하지 않고 reducer 함수(add)를 타입에 첨부할 수 있게 합니다.
from typing import Annotated, Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 상태 정의(add_messages 리듀서 사용)
class State(TypedDict):
aggregate: Annotated[list, add_messages]
# 노드 값 반환 클래스
class ReturnNodeValue:
# 초기화
def __init__(self, node_secret: str):
self._value = node_secret
# 호출시 상태 업데이트
def __call__(self, state: State) -> Any:
print(f"Adding {self._value} to {state['aggregate']}")
return {"aggregate": [self._value]}
builder = StateGraph(State)
# 노드 A부터 D까지 생성 및 값 할당
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_edge(START, "a")
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
# 노드 연결
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)
# 그래프 컴파일
graph = builder.compile()
그래프를 시각화하면 다음과 같습니다.
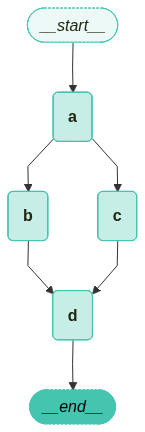
reducer를 통해서 각 노드에 추가된 값들이 누적되는 것을 확인할 수 있습니다.
# 그래프 실행
graph.invoke({"aggregate": []}, {"configurable": {"thread_id": "foo"}})
Output:
Adding I'm A to []
Adding I'm B to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='7fd3136e-a41b-4718-a84e-876b9315834c')]
Adding I'm C to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='7fd3136e-a41b-4718-a84e-876b9315834c')]
Adding I'm D to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='7fd3136e-a41b-4718-a84e-876b9315834c'), HumanMessage(content="I'm B", additional_kwargs={}, response_metadata={}, id='c247e846-dc8c-4442-94ff-701b5cf6b50e'), HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='c5a2e473-7007-4996-9be2-3e6a3ddc13c0')]
{'aggregate': [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='7fd3136e-a41b-4718-a84e-876b9315834c'),
HumanMessage(content="I'm B", additional_kwargs={}, response_metadata={}, id='c247e846-dc8c-4442-94ff-701b5cf6b50e'),
HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='c5a2e473-7007-4996-9be2-3e6a3ddc13c0'),
HumanMessage(content="I'm D", additional_kwargs={}, response_metadata={}, id='f6683029-d33d-4d12-8597-be3c8a1a83e3')]}
10.2 추가 단계가 있는 병렬 노드의 fan-out 및 fan-in
위의 예시에서는 각 경로가 단일 단계일 때의 fan-out과 fan-in 방법을 보여주었습니다. 하지만 하나의 경로에 여러 단계가 있다면 어떻게 되는지 한 번 알아보도록 하겠습니다.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
class State(TypedDict):
aggregate: Annotated[list, add_messages]
# 노드 값 반환 클래스
class ReturnNodeValue:
# 초기화
def __init__(self, node_secret: str):
self._value = node_secret
# 호출시 상태 업데이트
def __call__(self, state: State) -> Any:
print(f"Adding {self._value} to {state['aggregate']}")
return {"aggregate": [self._value]}
# 상태 그래프 초기화
builder = StateGraph(State)
# 노드 생성 및 연결
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_edge(START, "a")
builder.add_node("b1", ReturnNodeValue("I'm B1"))
builder.add_node("b2", ReturnNodeValue("I'm B2"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
builder.add_edge("a", "b1")
builder.add_edge("a", "c")
builder.add_edge("b1", "b2")
builder.add_edge(["b2", "c"], "d")
builder.add_edge("d", END)
# 그래프 컴파일
graph = builder.compile()
그래프를 시각화합니다.
