
[LLM/RAG] LangChain - 9. LangChain에서 사용하는 벡터저장소에 대해서 알아보자
이번 포스트에서는 임베딩 데이터들을 관리하는 벡터스토어에 대해서 알아보도록 하겠습니다.
1. 벡터 저장소(VectorStore) 개요
벡터 저장소(Vector Store)는 벡터 형태로 표현된 데이터, 즉 임베딩 벡터들을 효율적으로 저장하고 검색할 수 있는 시스템이나 데이터베이스를 의미합니다. 자연어 처리(NLP), 이미지 처리, 그리고 기타 다양한 머신러닝 응용 분야에서 생성된 고차원 벡터 데이터를 관리하기 위해 설계되었습니다. 벡터 저장소의 핵심 기능은 대규모 벡터 데이터셋에서 빠른 속도로 가장 유사한 항목을 찾아내는 것입니다.
1.1 벡터 저장소의 필요성
- 빠른 검색 속도: 임베딩 벡터들을 효과적으로 저장하고 색인화함으로써, 대량의 데이터 중에서도 관련된 정보를 빠르게 검색할 수 있습니다.
- 스케일러빌리티: 데이터가 지속적으로 증가함에 따라, 벡터스토어는 이를 수용할 수 있는 충분한 스케일러빌리티를 제공해야 합니다. 효율적인 저장 구조는 데이터 베이스의 확장성을 보장하며, 시스템의 성능 저하 없이 대규모 데이터를 관리할 수 있도록 합니다.
- 의미 검색(Semantic Search) 지원: 키워드 기반 검색이 아닌 사용자의 질문과 의미상으로 유사한 단락을 조회해야하는데, 벡터스토어는 이러한 기능을 지원합니다. 텍스트 자체가 저장되는 DB의 경우 키워드 기반 검색에 의존해야 하는 한계성이 있지만, 벡터스토어는 의미적으로 유사한 단락 검색을 가능케합니다.
1.2 RAG에서의 벡터 저장소의 중요성
벡터스토어 저장 단계는 RAG 시스템의 검색 기능과 직접적으로 연결되어 있으며, 전체 시스템의 응답 시간과 정확성에 큰 영향을 미칩니다. 이 단계를 통해 데이터가 잘 관리되고, 필요할 때 즉시 접근할 수 있도록 함으로써, 사용자에게 신속하고 정확한 정보를 제공할 수 있습니다.
2. Chroma
Chroma는 오픈 소스 AI 애플리케이션 데이터베이스입니다. Chroma는 검색을 위해 임베딩과 저장된 임베딩의 메타데이터의 저장 기능을 제공하고, 벡터 검색, 전체 텍스트 검색, 문서 저장, 메타데이터 필터링, 멀티-모달 검색 기능을 제공합니다.
2.1 사전 준비
실행에 필요한 라이브러리 설치를 먼저 진행해 줍니다.
pip install langchain langchain-community langchain-google-genai google-generativeai langchain-chroma langchain-text-splitters langchain-core
예제에서 사용할 임베딩 모델은 Google의 gemini 임베딩 모델을 사용할 예정이므로 환경변수의 GOOGLE_API_KEY 값에 본인의 KEY 값을 설정해 주시기 바랍니다.
import os
os.environ["GOOGLE_API_KEY"] = '본인의 KEY값'
다음으로 샘플 데이터셋을 로드합니다. 데이터는 https://github.com/teddylee777/langchain-kr/tree/main에서 구하실 수 있습니다.
from langchain_community.document_loaders import TextLoader
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
# 텍스트 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=600, chunk_overlap=0)
# 텍스트 파일을 load -> List[Document] 형태로 변환
loader1 = TextLoader("data/nlp-keywords.txt")
loader2 = TextLoader("data/finance-keywords.txt")
# 문서 분할
split_doc1 = loader1.load_and_split(text_splitter)
split_doc2 = loader2.load_and_split(text_splitter)
# 문서 개수 확인
len(split_doc1), len(split_doc2)
Output:
11 6
2.2 Chroma를 이용한 VectorStore 생성
2.2.1 from_documents를 이용한 문서 기준 벡터 저장소 생성
from_documents 클래스 메서드는 문서 리스트로부터 벡터 저장소를 생성합니다. 사용하는 매개변수는 다음과 같습니다.
- documents(List[Document]): 벡터 저장소에 추가할 문서 리스트
- embedding(Optional[Embeddings]): 임베딩 함수, 기본값은 None
- ids(Optional[List[str]]): 문서 ID 리스트, 기본값은 None
- collection_name(str): 생성할 컬렉션 이름
- persist_directory(Optional[str]): 컬렉션을 저장할 디렉토리, 기본값은 None
- client_settings(Optional[chromadb.config.Settings]): Chroma 클라이언트 설정
- client[Optional[chromadb.client]]: chroma 클라이언트 인스턴스
- collection_metadata(Optional[Dict]): 컬렉션 구성 정보, 기본값은 None
from_documents 클래스는 persist_directory가 지정되면 컬렉션이 해당 디렉토리에 저장됩니다. 저장되지 않으면 데이터는 메모리에 임시 저장됩니다. 이 메서드는 내부적으로 from_texts 메서드를 호출하여 벡터 저장소를 생성합니다. 문서의 page_content는 텍스트로, metadata는 메타데이터로 사용됩니다.
# 저장할 경로 지정
DB_PATH = "/content/drive/MyDrive/LangChain/db/chroma_db"
# 문서를 디스크에 저장합니다. 저장시 persist_directory에 저장할 경로를 지정합니다.
persist_db = Chroma.from_documents(
split_doc1, GoogleGenerativeAIEmbeddings(model="gemini-embedding-001"), persist_directory=DB_PATH, collection_name="my_db"
)
# 디스크에서 문서를 로드
persist_db = Chroma(
persist_directory=DB_PATH,
embedding_function=GoogleGenerativeAIEmbeddings(model="gemini-embedding-001"),
collection_name="my_db"
)
# 저장된 데이터 확인
persist_db.get()
Output:
{'ids': ['1bc02d31-d671-4ca0-8d7b-cc29f80d132b',
'c6839981-eded-4ea8-9f76-5cf7c898a6eb',
'0729dd39-7edb-4a0a-8604-c25b8b9f02a7',
'04ae393a-4d97-4386-b5ff-66474b429677',
'abf3fb11-e57a-4011-9235-417761d5a2c7',
'48c7a1f3-91c9-46b1-87cb-333ce89d5891',
'87ccac82-3ed1-42f0-b66d-bd6a56d4d5e0',
'd76ab6ff-aa72-4928-ba74-9d321e0ba405',
'e59f7c94-99b7-49dd-ac83-a412f3ea1b51',
'4e64dc13-847f-481e-a0d5-8c45a605dfb5',
'254a8787-0efe-4900-bba7-b4a157095421'],
'embeddings': None,
'documents': ['Semantic Search\n\n정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.\n예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.\n연관키워드: 자연어 처리, 검색 알고리즘, 데이터 마이닝\n\nEmbedding\n\n정의: 임베딩은 단어나 문장 같은 텍스트 데이터를 저차원의 연속적인 벡터로 변환하는 과정입니다. 이를 통해 컴퓨터가 텍스트를 이해하고 처리할 수 있게 합니다.\n예시: "사과"라는 단어를 [0.65, -0.23, 0.17]과 같은 벡터로 표현합니다.\n연관키워드: 자연어 처리, 벡터화, 딥러닝\n\nToken\n\n정의: 토큰은 텍스트를 더 작은 단위로 분할하는 것을 의미합니다. 이는 일반적으로 단어, 문장, 또는 구절일 수 있습니다.\n예시: 문장 "나는 학교에 간다"를 "나는", "학교에", "간다"로 분할합니다.\n연관키워드: 토큰화, 자연어 처리, 구문 분석\n\nTokenizer',
'정의: 토크나이저는 텍스트 데이터를 토큰으로 분할하는 도구입니다. 이는 자연어 처리에서 데이터를 전처리하는 데 사용됩니다.\n예시: "I love programming."이라는 문장을 ["I", "love", "programming", "."]으로 분할합니다.\n연관키워드: 토큰화, 자연어 처리, 구문 분석\n\nVectorStore\n\n정의: 벡터스토어는 벡터 형식으로 변환된 데이터를 저장하는 시스템입니다. 이는 검색, 분류 및 기타 데이터 분석 작업에 사용됩니다.\n예시: 단어 임베딩 벡터들을 데이터베이스에 저장하여 빠르게 접근할 수 있습니다.\n연관키워드: 임베딩, 데이터베이스, 벡터화\n\nSQL\n\n정의: SQL(Structured Query Language)은 데이터베이스에서 데이터를 관리하기 위한 프로그래밍 언어입니다. 데이터 조회, 수정, 삽입, 삭제 등 다양한 작업을 수행할 수 있습니다.\n예시: SELECT * FROM users WHERE age > 18;은 18세 이상의 사용자 정보를 조회합니다.\n연관키워드: 데이터베이스, 쿼리, 데이터 관리\n\nCSV',
'정의: CSV(Comma-Separated Values)는 데이터를 저장하는 파일 형식으로, 각 데이터 값은 쉼표로 구분됩니다. 표 형태의 데이터를 간단하게 저장하고 교환할 때 사용됩니다.\n예시: 이름, 나이, 직업이라는 헤더를 가진 CSV 파일에는 홍길동, 30, 개발자와 같은 데이터가 포함될 수 있습니다.\n연관키워드: 데이터 형식, 파일 처리, 데이터 교환\n\nJSON\n\n정의: JSON(JavaScript Object Notation)은 경량의 데이터 교환 형식으로, 사람과 기계 모두에게 읽기 쉬운 텍스트를 사용하여 데이터 객체를 표현합니다.\n예시: {"이름": "홍길동", "나이": 30, "직업": "개발자"}는 JSON 형식의 데이터입니다.\n연관키워드: 데이터 교환, 웹 개발, API\n\nTransformer\n\n정의: 트랜스포머는 자연어 처리에서 사용되는 딥러닝 모델의 한 유형으로, 주로 번역, 요약, 텍스트 생성 등에 사용됩니다. 이는 Attention 메커니즘을 기반으로 합니다.\n예시: 구글 번역기는 트랜스포머 모델을 사용하여 다양한 언어 간의 번역을 수행합니다.\n연관키워드: 딥러닝, 자연어 처리, Attention\n\nHuggingFace',
'정의: HuggingFace는 자연어 처리를 위한 다양한 사전 훈련된 모델과 도구를 제공하는 라이브러리입니다. 이는 연구자와 개발자들이 쉽게 NLP 작업을 수행할 수 있도록 돕습니다.\n예시: HuggingFace의 Transformers 라이브러리를 사용하여 감정 분석, 텍스트 생성 등의 작업을 수행할 수 있습니다.\n연관키워드: 자연어 처리, 딥러닝, 라이브러리\n\nDigital Transformation\n\n정의: 디지털 변환은 기술을 활용하여 기업의 서비스, 문화, 운영을 혁신하는 과정입니다. 이는 비즈니스 모델을 개선하고 디지털 기술을 통해 경쟁력을 높이는 데 중점을 둡니다.\n예시: 기업이 클라우드 컴퓨팅을 도입하여 데이터 저장과 처리를 혁신하는 것은 디지털 변환의 예입니다.\n연관키워드: 혁신, 기술, 비즈니스 모델\n\nCrawling\n\n정의: 크롤링은 자동화된 방식으로 웹 페이지를 방문하여 데이터를 수집하는 과정입니다. 이는 검색 엔진 최적화나 데이터 분석에 자주 사용됩니다.\n예시: 구글 검색 엔진이 인터넷 상의 웹사이트를 방문하여 콘텐츠를 수집하고 인덱싱하는 것이 크롤링입니다.\n연관키워드: 데이터 수집, 웹 스크래핑, 검색 엔진\n\nWord2Vec',
'정의: Word2Vec은 단어를 벡터 공간에 매핑하여 단어 간의 의미적 관계를 나타내는 자연어 처리 기술입니다. 이는 단어의 문맥적 유사성을 기반으로 벡터를 생성합니다.\n예시: Word2Vec 모델에서 "왕"과 "여왕"은 서로 가까운 위치에 벡터로 표현됩니다.\n연관키워드: 자연어 처리, 임베딩, 의미론적 유사성\nLLM (Large Language Model)\n\n정의: LLM은 대규모의 텍스트 데이터로 훈련된 큰 규모의 언어 모델을 의미합니다. 이러한 모델은 다양한 자연어 이해 및 생성 작업에 사용됩니다.\n예시: OpenAI의 GPT 시리즈는 대표적인 대규모 언어 모델입니다.\n연관키워드: 자연어 처리, 딥러닝, 텍스트 생성\n\nFAISS (Facebook AI Similarity Search)\n\n정의: FAISS는 페이스북에서 개발한 고속 유사성 검색 라이브러리로, 특히 대규모 벡터 집합에서 유사 벡터를 효과적으로 검색할 수 있도록 설계되었습니다.\n예시: 수백만 개의 이미지 벡터 중에서 비슷한 이미지를 빠르게 찾는 데 FAISS가 사용될 수 있습니다.\n연관키워드: 벡터 검색, 머신러닝, 데이터베이스 최적화\n\nOpen Source',
'정의: 오픈 소스는 소스 코드가 공개되어 누구나 자유롭게 사용, 수정, 배포할 수 있는 소프트웨어를 의미합니다. 이는 협업과 혁신을 촉진하는 데 중요한 역할을 합니다.\n예시: 리눅스 운영 체제는 대표적인 오픈 소스 프로젝트입니다.\n연관키워드: 소프트웨어 개발, 커뮤니티, 기술 협업\n\nStructured Data\n\n정의: 구조화된 데이터는 정해진 형식이나 스키마에 따라 조직된 데이터입니다. 이는 데이터베이스, 스프레드시트 등에서 쉽게 검색하고 분석할 수 있습니다.\n예시: 관계형 데이터베이스에 저장된 고객 정보 테이블은 구조화된 데이터의 예입니다.\n연관키워드: 데이터베이스, 데이터 분석, 데이터 모델링\n\nParser\n\n정의: 파서는 주어진 데이터(문자열, 파일 등)를 분석하여 구조화된 형태로 변환하는 도구입니다. 이는 프로그래밍 언어의 구문 분석이나 파일 데이터 처리에 사용됩니다.\n예시: HTML 문서를 구문 분석하여 웹 페이지의 DOM 구조를 생성하는 것은 파싱의 한 예입니다.\n연관키워드: 구문 분석, 컴파일러, 데이터 처리\n\nTF-IDF (Term Frequency-Inverse Document Frequency)',
'정의: TF-IDF는 문서 내에서 단어의 중요도를 평가하는 데 사용되는 통계적 척도입니다. 이는 문서 내 단어의 빈도와 전체 문서 집합에서 그 단어의 희소성을 고려합니다.\n예시: 많은 문서에서 자주 등장하지 않는 단어는 높은 TF-IDF 값을 가집니다.\n연관키워드: 자연어 처리, 정보 검색, 데이터 마이닝\n\nDeep Learning\n\n정의: 딥러닝은 인공신경망을 이용하여 복잡한 문제를 해결하는 머신러닝의 한 분야입니다. 이는 데이터에서 고수준의 표현을 학습하는 데 중점을 둡니다.\n예시: 이미지 인식, 음성 인식, 자연어 처리 등에서 딥러닝 모델이 활용됩니다.\n연관키워드: 인공신경망, 머신러닝, 데이터 분석\n\nSchema\n\n정의: 스키마는 데이터베이스나 파일의 구조를 정의하는 것으로, 데이터가 어떻게 저장되고 조직되는지에 대한 청사진을 제공합니다.\n예시: 관계형 데이터베이스의 테이블 스키마는 열 이름, 데이터 타입, 키 제약 조건 등을 정의합니다.\n연관키워드: 데이터베이스, 데이터 모델링, 데이터 관리\n\nDataFrame',
"정의: DataFrame은 행과 열로 이루어진 테이블 형태의 데이터 구조로, 주로 데이터 분석 및 처리에 사용됩니다.\n예시: 판다스 라이브러리에서 DataFrame은 다양한 데이터 타입의 열을 가질 수 있으며, 데이터 조작과 분석을 용이하게 합니다.\n연관키워드: 데이터 분석, 판다스, 데이터 처리\n\nAttention 메커니즘\n\n정의: Attention 메커니즘은 딥러닝에서 중요한 정보에 더 많은 '주의'를 기울이도록 하는 기법입니다. 이는 주로 시퀀스 데이터(예: 텍스트, 시계열 데이터)에서 사용됩니다.\n예시: 번역 모델에서 Attention 메커니즘은 입력 문장의 중요한 부분에 더 집중하여 정확한 번역을 생성합니다.\n연관키워드: 딥러닝, 자연어 처리, 시퀀스 모델링\n\n판다스 (Pandas)\n\n정의: 판다스는 파이썬 프로그래밍 언어를 위한 데이터 분석 및 조작 도구를 제공하는 라이브러리입니다. 이는 데이터 분석 작업을 효율적으로 수행할 수 있게 합니다.\n예시: 판다스를 사용하여 CSV 파일을 읽고, 데이터를 정제하며, 다양한 분석을 수행할 수 있습니다.\n연관키워드: 데이터 분석, 파이썬, 데이터 처리",
'GPT (Generative Pretrained Transformer)\n\n정의: GPT는 대규모의 데이터셋으로 사전 훈련된 생성적 언어 모델로, 다양한 텍스트 기반 작업에 활용됩니다. 이는 입력된 텍스트에 기반하여 자연스러운 언어를 생성할 수 있습니다.\n예시: 사용자가 제공한 질문에 대해 자세한 답변을 생성하는 챗봇은 GPT 모델을 사용할 수 있습니다.\n연관키워드: 자연어 처리, 텍스트 생성, 딥러닝\n\nInstructGPT\n\n정의: InstructGPT는 사용자의 지시에 따라 특정한 작업을 수행하기 위해 최적화된 GPT 모델입니다. 이 모델은 보다 정확하고 관련성 높은 결과를 생성하도록 설계되었습니다.\n예시: 사용자가 "이메일 초안 작성"과 같은 특정 지시를 제공하면, InstructGPT는 관련 내용을 기반으로 이메일을 작성합니다.\n연관키워드: 인공지능, 자연어 이해, 명령 기반 처리\n\nKeyword Search',
'정의: 키워드 검색은 사용자가 입력한 키워드를 기반으로 정보를 찾는 과정입니다. 이는 대부분의 검색 엔진과 데이터베이스 시스템에서 기본적인 검색 방식으로 사용됩니다.\n예시: 사용자가 "커피숍 서울"이라고 검색하면, 관련된 커피숍 목록을 반환합니다.\n연관키워드: 검색 엔진, 데이터 검색, 정보 검색\n\nPage Rank\n\n정의: 페이지 랭크는 웹 페이지의 중요도를 평가하는 알고리즘으로, 주로 검색 엔진 결과의 순위를 결정하는 데 사용됩니다. 이는 웹 페이지 간의 링크 구조를 분석하여 평가합니다.\n예시: 구글 검색 엔진은 페이지 랭크 알고리즘을 사용하여 검색 결과의 순위를 정합니다.\n연관키워드: 검색 엔진 최적화, 웹 분석, 링크 분석\n\n데이터 마이닝\n\n정의: 데이터 마이닝은 대량의 데이터에서 유용한 정보를 발굴하는 과정입니다. 이는 통계, 머신러닝, 패턴 인식 등의 기술을 활용합니다.\n예시: 소매업체가 고객 구매 데이터를 분석하여 판매 전략을 수립하는 것은 데이터 마이닝의 예입니다.\n연관키워드: 빅데이터, 패턴 인식, 예측 분석\n\n멀티모달 (Multimodal)',
'정의: 멀티모달은 여러 종류의 데이터 모드(예: 텍스트, 이미지, 소리 등)를 결합하여 처리하는 기술입니다. 이는 서로 다른 형식의 데이터 간의 상호 작용을 통해 보다 풍부하고 정확한 정보를 추출하거나 예측하는 데 사용됩니다.\n예시: 이미지와 설명 텍스트를 함께 분석하여 더 정확한 이미지 분류를 수행하는 시스템은 멀티모달 기술의 예입니다.\n연관키워드: 데이터 융합, 인공지능, 딥러닝'],
'uris': None,
'included': ['metadatas', 'documents'],
'data': None,
'metadatas': [{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'},
{'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}]}
만약 collection_name을 다르게 지정하면 저장된 데이터가 없기 때문에 아무런 결과도 얻지 못합니다.
