
[LangChain] LangChain - 13. LangChain에서의 AI Agent에 대해 알아보자
머리말
1. 개요
Agent(에이전트)는 LangChain 및 기타 LLM 애플리케이션에서 중요한 개념으로, 인공지능 시스템이 더욱 자율적이고 목표 지향적으로 작업을 수행할 수 있게 해주는 컴포넌트입니다. 에이전트는 주어진 목표를 달성하기 위해 환경과 상호작용하며 의사 결정을 내리고 행동을 취하는 지능형 개체로 볼 수 있습니다.
Agent의 주요 특징은 다음과 같습니다.
- 자율성: 에이전트는 사전에 정의된 규칙이나 명시적인 프로그래밍 없이도 스스로 결정을 내리고 행동할 수 있습니다.
- 목표 지향성: 특정 목표나 작업을 달성하기 위해 설계되어 있습니다.
- 환경 인식: 주변 환경이나 상황을 인식하고 이에 따라 적응할 수 있습니다.
- 도구 사용: 다양한 도구나 API를 활용하여 작업을 수행할 수 있습니다.
- 연속성: 주어진 목표를 달성하기 위하여 1회 수행이 아닌 반복 수행을 통해 목표 달성을 추구합니다.
LangChain에서의 Agent는 다음과 같은 구성요소로 이루어져 있습니다.
- Agent: 의사 결정을 담당하는 핵심 컴포넌트입니다.
- Tools: 에이전트가 사용할 수 있는 기능들의 집합입니다.
- Toolkits: 관련된 도구들의 그룹입니다.
- AgentExecutor: 에이전트의 실행을 관리하는 컴포넌트입니다.
Agent의 작동 방식은 다음과 같습니다.
- 입력 수신: 사용자로부터 작업이나 질문을 받습니다.
- 계획 수립: 주어진 작업을 완료하기 위한 단계별 계획을 세웁니다.
- 도구 선택: 각 단계에 적합한 도구를 선택합니다.
- 실행: 선택한 도구를 사용하여 작업을 수행합니다.
- 결과 평가: 수행 결과를 평가하고 필요시 계획을 조정합니다.
- 출력 생성: 최종 결과나 답변을 사용자에게 제공합니다.
Agent는 다음과 같은 다양한 분야에서 활용될 수 있습니다.
- 정보 검색 및 분석: 웹 검색, 데이터베이스 쿼리 등을 수행합니다.
- 작업 자동화: 복잡한 워크플로우를 자동으로 처리합니다.
- 고객 서비스: 질문에 답변하고 문제를 해결합니다.
- 의사 결정 지원: 데이터를 분석하고 권장 사항을 제공합니다.
- 창의적 작업: 글쓰기, 코드 생성 등의 창의적 작업을 수행합니다.
Agent의 장점과 한계
장점
- 복잡한 작업의 자동화
- 유연성과 적응성
- 다양한 도구와의 통합 가능성
한계
- 제어와 예측 가능성의 어려움
- 계산 비용과 리소스 요구사항
2. Tools
Tools는 에이전트, 체인 또는 LLM이 외부 세계와 상호작용하기 위한 인터페이스입니다. LangChain에서 기본 제공하는 도구를 사용하여 쉽게 도구를 활용할 수 있으며, 사용자 정의 도구(Custom Tool)를 쉽게 구축하는 것도 가능합니다.
2.1 빌트인 도구(built-in tools)
랭체인에서 제공하는 사전에 정의된 도구(tool)와 툴킷(toolkit)을 사용할 수 있습니다. tool은 단일 도구를 의미하며, toolkit은 여러 도구를 묶어서 하나의 도구로 사용할 수 있습니다.
2.1.1 Python REPL 도구
Python REPL은 Python 코드를 REPL(Read-Eval-Print Loop) 환경에서 실행하기 위한 두 가지 주요 클래스를 제공합니다.
- Python 셸 환경을 제공합니다.
- 유효한 Python 명령어를 입력으로 받아 실행합니다.
- 결과를 보려면 print() 함수를 사용해야 합니다.
Python REPL의 주요 특징은 다음과 같습니다.
- sanitize_input: 입력을 정제하는 옵션(기본값: True)
- python_repl: PythonREPL 인스턴스(기본값: 전역 범위에서 실행)
사용 방법
- PythonREPLTool 인스턴스 생성
- run 또는 arun, invoke 메서드를 사용하여 Python 코드 실행
예제를 통해 구체적으로 알아보도록 하겠습니다. 우선 실습 코드를 실행하기 위해 다음 라이브러리들을 설치해줍니다.
!pip install langchain-openai langchain-core langchain-experimental
아래는 LLM 모델에게 파이썬 코드를 작성하도록 요청하고 결과를 반환하는 예제입니다. LLM 모델에게 특정 작업을 수행하는 Python 코드를 작성하도록 요청합니다. 작성된 코드를 실행하여 결과를 얻습니다. 얻어온 결과를 출력합니다.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda
from langchain_experimental.tools import PythonREPLTool
python_tool = PythonREPLTool()
# 파이썬 코드를 실행하고 중간 과정을 출력하고 도구 실행 결과를 반환하는 함수
def print_and_execute(code, debug=True):
if debug:
print("CODE")
print(code)
return python_tool.invoke(code)
# 파이썬 코드를 작성하도록 요청하는 프롬프트
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are Raymond Hettinger, an expert python programmer, well versed in meta-programming and elegant, concise and short but well documented code. You follow the PEP8 style guide. "
"Return only the code, no intro, no explanation, no chatty, no markdown, no code block, no nothing. Just the code.",
),
("human", "{input}"),
]
)
# LLM 모델 생성
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 프롬프트와 LLM 모델을 사용하여 체인 생성
chain = prompt | llm | StrOutputParser() | RunnableLambda(print_and_execute)
# 결과 출력
print(chain.invoke("로또 번호 생성기를 출력하는 코드를 작성하세요."))
결과를 출력해보면 Python 코드를 작성해 주는 것을 확인할 수 있습니다.
Output:
import random
def generate_lotto_numbers():
"""Generate a set of 6 unique lotto numbers from 1 to 45."""
return sorted(random.sample(range(1, 46), 6))
if __name__ == "__main__":
print(generate_lotto_numbers())
2.1.2 검색 API 도구
검색 API 도구를 사용하여 외부 검색 결과를 LLM에 질문에 엮을 수 있습니다. LangChain에서는 여러 검색 API 도구들이 있지만 그 중에서 Tavily 검색 API를 가장 많이 사용합니다. Tavily는 두 가지 주요 클래스를 제공합니다. TavilySearchResults와 TavilyAnswer입니다. Tavily도 사용하기 위해선 API KEY가 필요합니다. 다음 URL에서 API KEY를 발급받고, 환경변수 세팅을 해줍니다.
import os
os.environ["TAVILY_API_KEY"] = '자신의 Tavily API KEY 값'
TavilySearchResults
이 클래스는 검색 결과로 나온 웹 페이지들의 리스트를 그대로 가져오는 도구입니다.
- 주요 용도: 검색된 여러 문서를 컨텍스트로 프롬프트에 넣어 LLM이 직접 분석하게 할 때 사용합니다.
- 작동 방식: 검색 엔진이 찾은 여러 소스를 가공하지 않고(혹은 최소한으로 정제 하여) 덩어리째 던져줍니다.
- 반환값: url, content, title, score 등이 담긴 딕셔너리 리스트를 반환합니다.
- 주요 매개변수:
- max_results (int): 반환할 최대 검색 결과 수 (기본값: 5)
- search_depth (str): 검색 깊이 (“basic” 또는 “advanced”)
- include_domains (List[str]): 검색 결과에 포함할 도메인 목록
- exclude_domains (List[str]): 검색 결과에서 제외할 도메인 목록
- include_answer (bool): 원본 쿼리에 대한 짧은 답변 포함 여부
- include_raw_content (bool): 각 사이트의 정제된 HTML 콘텐츠 포함 여부
- include_images (bool): 쿼리 관련 이미지 목록 포함 여부
그렇다면 간단한 예제로 실사용은 어떻게 하는지 알아보도록 하겠습니다.
from langchain_community.tools.tavily_search import TavilySearchResults
# 도구 생성
tool = TavilySearchResults(
max_results = 6,
include_answer = True,
include_raw_content = True,
# include_images = True,
# search_depth = "advanced", # or "basic"
include_domain = ["github.io", "wikidocs.net"],
# exclude_domains = []
)
# 도구 실행
tool.invoke({"query": "LangChain Tools에 대해서 알려주세요."})
결과를 출력해보면 아주 많은 문서들이 출력되는 것을 확인할 수 있습니다.
Output:
[{'title': '01. 도구(Tools) - <랭체인LangChain 노트>',
'url': 'https://wikidocs.net/262582',
'content': '```\nfrom langchain_community.tools.tavily_search import TavilySearchResults # 도구 생성 tool = TavilySearchResults( max_results=6, include_answer=True, include_raw_content=True, # include_images=True, # search_depth="advanced", # or "basic" include_domains=["github.io", "wikidocs.net"], # exclude_domains = [] ) \n```\n\n```\n# 도구 실행 tool.invoke({"query": "LangChain Tools 에 대해서 알려주세요"}) \n``` [...] from langchain_teddynote.tools.tavily import TavilySearch # 기본 예제 tavily_tool = TavilySearch() # include_domains 사용 예제 # 특정 도메인만 포함하여 검색 tavily_tool_with_domains = TavilySearch(include_domains=["github.io", "naver.com"]) # exclude_domains 사용 예제 # 특정 도메인을 제외하고 검색 tavily_tool_exclude = TavilySearch(exclude_domains=["ads.com", "spam.com"]) # 다양한 파라미터를 사용한 검색 예제 result1 = tavily_tool.search( query="유튜버 테디노트에 대해서 알려줘", # 검색 쿼리 search_depth="advanced", # 고급 검색 수준 topic="general", # 일반 주제 days=7, # 최근 7일 내 결과 max_results=10, # 최대 10개 결과 include_answer=True, # 답변 포함 include_raw_content=True, # 원본 콘텐츠 포함 include_images=True, # 이미지 포함 format_output=True, # 결과 포맷팅 ) # 뉴스 검색 예제 result2 = tavily_tool.search( query="최신 AI 기술 동향", # 검색 쿼리 search_depth="basic", # 기본 검색 수준 topic="news", # 뉴스 주제 days=3, # [...] LangChain 에서 제공하는 빌트인 도구 외에도 사용자가 직접 도구를 정의하여 사용할 수 있습니다.\n\n이를 위해서는 `langchain.tools` 모듈에서 제공하는 `tool` 데코레이터를 사용하여 함수를 도구로 변환합니다.\n\n### @tool 데코레이터\n\n이 데코레이터는 함수를 도구로 변환하는 기능을 제공합니다. 다양한 옵션을 통해 도구의 동작을 커스터마이즈할 수 있습니다.\n\n사용 방법\n\n1. 함수 위에 `@tool` 데코레이터 적용\n2. 필요에 따라 데코레이터 매개변수 설정\n\n이 데코레이터를 사용하면 일반 Python 함수를 강력한 도구로 쉽게 변환할 수 있으며, 자동화된 문서화와 유연한 인터페이스 생성이 가능합니다.\n\n```\nfrom langchain.tools import tool # 데코레이터를 사용하여 함수를 도구로 변환합니다. @tool def add_numbers(a: int, b: int) -> int: """Add two numbers""" return a + b @tool def multiply_numbers(a: int, b: int) -> int: """Multiply two numbers""" return a b \n```\n\n```\n# 도구 실행 add_numbers.invoke({"a": 3, "b": 4}) \n```\n\n```\n7\n```\n\n```\n# 도구 실행 multiply_numbers.invoke({"a": 3, "b": 4}) \n```\n\n```\n12\n```\n\n### 구글 뉴스기사 검색 도구',
'score': 0.999966,
...생략...
reference](https://guide.ncloud-docs.com/docs/clovastudio-dev-langchain) \n\n---\n\n[Edit this page on GitHub](https://github.com/langchain-ai/docs/edit/main/src/oss/python/integrations/chat/naver.mdx) or [file an issue](https://github.com/langchain-ai/docs/issues/new/choose).\n\n[Connect these docs](/use-these-docs) to Claude, VSCode, and more via MCP for real-time answers.\n\nWas this page helpful?'}]
TavilyAnswer
이 클래스는 Tavily 엔진이 내부적으로 검색 결과를 한 번 더 처리하여 질문에 대한 직접적인 답변을 생성해 주는 도구입니다.
- 주요 용도:
- 빠른 질의응답: 복잡한 체인 구성 없이 “검색 + 요약” 결과를 즉시 얻고 싶을 때 사용합니다.
- Perplexity 스타일의 검색: 사용자에게 소스 리스트보다는 깔끔하게 정리된 결론을 먼저 보여주고 싶을 때 유리합니다.
- 작동 방식: Tavily 서버 측에서 검색된 내용들을 바탕으로 자체적인 LLM을 사용하여 답변을 요약/추출한 뒤 전달합니다.
- 반환값: 검색 결과 리스트가 아닌, 질문에 대한 하나의 완성된 문자열(답변)을 반환합니다.
- 주요 매개변수: TavilySearchResults와 동일합니다.
TavilyAnswer도 예제 코드로 한 번 알아보도록 하겠습니다. 코드는 TavilySearchResults와 동일합니다.
from langchain_community.tools.tavily_search import TavilyAnswer
# 도구 생성
tool = TavilyAnswer(
max_results = 6,
include_answer = True,
include_raw_content = True,
# include_images = True,
# search_depth = "advanced", # or "basic"
include_domain = ["github.io", "wikidocs.net"],
# exclude_domains = []
)
# 도구 실행
tool.invoke({"query": "LangChain Tools에 대해서 알려주세요."})
출력 결과를 보면 TavilySearchResults와는 다르게 동일한 쿼리지만 몇 문장으로 정리해서 알려주는 것을 알 수 있습니다.
Output:
/tmp/ipython-input-3844436811.py:4: LangChainDeprecationWarning: The class `TavilyAnswer` was deprecated in LangChain 0.3.25 and will be removed in 1.0. An updated version of the class exists in the `langchain-tavily package and should be used instead. To use it run `pip install -U `langchain-tavily` and import as `from `langchain_tavily import TavilySearch``.
tool = TavilyAnswer(
LangChain Tools are components that enhance language model applications by integrating external data sources and custom functionalities. They enable complex search and retrieval processes. LangChain supports real-time data integration for dynamic, context-aware responses.
2.1.3 Image 생성 도구 (DALL-E)
LangChain에서 이미지 생성 도구로 활용되는 DALL-E는 OpenAI에서 개발한 Text-To-Image 생성 모델입니다. DALL-E는 자연어로 표현된 프롬프트를 입력받아 이를 해석하고, 그에 부합하는 고해상도 이미지를 생성하는 멀티모달(Multimodal) AI 모델입니다.
DallEAPIWrapper 클래스를 사용하면 DALL-E API를 쉽게 통합하여 텍스트 기반 이미지 생성 기능을 구현할 수 있습니다. 다양한 설정 옵션을 통해 유연하고 강력한 이미지 생성 도구로 활용할 수 있습니다.
DallEAPIWrapper 클래스의 주요 속성
- model: 사용할 DALL-E 모델 이름 (기본값: “dall-e-2”, “dall-e-3”)
- n: 생성할 이미지 수 (기본값 1)
- size: 생성할 이미지 크기
- style: 생성될 이미지의 스타일 (기본값: “natural”, “vivid”)
- quality: 생성될 이미지의 품질 (기본값: “standard”, “hd”)
- max_retries: 생성 시 최대 재시도 횟수
그럼 예제 코드로 DallEAPIWrapper 클래스에 대해서 구체적으로 알아보도록 하겠습니다. 아래 코드는 gpt-4o-mini로부터 query에 맞는 이미지 생성 프롬프트를 받아오고, gpt-4o-mini로 생성한 프롬프트로 DALL-E에서 이미지를 생성하는 예제입니다.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.9, max_tokens=1000)
# DALL-E 이미지 생성을 위한 프롬프트 템플릿 정의
prompt = PromptTemplate.from_template(
"Generate a detailed IMAGE GENERATION prompt for DALL-E based on the following description. "
"Return only the prompt, no intro, no explanation, no chatty, no markdown, no code block, no nothing. Just the prompt"
"Output should be less than 1000 characters. Write in English only."
"Image Description: \n{image_desc}",
)
# 프롬프트, LLM, 출력 파서를 연결하는 체인 생성
chain = prompt | llm | StrOutputParser()
# 체인 실행
image_prompt = chain.invoke(
{"image_desc": "스마트폰을 바라보는 사람을 풍자한 neo-classicism painting"}
)
# 이미지 프롬프트 출력
print(image_prompt)
생성된 프롬프트는 다음과 같습니다.
Output:
Create a neo-classical painting that satirizes a person gazing at a smartphone. The scene should juxtapose classical elements, such as marble columns and draped robes, with the modernity of the smartphone. Depict a male figure in a traditional toga, looking intently at the device, with a bemused expression. Surround him with several figures in classical attire, some engaged in conversation and others reading scrolls, highlighting the contrast between ancient knowledge and modern distraction. The background should feature lush landscapes typical of neo-classical art, while the smartphone's glowing screen casts an unnatural light. Use a palette of soft earth tones and rich golds to evoke the grandeur of the neo-classical style, while infusing a humorous commentary on contemporary society's obsession with technology.
# DALL-E API 래퍼 가져오기
from langchain_community.utilities.dalle_image_generator import DallEAPIWrapper
from IPython.display import Image
# DALL-E API 래퍼 초기화
# model: 사용할 DALL-E 모델 버전
# size: 생성할 이미지 크기
# quality: 이미지 품질
# n: 생성할 이미지 수
dalle = DallEAPIWrapper(model="dall-e-3", size="1024x1024", quality="standard", n=1)
# 질문
query = "스마트폰을 바라보는 사람들을 풍자한 neo-classicism painting"
# 이미지 생성 및 URL 받기
# chain.invoke()를 사용하여 이미지 설명을 DALL-E 프롬프트로 변환
# dalle.run()을 사용하여 실제 이미지 생성
image_url = dalle.run(chain.invoke({"image_desc": query}))
# 생성된 이미지를 표시합니다.
Image(url=image_url, width=500)
생성된 이미지를 보면 고대 그리스 시대 사람들이 그리스의 고대 건축물 안에서 모두 스마트폰만을 보고 있는 이미지가 생성되었습니다.

2.1.4 사용자 정의 도구(Custom Tool)
LangChain에서 제공하는 빌트인 도구 외에도 사용자가 직접 도구를 정의하여 사용할 수 있습니다. 이를 위해서는 langchain.tools 모듈에서 제공하는 tool 데코레이터를 사용하여 함수를 도구로 변환합니다.
tool 데코레이터
이 데코레이터는 함수를 도구로 변환하는 기능을 제공합니다. 다양한 옵션을 통해 도구의 동작을 커스터마이즈할 수 있습니다. 사용 방법은 함수 위에 @tool 데코레이터를 적용하고, 필요에 따라 데코레이터 매개변수를 설정합니다.
이 데코레이터를 사용하면 일반 Python 함수를 강력한 도구로 쉽게 변환할 수 있으며, 자동화된 문서화와 유연한 인터페이스 생성이 가능합니다.
아래는 데코레이터를 사용한 예시입니다.
from langchain.tools import tool
# 데코레이터를 사용하여 함수를 도구로 변환합니다.
@tool
def add_numbers(a: int, b: int) -> int:
"""Add two numbers"""
return a+b
@tool
def multiply_numbers(a:int, b: int) -> int:
"""Multiply two numbers"""
return a*b
# 도구 실행
print(add_numbers.invoke({"a":3, "b":4}))
print(multiply_numbers.invoke({"a":3, "b":4}))
3. 도구 바인딩(Binding Tools)
도구 바인딩이란 Python 함수나 LangChain의 Tool 객체를 LLM이 이해할 수 있는 JSON 스키마 형태로 변환하여, 모델의 추론 엔진에 주입하는 행위입니다. 주로 LangChain의 .bind_tools() 메서드를 통해 수행됩니다. 이 과정을 거치면 일반적인 ChatModel 객체는 도구 호출 기능이 활성화된 Runnable 객체로 업그레이드됩니다.
LangChain에서 도구 바인딩은 LLM이 외부 도구(함수, API 등)를 인식하고 사용할 수 있도록 모델의 ‘출력 형식’을 특정 도구의 스키마에 고정시키는 과정을 말합니다. 단순히 도구를 리스트로 전달하는 것을 넘어, 모델이 “이 도구들을 사용할 수 있다”는 것을 인지하고 그에 맞는 매개변수를 생성할 수 있게 만드는 핵심 단계입니다.
도구 바인딩의 작동 원리는 다음과 같습니다.
- 도구 정의: Python 함수 정의와 함께
docstring을 통해 도구의 역할과 매개변수를 설명합니다. - 스키마 추출: LangChain이 함수의 이름, 설명, 인자 타입을 분석하여 JSON 스키마를 생성합니다.
- 모델 결합:
.bind_tools([tools])명령을 통해 모델의 시스템 프롬프트 혹은 API 파라미터 영역에 해당하는 스키마를 전달합니다. - 도구 호출 생성: 사용자가 질문을 던지면, 모델은 바인딩된 스키마를 참고하여
tool_calls라는 특수 필드에 실행 정보를 담아 반환합니다.
3.1 LLM에 도구 바인딩(Binding Tools)
LLM 모델이 도구(tool)를 호출할 수 있으려면 chat 요청을 할 때 모델에 도구 스키마(tool schema)를 전달해야 합니다.