from langchain_teddynote.graphs import visualize_graph
visualize_graph(graph)
# 그래프 실행
graph.invoke({"aggregate": []}, {"configurable": {"thread_id": "foo"}})
Output:
Adding I'm A to []
Adding I'm B1 to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='3cfbe187-9f7f-42ee-9a21-04cc84ad2bac')]
Adding I'm C to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='3cfbe187-9f7f-42ee-9a21-04cc84ad2bac')]
Adding I'm B2 to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='3cfbe187-9f7f-42ee-9a21-04cc84ad2bac'), HumanMessage(content="I'm B1", additional_kwargs={}, response_metadata={}, id='4c7f7202-2f11-42d2-bae9-209f3f1961af'), HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='ee76d877-0ed0-4920-b465-0f54dcdf27ef')]
Adding I'm D to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='3cfbe187-9f7f-42ee-9a21-04cc84ad2bac'), HumanMessage(content="I'm B1", additional_kwargs={}, response_metadata={}, id='4c7f7202-2f11-42d2-bae9-209f3f1961af'), HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='ee76d877-0ed0-4920-b465-0f54dcdf27ef'), HumanMessage(content="I'm B2", additional_kwargs={}, response_metadata={}, id='02a43b05-6905-4b48-a2e6-dc8d25a056d5')]
{'aggregate': [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='3cfbe187-9f7f-42ee-9a21-04cc84ad2bac'),
HumanMessage(content="I'm B1", additional_kwargs={}, response_metadata={}, id='4c7f7202-2f11-42d2-bae9-209f3f1961af'),
HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='ee76d877-0ed0-4920-b465-0f54dcdf27ef'),
HumanMessage(content="I'm B2", additional_kwargs={}, response_metadata={}, id='02a43b05-6905-4b48-a2e6-dc8d25a056d5'),
HumanMessage(content="I'm D", additional_kwargs={}, response_metadata={}, id='bcf2da5c-7770-4d7b-956a-ab5ec9370ef7')]}
10.3 조건부 분기
fan-out이 결정적이지 않은 경우, add_conditional_edges를 직접 사용할 수 있습니다.
조건부 분기 이후 연결될 알려진 “sink” 노드가 있는 경우, 조건부 엣지를 생성할 때 `then=”실행할 노드명”을 제공할 수 있습니다.
from typing import Annotated, Sequence
from typing_extensions import TypedDict
from langgraph.graph import END, START, StateGraph
# 상태 정의(add_messages 리듀서 사용)
class State(TypedDict):
aggregate: Annotated[list, add_messages]
which: str
# 노드별 고유 값을 반환하는 클래스
class ReturnNodeValue:
def __init__(self, node_secret: str):
self._value = node_secret
def __call__(self, state: State) -> Any:
print(f"Adding {self._value} to {state['aggregate']}")
return {"aggregate": [self._value]}
# 상태 그래프 초기화
builder = StateGraph(State)
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_edge(START, "a")
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
builder.add_node("e", ReturnNodeValue("I'm E"))
# 상태의 `which` 값에 따른 조건부 라우팅 경로 결정 함수
def route_bc_or_cd(state: State) -> Sequence[str]:
if state["which"] == "cd":
return ["c", "d"]
return ["b", "c"]
# 전체 병렬 처리할 노드 목록
intermediates = ["b", "c", "d"]
builder.add_conditional_edges(
"a",
route_bc_or_cd,
intermediates,
)
for node in intermediates:
builder.add_edge(node, "e")
# 최종 노드 연결 및 그래프 컴파일
builder.add_edge("e", END)
graph = builder.compile()
그래프를 시각화 합니다.
from langchain_teddynote.graphs import visualize_graph
visualize_graph(graph)
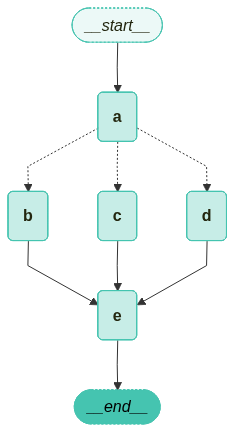
# 그래프 실행(which: bc로 지정)
graph.invoke({"aggregate": [], "which": "bc"})
Output:
Adding I'm A to []
Adding I'm B to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='a898aad5-c7e5-4363-a787-20c55a0b6245')]
Adding I'm C to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='a898aad5-c7e5-4363-a787-20c55a0b6245')]
Adding I'm E to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='a898aad5-c7e5-4363-a787-20c55a0b6245'), HumanMessage(content="I'm B", additional_kwargs={}, response_metadata={}, id='aa650632-b85d-4510-9a63-1ee85d37a4f2'), HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='eab520d2-b711-45ae-8f73-22295884533d')]
{'aggregate': [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='a898aad5-c7e5-4363-a787-20c55a0b6245'),