# 저장 시 컬렉션 이름과 로드할 때의 컬렉션 이름이 다를 경우
persist_db2 = Chroma(
persist_directory=DB_PATH,
embedding_function=GoogleGenerativeAIEmbeddings(model="gemini-embedding-001"),
collection_name="my_db2"
)
print(persist_db2.get())
Output:
{'ids': [], 'embeddings': None, 'documents': [], 'uris': None, 'included': ['metadatas', 'documents'], 'data': None, 'metadatas': []}
2.2.2 from_texts를 이용한 문자열 리스트를 이용한 벡터 저장소 생성
from_texts 클래스 메서드는 텍스트 리스트로부터 벡터 저장소를 생성합니다. 이 메서드의 매개변수는 다음과 같습니다.
- texts(List[str]): 컬렉션에 추가할 텍스트 리스트
- embedding(Optional[Embeddings]): 임베딩 함수, 기본값은 None
- metadatas(Optional[List[dict]]): 메타데이터 리스트, 기본값은 None
- ids(Optional[List[str]]): 문서 ID 리스트, 기본값은 None
- collection_name(str): 생성할 컬렉션 이름, 기본값은 ‘_LANGCHAIN_DEFAULT_COLLECTION_NAME’
- persist_directory(Optional[str]): 컬렉션을 저장할 디렉토리, 기본값은 None
- client_settings(Optional[chromadb.config.Settings]): Chroma 클라이언트 설정
- client(Optional[chromadb.Client]): Chroma 클라이언트 인스턴스
- collection_metadata(Optional[Dict]): 컬렉션 구성 정보, 기본값은 None
# from_texts를 이용한 벡터 저장소 생성
db2 = Chroma.from_texts(
["안녕하세요. 정말 반갑습니다.", "제 이름은 테디입니다."],
embedding=GoogleGenerativeAIEmbeddings(model="gemini-embedding-001"),
)
# 데이터를 조회합니다.
print(db2.get())
Output:
{'ids': ['9958ee84-554b-43b9-a9d1-3667dbbdcc3c', 'adf4898d-4684-4e9e-ab98-1e29a9f8eca0'], 'embeddings': None, 'documents': ['안녕하세요. 정말 반갑습니다.', '제 이름은 테디입니다.'], 'uris': None, 'included': ['metadatas', 'documents'], 'data': None, 'metadatas': [None, None]}
2.2.3 유사도 검색
similarity_search 메서드는 Chroma 데이터베이스에서 유사도 검색을 수행합니다. 이 메서드는 주어진 쿼리와 가장 유사한 문서들을 반환합니다. 매개변수는 다음과 같습니다.
- query(str): 검색할 쿼리 텍스트
- k(int, 선택적): 반환할 결과의 수, 기본값은 4입니다.
- filter(Dict[str, str], 선택적): 메타데이터로 필터링, 기본값은 None입니다.
만약 유사도 점수가 필요하다면 similarity_search_with_score 메서드를 사용하면 됩니다.
우선 similarity_search 메서드에 쿼리만 넣어서 결과를 보도록 하겠습니다.
# 유사도 검색
persist_db.similarity_search("TF_IDF에 대하여 알려줘")
Output:
[Document(id='87ccac82-3ed1-42f0-b66d-bd6a56d4d5e0', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: TF-IDF는 문서 내에서 단어의 중요도를 평가하는 데 사용되는 통계적 척도입니다. 이는 문서 내 단어의 빈도와 전체 문서 집합에서 그 단어의 희소성을 고려합니다.\n예시: 많은 문서에서 자주 등장하지 않는 단어는 높은 TF-IDF 값을 가집니다.\n연관키워드: 자연어 처리, 정보 검색, 데이터 마이닝\n\nDeep Learning\n\n정의: 딥러닝은 인공신경망을 이용하여 복잡한 문제를 해결하는 머신러닝의 한 분야입니다. 이는 데이터에서 고수준의 표현을 학습하는 데 중점을 둡니다.\n예시: 이미지 인식, 음성 인식, 자연어 처리 등에서 딥러닝 모델이 활용됩니다.\n연관키워드: 인공신경망, 머신러닝, 데이터 분석\n\nSchema\n\n정의: 스키마는 데이터베이스나 파일의 구조를 정의하는 것으로, 데이터가 어떻게 저장되고 조직되는지에 대한 청사진을 제공합니다.\n예시: 관계형 데이터베이스의 테이블 스키마는 열 이름, 데이터 타입, 키 제약 조건 등을 정의합니다.\n연관키워드: 데이터베이스, 데이터 모델링, 데이터 관리\n\nDataFrame'),
Document(id='48c7a1f3-91c9-46b1-87cb-333ce89d5891', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: 오픈 소스는 소스 코드가 공개되어 누구나 자유롭게 사용, 수정, 배포할 수 있는 소프트웨어를 의미합니다. 이는 협업과 혁신을 촉진하는 데 중요한 역할을 합니다.\n예시: 리눅스 운영 체제는 대표적인 오픈 소스 프로젝트입니다.\n연관키워드: 소프트웨어 개발, 커뮤니티, 기술 협업\n\nStructured Data\n\n정의: 구조화된 데이터는 정해진 형식이나 스키마에 따라 조직된 데이터입니다. 이는 데이터베이스, 스프레드시트 등에서 쉽게 검색하고 분석할 수 있습니다.\n예시: 관계형 데이터베이스에 저장된 고객 정보 테이블은 구조화된 데이터의 예입니다.\n연관키워드: 데이터베이스, 데이터 분석, 데이터 모델링\n\nParser\n\n정의: 파서는 주어진 데이터(문자열, 파일 등)를 분석하여 구조화된 형태로 변환하는 도구입니다. 이는 프로그래밍 언어의 구문 분석이나 파일 데이터 처리에 사용됩니다.\n예시: HTML 문서를 구문 분석하여 웹 페이지의 DOM 구조를 생성하는 것은 파싱의 한 예입니다.\n연관키워드: 구문 분석, 컴파일러, 데이터 처리\n\nTF-IDF (Term Frequency-Inverse Document Frequency)'),
Document(id='1bc02d31-d671-4ca0-8d7b-cc29f80d132b', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='Semantic Search\n\n정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.\n예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.\n연관키워드: 자연어 처리, 검색 알고리즘, 데이터 마이닝\n\nEmbedding\n\n정의: 임베딩은 단어나 문장 같은 텍스트 데이터를 저차원의 연속적인 벡터로 변환하는 과정입니다. 이를 통해 컴퓨터가 텍스트를 이해하고 처리할 수 있게 합니다.\n예시: "사과"라는 단어를 [0.65, -0.23, 0.17]과 같은 벡터로 표현합니다.\n연관키워드: 자연어 처리, 벡터화, 딥러닝\n\nToken\n\n정의: 토큰은 텍스트를 더 작은 단위로 분할하는 것을 의미합니다. 이는 일반적으로 단어, 문장, 또는 구절일 수 있습니다.\n예시: 문장 "나는 학교에 간다"를 "나는", "학교에", "간다"로 분할합니다.\n연관키워드: 토큰화, 자연어 처리, 구문 분석\n\nTokenizer'),
Document(id='4e64dc13-847f-481e-a0d5-8c45a605dfb5', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: 키워드 검색은 사용자가 입력한 키워드를 기반으로 정보를 찾는 과정입니다. 이는 대부분의 검색 엔진과 데이터베이스 시스템에서 기본적인 검색 방식으로 사용됩니다.\n예시: 사용자가 "커피숍 서울"이라고 검색하면, 관련된 커피숍 목록을 반환합니다.\n연관키워드: 검색 엔진, 데이터 검색, 정보 검색\n\nPage Rank\n\n정의: 페이지 랭크는 웹 페이지의 중요도를 평가하는 알고리즘으로, 주로 검색 엔진 결과의 순위를 결정하는 데 사용됩니다. 이는 웹 페이지 간의 링크 구조를 분석하여 평가합니다.\n예시: 구글 검색 엔진은 페이지 랭크 알고리즘을 사용하여 검색 결과의 순위를 정합니다.\n연관키워드: 검색 엔진 최적화, 웹 분석, 링크 분석\n\n데이터 마이닝\n\n정의: 데이터 마이닝은 대량의 데이터에서 유용한 정보를 발굴하는 과정입니다. 이는 통계, 머신러닝, 패턴 인식 등의 기술을 활용합니다.\n예시: 소매업체가 고객 구매 데이터를 분석하여 판매 전략을 수립하는 것은 데이터 마이닝의 예입니다.\n연관키워드: 빅데이터, 패턴 인식, 예측 분석\n\n멀티모달 (Multimodal)')]
k값을 지정했을 때의 결과를 한 번 보도록 하겠습니다.
# k값 지정
persist_db.similarity_search("TF IDF에 대하여 알려줘", k=1)
Output:
[Document(id='87ccac82-3ed1-42f0-b66d-bd6a56d4d5e0', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: TF-IDF는 문서 내에서 단어의 중요도를 평가하는 데 사용되는 통계적 척도입니다. 이는 문서 내 단어의 빈도와 전체 문서 집합에서 그 단어의 희소성을 고려합니다.\n예시: 많은 문서에서 자주 등장하지 않는 단어는 높은 TF-IDF 값을 가집니다.\n연관키워드: 자연어 처리, 정보 검색, 데이터 마이닝\n\nDeep Learning\n\n정의: 딥러닝은 인공신경망을 이용하여 복잡한 문제를 해결하는 머신러닝의 한 분야입니다. 이는 데이터에서 고수준의 표현을 학습하는 데 중점을 둡니다.\n예시: 이미지 인식, 음성 인식, 자연어 처리 등에서 딥러닝 모델이 활용됩니다.\n연관키워드: 인공신경망, 머신러닝, 데이터 분석\n\nSchema\n\n정의: 스키마는 데이터베이스나 파일의 구조를 정의하는 것으로, 데이터가 어떻게 저장되고 조직되는지에 대한 청사진을 제공합니다.\n예시: 관계형 데이터베이스의 테이블 스키마는 열 이름, 데이터 타입, 키 제약 조건 등을 정의합니다.\n연관키워드: 데이터베이스, 데이터 모델링, 데이터 관리\n\nDataFrame')]
filter에 metadata 정보를 활용하여 검색 결과를 필터링 할 수 있습니다.
# filter 사용
# 메타데이터가 없으면 출력결과가 없음
result = persist_db.similarity_search(
"TF IDF에 대하여 알려줘", filter={"source" : "/content/drive/MyDrive/LangChain/finance-keywords.txt"}, k=1
)
print(result)
result = persist_db.similarity_search(
"TF IDF에 대하여 알려줘", filter={"source" : "/content/drive/MyDrive/LangChain/nlp-keywords.txt"}, k=1
)
print(result)
결과를 보면 첫 번째 출력은 메타데이터 정보가 없어서 빈 리스트가 출력된 것을 확인할 수 있고, 두 번째 출력 결과에서는 메타데이터 정보가 있어서 해당 메타데이터의 문서로부터 결과를 추출해온 것을 확인할 수 있습니다.
Output:
[]
[Document(id='87ccac82-3ed1-42f0-b66d-bd6a56d4d5e0', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: TF-IDF는 문서 내에서 단어의 중요도를 평가하는 데 사용되는 통계적 척도입니다. 이는 문서 내 단어의 빈도와 전체 문서 집합에서 그 단어의 희소성을 고려합니다.\n예시: 많은 문서에서 자주 등장하지 않는 단어는 높은 TF-IDF 값을 가집니다.\n연관키워드: 자연어 처리, 정보 검색, 데이터 마이닝\n\nDeep Learning\n\n정의: 딥러닝은 인공신경망을 이용하여 복잡한 문제를 해결하는 머신러닝의 한 분야입니다. 이는 데이터에서 고수준의 표현을 학습하는 데 중점을 둡니다.\n예시: 이미지 인식, 음성 인식, 자연어 처리 등에서 딥러닝 모델이 활용됩니다.\n연관키워드: 인공신경망, 머신러닝, 데이터 분석\n\nSchema\n\n정의: 스키마는 데이터베이스나 파일의 구조를 정의하는 것으로, 데이터가 어떻게 저장되고 조직되는지에 대한 청사진을 제공합니다.\n예시: 관계형 데이터베이스의 테이블 스키마는 열 이름, 데이터 타입, 키 제약 조건 등을 정의합니다.\n연관키워드: 데이터베이스, 데이터 모델링, 데이터 관리\n\nDataFrame')]
마지막으로 유사도 점수를 함께 출력해 주는 similarity_search_with_score 함수를 사용한 추출 결과를 확인해 보도록 하겠습니다.
result = persist_db.similarity_search_with_score(
"TF IDF에 대하여 알려줘"
)
print(result)
Output:
[(Document(id='87ccac82-3ed1-42f0-b66d-bd6a56d4d5e0', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: TF-IDF는 문서 내에서 단어의 중요도를 평가하는 데 사용되는 통계적 척도입니다. 이는 문서 내 단어의 빈도와 전체 문서 집합에서 그 단어의 희소성을 고려합니다.\n예시: 많은 문서에서 자주 등장하지 않는 단어는 높은 TF-IDF 값을 가집니다.\n연관키워드: 자연어 처리, 정보 검색, 데이터 마이닝\n\nDeep Learning\n\n정의: 딥러닝은 인공신경망을 이용하여 복잡한 문제를 해결하는 머신러닝의 한 분야입니다. 이는 데이터에서 고수준의 표현을 학습하는 데 중점을 둡니다.\n예시: 이미지 인식, 음성 인식, 자연어 처리 등에서 딥러닝 모델이 활용됩니다.\n연관키워드: 인공신경망, 머신러닝, 데이터 분석\n\nSchema\n\n정의: 스키마는 데이터베이스나 파일의 구조를 정의하는 것으로, 데이터가 어떻게 저장되고 조직되는지에 대한 청사진을 제공합니다.\n예시: 관계형 데이터베이스의 테이블 스키마는 열 이름, 데이터 타입, 키 제약 조건 등을 정의합니다.\n연관키워드: 데이터베이스, 데이터 모델링, 데이터 관리\n\nDataFrame'), 0.4636484682559967), (Document(id='48c7a1f3-91c9-46b1-87cb-333ce89d5891', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: 오픈 소스는 소스 코드가 공개되어 누구나 자유롭게 사용, 수정, 배포할 수 있는 소프트웨어를 의미합니다. 이는 협업과 혁신을 촉진하는 데 중요한 역할을 합니다.\n예시: 리눅스 운영 체제는 대표적인 오픈 소스 프로젝트입니다.\n연관키워드: 소프트웨어 개발, 커뮤니티, 기술 협업\n\nStructured Data\n\n정의: 구조화된 데이터는 정해진 형식이나 스키마에 따라 조직된 데이터입니다. 이는 데이터베이스, 스프레드시트 등에서 쉽게 검색하고 분석할 수 있습니다.\n예시: 관계형 데이터베이스에 저장된 고객 정보 테이블은 구조화된 데이터의 예입니다.\n연관키워드: 데이터베이스, 데이터 분석, 데이터 모델링\n\nParser\n\n정의: 파서는 주어진 데이터(문자열, 파일 등)를 분석하여 구조화된 형태로 변환하는 도구입니다. 이는 프로그래밍 언어의 구문 분석이나 파일 데이터 처리에 사용됩니다.\n예시: HTML 문서를 구문 분석하여 웹 페이지의 DOM 구조를 생성하는 것은 파싱의 한 예입니다.\n연관키워드: 구문 분석, 컴파일러, 데이터 처리\n\nTF-IDF (Term Frequency-Inverse Document Frequency)'), 0.5732378959655762), (Document(id='1bc02d31-d671-4ca0-8d7b-cc29f80d132b', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='Semantic Search\n\n정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.\n예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.\n연관키워드: 자연어 처리, 검색 알고리즘, 데이터 마이닝\n\nEmbedding\n\n정의: 임베딩은 단어나 문장 같은 텍스트 데이터를 저차원의 연속적인 벡터로 변환하는 과정입니다. 이를 통해 컴퓨터가 텍스트를 이해하고 처리할 수 있게 합니다.\n예시: "사과"라는 단어를 [0.65, -0.23, 0.17]과 같은 벡터로 표현합니다.\n연관키워드: 자연어 처리, 벡터화, 딥러닝\n\nToken\n\n정의: 토큰은 텍스트를 더 작은 단위로 분할하는 것을 의미합니다. 이는 일반적으로 단어, 문장, 또는 구절일 수 있습니다.\n예시: 문장 "나는 학교에 간다"를 "나는", "학교에", "간다"로 분할합니다.\n연관키워드: 토큰화, 자연어 처리, 구문 분석\n\nTokenizer'), 0.6306159496307373), (Document(id='04ae393a-4d97-4386-b5ff-66474b429677', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: HuggingFace는 자연어 처리를 위한 다양한 사전 훈련된 모델과 도구를 제공하는 라이브러리입니다. 이는 연구자와 개발자들이 쉽게 NLP 작업을 수행할 수 있도록 돕습니다.\n예시: HuggingFace의 Transformers 라이브러리를 사용하여 감정 분석, 텍스트 생성 등의 작업을 수행할 수 있습니다.\n연관키워드: 자연어 처리, 딥러닝, 라이브러리\n\nDigital Transformation\n\n정의: 디지털 변환은 기술을 활용하여 기업의 서비스, 문화, 운영을 혁신하는 과정입니다. 이는 비즈니스 모델을 개선하고 디지털 기술을 통해 경쟁력을 높이는 데 중점을 둡니다.\n예시: 기업이 클라우드 컴퓨팅을 도입하여 데이터 저장과 처리를 혁신하는 것은 디지털 변환의 예입니다.\n연관키워드: 혁신, 기술, 비즈니스 모델\n\nCrawling\n\n정의: 크롤링은 자동화된 방식으로 웹 페이지를 방문하여 데이터를 수집하는 과정입니다. 이는 검색 엔진 최적화나 데이터 분석에 자주 사용됩니다.\n예시: 구글 검색 엔진이 인터넷 상의 웹사이트를 방문하여 콘텐츠를 수집하고 인덱싱하는 것이 크롤링입니다.\n연관키워드: 데이터 수집, 웹 스크래핑, 검색 엔진\n\nWord2Vec'), 0.6487559080123901)]
2.2.4 벡터 저장소에 문서 추가
add_documents 메서드는 벡터 저장소에 문서를 추가하거나 업데이트 합니다. 매개변수는 다음과 같습니다.
