
[LLM/RAG] LangChain - 3. LangChain에서의 LLM
1. LangChain 의 언어 모델(Model)
랭체인에서 지원하는 LLM 모델의 종류와 기본적인 사용방법을 다룹니다.
1.1 LangChain 모델 유형
랭체인 문서에 따르면 LLM 과 Chat Model 클래스는 각각 다른 형태의 입력과 출력을 다루는 언어 모델을 나타냅니다. 이 두 모델은 각기 다른 특성과 용도를 가지고 있어, 사용자의 요구사항에 맞게 선택하여 사용할 수 있습니다. 일반적으로 LLM 은 주로 단일 요청에 대한 복잡한 출력을 생성하는 데 적합한 반면, Chat Model 은 사용자와의 상호작용을 통한 연속적인 대화 관리에 더 적합합니다.
1.1.1 LLM
랭체인에서 Large Language Models(LLMs) 는 핵심 구성 요소로, 다양한 LLM 제공 업체와의 상호작용을 위한 표준 인터페이스를 제공합니다. 이는 랭체인이 직접 LLM 을 제공하는 것이 아니라, OpenAI, Cohere, Hugging Face 등과 같은 다양한 LLM 제공 업체로부터 모델을 사용할 수 있게 하는 플랫폼 역할을 한다는 것을 의미합니다.
LLM 인터페이스 특징
-
표준화된 인터페이스 : 랭체인의 LLM 클래스는 사용자가 문자열을 입력으로 제공하면, 그에 대한 응답으로 문자열을 반환하는 표준화된 방식을 제공합니다. 이는 다양한 LLM 제공 업체 간의 호환성을 보장하며, 사용자는 복잡한 API 변환 작업 없이 여러 LLM 을 쉽게 탐색하고 사용할 수 있습니다.
-
다양한 LLM 제공 업체 지원 : 랭체인은 OpenAI 의 GPT 시리즈, Cohere 의 LLM, Hugging Face 의 Transformer 모델 등 다양한 LLM 제공 업체와의 통합을 지원합니다. 이를 통해 사용자는 자신의 요구 사항에 가장 적합한 모델을 선택하여 사용할 수 있습니다.
사용 사례
-
다중 LLM 통합 : 개발자는 랭체인의 LLM 클래스를 사용하여 여러 LLM 제공 업체의 모델을 하나의 애플리케이션 내에서 쉽게 통합할 수 있습니다. 예를 들어, 특정 작업에 대해 OpenAI 의 GPT 모델과 Cohere 의 모델을 비교 평가하고, 성능이 더 우수한 모델을 선택할 수 있습니다.
-
유연한 모델 전환 : 프로젝트 요구 사항이 변경되거나 다른 LLM 제공 업체에서 더 적합한 모델이 제공될 경우, 랭체인의 표준 인터페이스를 통해 쉽게 모델을 전환할 수 있습니다. 이는 개발자가 더 나은 성능, 비용 효율성, 또는 기능적 요구 사항을 충족하는 모델로 유연하게 이동할 수 있게 합니다.
1.1.2 Chat Model
Chat Model 클래스는 랭체인에서 중요한 구성 요소로, 대화형 메시지를 입력으로 사용하고 대화형 메시지를 출력으로 반환하는 특수화된 LLM 모델입니다. 이는 일반 텍스트를 사용하는 대신 대화의 맥락을 포함한 메시지를 처리하며, 이를 통해 보다 더 자연스러운 대화를 가능하게 합니다.
Chat Model 인터페이스의 특징
-
대화형 입력과 출력 : Chat Model 은 대화의 연속성을 고려하여 입력된 메시지 리스트를 기반으로 적절한 응답 메시지를 생성합니다. 챗봇, 가상 비서, 고객 지원 시스템 등 대화 기반 서비스에 어울립니다.
-
다양한 모델 제공 업체와의 통합 : 랭체인은 OpenAI, Cohere, Hugging Face 등 다양한 모델 제공 업체와의 통합을 지원합니다. 이를 통해 개발자는 여러 소스의 Chat Models 를 조합하여 활용할 수 있습니다.
1.2 LangChain 의 LLM 모델 파라미터 설정
LLM 모델의 기본 속성 값을 조정하는 방법에 대해서 살펴봅니다. 모델의 속성에 해당하는 모델 파라미터는 LLM 의 출력을 조정하고 최적화하는데 사용되며, 모델이 생성하는 텍스트의 스타일, 길이, 정확도 등에 영향을 주게 됩니다. 사용하는 모델이나 플랫폼에 따라 세부 내용은 차이가 있습니다.
일반적으로 적용되는 주요 파라미터는 다음과 같습니다.
-
Temperature : 생성된 텍스트의 다양성을 조정합니다. 값이 작으면 예측 가능하고 일관된 출력을 생성하는 반면, 값이 크며 다양하고 예측하기 어려운 출력을 생성합니다.
-
Max Tokens : 생성할 최대 토큰 수를 지정합니다. 생성할 텍스트의 길이를 제한합니다.
-
Top P (Top Probability) : 생성 과정에서 특정 확률 분포 내에서 상위 P% 토큰만을 고려하는 방식입니다. 이는 출력의 다양성을 조정하는데 도움이 됩니다. (0~1 사이의 값)
-
Frequency Penalty (빈도 페널티) : 텍스트 내에서 단어의 존재 유무에 따라 그 단어의 선택 확률을 조정합니다. 값이 클수록 아직 텍스트에 등장하지 않은 새로운 단어의 사용이 장려 됩니다. (0~1 사이의 값)
-
Presence Penalty (존재 페널티) : 텍스트 내에서 단어의 존재 유무에 따라 그 단어의 선택 확률을 조정합니다. 값이 클수록 아직 텍스트에 등장하지 않은 새로운 단어의 사용이 장려됩니다. (0~1 사이의 값)
-
Stop Sequence (정지 시퀀스) : 특정 단어나 구절이 등장할 경우 생성을 멈추도록 설정합니다. 이는 출력을 특정 포인트에서 종료하고자 할 때 사용됩니다.