도구 호출(tool calling) 기능을 지원하는 Langchain Chat Model은 .bind_tools() 메서드를 구현하여 LangChain 도구 객체, Pydantic 클래스 또는 JSON 스키마 목록을 수신하고 공급자별 예상 형식으로 채팅 모델에 바인딩(binding) 합니다.
바인딩된 Chat Model의 후속 호출은 모델 API에 대한 모든 호출에 도구 스키마를 포함합니다.
실습 코드 실행을 위해서 아래 라이브러리들을 설치해 주시기 바랍니다.
!pip install -U langchain langchain-core langchain-openai langchain-classic
3.1.1 LLM에 바인딩할 Tool 정의
실험을 위한 도구(tool)을 정의합니다.
get_word_length: 단어의 길이를 반환하는 함수add_function: 두 숫자를 더하는 함수naver_news_crawl: 네이버 뉴스 기사를 크롤링하여 본문 내용을 반환하는 함수
import re
import requests
from bs4 import BeautifulSoup
from langchain.tools import tool
# 도구를 정의합니다.
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word"""
return len(word)
@tool
def add_function(a: float, b: float) -> float:
"""Adds two numbers together"""
return a+b
@tool
def naver_news_crawl(news_url: str) -> str:
"""Crawls a 네이버 (naver.com) news article and returns the body content."""
# HTTP GET 요청 보내기
response = requests.get(news_url)
# 요청이 성공했는지 확인
if response.status_code == 200:
# BeautifulSoup을 사용하여 HTML 파싱
soup = BeautifulSoup(response.text, "html.parser")
# 원하는 정보 추출
title = soup.find("h2", id="title_area").get_text()
content = soup.find("div", id="contents").get_text()
cleaned_title = re.sub(r"\n{2,}", "\n", title)
cleaned_content = re.sub(r"\n{2,}", "\n", content)
else:
print(f"HTTP 요청 실패. 응답 코드: {response.status_code}")
return f"{cleaned_title}\n{cleaned_content}"
tools = [get_word_length, add_function, naver_news_crawl]
3.1.2 bind_tools()로 LLM에 도구 바인딩
LLM 모델에 bind_tools()를 사용하여 도구를 바인딩합니다.
from langchain_openai import ChatOpenAI
# 모델 생성
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 도구 바인딩
llm_with_tools = llm.bind_tools(tools)
실행결과를 한 번 확인해 보도록 하겠습니다. 결과는 tool_calls에 저장됩니다. 따라서, .tool_calls를 확인하여 도구 호출 결과를 확인할 수 있습니다.
# 실행 결과
llm_with_tools.invoke("What is the length of the word 'teddynote'?").tool_calls
name은 도구의 이름을 의미합니다. args는 도구에 전달되는 인자를 의미합니다.
Output:
[{'name': 'get_word_length',
'args': {'word': 'teddynote'},
'id': 'call_9vUHLgGbVdLtvnK6yF6p1x6P',
'type': 'tool_call'}]
다음으로는 llm_with_tools와 JsonOutputToolsParser를 연결하여 tool_calls를 parsing하여 결과를 확인합니다.
from langchain_core.output_parsers.openai_tools import JsonOutputToolsParser
# 도구 바인딩 + 도구 파서
chain = llm_with_tools | JsonOutputToolsParser(tools=tools)
# 실행 결과
tool_call_results = chain.invoke("What is the length of the word 'teddynote'?")
type은 도구의 이름입니다. args는 도구에 전달되는 인자입니다.
Output:
[{'args': {'word': 'teddynote'}, 'type': 'get_word_length'}]
=========
get_word_length
{'word': 'teddynote'}
도구 이름과 일치하는 도구를 찾아 실행합니다.
tool_call_results[0]["type"], tools[0].name
Output:
('get_word_length', 'get_word_length')
execute_tool_calls 함수는 도구를 찾아 args를 전달하여 도구를 실행합니다.
def execute_tool_calls(tool_call_results):
"""
도구 호출 결과를 실행하는 함수
:param tool_call_results: 도구 호출 결과 리스트
:param tools: 사용 가능한 도구 리스트
"""
# 도구 호출 결과 리스트를 순회합니다.
for tool_call_result in tool_call_results:
# 도구의 이름과 인자를 추출합니다.
tool_name = tool_call_result["type"]
tool_args = tool_call_result["args"]
# 도구 이름과 일치하는 도구를 찾아 실행합니다.
# next() 함수를 사용하여 일치하는 첫 번째 도구를 찾습니다.
matching_tool = next((tool for tool in tools if tool.name == tool_name), None)
if matching_tool:
# 일치하는 도구를 찾았다면 해당 도구를 실행합니다.
result = matching_tool.invoke(tool_args)
# 실행 결과를 출력합니다.
print(f"[실행도구] {tool_name}\n[실행결과] {result}")
else:
# 일치하는 도구를 찾지 못했다면 경고 메시지를 출력합니다.
print(f"경고: {tool_name}에 해당하는 도구를 찾을 수 없습니다.")
# 도구 호출 실행
# 이전에 얻은 tool_call_results를 인자로 전달하여 함수를 실행합니다.
execute_tool_calls(tool_call_results)
Output:
[실행도구] get_word_length
[실행결과] 9
3.1.3 bind_tools + Parser + Execution
이번에는 일련의 과정을 한 번에 실행합니다.
llm_with_tools: 도구를 바인딩한 모델JsonOutputToolsParser: 도구 호출 결과를 파싱하는 파서execute_tool_calls: 도구 호출 결과를 실행하는 함수
흐름을 정리해보자면
- 모델에 도구를 바인딩
- 도구 호출 결과를 파싱
- 도구 호출 결과를 실행
from langchain_core.output_parsers.openai_tools import JsonOutputToolsParser
# bind_tools + Parser + Execution
chain = llm_with_tools | JsonOutputToolsParser(tools=tools) | execute_tool_calls
# 실행 결과
chain.invoke("What is the length of the word 'teddynote'?")
Output:
[실행도구] get_word_length
[실행결과] 9
# 실행 결과
chain.invoke("114.5 + 121.2")
Output:
[실행도구] add_function
[실행결과] 235.7
# 실행 결과
chain.invoke(
"뉴스 기사 내용을 크롤링해줘: https://n.news.naver.com/mnews/hotissue/article/092/0002347672?type=series&cid=2000065"
)
Output:
[실행도구] naver_news_crawl
[실행결과] [미장브리핑] 9월 미국 CPI 주목…3분기 S&P500 실적 발표
▲10일(현지시간) 미국 9월 소비자물가지수(CPI) 발표 예정. 고용 지표가 양호하게 나온 가운데 물가 지표 주목. 9월 미국 비농업고용 25만4천명 증가해 시장 예상치 14만명 크게 상회. 이는 6개월 래 최대 규모로 지난 12개월 평균값 20만3천명 증가한 것보다도 높은 수치. 9월 실업률은 4.1%로 2개월 연속 하락했으며, 평균 시간당 임금은 전년 동월 대비 4% 증가해 5월 이후 최고 수준.▲시장에서 9월 헤드라인 CPI는 8월 전년 동월 대비 2.6% 로 5개월 연속 둔화하고 9월에는 2.3% 증가로 추가 하락 예상. 전월 대비도 8월 0.2% 둔화 예상. 근원 CPI는 지난 8월 3.2%와 비슷한 수준 관측.▲11일에는 미국 9월 제조업물가지수(PPI) 발표. 지난 6월 부터 8월까지 반등 추세 꺾여. 8월은 1.7% 증가.
(사진=이미지투데이)▲11월 미국 연방준비제도(연준) 공개시장위원회(FOMC) 에서 0.50%p 인하 기대가 크케 후퇴한 가운데, 9일에는 FOMC 의사록 공개. 지난 9월 회의에서 빅컷(0.50%p) 단행한 배경과 인플레이션 전망에 대한 논의를 알 수 있을 것으로 보여.▲미국 스탠다드앤푸어스(S&P) 500 기업의 3분기 실적 발표 시작. 평균 이익증가율 추정치는 전년 동기 대비 4.6%로 5개분기 연속 플러스이나 증가폭은 둔화 예상. 11일부터 JP모건체이스, 웰스파고 등 대형은행들의 실적 발표.▲FTSE 러셀은 8일 정례 시장분류 결과를 발표. 한국은 2022년 관찰대상국 지정 이후 금번 시장접근성 등급(L1) 상향으로 세계국채지수(WGBI) 에 편입될 지 관심. 주식의 경우 지난 2009년부터 선진국 지수에 편입돼 있는 한국 증시에 대해 공매도 제한 등을 이유로 관찰 대상국으로 지정할지 관심. 지정되더라도 검토 기간이 있어 즉각 제외되지는 않음.
손희연 기자(kunst@zdnet.co.kr)
Copyright ⓒ ZDNet Korea. All rights reserved. 무단 전재 및 재배포 금지.
이 기사는 언론사에서 IT 섹션으로 분류했습니다.
기사 섹션 분류 안내
기사의 섹션 정보는 해당 언론사의 분류를 따르고 있습니다. 언론사는 개별 기사를 2개 이상 섹션으로 중복 분류할 수 있습니다.
닫기
기자 프로필
손희연 기자
손희연 기자
지디넷코리아
구독
구독중
국내 주식 시장 '물 들어올때 노젓자'…ETF 상품 다양해진다
차기 美연준의장 지명…비트코인 9개월 만에 7만달러대로
구독
지디넷코리아 구독하고 메인에서 바로 만나보세요!구독하고 메인에서 만나보세요!
구독중
지디넷코리아 구독하고 메인에서 바로 만나보세요!구독하고 메인에서 만나보세요!
언론사홈
지디넷코리아
주요뉴스해당 언론사에서 선정하며 언론사(아웃링크)로 이동합니다.
KB금융, 광주 1인 여성 자영업자에 월 100만원 지원
아파트만? 이제 빌라 주담대도 갈아타자
카카오뱅크, 6일 새벽 금융거래 일시 중단
우리은행 올해만 세 번째 금융사고…"허위서류로 55억 대출"
지디넷코리아 '홈페이지'
QR 코드를 클릭하면 크게 볼 수 있어요.
QR을 촬영해보세요.
지디넷코리아 '홈페이지'
닫기
네이버 채널 구독하기
지디넷코리아 언론사가 직접 선정한 이슈
이슈
반도체 전쟁
HBM 공급 프로세스 달라졌다…삼성·SK 모두 리스크 양산
이슈
트럼프 2.0시대
트럼프 지명 차기 연준 의장, 과거 발언 보니…가상자산 중도파?
이슈
AI 핫트렌드
"우린 GPU에만 의존하지 않아"…AI 가속기 선택 SW로 효율·전력·비용 잡아
이슈
고려아연 경영권 분쟁
KZ정밀 "진실 은폐" vs 영풍 "법적 권리"…새해도 공방 지속
이전
다음
이 기사를 추천합니다
기사 추천은 24시간 내 50회까지 참여할 수 있습니다.
닫기
쏠쏠정보
0
흥미진진
0
공감백배
0
분석탁월
0
후속강추
0
기자 구독 후 기사보기
구독 없이 계속 보기
3.1.4 bind_tools -> Agent & AgentExecutor로 대체
bind_tools()는 모델에 사용할 수 있는 스키마(도구)를 제공합니다. AgentExecutor는 실제로 LLM 호출, 올바른 도구로 라우팅, 실행, 모델 재호출 등을 위한 실행 루프를 생성합니다.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
# Agent프롬프트 생성
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are very powerful assistant, but don't know current events",
),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
# 모델 생성
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
from langchain_classic.agents import create_tool_calling_agent
from langchain_classic.agents import AgentExecutor
# 이전에 정의한 도구 사용
tools = [get_word_length, add_function, naver_news_crawl]
# Agent 생성
agent = create_tool_calling_agent(llm, tools, prompt)
# AgentExecutor 생성
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True,
)
# Agent 실행
result = agent_executor.invoke({"input": "How many letters in the word `teddynote`?"})
# 결과 확인
print(result["output"])
Output:
> Entering new AgentExecutor chain...
Invoking: `get_word_length` with `{'word': 'teddynote'}`
9The word 'teddynote' has 9 letters.
> Finished chain.
The word 'teddynote' has 9 letters.
# Agent 실행
result = agent_executor.invoke({"input": "114.5 + 121.2 의 계산 결과는?"})
# 결과 확인
print(result["output"])
Output:
> Entering new AgentExecutor chain...
Invoking: `add_function` with `{'a': 114.5, 'b': 121.2}`
235.7114.5 + 121.2의 계산 결과는 235.7입니다.
> Finished chain.
114.5 + 121.2의 계산 결과는 235.7입니다.
result = agent_executor.invoke(
{
"input": "뉴스 기사를 요약해 줘: https://n.news.naver.com/mnews/hotissue/article/092/0002347672?type=series&cid=2000065"
}
)
print(result["output"])
Output:
> Entering new AgentExecutor chain...
Invoking: `naver_news_crawl` with `{'news_url': 'https://n.news.naver.com/mnews/hotissue/article/092/0002347672?type=series&cid=2000065'}`
[미장브리핑] 9월 미국 CPI 주목…3분기 S&P500 실적 발표
▲10일(현지시간) 미국 9월 소비자물가지수(CPI) 발표 예정. 고용 지표가 양호하게 나온 가운데 물가 지표 주목. 9월 미국 비농업고용 25만4천명 증가해 시장 예상치 14만명 크게 상회. 이는 6개월 래 최대 규모로 지난 12개월 평균값 20만3천명 증가한 것보다도 높은 수치. 9월 실업률은 4.1%로 2개월 연속 하락했으며, 평균 시간당 임금은 전년 동월 대비 4% 증가해 5월 이후 최고 수준.▲시장에서 9월 헤드라인 CPI는 8월 전년 동월 대비 2.6% 로 5개월 연속 둔화하고 9월에는 2.3% 증가로 추가 하락 예상. 전월 대비도 8월 0.2% 둔화 예상. 근원 CPI는 지난 8월 3.2%와 비슷한 수준 관측.▲11일에는 미국 9월 제조업물가지수(PPI) 발표. 지난 6월 부터 8월까지 반등 추세 꺾여. 8월은 1.7% 증가.
(사진=이미지투데이)▲11월 미국 연방준비제도(연준) 공개시장위원회(FOMC) 에서 0.50%p 인하 기대가 크케 후퇴한 가운데, 9일에는 FOMC 의사록 공개. 지난 9월 회의에서 빅컷(0.50%p) 단행한 배경과 인플레이션 전망에 대한 논의를 알 수 있을 것으로 보여.▲미국 스탠다드앤푸어스(S&P) 500 기업의 3분기 실적 발표 시작. 평균 이익증가율 추정치는 전년 동기 대비 4.6%로 5개분기 연속 플러스이나 증가폭은 둔화 예상. 11일부터 JP모건체이스, 웰스파고 등 대형은행들의 실적 발표.▲FTSE 러셀은 8일 정례 시장분류 결과를 발표. 한국은 2022년 관찰대상국 지정 이후 금번 시장접근성 등급(L1) 상향으로 세계국채지수(WGBI) 에 편입될 지 관심. 주식의 경우 지난 2009년부터 선진국 지수에 편입돼 있는 한국 증시에 대해 공매도 제한 등을 이유로 관찰 대상국으로 지정할지 관심. 지정되더라도 검토 기간이 있어 즉각 제외되지는 않음.
손희연 기자(kunst@zdnet.co.kr)
Copyright ⓒ ZDNet Korea. All rights reserved. 무단 전재 및 재배포 금지.
이 기사는 언론사에서 IT 섹션으로 분류했습니다.
기사 섹션 분류 안내
기사의 섹션 정보는 해당 언론사의 분류를 따르고 있습니다. 언론사는 개별 기사를 2개 이상 섹션으로 중복 분류할 수 있습니다.
닫기
기자 프로필
손희연 기자
손희연 기자
지디넷코리아
구독
구독중
국내 주식 시장 '물 들어올때 노젓자'…ETF 상품 다양해진다
차기 美연준의장 지명…비트코인 9개월 만에 7만달러대로
구독
지디넷코리아 구독하고 메인에서 바로 만나보세요!구독하고 메인에서 만나보세요!
구독중
지디넷코리아 구독하고 메인에서 바로 만나보세요!구독하고 메인에서 만나보세요!
언론사홈
지디넷코리아
주요뉴스해당 언론사에서 선정하며 언론사(아웃링크)로 이동합니다.
KB금융, 광주 1인 여성 자영업자에 월 100만원 지원
아파트만? 이제 빌라 주담대도 갈아타자
카카오뱅크, 6일 새벽 금융거래 일시 중단
우리은행 올해만 세 번째 금융사고…"허위서류로 55억 대출"
지디넷코리아 '홈페이지'
QR 코드를 클릭하면 크게 볼 수 있어요.
QR을 촬영해보세요.
지디넷코리아 '홈페이지'
닫기
네이버 채널 구독하기
지디넷코리아 언론사가 직접 선정한 이슈
이슈
반도체 전쟁
HBM 공급 프로세스 달라졌다…삼성·SK 모두 리스크 양산
이슈
트럼프 2.0시대
트럼프 지명 차기 연준 의장, 과거 발언 보니…가상자산 중도파?
이슈
AI 핫트렌드
"우린 GPU에만 의존하지 않아"…AI 가속기 선택 SW로 효율·전력·비용 잡아
이슈
고려아연 경영권 분쟁
KZ정밀 "진실 은폐" vs 영풍 "법적 권리"…새해도 공방 지속
이전
다음
이 기사를 추천합니다
기사 추천은 24시간 내 50회까지 참여할 수 있습니다.
닫기
쏠쏠정보
0
흥미진진
0
공감백배
0
분석탁월
0
후속강추
0
기자 구독 후 기사보기
구독 없이 계속 보기
기사 요약:
9월 10일(현지시간) 미국의 소비자물가지수(CPI) 발표가 예정되어 있으며, 고용 지표가 양호하게 나온 가운데 물가 지표에 대한 주목이 필요하다. 9월 비농업 고용은 25만4천명 증가하여 시장 예상치를 크게 상회했으며, 실업률은 4.1%로 하락했다. 9월 헤드라인 CPI는 8월 대비 2.3% 증가할 것으로 예상되며, 근원 CPI는 3.2% 수준을 유지할 것으로 보인다.
11일에는 제조업물가지수(PPI) 발표가 예정되어 있으며, 미국 연방준비제도(FOMC)에서는 금리 인하 기대가 줄어들고 있다. 또한, S&P 500 기업의 3분기 실적 발표가 시작되며, 평균 이익 증가율은 4.6%로 예상된다. 한국은 FTSE 러셀의 시장 접근성 등급이 상향 조정될 가능성이 있어 주목받고 있다.
> Finished chain.
기사 요약:
9월 10일(현지시간) 미국의 소비자물가지수(CPI) 발표가 예정되어 있으며, 고용 지표가 양호하게 나온 가운데 물가 지표에 대한 주목이 필요하다. 9월 비농업 고용은 25만4천명 증가하여 시장 예상치를 크게 상회했으며, 실업률은 4.1%로 하락했다. 9월 헤드라인 CPI는 8월 대비 2.3% 증가할 것으로 예상되며, 근원 CPI는 3.2% 수준을 유지할 것으로 보인다.
11일에는 제조업물가지수(PPI) 발표가 예정되어 있으며, 미국 연방준비제도(FOMC)에서는 금리 인하 기대가 줄어들고 있다. 또한, S&P 500 기업의 3분기 실적 발표가 시작되며, 평균 이익 증가율은 4.6%로 예상된다. 한국은 FTSE 러셀의 시장 접근성 등급이 상향 조정될 가능성이 있어 주목받고 있다.
4. 에이전트(Agent)
에이전트(Agent)는 LLM을 추론 엔진(Reasoning Engine)으로 활용하여 스스로 계획을 세우고 도구를 선택하며, 결과가 만족스럽지 않을 경우 과정을 반복하는 자율적인 시스템입니다. 쉽게 비유하자면, 일반 RAG는 정해진 노선만 달리는 열차이고, RAG 에이전트는 목적지에 가기 위해 실시간 교통 상황을 보며 경로를 재탐색하는 내비게이션과 같습니다.
엔지니어링 관점에서 에이전트는 다음 네 가지 요소의 결합체로 볼 수 있습니다.
-
추론 및 계획(Reasoning & Planning): LLM이 사용자의 의도를 분석하고, 목표를 달성하기 위해 질문을 쪼개거나 실행 순서를 결정합니다.
-
도구(Tools): 벡터 데이터베이스 검색, 웹 브라우징(Tavily 등), 계산기, API 호출 등 에이전트가 외부 세계와 상호작용하는 ‘손’의 역할을 합니다.
-
기억(Memory): 이전 대화의 맥락이나 실행했던 단계의 결과를 저장하여 다음 판단에 반영합니다. (RunnableWithMessageHistory 등이 여기서 활용됩니다.)
-
행동(Action): 결정된 계획에 따라 실제로 도구를 실행하고 그 결과를 받아 다시 분석합니다.
4.1 도구 호출 에이전트(Tool Calling Agent)
도구 호출을 사용하면 모델이 하나 이상의 도구(tool)가 호출되어야 하는 시기를 감지하고 해당 도구에 전달해야 하는 입력으로 전달할 수 있습니다.
API 호출에서 도구를 설명하고 모델이 이러한 도구를 호출하기 위한 인수가 포함된 JSON과 같은 구조화된 객체를 출력하도록 지능적으로 선택할 수 있습니다.