- documents(List[Document]): 벡터 저장소에 추가할 문서 리스트
- **kwargs: 추가 키워드 인자
- ids: 문서 ID 리스트 (제공 시 문서의 ID보다 우선함)
# Chroma 벡터 저장소에 문서 추가
from langchain_core.documents import Document
# page_content, metadata, id 지정
persist_db.add_documents(
[
Document(
page_content="안녕하세요! 이번에 도큐먼트를 새로 추가해 볼게요",
metadata = {"source":"mydata.txt"},
id="1",
)
]
)
# id=1로 문서 조회
print(persist_db.get("1"))
Output:
{'ids': ['1'], 'embeddings': None, 'documents': ['안녕하세요! 이번에 도큐먼트를 새로 추가해 볼게요'], 'uris': None, 'included': ['metadatas', 'documents'], 'data': None, 'metadatas': [{'source': 'mydata.txt'}]}
이번엔 add_texts 메서드를 이용한 방법입니다. add_texts 메서드는 텍스트를 임베딩하고 벡터 저장소에 추가합니다. 매개변수는 다음과 같습니다.
- texts (Iterable[str]): 벡터 저장소에 추가할 텍스트 리스트
- metadatas(Optional[List[dict]]): 메타데이터 리스트, 기본값은 None
- ids(Optional[List[str]]): 문서 ID 리스트, 기본값은 None
# add_texts 메서드를 이용한 문서 추가 예제
persist_db.add_texts(
["이전에 추가한 Document를 덮어쓰겠습니다", "덮어쓴 결과가 어떤가요?"],
metadatas=[{"source":"mydata.txt"}, {"source":"mydata.txt"}],
ids=["1", "2"]
)
print(persist_db.get("1"))
print("==="*100)
print(persist_db.get("2"))
Output:
{'ids': ['1'], 'embeddings': None, 'documents': ['이전에 추가한 Document를 덮어쓰겠습니다'], 'uris': None, 'included': ['metadatas', 'documents'], 'data': None, 'metadatas': [{'source': 'mydata.txt'}]}
============================================================================================================================================================================================================================================================================================================
{'ids': ['2'], 'embeddings': None, 'documents': ['덮어쓴 결과가 어떤가요?'], 'uris': None, 'included': ['metadatas', 'documents'], 'data': None, 'metadatas': [{'source': 'mydata.txt'}]}
2.2.5 벡터 저장소에서 문서 삭제
delete 메서드는 벡터 저장소에서 지정된 ID의 문서를 삭제합니다. 매개변수는 다음과 같습니다.
- ids(Optional[List[str]]): 삭제할 문서의 ID리스트, 기본값은 None
# 벡터 저장소 문서 삭제 예제
# id 1 삭제
persist_db.delete(ids=["1"])
print(persist_db.get("1"))
Output:
{'ids': [], 'embeddings': None, 'documents': [], 'uris': None, 'included': ['metadatas', 'documents'], 'data': None, 'metadatas': []}
2.2.6 벡터 저장소 초기화
reset_collection 메서드는 벡터 저장소의 컬렉션을 초기화합니다.
# 벡터 초기화 예제
db = Chroma.from_texts(
["안녕하세요. 정말 반갑습니다.", "제 이름은 테디입니다."],
embedding=GoogleGenerativeAIEmbeddings(model="gemini-embedding-001"),
)
# 데이터를 조회합니다.
print(db.get())
# 컬렉션 초기화
db.reset_collection()
# 초기화 후 문서 조회
db.get()
Output:
{'ids': ['9958ee84-554b-43b9-a9d1-3667dbbdcc3c', 'adf4898d-4684-4e9e-ab98-1e29a9f8eca0', '3bfe414b-9f62-4e47-807b-224270e9c749', '2eb634a8-d81e-4259-b068-8a1003fac75f'], 'embeddings': None, 'documents': ['안녕하세요. 정말 반갑습니다.', '제 이름은 테디입니다.', '안녕하세요. 정말 반갑습니다.', '제 이름은 테디입니다.'], 'uris': None, 'included': ['metadatas', 'documents'], 'data': None, 'metadatas': [None, None, None, None]}
{'ids': [],
'embeddings': None,
'documents': [],
'uris': None,
'included': ['metadatas', 'documents'],
'data': None,
'metadatas': []}
2.2.7 MMR(Maximum marginal relevance search)
Chroma를 포함해 소개할 FAISS 벡터 저장소에서도 사용되는 MMR 검색 방식에 대해서 한 번 짚고 넘어가도록 하겠습니다. 최대 한계 관련성(Maximum Marginal Relevance, MMR) 검색 방식은 유사성과 다양성의 균형을 맞추어 검색 결과의 품질을 향상시키는 알고리즘입니다. 이 방식은 검색 쿼리에 대한 문서들의 관련성을 최대화하는 동시에, 검색된 문서들 사이의 중복성을 최소화하여, 사용자에게 다양하고 풍부한 정보를 제공하는 것을 목표로 합니다.
2.2.7.1 MMR의 작동 원리
MMR 은 쿼리에 대한 전체 문서에서 각 문서의 유사성 점수와 이미 선택된 문서들과의 다양성(또는 차별성) 점수를 조합하여, 각 문서의 최종 점수를 계산합니다. 이 최종 점수에 기반하여 문서를 선택합니다. MMR 은 다음과 같이 정의될 수 있습니다. 핵심 아이디어는 질의와의 유사도는 높게, 이미 선택된 것들과의 유사도는 낮게 입니다.
\[\operatorname{MMR}(d;Q,D') \;=\; \lambda \,\operatorname{Sim}(d, Q) \;-\; (1-\lambda)\,\max_{d' \in D'} \operatorname{Sim}(d, D')\]- ($\operatorname{Sim}(d, Q$) 는 전체 문서 ($d$) 와 쿼리 ($Q$) 사이의 유사성을 나타냅니다. 그리고 이 값은 MMR 수식 계산 전에 모든 문서에 대해서 계산을 해놓습니다.
- ($\max_{d’ \in D’} \operatorname{Sim}(d, d’)$) 는 문서 ($d$) 와 이미 선택된 문서 집합 ($D’$) 중 가장 유사한 문서와의 유사성을 나타냅니다.
- ($\lambda$) 는 유사성과 다양성의 상대적 중요도를 조절하는 매개변수입니다.
- MMR 점수는 뽑고자 하는 문서 개수 k 가 충족될 때까지 매번 모든 문서에 대해서 MMR 점수 계산을 진행합니다.
- 시간복잡도는 전체 문서를 $D$ 뽑고자 하는 문서의 개수가 $k$ 라면 $O(D \cdot k)$ 입니다. 하지만 실제 최적화는 쿼리와의 유사도가 높은 상위 100 ~ 200개 문서를 가지고 와서 진행합니다.
2.2.7.2 MMR의 주요 매개변수
- query : 사용자로부터 입력받은 검색 쿼리입니다.
- k : 최종적으로 선택할 문서의 수 입니다. 이 매개변수는 반환할 문서의 총 개수를 결정합니다.
- fetch_k : MMR 알고리즘을 수행할 때 고려할 상위 문서의 수입니다. 이는 초기 후보 문서 집합의 크기를 의미하며, 이 중에서 MMR 에 의해 최종 문서가 k 개 만큼 선택됩니다.
- lambda_mult : 쿼리와의 유사성과 선택된 문서 간의 다양성 사이의 균형을 조절합니다. ($\lambda = 1$) 은 유사성만을 고려하며, ($\lambda = 0$) 은 다양성만을 고려합니다. 실무 권장 범위는 보통 0.5 ~ 0.8 에서 검증하여 결정합니다.
MMR 방식을 사용하면, 검색 결과로 얻은 문서들이 쿼리와 관련성이 높으면서도 서로 다른 측면이나 정보를 제공하도록 할 수 있습니다. 이는 특히 정보 검색이나 추천 시스템에서 사용자에게 더 풍부하고 만족스러운 결과를 제공하는 데 도움이 됩니다.
다음은 일반적으로 사용되는 코사인 유사도와 MMR 비교를 위한 예제 코드입니다. 먼저 PyMuPDFLoader 를 사용하여 PDF 파일에서 텍스트 데이터를 로드합니다. 이 클래스는 PyMuPDF 라이브러리를 사용하여 PDF 문서의 내용을 추출합니다. 필요한 경우 !pip install pymupdf 명령어로 라이브러리를 설치합니다.
실습 데이터 : 카카오뱅크 2022 지속가능경영보고서.pdf
RecursiveCharacterTextSplitter 를 사용하여 문서를 텍스트 조각으로 분할하는 인스턴스를 생성하고 text_splitter.split_documents(data) 를 호출하여 문서 객체를 여러 개의 청크로 분할합니다.
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
loader = PyMuPDFLoader("/content/drive/MyDrive/LangChain/카카오뱅크 2022 지속가능경영보고서.pdf")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000,
chunk_overlap=200,
encoding_name='cl100k_base'
)
documents = text_splitter.split_documents(data)
다음은 OpenAIEmbedding 클래스를 사용하여 임베딩 모델의 인스턴스를 생성합니다. Chroma.from_documents 메소드를 사용하여 분할된 문서들을 임베딩하고, 이 임베딩들을 Chroma 벡터 저장소에 저장합니다. 여기서는 esg 라는 컬렉션 이름을 사용하며, collection_metadata 를 통해 유사도 검색에 사용될 공간을 cosine 으로 지정하여, 코사인 유사도를 사용합니다.
# Embedding -> Upload to Vectorstore
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
db2 = Chroma.from_documents(
documents,
embeddings_model,
collection_name = 'esg',
persist_directory = './db/chromadb',
collection_metadata = {'hnsw:space': 'cosine'}, # l2 is the default
)
db2
이제 일반 유사도 검색과 MMR 검색을 비교해 보도록 하겠습니다. 우선 일반적인 유사도 기반 검색의 결과부터 보도록 하겠습니다. 쿼리 카카오뱅크의 환경목표와 세부추진 내용을 알려줘?를 사용하여 유사성 검색을 수행합니다.
query = '카카오뱅크의 환경목표와 세부추진내용을 알려줘?'
docs = db2.similarity_search(query)
print(len(docs))
print(docs[0].page_content)
Output:
4
더 나은 세상을 만들어 나가는데 앞장서겠습니다.
이에 따라 카카오뱅크는 아래와 같은 환경방침을 수립하여 운영합니다.
• 전사 환경경영 정책 수립
• 녹색 구매 지침 수립
• 환경 지표 설정 및 성과 관리
• 용수, 폐기물, 에너지 등
자원 사용량 관리
• 기후변화를 포함한
환경 리스크 관리체계 마련
• Scope 1&2&3 온실가스
배출량 모니터링
• 탄소 가격 도입을 통한
환경 비용 관리
• 신재생 에너지 사용 확대
• 녹색채권 발행 기반 마련
단기
중기
장기
• 환경경영 조직 및
관리 체계 구축
• 환경영향평가 체계 구축
환경경영
관리체계
구축
환경
리스크 및
성과 관리
환경
영향
저감
환경경영체계 구축
카카오뱅크 환경방침
Protect Environment
카카오뱅크 2022 지속가능경영보고서
검색 결과 중 가장 유사도가 낮은 문서의 내용을 출력해 봅니다.
print(docs[-1].page_content)
유사도 기반 검색 결과의 경우 중복 방지가 따로 되어 있지 않아 검색된 4개의 문서가 모두 같은 내용인 것을 확인할 수 있습니다.
Output:
더 나은 세상을 만들어 나가는데 앞장서겠습니다.
이에 따라 카카오뱅크는 아래와 같은 환경방침을 수립하여 운영합니다.
• 전사 환경경영 정책 수립
• 녹색 구매 지침 수립
• 환경 지표 설정 및 성과 관리
• 용수, 폐기물, 에너지 등
자원 사용량 관리
• 기후변화를 포함한
환경 리스크 관리체계 마련
• Scope 1&2&3 온실가스
배출량 모니터링
• 탄소 가격 도입을 통한
환경 비용 관리
• 신재생 에너지 사용 확대
• 녹색채권 발행 기반 마련
단기
중기
장기
• 환경경영 조직 및
관리 체계 구축
• 환경영향평가 체계 구축
환경경영
관리체계
구축
환경
리스크 및
성과 관리
환경
영향
저감
환경경영체계 구축
카카오뱅크 환경방침
Protect Environment
카카오뱅크 2022 지속가능경영보고서
이제 MMR 검색을 이용한 결과입니다. 동일한 쿼리를 사용하여 MMR 검색을 수행합니다. 여기서는 k=4 와 fetch_k=100 을 설정하여, 상위 10개의 유사한 문서 중에서 서로 다른 정보를 제공하는 4개의 문서를 선택합니다.
mmr_docs = db2.max_marginal_relevance_search(query, k=4, fetch_k=100)
print(len(mmr_docs))
print(mmr_docs[0].page_content)
유사도 기반 검색과 동일한 문서가 출력되는 것을 확인할 수 있습니다.
실행 결과
4
더 나은 세상을 만들어 나가는데 앞장서겠습니다.
이에 따라 카카오뱅크는 아래와 같은 환경방침을 수립하여 운영합니다.
• 전사 환경경영 정책 수립
• 녹색 구매 지침 수립
• 환경 지표 설정 및 성과 관리
• 용수, 폐기물, 에너지 등
자원 사용량 관리
• 기후변화를 포함한
환경 리스크 관리체계 마련
• Scope 1&2&3 온실가스
배출량 모니터링
• 탄소 가격 도입을 통한
환경 비용 관리
• 신재생 에너지 사용 확대
• 녹색채권 발행 기반 마련
단기
중기
장기
• 환경경영 조직 및
관리 체계 구축
• 환경영향평가 체계 구축
환경경영
관리체계
구축
환경
리스크 및
성과 관리
환경
영향
저감
환경경영체계 구축
카카오뱅크 환경방침
Protect Environment
카카오뱅크 2022 지속가능경영보고서
print(mmr_docs[-1].page_content)
유사도 기반 검색과 달리 MMR 검색의 경우 가장 낮은 순위의 문서 내용이 순위가 가장 높은 순위의 문서 내용과 다른 것을 확인할 수 있습니다.
실행 결과
니다. 또한 운영에 많은 에너지가 필요한 오프라인 지점 대신 챗봇으로 고객과 소통
하는 것도 환경 중심 경영에 도움이 되고 있습니다. 비대면 계좌 개설, 대출 서류 전자
서식 도입 등 페이퍼리스 정책은 카카오뱅크가 선도해 온, 카카오뱅크만의 자랑입니
다. 카카오뱅크는 국제표준 환경경영시스템 ISO 14001을 취득했습니다. 카카오뱅
크의 모든 임직원이 환경적 지속가능성의 중요성에 공감하며, 환경을 먼저 고려하는
방안을 경영 전략에 담고 실천하겠습니다. 사업과 업무 단계에서 발생하는 온실가스
배출량을 측정하고, 절감하는 방안도 모색하고 있습니다.
2,000만 고객의 주거래은행 : 계속되는 포용금융
카카오뱅크의 2022년 말 기준 고객 수는 2,042만 명입니다. 경제활동인구 대비
71%에 달하는 수준입니다. 카카오뱅크의 출범의 이유와 성장 동력은 모두 ‘고객’
입니다. 카카오뱅크는 IT 기술로 절감한 비용을 2,000만 명이 넘는 고객들에게 돌
려드리기 위해 최선을 다하고 있습니다. 카카오뱅크의 독자적인 대안신용평가모형
(CSS) ‘카카오뱅크 스코어’를 기반으로 한 중저신용대출 공급액은 출범 이후 2022
년 12월까지 누적 7조 1,106억 원에 달합니다.
중도상환해약금 면제 금액도 지난해 말까지 992억 원에 달하며, 2,494억 원에 달
하는 ATM 이용 수수료도 받지 않고 고객들에 돌려드렸습니다.
금리인하요구권을 통한 고객 이자 절감 규모는 누적 169억 원입니다. 카카오뱅크는
고객들이 상품과 서비스를 이용하며 마주할 수 있는 문제를 해결하는 데 최선을 다하
겠습니다. 지난해 시니어 고객 대상으로 무료로 금융안심보험에 가입할 수 있도록 했
고, 빅데이터와 디지털 기술을 활용하여 보이스피싱을 예방하는 프로그램도 진행하
고 있습니다. 올해도 더 안전하고 더 편리하게 금융 서비스를 이용할 수 있도록 ‘모바
일 금융 안전망 강화’에 연구 역량과 자원을 투입하고 지원하겠습니다.
2.2.8 벡터 저장소를 검색기(Retriever)로 변환
이제 Chroma 벡터 저장소를 이용해 저장소에서 쿼리와 가장 밀접한 문서를 찾아오도록 하는 검색기 기능을 알아보도록 하겠습니다. as_retriever 메서드를 이용하며 이 메서드는 벡터 저장소를 기반으로 VectorStoreRetriever를 생성합니다. 매개변수는 다음과 같습니다.
- **kwargs: 검색 함수에 전달할 키워드 인자
- search_type(Optional[str]): 검색 유형(similarity, mmr, similarity_score_threshold 사용)
- search_kwargs(Optional[Dict]): 검색 함수에 전달할 추가 인자
- k: 반환할 문서 수(기본값: 4)
- score_threshold: 최소 유사도 임계값
- fetch_k: MMR 알고리즘에 전달할 문서 수(기본값: 20)
- lambda_mult: MMR 결과의 다양성 조절 (0~1, 기본값: 0.5)
- filter: 문서 메타데이터 필터링
우선 기본적으로 아무런 매개변수 없이 검색한 결과를 한 번 보도록 하겠습니다.