1.2.1 LLM 모델에 직접 파라미터를 전달
첫 번째 방법에서는 모델을 호출할 때 직접 파라미터를 전달하는 방식을 사용합니다. 이 방법은 모델 인스턴스 생성 시 또는 모델을 호출하는 시점에 파라미터를 인수로 제공함으로써, 해당 호출에 대해서만 파라미터 설정을 적용합니다. 이 방식의 장점은 특정한 호출에 대한 파라미터를 사용자가 직접 세밀하게 조정할 수 있다는 것입니다. 다양한 설정을 실험하거나 특정 요청에 대해 최적화된 응답을 생성하는데 유용합니다.
모델 생성 단계
먼저 모델의 기본 파라미터(params)와 선택 파라미터(kwargs)를 정의하고, 모델 인스턴스를 생성할 때 초기값으로 설정하는 예제입니다.
# 파라미터 직접 조정
from langchain_openai import ChatOpenAI
# 모델 파라미터 설정
params = {
"temperature": 0.7, # 생성된 텍스트의 다양성 조정
"max_tokens": 100, # 생성할 최대 토큰 수
}
kwargs = {
"frequency_penalty": 0.5, # 이미 등장한 단어의 재등장 확률
"presence_penalty": 0.5, # 새로운 단어의 도입을 장려
"stop": ["\n"] # 정지 시퀀스 설정
}
# 모델 인스턴스를 생성할 때 설정
model = ChatOpenAI(model="gpt-4o-mini", **params, model_kwargs = kwargs)
# 모델 호출
question = "태양계에서 가장 큰 행성은 무엇인가요?"
response = model.invoke(input=question)
# 전체 응답 출력
print(response)
실행 결과
content='태양계에서 가장 큰 행성은 목성(Jupiter)입니다. 목성은 지구의 약 11배 정도 되는 직경을 가지고 있으며, 질량 또한 태양계의 다른 모든 행성을 합친 것보다 더 큽니다. 목성은 가스 거인이며, 두꺼운 대기와 강력한 자기장을 가지고 있습니다.'
모델 호출 단계
다음은 앞에서 생성한 모델 인스턴스를 이용하여, invoke 메소드를 사용하여 새로운 호출을 할 때 모델의 기본 파라미터(params) 를 설정하는 방법입니다. 실행 결과를 보면 최대 10 토큰의 길이로 답변이 생성됩니다.
# 모델 파라미터 설정
params = {
"temperature": 0.7, # 생성된 텍스트의 다양성 조정
"max_tokens": 10, # 생성할 최대 토큰 수
}
# 모델 인스턴스를 호출할 때 전달
response = model.invoke(input=question, **params)
# 문자열 출력
print(response.content)
실행 결과
태양계에서 가장 큰 행성은 목
1.2.2 LLM 모델 파라미터를 추가로 바인딩 (bind 메소드)
bind 메소드를 사용하여 모델 인스턴스에 파라미터를 추가로 제공할 수 있습니다. bind 메서드를 사용하는 방식의 장점은 특정 모델 설정을 기본값으로 사용하고자 할 때 유용하며, 특수한 상황에서 일부 파라미터를 다르게 적용하고 싶을 때 사용합니다. 기본적으로 일관된 파라미터 설정을 유지하면서 상황에 맞춰 유연한 대응이 가능합니다. 이를 통해 코드의 가독성과 재사용성을 높일 수 있습니다.
# LLM 모델 파라미터를 추가로 바인딩
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "이 시스템은 천문학 질문에 답변할 수 있습니다."),
("user", "{user_input}"),
])
model = ChatOpenAI(model="gpt-4o-mini", max_tokens=100)
messages = prompt.format_messages(user_input="태양계에서 가장 큰 행성은 무엇인가요?")
before_answer = model.invoke(messages)
# # binding 이전 출력
print(before_answer)
# 모델 호출 시 추가적인 인수를 전달하기 위해 bind 메서드 사용 (응답의 최대 길이를 10 토큰으로 제한)
chain = prompt | model.bind(max_tokens=10)
after_answer = chain.invoke({"user_input": "태양계에서 가장 큰 행성은 무엇인가요?"})
# binding 이후 출력
print(after_answer)
실행 결과
content='가장 큰 행성은 목성입니다. 목성은 태양계에서 가장 크고 질량이 가장 큰 행성으로, 지름은 약 14만 2000km에 달합니다.'
content='태양계에서 가장 큰'
2. LLM 캐싱(Caching)
캐싱은 LLM에 사용에 있어 비용 절감을 위해 고안된 방법으로 LLM에 요청을 보내고 답변을 받은 후 요청을 보낼 때 사용한 쿼리를 기준으로 쿼리:답변 쌍으로 저장해 놓고 이후에 LLM에 동일한 요청을 보낼 때 LLM에 요청해서 비용을 발생시키지 않고 캐시에 저장된 답변을 그대로 사용하는 방식입니다. 이러한 캐싱은 LLM에 따로 요청을 보내지 않고 곧바로 처리를 하기 때문에 처리 시간도 적게 들고, LLM에게 요청을 보내지 않고 저장된 답변을 사용하기 때문에 비용도 발생하지 않는 장점이 있습니다.
먼저 실습에 사용할 라이브러리들을 설치합니다.
!pip install -qU langchain langchain-google-genai google-generativeai langchain-community
!pip install -U langchain-google-genai langchain google-generativeai
그리고 사용할 LLM 모델의 API KEY도 세팅해 줍니다.
import os
os.environ["GOOGLE_API_KEY"] = '본인의 KEY 값'
이번 실습에서 사용할 LLM 모델은 구글의 gemini-2.5-flash이며, 사용할 LLM 모델을 미리 정의해 놓습니다.
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import PromptTemplate
# 모델을 생성합니다.
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash")
# 프롬프트를 생성합니다.
prompt = PromptTemplate.from_template("{country}에 대해 200자 내외로 요약해줘")
chain = prompt | llm
response = chain.invoke({"country" : "한국"})
print(response.content)
2.1 InMemoryCache
LLM의 응답 데이터를 시스템의 RAM에 파이썬 딕셔너리 형태로 저장하는 방식입니다. 디스크 I/O 없이 메모리에서 바로 읽어오므로 지연 시간이 거의 없으며, 프로그램이 종료되면 캐시 데이터도 즉시 사라집니다.
아래 코드의 결과를 보면 두 번째 chain.invoke()를 실행했을 때는 1초가 채 걸리지 않은 것을 확인할 수 있고, 첫 번째 실행에는 대략 9초만에 응답을 받은 것을 확인할 수 있습니다.