도구 API의 목표는 일반 텍스트 완성이나 채팅 API를 사용하여 수행할 수 있는 것보다 더 안정적으로 유효하고 유용한 도구 호출(tool call)을 반환하는 것입니다.
이러한 구조화된 출력을 도구 호출 채팅 모델에 여러 도구를 바인딩하고 모델이 호출할 도구를 선택할 수 있다는 사실과 결합하여 쿼리가 해결될 때까지 반복적으로 도구를 호출하고 결과를 수신하는 에이전트를 만들 수 있습니다. 이것은 OpenAI의 특정 도구 호출 스타일에 맞게 설계된 OpenAI 도구 에이전트의 보다 일반화된 버전입니다.
이 에이전트는 LangChain의 ToolCall 인터페이스를 사용하여 OpenAI 외에도 Anthropic, Google Gemini, Mistral과 같은 더 광범위한 공급자 구현을 지원합니다.
그럼 실습 코드 실행에 필요한 라이브러리부터 설치해 줍니다.
!pip install -U langchain langchain-core langchain-experimental langchain-classic langchain-openai langchain-teddynote langchain-community
from langchain.tools import tool
from typing import List, Dict, Annotated
from langchain_teddynote.tools import GoogleNews
from langchain_experimental.utilities import PythonREPL
# 도구 생성
@tool
def search_news(query: str) -> List[Dict[str, str]]:
"""Search Google News by input keyword"""
news_tool = GoogleNews()
return news_tool.search_by_keyword(query, k=5)
@tool
def python_repl_tool(
code: Annotated[str, "The python code to execute to generate your chart."],):
"""Use this to execute python code. If you want to see the output of a value, you
should print it out with `print(...)`. This is visible to the user.
"""
result = ""
try:
result = PythonREPL().run(code)
except BaseException as e:
print(f"Failed to execute. Error: {repr(e)}")
finally:
return result
print(f"도구 이름: {search_news.name}")
print(f"도구 설명: {search_news.description}")
print(f"도구 이름: {python_repl_tool.name}")
print(f"도구 설명: {python_repl_tool.description}")
4.1.1 Agent 프롬프트 생성
chat_history: 이전 대화 내용을 저장하는 변수(멀티턴을 지원하지 않는다면, 생략 가능합니다.)agent_scratchpad: 에이전트가 임시로 저장하는 변수input: 사용자의 입력
from langchain_core.prompts import ChatPromptTemplate
# 프롬프트 생성
# 프롬프트는 에이전트에게 모델이 수행할 작업을 설명하는 텍스트를 제공합니다. (도구의 이름과 역할을 입력)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. "
"Make sure to use the `search_news` tool for searching keyword related news.",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
4.1.2 Agent 생성
create_tool_calling_agent를 이용해 Agent를 생성해 줍니다.
from langchain_openai import ChatOpenAI
from langchain_classic.agents import create_tool_calling_agent
# LLM 정의
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Agent 생성
agent = create_tool_calling_agent(llm, tools, prompt)
4.1.3 AgentExecutor
AgentExecutor는 도구를 사용하는 에이전트를 실행하는 클래스입니다.
주요 속성은 다음과 같습니다.
agent: 실행 루프와 각 단계에서 계획을 생성하고 행동을 결정하는 에이전트tools: 에이전트가 사용할 수 있는 유효한 도구 목록return_intermediate_steps: 최종 출력과 함께 에이전트의 중간 단계 경로를 반환할지 여부max_iterations: 실행 루프를 종료하기 전 최대 단계 수max_execution_time: 실행 루프에 소요될 수 있는 최대 시간early_stopping_method: 에이전트가AgentFinish를 반환하지 않을 때 사용할 조기 종료 방법. (“force” or “generate”)"force"는 시간 또는 반복 제한에 도달하여 중지되었다는 문자열을 반환합니다."generate"는 에이전트의 LLM 체인을 마지막으로 한 번 호출하여 이전 단계에 따라 최종 답변을 생성합니다.
handle_parsing_errors: 에이전트의 출력 파서에서 발생한 오류 처리 방법. (True, False, 또는 오류 처리 함수)trim_intermediate_steps: 중간 단계를 트리밍하는 방법. (-1: trim 하지 않음, 또는 트리밍 함수)
주요 메서드는 다음과 같습니다.
invoke: 에이전트 실행stream: 최종 출력에 도달하는 데 필요한 단계를 스트리밍
주요 기능은 다음과 같습니다.
- 도구 검증: 에이전트와 호환되는 도구인지 확인
- 실행 제어: 최대 반복 횟수 및 실행 시간 제한 설정 가능
- 오류 처리: 출력 파싱 오류에 대한 다양한 처리 옵션 제공
- 중간 단계 관리: 중간 단계 트리밍 및 반환 옵션
- 비동기 지원: 비동기 실행 및 스트리밍 지원
최적화 팁
max_iterations와max_execution_time을 적절히 설정하여 실행 시간 관리trim_intermediate_steps를 활용하여 메모리 사용량 최적화- 복잡한 작업의 경우
stream메서드를 사용하여 단계별 결과 모니터링
from langchain_classic.agents import AgentExecutor
# AgentExecutor 생성
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
max_iterations=10,
max_execution_time=10,
handle_parsing_errors=True,
)
# AgentExecutor 실행
result = agent_executor.invoke({"input": "AI 투자와 관련된 뉴스를 검색해 주세요."})
print("Agent 실행 결과:")
print(result["output"])
Output:
> Entering new AgentExecutor chain...
Invoking: `search_news` with `{'query': 'AI 투자'}`
[{'url': 'https://news.google.com/rss/articles/CBMiTkFVX3lxTE1nYnl1ajAyenR6dVVZdGpOa29mQjVrZmROUUE4QmZIdzQycEpTdDBVSU55Q2ZJVkJrSjVQSHRYWlh0dDdKRXJNOUMzbDZxZw?oc=5', 'content': '지난해 AI 투자 85% 늘어…60%는 美실리콘밸리 쏠림 - 전자신문'}, {'url': 'https://news.google.com/rss/articles/CBMingFBVV95cUxPRFBhbXRJdDdUdDBhSUdpRmtjTENLU0xwVWJSVGc0SUtlbDdiMC1qUllBdnZ2NUx3dzFySnR2V2ZKMnRNOGIxSUJzLWF4dWZEUURJSlZtNzVMb1NHOGdodEY3bHAwUHctSGpQWVpVTm1tT2lsU29XRTEyb0lUT3dGNXhYQ18wbVpfMmYtUExVOVZUcjZnMEFhSGJWYVB1Z9IBsgFBVV95cUxNN0M5WVNaTFZacHJpRFBFOGRIZG1JV3BZTE5FZnpZaEp6WTNmcnBseXdjcldRTXRsbmtqR05ad3RiM0gyNFp3QTFFNGkta2dfdlRMS0xkUC1SMGFGckRPRWFtbnV1WGdhNTQzaHd3WVF2Q2czUE5wcm1UNGRBNFZXeE1YZkx1cFdOM3F0ZWZ5YUJmaUtYU1NjbTNvSjNPQ1B4VkdyMl9OTURZMWJZUWRGLURR?oc=5', 'content': '오픈AI는 ‘깐부’ 아니었나... 젠슨 황, 145조 투자 보류 - 조선일보'}, {'url': 'https://news.google.com/rss/articles/CBMiWkFVX3lxTE1MSGV6RFQ0eDdNSjJXejJHVHlIMTNJTWxXQk92VU9XWjNCVWRiT3lKTzEwOHdWRDFhS05Xd3ZiS1RNSWl3TjJfdTN5Qk0yQUJCcVhSMkxsYS01QdIBXkFVX3lxTE5iS0dZQjh6bzRsbndNTjFCbThBbEV6MDlYakVrOWcxeGZFTlVFVHJXTjhHR0hKNzJpeVJXeXNvTjlhaC14YjZ6V3BuQzgzQkpKLW83U2FReklaek1oVHc?oc=5', 'content': '美 대기업까지 흔들?… AI 투자 위해 조직 슬림화 - fnnews.com'}, {'url': 'https://news.google.com/rss/articles/CBMiYEFVX3lxTE1PbnhNcWJlbU1ZUEd1dmRTMDBJdDRpb2RSTngwZVpLS2VxaFBVZTVfUTFfUVlabHpJS3h6Tk56LVlqWDE4WElkM2lDRDhTU2VZQWxmd0UtUFB6clBUa2UyLQ?oc=5', 'content': "축소되는 글로벌 AI '빅딜'…투자수익률 불확실성은 확대 - 네이트"}, {'url': 'https://news.google.com/rss/articles/CBMickFVX3lxTE5Lc0Q4TFVBNjhkRzFobjBEU1M5MXRrQ2NYVlE5ekgzNnJRemVkTWhTR3pMZXRDN3JLWktjcHhGem1NMmhYTnBvUWF3ZnBreDgwdXA0Mmo4ODFGMTJ2UFpnTjBOVHQwdzNHbGx5bkpqaWRmZ9IBdkFVX3lxTE1kLUgzeG5vVzJHN2Rtd0gtUV92RmJFVWNEaVJIdk1sbFhPT2FBajFXZzdOT255cFU0SnNoaDJnbGhnWXVPTDdFalNEdkhQTXdGNDlWTloxVlVWQTdQN3c1QU1nRnBOOHp1Z25vcnpfX0RlRzdpUXc?oc=5', 'content': '오픈AI 기업공개, AI 투자 거품 확인하는 시험대 될 듯 - 포춘코리아 디지털 뉴스'}]다음은 AI 투자와 관련된 최근 뉴스입니다:
1. [지난해 AI 투자 85% 늘어…60%는 美실리콘밸리 쏠림 - 전자신문](https://news.google.com/rss/articles/CBMiTkFVX3lxTE1nYnl1ajAyenR6dVVZdGpOa29mQjVrZmROUUE4QmZIdzQycEpTdDBVSU55Q2ZJVkJrSjVQSHRYWlh0dDdKRXJNOUMzbDZxZw?oc=5)
2. [오픈AI는 ‘깐부’ 아니었나... 젠슨 황, 145조 투자 보류 - 조선일보](https://news.google.com/rss/articles/CBMingFBVV95cUxPRFBhbXRJdDdUdDBhSUdpRmtjTENLU0xwVWJSVGc0SUtlbDdiMC1qUllBdnZ2NUx3dzFySnR2V2ZKMnRNOGIxSUJzLWF4dWZEUURJSlZtNzVMb1NHOGdodEY3bHAwUHctSGpQWVpVTm1tT2lsU29XRTEyb0lUT3dGNXhYQ18wbVpfMmYtUExVOVZUcjZnMEFhSGJWYVB1Z9IBsgFBVV95cUxNN0M5WVNaTFZacHJpRFBFOGRIZG1JV3BZTE5FZnpZaEp6WTNmcnBseXdjcldRTXRsbmtqR05ad3RiM0gyNFp3QTFFNGkta2dfdlRMS0xkUC1SMGFGckRPRWFtbnV1WGdhNTQzaHd3WVF2Q2czUE5wcm1UNGRBNFZXeE1YZkx1cFdOM3F0ZWZ5YUJmaUtYU1NjbTNvSjNPQ1B4VkdyMl9OTURZMWJZUWRGLURR?oc=5)
3. [美 대기업까지 흔들?… AI 투자 위해 조직 슬림화 - fnnews.com](https://news.google.com/rss/articles/CBMiWkFVX3lxTE1MSGV6RFQ0eDdNSjJXejJHVHlIMTNJTWxXQk92VU9XWjNCVWRiT3lKTzEwOHdWRDFhS05Xd3ZiS1RNSWl3TjJfdTN5Qk0yQUJCcVhSMkxsYS01QdIBXkFVX3lxTE5iS0dZQjh6bzRsbndNTjFCbThBbEV6MDlYakVrOWcxeGZFTlVFVHJXTjhHR0hKNzJpeVJXeXNvTjlhaC14YjZ6V3BuQzgzQkpKLW83U2FReklaek1oVHc?oc=5)
4. [축소되는 글로벌 AI '빅딜'…투자수익률 불확실성은 확대 - 네이트](https://news.google.com/rss/articles/CBMiYEFVX3lxTE1PbnhNcWJlbU1ZUEd1dmRTMDBJdDRpb2RSTngwZVpLS2VxaFBVZTVfUTFfUVlabHpJS3h6Tk56LVlqWDE4WElkM2lDRDhTU2VZQWxmd0UtUFB6clBUa2UyLQ?oc=5)
5. [오픈AI 기업공개, AI 투자 거품 확인하는 시험대 될 듯 - 포춘코리아 디지털 뉴스](https://news.google.com/rss/articles/CBMickFVX3lxTE5Lc0Q4TFVBNjhkRzFobjBEU1M5MXRrQ2NYVlE5ekgzNnJRemVkTWhTR3pMZXRDN3JLWktjcHhGem1NMmhYTnBvUWF3ZnBreDgwdXA0Mmo4ODFGMTJ2UFpnTjBOVHQwdzNHbGx5bkpqaWRmZ9IBdkFVX3lxTE1kLUgzeG5vVzJHN2Rtd0gtUV92RmJFVWNEaVJIdk1sbFhPT2FBajFXZzdOT255cFU0SnNoaDJnbGhnWXVPTDdFalNEdkhQTXdGNDlWTloxVlVWQTdQN3c1QU1nRnBOOHp1Z25vcnpfX0RlRzdpUXc?oc=5)
이 뉴스들은 AI 투자에 대한 최근 동향과 이슈를 다루고 있습니다.
> Finished chain.
Agent 실행 결과:
다음은 AI 투자와 관련된 최근 뉴스입니다:
1. [지난해 AI 투자 85% 늘어…60%는 美실리콘밸리 쏠림 - 전자신문](https://news.google.com/rss/articles/CBMiTkFVX3lxTE1nYnl1ajAyenR6dVVZdGpOa29mQjVrZmROUUE4QmZIdzQycEpTdDBVSU55Q2ZJVkJrSjVQSHRYWlh0dDdKRXJNOUMzbDZxZw?oc=5)
2. [오픈AI는 ‘깐부’ 아니었나... 젠슨 황, 145조 투자 보류 - 조선일보](https://news.google.com/rss/articles/CBMingFBVV95cUxPRFBhbXRJdDdUdDBhSUdpRmtjTENLU0xwVWJSVGc0SUtlbDdiMC1qUllBdnZ2NUx3dzFySnR2V2ZKMnRNOGIxSUJzLWF4dWZEUURJSlZtNzVMb1NHOGdodEY3bHAwUHctSGpQWVpVTm1tT2lsU29XRTEyb0lUT3dGNXhYQ18wbVpfMmYtUExVOVZUcjZnMEFhSGJWYVB1Z9IBsgFBVV95cUxNN0M5WVNaTFZacHJpRFBFOGRIZG1JV3BZTE5FZnpZaEp6WTNmcnBseXdjcldRTXRsbmtqR05ad3RiM0gyNFp3QTFFNGkta2dfdlRMS0xkUC1SMGFGckRPRWFtbnV1WGdhNTQzaHd3WVF2Q2czUE5wcm1UNGRBNFZXeE1YZkx1cFdOM3F0ZWZ5YUJmaUtYU1NjbTNvSjNPQ1B4VkdyMl9OTURZMWJZUWRGLURR?oc=5)
3. [美 대기업까지 흔들?… AI 투자 위해 조직 슬림화 - fnnews.com](https://news.google.com/rss/articles/CBMiWkFVX3lxTE1MSGV6RFQ0eDdNSjJXejJHVHlIMTNJTWxXQk92VU9XWjNCVWRiT3lKTzEwOHdWRDFhS05Xd3ZiS1RNSWl3TjJfdTN5Qk0yQUJCcVhSMkxsYS01QdIBXkFVX3lxTE5iS0dZQjh6bzRsbndNTjFCbThBbEV6MDlYakVrOWcxeGZFTlVFVHJXTjhHR0hKNzJpeVJXeXNvTjlhaC14YjZ6V3BuQzgzQkpKLW83U2FReklaek1oVHc?oc=5)
4. [축소되는 글로벌 AI '빅딜'…투자수익률 불확실성은 확대 - 네이트](https://news.google.com/rss/articles/CBMiYEFVX3lxTE1PbnhNcWJlbU1ZUEd1dmRTMDBJdDRpb2RSTngwZVpLS2VxaFBVZTVfUTFfUVlabHpJS3h6Tk56LVlqWDE4WElkM2lDRDhTU2VZQWxmd0UtUFB6clBUa2UyLQ?oc=5)
5. [오픈AI 기업공개, AI 투자 거품 확인하는 시험대 될 듯 - 포춘코리아 디지털 뉴스](https://news.google.com/rss/articles/CBMickFVX3lxTE5Lc0Q4TFVBNjhkRzFobjBEU1M5MXRrQ2NYVlE5ekgzNnJRemVkTWhTR3pMZXRDN3JLWktjcHhGem1NMmhYTnBvUWF3ZnBreDgwdXA0Mmo4ODFGMTJ2UFpnTjBOVHQwdzNHbGx5bkpqaWRmZ9IBdkFVX3lxTE1kLUgzeG5vVzJHN2Rtd0gtUV92RmJFVWNEaVJIdk1sbFhPT2FBajFXZzdOT255cFU0SnNoaDJnbGhnWXVPTDdFalNEdkhQTXdGNDlWTloxVlVWQTdQN3c1QU1nRnBOOHp1Z25vcnpfX0RlRzdpUXc?oc=5)
이 뉴스들은 AI 투자에 대한 최근 동향과 이슈를 다루고 있습니다.
4.1.4 Stream 출력으로 단계별 결과 확인
AgentExecutor의 stream() 메소드를 사용하여 에이전트의 중간 단계를 스트리밍할 것입니다.
stream()의 출력은 (Actions, Observation) 쌍 사이에서 번갈아 나타나며, 최종적으로 에이전트가 목표를 달성했다면 답변으로 마무리됩니다.
결과 출력이 되면 다음과 같은 형태와 순서로 출력이 됩니다.
- Actions 출력
- Observation 출력
- Action 출력
- Observation 출력
- …(목표 달성까지 계속)…
그 다음, 최종 목표가 달성되면 에이전트는 최종 답변을 출력할 것입니다. 이러한 출력의 내용은 다음과 같이 요약됩니다.