# 벡터 DB 초기화
db = Chroma.from_documents(
documents = split_doc1 + split_doc2,
embedding = GoogleGenerativeAIEmbeddings(model="gemini-embedding-001"),
collection_name="nlp"
)
retriever = db.as_retriever()
response = retriever.invoke("Word2Vec에 대하여 알려줘")
print(len(response))
print(response)
검색된 문서의 개수는 4개로 k값을 설정해 주지 않았을 때 기본값인 4개의 문서를 검색해 주는 것을 확인할 수 있습니다.
Output:
4
[Document(id='b34cf825-648a-4836-8523-f5f08a4c7dbf', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: Word2Vec은 단어를 벡터 공간에 매핑하여 단어 간의 의미적 관계를 나타내는 자연어 처리 기술입니다. 이는 단어의 문맥적 유사성을 기반으로 벡터를 생성합니다.\n예시: Word2Vec 모델에서 "왕"과 "여왕"은 서로 가까운 위치에 벡터로 표현됩니다.\n연관키워드: 자연어 처리, 임베딩, 의미론적 유사성\nLLM (Large Language Model)\n\n정의: LLM은 대규모의 텍스트 데이터로 훈련된 큰 규모의 언어 모델을 의미합니다. 이러한 모델은 다양한 자연어 이해 및 생성 작업에 사용됩니다.\n예시: OpenAI의 GPT 시리즈는 대표적인 대규모 언어 모델입니다.\n연관키워드: 자연어 처리, 딥러닝, 텍스트 생성\n\nFAISS (Facebook AI Similarity Search)\n\n정의: FAISS는 페이스북에서 개발한 고속 유사성 검색 라이브러리로, 특히 대규모 벡터 집합에서 유사 벡터를 효과적으로 검색할 수 있도록 설계되었습니다.\n예시: 수백만 개의 이미지 벡터 중에서 비슷한 이미지를 빠르게 찾는 데 FAISS가 사용될 수 있습니다.\n연관키워드: 벡터 검색, 머신러닝, 데이터베이스 최적화\n\nOpen Source'), Document(id='97cbabc0-2a3c-403f-a47d-15d2e1d665f3', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: HuggingFace는 자연어 처리를 위한 다양한 사전 훈련된 모델과 도구를 제공하는 라이브러리입니다. 이는 연구자와 개발자들이 쉽게 NLP 작업을 수행할 수 있도록 돕습니다.\n예시: HuggingFace의 Transformers 라이브러리를 사용하여 감정 분석, 텍스트 생성 등의 작업을 수행할 수 있습니다.\n연관키워드: 자연어 처리, 딥러닝, 라이브러리\n\nDigital Transformation\n\n정의: 디지털 변환은 기술을 활용하여 기업의 서비스, 문화, 운영을 혁신하는 과정입니다. 이는 비즈니스 모델을 개선하고 디지털 기술을 통해 경쟁력을 높이는 데 중점을 둡니다.\n예시: 기업이 클라우드 컴퓨팅을 도입하여 데이터 저장과 처리를 혁신하는 것은 디지털 변환의 예입니다.\n연관키워드: 혁신, 기술, 비즈니스 모델\n\nCrawling\n\n정의: 크롤링은 자동화된 방식으로 웹 페이지를 방문하여 데이터를 수집하는 과정입니다. 이는 검색 엔진 최적화나 데이터 분석에 자주 사용됩니다.\n예시: 구글 검색 엔진이 인터넷 상의 웹사이트를 방문하여 콘텐츠를 수집하고 인덱싱하는 것이 크롤링입니다.\n연관키워드: 데이터 수집, 웹 스크래핑, 검색 엔진\n\nWord2Vec'), Document(id='421bbc7e-2fce-47bb-b414-23fe639a6aba', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='Semantic Search\n\n정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.\n예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.\n연관키워드: 자연어 처리, 검색 알고리즘, 데이터 마이닝\n\nEmbedding\n\n정의: 임베딩은 단어나 문장 같은 텍스트 데이터를 저차원의 연속적인 벡터로 변환하는 과정입니다. 이를 통해 컴퓨터가 텍스트를 이해하고 처리할 수 있게 합니다.\n예시: "사과"라는 단어를 [0.65, -0.23, 0.17]과 같은 벡터로 표현합니다.\n연관키워드: 자연어 처리, 벡터화, 딥러닝\n\nToken\n\n정의: 토큰은 텍스트를 더 작은 단위로 분할하는 것을 의미합니다. 이는 일반적으로 단어, 문장, 또는 구절일 수 있습니다.\n예시: 문장 "나는 학교에 간다"를 "나는", "학교에", "간다"로 분할합니다.\n연관키워드: 토큰화, 자연어 처리, 구문 분석\n\nTokenizer'), Document(id='45a24b1d-50f3-43f5-b57e-fba7729d3556', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: 토크나이저는 텍스트 데이터를 토큰으로 분할하는 도구입니다. 이는 자연어 처리에서 데이터를 전처리하는 데 사용됩니다.\n예시: "I love programming."이라는 문장을 ["I", "love", "programming", "."]으로 분할합니다.\n연관키워드: 토큰화, 자연어 처리, 구문 분석\n\nVectorStore\n\n정의: 벡터스토어는 벡터 형식으로 변환된 데이터를 저장하는 시스템입니다. 이는 검색, 분류 및 기타 데이터 분석 작업에 사용됩니다.\n예시: 단어 임베딩 벡터들을 데이터베이스에 저장하여 빠르게 접근할 수 있습니다.\n연관키워드: 임베딩, 데이터베이스, 벡터화\n\nSQL\n\n정의: SQL(Structured Query Language)은 데이터베이스에서 데이터를 관리하기 위한 프로그래밍 언어입니다. 데이터 조회, 수정, 삽입, 삭제 등 다양한 작업을 수행할 수 있습니다.\n예시: SELECT * FROM users WHERE age > 18;은 18세 이상의 사용자 정보를 조회합니다.\n연관키워드: 데이터베이스, 쿼리, 데이터 관리\n\nCSV')]
이번엔 다양성이 높고 더 많은 문서를 검색해 보기 위해 MMR 알고리즘을 사용해 보도록 하겠습니다.
retriever = db.as_retriever(
search_type="mmr",
search_kwargs={"k":6, "lambda_mult":0.25, "fetch_k":10}
)
response = retriever.invoke("Word2Vec에 대하여 알려줘")
print(len(response))
print(response)
설정한 대로 총 6개의 문서를 검색해 준 것을 확인할 수 있습니다.
Output:
6
[Document(id='b34cf825-648a-4836-8523-f5f08a4c7dbf', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: Word2Vec은 단어를 벡터 공간에 매핑하여 단어 간의 의미적 관계를 나타내는 자연어 처리 기술입니다. 이는 단어의 문맥적 유사성을 기반으로 벡터를 생성합니다.\n예시: Word2Vec 모델에서 "왕"과 "여왕"은 서로 가까운 위치에 벡터로 표현됩니다.\n연관키워드: 자연어 처리, 임베딩, 의미론적 유사성\nLLM (Large Language Model)\n\n정의: LLM은 대규모의 텍스트 데이터로 훈련된 큰 규모의 언어 모델을 의미합니다. 이러한 모델은 다양한 자연어 이해 및 생성 작업에 사용됩니다.\n예시: OpenAI의 GPT 시리즈는 대표적인 대규모 언어 모델입니다.\n연관키워드: 자연어 처리, 딥러닝, 텍스트 생성\n\nFAISS (Facebook AI Similarity Search)\n\n정의: FAISS는 페이스북에서 개발한 고속 유사성 검색 라이브러리로, 특히 대규모 벡터 집합에서 유사 벡터를 효과적으로 검색할 수 있도록 설계되었습니다.\n예시: 수백만 개의 이미지 벡터 중에서 비슷한 이미지를 빠르게 찾는 데 FAISS가 사용될 수 있습니다.\n연관키워드: 벡터 검색, 머신러닝, 데이터베이스 최적화\n\nOpen Source'), Document(id='97cbabc0-2a3c-403f-a47d-15d2e1d665f3', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: HuggingFace는 자연어 처리를 위한 다양한 사전 훈련된 모델과 도구를 제공하는 라이브러리입니다. 이는 연구자와 개발자들이 쉽게 NLP 작업을 수행할 수 있도록 돕습니다.\n예시: HuggingFace의 Transformers 라이브러리를 사용하여 감정 분석, 텍스트 생성 등의 작업을 수행할 수 있습니다.\n연관키워드: 자연어 처리, 딥러닝, 라이브러리\n\nDigital Transformation\n\n정의: 디지털 변환은 기술을 활용하여 기업의 서비스, 문화, 운영을 혁신하는 과정입니다. 이는 비즈니스 모델을 개선하고 디지털 기술을 통해 경쟁력을 높이는 데 중점을 둡니다.\n예시: 기업이 클라우드 컴퓨팅을 도입하여 데이터 저장과 처리를 혁신하는 것은 디지털 변환의 예입니다.\n연관키워드: 혁신, 기술, 비즈니스 모델\n\nCrawling\n\n정의: 크롤링은 자동화된 방식으로 웹 페이지를 방문하여 데이터를 수집하는 과정입니다. 이는 검색 엔진 최적화나 데이터 분석에 자주 사용됩니다.\n예시: 구글 검색 엔진이 인터넷 상의 웹사이트를 방문하여 콘텐츠를 수집하고 인덱싱하는 것이 크롤링입니다.\n연관키워드: 데이터 수집, 웹 스크래핑, 검색 엔진\n\nWord2Vec'), Document(id='45a24b1d-50f3-43f5-b57e-fba7729d3556', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: 토크나이저는 텍스트 데이터를 토큰으로 분할하는 도구입니다. 이는 자연어 처리에서 데이터를 전처리하는 데 사용됩니다.\n예시: "I love programming."이라는 문장을 ["I", "love", "programming", "."]으로 분할합니다.\n연관키워드: 토큰화, 자연어 처리, 구문 분석\n\nVectorStore\n\n정의: 벡터스토어는 벡터 형식으로 변환된 데이터를 저장하는 시스템입니다. 이는 검색, 분류 및 기타 데이터 분석 작업에 사용됩니다.\n예시: 단어 임베딩 벡터들을 데이터베이스에 저장하여 빠르게 접근할 수 있습니다.\n연관키워드: 임베딩, 데이터베이스, 벡터화\n\nSQL\n\n정의: SQL(Structured Query Language)은 데이터베이스에서 데이터를 관리하기 위한 프로그래밍 언어입니다. 데이터 조회, 수정, 삽입, 삭제 등 다양한 작업을 수행할 수 있습니다.\n예시: SELECT * FROM users WHERE age > 18;은 18세 이상의 사용자 정보를 조회합니다.\n연관키워드: 데이터베이스, 쿼리, 데이터 관리\n\nCSV'), Document(id='4c6e0b03-5958-4378-866c-b2d4ce0fe9fb', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='GPT (Generative Pretrained Transformer)\n\n정의: GPT는 대규모의 데이터셋으로 사전 훈련된 생성적 언어 모델로, 다양한 텍스트 기반 작업에 활용됩니다. 이는 입력된 텍스트에 기반하여 자연스러운 언어를 생성할 수 있습니다.\n예시: 사용자가 제공한 질문에 대해 자세한 답변을 생성하는 챗봇은 GPT 모델을 사용할 수 있습니다.\n연관키워드: 자연어 처리, 텍스트 생성, 딥러닝\n\nInstructGPT\n\n정의: InstructGPT는 사용자의 지시에 따라 특정한 작업을 수행하기 위해 최적화된 GPT 모델입니다. 이 모델은 보다 정확하고 관련성 높은 결과를 생성하도록 설계되었습니다.\n예시: 사용자가 "이메일 초안 작성"과 같은 특정 지시를 제공하면, InstructGPT는 관련 내용을 기반으로 이메일을 작성합니다.\n연관키워드: 인공지능, 자연어 이해, 명령 기반 처리\n\nKeyword Search'), Document(id='fef8aa37-6802-4f72-bb4c-4ff050a12386', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: 키워드 검색은 사용자가 입력한 키워드를 기반으로 정보를 찾는 과정입니다. 이는 대부분의 검색 엔진과 데이터베이스 시스템에서 기본적인 검색 방식으로 사용됩니다.\n예시: 사용자가 "커피숍 서울"이라고 검색하면, 관련된 커피숍 목록을 반환합니다.\n연관키워드: 검색 엔진, 데이터 검색, 정보 검색\n\nPage Rank\n\n정의: 페이지 랭크는 웹 페이지의 중요도를 평가하는 알고리즘으로, 주로 검색 엔진 결과의 순위를 결정하는 데 사용됩니다. 이는 웹 페이지 간의 링크 구조를 분석하여 평가합니다.\n예시: 구글 검색 엔진은 페이지 랭크 알고리즘을 사용하여 검색 결과의 순위를 정합니다.\n연관키워드: 검색 엔진 최적화, 웹 분석, 링크 분석\n\n데이터 마이닝\n\n정의: 데이터 마이닝은 대량의 데이터에서 유용한 정보를 발굴하는 과정입니다. 이는 통계, 머신러닝, 패턴 인식 등의 기술을 활용합니다.\n예시: 소매업체가 고객 구매 데이터를 분석하여 판매 전략을 수립하는 것은 데이터 마이닝의 예입니다.\n연관키워드: 빅데이터, 패턴 인식, 예측 분석\n\n멀티모달 (Multimodal)'), Document(id='009825d7-3701-427a-b7d4-e804b43da837', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content="정의: DataFrame은 행과 열로 이루어진 테이블 형태의 데이터 구조로, 주로 데이터 분석 및 처리에 사용됩니다.\n예시: 판다스 라이브러리에서 DataFrame은 다양한 데이터 타입의 열을 가질 수 있으며, 데이터 조작과 분석을 용이하게 합니다.\n연관키워드: 데이터 분석, 판다스, 데이터 처리\n\nAttention 메커니즘\n\n정의: Attention 메커니즘은 딥러닝에서 중요한 정보에 더 많은 '주의'를 기울이도록 하는 기법입니다. 이는 주로 시퀀스 데이터(예: 텍스트, 시계열 데이터)에서 사용됩니다.\n예시: 번역 모델에서 Attention 메커니즘은 입력 문장의 중요한 부분에 더 집중하여 정확한 번역을 생성합니다.\n연관키워드: 딥러닝, 자연어 처리, 시퀀스 모델링\n\n판다스 (Pandas)\n\n정의: 판다스는 파이썬 프로그래밍 언어를 위한 데이터 분석 및 조작 도구를 제공하는 라이브러리입니다. 이는 데이터 분석 작업을 효율적으로 수행할 수 있게 합니다.\n예시: 판다스를 사용하여 CSV 파일을 읽고, 데이터를 정제하며, 다양한 분석을 수행할 수 있습니다.\n연관키워드: 데이터 분석, 파이썬, 데이터 처리")]
다음은 MMR 알고리즘을 위해 더 많은 문서를 가져오되 상위 2개만 반환하도록 해보았습니다.
# MMR 알고리즘을 위해 더 많은 문서를 가져오되 상위 2개만 반환
retriever = db.as_retriever(
search_type="mmr",
search_kwargs={"k":2, "fetch_k":10}
)
response = retriever.invoke("Word2Vec에 대하여 알려줘")
print(len(response))
print(response)
Output:
2
[Document(id='b34cf825-648a-4836-8523-f5f08a4c7dbf', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: Word2Vec은 단어를 벡터 공간에 매핑하여 단어 간의 의미적 관계를 나타내는 자연어 처리 기술입니다. 이는 단어의 문맥적 유사성을 기반으로 벡터를 생성합니다.\n예시: Word2Vec 모델에서 "왕"과 "여왕"은 서로 가까운 위치에 벡터로 표현됩니다.\n연관키워드: 자연어 처리, 임베딩, 의미론적 유사성\nLLM (Large Language Model)\n\n정의: LLM은 대규모의 텍스트 데이터로 훈련된 큰 규모의 언어 모델을 의미합니다. 이러한 모델은 다양한 자연어 이해 및 생성 작업에 사용됩니다.\n예시: OpenAI의 GPT 시리즈는 대표적인 대규모 언어 모델입니다.\n연관키워드: 자연어 처리, 딥러닝, 텍스트 생성\n\nFAISS (Facebook AI Similarity Search)\n\n정의: FAISS는 페이스북에서 개발한 고속 유사성 검색 라이브러리로, 특히 대규모 벡터 집합에서 유사 벡터를 효과적으로 검색할 수 있도록 설계되었습니다.\n예시: 수백만 개의 이미지 벡터 중에서 비슷한 이미지를 빠르게 찾는 데 FAISS가 사용될 수 있습니다.\n연관키워드: 벡터 검색, 머신러닝, 데이터베이스 최적화\n\nOpen Source'), Document(id='97cbabc0-2a3c-403f-a47d-15d2e1d665f3', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: HuggingFace는 자연어 처리를 위한 다양한 사전 훈련된 모델과 도구를 제공하는 라이브러리입니다. 이는 연구자와 개발자들이 쉽게 NLP 작업을 수행할 수 있도록 돕습니다.\n예시: HuggingFace의 Transformers 라이브러리를 사용하여 감정 분석, 텍스트 생성 등의 작업을 수행할 수 있습니다.\n연관키워드: 자연어 처리, 딥러닝, 라이브러리\n\nDigital Transformation\n\n정의: 디지털 변환은 기술을 활용하여 기업의 서비스, 문화, 운영을 혁신하는 과정입니다. 이는 비즈니스 모델을 개선하고 디지털 기술을 통해 경쟁력을 높이는 데 중점을 둡니다.\n예시: 기업이 클라우드 컴퓨팅을 도입하여 데이터 저장과 처리를 혁신하는 것은 디지털 변환의 예입니다.\n연관키워드: 혁신, 기술, 비즈니스 모델\n\nCrawling\n\n정의: 크롤링은 자동화된 방식으로 웹 페이지를 방문하여 데이터를 수집하는 과정입니다. 이는 검색 엔진 최적화나 데이터 분석에 자주 사용됩니다.\n예시: 구글 검색 엔진이 인터넷 상의 웹사이트를 방문하여 콘텐츠를 수집하고 인덱싱하는 것이 크롤링입니다.\n연관키워드: 데이터 수집, 웹 스크래핑, 검색 엔진\n\nWord2Vec')]
이번엔 특정 임계값 이상의 유사도를 가진 문서만 검색하도록 해보았습니다.