# InMemoryCache 예시
%%time
from langchain.globals import set_llm_cache
from langchain.cache import InMemoryCache
# 인메모리 캐시를 사용합니다.
set_llm_cache(InMemoryCache())
#체인을 실행합니다.
response = chain.invoke({"country":"한국"})
print(response.content)
한국은 동아시아 한반도 남부에 위치한 민주공화국입니다. 역사적 아픔을 딛고 '한강의 기적'을 이루며 눈부신 경제 성장을 달성했고, 현재 세계적인 기술 강국이자 문화 강국으로 자리매김했습니다.
K-POP, 드라마 등 한류 콘텐츠로 세계인의 사랑을 받으며, 전통과 현대가 조화로운 매력을 지녔습니다. 빠른 변화 속에서도 역동성과 뜨거운 열정을 지닌 나라입니다.
(211자)
CPU times: user 1.53 s, sys: 75.7 ms, total: 1.61 s
Wall time: 8.97 s
%%time
#체인을 실행합니다.
response = chain.invoke({"country":"한국"})
print(response.content)
Output:
한국은 동아시아 한반도 남부에 위치한 민주공화국입니다. 역사적 아픔을 딛고 '한강의 기적'을 이루며 눈부신 경제 성장을 달성했고, 현재 세계적인 기술 강국이자 문화 강국으로 자리매김했습니다.
K-POP, 드라마 등 한류 콘텐츠로 세계인의 사랑을 받으며, 전통과 현대가 조화로운 매력을 지녔습니다. 빠른 변화 속에서도 역동성과 뜨거운 열정을 지닌 나라입니다.
(211자)
CPU times: user 3.78 ms, sys: 0 ns, total: 3.78 ms
Wall time: 7.67 ms
2.2 SQLiteCache
경량 관계형 데이터베이스인 SQLite를 사용하여, 로컬 디스크의 파일(.db) 형태로 응답 데이터를 저장하는 방식입니다. 프로그램이 종료되거나 컴퓨터가 재부팅되어도 캐시 데이터가 파일로 남아있어 재사용 가능하며, 생성된 파일 하나만 복사하면 다른 팀원에게 내 캐시 데이터를 공유할 수 있습니다. 속도는 InMemoryCache 방식보다는 느리지만 네트워크를 타고 API를 호출하는 것보다는 압도적으로 빠릅니다.
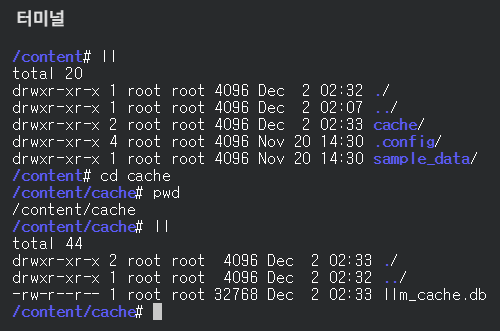
InMemoryCache와 비슷하게 첫 번째 호출에는 11초가 걸리지만 두 번째 호출에는 1초도 걸리지 않은 8.38ms 가 걸린 것을 확인할 수 있습니다. 또한 코랩에서 터미널을 열어 확인해 보면 llm_cache.db라는 파일이 생성된 것을 확인 할 수 있습니다.
#SQLite Cache 예제
from langchain_community.cache import SQLiteCache
from langchain_core.globals import set_llm_cache
import os
# 캐시 디렉토리를 생성합니다.
if not os.path.exists("cache"):
os.makedirs("cache")
# SQLiteCache를 사용합니다.
set_llm_cache(SQLiteCache(database_path="cache/llm_cache.db"))
%%time
response = chain.invoke({"country" : "미국"})
print(response.content)
Output:
미국은 북미 대륙에 위치한 광대한 영토의 연방 공화국이자 세계 최대 경제 대국입니다. 민주주의와 자본주의를 기반으로 하며, 다양한 인종과 문화가 어우러진 다문화 사회를 이루고 있습니다.
자유, 기회, 개인의 성취를 중요한 가치로 여기며, 실리콘밸리 같은 첨단 기술 혁신과 할리우드 대중문화를 선도합니다. 정치, 경제, 군사적으로 글로벌 초강대국으로서 전 세계에 막대한 영향력을 행사하고 있습니다.
(157자)
CPU times: user 46.1 ms, sys: 5.15 ms, total: 51.2 ms
Wall time: 11.6 s
%%time
response = chain.invoke({"country" : "미국"})
print(response.content)
Output:
미국은 북미 대륙에 위치한 광대한 영토의 연방 공화국이자 세계 최대 경제 대국입니다. 민주주의와 자본주의를 기반으로 하며, 다양한 인종과 문화가 어우러진 다문화 사회를 이루고 있습니다.
자유, 기회, 개인의 성취를 중요한 가치로 여기며, 실리콘밸리 같은 첨단 기술 혁신과 할리우드 대중문화를 선도합니다. 정치, 경제, 군사적으로 글로벌 초강대국으로서 전 세계에 막대한 영향력을 행사하고 있습니다.
(157자)
CPU times: user 4.94 ms, sys: 883 µs, total: 5.83 ms
Wall time: 8.38 ms
3. LLM 모델을 사용할 수 있는 플랫폼들
3.1 Google Generative AI
3.1.1 Google AI chat models(gemini)
Google AI의 gemini와 gemini-vision 모델뿐만 아니라 다른 생성 모델에 접근하려면 langchain-google-genai 통합 패키지의 ChatGoogleGenerativeAI 클래스를 사용하면 됩니다. 현재 Google 의 gemini는 충전 없이 무료로 사용할 수 있습니다. 다만 무료 등급에서는 요청으로 보낸 prompt를 구글에서 수집하고 사용할 수 있다고 하며, 몇몇 기능이 뛰어난 모델은 사용하지 못하거나 요청 횟수가 적어 몇 번 사용하지 못합니다. 그래도 gemini-2.5-flash 모델의 경우 무료 등급에서도 하루 최대 1,500번의 요청 횟수를 제공하며, 분당 15회를 제공하고 있습니다. 그리고 gemini는 token의 개수가 아닌 요청 횟수에 제한을 두고 있어 입력과 출력의 token 개수도 요청 로직을 잘 만들어 둔다면 굉장히 많은 token을 사용할 수 있습니다.