| 출력 | 내용 |
|---|---|
| Action | actions: AgentAction 또는 그 하위 클래스 messages: 액션 호출에 해당하는 채팅 메시지 |
| Observation | steps: 현재 액션과 그 관찰을 포함한 에이전트가 지금까지 수행한 작업의 기록 messages: 함수 호출 결과(즉, 관찰)를 포함한 채팅 메시지 |
| Final Answer | output: AgentFinish messages: 최종 출력을 포함한 채팅 메시지 |
from langchain_classic.agents import AgentExecutor
# AgentExecutor 생성
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=False,
handle_parsing_errors=True,
)
# 스트리밍 모드 실행
result = agent_executor.stream({"input": "AI 투자와 관련된 뉴스를 검색해 주세요."})
for step in result:
# 중간 단계 출력
print(step)
Output:
{'actions': [ToolAgentAction(tool='search_news', tool_input={'query': 'AI 투자'}, log="\nInvoking: `search_news` with `{'query': 'AI 투자'}`\n\n\n", message_log=[AIMessageChunk(content='', additional_kwargs={}, response_metadata={'model_provider': 'openai', 'finish_reason': 'tool_calls', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_1590f93f9d', 'service_tier': 'default'}, id='lc_run--019c1b68-7464-7970-8d4f-778675040fca', tool_calls=[{'name': 'search_news', 'args': {'query': 'AI 투자'}, 'id': 'call_omFVSCgFauxtqhyrVmZJTndh', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 140, 'output_tokens': 15, 'total_tokens': 155, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}, tool_call_chunks=[{'name': 'search_news', 'args': '{"query":"AI 투자"}', 'id': 'call_omFVSCgFauxtqhyrVmZJTndh', 'index': 0, 'type': 'tool_call_chunk'}], chunk_position='last')], tool_call_id='call_omFVSCgFauxtqhyrVmZJTndh')], 'messages': [AIMessageChunk(content='', additional_kwargs={}, response_metadata={'model_provider': 'openai', 'finish_reason': 'tool_calls', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_1590f93f9d', 'service_tier': 'default'}, id='lc_run--019c1b68-7464-7970-8d4f-778675040fca', tool_calls=[{'name': 'search_news', 'args': {'query': 'AI 투자'}, 'id': 'call_omFVSCgFauxtqhyrVmZJTndh', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 140, 'output_tokens': 15, 'total_tokens': 155, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}, tool_call_chunks=[{'name': 'search_news', 'args': '{"query":"AI 투자"}', 'id': 'call_omFVSCgFauxtqhyrVmZJTndh', 'index': 0, 'type': 'tool_call_chunk'}], chunk_position='last')]}
{'steps': [AgentStep(action=ToolAgentAction(tool='search_news', tool_input={'query': 'AI 투자'}, log="\nInvoking: `search_news` with `{'query': 'AI 투자'}`\n\n\n", message_log=[AIMessageChunk(content='', additional_kwargs={}, response_metadata={'model_provider': 'openai', 'finish_reason': 'tool_calls', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_1590f93f9d', 'service_tier': 'default'}, id='lc_run--019c1b68-7464-7970-8d4f-778675040fca', tool_calls=[{'name': 'search_news', 'args': {'query': 'AI 투자'}, 'id': 'call_omFVSCgFauxtqhyrVmZJTndh', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 140, 'output_tokens': 15, 'total_tokens': 155, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}, tool_call_chunks=[{'name': 'search_news', 'args': '{"query":"AI 투자"}', 'id': 'call_omFVSCgFauxtqhyrVmZJTndh', 'index': 0, 'type': 'tool_call_chunk'}], chunk_position='last')], tool_call_id='call_omFVSCgFauxtqhyrVmZJTndh'), observation=[{'url': 'https://news.google.com/rss/articles/CBMiTkFVX3lxTE1nYnl1ajAyenR6dVVZdGpOa29mQjVrZmROUUE4QmZIdzQycEpTdDBVSU55Q2ZJVkJrSjVQSHRYWlh0dDdKRXJNOUMzbDZxZw?oc=5', 'content': '지난해 AI 투자 85% 늘어…60%는 美실리콘밸리 쏠림 - 전자신문'}, {'url': 'https://news.google.com/rss/articles/CBMingFBVV95cUxPRFBhbXRJdDdUdDBhSUdpRmtjTENLU0xwVWJSVGc0SUtlbDdiMC1qUllBdnZ2NUx3dzFySnR2V2ZKMnRNOGIxSUJzLWF4dWZEUURJSlZtNzVMb1NHOGdodEY3bHAwUHctSGpQWVpVTm1tT2lsU29XRTEyb0lUT3dGNXhYQ18wbVpfMmYtUExVOVZUcjZnMEFhSGJWYVB1Z9IBsgFBVV95cUxNN0M5WVNaTFZacHJpRFBFOGRIZG1JV3BZTE5FZnpZaEp6WTNmcnBseXdjcldRTXRsbmtqR05ad3RiM0gyNFp3QTFFNGkta2dfdlRMS0xkUC1SMGFGckRPRWFtbnV1WGdhNTQzaHd3WVF2Q2czUE5wcm1UNGRBNFZXeE1YZkx1cFdOM3F0ZWZ5YUJmaUtYU1NjbTNvSjNPQ1B4VkdyMl9OTURZMWJZUWRGLURR?oc=5', 'content': '오픈AI는 ‘깐부’ 아니었나... 젠슨 황, 145조 투자 보류 - 조선일보'}, {'url': 'https://news.google.com/rss/articles/CBMiWkFVX3lxTE1MSGV6RFQ0eDdNSjJXejJHVHlIMTNJTWxXQk92VU9XWjNCVWRiT3lKTzEwOHdWRDFhS05Xd3ZiS1RNSWl3TjJfdTN5Qk0yQUJCcVhSMkxsYS01QdIBXkFVX3lxTE5iS0dZQjh6bzRsbndNTjFCbThBbEV6MDlYakVrOWcxeGZFTlVFVHJXTjhHR0hKNzJpeVJXeXNvTjlhaC14YjZ6V3BuQzgzQkpKLW83U2FReklaek1oVHc?oc=5', 'content': '美 대기업까지 흔들?… AI 투자 위해 조직 슬림화 - fnnews.com'}, {'url': 'https://news.google.com/rss/articles/CBMiYEFVX3lxTE1PbnhNcWJlbU1ZUEd1dmRTMDBJdDRpb2RSTngwZVpLS2VxaFBVZTVfUTFfUVlabHpJS3h6Tk56LVlqWDE4WElkM2lDRDhTU2VZQWxmd0UtUFB6clBUa2UyLQ?oc=5', 'content': "축소되는 글로벌 AI '빅딜'…투자수익률 불확실성은 확대 - 네이트"}, {'url': 'https://news.google.com/rss/articles/CBMickFVX3lxTE5Lc0Q4TFVBNjhkRzFobjBEU1M5MXRrQ2NYVlE5ekgzNnJRemVkTWhTR3pMZXRDN3JLWktjcHhGem1NMmhYTnBvUWF3ZnBreDgwdXA0Mmo4ODFGMTJ2UFpnTjBOVHQwdzNHbGx5bkpqaWRmZ9IBdkFVX3lxTE1kLUgzeG5vVzJHN2Rtd0gtUV92RmJFVWNEaVJIdk1sbFhPT2FBajFXZzdOT255cFU0SnNoaDJnbGhnWXVPTDdFalNEdkhQTXdGNDlWTloxVlVWQTdQN3c1QU1nRnBOOHp1Z25vcnpfX0RlRzdpUXc?oc=5', 'content': '오픈AI 기업공개, AI 투자 거품 확인하는 시험대 될 듯 - 포춘코리아 디지털 뉴스'}])], 'messages': [FunctionMessage(content='[{"url": "https://news.google.com/rss/articles/CBMiTkFVX3lxTE1nYnl1ajAyenR6dVVZdGpOa29mQjVrZmROUUE4QmZIdzQycEpTdDBVSU55Q2ZJVkJrSjVQSHRYWlh0dDdKRXJNOUMzbDZxZw?oc=5", "content": "지난해 AI 투자 85% 늘어…60%는 美실리콘밸리 쏠림 - 전자신문"}, {"url": "https://news.google.com/rss/articles/CBMingFBVV95cUxPRFBhbXRJdDdUdDBhSUdpRmtjTENLU0xwVWJSVGc0SUtlbDdiMC1qUllBdnZ2NUx3dzFySnR2V2ZKMnRNOGIxSUJzLWF4dWZEUURJSlZtNzVMb1NHOGdodEY3bHAwUHctSGpQWVpVTm1tT2lsU29XRTEyb0lUT3dGNXhYQ18wbVpfMmYtUExVOVZUcjZnMEFhSGJWYVB1Z9IBsgFBVV95cUxNN0M5WVNaTFZacHJpRFBFOGRIZG1JV3BZTE5FZnpZaEp6WTNmcnBseXdjcldRTXRsbmtqR05ad3RiM0gyNFp3QTFFNGkta2dfdlRMS0xkUC1SMGFGckRPRWFtbnV1WGdhNTQzaHd3WVF2Q2czUE5wcm1UNGRBNFZXeE1YZkx1cFdOM3F0ZWZ5YUJmaUtYU1NjbTNvSjNPQ1B4VkdyMl9OTURZMWJZUWRGLURR?oc=5", "content": "오픈AI는 ‘깐부’ 아니었나... 젠슨 황, 145조 투자 보류 - 조선일보"}, {"url": "https://news.google.com/rss/articles/CBMiWkFVX3lxTE1MSGV6RFQ0eDdNSjJXejJHVHlIMTNJTWxXQk92VU9XWjNCVWRiT3lKTzEwOHdWRDFhS05Xd3ZiS1RNSWl3TjJfdTN5Qk0yQUJCcVhSMkxsYS01QdIBXkFVX3lxTE5iS0dZQjh6bzRsbndNTjFCbThBbEV6MDlYakVrOWcxeGZFTlVFVHJXTjhHR0hKNzJpeVJXeXNvTjlhaC14YjZ6V3BuQzgzQkpKLW83U2FReklaek1oVHc?oc=5", "content": "美 대기업까지 흔들?… AI 투자 위해 조직 슬림화 - fnnews.com"}, {"url": "https://news.google.com/rss/articles/CBMiYEFVX3lxTE1PbnhNcWJlbU1ZUEd1dmRTMDBJdDRpb2RSTngwZVpLS2VxaFBVZTVfUTFfUVlabHpJS3h6Tk56LVlqWDE4WElkM2lDRDhTU2VZQWxmd0UtUFB6clBUa2UyLQ?oc=5", "content": "축소되는 글로벌 AI \'빅딜\'…투자수익률 불확실성은 확대 - 네이트"}, {"url": "https://news.google.com/rss/articles/CBMickFVX3lxTE5Lc0Q4TFVBNjhkRzFobjBEU1M5MXRrQ2NYVlE5ekgzNnJRemVkTWhTR3pMZXRDN3JLWktjcHhGem1NMmhYTnBvUWF3ZnBreDgwdXA0Mmo4ODFGMTJ2UFpnTjBOVHQwdzNHbGx5bkpqaWRmZ9IBdkFVX3lxTE1kLUgzeG5vVzJHN2Rtd0gtUV92RmJFVWNEaVJIdk1sbFhPT2FBajFXZzdOT255cFU0SnNoaDJnbGhnWXVPTDdFalNEdkhQTXdGNDlWTloxVlVWQTdQN3c1QU1nRnBOOHp1Z25vcnpfX0RlRzdpUXc?oc=5", "content": "오픈AI 기업공개, AI 투자 거품 확인하는 시험대 될 듯 - 포춘코리아 디지털 뉴스"}]', additional_kwargs={}, response_metadata={}, name='search_news')]}
{'output': "다음은 AI 투자와 관련된 최근 뉴스입니다:\n\n1. [지난해 AI 투자 85% 늘어…60%는 美실리콘밸리 쏠림 - 전자신문](https://news.google.com/rss/articles/CBMiTkFVX3lxTE1nYnl1ajAyenR6dVVZdGpOa29mQjVrZmROUUE4QmZIdzQycEpTdDBVSU55Q2ZJVkJrSjVQSHRYWlh0dDdKRXJNOUMzbDZxZw?oc=5)\n\n2. [오픈AI는 ‘깐부’ 아니었나... 젠슨 황, 145조 투자 보류 - 조선일보](https://news.google.com/rss/articles/CBMingFBVV95cUxPRFBhbXRJdDdUdDBhSUdpRmtjTENLU0xwVWJSVGc0SUtlbDdiMC1qUllBdnZ2NUx3dzFySnR2V2ZKMnRNOGIxSUJzLWF4dWZEUURJSlZtNzVMb1NHOGdodEY3bHAwUHctSGpQWVpVTm1tT2lsU29XRTEyb0lUT3dGNXhYQ18wbVpfMmYtUExVOVZUcjZnMEFhSGJWYVB1Z9IBsgFBVV95cUxNN0M5WVNaTFZacHJpRFBFOGRIZG1JV3BZTE5FZnpZaEp6WTNmcnBseXdjcldRTXRsbmtqR05ad3RiM0gyNFp3QTFFNGkta2dfdlRMS0xkUC1SMGFGckRPRWFtbnV1WGdhNTQzaHd3WVF2Q2czUE5wcm1UNGRBNFZXeE1YZkx1cFdOM3F0ZWZ5YUJmaUtYU1NjbTNvSjNPQ1B4VkdyMl9OTURZMWJZUWRGLURR?oc=5)\n\n3. [美 대기업까지 흔들?… AI 투자 위해 조직 슬림화 - fnnews.com](https://news.google.com/rss/articles/CBMiWkFVX3lxTE1MSGV6RFQ0eDdNSjJXejJHVHlIMTNJTWxXQk92VU9XWjNCVWRiT3lKTzEwOHdWRDFhS05Xd3ZiS1RNSWl3TjJfdTN5Qk0yQUJCcVhSMkxsYS01QdIBXkFVX3lxTE5iS0dZQjh6bzRsbndNTjFCbThBbEV6MDlYakVrOWcxeGZFTlVFVHJXTjhHR0hKNzJpeVJXeXNvTjlhaC14YjZ6V3BuQzgzQkpKLW83U2FReklaek1oVHc?oc=5)\n\n4. [축소되는 글로벌 AI '빅딜'…투자수익률 불확실성은 확대 - 네이트](https://news.google.com/rss/articles/CBMiYEFVX3lxTE1PbnhNcWJlbU1ZUEd1dmRTMDBJdDRpb2RSTngwZVpLS2VxaFBVZTVfUTFfUVlabHpJS3h6Tk56LVlqWDE4WElkM2lDRDhTU2VZQWxmd0UtUFB6clBUa2UyLQ?oc=5)\n\n5. [오픈AI 기업공개, AI 투자 거품 확인하는 시험대 될 듯 - 포춘코리아 디지털 뉴스](https://news.google.com/rss/articles/CBMickFVX3lxTE5Lc0Q4TFVBNjhkRzFobjBEU1M5MXRrQ2NYVlE5ekgzNnJRemVkTWhTR3pMZXRDN3JLWktjcHhGem1NMmhYTnBvUWF3ZnBreDgwdXA0Mmo4ODFGMTJ2UFpnTjBOVHQwdzNHbGx5bkpqaWRmZ9IBdkFVX3lxTE1kLUgzeG5vVzJHN2Rtd0gtUV92RmJFVWNEaVJIdk1sbFhPT2FBajFXZzdOT255cFU0SnNoaDJnbGhnWXVPTDdFalNEdkhQTXdGNDlWTloxVlVWQTdQN3c1QU1nRnBOOHp1Z25vcnpfX0RlRzdpUXc?oc=5)\n\n이 뉴스들은 AI 투자에 대한 최근 동향과 이슈를 다루고 있습니다.", 'messages': [AIMessage(content="다음은 AI 투자와 관련된 최근 뉴스입니다:\n\n1. [지난해 AI 투자 85% 늘어…60%는 美실리콘밸리 쏠림 - 전자신문](https://news.google.com/rss/articles/CBMiTkFVX3lxTE1nYnl1ajAyenR6dVVZdGpOa29mQjVrZmROUUE4QmZIdzQycEpTdDBVSU55Q2ZJVkJrSjVQSHRYWlh0dDdKRXJNOUMzbDZxZw?oc=5)\n\n2. [오픈AI는 ‘깐부’ 아니었나... 젠슨 황, 145조 투자 보류 - 조선일보](https://news.google.com/rss/articles/CBMingFBVV95cUxPRFBhbXRJdDdUdDBhSUdpRmtjTENLU0xwVWJSVGc0SUtlbDdiMC1qUllBdnZ2NUx3dzFySnR2V2ZKMnRNOGIxSUJzLWF4dWZEUURJSlZtNzVMb1NHOGdodEY3bHAwUHctSGpQWVpVTm1tT2lsU29XRTEyb0lUT3dGNXhYQ18wbVpfMmYtUExVOVZUcjZnMEFhSGJWYVB1Z9IBsgFBVV95cUxNN0M5WVNaTFZacHJpRFBFOGRIZG1JV3BZTE5FZnpZaEp6WTNmcnBseXdjcldRTXRsbmtqR05ad3RiM0gyNFp3QTFFNGkta2dfdlRMS0xkUC1SMGFGckRPRWFtbnV1WGdhNTQzaHd3WVF2Q2czUE5wcm1UNGRBNFZXeE1YZkx1cFdOM3F0ZWZ5YUJmaUtYU1NjbTNvSjNPQ1B4VkdyMl9OTURZMWJZUWRGLURR?oc=5)\n\n3. [美 대기업까지 흔들?… AI 투자 위해 조직 슬림화 - fnnews.com](https://news.google.com/rss/articles/CBMiWkFVX3lxTE1MSGV6RFQ0eDdNSjJXejJHVHlIMTNJTWxXQk92VU9XWjNCVWRiT3lKTzEwOHdWRDFhS05Xd3ZiS1RNSWl3TjJfdTN5Qk0yQUJCcVhSMkxsYS01QdIBXkFVX3lxTE5iS0dZQjh6bzRsbndNTjFCbThBbEV6MDlYakVrOWcxeGZFTlVFVHJXTjhHR0hKNzJpeVJXeXNvTjlhaC14YjZ6V3BuQzgzQkpKLW83U2FReklaek1oVHc?oc=5)\n\n4. [축소되는 글로벌 AI '빅딜'…투자수익률 불확실성은 확대 - 네이트](https://news.google.com/rss/articles/CBMiYEFVX3lxTE1PbnhNcWJlbU1ZUEd1dmRTMDBJdDRpb2RSTngwZVpLS2VxaFBVZTVfUTFfUVlabHpJS3h6Tk56LVlqWDE4WElkM2lDRDhTU2VZQWxmd0UtUFB6clBUa2UyLQ?oc=5)\n\n5. [오픈AI 기업공개, AI 투자 거품 확인하는 시험대 될 듯 - 포춘코리아 디지털 뉴스](https://news.google.com/rss/articles/CBMickFVX3lxTE5Lc0Q4TFVBNjhkRzFobjBEU1M5MXRrQ2NYVlE5ekgzNnJRemVkTWhTR3pMZXRDN3JLWktjcHhGem1NMmhYTnBvUWF3ZnBreDgwdXA0Mmo4ODFGMTJ2UFpnTjBOVHQwdzNHbGx5bkpqaWRmZ9IBdkFVX3lxTE1kLUgzeG5vVzJHN2Rtd0gtUV92RmJFVWNEaVJIdk1sbFhPT2FBajFXZzdOT255cFU0SnNoaDJnbGhnWXVPTDdFalNEdkhQTXdGNDlWTloxVlVWQTdQN3c1QU1nRnBOOHp1Z25vcnpfX0RlRzdpUXc?oc=5)\n\n이 뉴스들은 AI 투자에 대한 최근 동향과 이슈를 다루고 있습니다.", additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[])]}
4.2 중간 단계 출력을 사용자 정의 함수로 출력
다음의 3개 함수를 정의하고 이를 통해 중간 단계 출력을 사용자 정의합니다.
tool_callback: 도구 호출 출력을 처리하는 함수observation_callback: 관찰(Observation) 출력을 처리하는 함수result_callback: 최종 답변 출력을 처리하는 함수
아래는 Agent의 중간 단계 과정을 깔끔하게 출력하기 위하여 사용되는 콜백 함수입니다. 이 콜백 함수는 Streamlit에서 중간 단계를 출력하여 사용자에게 제공할 때 유용할 수 있습니다.
from langchain_teddynote.messages import AgentStreamParser
agent_stream_parser = AgentStreamParser()
스트리밍 방식으로 Agent의 응답 과정을 확인합니다.
# 질의에 대한 답변을 스트리밍으로 출력 요청
result = agent_executor.stream(
{"input": "matplotlib 을 사용하여 pie 차트를 그리는 코드를 작성하고 실행하세요."}
)
for step in result:
# 중간 단계를 parser를 사용하여 단계별로 출력
agent_stream_parser.process_agent_steps(step)
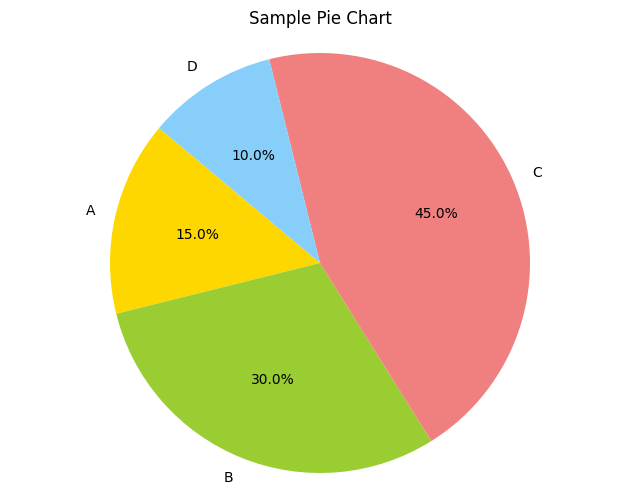
Output:
WARNING:langchain_experimental.utilities.python:Python REPL can execute arbitrary code. Use with caution.
[도구 호출]
Tool: python_repl_tool
code: import matplotlib.pyplot as plt
# 데이터
sizes = [15, 30, 45, 10]
labels = ['A', 'B', 'C', 'D']
colors = ['gold', 'yellowgreen', 'lightcoral', 'lightskyblue']
# 파이 차트 그리기
plt.figure(figsize=(8, 6))
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=140)
plt.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.title('Sample Pie Chart')
plt.show()
Log:
Invoking: `python_repl_tool` with `{'code': "import matplotlib.pyplot as plt\n\n# 데이터\nsizes = [15, 30, 45, 10]\nlabels = ['A', 'B', 'C', 'D']\ncolors = ['gold', 'yellowgreen', 'lightcoral', 'lightskyblue']\n\n# 파이 차트 그리기\nplt.figure(figsize=(8, 6))\nplt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=140)\nplt.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.\nplt.title('Sample Pie Chart')\nplt.show()"}`
[관찰 내용]
Observation:
[최종 답변]
코드 실행 결과로 파이 차트가 생성되었습니다. 차트는 다음과 같은 데이터로 구성되어 있습니다:
- A: 15%
- B: 30%
- C: 45%
- D: 10%
각 섹션은 서로 다른 색상으로 표시되며, 차트의 제목은 "Sample Pie Chart"입니다.
다음은 callback을 수정하여 사용하는 방법입니다.
# AgentCallbacks와 AgentStreamParser를 langchain_teddynote.messages에서 가져옵니다.
from langchain_teddynote.messages import AgentCallbacks, AgentStreamParser
# 도구 호출 시 실행되는 콜백 함수입니다.
def tool_callback(tool) -> None:
print("<<<<<<< 도구 호출 >>>>>>")
print(f"Tool: {tool.get('tool')}") # 사용된 도구의 이름을 출력합니다.
print("<<<<<<< 도구 호출 >>>>>>")
# 관찰 결과를 출력하는 콜백 함수입니다.
def observation_callback(observation) -> None:
print("<<<<<<< 관찰 내용 >>>>>>")
print(
f"Observation: {observation.get('observation')[0]}"
) # 관찰 내용을 출력합니다.
print("<<<<<<< 관찰 내용 >>>>>>")
#최종 결과를 출력하는 콜백 함수입니다.
def result_callback(result: str) -> None:
print("<<<<<<< 최종 답변 >>>>>>")
print(result) # 최종 답변을 출력합니다.
print("<<<<<<< 최종 답변 >>>>>>")
# AgentCallbacks 객체를 생성하여 각 단계별 콜백 함수를 설정합니다.
agent_callbacks = AgentCallbacks(
tool_callback=tool_callback,
observation_callback=observation_callback,
result_callback=result_callback,
)
# AgentStreamParser 객체를 생성하여 에이전트의 실행 과정을 파싱합니다.
agent_stream_parser = AgentStreamParser()
아래의 출력 내용을 확인해 보면 중간 내용의 출력 값이 내가 변경한 콜백 함수의 출력 값으로 변경된 것을 확인할 수 있습니다.