HumanMessage(content="I'm B", additional_kwargs={}, response_metadata={}, id='aa650632-b85d-4510-9a63-1ee85d37a4f2'),
HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='eab520d2-b711-45ae-8f73-22295884533d'),
HumanMessage(content="I'm E", additional_kwargs={}, response_metadata={}, id='340a0a62-4615-4b8b-aa8a-1401985b4f85')],
'which': 'bc'}
# 그래프 실행(which: cd로 지정)
graph.invoke({"aggregate": [], "which": "cd"})
Output:
Adding I'm A to []
Adding I'm C to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='a3d7b77a-e186-4c16-a0d9-833a62304011')]
Adding I'm D to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='a3d7b77a-e186-4c16-a0d9-833a62304011')]
Adding I'm E to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='a3d7b77a-e186-4c16-a0d9-833a62304011'), HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='85774756-dede-4b57-8c40-73f4963c9322'), HumanMessage(content="I'm D", additional_kwargs={}, response_metadata={}, id='99154e93-1ca3-4fa7-8258-d66b306669a1')]
{'aggregate': [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='a3d7b77a-e186-4c16-a0d9-833a62304011'),
HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='85774756-dede-4b57-8c40-73f4963c9322'),
HumanMessage(content="I'm D", additional_kwargs={}, response_metadata={}, id='99154e93-1ca3-4fa7-8258-d66b306669a1'),
HumanMessage(content="I'm E", additional_kwargs={}, response_metadata={}, id='9f8c2757-d9d6-4841-b2cf-5c37842fde10')],
'which': 'cd'}
10.4 fan-out 값의 신뢰도에 따른 정렬
병렬로 펼쳐진 노드들은 하나의 “super-step”으로 실행됩니다. 각 super-step에서 발생한 업데이트들은 해당 super-step이 완료된 후 순차적으로 상태에 적용됩니다.
병렬 super-step에서 일관된 사전 정의된 업데이트 순서가 필요한 경우, 출력값을 식별 키와 함께 상태의 별도 필드에 기록한 다음, 팬아웃된 각 노드에서 집결 지점까지 일반 edge를 추가하여 “sink” 노드에서 이들을 결합해야 합니다.
예를 들어, 병렬 단계의 출력을 “신뢰도”에 따라 정렬하고자 하는 경우를 고려해보겠습니다.
from typing import Annotated, Sequence
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
# 팬아웃 값들의 병합 로직 구현, 빈 리스트 처리 및 리스트 연결 수행
def reduce_fanouts(left, right):
if left is None:
left = []
if not right:
# 덮어쓰기
return []
return left + right
class State(TypedDict):
aggregate: Annotated[list, add_messages]
fanout_values: Annotated[list, reduce_fanouts]
which: str
builder = StateGraph(State)
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_edge(START, "a")
# 병렬 노드 값 반환 클래스
class ParallelReturnNodeValue:
def __init__(
self,
node_secret: str,
reliability: float,):
self._value = node_secret
self._reliability = reliability
# 호출시 상태 업데이트
def __call__(self, state: State) -> Any:
print(f"Adding {self._value} to {state['aggregate']} in parallel.")
return {
"fanout_values": [
{
"value": [self._value],
"reliability": self._reliability,
}
]
}
# 신뢰도(reliability)가 다른 병렬 노드들 추가
builder.add_node("b", ParallelReturnNodeValue("I'm B", reliability=0.1))
builder.add_node("c", ParallelReturnNodeValue("I'm C", reliability=0.9))
builder.add_node("d", ParallelReturnNodeValue("I'm D", reliability=0.5))
# 팬아웃 값들을 신뢰도 기준으로 정렬하고 최종 집계 수행
def aggregate_fanout_values(state: State) -> Any:
ranked_values = sorted(
state["fanout_values"], key=lambda x: x["reliability"], reverse=True
)
print(ranked_values)
return {
"aggregate": [x["value"][0] for x in ranked_values] + ["I'm E"],
"fanout_values": [],
}
# 집계 노드 추가
builder.add_node("e", aggregate_fanout_values)
# 상태에 따른 조건부 라우팅 로직 구현
def route_bc_or_cd(state: State) -> Sequence[str]:
if state["which"] == "cd":
return ["c", "d"]
return ["b", "c"]
# 중간 노드들 설정 및 조건부 엣지 추가
intermediates = ["b", "c", "d"]
builder.add_conditional_edges("a", route_bc_or_cd, intermediates)
# 중간 노드들과 최종 집계 노드 연결
for node in intermediates:
builder.add_edge(node, "e")
graph = builder.compile()
그래프를 시각화합니다.
from langchain_teddynote.graphs import visualize_graph
visualize_graph(graph)
# 그래프 실행(which: bc 로 지정)
graph.invoke({"aggregate": [], "which": "bc", "fanout_values": []})
Output:
Adding I'm A to []
Adding I'm B to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='3695a26e-f8c5-4ea4-8642-2a13e6313425')] in parallel.