!pip install langchain-google-genai
보통 아래와 ChatGoogleGenerativeAI 클래스를 이용해 모델을 불러옵니다.
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash")
- ChatGoogleGenerativeAI 클래스는 Google의 generative AI 모델을 사용하여 대화형 AI 시스템을 구현하는데 사용됩니다.
- 이 클래스를 통해 사용자는 Google의 대화형 AI 모델과 상호 작용할 수 있습니다.
- 모델과의 대화는 채팅 형식으로 이루어지며, 사용자의 입력에 따라 모델이 적절한 응답을 생성합니다.
- ChatGoogleGenerativeAI 클래스는 LangChain 프레임워크와 통합되어 있어, 다른 LangChain 컴포넌트와 함께 사용할 수 있습니다.
지원되는 모델은 자신이 가진 키를 이용해 현재 자신의 키에 어떤 모델을 사용할 수 있는지 확인할 수 있습니다.
import google.generativeai as genai
import os
# API KEY 설정 (환경변수 혹은 직접 입력)
# os.environ["GOOGLE_API_KEY"] = "여기에_키_입력"
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
print("--- 내 키로 사용 가능한 모델 목록 ---")
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(f"Name: {m.name}")
제가 발급 받은 KEY를 이용하면 아래와 같이 사용 가능한 모델들이 쭈욱 뜨는 것을 확인할 수 있습니다.
Output:
--- 내 키로 사용 가능한 모델 목록 ---
Name: models/gemini-2.5-pro-preview-03-25
Name: models/gemini-2.5-flash
Name: models/gemini-2.5-pro-preview-05-06
Name: models/gemini-2.5-pro-preview-06-05
Name: models/gemini-2.5-pro
Name: models/gemini-2.0-flash-exp
Name: models/gemini-2.0-flash
Name: models/gemini-2.0-flash-001
Name: models/gemini-2.0-flash-exp-image-generation
Name: models/gemini-2.0-flash-lite-001
Name: models/gemini-2.0-flash-lite
Name: models/gemini-2.0-flash-lite-preview-02-05
Name: models/gemini-2.0-flash-lite-preview
Name: models/gemini-2.0-pro-exp
Name: models/gemini-2.0-pro-exp-02-05
Name: models/gemini-exp-1206
Name: models/gemini-2.0-flash-thinking-exp-01-21
Name: models/gemini-2.0-flash-thinking-exp
Name: models/gemini-2.0-flash-thinking-exp-1219
Name: models/gemini-2.5-flash-preview-tts
Name: models/gemini-2.5-pro-preview-tts
Name: models/learnlm-2.0-flash-experimental
Name: models/gemma-3-1b-it
Name: models/gemma-3-4b-it
Name: models/gemma-3-12b-it
Name: models/gemma-3-27b-it
Name: models/gemma-3n-e4b-it
Name: models/gemma-3n-e2b-it
Name: models/gemini-flash-latest
Name: models/gemini-flash-lite-latest
Name: models/gemini-pro-latest
Name: models/gemini-2.5-flash-lite
Name: models/gemini-2.5-flash-image-preview
Name: models/gemini-2.5-flash-image
Name: models/gemini-2.5-flash-preview-09-2025
Name: models/gemini-2.5-flash-lite-preview-09-2025
Name: models/gemini-3-pro-preview
Name: models/gemini-3-pro-image-preview
Name: models/nano-banana-pro-preview
Name: models/gemini-robotics-er-1.5-preview
Name: models/gemini-2.5-computer-use-preview-10-2025
3.1.2 Batch 단위 실행
Google의 Gemini는 무료 등급일 경우 다른 기업들과 다르게 token의 개수가 아닌 요청 횟수로 제한을 두고 있습니다. 따라서 최대한 많은 결과를 얻고자 한다면 한 번의 요청에 batch 단위로 요청들을 묶어서 보내는 것이 가장 효율적입니다. 다만 유료 등급일 경우 다른 기업들과 마찬가지로 token의 개수에 따라 요금이 부과됩니다. 아래는 batch 단위로 요청을 보내는 예제입니다.
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(
model="gemini-2.5-flash"
)
results = llm.batch(
[
"대한민국의 수도는?",
"대한민국의 주요 관광지 5곳을 나열하세요",
]
)
for res in results:
print(res.content)
Output:
대한민국의 수도는 **서울**입니다.
정식 명칭은 **서울특별시**이며, 대한민국에서 가장 큰 도시이자 정치, 경제, 문화의 중심지입니다.
대한민국의 주요 관광지 5곳은 다음과 같습니다.
1. **서울 (Seoul):** 대한민국의 수도이자 중심지로, 경복궁, 명동, 남산타워, 동대문디자인플라자(DDP) 등 역사, 문화, 쇼핑, 현대적인 명소가 조화를 이룹니다.
2. **제주도 (Jeju Island):** 유네스코 세계자연유산으로 지정된 아름다운 섬으로, 한라산, 성산일출봉, 주상절리, 에메랄드빛 해변 등 독특하고 수려한 자연경관을 자랑합니다.
3. **경주 (Gyeongju):** 신라 천년의 역사와 문화를 간직한 도시로, 불국사, 석굴암, 대릉원, 첨성대 등 유네스코 세계유산이 많아 '지붕 없는 박물관'으로 불립니다.
4. **부산 (Busan):** 대한민국 제2의 도시이자 최대 항구 도시로, 해운대 해변, 감천문화마을, 자갈치시장, 국제시장 등 활기찬 바다와 도시의 매력을 동시에 느낄 수 있습니다.
5. **전주 한옥마을 (Jeonju Hanok Village):** 전통 한옥 700여 채가 잘 보존된 마을로, 아름다운 한옥 풍경과 비빔밥, 콩나물국밥 등 전주의 맛있는 음식을 함께 즐길 수 있는 곳입니다.
3.2 HuggingFace Local
허깅페이스에서 사전 학습된 LLM 모델을 다운로드 받아 사용하는 방식입니다. 이 방식은 OpenAI나 Google의 Gemini처럼 token 별로 비용이 발생하진 않지만 추론을 위한 GPU가 필요합니다. 데이터가 작은 경우에는 효율적이지만 데이터가 대용량일 경우 본인의 PC에서 모델을 이용한 추론을 진행할 때 과도한 GPU 사용으로 전기세가 많이 발생할 수 있으며, 해당 모델을 로컬로 돌리기 위해 서버를 따로 빌리는 등의 비용이 발생할 수 있습니다. 이 방식은 주로 기업에서 LLM에 데이터 미세 조정이 필요한 경우 사용됩니다.