# 질의에 대한 답변을 스트리밍으로 출력 요청
result = agent_executor.stream({"input": "AI 투자관련 뉴스를 검색해 주세요."})
for step in result:
# 중간 단계를 parser를 사용하여 단계별로 출력
agent_stream_parser.process_agent_steps(step)
Output:
[도구 호출]
Tool: search_news
query: AI 투자
Log:
Invoking: `search_news` with `{'query': 'AI 투자'}`
[관찰 내용]
Observation: [{'url': 'https://news.google.com/rss/articles/CBMiTkFVX3lxTE1nYnl1ajAyenR6dVVZdGpOa29mQjVrZmROUUE4QmZIdzQycEpTdDBVSU55Q2ZJVkJrSjVQSHRYWlh0dDdKRXJNOUMzbDZxZw?oc=5', 'content': '지난해 AI 투자 85% 늘어…60%는 美실리콘밸리 쏠림 - 전자신문'}, {'url': 'https://news.google.com/rss/articles/CBMingFBVV95cUxPRFBhbXRJdDdUdDBhSUdpRmtjTENLU0xwVWJSVGc0SUtlbDdiMC1qUllBdnZ2NUx3dzFySnR2V2ZKMnRNOGIxSUJzLWF4dWZEUURJSlZtNzVMb1NHOGdodEY3bHAwUHctSGpQWVpVTm1tT2lsU29XRTEyb0lUT3dGNXhYQ18wbVpfMmYtUExVOVZUcjZnMEFhSGJWYVB1Z9IBsgFBVV95cUxNN0M5WVNaTFZacHJpRFBFOGRIZG1JV3BZTE5FZnpZaEp6WTNmcnBseXdjcldRTXRsbmtqR05ad3RiM0gyNFp3QTFFNGkta2dfdlRMS0xkUC1SMGFGckRPRWFtbnV1WGdhNTQzaHd3WVF2Q2czUE5wcm1UNGRBNFZXeE1YZkx1cFdOM3F0ZWZ5YUJmaUtYU1NjbTNvSjNPQ1B4VkdyMl9OTURZMWJZUWRGLURR?oc=5', 'content': '오픈AI는 ‘깐부’ 아니었나... 젠슨 황, 145조 투자 보류 - 조선일보'}, {'url': 'https://news.google.com/rss/articles/CBMiWkFVX3lxTE1MSGV6RFQ0eDdNSjJXejJHVHlIMTNJTWxXQk92VU9XWjNCVWRiT3lKTzEwOHdWRDFhS05Xd3ZiS1RNSWl3TjJfdTN5Qk0yQUJCcVhSMkxsYS01QdIBXkFVX3lxTE5iS0dZQjh6bzRsbndNTjFCbThBbEV6MDlYakVrOWcxeGZFTlVFVHJXTjhHR0hKNzJpeVJXeXNvTjlhaC14YjZ6V3BuQzgzQkpKLW83U2FReklaek1oVHc?oc=5', 'content': '美 대기업까지 흔들?… AI 투자 위해 조직 슬림화 - fnnews.com'}, {'url': 'https://news.google.com/rss/articles/CBMiYEFVX3lxTE1PbnhNcWJlbU1ZUEd1dmRTMDBJdDRpb2RSTngwZVpLS2VxaFBVZTVfUTFfUVlabHpJS3h6Tk56LVlqWDE4WElkM2lDRDhTU2VZQWxmd0UtUFB6clBUa2UyLQ?oc=5', 'content': "축소되는 글로벌 AI '빅딜'…투자수익률 불확실성은 확대 - 네이트"}, {'url': 'https://news.google.com/rss/articles/CBMickFVX3lxTE5Lc0Q4TFVBNjhkRzFobjBEU1M5MXRrQ2NYVlE5ekgzNnJRemVkTWhTR3pMZXRDN3JLWktjcHhGem1NMmhYTnBvUWF3ZnBreDgwdXA0Mmo4ODFGMTJ2UFpnTjBOVHQwdzNHbGx5bkpqaWRmZ9IBdkFVX3lxTE1kLUgzeG5vVzJHN2Rtd0gtUV92RmJFVWNEaVJIdk1sbFhPT2FBajFXZzdOT255cFU0SnNoaDJnbGhnWXVPTDdFalNEdkhQTXdGNDlWTloxVlVWQTdQN3c1QU1nRnBOOHp1Z25vcnpfX0RlRzdpUXc?oc=5', 'content': '오픈AI 기업공개, AI 투자 거품 확인하는 시험대 될 듯 - 포춘코리아 디지털 뉴스'}]
[최종 답변]
다음은 AI 투자와 관련된 최근 뉴스 기사들입니다:
1. [지난해 AI 투자 85% 늘어…60%는 美실리콘밸리 쏠림 - 전자신문](https://news.google.com/rss/articles/CBMiTkFVX3lxTE1nYnl1ajAyenR6dVVZdGpOa29mQjVrZmROUUE4QmZIdzQycEpTdDBVSU55Q2ZJVkJrSjVQSHRYWlh0dDdKRXJNOUMzbDZxZw?oc=5)
2. [오픈AI는 ‘깐부’ 아니었나... 젠슨 황, 145조 투자 보류 - 조선일보](https://news.google.com/rss/articles/CBMingFBVV95cUxPRFBhbXRJdDdUdDBhSUdpRmtjTENLU0xwVWJSVGc0SUtlbDdiMC1qUllBdnZ2NUx3dzFySnR2V2ZKMnRNOGIxSUJzLWF4dWZEUURJSlZtNzVMb1NHOGdodEY3bHAwUHctSGpQWVpVTm1tT2lsU29XRTEyb0lUT3dGNXhYQ18wbVpfMmYtUExVOVZUcjZnMEFhSGJWYVB1Z9IBsgFBVV95cUxNN0M5WVNaTFZacHJpRFBFOGRIZG1JV3BZTE5FZnpZaEp6WTNmcnBseXdjcldRTXRsbmtqR05ad3RiM0gyNFp3QTFFNGkta2dfdlRMS0xkUC1SMGFGckRPRWFtbnV1WGdhNTQzaHd3WVF2Q2czUE5wcm1UNGRBNFZXeE1YZkx1cFdOM3F0ZWZ5YUJmaUtYU1NjbTNvSjNPQ1B4VkdyMl9OTURZMWJZUWRGLURR?oc=5)
3. [美 대기업까지 흔들?… AI 투자 위해 조직 슬림화 - fnnews.com](https://news.google.com/rss/articles/CBMiWkFVX3lxTE1MSGV6RFQ0eDdNSjJXejJHVHlIMTNJTWxXQk92VU9XWjNCVWRiT3lKTzEwOHdWRDFhS05Xd3ZiS1RNSWl3TjJfdTN5Qk0yQUJCcVhSMkxsYS01QdIBXkFVX3lxTE5iS0dZQjh6bzRsbndNTjFCbThBbEV6MDlYakVrOWcxeGZFTlVFVHJXTjhHR0hKNzJpeVJXeXNvTjlhaC14YjZ6V3BuQzgzQkpKLW83U2FReklaek1oVHc?oc=5)
4. [축소되는 글로벌 AI '빅딜'…투자수익률 불확실성은 확대 - 네이트](https://news.google.com/rss/articles/CBMiYEFVX3lxTE1PbnhNcWJlbU1ZUEd1dmRTMDBJdDRpb2RSTngwZVpLS2VxaFBVZTVfUTFfUVlabHpJS3h6Tk56LVlqWDE4WElkM2lDRDhTU2VZQWxmd0UtUFB6clBUa2UyLQ?oc=5)
5. [오픈AI 기업공개, AI 투자 거품 확인하는 시험대 될 듯 - 포춘코리아 디지털 뉴스](https://news.google.com/rss/articles/CBMickFVX3lxTE5Lc0Q4TFVBNjhkRzFobjBEU1M5MXRrQ2NYVlE5ekgzNnJRemVkTWhTR3pMZXRDN3JLWktjcHhGem1NMmhYTnBvUWF3ZnBreDgwdXA0Mmo4ODFGMTJ2UFpnTjBOVHQwdzNHbGx5bkpqaWRmZ9IBdkFVX3lxTE1kLUgzeG5vVzJHN2Rtd0gtUV92RmJFVWNEaVJIdk1sbFhPT2FBajFXZzdOT255cFU0SnNoaDJnbGhnWXVPTDdFalNEdkhQTXdGNDlWTloxVlVWQTdQN3c1QU1nRnBOOHp1Z25vcnpfX0RlRzdpUXc?oc=5)
이 기사들은 AI 투자에 대한 최근 동향과 이슈를 다루고 있습니다.
4.3 이전 대화내용을 기억하는 Agent
이전의 대화내용을 기억하기 위해서는 이전에 알아보았던 RunnableWithMessageHistory를 사용하여 AgentExecutor를 감싸줍니다.
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# session_id를 저장할 딕셔너리 생성
store = {}
# session_id를 기반으로 세션 기록을 가져오는 함수
def get_session_history(session_ids): # session_id가 store에 없는 경우
# 새로운 ChatMessageHistory 객체를 생성하여 store에 저장
if session_ids not in store:
store[session_ids] = ChatMessageHistory()
return store[session_ids] # 해당 세션 ID에 대한 세션 기록 반환
# 채팅 메시지 기록이 추가된 에이전트를 생성합니다.
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
# 대화 session_id
get_session_history,
# 프롬프트의 질문이 입력되는 key: "input"
input_messages_key = "input",
# 프롬프트의 메시지가 입력되는 key: "chat_history"
history_messages_key="chat_history",
)
# 질의에 대한 답변을 스트리밍으로 출력 요청
response = agent_with_chat_history.stream(
{"input" : "안녕? 내 이름은 테디야!"},
# session_id 설정
config={"configurable": {"session_id": "abc123"}},
)
# 출력 확인
for step in response:
agent_stream_parser.process_agent_steps(step)
Output:
[최종 답변]
안녕하세요, 테디! 만나서 반가워요. 어떻게 도와드릴까요?
# 질의에 대한 답변을 스트리밍으로 출력 요청
response = agent_with_chat_history.stream(
{"input": "내 이름이 뭐라고?"},
# session_id 설정
config={"configurable": {"session_id": "abc123"}},
)
# 출력 확인
for step in response:
agent_stream_parser.process_agent_steps(step)
Output:
[최종 답변]
당신의 이름은 테디입니다!
# 질의에 대한 답변을 스트리밍으로 출력 요청
response = agent_with_chat_history.stream(
{
"input": "내 이메일 주소는 teddy@teddynote.com 이야. 회사 이름은 테디노트 주식회사야."
},
# session_id 설정
config={"configurable": {"session_id": "abc123"}},
)
# 출력 확인
for step in response:
agent_stream_parser.process_agent_steps(step)
Output:
[최종 답변]
감사합니다, 테디! 테디노트 주식회사에 대해 더 알고 싶으신가요? 아니면 다른 도움이 필요하신가요?
# 질의에 대한 답변을 스트리밍으로 출력 요청
response = agent_with_chat_history.stream(
{
"input": "최신 뉴스 5개를 검색해서 이메일의 본문으로 작성해줘. "
"수신인에는 `셜리 상무님` 그리고, 발신인에는 내 인적정보를 적어줘."
"정중한 어조로 작성하고, 메일의 시작과 끝에는 적절한 인사말과 맺음말을 적어줘."
},
# session_id 설정
config={"configurable": {"session_id": "abc123"}},
)
# 출력 확인
for step in response:
agent_stream_parser.process_agent_steps(step)
Output:
[도구 호출]
Tool: search_news
query: 최신 뉴스
Log:
Invoking: `search_news` with `{'query': '최신 뉴스'}`
[관찰 내용]
Observation: [{'url': 'https://news.google.com/rss/articles/CBMiS0FVX3lxTFA4Yll2enlYODJCeXJja3FjcHFqX3pUeUNabXIyT2p2cUdaMmFTMkhvSFdmWWJlSXFqTXVmcHhDZ0JkNkI3QkNmWEd4MA?oc=5', 'content': '정치 - 동아일보'}, {'url': 'https://news.google.com/rss/articles/CBMiakFVX3lxTFB6b3FPREFINURLSy1pVUZDbXB4X3JwaW1fVGNCRks1RklJMDFNTWxCbURTbGMwU05kWVRRLU9xNnVFUkNPVFNLaUlTOThQaDRoQzlKQWtsQnVETnFqbEhGc2hIQnU2RERoS3c?oc=5', 'content': '인사이드 구글 - blog.google'}, {'url': 'https://news.google.com/rss/articles/CBMiaEFVX3lxTE85NThoVWlJbFdIVURHX1F3WU9qTHBHTF9vQlMyMGZjYllnMnY3RWUyak5WWnFlWm9aS3BWYWN1V3l1VGFxUHhzRzVzc3otcEl6blhPaG1YNk1xcXRHYlhRZkZXRzNOWDNf0gFsQVVfeXFMUEozdmpvVTg0UnRqc1c3b1NxZ1pqNW8ybU9XVjdNLWZnWHRzWmtROTJ3NlBSWDRXLTR0VWJtUHhBRzM4aXJaOVp4ckdUVWtMdmhYcmFuZW5aUHFlY0JkUU12SVdhRF8tenl1YjFJ?oc=5', 'content': '“건설경기 활로 찾는다” 제주, 그린 리모델링 에너지 전환 - 대한전문건설신문'}, {'url': 'https://news.google.com/rss/articles/CBMilAFBVV95cUxOd0IzSlliaEJPQXU4aktNM1o3WWRDTV94RFRDQlZsUWY0aXpieGtnX1hmMDlqV1F4Mk5KYzh0V08wSDZpVGxlS25BZ2R3TlAyN2NES0J6LVVSNm5XbFJrVzJMQ2RPNmY0RUM5bFl3X1lGd3ZmLXVFOHFYQ2RPMHY2NjM5eHVGTFZfLUFrWWdManlCckYx0gGaAUFVX3lxTFBfTGpNeXhlZzJlb2JxNXZjaTBpYk50SHRxM2ZUdjJmVWVONTU4dTUzZnYtbnFoOHV2Y3JHbFpNSUMwaTFKelRTOW9JcmNFVzRJVGZIb3kwRWQ1aE1vZEo0RWRaZXRQbzJxVVIzY09acnBySEJkejA2YURZcGdMeTB2VGZTbXJMc3lidUc5VHJIUWwxdXlGS1dvUmc?oc=5', 'content': 'AI 칩의 최신 뉴스 - 마이크론, 전략적 대만 인수로 DRAM 용량 확대 - simplywall.st'}, {'url': 'https://news.google.com/rss/articles/CBMiW0FVX3lxTE1CenUwbWg3ZUJraFE5Q1l5blZfVnpEdDdxYTFYZlg2MnN2LVdEak95Vk1YWS1ILXlhQW5sLWFCSFdRUWZjanpqLTBoVldHUlBGZ0RFbTc2SHpORlE?oc=5', 'content': '밀라노-코르티나 2026 동계 올림픽 - 최신뉴스, 일정, 결과 - Milano Cortina 2026'}]
[최종 답변]
아래는 셜리 상무님께 보낼 이메일 본문입니다.
---
제목: 최신 뉴스 업데이트
안녕하세요, 셜리 상무님.
테디노트 주식회사의 테디입니다. 최신 뉴스 5개를 아래와 같이 정리하여 전달드립니다.
1. [정치 - 동아일보](https://news.google.com/rss/articles/CBMiS0FVX3lxTFA4Yll2enlYODJCeXJja3FjcHFqX3pUeUNabXIyT2p2cUdaMmFTMkhvSFdmWWJlSXFqTXVmcHhDZ0JkNkI3QkNmWEd4MA?oc=5)
2. [인사이드 구글 - blog.google](https://news.google.com/rss/articles/CBMiakFVX3lxTFB6b3FPREFINURLSy1pVUZDbXB4X3JwaW1fVGNCRks1RklJMDFNTWxCbURTbGMwU05kWVRRLU9xNnVFUkNPVFNLaUlTOThQaDRoQzlKQWtsQnVETnFqbEhGc2hIQnU2RERoS3c?oc=5)
3. [“건설경기 활로 찾는다” 제주, 그린 리모델링 에너지 전환 - 대한전문건설신문](https://news.google.com/rss/articles/CBMiaEFVX3lxTE85NThoVWlJbFdIVURHX1F3WU9qTHBHTF9vQlMyMGZjYllnMnY3RWUyak5WWnFlWm9aS3BWYWN1V3l1VGFxUHhzRzVzc3otcEl6blhPaG1YNk1xcXRHYlhRZkZXRzNOWDNf0gFsQVVfeXFMUEozdmpvVTg0UnRqc1c3b1NxZ1pqNW8ybU9XVjdNLWZnWHRzWmtROTJ3NlBSWDRXLTR0VWJtUHhBRzM4aXJaOVp4ckdUVWtMdmhYcmFuZW5aUHFlY0JkUU12SVdhRF8tenl1YjFJ?oc=5)
4. [AI 칩의 최신 뉴스 - 마이크론, 전략적 대만 인수로 DRAM 용량 확대 - simplywall.st](https://news.google.com/rss/articles/CBMilAFBVV95cUxOd0IzSlliaEJPQXU4aktNM1o3WWRDTV94RFRDQlZsUWY0aXpieGtnX1hmMDlqV1F4Mk5KYzh0V08wSDZpVGxlS25BZ2R3TlAyN2NES0J6LVVSNm5XbFJrVzJMQ2RPNmY0RUM5bFl3X1lGd3ZmLXVFOHFYQ2RPMHY2NjM5eHVGTFZfLUFrWWdManlCckYx0gGaAUFVX3lxTFBfTGpNeXhlZzJlb2JxNXZjaTBpYk50SHRxM2ZUdjJmVWVONTU4dTUzZnYtbnFoOHV2Y3JHbFpNSUMwaTFKelRTOW9JcmNFVzRJVGZIb3kwRWQ1aE1vZEo0RWRaZXRQbzJxVVIzY09acnBySEJkejA2YURZcGdMeTB2VGZTbXJMc3lidUc5VHJIUWwxdXlGS1dvUmc?oc=5)
5. [밀라노-코르티나 2026 동계 올림픽 - 최신뉴스, 일정, 결과 - Milano Cortina 2026](https://news.google.com/rss/articles/CBMiW0FVX3lxTE1CenUwbWg3ZUJraFE5Q1l5blZfVnpEdDdxYTFYZlg2MnN2LVdEak95Vk1YWS1ILXlhQW5sLWFCSFdRUWZjanpqLTBoVldHUlBGZ0RFbTc2SHpORlE?oc=5)
이 정보가 도움이 되길 바랍니다. 추가적인 질문이나 요청이 있으시면 언제든지 말씀해 주세요.
감사합니다.
테디
teddy@teddynote.com
테디노트 주식회사
---
이메일을 보내실 준비가 되셨나요? 추가로 수정할 부분이 있으면 말씀해 주세요!
5. Iteration 기능과 사람 개입(Human-in-the-loop)
5.1 Iteration 기능과 사람 개입(Human-in-the-loop)
iter() 메서드는 에이전트의 실행 과정을 단계별로 반복할 수 있게 해주는 반복자(iterator)를 생성합니다. 중간 과정에서 사용자의 입력을 받아 계속 진행할지 묻는 기능을 제공합니다. 이를 Human-in-the-loop라고 합니다.
우선 실습 코드 실행에 필요한 라이브러리 설치부터 진행해 줍니다.
!pip install -U langchain langchain-core langchain-classic langchain-openai
먼저 도구(tool)를 정의합니다.
from langchain_classic.tools import tool
@tool
def add_function(a: float, b: float) -> float:
"""Adds two numbers together."""
return a+b
다음으로, add_function을 사용하여 덧셈 계산을 수행하는 Agent를 정의합니다.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_classic.agents import create_tool_calling_agent, AgentExecutor
# 도구 정의
tools = [add_function]
# LLM 생성
gpt = ChatOpenAI(model="gpt-4o-mini")
# prompt 생성
prompt = ChatPromptTemplate.from_messages(
[
("system",
"You are ar helpful assistant. Make sure to use the 'search_news' tool for searching keyword related news.",
),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
# Agent 생성
gpt_agent = create_tool_calling_agent(gpt, tools, prompt)
# AgentExecutor 생성
agent_executor = AgentExecutor(
agent=gpt_agent,
tools=tools,
verbose=False,
max_iterations=10,
handle_parsing_errors=True,
)
5.1.1 AgentExecutor의 iter() 메서드
iter() 메서드는 AgentExecutor의 실행 과정을 단계별로 반복할 수 있게 해주는 반복자(iterator)를 생성합니다.
이 메서드는 에이전트가 최종 출력에 도달하기까지 거치는 단계들을 순차적으로 접근할 수 있는 AgentExecutorIterator 객체를 반환합니다.
이 메서드를 이용해 단계별로 계산 결과를 사용자에게 보여주고, 사용자가 계속 진행할지 묻도록 하는 Human-in-the-loop 기능을 구현할 수 있습니다. 사용자가 ‘y’가 아닌 다른 입력을 하면 반복 중단됩니다.
# 계산할 질문 설정
question = "114.5 + 121.2 + 34.2 + 110.1 의 계산 결과는?"