Adding I'm C to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='3695a26e-f8c5-4ea4-8642-2a13e6313425')] in parallel.
[{'value': ["I'm C"], 'reliability': 0.9}, {'value': ["I'm B"], 'reliability': 0.1}]
{'aggregate': [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='3695a26e-f8c5-4ea4-8642-2a13e6313425'),
HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='91d8979e-08d1-4010-9302-f71d3982ffc3'),
HumanMessage(content="I'm B", additional_kwargs={}, response_metadata={}, id='851e3539-439b-4453-8e70-dab5e950627a'),
HumanMessage(content="I'm E", additional_kwargs={}, response_metadata={}, id='8962e207-4b39-45ba-993a-af87c3180a45')],
'fanout_values': [],
'which': 'bc'}
# 그래프 실행(which: cd 로 지정)
graph.invoke({"aggregate": [], "which": "cd"})
Output:
Adding I'm A to []
Adding I'm C to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='75a2de65-c052-4ff5-be30-e71e17c92404')] in parallel.
Adding I'm D to [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='75a2de65-c052-4ff5-be30-e71e17c92404')] in parallel.
[{'value': ["I'm C"], 'reliability': 0.9}, {'value': ["I'm D"], 'reliability': 0.5}]
{'aggregate': [HumanMessage(content="I'm A", additional_kwargs={}, response_metadata={}, id='75a2de65-c052-4ff5-be30-e71e17c92404'),
HumanMessage(content="I'm C", additional_kwargs={}, response_metadata={}, id='63230975-3eac-4cd8-aa2d-8abfc887c62a'),
HumanMessage(content="I'm D", additional_kwargs={}, response_metadata={}, id='d529d1c9-e526-49a0-84b4-47b3c55bb124'),
HumanMessage(content="I'm E", additional_kwargs={}, response_metadata={}, id='6d53fbf5-5dc3-419f-8fb8-a9889a793e2e')],
'fanout_values': [],
'which': 'cd'}
11. 대화 기록 요약을 추가하는 방법
대화 기록을 유지하는 것은 지속성의 가장 일반적인 사용 사례 중 하나입니다. 이는 대화를 지속하기 쉽게 만들어주는 장점이 있습니다. 하지만 대화가 길어질수록 대화 기록이 누적되어 context window를 더 많이 차지하게 됩니다. 이는 LLM 호출이 더 비싸고 길어지며 잠재적으로 오류가 발생할 수 있어 바람직하지 않을 수 있습니다. 이를 해결하기 위한 한 가지 방법은 현재까지의 대화 요약본을 생성하고, 이를 최근 N개의 메시지와 함께 사용하는 것입니다.
이번 예제에서는 이를 구현하는 방법에 대해서 알아보도록 하겠습니다. 예제에서는 다음과 같은 단계를 진행합니다.
- 대화가 너무 긴지 확인 (메시지 수나 길이로 확인 가능)
- 너무 길다면 요약본 생성 (이를 위한 프롬프트 필요)
- 마지막
N개의 메시지를 제외한 나머지 삭제
이 과정에서 중요한 부분은 오래된 메시지를 삭제(DeleteMessage)하는 것입니다.
11.1 긴 대화를 요약하여 대화로 저장
긴 대화에 대하여 요약본을 생성한 뒤, 기존의 대화를 삭제하고 요약본을 대화로 저장합니다.
조건은 대화의 길이가 6개 초과일 경우 요약본을 생성합니다.
from typing import Literal, Annotated
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, RemoveMessage, HumanMessage
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import MessagesState, StateGraph, START
from langgraph.graph.message import add_messages
# 메모리 저장소 설정
memory = MemorySaver()
# 메시지 상태와 요약 정보를 포함하는 상태 클래스
class State(MessagesState):
messages: Annotated[list, add_messages]
summary: str
# 대화 및 요약을 위한 모델 초기화
model = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
ask_llm 노드는 messages를 LLM에 주입하여 답변을 얻습니다. 만약, 이전의 대화 요약본이 존재한다면, 이를 시스템 메시지로 추가하여 대화에 포함시킵니다. 하지만, 이전의 대화 요약본이 존재하지 않는다면, 이전의 대화 내용만 사용합니다.