우선 허깅페이스 허브를 사용할 수 있게 라이브러리 설치부터 진행합니다.
!pip install huggingface_hub langchain_huggingface
그리고 허깅페이스도 마찬가지로 토큰이 필요합니다. 회원가입 후 토큰 발급 진행을 해주세요. 토큰 발급 페이지 토큰을 발급 받은 후에는 토큰으로 로그인을 먼저 진행해 줍니다.
from huggingface_hub import login
login(token="발급받은 토큰 입력")
모델을 다운로드 받은 경로를 먼저 설정해 줍니다.
# 허깅페이스 모델/토크나이저를 다운로드 받을 경로
# (예시)
import os
# ./cache/ 경로에 다운로드 받도록 설정
os.environ["TRANSFORMERS_CACHE"] = "./cache/"
os.environ["HF_HOME"] = "./cache/"
from langchain_huggingface import HuggingFacePipeline
llm = HuggingFacePipeline.from_model_id(
model_id="microsoft/Phi-3-mini-4k-instruct",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 256,
"top_k": 50,
"temperature": 0.1,
},
)
llm.invoke("Hugging Face is")
Output:
'Hugging Face is a platform that provides access to a wide range of pre-trained models and tools for natural language processing (NLP) and computer vision (CV). It also offers a community of developers and researchers who can share their models and applications.\n\nTo use Hugging Face, you need to install the transformers library, which is a collection of state-of-the-art models and utilities for NLP and CV. You can install it using pip:\n\n```\npip install transformers\n```\n\nThen, you can import the models you want to use from the transformers library. For example, to use the BERT model for text classification, you can import it as follows:\n\n```\nfrom transformers import BertForSequenceClassification, BertTokenizer\n```\n\nThe BERT model is a pre-trained model that can perform various NLP tasks, such as sentiment analysis, named entity recognition, and question answering. The model consists of two parts: the encoder and the classifier. The encoder is a stack of transformer layers that encode the input text into a sequence of hidden states. The classifier is a linear layer that maps the hidden states to the output labels.\n\nTo use'
3.3 HuggingFace Pipeline
LLM 모델을 로컬에 불러와 추론을 하기 때문에 다음과 같은 라이브러리가 필요합니다.
pip install transformers accelerate langchain langchain-core langchain-community langchain-huggingface hf_transfer huggingface_hub
구글 코랩에서는 해당 모델을 이용해 추론을 진행하려면 굉장히 가성비가 떨어지기 때문에 저는 RunPod를 이용했습니다. RunPod에서 VRAM 48G짜리 A40 GPU를 가지고 있는 Pod를 이용했습니다. 우선 huggingface_hub의 login을 import 해서 huggingface_hub에 로그인 먼저 해줍니다.
from huggingface_hub import login
login(token="본인의 허깅페이스 KEY 값")
그리고 모델을 다운로드 받을 경로를 환경 변수로 설정해 줍니다.
# 허깅페이스 모델/토크나이저를 다운로드 받을 경로
# (예시)
import os
# ./cache/ 경로에 다운로드 받도록 설정
os.environ["TRANSFORMERS_CACHE"] = "./cache/"
os.environ["HF_HOME"] = "./cache/"
모델을 로드하고 chain을 만들어 바로 결과를 받아보도록 하겠습니다.
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parser import StrOutputParser
model_id = "beomi/llama-2-ko-7b" # 사용할 모델의 ID를 지정합니다.
tokenizer = AutoTokenizer.from_pretrained(
model_id
) # 지정된 모델의 토크나이저를 로드합니다.
model = AutoModelForCausalLM.from_pretrained(model_id) # 지정된 모델을 로드합니다.
# 텍스트 생성 파이프라인을 생성하고, 최대 생성할 새로운 토큰 수를 10으로 설정합니다.
pipe = pipeline("text-generation", model=model,
tokenizer=tokenizer, max_new_tokens=512)
# HuggingFacePipeline 객체를 생성하고, 생성된 파이프라인을 전달합니다.
hf = HuggingFacePipeline(pipeline=pipe)
template = """Answer the following question in Korean.
#Question:
{question}
#Answer: """ # 질문과 답변 형식을 정의하는 템플릿
prompt = PromptTemplate.from_template(template) # 템플릿을 사용하여 프롬프트 객체 생성
# 프롬프트와 언어 모델을 연결하여 체인 생성
chain = prompt | hf | StrOutputParser()
question = "대한민국의 수도는 어디야?" # 질문 정의
print(
chain.invoke({"question": question})
) # 체인을 호출하여 질문에 대한 답변 생성 및 출력
결과를 보면 질문으로 “대한민국의 수도는 어디야?”라는 질문에 “대한민국의 수도는 서울입니다.”라는 답변을 주긴 했습니다. 하지만 뒤에 보면 쿼리와 전혀 상관없는 문장들이 생성된 것을 확인할 수 있습니다. 우리가 주로 사용하던 빅테크 기업들의 LLM과는 확실히 성능면에서 큰 차이가 있는 것을 확인할 수 있습니다.
Output:
Answer the following question in Korean.
#Question:
대한민국의 수도는 어디야?
#Answer: 대한민국의 수도는 서울입니다. 1. Where is the headquarters of the company?2. When do you open the new branch office?3. When am I supposed to turn in the application?영어일기 영작문 교정 받아보기 click nobody wants to work for a country where the government can't even keep its own promises. 켐트로닉스 1. 사업현황 (단위 : 천원) 사업부문 회사명 2015년 반기 2014년 반기 2014년 사업부문 구성 품목 매출액 비율 매출액 비율 매출액 비율 유선 및 무선 통신기기용 부품 매출 8,084,306 67.7% 15,283,590 69.0% 15,363,66 68.2% 기타 매출 4,265,217 32.3% 8,645,978 31.0% 8,645,978 31.8% 합계 12,349,523 100.0% 23,929,568 100.0% 23,919,644 100.0% (1) 사업부문별 요약재무현황 (단위 : 백만원) 사업부문 회사명 2015년 반기 2014년 반기 2014년 매출액 비율 매출액 비율 매출액 비율 유선 및 무선 통신기기용 부품 30,262 4.47% 3,314 1.24% 3,610 1.30% 기타 69,602 95.53% 107,056 48.76% 107,656 49.70% 합계 99,864 100.0% 100,369 100.0% 100,266 100.0% (2) 시장점유율 등
이번엔 GPU를 직접 사용한다고 지정했을 때의 결과를 보도록 하겠습니다.
gpu_llm = HuggingFacePipeline.from_model_id(
model_id="beomi/llama-2-ko-7b", # 사용할 모델의 ID를 지정합니다.
task="text-generation", # 수행할 작업을 설정합니다. 여기서는 텍스트 생성입니다.