# agent_executor를 반복적으로 실행
for step in agent_executor.iter({"input": question}):
if output := step.get("intermediate_step"):
action, value = output[0]
if action.tool == "add_function":
# Tool 실행 결과 출력
print(f"\nTool Name: {action.tool}, 실행 결과: {value}")
# 사용자에게 계속 진행할지 묻습니다.
_continue = input("계속 진행하시겠습니까? (y/n)?:\n") or "Y"
# 사용자가 'y'가 아닌 다른 입력을 하면 반복 중단
if _continue.lower() != "y":
break
# 최종 결과 출력
if "output" in step:
print(step["output"])
Output:
Tool Name: add_function, 실행 결과: 235.7
계속 진행하시겠습니까? (y/n)?:
y
Tool Name: add_function, 실행 결과: 269.9
계속 진행하시겠습니까? (y/n)?:
y
Tool Name: add_function, 실행 결과: 380.0
계속 진행하시겠습니까? (y/n)?:
y
114.5 + 121.2 + 34.2 + 110.1의 계산 결과는 380.0입니다.
6. Agentic RAG
Agentic RAG란 고정된 선형 파이프라인(Simple RAG)을 넘어, LLM이 스스로 추론하고 행동하는 ‘에이전트(Agent)’로서 RAG 프로세스를 주도하는 아키텍처를 의미합니다.
기본적인 RAG가 사용자의 질문을 받으면 무조건 ‘검색’하고 ‘생성’하는 수동적인 방식이라면, Agentic RAG는 “이 질문에 검색이 필요한가?”, “검색 결과가 충분한가?”, “답변에 오류는 없는가?”를 스스로 판단하고 필요에 따라 과정을 반복하거나 경로를 수정합니다.
기본적인 RAG(Naive/Advanced RAG)는 다음과 같은 고질적인 문제를 가지고 있습니다.
- 저품질 검색의 고착화: 검색된 문서가 질문과 상관없어도 무조건 답변을 생성하여 할루시네이션(Hallucination) 유발
- 복잡한 질문 처리 불가: 여러 단계의 추론이나 다수의 문서 검색이 필요한 ‘Multi-hop’ 질문에 취약
- 유연성 부족: 질문의 성격에 관계없이 항상 똑같은 로직만 수행.
이번엔 여태까지 배웠던 Agent의 여러 개념을 통합하여 문서 검색을 통해 최신 정보에 접근하여 검색 결과를 가지고 답변을 생성하는 에이전트를 만들어 보도록 하겠습니다. 질문에 따라 문서를 검색하여 답변하거나, 인터넷 검색 도구를 활용하여 답변하는 에이전트를 만들어 보겠습니다.
실습 코드를 실행하기 위해 다음 라이브러리 설치부터 진행해 줍니다.
!pip install -U langchain langchain-core langchain-community langchain-text-splitters langchain-openai pypdf faiss-cpu langchain-teddynote
6.1 도구(Tools) 정의
6.1.1 웹 검색도구: Tavily Search
이번 Agentic RAG에서 검색에 사용할 도구로 이전에 알아보았던 Tavily Search를 사용할 예정입니다. 아래와 같이 정의해 줍니다.
# TavilySearchResults 클래스를 langchain_community.tools.tavily_search 모듈에서 가져옵니다.
from langchain_community.tools.tavily_search import TavilySearchResults
# TavilySearchResults 클래스의 인스턴스를 생성합니다.
search = TavilySearchResults(k=6)
6.1.2 문서 기반 검색 도구: Retriever
데이터에 대해 조회를 수행할 retriever도 생성합니다. 실습에 활용한 문서는 “소프트웨어정책연구소(SPRi) - 2023년 12월호” PDF 파일을 사용했습니다.
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
# PDF 파일 로드. 파일의 경로 입력
loader = PyPDFLoader("/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf")
# 텍스트 분할기를 사용하여 문서를 분할합니다.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100
)
# 문서를 로드하고 분할합니다.
split_docs = loader.load_and_split(text_splitter)
# VectorStore를 생성합니다.
vector = FAISS.from_documents(split_docs, OpenAIEmbeddings())
# Retriever를 생성합니다.
retriever = vector.as_retriever()
create_retriever_tool 함수로 retriever를 도구로 변환합니다.
from langchain_classic.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
name="pdf_search", # 도구의 이름을 입력합니다.
description="use this tool to search information from the PDF document", # 도구에 대한 설명을 자세히 기입해야 합니다.
)
6.1.3 Agent가 사용할 도구 목록 정의
이제 두 가지 도구를 만들었으므로, Agent가 사용할 도구 목록을 만들 수 있습니다. tools리스트는 search와 retriever_tool을 포함합니다.
# tools 리스트에 search와 retriever_tool을 추가합니다.
tools = [search, retriever_tool]
6.2 Agent 생성
이제 도구를 정의했으니 에이전트를 생성할 수 있습니다. 먼저, Agent가 활용할 LLM을 정의하고, Agent가 참고할 Prompt를 정의합니다.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# LLM 정의
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Prompt 정의
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. "
"Make sure to use the `pdf_search` tool for searching information from the PDF document. "
"If you can't find the information from the PDF document, use the `search` tool for searching information from the web.",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
다음으로는 Tool Calling Agent를 생성합니다.
from langchain_classic.agents import create_tool_calling_agent
# tool calling agent 생성
agent = create_tool_calling_agent(llm, tools, prompt)
마지막으로, 생성한 agent를 실행하는 AgentExecutor를 생성합니다.
from langchain_classic.agents import AgentExecutor
# AgentExecutor 생성
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=False)
6.3 에이전트 실행하기
이제 몇 가지 질의에 대해 에이전트를 실행할 수 있습니다.
from langchain_teddynote.messages import AgentStreamParser
# 각 단계별 출력을 위한 파서 생성
agent_stream_parser = AgentStreamParser()
# 질의에 대한 답변을 스트리밍으로 출력 요청
result = agent_executor.stream(
{"input": "2025년 프로야구 플레이오프 진출한 5개 팀을 검색하여 알려주세요."}
)
for step in result:
# 중간 단계를 parser를 사용하여 단계별로 출력
agent_stream_parser.process_agent_steps(step)
Output:
[도구 호출]
Tool: tavily_search_results_json
query: 2025년 프로야구 플레이오프 진출 팀
Log:
Invoking: `tavily_search_results_json` with `{'query': '2025년 프로야구 플레이오프 진출 팀'}`
[관찰 내용]
Observation: [{'title': '2025년 KBO 포스트시즌 - 위키백과, 우리 모두의 백과사전', 'url': 'https://ko.wikipedia.org/wiki/2025%EB%85%84_KBO_%ED%8F%AC%EC%8A%A4%ED%8A%B8%EC%8B%9C%EC%A6%8C', 'content': '위키백과\n\n## 목차\n\n# 2025년 KBO 포스트시즌\n\n2025 신한 SOL Bank KBO 포스트시즌은 2025년 10월 6일부터 10월 31일까지 진행됐다. 이번 포스트시즌부터 한국시리즈 방식이 2-2-3에서 2-3-2로 다시 회귀하면서 한국시리즈 5차전 장소는 플레이오프 승리팀의 홈구장인 대전한화생명볼파크에서 치러진다.\n\n## 진출팀\n\n2025년 포스트시즌에 진출한 팀은 LG 트윈스, 한화 이글스, SSG 랜더스, 삼성 라이온즈, NC 다이노스다.\n\n## 대진표\n\n| | | | | | | | | | | | | | | | | | | |\n --- --- --- --- --- --- --- --- --- \n| | 와일드카드 결정전 | | | | | 준플레이오프 | | | | | 플레이오프 | | | | | 한국시리즈 | | |\n| | | | | | | | | | | | | | | | | | | |\n| | | | | | | | | | | | | | | | | 1 | LG 트윈스 | 4 |\n| | | | | | | | | | | | 2 | 한화 이글스 | 3 | | | 2 | 한화 이글스 | 1 |\n| | | | | | | 3 | SSG 랜더스 | 1 | | | 4 | 삼성 라이온즈 | 2 | |\n| | 4 | 삼성 라이온즈 | 1 | | | 4 | 삼성 라이온즈 | 3 | |\n| | 5 | NC 다이노스 | 1 | |\n\n## 와일드카드 결정전\n\n### 출장자 명단 [...] ### 경기 기록\n\n2025 신한은행 SOL KBO 플레이오프\n\n| 일시 | 경기 | 원정팀(선공) | 스코어 | 홈팀(후공) | 개최 구장 | 개시 시각 | 관중수 | 경기 MVP |\n --- --- --- --- \n| 10월 18일(토) | 1차전 | 삼성 라이온즈 | 8 - 9 | 한화 이글스 | 대전한화생명볼파크 | 14시 00분 | 16,750명 (매진) | 문동주 "문동주 (야구 선수)") (한화 이글스) |\n| 10월 19일(일) | 2차전 | 삼성 라이온즈 | 7 - 3 | 한화 이글스 | 16,750명 (매진) | 최원태 (삼성 라이온즈) |\n| 10월 21일(화) | 3차전 | 한화 이글스 | 5 - 4 | 삼성 라이온즈 | 대구삼성라이온즈파크 | 18시 30분 | 23,680명 (매진) | 문동주 "문동주 (야구 선수)") (한화 이글스) |\n| 10월 22일(수) | 4차전 | 한화 이글스 | 4 - 7 | 삼성 라이온즈 | 23,680명 (매진) | 김영웅 "김영웅 (야구 선수)") (삼성 라이온즈) |\n| 10월 24일(금) | 5차전 | 삼성 라이온즈 | 2 - 11 | 한화 이글스 | 대전한화생명볼파크 | 16,750명 (매진) | 폰세 (한화 이글스) |\n| 승리팀 : 한화 이글스, 플레이오프 MVP : 문동주 "문동주 (야구 선수)") (한화 이글스) | | | | | | | | |\n\n### 1차전\n\n2025년 10월 18일 - 대전한화생명볼파크 [...] (야구 선수)")이 SSG의 9회초 공격을 삼자범퇴로 막아세우며 경기를 끝냈고 시리즈 최종 전적 3승 1패를 기록하면서 정규 시즌 4위 삼성이 정규 시즌 3위 SSG를 물리치고 플레이오프에 진출했다.', 'score': 0.8127637}, {'title': 'In charts: 7 global shifts defining 2025 so far | World
...중략...
[최종 답변]
2025년 프로야구 플레이오프에 진출한 팀은 다음과 같습니다:
1. LG 트윈스
2. 한화 이글스
3. SSG 랜더스
4. 삼성 라이온즈
5. NC 다이노스
자세한 내용은 [위키백과](https://ko.wikipedia.org/wiki/2025%EB%85%84_KBO_%ED%8F%AC%EC%8A%A4%ED%8A%B8%EC%8B%9C%EC%A6%8C)에서 확인하실 수 있습니다.
그럼 이제 pdf_search도구를 사용한 예제를 살펴보도록 하겠습니다.
# 질의에 대한 답변을 스트리밍으로 출력 요청
result = agent_executor.stream(
{"input": "삼성전자가 자체 개발한 생성형 AI 관련된 정보를 문서에서 찾아주세요."}
)
for step in result:
# 중간 단계를 parser 를 사용하여 단계별로 출력
agent_stream_parser.process_agent_steps(step)
Output:
[도구 호출]
Tool: pdf_search
query: 삼성전자 생성형 AI
Log:
Invoking: `pdf_search` with `{'query': '삼성전자 생성형 AI'}`
[관찰 내용]
Observation: SPRi AI Brief | 2023-12월호
10
삼성전자, 자체 개발 생성 AI ‘삼성 가우스’ 공개n삼성전자가 온디바이스에서 작동 가능하며 언어, 코드, 이미지의 3개 모델로 구성된 자체 개발 생성 AI 모델 ‘삼성 가우스’를 공개n삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획으로, 온디바이스 작동이 가능한 삼성 가우스는 외부로 사용자 정보가 유출될 위험이 없다는 장점을 보유
KEY Contents
KEY Contents
£언어, 코드, 이미지의 3개 모델로 구성된 삼성 가우스, 온디바이스 작동 지원n삼성전자가 2023년 11월 8일 열린 ‘삼성 AI 포럼 2023’ 행사에서 자체 개발한 생성 AI 모델 ‘삼성 가우스’를 최초 공개∙정규분포 이론을 정립한 천재 수학자 가우스(Gauss)의 이름을 본뜬 삼성 가우스는 다양한 상황에 최적화된 크기의 모델 선택이 가능∙삼성 가우스는 라이선스나 개인정보를 침해하지 않는 안전한 데이터를 통해 학습되었으며, 온디바이스에서 작동하도록 설계되어 외부로 사용자의 정보가 유출되지 않는 장점을 보유∙삼성전자는 삼성 가우스를 활용한 온디바이스 AI 기술도 소개했으며, 생성 AI 모델을 다양한 제품에 단계적으로 탑재할 계획n삼성 가우스는 △텍스트를 생성하는 언어모델 △코드를 생성하는 코드 모델 △이미지를 생성하는 이미지 모델의 3개 모델로 구성∙언어 모델은 클라우드와 온디바이스 대상 다양한 모델로 구성되며, 메일 작성, 문서 요약, 번역 업무의 처리를 지원∙코드 모델 기반의 AI 코딩 어시스턴트 ‘코드아이(code.i)’는 대화형 인터페이스로 서비스를 제공하며 사내 소프트웨어 개발에 최적화∙이미지 모델은 창의적인 이미지를 생성하고 기존 이미지를 원하는 대로 바꿀 수 있도록 지원하며 저해상도 이미지의 고해상도 전환도 지원nIT 전문지 테크리퍼블릭(TechRepublic)은 온디바이스 AI가 주요 기술 트렌드로 부상했다며, 2024년부터 가우스를 탑재한 삼성 스마트폰이 메타의 라마(Llama)2를 탑재한 퀄컴 기기 및 구글 어시스턴트를 적용한 구글 픽셀(Pixel)과 경쟁할 것으로 예상☞ 출처 : 삼성전자, ‘삼성 AI 포럼’서 자체 개발 생성형 AI ‘삼성 가우스’ 공개, 2023.11.08.삼성전자, ‘삼성 개발자 콘퍼런스 코리아 2023’ 개최, 2023.11.14.TechRepublic, Samsung Gauss: Samsung Research Reveals Generative AI, 2023.11.08.
사업계획과 발표 자료 작성, 제품 이미지 생성을 지원하며, 임원의 개인 비서와 같은 역할도 수행 ∙(엔터테인먼트·쇼핑) 쇼핑 시 에이전트가 모든 리뷰를 읽고 요약해 최적의 제품을 추천하고 사용자 대신 주문할 수 있으며 사용자의 관심사에 맞춤화된 뉴스와 엔터테인먼트를 구독 가능☞ 출처 : GatesNotes, AI is about to completely change how you use computers, 2023.11.09.
노래나 목소리를 모방한 AI 생성 음악에 대하여 삭제를 요청할 수 있는 기능도 도입할 방침☞ 출처 : Youtube, Our approach to responsible AI innovation, 2023.11.14.
[최종 답변]
삼성전자가 자체 개발한 생성형 AI 모델인 '삼성 가우스'에 대한 정보는 다음과 같습니다:
- **모델 구성**: 삼성 가우스는 언어, 코드, 이미지의 3개 모델로 구성되어 있습니다.
- **언어 모델**: 클라우드와 온디바이스에서 작동하며, 메일 작성, 문서 요약, 번역 등의 작업을 지원합니다.
- **코드 모델**: AI 코딩 어시스턴트 '코드아이(code.i)'를 통해 대화형 인터페이스로 서비스를 제공하며, 사내 소프트웨어 개발에 최적화되어 있습니다.
- **이미지 모델**: 창의적인 이미지를 생성하고 기존 이미지를 수정할 수 있으며, 저해상도 이미지를 고해상도로 변환하는 기능도 지원합니다.
- **온디바이스 작동**: 삼성 가우스는 온디바이스에서 작동하도록 설계되어 있어, 사용자 정보가 외부로 유출될 위험이 없습니다. 이는 안전한 데이터 학습을 통해 이루어졌습니다.
- **제품 탑재 계획**: 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획을 가지고 있습니다.
- **기술 트렌드**: IT 전문지에 따르면, 온디바이스 AI가 주요 기술 트렌드로 부상하고 있으며, 2024년부터 삼성 가우스를 탑재한 스마트폰이 다른 경쟁 제품들과 경쟁할 것으로 예상됩니다.
이 정보는 2023년 11월 8일 열린 '삼성 AI 포럼 2023'에서 공개된 내용입니다.
6.4 이전 대화내용을 기억하는 Agent
이전의 대화내용을 기억하기 위해서는 RunnableWithMessageHistory를 사용하여 AgentExecutor를 감싸줍니다.
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# session_id를 저장할 딕셔너리 생성
store = {}
# session_id 를 기반으로 세션 기록을 가져오는 함수
def get_session_history(session_ids):
if session_ids not in store: # session_id 가 store에 없는 경우
# 새로운 ChatMessageHistory 객체를 생성하여 store에 저장
store[session_ids] = ChatMessageHistory()
return store[session_ids] # 해당 세션 ID에 대한 세션 기록 반환
# 채팅 메시지 기록이 추가된 에이전트를 생성합니다.
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
# 대화 session_id
get_session_history,
# 프롬프트의 질문이 입력되는 key: "input"
input_messages_key = "input",
# 프롬프트의 메시지가 입력되는 key: "chat_history"
history_messages_key="chat_history",
)
Output:
...생략...
[최종 답변]
삼성전자가 개발한 생성형 AI에 대한 정보는 다음과 같습니다:
- **모델 이름**: 삼성 가우스(Samsung Gauss)
- **발표일**: 2023년 11월 8일, 삼성 AI 포럼 2023에서 최초 공개
- **구성**: 삼성 가우스는 언어, 코드, 이미지의 3개 모델로 구성되어 있습니다.
- **언어 모델**: 메일 작성, 문서 요약, 번역 업무 지원
- **코드 모델**: AI 코딩 어시스턴트 '코드아이(code.i)'를 통해 대화형 인터페이스로 서비스 제공
- **이미지 모델**: 창의적인 이미지 생성 및 기존 이미지의 변형, 저해상도 이미지를 고해상도로 전환하는 기능 지원
- **온디바이스 작동**: 삼성 가우스는 온디바이스에서 작동하도록 설계되어 있어 사용자 정보가 외부로 유출될 위험이 없습니다.
- **안전한 데이터 학습**: 라이선스나 개인정보를 침해하지 않는 안전한 데이터를 통해 학습되었습니다.
- **제품 탑재 계획**: 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획입니다.
삼성 가우스는 IT 전문지 테크리퍼블릭에 따르면, 2024년부터 삼성 스마트폰에 탑재되어 메타의 라마(Llama)2를 탑재한 퀄컴 기기 및 구글 어시스턴트를 적용한 구글 픽셀(Pixel)과 경쟁할 것으로 예상됩니다.
response = agent_with_chat_history.stream(
{"input": "이전의 답변을 영어로 번역해 주세요."},
# session_id 설정
config={"configurable": {"session_id": "abc123"}},
)
# 출력 확인
for step in response:
agent_stream_parser.process_agent_steps(step)
이전의 답변을 기억해 영어로 번역해 주는 것을 확인할 수 있습니다.
Output:
[최종 답변]
Here is the translation of the previous response into English:
- **Model Name**: Samsung Gauss
- **Announcement Date**: First unveiled on November 8, 2023, at the Samsung AI Forum 2023
- **Composition**: Samsung Gauss consists of three models: language, code, and image.
- **Language Model**: Supports tasks such as email writing, document summarization, and translation.
- **Code Model**: Provides a coding assistant called 'code.i' through an interactive interface.
- **Image Model**: Supports creative image generation, modification of existing images, and enhancement of low-resolution images to high resolution.
- **On-Device Operation**: Samsung Gauss is designed to operate on-device, minimizing the risk of user information being leaked externally.
- **Safe Data Learning**: It has been trained on safe data that does not infringe on licenses or personal information.
- **Product Integration Plans**: Samsung plans to gradually integrate Samsung Gauss into various products.
According to the IT news outlet TechRepublic, Samsung Gauss is expected to be integrated into Samsung smartphones starting in 2024, competing with Qualcomm devices equipped with Meta's Llama 2 and Google Pixel devices that utilize Google Assistant.
7. CSV/Excel 데이터 분석 Agent
CSV 혹은 Excel 파일을 분석하는 Agent를 한 번 만들어보도록 하겠습니다. 여기서 Pandas DataFrame을 활용하여 분석을 수행하는 Agent를 생성할 수 있습니다.
CSV/Excel 데이터로부터 Pandas DataFrame 객체를 생성할 수 있으며, 이를 활용하여 Agent가 Pandas query를 생성하여 분석을 수행할 수 있습니다.
이번 CSV/Excel 데이터 분석 Agent에 사용할 데이터는 이전 타이타닉에 탔었던 승객의 정보가 있는 CSV 파일을 사용합니다.
우선 실습 코드 실행 전에 실행에 필요한 라이브러리 설치부터 진행해 줍니다.
!pip install -U langchain langchain-core langchain-experimental langchain-classic langchain-openai langchain-teddynote
Pandas를 이용해 CSV 파일을 읽어옵니다.
import pandas as pd
df = pd.read_csv("/content/drive/MyDrive/LangChain/titanic.csv") # csv 파일을 읽습니다.
df.head()
Agent와 AgentStreamParser를 정의해 줍니다.