def ask_llm(state: State):
summary = state.get("summary", "")
# 이전 요약 정보가 있다면 시스템 메시지로 추가
if summary:
# 시스템 메시지 생성
system_message = f"Summary of conversation earlier: {summary}"
# 시스템 메시지와 이전 메시지 결합
messages = [SystemMessage(content=system_message)] + state["messages"]
else:
# 이전 메시지만 사용
messages = state["messages"]
# 모델 호출
response = model.invoke(messages)
# 응답 반환
return {"messages": [response]}
should_continue노드는 대화의 길이가 6개 초과일 경우 요약 노드로 이동합니다. 그렇지 않다면, 즉각 답변을 반환합니다. (END 노드로 이동)
from langgraph.graph import END
# 대화 종료 또는 요약 결정 로직
def should_continue(state: State) -> Literal["summarize_conversation", END]:
# 메시지 목록 확인
messages = state["messages"]
# 메시지 수가 6개 초과라면 요약 노드로 이동
if len(messages) > 6:
return "summarize_conversation"
return END
summarize_conversation 노드는 대화 내용을 요약하고, 오래된 메시지를 삭제합니다.
# 대화 내용 요약 및 메시지 정리 로직
def summarize_conversation(state: State):
# 이전 요약 정보 확인
summary = state.get("summary", "")
# 이전 요약 정보가 있다면 요약 메시지 생성
if summary:
summary_message = (
f"This is summary of the conversation to date: {summary}\n\n"
"Extend the summary by taking into account the new messages above in Korean:"
)
else:
# 요약 메시지 생성
summary_message = "Create a summary of the conversation above in Korean:"
# 요약 메시지와 이전 메시지 결합
messages = state["messages"] + [HumanMessage(content=summary_message)]
# 모델 호출
response = model.invoke(messages)
# 오래된 메시지 삭제
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
# 요약 정보 반환
return {"summary": response.content, "messages": delete_messages}
# 워크플로우 그래프 초기화
workflow = StateGraph(State)
# 대화 및 요약 노드 추가
workflow.add_node("conversation", ask_llm)
workflow.add_node(summarize_conversation)
# 시작점을 대화 노드로 설정
workflow.add_edge(START, "conversation")
# 조건부 엣지 추가
workflow.add_conditional_edges(
"conversation",
should_continue,
)
# 요약 노드에서 종료 노드로의 엣지 추가
workflow.add_edge("summarize_conversation", END)
# 워크플로우 컴파일 및 메모리 체크포인터 설정
app = workflow.compile(checkpointer=memory)

11.2 그래프 실행
# 업데이트 정보 출력 함수
def print_update(update):
for k, v in update.items():
# 메시지 목록 출력
for m in v["messages"]:
m.pretty_print()
# 요약 정보 존재 시 출력
if "summary" in v:
print(v["summary"])
from langchain_core.messages import HumanMessage
# 스레드 ID가 포함된 설정 객체 초기화
config = {"configurable": {"thread_id": 1}}
# 첫 번째 사용자 메시지 생성 및 출력
input_message = HumanMessage(content="안녕하세요? 반갑습니다. 제 이름은 테디입니다.")
input_message.pretty_print()
# 스트림 모드에서 첫 번째 메시지 처리 및 업데이트 출력
for event in app.stream({"messages": [input_message]}, config, stream_mode="updates"):
print_update(event)
# 두 번째 사용자 메시지 생성 및 출력
input_message = HumanMessage(content="제 이름이 뭔지 기억하세요?")
input_message.pretty_print()
# 스트림 모드에서 두 번째 메시지 처리 및 업데이트 출력
for event in app.stream({"messages": [input_message]}, config, stream_mode="updates"):
print_update(event)
# 세 번째 사용자 메시지 생성 및 출력
input_message = HumanMessage(content="제 직업은 AI 연구원이에요")
input_message.pretty_print()
# 스트림 모드에서 세 번째 메시지 처리 및 업데이트 출력
for event in app.stream({"messages": [input_message]}, config, stream_mode="updates"):
print_update(event)
현재까지는 요약이 전혀 이루어지지 않은 것을 확인할 수 있습니다. 이는 목록에 메시지가 6개 밖에 없기 때문입니다.
Output:
================================ Human Message =================================
안녕하세요? 반갑습니다. 제 이름은 테디입니다.
================================== Ai Message ==================================
안녕하세요, 테디님! 반갑습니다. 어떻게 도와드릴까요?
================================ Human Message =================================
제 이름이 뭔지 기억하세요?