# 특정 임계값 이상의 유사도를 가진 문서만 검색
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold":0.6}
)
response = retriever.invoke("Word2Vec에 대하여 알려줘")
print(len(response))
print(response)
임계값이 0.6보다 큰 문서는 하나뿐이며, 제대로 검색해 찾아주는 것을 확인할 수 있습니다.
Output:
1
[Document(id='b34cf825-648a-4836-8523-f5f08a4c7dbf', metadata={'source': '/content/drive/MyDrive/LangChain/nlp-keywords.txt'}, page_content='정의: Word2Vec은 단어를 벡터 공간에 매핑하여 단어 간의 의미적 관계를 나타내는 자연어 처리 기술입니다. 이는 단어의 문맥적 유사성을 기반으로 벡터를 생성합니다.\n예시: Word2Vec 모델에서 "왕"과 "여왕"은 서로 가까운 위치에 벡터로 표현됩니다.\n연관키워드: 자연어 처리, 임베딩, 의미론적 유사성\nLLM (Large Language Model)\n\n정의: LLM은 대규모의 텍스트 데이터로 훈련된 큰 규모의 언어 모델을 의미합니다. 이러한 모델은 다양한 자연어 이해 및 생성 작업에 사용됩니다.\n예시: OpenAI의 GPT 시리즈는 대표적인 대규모 언어 모델입니다.\n연관키워드: 자연어 처리, 딥러닝, 텍스트 생성\n\nFAISS (Facebook AI Similarity Search)\n\n정의: FAISS는 페이스북에서 개발한 고속 유사성 검색 라이브러리로, 특히 대규모 벡터 집합에서 유사 벡터를 효과적으로 검색할 수 있도록 설계되었습니다.\n예시: 수백만 개의 이미지 벡터 중에서 비슷한 이미지를 빠르게 찾는 데 FAISS가 사용될 수 있습니다.\n연관키워드: 벡터 검색, 머신러닝, 데이터베이스 최적화\n\nOpen Source')]
마지막으로 특정 메타데이터 필터를 적용해 보았습니다.
# 특정 메타데이터 필터 적용
retriever = db.as_retriever(
search_kwargs={"filter":{"source":"/content/drive/MyDrive/LangChain/finance-keywords.txt"}, "k":2}
)
response = retriever.invoke("Word2Vec에 대하여 알려줘")
print(len(response))
print(response)
쿼리와 관련이 없는 메타데이터에서 찾도록 해보았습니다. 검색해온 데이터를 살펴보면 실제로 finance-keywords.txt 파일에 있는 내용의 문서들만 찾아진 것을 확인할 수 있습니다.
Output:
2
[Document(id='c999b46f-68ec-45c4-9e99-b2d32f2f10cb', metadata={'source': '/content/drive/MyDrive/LangChain/finance-keywords.txt'}, page_content='정의: 주가수익비율(P/E)은 주가를 주당순이익으로 나눈 값으로, 기업의 가치를 평가하는 데 사용되는 지표입니다.\n예시: 아마존의 P/E 비율이 높은 것은 투자자들이 회사의 미래 성장 가능성을 높게 평가하고 있다는 것을 의미합니다.\n연관키워드: 주식 가치평가, 투자 분석, 성장주\n\nQuarterly Earnings Report\n\n정의: 분기별 실적 보고서는 기업이 3개월마다 발표하는 재무 성과와 사업 현황에 대한 보고서입니다.\n예시: 애플의 분기별 실적 발표는 전체 기술 섹터와 S&P 500 지수에 큰 영향을 미칩니다.\n연관키워드: 기업 실적, 투자자 관계, 재무 분석\n\nIndex Fund\n\n정의: 인덱스 펀드는 S&P 500과 같은 특정 지수의 구성과 성과를 그대로 추종하는 투자 상품입니다.\n예시: 바운가드 S&P 500 ETF는 S&P 500 지수를 추종하는 대표적인 인덱스 펀드입니다.\n연관키워드: 패시브 투자, ETF, 포트폴리오 관리\n\nMarket Weight'), Document(id='d2122e18-75d9-4234-829e-f9b40fb95bef', metadata={'source': '/content/drive/MyDrive/LangChain/finance-keywords.txt'}, page_content='정의: 시장 가중치는 특정 기업이나 섹터가 전체 지수에서 차지하는 비중을 나타냅니다.\n예시: 기술 섹터는 S&P 500 지수에서 가장 큰 시장 가중치를 차지하고 있습니다.\n연관키워드: 포트폴리오 구성, 섹터 분석, 자산 배분\n\nGrowth Stock\n\n정의: 성장주는 평균 이상의 높은 성장률을 보이는 기업의 주식을 의미합니다.\n예시: 페이스북(메타)과 같은 기술 기업들은 S&P 500에 포함된 대표적인 성장주로 꼽힙니다.\n연관키워드: 고성장 기업, 기술주, 투자 전략\n\nValue Stock\n\n정의: 가치주는 현재 시장 가치가 내재 가치보다 낮다고 평가되는 기업의 주식을 말합니다.\n예시: 워렌 버핏이 투자한 코카콜라는 S&P 500에 포함된 대표적인 가치주 중 하나입니다.\n연관키워드: 가치 투자, 배당주, 안정적 수익\n\nMarket Volatility\n\n정의: 시장 변동성은 주식 시장의 가격 변동 폭을 나타내는 지표입니다.\n예시: VIX 지수(변동성 지수)가 상승하면 S&P 500 지수의 변동성이 높아질 것으로 예상됩니다.\n연관키워드: 리스크 관리, 투자 심리, 헤지 전략\n\nEquity Research')]
2.3 Chroma를 이용한 멀티모달 검색
Chroma는 멀티모달 컬렉션, 즉 여러 양식의 데이터를 포함하고 쿼리할 수 있는 컬렉션을 지원합니다. 그렇 Chroma를 이용해 멀티 모달 임베딩 저장과 검색에 대해서 알아보도록 하겠습니다. 우선 예제 실행에 필요한 라이브러리 부터 설치를 진행해 줍니다.
pip install langchain langchain-core langchain-community langchain-openai datasets open-clip-torch langchain-experimental langchain-teddynote
2.3.1 데이터 준비
허깅페이스에서 호스팅되는 coco object detection dataset의 작은 하위 집합을 사용하도록 하겠습니다.
데이터 세트의 모든 이미지 중 일부만 로컬로 다운로드하고 이를 사용하여 멀티모달 컬렉션을 생성합니다.
import os
from datasets import load_dataset
from matplotlib import pyplot as plt
# coco 데이터셋 로드
dataset = load_dataset(path="detection-datasets/coco", name="default", split="train", streaming=True)
# 이미지 저장 폴더와 이미지 개수 설정
IMAGE_FOLDER = "/content/drive/MyDrive/LangChain/image"
N_IMAGES = 20
# 그래프 플로팅을 위한 설정
plot_cols = 5
plot_rows = N_IMAGES // plot_cols
fig, axex = plt.subplots(plot_rows, plot_cols, figsize=(plot_rows*2, plot_cols*2))
axes = axex.flatten()
# 이미지를 폴더에 저장하고 그래프에 표시
dataset_iter = iter(dataset)
os.makedirs(IMAGE_FOLDER, exist_ok=True)
for i in range(N_IMAGES):
# 데이터셋에서 이미지와 레이블 추출
data = next(dataset_iter)
image = data["image"]
label = data["objects"]["category"][0] # 첫 번째 객체의 카테고리를 레이블로 사용
# 그래프에 이미지 표시 및 레이블 추가
axes[i].imshow(image)
axes[i].set_title(label, fontsize=8)
axes[i].axis("off")
# 이미지 파일로 저장
image.save(f"{IMAGE_FOLDER}/{i}.jpg")
# 그래프 레이아웃 조정 및 표시
plt.tight_layout()
plt.show()

2.3.2 Multimodal Embeddings를 이용해 임베딩 생성
Multimodal Embeddings를 활용해 이미지, 텍스트에 대한 Embedding을 생성합니다. 예제에서는 OpenClipEmbeddingFunction을 사용하여 이미지를 임베딩합니다. 우선 아래 코드를 이용해 사용 가능한 모델의 이름과 체크포인트를 확인할 수 있습니다.
# 사용 가능한 모델 출력
import open_clip
import pandas as pd
pd.DataFrame(open_clip.list_pretrained(), columns=["model_name", "checkpoint"]).head(10)
| model_name | checkpoint | |
|---|---|---|
| 0 | RN50 | openai |
| 1 | RN50 | yfcc15m |
| 2 | RN50 | cc12m |
| 3 | RN101 | openai |
| 4 | RN101 | yfcc15m |
| 5 | RN50x4 | openai |
| 6 | RN50x16 | openai |
| 7 | RN50x64 | openai |
| 8 | ViT-B-32 | openai |
| 9 | ViT-B-32 | laion400m_e31 |
그럼 이번 예제에서 우리가 사용할 모델을 미리 정의해 놓도록 하겠습니다. ViT-H-14-378-quickgelu 모델의 dfn5b 체크포인트를 사용하도록 하겠습니다.
from langchain_experimental.open_clip import OpenCLIPEmbeddings
# OpenCLIP 임베딩 함수 객체 생성
image_embedding_function = OpenCLIPEmbeddings(
model_name="ViT-H-14-378-quickgelu", checkpoint="dfn5b"
)
coco 데이터셋에서 사용할 이미지들을 로컬로 저장합니다.
import os
# 이미지 경로를 리스트로 저장
image_uris = sorted(
[
os.path.join(IMAGE_FOLDER, image_name)
for image_name in os.listdir(IMAGE_FOLDER)
if image_name.endswith(".jpg")
]
)
print(image_uris)
Output:
['/content/drive/MyDrive/LangChain/image/0.jpg', '/content/drive/MyDrive/LangChain/image/1.jpg', '/content/drive/MyDrive/LangChain/image/10.jpg', '/content/drive/MyDrive/LangChain/image/11.jpg', '/content/drive/MyDrive/LangChain/image/12.jpg', '/content/drive/MyDrive/LangChain/image/13.jpg', '/content/drive/MyDrive/LangChain/image/14.jpg', '/content/drive/MyDrive/LangChain/image/15.jpg', '/content/drive/MyDrive/LangChain/image/16.jpg', '/content/drive/MyDrive/LangChain/image/17.jpg', '/content/drive/MyDrive/LangChain/image/18.jpg', '/content/drive/MyDrive/LangChain/image/19.jpg', '/content/drive/MyDrive/LangChain/image/2.jpg', '/content/drive/MyDrive/LangChain/image/3.jpg', '/content/drive/MyDrive/LangChain/image/4.jpg', '/content/drive/MyDrive/LangChain/image/5.jpg', '/content/drive/MyDrive/LangChain/image/6.jpg', '/content/drive/MyDrive/LangChain/image/7.jpg', '/content/drive/MyDrive/LangChain/image/8.jpg', '/content/drive/MyDrive/LangChain/image/9.jpg']
이미지에 대한 설명을 얻기 위해 gpt-4o-mini를 이용해 이미지를 주고 답변을 받도록 합니다.
from langchain_teddynote.models import MultiModal
from langchain_openai import ChatOpenAI
# ChatOpenAI 모델 초기화
llm = ChatOpenAI(model="gpt-4o-mini")
# MultiModal 모델 설정
model = MultiModal(
model=llm,
system_prompt="Your mission is to describe the image in detail", # 시스템 프롬프트: 이미지를 상세히 설명하도록 지시
user_prompt="Description should be written in one sentence(less than 60 characters)", # 사용자 프롬프트: 60자 이내의 한 문장으로 설명 요청
)
# 이미지 설명 생성
model.invoke(image_uris[0])
생성된 이미지 밑에 gpt-4o-mini로부터 받아온 설명이 함께 출력되어 있는 것을 볼 수 있습니다.

이제 모든 이미지에 대한 설명을 받아오도록 합니다. 참고로 20개의 이미지에 대한 설명을 요청하면 OpenAI의 gpt-4o-mini 기준 약 0.05\$의 비용이 발생합니다. 저는 구글 코랩에서 진행을 했는데 이후에 진행할 이미지와 텍스트의 유사도 계산에서 코랩에서 무료로 제공해 주는 램이 계산을 버티질 못해서 총 3번의 요청을 진행했고 하는 수 없이 RunPod의 Pod를 빌려 한 번 더 진행해 총 0.2\$의 비용이 청구되었습니다. 예제 진행하실 때 저 처럼 해서 애꿎은돈 날리지 마시고 gpt-4o-mini로 받아온 설명을 따로 저장해 두시길 바랍니다.
# 이미지 설명
descriptions = dict()
for image_uri in image_uris:
descriptions[image_uri] = model.invoke(image_uri, display_image=False)
# 생성된 결과물 출력
for key in descriptions.keys():
print(f"{key}: {descriptions[key]}")
Output:
/content/drive/MyDrive/LangChain/image/0.jpg: A colorful lunchbox featuring fruit, broccoli, and snacks.
/content/drive/MyDrive/LangChain/image/1.jpg: Two giraffes are feeding on leaves from a tall tree.
/content/drive/MyDrive/LangChain/image/10.jpg: Two giraffes intertwine their necks among trees.
/content/drive/MyDrive/LangChain/image/11.jpg: A vintage motorcycle with a sleek design and front headlight.
/content/drive/MyDrive/LangChain/image/12.jpg: A white dog sleeps peacefully on a cobblestone street.
/content/drive/MyDrive/LangChain/image/13.jpg: A skater performs tricks on a graffiti-covered ramp.
/content/drive/MyDrive/LangChain/image/14.jpg: A decorative owl candle holder next to an elegant clock.
/content/drive/MyDrive/LangChain/image/15.jpg: An Air France Airbus A380 flying through a cloudy sky.
/content/drive/MyDrive/LangChain/image/16.jpg: A man in a cap sits on a vintage motorcycle by a mailbox.
/content/drive/MyDrive/LangChain/image/17.jpg: A clean kitchen with a white stove and knife rack.
/content/drive/MyDrive/LangChain/image/18.jpg: A chocolate layered cake topped with coconut flakes.
/content/drive/MyDrive/LangChain/image/19.jpg: A quiet street scene featuring the "Peace Way Hotel."
/content/drive/MyDrive/LangChain/image/2.jpg: A white vase holds a colorful bouquet of flowers.
/content/drive/MyDrive/LangChain/image/3.jpg: A zebra grazes on green grass under bright sunlight.
/content/drive/MyDrive/LangChain/image/4.jpg: A joyful woman in a floral swimsuit holds a pink umbrella.
/content/drive/MyDrive/LangChain/image/5.jpg: A fluffy dog naps atop a pile of assorted shoes.
/content/drive/MyDrive/LangChain/image/6.jpg: Two horses perform rearing tricks with riders in an outdoor arena.
/content/drive/MyDrive/LangChain/image/7.jpg: Elephant riders navigate through dense tropical greenery.
/content/drive/MyDrive/LangChain/image/8.jpg: A vintage Rolex clock stands beside a street in a quiet area.
/content/drive/MyDrive/LangChain/image/9.jpg: A train travels along curved tracks in an industrial area.
그럼 이제 받아온 설명을 이미지에 첨부해 설명이 달린 이미지를 출력해 보도록 하겠습니다.
import os
from PIL import Image
import matplotlib.pyplot as plt
# 원본 이미지, 처리된 이미지, 텍스트 설명을 저장할 리스트 초기화
original_images = []
images = []
texts = []
# 그래프 크기 설정 (20x10)
plt.figure(figsize=(20, 10))
# IMAGE_FOLDER 디렉토리에 저장된 이미지 파일들 처리
for i, image_uri in enumerate(image_uris):
# 이미지 파일 열기 및 RGB 모드로 변환
image = Image.open(image_uri).convert("RGB")
# 4x5 그리그의 서브플롯 생성
plt.subplot(4, 5, i+1)
# 이미지 표시
plt.imshow(image)
# 이미지 파일명과 설명을 제목으로 설정
plt.title(f"{os.path.basename(image_uri)}\n{descriptions[image_uri]}", fontsize=8)
# x축과 y축의 눈금 제거
plt.xticks([])
plt.yticks([])
# 원본 이미지, 처리된 이미지, 텍스트 설명을 각 리스트에 추가
original_images.append(image)
images.append(image)
texts.append(descriptions[image_uri])
# 서브플롯 간 간격 조정
plt.tight_layout()

이제 이미지와 gpt-4o-mini가 생성한 설명에 대한 유사도를 구하고 이를 이미지로 나타내 보도록 하겠습니다.
import numpy as np
# 이미지와 텍스트 임베딩
# 이미지 URI를 사용하여 이미지 특징 추출
img_features = image_embedding_function.embed_image(image_uris)
# 텍스트 설명에 "This is" 접두사를 추가하고 텍스트 특징 추출
text_features = image_embedding_function.embed_documents(
["This is" + desc for desc in texts]
)
# 행렬 연산을 위해 리스트를 numpy 배열로 변환
img_features_np = np.array(img_features)
text_features_np = np.array(text_features)
# 유사도계산
# 텍스트와 이미지 특징 간의 코사인 유사도를 계산
similarity = np.matmul(text_features_np, img_features_np.T)
# 유사도 행렬을 시각화하기 위한 플롯 생성
count = len(descriptions)
plt.figure(figsize=(20, 14))
# 유사도 행렬을 히트맵으로 표시
plt.imshow(similarity, vmin=0.1, vmax=0.3, cmap="coolwarm")
plt.colorbar() # 컬러바 추가
# y축에 텍스트 설명 표시
plt.yticks(range(count), texts, fontsize=18)
plt.xticks([])
# 원본 이미지를 x축 아래에 표시
for i, image in enumerate(original_images):
plt.imshow(image, extent = (i-0.5, i+0.5, -1.6, -0.6), origin="lower")
# 유사도 값을 히트맵 텍스트로 표시
for x in range(similarity.shape[1]):
for y in range(similarity.shape[0]):
plt.text(x, y, f"{similarity[y, x]:.2f}", ha="center", va="center", size=12)
# 플롯 테두리 제거
for side in ["left", "top", "right", "bottom"]:
plt.gca().spines[side].set_visible(False)
# 플롯 범위 설정
plt.xlim([-0.5, count-0.5])
plt.ylim([count+0.5, -2])
# 제목 추가
plt.title("Cosine similarity between text and image features", size=20)

2.3.3 벡터 저장소 생성 및 이미지 추가
벡터 저장소를 생성하고 이미지를 추가합니다.
from langchain_chroma import Chroma
# DB 생성
image_db = Chroma(
collection_name = "multimodal",
embedding_function = image_embedding_function,
)
# 이미지 추가
image_db.add_images(uris=image_uris)
Output:
['d575af7f-03b5-47c4-999f-42f7e90c54ba',
'f254220e-0586-4bf2-a4fd-3bf8eefbcba8',
'8005eee4-a515-43f1-a2d2-dda2f449c500',
'8f1ae720-31c2-42d6-9c88-fc6017dab8fe',
'6a5786e0-df54-473a-97e6-ab7ae6a00307',
'7881d465-647c-4c6b-b563-603689779647',
'91cca9af-6a8d-49f9-b909-2d1de8133f91',
'e9a3c575-1d81-45c9-b828-fe7e6a326289',
'a3443088-e6ea-49ef-a363-4dfb81bb08e1',
'356688ee-a2a1-459a-bd19-a63353c89942',
'a920f120-984e-4c1d-85e5-7fccfc4bad21',
'a4e2e29f-bdf5-498c-8ff5-e2ea5638b21c',
'b4462766-73e8-4538-9633-7db6b4417370',
'd56a490f-d43e-4e23-b986-1074dca5ef7d',
'426259be-c1fd-4563-8d9e-cd33756e0850',
'081db4c7-8ad9-4cfc-9aee-98e3fb68d67c',
'011462c0-0cf0-448b-8d2d-7fce4199a0d1',
'9b8403a1-0dd4-4554-9895-f276621b7fda',
'a8a07bf0-94ab-4289-8674-e8db67c09b61',
'bbd1ac54-789d-497e-84ce-631a7cbac593']
아래는 이미지 검색된 결과를 이미지로 출력하기 위한 helper class입니다.
import base64
import io
from PIL import Image
from IPython.display import HTML, display
from langchain_core.documents import Document
class ImageRetriever:
def __init__(self, retriever):
"""
이미지 검색기를 초기화합니다.