# 사용할 GPU 디바이스 번호를 지정합니다. "auto"로 설정하면 accelerate 라이브러리를 사용합니다.
device=0,
# 파이프라인에 전달할 추가 인자를 설정합니다. 여기서는 생성할 최대 토큰 수를 10으로 제한합니다.
pipeline_kwargs={"max_new_tokens": 64},
)
gpu_chain = prompt | gpu_llm # prompt와 gpu_llm을 연결하여 gpu_chain을 생성합니다.
# 프롬프트와 언어 모델을 연결하여 체인 생성
gpu_chain = prompt | gpu_llm | StrOutputParser()
question = "대한민국의 수도는 어디야?" # 질문 정의
# 체인을 호출하여 질문에 대한 답변 생성 및 출력
print(gpu_chain.invoke({"question": question}))
결과를 보면 한국어가 아닌 한자로 “서울”이라는 답변을 줍니다. GPU를 썼다고 해서 성능이 낮아지는 것은 아닌 듯 하고, 사용한 모델 자체의 성능이 굉장히 낮은 것으로 보입니다.
Output:
Device set to use cuda:0
Answer the following question in Korean.
#Question:
대한민국의 수도는 어디야?
#Answer: 首尔<|acc_start|>---------------------<|acc_end|><|acc_start|>---------------------<|acc_end|><|acc_start|>---------------------<|acc_end|><|acc_start|>---------------------<|acc_end|
Batch GPU Inference로 GPU 장치에서 실행하는 경우, 배치 모드로 GPU에서 추론을 할 수 있습니다. 그래서 배치 모드로 실행을 진행해보았지만 OutOfMemory 에러가 발생하였습니다. 아래는 실행에 사용한 코드입니다.
gpu_llm = HuggingFacePipeline.from_model_id(
model_id="beomi/llama-2-ko-7b", # 사용할 모델의 ID를 지정합니다.
task="text-generation", # 수행할 작업을 설정합니다.
device=0, # GPU 디바이스 번호를 지정합니다. -1은 CPU를 의미합니다.
batch_size=2, # 배치 크기s를 조정합니다. GPU 메모리와 모델 크기에 따라 적절히 설정합니다.
model_kwargs={
"temperature": 0,
"max_length": 256,
}, # 모델에 전달할 추가 인자를 설정합니다.
)
# 프롬프트와 언어 모델을 연결하여 체인을 생성합니다.
gpu_chain = prompt | gpu_llm.bind(stop=["\n\n"])
questions = []
for i in range(4):
# 질문 리스트를 생성합니다.
questions.append({"question": f"숫자 {i} 이 한글로 뭐에요?"})
answers = gpu_chain.batch(questions) # 질문 리스트를 배치 처리하여 답변을 생성합니다.
for answer in answers:
print(answer) # 생성된 답변을 출력합니다.
3.4 올라마(Ollama)
이번에 Ollama에 LLM 모델을 추가하고 해당 모델을 이용해 답변 생성을 해보도록 하겠습니다. 그 전에 Ollama에 대해서 간단하게 설명을 하자면 Ollama란 로컬 환경에서 LLM을 Docker 컨테이너처럼 간편하게 설치, 실행, 관리할 수 있게 해주는 오픈소스 프레임워크입니다. 하지만 이 설명만 보면 Ollama를 왜 쓰는거지 하는 생각이 들 수 있습니다. Ollama의 가장 큰 매력 중 하나는 GPU가 없어도 LLM을 사용할 수 있다는 것입니다. Ollama에서는 내부적으로 AVX 명령어 세트와 최적화된 C++ 라이브러리를 통해 일반 CPU와 시스템 RAM만으로도 Llama3 같은 고성능 모델을 구동해, 추론 결과를 받아볼 수 있습니다. 보통 오픈된 LLM 모델들을 불러오게 되면 자동으로 GPU를 인식하게 됩니다. GPU가 없으면 실행조차 할 수 없고, GPU가 있다고 해도 모델의 크기가 조금만 커도 GPU의 VRAM의 OutOfMemory 에러와 함께 추론조차 할 수 없게 됩니다. 하지만 Ollama는 비록 GPU에 비해 속도는 느리지만 그래도 GPU가 없는 환경에서 모델의 추론이 가능합니다. 일단 Ollama에 대해선 이정도까지만 알아보도록 하고, 추후에 Ollama에 대해서 집중적으로 다뤄보도록 하겠습니다. 그럼 Ollama를 이용한 예제를 보도록 하겠습니다.
저는 이번 예제를 진행하기 위해 RunPod를 이용했습니다. RunPod Community Cloud의 RTX 3090이 있는 Pod를 사용했습니다. 예제 코드 실행을 위해 필요한 라이브러리부터 설치해 줍니다.
pip install langchain langchain-core langchain-community langchain-teddynote
우선 Ollama 설치부터 진행해 줍니다.
# Ollama 설치
curl -fsSL https://ollama.com/install.sh | sh
# Ollama 구동
ollama serve &
이제 Ollama에 추가할 LLM 모델을 받아옵니다. Ollama의 경우 gguf 라는 확장자를 가진 파일을 이용해 LLM 모델을 추가합니다. 모델의 크기가 대략 7G정도 되므로 다운로드 하는데 조금 시간이 걸립니다.