================================== Ai Message ==================================
네, 테디님이라고 하셨습니다! 어떻게 도와드릴까요?
================================ Human Message =================================
제 직업은 AI 연구원이에요
================================== Ai Message ==================================
멋진 직업이네요, 테디님! AI 연구원으로서 어떤 분야에 주로 관심이 있으신가요? 또는 현재 진행 중인 프로젝트가 있으신가요?
이제 다른 메시지를 추가로 보내보도록 하겠습니다.
input_message = HumanMessage(
content="최근 LLM에 대해 좀 더 알아보고 있어요. LLM에 대한 최근 논문을 읽고 있습니다."
)
# 메시지 내용 출력
input_message.pretty_print()
# 스트림 이벤트 실시간 처리 및 업데이트 출력
for event in app.stream({"messages": [input_message]}, config, stream_mode="updates"):
print_update(event)
이전 메시지들이 삭제되고 요약된 것을 확인할 수 있습니다.
Output:
================================ Human Message =================================
최근 LLM에 대해 좀 더 알아보고 있어요. LLM에 대한 최근 논문을 읽고 있습니다.
================================== Ai Message ==================================
LLM(대규모 언어 모델)에 대한 연구는 정말 흥미로운 분야입니다! 최근 몇 년 동안 많은 발전이 있었고, 다양한 논문들이 발표되고 있습니다. 어떤 특정한 주제나 질문이 있으신가요? 아니면 추천할 만한 논문이나 자료를 찾고 계신가요?
================================ Remove Message ================================
================================ Remove Message ================================
================================ Remove Message ================================
================================ Remove Message ================================
================================ Remove Message ================================
================================ Remove Message ================================
대화 요약:
사용자는 자신을 테디라고 소개하며, AI 연구원이라고 말했습니다. 테디는 최근 LLM(대규모 언어 모델)에 대해 더 알아보고 있으며, 관련 논문을 읽고 있다고 언급했습니다. 대화 중에 테디의 관심사와 진행 중인 프로젝트에 대해 질문이 있었습니다.
마지막 두 개의 메시지만 있더라도 이전 대화 내용에 대해 질문할 수 있습니다. 그 이유는 이전 내용이 요약되어 있기 때문입니다.
input_message = HumanMessage(content="제 이름이 무엇인지 기억하세요?")
# 메시지 내용 출력
input_message.pretty_print()
# 스트림 이벤트 실시간 처리 및 업데이트
for event in app.stream({"messages": [input_message]}, config, stream_mode="updates"):
print_update(event)
Output:
================================ Human Message =================================
제 이름이 무엇인지 기억하세요?
================================== Ai Message ==================================
네, 당신의 이름은 테디입니다. AI 연구원으로서 LLM에 대해 더 알아보고 있다고 하셨죠. 도움이 필요하시면 언제든지 말씀해 주세요!
# 사용자 메시지 객체 생성
input_message = HumanMessage(content="제 직업도 혹시 기억하고 계세요?")
# 메시지 내용 출력
input_message.pretty_print()
# 스트림 이벤트 실시간 처리 및 업데이트 출력
for event in app.stream({"messages": [input_message]}, config, stream_mode="updates"):
print_update(event)
Output:
================================ Human Message =================================
제 직업도 혹시 기억하고 계세요?
================================== Ai Message ==================================
네, 당신은 AI 연구원이라고 말씀하셨습니다. LLM에 대해 더 알아보고 있다고 하셨죠. 추가로 궁금한 점이나 논의하고 싶은 주제가 있다면 말씀해 주세요!
12. 서브그래프 추가 및 사용 방법
SubGraph를 사용하면 여러 구성 요소를 포함하는 복잡한 시스템을 구축할 수 있으며, 이러한 구성 요소 자체가 그래프가 될 수 있습니다. SubGraph의 일반적인 사용 사례는 멀티 에이전트 시스템 구축입니다.
SubGraph를 구축할 때 주요 고려사항은 상위 그래프와 SubGraph가 어떻게 통신하는지, 즉 그래프 실행 중에 상태(State)를 서로 어떻게 전달하는지입니다.
다음 두 가지 시나리오가 있습니다.
- 상위 그래프와 서브그래프가 스키마 키를 공유하는 경우: 이 경우 컴파일된 서브그래프로 노드를 추가할 수 있습니다.
- 상위 그래프와 서브그래프가 서로 다른 스키마를 가지는 경우: 이 경우 서브그래프를 호출하는 노드 함수를 추가해야 합니다.