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain_classic.agents.agent_types import AgentType
from langchain_openai import ChatOpenAI
from langchain_teddynote.messages import AgentStreamParser
import seaborn as sns
sns.set_style("white")
agent = create_pandas_dataframe_agent(
ChatOpenAI(model="gpt-4o-mini", temperature=0),
df,
verbose=False,
agent_type = AgentType.OPENAI_FUNCTIONS,
allow_dangerous_code=True,
)
stream_parser = AgentStreamParser()
Agent를 이용해 답변을 출력하도록 하는 메서드를 정의합니다.
def ask(query):
# 질의에 대한 답변을 출력합니다.
response = agent.stream({"input": query})
for step in response:
stream_parser.process_agent_steps(step)
ask("몇 개의 행이 있어?")
Output:
[도구 호출]
Tool: python_repl_ast
query: len(df)
Log:
Invoking: `python_repl_ast` with `{'query': 'len(df)'}`
[관찰 내용]
Observation: 891
[최종 답변]
데이터프레임 `df`에는 총 891개의 행이 있습니다.
ask("남자와 여자의 생존율의 차이는 몇이야?")
Output:
[도구 호출]
Tool: python_repl_ast
query: male_survival_rate = df[df['Sex'] == 'male']['Survived'].mean()
female_survival_rate = df[df['Sex'] == 'female']['Survived'].mean()
survival_rate_difference = female_survival_rate - male_survival_rate
survival_rate_difference
Log:
Invoking: `python_repl_ast` with `{'query': "male_survival_rate = df[df['Sex'] == 'male']['Survived'].mean()\nfemale_survival_rate = df[df['Sex'] == 'female']['Survived'].mean()\nsurvival_rate_difference = female_survival_rate - male_survival_rate\nsurvival_rate_difference"}`
[관찰 내용]
Observation: 0.5531300709799203
[최종 답변]
남자와 여자의 생존율의 차이는 약 0.55입니다. 즉, 여자의 생존율이 남자보다 약 55.3% 더 높습니다.
ask("남자 승객과 여자 승객의 생존율을 구한뒤 barplot 차트로 시각화 해줘")
Output:
[도구 호출]
Tool: python_repl_ast
query: import pandas as pd
import matplotlib.pyplot as plt
# 남자와 여자 승객의 생존율 계산
survival_rate = df.groupby('Sex')['Survived'].mean()
# barplot 시각화
survival_rate.plot(kind='bar', color=['blue', 'pink'])
plt.title('Survival Rate by Gender')
plt.xlabel('Gender')
plt.ylabel('Survival Rate')
plt.xticks(rotation=0)
plt.show()
Log:
Invoking: `python_repl_ast` with `{'query': "import pandas as pd\nimport matplotlib.pyplot as plt\n\n# 남자와 여자 승객의 생존율 계산\nsurvival_rate = df.groupby('Sex')['Survived'].mean()\n\n# barplot 시각화\nsurvival_rate.plot(kind='bar', color=['blue', 'pink'])\nplt.title('Survival Rate by Gender')\nplt.xlabel('Gender')\nplt.ylabel('Survival Rate')\nplt.xticks(rotation=0)\nplt.show()"}`
[관찰 내용]
Observation:
[최종 답변]
남자 승객과 여자 승객의 생존율을 계산한 후, 바 차트로 시각화한 결과를 확인할 수 있습니다. 차트는 남성과 여성의 생존율을 비교하여 보여줍니다.
8. RAG + Image Generator Agent를 이용한 보고서 작성
이제 여태까지 배운 내용을 토대로 Agent의 전체적인 튜토리얼을 진행해 보고자 합니다. 이번 튜토리얼에서는 웹 검색(Web Search), PDF 문서 기반 검색(RAG), 이미지 생성(Image Generation) 등을 통해 보고서를 작성하는 에이전트를 만들어 보도록 하겠습니다.
그럼 실습 코드 실행에 필요한 라이브러리 설치부터 진행해 주시길 바랍니다.
!pip install -U langchain-community langchain langchain-core langchain-text-splitters langchain-openai pypdf faiss-cpu pymupdf langchain-teddynote
8.1 도구 정의
8.1.1 웹 검색도구 정의: Tavily Search
from langchain_community.tools.tavily_search import TavilySearchResults
# TavilySearchResults 클래스의 인스턴스를 생성합니다.
search = TavilySearchResults(k=6)
8.1.2 문서 기반 문서 검색도구
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 100
)
split_docs = loader.load_and_split(text_splitter)
vector = FAISS.from_documents(split_docs, OpenAIEmbeddings())
retriever = vector.as_retriever()
retriever를 도구로 정의합니다. document_prompt는 문서의 내용을 표시하는 템플릿을 정의합니다.
기본 값은 문서의 page_content만 표기합니다. 따라서, 나중에 문서의 페이지 번호나 출처등을 표시하기 위해서는 템플릿을 따로 정의해야 합니다.
from langchain_classic.tools.retriever import create_retriever_tool
from langchain_core.prompts import PromptTemplate
# 문서의 내용을 표시하는 템플릿을 정의합니다.
document_prompt = PromptTemplate.from_template(
"<document><content>{page_content}</content><page>{page}</page><filename>{source}</filename></document>"
)
# retriever를 도구로 정의합니다.
retriever_tool = create_retriever_tool(
retriever,
name="pdf_search",
description="use this tool to search for information in the PDF file",
document_prompt=document_prompt,
)
8.1.3 DallE 이미지 생성 도구
from langchain_community.utilities.dalle_image_generator import DallEAPIWrapper
from langchain.tools import tool
# DallE API Wrapper를 생성합니다.
dalle = DallEAPIWrapper(model="dall-e-3", size="1024x1024", quality="standard", n=1)
# DallE API Wrapper를 도구로 정의합니다.
@tool
def dalle_tool(query):
"""use this tool to generator image from text"""
return dalle.run(query)
8.1.4 파일 관리 도구
파일 관리 도구들
CopyFileTool: 파일 복사DeleteFileTool: 파일 삭제FileSearchTool: 파일 검색MoveFileTool: 파일 이동ReadFileTool: 파일 읽기WriteFileTool: 파일 쓰기ListDirectoryTool: 디렉토리 목록 조회
from langchain_community.agent_toolkits import FileManagementToolkit
# 작업 디렉토리 경로 설정
working_directory = "/content/drive/MyDrive/LangChain/tmp"
# 파일 관리 도구 생성(파일 쓰기, 읽기, 디렉토리 목록 조회)
file_tools = FileManagementToolkit(
root_dir = str(working_directory),
selected_tools = ["write_file", "read_file", "list_directory"],
).get_tools()
# 생성된 파일 관리 도구 출력
file_tools
Output:
[WriteFileTool(root_dir='/content/drive/MyDrive/LangChain/tmp'),
ReadFileTool(root_dir='/content/drive/MyDrive/LangChain/tmp'),
ListDirectoryTool(root_dir='/content/drive/MyDrive/LangChain/tmp')]
여기까지 했다면 모든 도구를 종합합니다.
tools = file_tools + [
retriever_tool, search, dalle_tool,
]
# 최종 도구 목록 출력
tools
Output:
[WriteFileTool(root_dir='/content/drive/MyDrive/LangChain/tmp'),
ReadFileTool(root_dir='/content/drive/MyDrive/LangChain/tmp'),
ListDirectoryTool(root_dir='/content/drive/MyDrive/LangChain/tmp'),
StructuredTool(name='pdf_search', description='use this tool to search for information in the PDF file', args_schema=<class 'langchain_core.tools.retriever.RetrieverInput'>, func=<function create_retriever_tool.<locals>.func at 0x786698f80cc0>, coroutine=<function create_retriever_tool.<locals>.afunc at 0x786698f80b80>),
TavilySearchResults(api_wrapper=TavilySearchAPIWrapper(tavily_api_key=SecretStr('**********'))),
StructuredTool(name='dalle_tool', description='use this tool to generator image from text', args_schema=<class 'langchain_core.utils.pydantic.dalle_tool'>, func=<function dalle_tool at 0x786698e88cc0>)]
8.2 Agent 생성
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_classic.agents import create_tool_calling_agent, AgentExecutor
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_openai import ChatOpenAI
from langchain_teddynote.messages import AgentStreamParser
# session_id를 저장할 딕셔너리 생성
store = {}
# 프롬프트 생성
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant."
"You are a professional researcher."
"You can use the pdf_search tool to search for information in the PDF file."
"You can find further information by using search tool."
"You can use image generation tool to generate image from text."
"Finally, you can use file management tool to save your research result into files."
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
# LLM 생성
llm = ChatOpenAI(model="gpt-4o-mini")
# Agent 생성
agent = create_tool_calling_agent(llm, tools, prompt)
# AgentExecutor 생성
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=False,
handle_parsing_errors=True,
)
# session_id 를 기반으로 세션 기록을 가져오는 함수
def get_session_history(session_ids):
if session_ids not in store: # session_id 가 store에 없는 경우
# 새로운 ChatMessageHistory 객체를 생성하여 store에 저장
store[session_ids] = ChatMessageHistory()
return store[session_ids] # 해당 세션 ID에 대한 세션 기록 반환
# 채팅 메시지 기록이 추가된 에이전트를 생성
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
# 스트림 파서 생성
agent_stream_parser = AgentStreamParser()
만든 에이전트를 실행해 보도록 하겠습니다. 우선 PDF 문서에서 원하는 내용을 찾아 Markdown 형식의 보고서를 만들어 보도록 하겠습니다.
# 에이전트 실행
result = agent_with_chat_history.stream(
{
"input": "삼성전자가 개발한 '생성형 AI'와 관련된 유용한 정보들을 PDF 문서에서 찾아 bullet point로 정리해 주세요."
"한글로 작성해 주세요."
"다음으로는 'report.md' 파일을 새롭게 생성하여 정리한 내용을 저장해주세요. \n\n"
"#작성방법: \n"
"1. markdown header 2 크기로 적절한 제목을 작성하세요. \n"
"2. 발췌한 PDF 문서의 페이지 번호, 파일명을 기입하세요(예시: page 10, filename.pdf). \n"
"3. 정리된 bullet point를 작성하세요. \n"
"4. 작성이 완료되면 파일을 'report.md'에 저장하세요. \n"
"5. 마지막으로 저장한 'report.md' 파일을 읽어서 출력해 주세요. \n"
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)
Output:
Agent 실행 결과:
[도구 호출]
Tool: pdf_search
query: 삼성전자 생성형 AI
Log:
Invoking: `pdf_search` with `{'query': '삼성전자 생성형 AI'}`
[관찰 내용]
Observation: <document><content>SPRi AI Brief |
2023-12월호
10
삼성전자, 자체 개발 생성 AI ‘삼성 가우스’ 공개
n 삼성전자가 온디바이스에서 작동 가능하며 언어, 코드, 이미지의 3개 모델로 구성된 자체 개발 생성
AI 모델 ‘삼성 가우스’를 공개
n 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획으로, 온디바이스 작동이 가능한
삼성 가우스는 외부로 사용자 정보가 유출될 위험이 없다는 장점을 보유
KEY Contents
£ 언어, 코드, 이미지의 3개 모델로 구성된 삼성 가우스, 온디바이스 작동 지원
n 삼성전자가 2023년 11월 8일 열린 ‘삼성 AI 포럼 2023’ 행사에서 자체 개발한 생성 AI 모델
‘삼성 가우스’를 최초 공개
∙정규분포 이론을 정립한 천재 수학자 가우스(Gauss)의 이름을 본뜬 삼성 가우스는 다양한 상황에
최적화된 크기의 모델 선택이 가능
∙삼성 가우스는 라이선스나 개인정보를 침해하지 않는 안전한 데이터를 통해 학습되었으며,
온디바이스에서 작동하도록 설계되어 외부로 사용자의 정보가 유출되지 않는 장점을 보유
∙삼성전자는 삼성 가우스를 활용한 온디바이스 AI 기술도 소개했으며, 생성 AI 모델을 다양한 제품에
단계적으로 탑재할 계획
n 삼성 가우스는 △텍스트를 생성하는 언어모델 △코드를 생성하는 코드 모델 △이미지를 생성하는
이미지 모델의 3개 모델로 구성
∙언어 모델은 클라우드와 온디바이스 대상 다양한 모델로 구성되며, 메일 작성, 문서 요약, 번역 업무의
처리를 지원
∙코드 모델 기반의 AI 코딩 어시스턴트 ‘코드아이(code.i)’는 대화형 인터페이스로 서비스를 제공하며
사내 소프트웨어 개발에 최적화
∙이미지 모델은 창의적인 이미지를 생성하고 기존 이미지를 원하는 대로 바꿀 수 있도록 지원하며
저해상도 이미지의 고해상도 전환도 지원
n IT 전문지 테크리퍼블릭(TechRepublic)은 온디바이스 AI가 주요 기술 트렌드로 부상했다며,</content><page>12</page><filename>/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf</filename></document>
<document><content>저해상도 이미지의 고해상도 전환도 지원
n IT 전문지 테크리퍼블릭(TechRepublic)은 온디바이스 AI가 주요 기술 트렌드로 부상했다며,
2024년부터 가우스를 탑재한 삼성 스마트폰이 메타의 라마(Llama)2를 탑재한 퀄컴 기기 및 구글
어시스턴트를 적용한 구글 픽셀(Pixel)과 경쟁할 것으로 예상
☞ 출처 : 삼성전자, ‘삼성 AI 포럼’서 자체 개발 생성형 AI ‘삼성 가우스’ 공개, 2023.11.08.
삼성전자, ‘삼성 개발자 콘퍼런스 코리아 2023’ 개최, 2023.11.14.
TechRepublic, Samsung Gauss: Samsung Research Reveals Generative AI, 2023.11.08.</content><page>12</page><filename>/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf</filename></document>
<document><content>SPRi AI Brief |
2023-12월호
4
미국 법원, 예술가들이 생성 AI 기업에 제기한 저작권 소송 기각
n 미국 캘리포니아 북부지방법원은 미드저니, 스태빌리티AI, 디비언트아트를 대상으로 예술가
3인이 제기한 저작권 침해 소송을 기각
n 법원은 기각 이유로 고소장에 제시된 상당수 작품이 저작권청에 등록되지 않았으며, AI로
생성된 이미지와 특정 작품 간 유사성을 입증하기 어렵다는 점을 제시
KEY Contents
£ 예술가들의 AI 저작권 침해 소송, 저작권 미등록과 증거불충분으로 기각
n 미국 캘리포니아 북부지방법원의 윌리엄 오릭(William Orrick) 판사는 2023년 10월 30일 미드저니
(Midjourney), 스태빌리티AI(Stability AI), 디비언트아트(DeviantArt)에 제기된 저작권 침해 소송을 기각
∙2023년 1월 예술가 사라 앤더슨(Sarah Anderson), 캘리 맥커넌(Kelly McKernan), 칼라
오르티즈(Karla Ortiz)는 이미지 생성 AI 서비스를 개발한 3개 기업을 상대로 저작권 침해 소송을 제기
∙예술가들은 3개 기업이 AI 모델을 학습시키기 위해 원작자 동의 없이 작품을 학습 데이터셋에
포함하여 저작권을 침해했다고 주장했으며, 법원은 지난 4월 피소 기업들이 제출한 기각 신청을
수용해 소송을 기각
n 오릭 판사는 판결문에서 소송을 기각한 핵심 이유로 예술가들의 저작권 미등록을 제시
∙판결문은 소송을 제기한 캘리 맥커넌과 칼라 오르티즈가 미국 저작권청에 예술 작품에 대한 저작권을
제출하지 않았다는 점을 지적했으며, 사라 앤더슨은 고소장에 인용된 수백 개의 작품 중 16개 작품에
대해서만 저작권을 보유
n 판결문은 또한 생성 AI 모델 훈련에 사용된 모든 이미지에 저작권이 있다거나, 생성 AI로 만든
이미지가 저작물을 이용해 훈련되었으므로 저작물의 파생 이미지라는 주장은 개연성이 부족하다고
지적</content><page>6</page><filename>/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf</filename></document>
<document><content><AI 기술 유형 평균 기술 대비 갖는 임금 프리미엄></content><page>20</page><filename>/content/drive/MyDrive/LangChain/pdf_data/SPRI_AI_Brief_2023년12월호_F.pdf</filename></document>
[도구 호출]
Tool: write_file
file_path: report.md
text: ## 삼성전자 생성형 AI '삼성 가우스' 관련 정보
- 발췌한 PDF 문서: page 10, filename: SPRI_AI_Brief_2023년12월호_F.pdf
- 삼성전자가 개발한 생성형 AI '삼성 가우스'는 온디바이스에서 작동 가능하며, 언어, 코드, 이미지의 3개 모델로 구성됨.
- 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획이며, 사용자의 정보 유출 위험이 없는 점이 장점임.
- '삼성 가우스'는 자체 안전한 데이터로 학습되었으며, 정규분포 이론을 정립한 수학자 가우스의 이름을 본뜸.
- 언어 모델은 메일 작성, 문서 요약, 번역 업무를 지원하며, 클라우드와 온디바이스에서 사용할 수 있음.
- 코드 생성 모델인 '코드아이'는 대화형 인터페이스로 제공되어 사내 소프트웨어 개발에 최적화됨.
- 이미지 모델은 창의적인 이미지 생성 및 저해상도 이미지를 고해상도로 전환하는 기능을 지원함.
- IT 전문지에 따르면, 온디바이스 AI 기술이 중요한 트렌드로 부상하고 있으며, 삼성 스마트폰은 경쟁력을 강화할 것으로 예상됨.
Log:
Invoking: `write_file` with `{'file_path': 'report.md', 'text': "## 삼성전자 생성형 AI '삼성 가우스' 관련 정보\n\n- 발췌한 PDF 문서: page 10, filename: SPRI_AI_Brief_2023년12월호_F.pdf\n- 삼성전자가 개발한 생성형 AI '삼성 가우스'는 온디바이스에서 작동 가능하며, 언어, 코드, 이미지의 3개 모델로 구성됨.\n- 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획이며, 사용자의 정보 유출 위험이 없는 점이 장점임.\n- '삼성 가우스'는 자체 안전한 데이터로 학습되었으며, 정규분포 이론을 정립한 수학자 가우스의 이름을 본뜸.\n- 언어 모델은 메일 작성, 문서 요약, 번역 업무를 지원하며, 클라우드와 온디바이스에서 사용할 수 있음.\n- 코드 생성 모델인 '코드아이'는 대화형 인터페이스로 제공되어 사내 소프트웨어 개발에 최적화됨.\n- 이미지 모델은 창의적인 이미지 생성 및 저해상도 이미지를 고해상도로 전환하는 기능을 지원함.\n- IT 전문지에 따르면, 온디바이스 AI 기술이 중요한 트렌드로 부상하고 있으며, 삼성 스마트폰은 경쟁력을 강화할 것으로 예상됨."}`
[관찰 내용]
Observation: File written successfully to report.md.
[도구 호출]
Tool: read_file
file_path: report.md
Log:
Invoking: `read_file` with `{'file_path': 'report.md'}`
[관찰 내용]
Observation: ## 삼성전자 생성형 AI '삼성 가우스' 관련 정보
- 발췌한 PDF 문서: page 10, filename: SPRI_AI_Brief_2023년12월호_F.pdf
- 삼성전자가 개발한 생성형 AI '삼성 가우스'는 온디바이스에서 작동 가능하며, 언어, 코드, 이미지의 3개 모델로 구성됨.
- 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획이며, 사용자의 정보 유출 위험이 없는 점이 장점임.
- '삼성 가우스'는 자체 안전한 데이터로 학습되었으며, 정규분포 이론을 정립한 수학자 가우스의 이름을 본뜸.
- 언어 모델은 메일 작성, 문서 요약, 번역 업무를 지원하며, 클라우드와 온디바이스에서 사용할 수 있음.
- 코드 생성 모델인 '코드아이'는 대화형 인터페이스로 제공되어 사내 소프트웨어 개발에 최적화됨.
- 이미지 모델은 창의적인 이미지 생성 및 저해상도 이미지를 고해상도로 전환하는 기능을 지원함.
- IT 전문지에 따르면, 온디바이스 AI 기술이 중요한 트렌드로 부상하고 있으며, 삼성 스마트폰은 경쟁력을 강화할 것으로 예상됨.
[최종 답변]
다음은 '삼성전자 생성형 AI'에 대한 정보를 정리한 내용입니다:
## 삼성전자 생성형 AI '삼성 가우스' 관련 정보
- 발췌한 PDF 문서: page 10, filename: SPRI_AI_Brief_2023년12월호_F.pdf
- 삼성전자가 개발한 생성형 AI '삼성 가우스'는 온디바이스에서 작동 가능하며, 언어, 코드, 이미지의 3개 모델로 구성됨.
- 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획이며, 사용자의 정보 유출 위험이 없는 점이 장점임.
- '삼성 가우스'는 자체 안전한 데이터로 학습되었으며, 정규분포 이론을 정립한 수학자 가우스의 이름을 본뜸.
- 언어 모델은 메일 작성, 문서 요약, 번역 업무를 지원하며, 클라우드와 온디바이스에서 사용할 수 있음.
- 코드 생성 모델인 '코드아이'는 대화형 인터페이스로 제공되어 사내 소프트웨어 개발에 최적화됨.
- 이미지 모델은 창의적인 이미지 생성 및 저해상도 이미지를 고해상도로 전환하는 기능을 지원함.
- IT 전문지에 따르면, 온디바이스 AI 기술이 중요한 트렌드로 부상하고 있으며, 삼성 스마트폰은 경쟁력을 강화할 것으로 예상됨.
이 내용은 'report.md' 파일에 저장되었습니다. 추가로 궁금한 점이 있으면 말씀해 주세요!
생성된 보고서 파일(report.md)의 내용을 확인하면 다음과 같습니다.