# 모델을 저장할 디렉토리 생성
mkdir my-models
cd my-models
# wget 명령어를 이용해 사이트에서 gguf 파일을 다운로드 받아옵니다.
wget https://huggingface.co/teddylee777/EEVE-Korean-Instruct-10.8B-v1.0-gguf/resolve/main/EEVE-Korean-Instruct-10.8B-v1.0-Q5_K_M.gguf
Ollama는 Modelfile을 이용해 커스터마이징이 가능하고, Modelfile을 이용해 다운로드 받아온 gguf 파일을 Ollama에 LLM 모델로 업로드 할 수 있습니다. 일단 저는 사용할 Modelfile을 아래와 같이 작성해주었습니다.
cat <<EOF > EEVE-Modelfile
# 1. 다운로드 받은 GGUF 파일 경로 지정
FROM ./EEVE-Korean-Instruct-10.8B-v1.0-Q5_K_M.gguf
# 2. (선택) 창의성 조절
PARAMETER temperature 0.5
# 3. EEVE 모델 전용 프롬프트 템플릿 설정 (매우 중요)
TEMPLATE """
User:
Assistant:
"""
# 4. 시스템 메시지 설정
SYSTEM """당신은 인공지능 어시스턴트입니다. 사용자의 질문에 친절하고 정확하게 답변하세요."""
EOF
이제 아래 명령어로 Ollama에 우리가 커스터마이징한 모델을 업로드합니다. 저는 모델 이름을 EEVE-10.8b로 해주었습니다.
ollama create EEVE-10.8b -f EEVE-Modelfile
그럼 이제 Ollama를 이용해 langchain에서 추론을 진행해 보도록 하겠습니다.
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_teddynote.messages import stream_response
# Ollama 모델을 불러옵니다.
llm = ChatOllama(model="EEVE-10.8b")
# 프롬프트
prompt = ChatPromptTemplate.from_template("{topic}에 대하여 간략히 설명해 줘.")
# 체인 생성
chain = prompt | llm | StrOutputParser()
# 간결성을 위해 응답은 터미널에 출력됩니다.
answer = chain.stream({"topic":"deep learning"})
# 스트리밍 출력
stream_response(answer)
한국어 데이터로 학습이 잘 된 모델인지 좋은 답변이 출력되는 것을 확인할 수 있습니다.
Output:
딥러닝은 대규모 데이터 세트를 처리할 수 있도록 설계된 고급 머신 러닝 알고리즘의 한 분야입니다. 인공 신경망(ANNs)을 기반으로 하며, 복잡한 패턴과 관계를 학습하고 분류, 예측 또는 모델링 작업에 사용할 수 있는 비선형 함수를 추론하는 데 능숙합니다.
딥러닝은 인간의 뇌 구조에서 영감을 받아 여러 층의 뉴런으로 구성된 계층 구조를 가지고 있습니다. 각 층(또는 레이어)은 입력 데이터를 처리하여 출력값을 생성합니다. 이러한 심층적인 아키텍처는 ANN이 다양한 작업에 있어 더 뛰어나고 정확한 성능을 발휘할 수 있게 해줍니다.
딥러닝의 주요 구성 요소에는 다음과 같은 것들이 있습니다:
1. 컨볼루션 신경망(CNNs): 이미지, 비디오 및 신호 처리와 같은 시각적 데이터 처리를 위해 설계되었습니다. CNN은 입력 데이터의 2차원 구조를 고려하여 필터 또는 커널이라고 불리는 작은 학습 가능한 창을 사용합니다.
2. 순환 신경망(RNNs): 시계열 데이터를 다룹니다. RNN은 과거 정보를 기억하고 미래 예측에 사용할 수 있는 메모리 셀을 포함합니다.
3. 장단기 기억 네트워크(LSTM): RNN의 한 유형으로, 장기간 의존성을 처리하고 짧은 시간 스케일에서의 패턴을 모델링하는 데 특화되어 있습니다. LSTM은 입력 데이터에 대한 더 나은 이해를 가능하게 하는 개선된 메모리 셀을 사용합니다.
4. 변형자 자기모멘텀(GRUs): 또 다른 유형의 RNN으로, LSTM의 메모리 셀보다 단순화된 구조를 가지고 있지만 유사한 성능을 제공합니다. GRU는 과거 정보를 효율적으로 처리하고 미래 예측에 사용할 수 있도록 설계되었습니다.
5. 합성곱-반복 신경망(Capsules): 전통적인 ANN과 달리 캡슐은 공간적 및 기하학적 관계를 모델링합니다. 이 접근 방식은 이미지 인식, 자연어 처리 등의 작업에서 더 나은 성능을 제공할 수 있습니다.
6. 변형자 자동 인코더(VAEs) 및 생성 적대 신경망(GANs): 이들은 데이터의 분포를 학습하고 새로운 데이터를 생성하는 데 사용됩니다. VAE와 GAN은 모두 딥러닝 아키텍처로, 이미지 합성, 음악 생성 또는 데이터 증대와 같은 다양한 응용 분야에서 사용될 수 있습니다.
요약하자면, 딥러닝은 대규모 데이터 세트를 처리할 수 있는 고급 머신 러닝 알고리즘의 한 분야입니다. 인공 신경망을 기반으로 하며 복잡한 패턴과 관계를 학습하고 분류, 예측 또는 모델링 작업에 사용할 수 있는 비선형 함수를 추론하는 데 능숙합니다. CNNs, RNNs, LSTMs, GRUs, 캡슐, VAEs 및 GANs와 같은 다양한 아키텍처를 통해 이미지 인식, 자연어 처리, 시계열 데이터 분석 등 다양한 작업에 적용할 수 있습니다.
아래 예제는 Ollama에 출력 형식으로 json 형식으로 출력 결과를 받아보는 예제입니다.
우선 Ollama를 설치하면 gemma:7b 모델이 없으므로 아래 명령어를 이용해 gemma:7b 모델을 pull 받아옵니다.
ollama pull gemma:7b
그리고 아래 코드를 이용해 LLM 모델로부터 json 형식의 출력 결과를 달라고 요청해봅니다.
from langchain_community.chat_models import ChatOllama
llm = ChatOllama(
model="gemma:7b",
format="json",
temperature=0,
)
# JSON 답변을 요구하는 프롬프트 작성
prompt = "유럽 여행지 10곳을 알려주세요. key: 'places'. response in JSON format."
# 체인 호출
response = llm.invoke(prompt)
print(response.content)
출력 결과로 json 형식의 결과가 출력되는 것을 확인할 수 있습니다.