이는 상위 그래프와 서브그래프가 서로 다른 상태 스키마를 가지고 있고 서브그래프를 호출하기 전후에 상태를 변환해야 할 때 유용합니다.
예제 코드를 통해 각 시나리오에 대한 서브그래프 추가 방법을 알아보도록 하겠습니다.
12.1 Case1: 스키마를 공유하는 경우
컴파일된 SubGraph로 노드 추가하기
상위 그래프와 서브그래프가 공유 상태 키(State Key)를 통해 통신하는 것이 일반적인 사례입니다. 예를 들어, 멀티 에이전트 시스템에서 에이전트들은 주로 공유된 messages를 통해 통신합니다.
서브그래프가 상위 그래프와 상태 키를 공유하는 경우, 다음 단계에 따라 그래프에 추가할 수 있습니다.
- 서브그래프 워크플로우를 정의하고 컴파일
- 상위 그래프 워크플로우를 정의할 때
.add_node메서드에 컴파일된 서브그래프 전달
from langgraph.graph import START, END, StateGraph
from typing import TypedDict
# 서브그래프 상태 정의를 위한 TypedDict 클래스, 부모 그래프와 공유되는 name 키와 서브그래프 전용 family_name 키 포함
class ChildState(TypedDict):
name: str # 부모 그래프와 공유되는 상태 키
family_name: str
# 서브 그래프의 첫 번째 노드, family_name 키에 초기값 설정
def subgraph_node_1(state: ChildState):
return {"family_name": "Lee"}
# 서브 그래프의 두 번째 노드, 서브그래프 전용 family_name 키와 공유 name 키를 결합하여 새로운 상태 생성
def subgraph_node_2(state: ChildState):
# 서브그래프 내부에서만 사용 가능한 family_name 키와 공유 상태 키 name을 사용하여 업데이트 수행
return {"name": f'{state["name"]} {state["family_name"]}'}
# 서브그래프 구조 정의 및 노드 간 연결 관계 설정
subgraph_builder = StateGraph(ChildState)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_node(subgraph_node_2)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2")
subgraph = subgraph_builder.compile()
그래프를 시각화하면 다음과 같습니다.
from langchain_teddynote.graphs import visualize_graph
visualize_graph(subgraph, xray=True)
# 부모 그래프의 상태 정의를 위한 TypedDict 클래스, name 키만 포함
class ParentState(TypedDict):
name: str
company: str
# 부모 그래프의 첫 번째 노드, name 키의 값을 수정하여 새로운 상태 생성
def node_1(state: ParentState):
return {"name": f'My name is {state["name"]}'}
# 부모 그래프 구조 정의 및 서브그래프를 포함한 노드 간 연결 관계 설정
builder = StateGraph(ParentState)
builder.add_node("node_1", node_1)
# 컴파일된 서브그래프를 부모 그래프의 노드로 추가
builder.add_node("node_2", subgraph)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_2", END)
graph = builder.compile()
from langchain_teddynote.graphs import visualize_graph
visualize_graph(subgraph, xray=True)
# 그래프 스트림에서 청크 단위로 데이터 처리 및 각 청크 출력
for chunk in graph.stream({"name": "Teddy"}):
print(chunk)
Output:
{'node_1': {'name': 'My name is Teddy'}}
{'node_2': {'name': 'My name is Teddy Lee'}}
# 그래프 스트리밍 처리를 통한 서브그래프 데이터 청크 단위 순차 출력
# subgraphs 파라미터를 True로 설정하여 하위 그래프 포함 스트리밍 처리
for chunk in graph.stream({"name": "Teddy"}, subgraphs=True):
print(chunk)
Output:
((), {'node_1': {'name': 'My name is Teddy'}})
(('node_2:17be9bfa-082c-47fc-32d9-26a14ec1f885',), {'subgraph_node_1': {'family_name': 'Lee'}})
(('node_2:17be9bfa-082c-47fc-32d9-26a14ec1f885',), {'subgraph_node_2': {'name': 'My name is Teddy Lee'}})
((), {'node_2': {'name': 'My name is Teddy Lee'}})
12.2 Case2: 스키마 키를 공유하지 않는 경우
하위 그래프를 호출하는 노드 함수 추가
더 복잡한 시스템의 경우, 상위 그래프와 완전히 다른 스키마를 가진 하위 그래프를 정의해야 할 수 있습니다(공유되는 상태 키가 없는 경우입니다.)