인자:
retriever: LangChain의 retriever 객체
"""
self.retriever = retriever
def invoke(self, query):
"""
쿼리를 사용하여 이미지를 검색하고 표시합니다.
인자:
query (str): 검색 쿼리
"""
docs = self.retriever.invoke(query)
if docs and isinstance(docs[0], Document):
self.plt_img_base64(docs[0].page_content)
else:
print("검색된 이미지가 없습니다.")
return docs
@staticmethod
def resize_base64_image(base64_string, size=(224, 224)):
"""
Base64 문자열로 인코딩된 이미지의 크기를 조정합니다.
인자:
base64_string (str): 원본 이미지의 Base64 문자열.
size (tuple): (너비, 높이)로 표현된 원하는 이미지 크기.
반환:
str: 크기가 조정된 이미지의 Base64 문자열.
"""
img_data = base64.b64decode(base64_string)
img = Image.open(io.BytesIO(img_data))
resized_img = img.resize(size, Image.LANCZOS)
buffered = io.BytesIO()
resized_img.save(buffered, format=img.format)
return base64.b64encode(buffered.getvalue()).decode("utf-8")
@staticmethod
def plt_img_base64(img_base64):
"""
Base64로 인코딩된 이미지를 표시합니다.
인자:
img_base64 (str): Base64로 인코딩된 이미지 문자열
"""
image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />'
display(HTML(image_html))
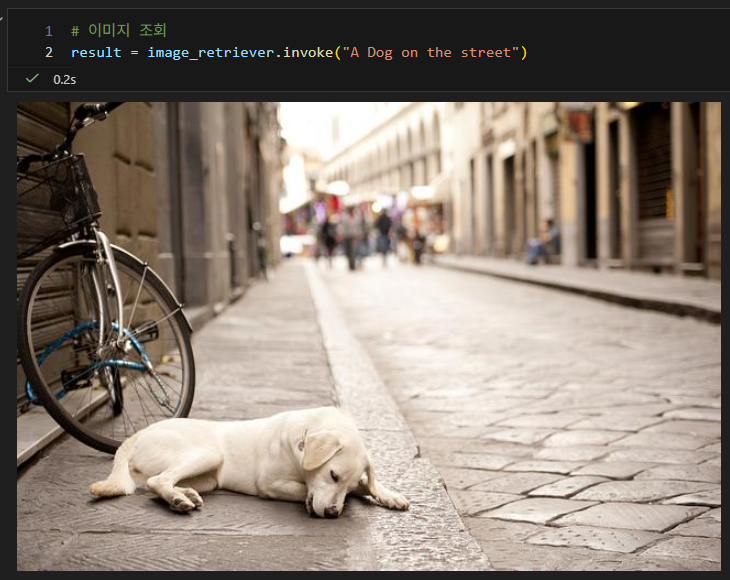
아래와 같이 “A Dog on the street” 라는 검색 쿼리를 넣어주면 길 위에서 강아지가 자고 있는 이미지를 출력해 줍니다.
# 이미지 조회
result = image_retriever.invoke("A Dog on the street")
마찬가지로 같이 “Motorcycle with a man” 라는 검색 쿼리를 넣어주면 오토바이를 타고 있는 남자 이미지를 출력해 줍니다.
# 이미지 조회
result = image_retriever.invoke("Motorcycle with a man")

3. FAISS
FAISS는 현재는 메타로 이름을 바꾼 Facebook에서 개발한 Facebook AI Similarity Search의 약자로 밀집 벡터의 효율적인 유사도 검색과 클러스터링을 위한 라이브러리입니다.
FAISS는 RAM에 맞지 않을 수도 있는 벡터 집합을 포함하여 모든 크기의 벡터 집합을 검색하는 알고리즘을 포함하고 있습니다. 또한 평가와 매개변수 튜닝을 위한 지원 코드도 포함되어 있습니다.
FAISS의 경우 문서와 텍스트 리스트를 이용한 벡터 저장소 생성, 문서 추가, 문서 제거, 유사도 검색, 검색기로 변환하는 것은 이전에 다루었던 Chroma와 동일한 메서드를 사용하므로 FAISS에서는 따로 다루지 않도록 하겠습니다. Chroma와 다른 벡터 저장소 로컬 저장과 불러오기, 벡터 저장소 병합 기능에 대해서만 살펴보도록 하겠습니다.
우선 예제를 살펴보기 전에 필요한 라이브러리 설치를 먼저 진행해 줍니다.
pip install langchain-community langchain langchain-core faiss-cpu langchain-text-splitters langchain-google-genai google-generativeai
이전 Chroma 때와 마찬가지로 예제에 사용할 문서들을 미리 로드해 놓도록 합니다.
# 샘플 데이터셋 로드
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 텍스트 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=600, chunk_overlap=0)
# 텍스트 파일을 load -> List[Document] 형태로 변환
loader1 = TextLoader("/content/drive/MyDrive/LangChain/nlp-keywords.txt")
loader2 = TextLoader("/content/drive/MyDrive/LangChain/finance-keywords.txt")
# 문서 분할
split_doc1 = loader1.load_and_split(text_splitter)
split_doc2 = loader2.load_and_split(text_splitter)
# 문서 개수 확인
print(len(split_doc1), len(split_doc2))
Output:
11 6
3.1 FAISS 벡터 저장소 생성
FAISS는 고성능 벡터 검색 및 클러스터링을 위한 라이브러리입니다. 이 클래스는 FAISS를 LangChain의 VectorStore 인터페이스와 통합합니다. 임베딩 함수, FAISS 인덱스, 문서 저장소를 조합하여 효율적인 검색 시스템을 구축할 수 있습니다.
import faiss
from langchain_community.vectorstores import FAISS
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_openai import OpenAIEmbeddings
# 임베딩
embeddings = OpenAIEmbeddings()
# 임베딩 차원 크기를 계산
dimension_size = len(embeddings.embed_query("hello world"))
print(dimension_size)
# FAISS 벡터 저장소 생성
db = FAISS(
embedding_function=OpenAIEmbeddings(),
index=faiss.IndexFlatL2(dimension_size),
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
3.2 FAISS 벡터 저장소 저장 및 로드
3.2.1 로컬 저장
save_local 메서드는 FAISS 인덱스, 문서 저장소, 그리고 인덱스-문서 ID 매핑을 로컬 디스크에 저장하는 기능을 제공합니다. 매개변수는 다음과 같습니다.
- folder_path(str): 저장할 폴더 경로
- index_name(str): 저장할 인덱스 파일 이름(기본값: “index”)
# 로컬 Disk 에 저장
db.save_local(folder_path="/content/drive/MyDrive/LangChain/db/faiss_db", index_name="faiss_index")
3.2.2 로컬에서 불러오기
load_local 클래스 메서드는 로컬 디스크에 저장된 FAISS 인덱스, 문서 저장소, 그리고 인덱스-문서 ID 매핑을 불러오는 기능을 제공합니다. 매개변수는 다음과 같습니다.
- folder_path(str): 불러올 파일들이 저장된 폴더 경로
- embeddings(Embeddings): 쿼리 생성에 사용할 임베딩 객체
- index_name(str): 불러올 인덱스 파일 이름(기본값: “index”)
- allow_dangerous_deserialization(bool): pickle 파일 역직렬화 허용 여부, 기본값은 False
# 저장된 데이터를 로드
loaded_db = FAISS.load_local(
folder_path = "/content/drive/MyDrive/LangChain/db/faiss_db/",
index_name = "faiss_index",
embeddings = embeddings,
allow_dangerous_deserialization=True,
)
# 로드된 데이터 확인
loaded_db.index_to_docstore_id
Output:
{0: 'bd99c170-f840-41cd-95f4-475258aa8aa9',
1: 'ab7078a7-3645-4ac4-bdd4-a5de5574c914',
2: '23aed86d-0158-46fd-aece-8744a30aec62',
3: '9098e210-7135-419e-9a41-500708c38740',
4: 'eeb84d3c-4a9b-4105-9f11-53bfd39dbd70',
5: '878d74b5-4d4c-4d2f-9a42-5e65e6afb67a',
6: '31fe04d4-c77e-4a35-a93c-d840ffb40977',
7: 'f9aca7fe-b294-446f-ab13-0fedcabb5cf8',
8: '1a2e62b8-9ddd-4628-9cd6-6a84980215fd',
9: '6464dc42-bf78-4db4-acb0-6169f8d45fdf',
10: '3c288235-eacf-4bea-8065-7a9a12339084'}
3.3 FAISS 객체 병합
merge_from 메서드는 현재 FAISS 객체에 다른 FAISS 객체를 병합하는 기능을 제공합니다. 매개변수는 다음과 같습니다.
- target(FAISS): 현재 객체에 병합할 대상 FAISS 객체
# 새로운 FAISS 벡터 저장소 생성
db2 = FAISS.from_documents(documents=split_doc2, embedding=embeddings)
# db와 db2의 데이터 확인
print(len(db.index_to_docstore_id))
print(db.index_to_docstore_id)
print()
print(len(db2.index_to_docstore_id))
print(db2.index_to_docstore_id)
병합 전 각 저장소의 자료 개수를 보면 db라는 변수명의 저장소에는 11개 db2라는 변수명의 저장소에는 6개가 있는 것을 확인할 수 있습니다.
Output:
11
{0: 'bd99c170-f840-41cd-95f4-475258aa8aa9', 1: 'ab7078a7-3645-4ac4-bdd4-a5de5574c914', 2: '23aed86d-0158-46fd-aece-8744a30aec62', 3: '9098e210-7135-419e-9a41-500708c38740', 4: 'eeb84d3c-4a9b-4105-9f11-53bfd39dbd70', 5: '878d74b5-4d4c-4d2f-9a42-5e65e6afb67a', 6: '31fe04d4-c77e-4a35-a93c-d840ffb40977', 7: 'f9aca7fe-b294-446f-ab13-0fedcabb5cf8', 8: '1a2e62b8-9ddd-4628-9cd6-6a84980215fd', 9: '6464dc42-bf78-4db4-acb0-6169f8d45fdf', 10: '3c288235-eacf-4bea-8065-7a9a12339084'}
6
{0: '51aa5552-0b3d-4461-9e93-3a9d4333d251', 1: '6f7c9a38-71f9-4f07-b6e1-5876781f0531', 2: '8de02844-a234-4df1-a9d3-550a23cb1989', 3: 'e0fc5959-d326-43e6-9ef1-e8d4a12517af', 4: 'cd119cb9-561b-400c-b670-6e0ee24d98c7', 5: '03e2bbbe-036e-4129-b7b5-4e33ab5e2088'}
# db + db2를 병합
db.merge_from(db2)
print(len(db.index_to_docstore_id))
print(db.index_to_docstore_id)
병합 후에는 자료의 개수가 11개와 6개가 합쳐진 17개인 것을 확인할 수 있습니다.
Output:
17
{0: 'bd99c170-f840-41cd-95f4-475258aa8aa9', 1: 'ab7078a7-3645-4ac4-bdd4-a5de5574c914', 2: '23aed86d-0158-46fd-aece-8744a30aec62', 3: '9098e210-7135-419e-9a41-500708c38740', 4: 'eeb84d3c-4a9b-4105-9f11-53bfd39dbd70', 5: '878d74b5-4d4c-4d2f-9a42-5e65e6afb67a', 6: '31fe04d4-c77e-4a35-a93c-d840ffb40977', 7: 'f9aca7fe-b294-446f-ab13-0fedcabb5cf8', 8: '1a2e62b8-9ddd-4628-9cd6-6a84980215fd', 9: '6464dc42-bf78-4db4-acb0-6169f8d45fdf', 10: '3c288235-eacf-4bea-8065-7a9a12339084', 11: '51aa5552-0b3d-4461-9e93-3a9d4333d251', 12: '6f7c9a38-71f9-4f07-b6e1-5876781f0531', 13: '8de02844-a234-4df1-a9d3-550a23cb1989', 14: 'e0fc5959-d326-43e6-9ef1-e8d4a12517af', 15: 'cd119cb9-561b-400c-b670-6e0ee24d98c7', 16: '03e2bbbe-036e-4129-b7b5-4e33ab5e2088'}
4. Pinecone
Pinecone은 고성능 벡터 데이터 베이스로, AI 및 머신러닝 애플리케이션을 위한 효율적인 벡터 저장 및 검색 솔루션입니다. Pinecone의 장점과 단점에 대해서 알아보고, 이전에 알아본 Chroma와 FAISS와 비교를 해보도록 하겠습니다.
Pinecone의 장점
- 확장성: 대규모 데이터셋에 대해 뛰어난 확장성을 제공합니다.
- 관리 용이성: 완전 관리형 서비스로 인프라 관리 부담이 적습니다.
- 실시간 업데이트: 데이터의 실시간 삽입, 업데이트, 삭제가 가능합니다.
- 고가용성: 클라우드 기반으로 높은 가용성과 내구성을 제공합니다.
- API 친화적: RESTfull/Python API를 통해 쉽게 통합할 수 있습니다.
Pinecone의 단점
- 비용: Chroma나 FAISS에 비해 상대적으로 비용이 높을 수 있습니다.
- 커스터마이징 제한: 완전 관리형 서비스이기 때문에 세부적인 커스터마이징에 제한이 있을 수 있습니다 .
- 데이터 위치: 클라우드에 데이터를 저장해야 하므로, 데이터 주권 문제가 있을 수 있습니다.
Chroma와 FAISS와 비교했을 때
- Chroma/FAISS는 오픈소스이며 로컬에서 실행 가능하여 초기 비용이 낮고 데이터 제어가 용이합니다. 커스터마이징의 자유도가 높습니다. 하지만 대규모 확장성 면에서는 Pinecone에 비해 제한적일 수 있습니다.
- 대규모 프로덕션에서는 Pinecone이 유리할 수 있지만, 소규모 프로젝트나 실험적인 환경에서는 Chroma나 FAISS가 더 적합할 수 있습니다.
그럼 예제를 통해 Pinecone 벡터 DB를 어떻게 사용하면 되는지 알아보도록 하겠습니다. 예제를 실행하기 전에 예제 실행에 필요한 라이브러리 설치를 먼저 진행해 주시길 바랍니다.
pip install langchain-teddynote langchain langchain-community langchain-text-splitters langchain-core langchain-openai pymupdf pinecone
4.1 사전 준비
4.1.1 한글 처리를 위한 불용어 사전 가져오기
토크나이저에 사용하기 위한 한글 불용어 사전을 가져옵니다.
# 한국어 불용어 가져오기
from langchain_teddynote.korean import stopwords
print(stopwords()[:20])
Output:
['아', '휴', '아이구', '아이쿠', '아이고', '어', '나', '우리', '저희', '따라', '의해', '을', '를', '에', '의', '가', '으로', '로', '에게', '뿐이다']
4.1.2 데이터 전처리
아래 코드는 pdf 파일을 문서를 사용하기 위한 전처리 과정입니다. 사용한 문서는 소프트웨어정책연구소(SPRi) 간행물 인공지능 산업의 최신 동향 2024년 1월호부터 12월호 pdf 파일들입니다. 이 pdf 파일들은 SPRi 사이트의 간행물 항목에서 다운로드 받으실 수 있습니다.
# 데이터 전처리
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
import glob
# 텍스트 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
split_docs = []
# 텍스트 파일을 load -> List[Document] 형태로 변환
files = sorted(glob.glob("/content/drive/MyDrive/LangChain/pdf_data/*.pdf"))
for file in files:
loader = PyMuPDFLoader(file)
split_docs.extend(loader.load_and_split(text_splitter))
# 문서 개수 확인
print(len(split_docs))
Output:
1551
전처리한 문서들 중 첫 번째 문서를 출력해 보면 다음과 같습니다.
print(split_docs[0].page_content)
print(split_docs[0].metadata)
Output:
2024년 10월호
{'producer': 'Hancom PDF 1.3.0.547', 'creator': 'Hwp 2018 10.0.0.13947', 'creationdate': '2024-10-07T09:05:46+09:00', 'source': '/content/drive/MyDrive/LangChain/pdf_data/SPRi AI Brief_10월호_산업동향_F.pdf', 'file_path': '/content/drive/MyDrive/LangChain/pdf_data/SPRi AI Brief_10월호_산업동향_F.pdf', 'total_pages': 25, 'format': 'PDF 1.4', 'title': '', 'author': 'dj', 'subject': '', 'keywords': '', 'moddate': '2024-10-07T09:05:46+09:00', 'trapped': '', 'modDate': "D:20241007090546+09'00'", 'creationDate': "D:20241007090546+09'00'", 'page': 0}
아래 코드는 전처리된 문서들에 대한 전처리를 진행합니다. 문서의 전처리는 메타데이터 정보들 중에서 필요한 것만 추출해 오도록 하거나 최소 길이 이상의 데이터만 가져오도록 하고, 메타데이터 중 하나인 파일 이름에 파일 이름 앞의 경로를 없애는 전처리를 진행합니다.
from langchain_teddynote.community.pinecone import preprocess_documents
contents, metadatas = preprocess_documents(
split_docs = split_docs,
metadata_keys = ["source", "page", "author"],
min_length = 5,
use_basename = True,
)
문서 전처리를 진행한 문서의 내용을 확인해 보면 다음과 같습니다.