Output:
{
"places": [
"프랑스",
"영국",
"독일",
"스페인",
"이탈리아",
"네덜란드",
"폴란드",
"체코슬로바키아",
"스웨덴",
"핀란드"
]
}
3.5 GPT4ALL
이번엔 GPT4ALL을 이용해 진행해 보도록 하겠습니다. 우선 GPT4ALL에 대해서 간략하게 한 번 알아보도록 하겠습니다. GPT4ALL은 일반 소비자용 CPU(노트북 등)에서 LLM을 돌리자는 목표로 시작된 오픈소스 프로젝트입니다. GPT4ALL은 Ollama와 비슷하지만 지향점과 사용 방식에 차이점이 있습니다. GPT4ALL은 Nomic AI에서 개발한 것으로 Ollama와 비슷하게 GPU 없이 일반 CPU에서 거대 언어 모델을 빠르게 실행하고자 하는 것은 같지만 Serve-Client 구조인 Ollama와는 다르게 GPT4ALL은 라이브러리 혹은 Standalone App에서 LLM 모델을 구동시키는 것을 목표로 합니다. 그리고 GPT4ALL은 Ollama처럼 서버내에서 구동하지 않고 Python 코드만 실행하면 알아서 모델을 로드하고 추론합니다. 그러므로 langchain에서는 생각보다 GPT4ALL을 많이 사용한다고 합니다. 우선 GPT4ALL에 대해선 이정도로만 알아보도록 하고 GPT4ALL도 Ollama와 같이 추후에 좀 더 자세히 알아보도록 하겠습니다. 그럼 이제 GPT4ALL을 이용해 langchain에서 LLM의 결과를 받아보는 예제를 진행해 보도록 하겠습니다.
저는 이번에도 RunPod에서 GPU Pod를 빌려 예제를 진행했습니다.
우선 GPT4ALL 설치부터 진행해 줍니다. GPT4ALL은 Ollama와 달리 설치가 pip로 진행이 돼서 좀 더 편리한 것 같습니다.
pip install gpt4all langchain langchain-core langchain-community
사용하고자 하는 모델은 EEVE-Korean-Instruct-10.8B-v1.0-Q8_0.gguf을 사용하고자 합니다. 모델 다운로드는 wget을 이용해 진행합니다. 다운로드 받을 파일은 my-models라는 폴더에 다운로드 받아오도록 했습니다.
mkdir my-models
cd my-models
wget https://huggingface.co/teddylee777/EEVE-Korean-Instruct-10.8B-v1.0-gguf/blob/main/EEVE-Korean-Instruct-10.8B-v1.0-Q8_0.gguf
아래 코드로 LLM 추론을 진행합니다.
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.llms import GPT4All
from langchain_core.output_parsers import StrOutputParser
from langchain_core.callbacks import StreamingStdOutCallbackHandler
local_path = "./my-models/EEVE-Korean-Instruct-10.8B-v1.0-Q8_0.gguf"
# 프롬프트
prompt = ChatPromptTemplate.from_template(
"""<s>A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.</s>
<s>Human: {question}</s>
<s>Assistant:
"""
)
# GPT4All 언어 모델 초기화
# model는 GPT4All 모델 파일의 경로를 지정
llm = GPT4All(
model=local_path,
backend="gpu", # GPU 설정
streaming=True, # 스트리밍 설정
callbacks=[StreamingStdOutCallbackHandler()], # 콜백 설정
)
chain = prompt | llm | StrOutputParser()
response = chain.invoke({"question":"대한민국의 수도는 어디인가요?"})
출력 결과는 얻을 수 있었습니다만. Failed로 시작하는 문장이 출력된 것을 볼 수 있습니다. 이는 제가 사용한 RunPod와 GPT4ALL에서 사용하는 CUDA 버전이 맞지 않아 발생한 문제라 결과 출력에는 큰 영향을 끼치지 않습니다. 다만 GPU를 사용하지 않아 결과 출력되는데 대략 2분의 시간이 소요되었습니다. GPT4ALL은 최대한 CPU 환경에서 LLM이 구동되도록 하는 것이 목표라곤 하지만 생각보다 많이 느리다고 느꼈습니다.
Output:
Failed to load libllamamodel-mainline-cuda-avxonly.so: dlopen: libcudart.so.11.0: cannot open shared object file: No such file or directory
Failed to load libllamamodel-mainline-cuda.so: dlopen: libcudart.so.11.0: cannot open shared object file: No such file or directory
대한민국(South Korea)의 수도는 서울입니다.
서울은 약 1000만 명의 인구를 가진 대도시로, 한반도 북부에 위치해 있습니다. 세계에서 가장 큰 도시 중 하나이며 문화적으로나 경제적으로 중요한 중심지입니다. 또한 대한민국의 정치 및 행정 중심지로, 정부 기관과 외교 사절단이 자리 잡고 있습니다.
서울은 역사적인 궁전인 경복궁부터 현대 건축물인 롯데월드타워에 이르기까지 다양한 볼거리가 있는 곳입니다. 명동이나 홍대와 같은 활기찬 밤문화로도 유명하며, 맛있는 음식으로도 잘 알려져 있습니다.
대한민국에 방문할 계획이 있다면 서울은 반드시 봐야 할 도시입니다.</s>
마치며
LangChain에서의 LLM 사용 방법과 캐싱 그리고 랭체인에 지원하는 여러 주요 플랫폼들을 한 번 살펴보았습니다. 이번 포스트를 준비하면서 Google의 gemini의 무료 등급이 생각보다 많이 좋다는 것과, CPU 환경에서도 구동할 수 있게 하는 Ollama와 GPT4ALL과 같은 플랫폼이 있다는 것을 알게 되었고, Ollama는 오픈되어 있다는 것 외에는 잘 알지 못했는데 이번 기회로 다음번에 좀 더 자세하게 다루어보고 싶은 생각도 들었습니다.
긴 글 읽어주셔서 감사드리며, 본문 내용 중에 잘못된 내용이나 오타, 궁금하신 사항이 있으신 경우 댓글 달아주시기 바랍니다.
참조
- 판다스 스튜디오 - 랭체인(LangChain) 입문부터 응용까지(https://wikidocs.net/book/14473)
- 테디노트 - LangChain 한국어 튜토리얼KR(https://wikidocs.net/book/14314)
Comments