이러한 경우라면, 하위 그래프를 호출하는 노드 함수를 정의해야 합니다.
이 함수는 하위 그래프를 호출하기 전에 상위 상태(Parent State)를 하위 그래프 상태(Child State)로 변환하고, 노드에서 상태 업데이트를 반환하기 전에 결과를 다시 상위 상태(Parent State)로 변환해야 합니다.
# 서브그래프의 상태 타입 정의 (부모 그래프와 키를 공유하지 않음)
class ChildState(TypedDict):
# 부모 그래프와 공유되지 않는 키들
name: str
# 서브 그래프의 첫 번째 노드: name 키에 초기값 설정
def subgraph_node_1(state: ChildState):
return {"name": "Teddy" + state["name"]}
# 서브그래프의 두 번째 노드: name 값 그대로 반환
def subgraph_node_2(state: ChildState):
return {"name": f'My name is {state["name"]}'}
# 서브그래프 빌더 초기화 및 노드 연결 구성
subgraph_builder = StateGraph(ChildState)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_node(subgraph_node_2)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2")
subgraph = subgraph_builder.compile()
# 부모 그래프의 상태 타입 정의
class ParentState(TypedDict):
family_name: str
full_name: str
# 부모 그래프의 첫 번째 노드: family_name 값 그대로 반환
def node_1(state: ParentState):
return {"family_name": state["family_name"]}
# 부모 그래프의 두 번째 노드: 서브그래프와 상태 변환 및 결과 처리
def node_2(state: ParentState):
# 부모 상태를 서브그래프 상태로 변환
response = subgraph.invoke({"name": state["family_name"]})
# 서브 그래프 응답을 부모 상태로 변환
return {"full_name": response["name"]}
# 부모 그래프 빌더 초기화 및 노드 연결 구성
builder = StateGraph(ParentState)
builder.add_node("node_1", node_1)
# 컴파일된 서브그래프 대신 서브그래프를 호출하는 node_2 함수 사용
builder.add_node("node_2", node_2)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_2", END)
graph = builder.compile()
from langchain_teddynote.graphs import visualize_graph
visualize_graph(graph, xray=True)
# 그래프 스트리밍 처리를 통한 서브그래프 데이터 청크 단위 순차 출력
# subgraphs=True 옵션으로 하위 그래프 포함하여 스트림 데이터 처리
for chunk in graph.stream({"family_name": "Lee"}, subgraphs=True):
print(chunk)
결과를 보면 자식 그래프인 서브그래프의 name 상태에 부모 그래프의 family_name을 넣어 주어 서브그래프를 이용해 full_name 형태를 만들어주고 최종적으로 node_2 마지막 부분에서 다시 부모 그래프의 full_name에 서브그래프에서 만들어준 name 상태를 넣어주는 것을 확인할 수 있습니다.
Output:
((), {'node_1': {'family_name': 'Lee'}})
(('node_2:d01507db-c5cb-9b34-3640-6c07c459dc78',), {'subgraph_node_1': {'name': 'TeddyLee'}})
(('node_2:d01507db-c5cb-9b34-3640-6c07c459dc78',), {'subgraph_node_2': {'name': 'My name is TeddyLee'}})
((), {'node_2': {'full_name': 'My name is TeddyLee'}})
마무리
LangGraph에서 사용되는 핵심 기능들에 대해서 알아보았습니다. 사실 이번 포스트를 준비하면서 핵심 기능 각각만 알아보았고, 또 LangGraph에 대한 지식이 거의 없다시피 해서 각 기능을 알아보고 포스트로 정리를 하면서도 이게 무엇을 하는 기능이고 이러한 기능들이 결국 어떻게 사용되는지는 아직 잘 모르겠다라는 느낌입니다. 그래도 이번 기회에 정리해 놓고 추후에 LangGraph에 대해서 자세히 알게 되었을 때 핵심 기능들을 더 잘 사용하기 위해 참고 자료로써 정리해 놓는 것이 필요하니 그 작업도 미리 해두는 차원에서 이렇게 정리를 해보았습니다.
긴 글 읽어주셔서 감사드리며, 본문 내용 중에 잘못된 내용, 오타 혹은 궁금하신 사항이 있으신 경우에는 댓글 달아주시기 바랍니다.
참조
- 테디노트 - LangChain 한국어 튜토리얼KR(https://wikidocs.net/book/14314)
Comments