# VectorStore에 저장할 문서 확인
contents[:5]
Output:
['2024년 10월호',
'2024년 10월호\nⅠ. 인공지능 산업 동향 브리프\n 1. 정책/법제 \n ▹ 미·영·EU, 법적 구속력 갖춘 유럽평의회의 AI 국제조약에 서명········································· 1\n ▹ 미국 캘리포니아 주지사, AI 규제법안 「SB1047」에 거부권 행사······································ 2\n ▹ 호주 의회, 동의 없는 딥페이크 음란물 공유를 처벌하는 법안 통과·································· 3',
'▹ UN, ‘인류를 위한 AI 거버넌스’ 최종 보고서 발표····························································· 4\n \n 2. 기업/산업 \n ▹ 앤스로픽과 오픈AI, 미국 AI 안전연구소와 모델 평가 합의················································ 5',
'▹ 오픈AI, 추론에 특화된 AI 모델 ‘o1-프리뷰’ 출시······························································ 6\n ▹ 메타의 AI 모델 ‘라마’, 다운로드 수 3억 5천만 회 달성하며 활발한 생태계 형성··········· 7\n ▹ 구글, AI 신기능 ‘젬스’와 이미지 생성 모델 ‘이마젠 3’ 출시············································· 8',
'▹ 구글, C2PA 표준 적용으로 AI 생성물의 투명성 향상 추진··············································· 9\n ▹ 마이크로소프트, 오픈소스 소형 언어모델 ‘파이 3.5’ 공개··············································· 10\n ▹ 하이퍼라이트, 오류를 자체 수정하는 ‘리플렉션 70B’ 오픈소스 모델 공개····················· 11\n 3. 기술/연구']
문서 전처리를 진행한 문서의 메타데이터를 확인해 보면 다음과 같이 지정한 정보만 추출해 온 것을 확인할 수 있습니다.
# VectorStore에 저장할 metadata 확인
print(metadatas.keys())
Output:
dict_keys(['source', 'page', 'author'])
# metadata에서 source를 확인합니다.
metadatas["source"][:5]
Output:
['SPRi AI Brief_10월호_산업동향_F.pdf',
'SPRi AI Brief_10월호_산업동향_F.pdf',
'SPRi AI Brief_10월호_산업동향_F.pdf',
'SPRi AI Brief_10월호_산업동향_F.pdf',
'SPRi AI Brief_10월호_산업동향_F.pdf']
4.2 Pinecone 벡터 저장소 인덱스 생성
4.2.1 API 키 발급
Pinecone에 가서 회원 등록(sign up)을 진행하면 기본적으로 API KEY가 발급이 됩니다. 발급된 API KEY를 os 라이브러리를 이용해 환경변수에 등록을 해줍니다.
import os
os.environ["PINECONE_API_KEY"] = '본인의 Pinecone API KEY'
4.2.2 벡터 저장소 인덱스 생성
Pinecone에서 사용할 인덱스를 생성합니다. 저는 Pinecone의 인덱스에 사용할 모델로 OpenAI의 text-embedding-3-large 모델을 사용하기 때문에 Pinecone 인덱스의 dimesion 값을 해당 모델의 차원인 3072로 맞춰 주었습니다. 만약 다른 임베딩 모델을 사용하신다면 그 모델에 맞는 차원으로 맞춰 주시기 바랍니다. 그리고 metric은 유사도 측정 방법을 지정하는 매개변수로 만약 HybridSearch를 고려하고 있다면 metric은 dotproduct로 지정해야 합니다.
# pinecone 벡터 저장소 인덱스 생성
import os
from langchain_teddynote.community.pinecone import create_index
# Pinecone 인덱스 생성
pc_index = create_index(
api_key = os.environ["PINECONE_API_KEY"],
index_name = "test-db-index", # 인덱스 이름을 지정합니다.
dimension=3072, # 사용하는 임베딩 모델에 맞는 임베딩 차원을 맞춰줍니다.
metric="dotproduct", # 유사도 측정 방법을 지정합니다. (dotproduct, eucliean, cosine)
)
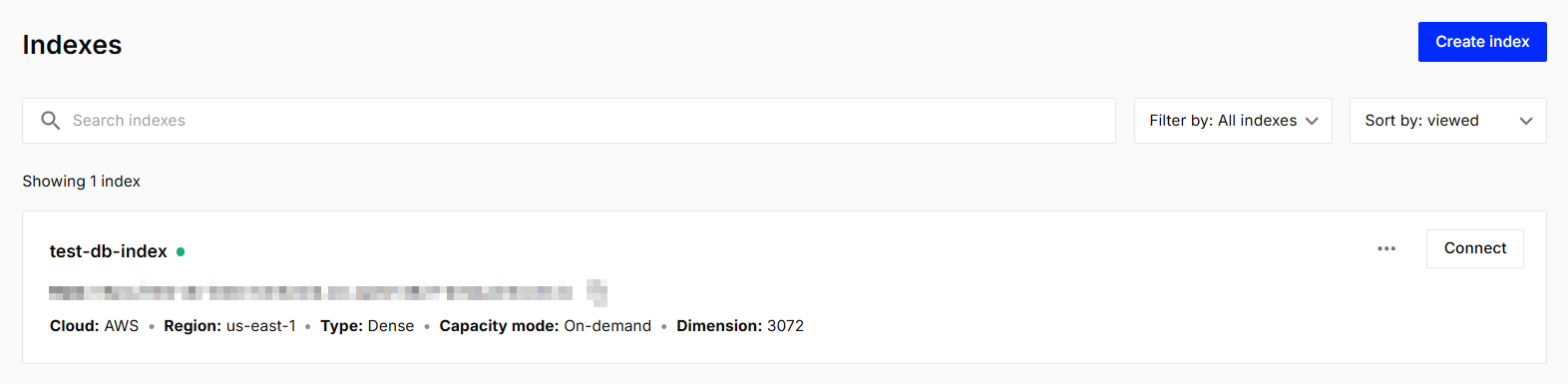
위 코드를 실행하면 아래 이미지 처럼 본인의 index 항목에 새로운 index가 생긴 것을 확인할 수 있습니다.
4.2.3 Sparse Encoder 생성
이번 예제에서는 Dense 벡터인 임베딩 벡터와 Sparse 벡터 두 벡터를 사용한 Hybrid Search 검색기를 사용하고자 합니다. Sparse 벡터는 Dense 벡터와는 다르게 사용하는 전체 문서의 token 개수 만큼을 차원으로 가지며, 쿼리나 문서에 등장한 token 이외에는 모두 0의 값을 가지는 벡터로 등장한 token에만 의미를 부여하는 벡터입니다. 이 예제에서는 Sparse 벡터를 생성하기 위해 Sparse Encoder를 정의합니다. Sparse Encoder를 정의하는 과정은 다음과 같습니다.
- Sparse Encoder를 생성합니다.
- Kiwi Tokenizer와 한글 불용어 처리를 수행합니다.
- Sparse Encoder를 활용하여 contents를 학습합니다. 여기서 학습한 인코드는 벡터 저장소에 문서를 저장할 때 Sparse 벡터를 생성할 때 활용됩니다.
# Sparse Encoder 생성
from langchain_teddynote.community.pinecone import(
create_sparse_encoder,
fit_sparse_encoder,
)
# 한글 불용어 사전 + Kiwi 형태소 분석기를 사용합니다.
sparse_encoder = create_sparse_encoder(stopwords(), mode="kiwi")
Sparse Encoder에 corpus를 학습합니다. 지정한 save_path에 pickle 파일이 저장됩니다.
# Sparse Encoder를 사용하여 contents를 학습
saved_path = fit_sparse_encoder(
sparse_encoder=sparse_encoder, contents=contents, save_path="/content/drive/MyDrive/LangChain/sparse_encoder.pkl"
)
아래 코드는 학습해서 저장된 Sparse Encoder pickle 파일을 로드하는 코드입니다.
# 학습된 sparse encoder를 불러올 때 사용하는 코드
from langchain_teddynote.community.pinecone import load_sparse_encoder
sparse_encoder = load_sparse_encoder("/content/drive/MyDrive/LangChain/sparse_encoder.pkl")
4.3 Pinecone Index에 데이터 추가(Upsert)
그럼 이제 생성한 Pinecone index에 데이터 추가 작업에 대해서 알아보도록 하겠습니다.
4.3.1 임베딩 모델 정의
문서의 내용을 임베딩 벡터로 만들어줄 임베딩 모델을 먼저 정의합니다. 저는 OpenAI의 text-embedding-3-large 모델을 사용했습니다. 이번 예제에 사용한 전체 데이터의 임베딩화를 진행했을 때 약 0.05\$ 정도 사용한 것 같습니다 참고하시기 바랍니다.
from langchain_openai import OpenAIEmbeddings
openai_embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
4.3.2 데이터 추가
langchain-teddynote 라이브러리에서 제공하는 upsert_documents 메서드를 이용했습니다. 특히 아래 코드는 분산처리를 수행하여 대용량 문서를 빠르게 Upsert하는 코드입니다. 대용량 데이터 업로드시 사용하면 됩니다. 분산처리를 하지 않은 코드와 차이점은 분산처리를 한 경우 upsert_documents 메서드에 max_workers 매개변수가 사용됩니다.
%%time
# 분산 처리를 수행해 빠르게 문서를 Upsert하는 코드
from langchain_teddynote.community.pinecone import upsert_documents_parallel
upsert_documents_parallel(
index=pc_index,
namespace="namespace-01",
contents=contents,
metadatas=metadatas,
sparse_encoder=sparse_encoder,
embedder=openai_embeddings,
batch_size=64,
max_workers=30,
)
Output:
문서 Upsert 중: 100%
25/25 [00:13<00:00, 6.22it/s]
총 1551개의 Vector 가 Upsert 되었습니다.
{'dimension': 3072,
'index_fullness': 0.0,
'namespaces': {'namespace-01': {'vector_count': 1551}},
'total_vector_count': 1551}
CPU times: user 12 s, sys: 720 ms, total: 12.7 s
Wall time: 13.4 s
아래 코드는 분산 처리를 하지 않고 문서를 Upsert 하는 코드입니다. 분산처리를 했을 경우와 하지 않을 경우 대략 10배 정도 속도 차이가 납니다.
%%time
# 분산 처리를 하지 않고 배치 단위로 문서를 Upsert하는 코드
from langchain_teddynote.community.pinecone import upsert_documents
upsert_documents(
index=pc_index,
namespace="namespace-01",
contents=contents,
metadatas=metadatas,
sparse_encoder=sparse_encoder,
embedder=openai_embeddings,
batch_size=32,
)
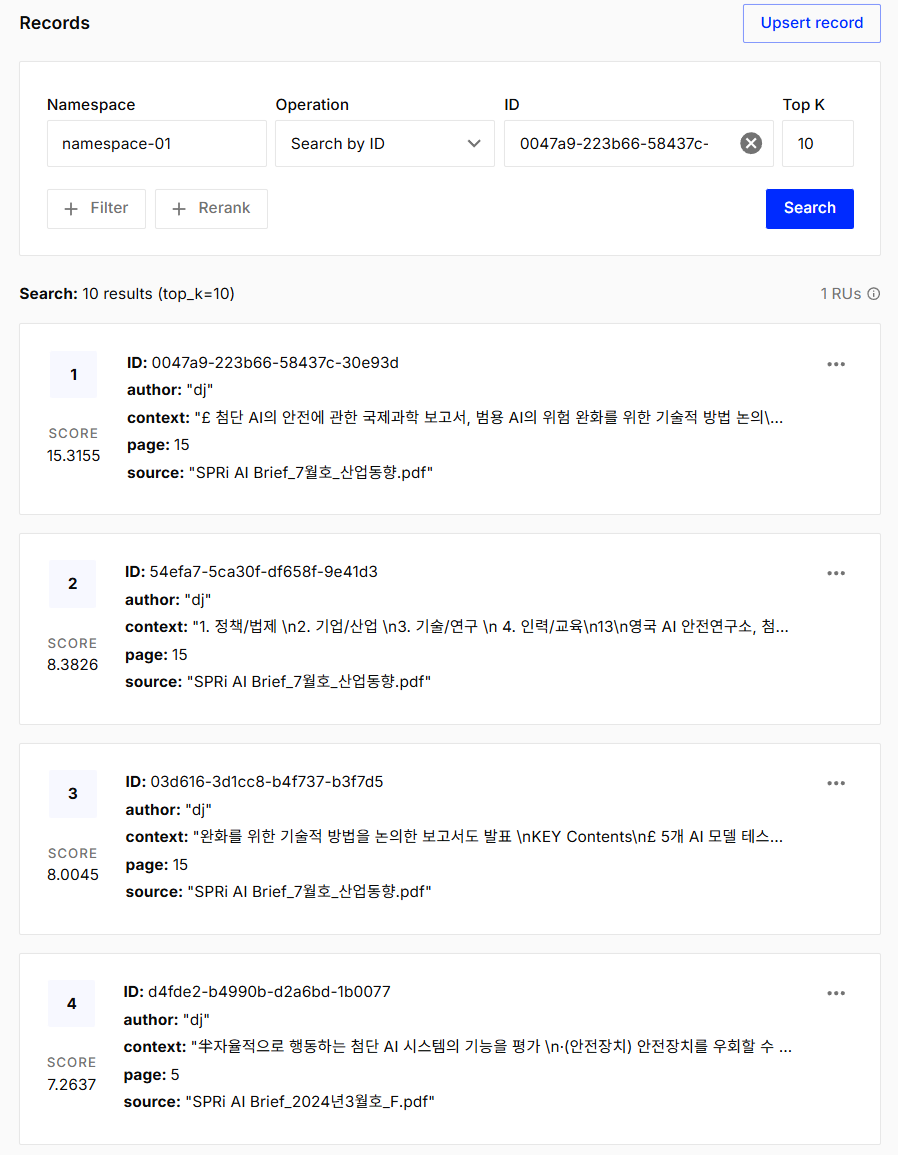
위 코드를 이용해 Pinecone index에 upsert를 하게 되면 Pinecone의 index를 클릭했을 경우 아래와 같이 upsert된 데이터들을 확인할 수 있습니다.
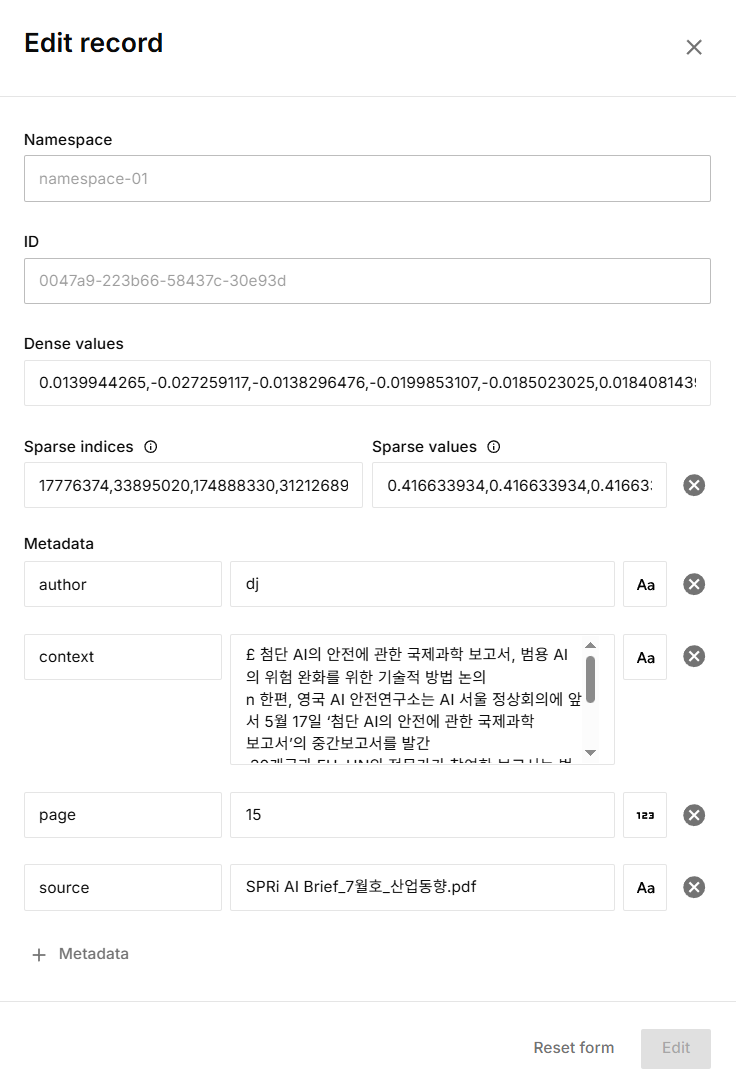
그리고 각 데이터 오른쪽에 있는 $\cdots$ 모양을 클릭해 나오는 Edit를 클릭하면 나오면 화면에서 구체적인 정보를 확인할 수 있습니다.
4.4 인덱스 조회 및 네임스페이스 삭제
4.4.1 인덱스 조회
describe_index_stats 메서드는 인덱스의 내용에 대한 통계 정보를 제공합니다. 이 메서드를 통해 네임스페이스별 벡터 수와 차원 수 등의 정보를 얻을 수 있습니다. 참고로 metadata를 이용해 필터링을 할 수 있지만 이는 유료 이용자에게만 제공합니다. 따라서 이번 예제에서는 조회 예제만 알아보도록 하겠습니다.
# 인덱스 조회
print(pc_index.describe_index_stats())
Output:
{'dimension': 3072,
'index_fullness': 0.0,
'namespaces': {'namespace-01': {'vector_count': 1551}},
'total_vector_count': 1551}
4.4.2 네임스페이스 삭제
delete_namespace 메서드를 이용해 네임스페이스 삭제를 할 수 있습니다.
# 네임스페이스 삭제
from langchain_teddynote.community.pinecone import delete_namespace
delete_namespace(index=pc_index, namespace="namespace-01")
4.5 검색기(Retriever) 생성
4.5.1 PineconeKiwiHybridRetriever 사용을 위한 Pinecone 인덱스 초기화 파라미터 설정
Dense 벡터와 Sparse 벡터를 이용한 Hybrid 검색기를 사용하고자 합니다. Dense 벡터는 OpenAI를 이용하며, Sparse 벡터는 Kiwi와 Sparse Encoder를 이용합니다. 그렇다면 이런 Hybrid 검색기를 사용하기 위해선 Pinecone 인덱스 초기화 파라미터를 설정해 주어야 합니다. init_pinecone_index 함수를 사용해 초기화를 진행해 줍니다. 해당 함수의 매개변수는 다음과 같습니다.
- index_name(str): 사용하고자 하는 Pinecone의 인덱스 이름입니다.
- namespace(str): 사용하고자 하는 네임스페이스 이름입니다.
- api_key(str): 본인의 Pinecone API KEY 값입니다.
- sparse_encoder_path(str): 사용하고자 하는 sparse encoder pickle 파일이 저장된 경로입니다.
- stopwords(List[Str]): 사용하고자 하는 불용어 사전 리스트입니다.
- tokenizer(str): 사용하고자 하는 토크나이저 이름입니다. (기본값은 kiwi입니다.)
- embeddings(Embeddings): 사용하고자 하는 임베딩 모델입니다.
- top_k(int): 반환할 최대 문서의 수 입니다. (기본 값은 10입니다.)
- alpha(float): dense 벡터와 sparse 벡터의 가중치 조절 파라미터 입니다. (기본값은 0.5입니다.)
# 검색기 생성을 위한 pinecone index 초기화 진행
from langchain_teddynote.community.pinecone import init_pinecone_index
pinecone_params = init_pinecone_index(
index_name = "test-db-index", # pinecone 인덱스 이름
namespace = "namespace-01", # pinecone namespace
api_key = os.environ["PINECONE_API_KEY"], # pinecone api key
sparse_encoder_path = "/content/drive/MyDrive/LangChain/sparse_encoder.pkl", # sparse encoder 저장경로
stopwords=stopwords(), # 불용어 사전
tokenizer="kiwi",
embeddings=openai_embeddings, # dense embedder
top_k=5, # Top-k 문서 반환 개수
alpha=0.5, # alpha=0.75로 설정한 경우 -> (0.75: Dense Embedding, 0.25: Sparse Embedding)
)
Output:
[init_pinecone_index]
{'dimension': 3072,
'index_fullness': 0.0,
'namespaces': {'namespace-01': {'vector_count': 1551}},
'total_vector_count': 1551}
4.5.2 PineconeKiwiHybridRetriever
PineconeKiwiHybridRetriever 클래스를 이용해 검색기를 정의합니다. PineconeKiwiHybridRetriever 클래스는 Pinecone과 Kiwi를 결합한 하이브리드 검색기를 구현합니다. 해당 클래스에는 좀 전에 우리가 초기화를 진행했던 pinecone_params를 넣어줍니다.
# pineconekiwihybridretriever 검색기
from langchain_teddynote.community.pinecone import PineconeKiwiHybridRetriever
# 검색기 생성
pinecone_retriever = PineconeKiwiHybridRetriever(**pinecone_params)
정의한 검색기로 일반 검색을 한 번 진행해 보도록 하겠습니다.
# 일반 검색
search_results = pinecone_retriever.invoke("gpt-4o 미니 출시 관련 정보에 대해서 알려줘")
for result in search_results:
print(result.page_content)
print(result.metadata)
print("\n==============\n")
쿼리와 관련된 5개의 문서를 검색해서 보여주는 것을 확인할 수 있습니다.
Output:
1. 정책/법제
2. 기업/산업
3. 기술/연구
4. 인력/교육
11
오픈AI, 비용 효율적인 소형 AI 모델 ‘GPT-4o 미니’ 출시
n 오픈AI가 GPT-3.5 터보 대비 60% 이상 저렴한 소형 모델 ‘GPT-4o’ 미니를 발표했으며, 저렴한
비용과 낮은 지연 시간으로 다양한 애플리케이션에 활용될 것으로 기대
n GPT-4o는 주요 벤치마크에서 GPT-3.5를 앞섰으며, 경쟁 소형 모델인 구글의 제미나이 플래시와
앤트로픽의 클로드 하이쿠보다 높은 점수를 기록
KEY Contents
{'context': '1. 정책/법제 \n2. 기업/산업 \n3. 기술/연구 \n 4. 인력/교육\n11\n오픈AI, 비용 효율적인 소형 AI 모델 ‘GPT-4o 미니’ 출시\nn 오픈AI가 GPT-3.5 터보 대비 60% 이상 저렴한 소형 모델 ‘GPT-4o’ 미니를 발표했으며, 저렴한 \n비용과 낮은 지연 시간으로 다양한 애플리케이션에 활용될 것으로 기대\nn GPT-4o는 주요 벤치마크에서 GPT-3.5를 앞섰으며, 경쟁 소형 모델인 구글의 제미나이 플래시와 \n앤트로픽의 클로드 하이쿠보다 높은 점수를 기록\nKEY Contents', 'page': 13.0, 'author': 'dj', 'source': 'SPRi AI Brief_8월호_산업동향.pdf'}
==============
앤트로픽의 클로드 하이쿠보다 높은 점수를 기록
KEY Contents
£ GPT-4o 미니, GPT-3.5 터보 대비 60% 이상 저렴하면서 성능은 우수
n 오픈AI는 2024년 7월 28일 가장 비용 효율적인 소형 모델인 ‘GPT-4o 미니’를 출시하고 챗GPT에서
GPT-3.5를 대신해 무료 사용자 및 플러스와 팀 사용자에게 제공한다고 발표
∙GPT-4o 미니는 입력 토큰 100만 개당 15센트, 출력 토큰 100만 개당 60센트로 가격이 책정되어,
GPT-3.5 터보 대비 60% 이상 저렴
{'context': '앤트로픽의 클로드 하이쿠보다 높은 점수를 기록\nKEY Contents\n£ GPT-4o 미니, GPT-3.5 터보 대비 60% 이상 저렴하면서 성능은 우수\nn 오픈AI는 2024년 7월 28일 가장 비용 효율적인 소형 모델인 ‘GPT-4o 미니’를 출시하고 챗GPT에서 \nGPT-3.5를 대신해 무료 사용자 및 플러스와 팀 사용자에게 제공한다고 발표\n∙GPT-4o 미니는 입력 토큰 100만 개당 15센트, 출력 토큰 100만 개당 60센트로 가격이 책정되어, \nGPT-3.5 터보 대비 60% 이상 저렴', 'page': 13.0, 'author': 'dj', 'source': 'SPRi AI Brief_8월호_산업동향.pdf'}
==============
대화 기록)를 전달하는 작업, 실시간 고객 지원 챗봇 등 다양한 작업을 처리 가능
∙오픈AI는 GPT-4o 미니를 통해 훨씬 저렴한 비용으로 AI를 이용할 수 있게 됨으로써 AI 애플리케이션
범위가 크게 확장될 것으로 기대
n GPT-4o 미니는 뛰어난 텍스트 성능과 다중모드 추론을 지원하여 주요 벤치마크에서 GPT-4o에는
미달하지만 GPT-3.5 터보와 기타 소형 모델을 능가하는 결과를 기록
∙GPT-4o 미니는 텍스트 지능과 추론 벤치마크인 MMLU에서 82.0%의 점수로 제미나이
{'context': '대화 기록)를 전달하는 작업, 실시간 고객 지원 챗봇 등 다양한 작업을 처리 가능\n∙오픈AI는 GPT-4o 미니를 통해 훨씬 저렴한 비용으로 AI를 이용할 수 있게 됨으로써 AI 애플리케이션 \n범위가 크게 확장될 것으로 기대\nn GPT-4o 미니는 뛰어난 텍스트 성능과 다중모드 추론을 지원하여 주요 벤치마크에서 GPT-4o에는 \n미달하지만 GPT-3.5 터보와 기타 소형 모델을 능가하는 결과를 기록\n∙GPT-4o 미니는 텍스트 지능과 추론 벤치마크인 MMLU에서 82.0%의 점수로 제미나이', 'page': 13.0, 'author': 'dj', 'source': 'SPRi AI Brief_8월호_산업동향.pdf'}
==============
GPT-4 터보의 86.5%와 구글 제미나이 울트라의 83.7%를 넘어섰음
n GPT-4o는 전 세계 사용자들에게 무료로 제공되며, 유료 사용자는 무료 사용자보다 5배 더 많은
질문을 할 수 있음
∙GPT-4o의 텍스트와 이미지 기능은 5월 13일부터 바로 제공되며, 유료 서비스인 챗GPT 플러스
사용자에게는 음성이 지원되는 신규 버전이 수 주 안에 출시될 예정
∙개발자들은 API로 GPT-4o의 텍스트와 이미지 기능을 사용할 수 있으며, 오디오와 비디오 기능은 수
주 안에 일부 파트너 집단에 선공개할 예정
{'context': 'GPT-4 터보의 86.5%와 구글 제미나이 울트라의 83.7%를 넘어섰음\nn GPT-4o는 전 세계 사용자들에게 무료로 제공되며, 유료 사용자는 무료 사용자보다 5배 더 많은 \n질문을 할 수 있음 \n∙GPT-4o의 텍스트와 이미지 기능은 5월 13일부터 바로 제공되며, 유료 서비스인 챗GPT 플러스 \n사용자에게는 음성이 지원되는 신규 버전이 수 주 안에 출시될 예정\n∙개발자들은 API로 GPT-4o의 텍스트와 이미지 기능을 사용할 수 있으며, 오디오와 비디오 기능은 수 \n주 안에 일부 파트너 집단에 선공개할 예정', 'page': 9.0, 'author': 'dj', 'source': 'SPRi AI Brief_6월호_산업동향 최종.pdf'}
==============
1. 정책/법제
2. 기업/산업
3. 기술/연구
4. 인력/교육
7
오픈AI, 사람과 자연스러운 실시간 대화가 가능한 ‘GPT-4o’ 출시
n 오픈AI가 응답시간이 최소 0.23초, 평균 0.32초에 불과해 사람과 실시간 음성 대화가 가능한
신규 AI 모델 ‘GPT-4o’를 무료로 공개
n GPT-4o는 API로 제공 시 기존 GPT 모델보다 처리속도가 2배 빠르고 비용은 절반 수준이며,
다국어, 오디오, 이미지 관련 벤치마크 테스트에서 최고 수준의 성능을 기록
KEY Contents
{'context': '1. 정책/법제 \n2. 기업/산업 \n3. 기술/연구 \n 4. 인력/교육\n7\n오픈AI, 사람과 자연스러운 실시간 대화가 가능한 ‘GPT-4o’ 출시\nn 오픈AI가 응답시간이 최소 0.23초, 평균 0.32초에 불과해 사람과 실시간 음성 대화가 가능한 \n신규 AI 모델 ‘GPT-4o’를 무료로 공개\nn GPT-4o는 API로 제공 시 기존 GPT 모델보다 처리속도가 2배 빠르고 비용은 절반 수준이며, \n다국어, 오디오, 이미지 관련 벤치마크 테스트에서 최고 수준의 성능을 기록\nKEY Contents', 'page': 9.0, 'author': 'dj', 'source': 'SPRi AI Brief_6월호_산업동향 최종.pdf'}
==============
이번엔 반환할 문서 수 k개를 조절한 결과를 출력해 보도록 하겠습니다. k값은 1로 설정해 주었습니다.
# 동적 search_kwargs 사용 k
search_results = pinecone_retriever.invoke("gpt-4o 미니 출시 관련 정보에 대해서 알려줘", search_kwargs={"k":1})
for result in search_results:
print(result.page_content)
print(result.metadata)
print("\n==============\n")
문서 하나만 검색해서 출력해 주는 것을 확인할 수 있습니다.
Output:
1. 정책/법제
2. 기업/산업
3. 기술/연구
4. 인력/교육
11
오픈AI, 비용 효율적인 소형 AI 모델 ‘GPT-4o 미니’ 출시
n 오픈AI가 GPT-3.5 터보 대비 60% 이상 저렴한 소형 모델 ‘GPT-4o’ 미니를 발표했으며, 저렴한
비용과 낮은 지연 시간으로 다양한 애플리케이션에 활용될 것으로 기대
n GPT-4o는 주요 벤치마크에서 GPT-3.5를 앞섰으며, 경쟁 소형 모델인 구글의 제미나이 플래시와
앤트로픽의 클로드 하이쿠보다 높은 점수를 기록
KEY Contents
{'context': '1. 정책/법제 \n2. 기업/산업 \n3. 기술/연구 \n 4. 인력/교육\n11\n오픈AI, 비용 효율적인 소형 AI 모델 ‘GPT-4o 미니’ 출시\nn 오픈AI가 GPT-3.5 터보 대비 60% 이상 저렴한 소형 모델 ‘GPT-4o’ 미니를 발표했으며, 저렴한 \n비용과 낮은 지연 시간으로 다양한 애플리케이션에 활용될 것으로 기대\nn GPT-4o는 주요 벤치마크에서 GPT-3.5를 앞섰으며, 경쟁 소형 모델인 구글의 제미나이 플래시와 \n앤트로픽의 클로드 하이쿠보다 높은 점수를 기록\nKEY Contents', 'page': 13.0, 'author': 'dj', 'source': 'SPRi AI Brief_8월호_산업동향.pdf'}
==============
이번엔 dense 벡터와 sparse 벡터의 비율을 조정하는 alpha 값을 조절해 보도록 하겠습니다. alpha 값에 1을 주어 dense 벡터만 사용하도록 해보았습니다.
# 동적 search_kwargs 사용 - alpha
search_results = pinecone_retriever.invoke(
"앤스로픽", search_kwargs={"alpha":1, "k":1}
)
for result in search_results:
print(result.page_content)
print(result.metadata)
print("\n==============\n")
검색된 문서 내용에 앤스로픽에 대한 내용이 생각보다 별로 없는 것을 볼 수 있습니다.
Output:
이노베이션 인스티튜트(TII), xAI, 지푸AI
** AI 생성물에 대한 워터마크 추가, 사이버보안 투자, AI 오남용 모니터링 등을 약속한 자발적 서약
∙앤스로픽의 잭 클라크(Jack Clark) 공동 창립자는 성명을 통해 “미국 AI 안전연구소와의 협력으로 모델 배포 전
엄격한 테스트를 통해 위험을 식별·완화하는 역량을 강화함으로써 책임 있는 AI 개발이 진전될 것”으로 기대
∙앤스로픽은 2024년 6월 ‘클로드 3.5 소네트(Claude 3.5 Sonnet)’ 출시 전 영국 AI 안전연구소와 협력해
{'context': '이노베이션 인스티튜트(TII), xAI, 지푸AI\n** AI 생성물에 대한 워터마크 추가, 사이버보안 투자, AI 오남용 모니터링 등을 약속한 자발적 서약 \n∙앤스로픽의 잭 클라크(Jack Clark) 공동 창립자는 성명을 통해 “미국 AI 안전연구소와의 협력으로 모델 배포 전 \n엄격한 테스트를 통해 위험을 식별·완화하는 역량을 강화함으로써 책임 있는 AI 개발이 진전될 것”으로 기대\n∙앤스로픽은 2024년 6월 ‘클로드 3.5 소네트(Claude 3.5 Sonnet)’ 출시 전 영국 AI 안전연구소와 협력해', 'page': 7.0, 'author': 'dj', 'source': 'SPRi AI Brief_10월호_산업동향_F.pdf'}
==============
그럼 이번엔 alpha 값을 0으로 주고 검색을 진행해 보도록 하겠습니다.
# 동적 search_kwargs 사용 - alpha
search_results = pinecone_retriever.invoke(
"앤스로픽", search_kwargs={"alpha":0, "k":1}
)
for result in search_results:
print(result.page_content)
print(result.metadata)
print("\n==============\n")
dense 벡터만 사용했을 때보다 sparse 벡터만 사용했을 때 사람의 기준으로 보면 더 잘 찾아주는 느낌이 듭니다. 아마도 그 이유는 dense 벡터의 경우 쿼리인 앤스로픽과 의미적으로 유사도가 높은 문서 위주로 찾아주는 반면 sparse 벡터는 일종의 키워드 검색과 비슷하게 쿼리에 사용한 단어가 많이 등장한 문서를 찾아주기 때문입니다.
Output:
KEY Contents
£ 앤스로픽, 사용자를 속이고 악성코드를 출력하는 LLM 연구
n 앤스로픽이 2024년 1월 15일 공개한 연구 결과에 따르면, AI도 사람처럼 의도적으로 거짓말을 해
사용자를 속일 수 있는 것으로 나타남
∙앤스로픽은 처음에는 정상적으로 보이지만 특별한 지시를 받으면 악성코드를 출력하는 ‘슬리퍼
에이전트(Sleeper Agent)’라는 LLM에 대한 논문을 발표
∙연구진은 특정 프롬프트가 주어지면 악성코드를 작성하는 백도어가 숨겨진 LLM의 훈련을 진행했으며,
{'context': 'KEY Contents\n£ 앤스로픽, 사용자를 속이고 악성코드를 출력하는 LLM 연구\nn 앤스로픽이 2024년 1월 15일 공개한 연구 결과에 따르면, AI도 사람처럼 의도적으로 거짓말을 해 \n사용자를 속일 수 있는 것으로 나타남\n∙앤스로픽은 처음에는 정상적으로 보이지만 특별한 지시를 받으면 악성코드를 출력하는 ‘슬리퍼 \n에이전트(Sleeper Agent)’라는 LLM에 대한 논문을 발표\n∙연구진은 특정 프롬프트가 주어지면 악성코드를 작성하는 백도어가 숨겨진 LLM의 훈련을 진행했으며,', 'page': 13.0, 'author': 'dj', 'source': 'SPRi AI Brief_2024년3월호_F.pdf'}
==============
마치며
LangChain에서 가장 많이 사용되는 3가지 벡터 저장소에 대해서 알아보았습니다. Chroma와 FAISS의 경우 로컬에서의 구현이 쉽고, 커스터마이징하기 좋아서 벡터 DB를 직접 구현할 수 있는 서버가 있을 때 굳이 비용을 써가며 벡터 DB를 사용하고 싶지 않거나 단순한 실험 혹은 공부를 위한 목적으로 사용하기 좋다는 것을 이번 기회에 다시 한 번 알게 되었습니다. 그리고 대충 Pinecone이라는 벡터 DB가 있다는 것을 알고 있었지만 이번 기회에 직접 Pinecone을 다뤄 볼 수 있었고, 그 사용법이 굉장히 간단해 흥미로웠습니다. 다만 제가 아직까지 벡터 DB를 활용하는 단계는 아니라 Pinecone에서 제공하는 유료 기능인 메타데이터를 이용한 필터 기능이나 ReRanking 기능을 사용해 보지 못해서 아쉬웠던 것 같습니다. 추후에는 이번 포스트에서 다뤄 보았던 3가지 벡터 DB 말고도 더 다양한 벡터 DB에 대해서 알아보고, Pinecone과 같은 기능을 제공하지만 좀 더 저렴하거나 무료로 사용할 수 있는 벡터 DB를 사용해 RAG 애플리케이션을 만들어 보고자 합니다.
긴 글 읽어주셔서 감사드리며, 본문 내용 중에 잘못된 내용이나 오타, 궁금하신 사항이 있으신 경우 댓글 달아주시기 바랍니다.
참조
- 판다스 스튜디오 - 랭체인(LangChain) 입문부터 응용까지(https://wikidocs.net/book/14473)
- 테디노트 - LangChain 한국어 튜토리얼KR(https://wikidocs.net/book/14314)
- 소프트웨어정책연구소(SPRi) - https://spri.kr/
Comments