다음으로는 웹 검색을 통해 보고서 파일을 업데이트 해보도록 하겠습니다.
# 웹 검색을 통해 보고서 파일 업데이트
result = agent_with_chat_history.stream(
{
"input": "이번에는 삼성전자가 개발한 '생성형 AI'와 관련된 정보들을 웹 검색하고, 검색한 결과를 정리해 주세요."
"한글로 작성해 주세요."
"다음으로는 'report.md' 파일을 열어서 기존의 내용을 읽고, 웹 검색하여 찾은 정보를 이전에 작성한 형식에 맞춰 뒷 부분에 추가해 주세요. \n\n"
"#작성방법: \n"
"1. markdown header 2 크기로 적절한 제목을 작성하세요. \n"
"2. 정보의 출처(url)을 기입하세요(예시: 출처: 네이버 지식백과). \n"
"3. 정리된 웹검색 내용을 작성하세요.\n"
"4. 작성이 완료되면 파일을 'report.md'에 저장하세요. \n"
"5. 마지막으로 저장한 'report.md' 파일을 읽어서 출력해 주세요. \n"
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)
Output:
Agent 실행 결과:
[도구 호출]
Tool: tavily_search_results_json
query: 삼성전자 생성형 AI
Log:
Invoking: `tavily_search_results_json` with `{'query': '삼성전자 생성형 AI'}`
[관찰 내용]
Observation: [{'title': '[단독] 삼성전자, AI 폐쇄 전략 접는다… 외부 AI 적극 도입', 'url': 'https://www.finance-scope.com/article/view/scp202502070005', 'content': '다만 최근 초거대 AI 경쟁에서 글로벌 빅테크 기업들이 엄청난 규모의 투자와 기술 노하우를 앞세워 시장을 선점하고 있는 상황에서, ‘가우스’에 추가로 대규모 투자를 하더라도 빠른 시일 내 성과를 내기 어렵다는 판단이 작용한 것으로 보인다. \n \n삼성전자 관계자는 "삼성전자는 생산성 향상을 위해 자체 생성형 AI를 활용 중"이라며 "외부 생성형 AI를 포함한 AI 활용 고도화 방안도 검토중"이라고 말했다. \n \n샘 올트먼과의 회동 이후, 이 회장의 경영 철학이 내부 폐쇄성보다는 개방적 협업으로 전환됐다는 평가가 많다. 향후 삼성전자는 스마트폰·가전·네트워크 장비 등 영역에서도 외부와의 협업을 넓혀, 소비자들에게 보다 혁신적인 AI 기능을 빠르게 제공할 수 있을 것으로 기대된다. [...] 삼성전자가 사내망에서만 활용해온 자체 AI 플랫폼 ‘가우스(GAUSS)’와 함께 외부 AI를 도입·활용하라는 지시를 내렸다. \n \n보안 문제 등으로 삼성 내부에서는 그간 외부 AI 사용이 제한적이었으나, 이번 이재용 회장의 결정으로 삼성전자의 AI 전략이 대대적으로 전환될 것으로 전망된다. \n \n \n \n7일 IT업계에 따르면 이재용 회장이 지난 5일 오픈AI CEO 샘 올트먼(Sam Altman)을 만난 이후, 외부 AI 활용에 대한 회장의 시각이 크게 달라졌으며 삼성전자 경영진은 반도체 사업부(DS)에서 외부 AI를 우선 도입하라는 지시를 내렸다. \n \n삼성전자는 반도체 사업부를 시작으로 외부AI를 활용해 제조·개발 공정을 혁신하고, 이후 전 부서로 확대 적용할 방침이다. \n \n방향성은 외부 AI 솔루션을 활용해 실시간 공정 모니터링, 결함 예측, 수율(yield) 개선 등이 주요 목적이다. \n \n특히 기계학습·딥러닝 알고리즘을 장비 센서 데이터 분석에 적용해 고장 전 예지보전을 강화함으로써 불량률과 다운타임을 줄일 수 있다. \n \n또한 글로벌 공급망 변동성이 커진 상황에서, 외부 AI 시스템을 통한 수요 예측·재고 관리 능력 향상이 기대된다. \n \n삼성전자 리서치센터가 자체 개발해온 ‘가우스’ 프로젝트 투자는 우선 순위에서 밀린 것으로 파악된다. 가우스는 내부용 AI 플랫폼으로, 보안을 중시하는 삼성전자 특성에 맞춰 발전해왔다.', 'score': 0.99973255}, {'title': 'Galaxy AI - 나무위키', 'url': 'https://namu.wiki/w/Galaxy%20AI', 'content': "삼성 갤럭시에 온보딩되어 있는 생성형 AI 세트로 온디바이스 생성형 AI와 클라우드 생성형 AI의 조화를 이루는 하이브리드 생성형 AI 세트이다. 삼성 갤럭시에 있는 초거대 AI 모델을 프로세서로 돌리는 온디바이스 생성형 AI부터, 삼성 클라우드에서 초거대 AI 모델을 호출하는 클라우드 생성형 AI가 모두 모여 있는 멀티모달 모델의 세트이다. \n \n2024년 1월 17일 삼성 갤럭시 언팩 2024에서 갤럭시 S24 시리즈 와 함께 공개되었다. \n \n삼성 갤럭시에 삼성전자가 자체 개발한 삼성 가우스의 생성형 AI와, 파트너의 생성형 AI로 구현되는 여러 생성형 AI들을 삼성 갤럭시의 One UI와 삼성전자의 앱에서 쓸 수 있게 하는 멀티 생성형 AI 경험을 누릴 수 있다. \n \n삼성전자는 이러한 Galaxy AI의 뛰어난 머신러닝 기술로 Galaxy에서 여러 기능을 활용할 수 있다고 안내하고 있다. \n \nGalaxy AI와 같이 초거대 생성형 AI 모델이 임베디드로 온보딩 되어 있는 디바이스는 AI 컴퓨팅을 디바이스 안에서 온디바이스로 스스로 해낸다. 이러한 제품의 타입은 AI 제품으로 분류된다. Galaxy AI가 온보딩 되어 있는 삼성 갤럭시는 AI 폰, AI 노트북, AI PC 등 AI 카테고리의 제품으로 부른다. [...] ### 2.2. 인텔리전스 UX(/edit/Galaxy%20AI?section=6)\n\n삼성전자는 Galaxy AI의 생성형 AI를 쓰는 삼성 갤럭시 유저의 경험을 '인텔리전스 UX'로 정의하고 있다. \n \n삼성전자는 생성형 AI가 널리 알려진 2023년보다 앞서 생성형 AI 경험을 삼성 갤럭시 유저에게 어떻게 줄 것인가에 대한 연구를 하고 있었다. 이 연구를 거쳐서 삼성전자는 자주 쓰는 앱의 파트를 재해석해서 '각 앱에 특화된 방식으로 AI 기술을 적용하는 방향'이라는 콘셉트를 잡아 인텔리전스 UX를 만들어냈다. \n \n인텔리전스 UX의 목표는 '내가 자주 쓰는 앱부터 차근차근 경험해 보며 AI 진입 장벽을 낮추는 것.'이다.#\n\n### 2.3. 앰비언트 AI(/edit/Galaxy%20AI?section=7)\n\n### 2.4. Bixby로 Galaxy AI 쓰기(/edit/Galaxy%20AI?section=8)\n\n삼성전자의 AI인 Bixby로 Galaxy AI를 쓸 수 있다. \n \nBixby에게 말로 시키면 Galaxy AI를 켜는 Bixby의 캡슐이 Galaxy AI를 켠다.\n\n## 3. 생성형 AI 모델(/edit/Galaxy%20AI?section=9) [...] ## 3. 생성형 AI 모델(/edit/Galaxy%20AI?section=9)\n\nGalaxy AI에는 여러 가지의 생성형 AI 모델들이 쓰인다. \n \n생성형 AI는 Galaxy AI를 이루는 프레임워크이다. Galaxy AI가 들어간 앱에서 Galaxy AI를 쓸 때 만들어진 프롬프트가 생성형 AI로 보내진다. Galaxy AI를 이루는 생성형 AI가 프롬프트를 받아 만들어낸 AIGC가 다시 유저에게 보내지며 유저는 Galaxy AI를 쓸 수 있게 된다. \n \nGalaxy AI의 생성형 AI 모델들은 크게 네 가지의 타입으로 나눌 수 있다.\n\n 삼성 가우스의 온디바이스 생성형 AI 모델\n 삼성 가우스의 클라우드 생성형 AI 모델\n ProVisual Engine\n 파트너의 클라우드 생성형 AI 모델\n\n보다 디테일한 생성형 AI 모델의 리스트는 다음과 같다.\n\n### 3.1. 삼성 가우스(/edit/Galaxy%20AI?section=10)\n\n자세한 내용은 삼성 가우스 문서를 참고하십시오.\n\n#### 3.1.1. Samsung Intelligence Voice Services(/edit/Galaxy%20AI?section=11)\n\n자세한 내용은 삼성 가우스 문서를 참고하십시오.\n\n#### 3.1.2. Samsung Language Core(/edit/Galaxy%20AI?section=12)\n\n자세한 내용은 삼성 가우스 문서를 참고하십시오.\n\n#### 3.1.3. Samsung Vision Core(/edit/Galaxy%20AI?section=13)", 'score': 0.99964297}, {'title': '생성형 AI 결과물에 대한 기대와 현실 | 인사이트리포트 | 삼성SDS', 'url': 'https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html', 'content': "성공적인 생성형 AI를 위해 맞춤형 키보드를 구입하거나, 새로운 최고 AI 책임자를 채용해야 할까요? 생성형 AI에 대한 큰 기대와 투자 관점에서 성과를 어떻게 바라보고 있을까요? \n \n 생성형 AI는 머신러닝(ML) 모델에서부터 다양한 영역에서 사용할 수 있는 플랫폼이 될 가능성을 제시합니다. 그러나 생성형 AI 자체가 문제 해결에 적합한지, 사용자들이 생성형 AI를 효과적으로 활용하는 방법을 알고 있는지 검증해야 합니다. [...] 최근 PageDuty의 연구에 따르면, 많은 사람들이 생성형 AI 툴을 개인 및 업무용으로 특정 업무나 부서 단위에서 정기적으로 사용하고 있으며, Fortune 1000대 기업 중 98%가 생성형 AI를 실험하고 있는 것으로 나타났습니다. 그러나 이제 많은 기업이 배포에 앞서 신중한 접근 방식을 취하고 있는 것으로 보입니다. 예를 들어, Foundry의 ‘2023 AI Priorities Study’에서 IT 의사결정권자의 4분의 1이 생성형 AI 기술을 시험하고 있지만, 배포까지 이어진 비율은 20%에 불과했습니다. CCS Insight의 ‘Employee Technology and Workplace Transformation Survey’에 참여한 고위급 리더들은 2023년 말까지 18%가 전체 직원에 생성형 AI를 배포했으며, 22%는 배포할 준비가 되어 있다고 응답했습니다. Intel의 ‘2023 ML Insider’ 설문조사에서 AI 전문가와 같은 IT 팀들의 응답에 따르면, 기업의 10%만이 2023년에 생성형 AI 솔루션을 프로덕션에 도입한 것으로 나타났습니다. [...] 생성형 AI 결과물의 품질과 정확성을 측정하는 것은 까다롭고 어렵습니다. 동일한 입력을 해도 매번 다른 결과가 나올 가능성이 높기 때문에 더 어렵습니다. 자체 보고된 생산성은 생성형 AI의 성공을 측정하는 최선의 방법이 아닐 수 있습니다. 성공적인 배포를 위해 중요한 지표를 바꾸어야 할 수도 있습니다. \n \n 생성형 AI 툴을 평가하기 위해 좋은 응답이 어떤 모습인지에 대한 공유 지침을 만듭니다. 예를 들면, Microsoft는 Azure Copilot을 구동하는 Ask Learn API에 대해 답변 품질에 대해 테스트할 실측 자료와 메트릭에 대한 참조 데이터가 포함된 대표적이고 주석이 달린 질문 및 답변의 '골든 데이터 세트'를 구축했습니다. \n \n 기업은 종종 생성형 AI를 배포하여 비용을 절감하는 것보다 돈을 벌 수 있는지에 더 관심이 있습니다. 이는 직원들의 생산성 능력 및 효율성 향상과 관련이 있습니다. 그러나, 많은 기업이 ROI를 입증해야 한다는 압박감이 있지만, 아직 그 단계에는 도달하지 않았습니다. Copilot for Sales와 같은 역할별 도구를 전환율, 거래 흐름 또는 통화 해결까지의 평균 시간 개선에 연결하는 것이 더 쉬울 수 있지만, 변수가 너무 많을 때에는 직접적인 인과 관계를 가정하지 않아야 합니다.", 'score': 0.9989267}, {'title': '삼성이 개척하는 온디바이스 생성형 AI의 전환점', 'url': 'https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/', 'content': '## 키워드 검색\n\n# 삼성이 개척하는 온디바이스 생성형 AI의 전환점\n\n2025년, 생성형 AI는 우리 손 위에 놓여져 있으며, 삼성의 Exynos SoC에 내장된 온디바이스 AI 기능 덕분에 이제 이 힘을 더 빠르고, 안전하게 활용할 수 있게 되었다. 과거에는 대규모 서버와 지속적인 인터넷 연결이 필요했던 AI 연산이 이제 스마트폰과 같은 개인 기기에서 직접 구동 가능해진 것이다. 이러한 관점에서 온디바이스 AI는 단순한 기술적 이정표가 아닌, AI 활용 방식의 근본적인 전환을 의미한다. \n \n온디바이스 AI는 클라우드 기반 모델 대비 여러 가지 중요한 이점을 제공한다. 인터넷 연결 없이도 실시간으로 AI 서비스를 이용할 수 있으며, 모든 연산을 로컬에서 처리하여 개인정보를 안전하게 보호할 수 있다. 또한 클라우드 서비스 비용 절감에도 기여한다. 그러나 스마트폰에서 온디바이스로 대규모 생성형 AI를 원활하게 구동하는 것은 연산 자원과 메모리 용량의 한계로 인해 쉽지 않은 일이다. 이를 해결하기 위해 고효율 추론 기술과 모델 경량화 및 양자화 기술이 필수적이며, 고성능 모델의 실시간 구동을 지원하기 위한 모델 변환 툴, 런타임 소프트웨어 기술, 이종 코어 아키텍처 기반의 고성능/저전력 신경망 가속기 설계 기술이 필요하다. [...] g33b4vqccuqvax5bvzcq-phk9tj-828709858-clientnsv4-s.akamaihd.net, g33b4vqccuqvax5bw2bq-py1x2v-a7310f6e5-clientnsv4-s.akamaihd.net, g33b4vqccuqvax5bx3za-pge3ox-a91a32353-clientnsv4-s.akamaihd.net, g33b4vqccuqwcx5bu4na-pqdvvi-3aaa5c611-clientnsv4-s.akamaihd.net, g33b4vqccuqwcx5bwzaq-pvw5k6-d3e3dcd05-clientnsv4-s.akamaihd.net, g33b4vqccuqwcx5bx22q-p8kovq-e038e0c0c-clientnsv4-s.akamaihd.net, g33b4vqccuqxax5bstpa-p4rsfx-bd0382a30-clientnsv4-s.akamaihd.net, g33b4vqccuqxax5btyeq-poz8cc-9955b8a36-clientnsv4-s.akamaihd.net, g33b4vqxzp4swx5bu27q-pxv1vf-89db7a111-clientnsv4-s.akamaihd.net, g33b4vqxzp4swx5bv25q-pt8447-731cc407d-clientnsv4-s.akamaihd.net, g33b4vsy3wdkax5bswnq-plqmrf-ff7289811-clientnsv4-s.akamaihd.net, g33b4vsy3wdkex5bsuoq-p56ka1-9bf23f300-clientnsv4-s.akamaihd.net, [...] gzfstpqxzp4swx5bsttq-p683qt-2c3f6e21e-clientnsv4-s.akamaihd.net, gzfstpqxzp4swx5bsu5q-pyioyl-3b5424f35-clientnsv4-s.akamaihd.net, gzfstpqxzp4swx5bsvra-ps8whv-800c4ca06-clientnsv4-s.akamaihd.net, gzfstpqxzp4swx5bt2ka-p3owfu-9bef421db-clientnsv4-s.akamaihd.net, gzfstpqxzp4swx5btynq-p80cg4-5fbda6ae3-clientnsv4-s.akamaihd.net, gzfstpsy3wdkax5btvta-pc4hb3-c24fbde0b-clientnsv4-s.akamaihd.net, i03f9f400-ds-aksb-a.akamaihd.net, i03fa4400-ds-aksb-a.akamaihd.net, i03faac00-ds-aksb-a.akamaihd.net, i03fae300-ds-aksb-a.akamaihd.net, i03fb4f00-ds-aksb-a.akamaihd.net, i22f29600-ds-aksb-a.akamaihd.net, i22f44600-ds-aksb-a.akamaihd.net, i22f47c00-ds-aksb-a.akamaihd.net, i22f4a100-ds-aksb-a.akamaihd.net, i22f55c00-ds-aksb-a.akamaihd.net, i22f5ca00-ds-aksb-a.akamaihd.net, i22f6b100-ds-aksb-a.akamaihd.net,', 'score': 0.99884856}, {'title': "삼성전자, AI 내재화 안 멈췄다...'이미지 생성 모델'도 개발 - 디일렉", 'url': 'https://www.thelec.kr/news/articleView.html?idxno=44288', 'content': '삼성리서치는 이와 같은 근본적인 한계를 개선하기 위해 자연어와 함께 \'참조 이미지(Reference Image)\'를 입력할 수 있는 이미지 생성 모델을 설계했다. 참조 이미지의 시각적인 정보를 직접 입력하는 방법이다. 이 모델은 참조 이미지의 주요 특성(ID, Identity)을 왜곡하지 않으면서 동시에 프롬프트(자연어요청)에 따라 객체를 변형할 수 있는 것이 특징이다. 삼성전자에 따르면 자체 개발 이미지 생성 모델은 사내 공개 후 월간 사용량이 153% 증가했다.\n\n삼성리서치 AI모델팀 시각언어모델(VLM)파트 연구진은 "참조 이미지 기반 생성 모델 개발 도중 많은 도전 과제에 직면했는데 대표적으로 파운데이션 모델을 확보하는 과정"이라며 "상업적 사용과 추가 학습이 가능한 오픈소스 파운데이션 모델이 필요했는데 개발 당시인 2024년 말에는 이에 적합한 모델을 구하기 어려웠다"고 밝혔다.\n\n이어 "저성능 오픈소스 모델보다 높은 성능을 갖춘 오픈소스 모델을 채택하는 방향으로 연구를 진행했다"며 "고성능 모델은 대체로 추가 학습을 방지하는 LAD(Latent Diffusion Model Acceleration) 기법이 적용돼 있다. 연구진은 특수 데이터셋을 구축해 학습 능력을 복원하고 당사의 요구에 맞게 최적화에 성공했다"고 말했다.\n\n관련 업계는 삼성전자의 전방위적인 AI 내재화 정책에 대해 AI를 조직의 핵심 경쟁력으로 끌어올리려는 전략으로 해석한다. 삼성전자의 AI 연구가 외부 사업화보다 임직원의 생산성 향상을 목적으로 두고 있다는 것이다.\n\n관련기사 [...] 삼성의 \'에이전트 빌더\'는 \'컴포넌트\' 조합만으로 업무용 에이전트를 빠르게 제작할 수 있는 솔루션을 의미한다. 컴포넌트는 에이전트 구성 단위다. 입출력창, AI모델, 논리구조 등 기본 요소부터 사내 시스템 특화 요소인 ‘DoXA’까지 포함한다. \'DoXA\'는 삼성리서치에서 만든 문서분석 서비스로 이를 에이전트에 추가하면 실제 업무 맥락을 잘 이해하는 에이전트를 구현할 수 있다. 프로그래밍이 필요 없는 \'드래그 앤 드롭\' 조작법이 적용된 것도 장점이다.\n\n삼성리서치는 가우스의 멀티모달 특징을 살려 사내 지식검색 서비스 \'시리우스(SIRIUS)\'를 개발했다. \'시리우스\'는 그래프 기반의 정보 구조화를 핵심으로 삼는다. 전통적인 검색 방식이 표, 이미지, 첨부파일 등 멀티모달 컨텐츠의 맥락을 파악하지 못하는 단점을 극복했다. 예를 들어 \'시리우스\'는 테이블 데이터를 \'어떤 행의 어떤 열에 어떤 값이 있다\'와 같이 문장 형식으로 치환한다. 이미지도 마찬가지로 텍스트로 특징을 서술한다.\n\n삼성리서치 소프트웨어 혁신센터 관계자는 "시리우스는 현재 임직원 대상으로 베타 서비스로 제공되고 있다"며 "주로 제품 개발 관련 지식을 검색하거나 특정 기술과제와 담당자 정보를 탐색하는 목적으로 사용된다"고 설명했다.\n\n또 삼성리서치는 이미지 생성 모델의 한계를 극복한 \'참조 이미지 기반 이미지 생성 모델\'을 개발했다. 기존 이미지 생성 모델은 정보량이 제한적인 자연어 입력만으로 원하는 이미지를 정확히 구현하지 못하는 한계가 있다. 학습하지 않은 지식에 대해서는 이미지를 구현하지 못하는 단점도 있다. [...] 관련기사\n\n 삼성, 초미니 AI모델 자체 연구...제미나이 꺾었다.\n [[발행인 칼럼] AI시대, \'소버린 AI\' 없는 삼성](\n AI 전략 바꾼 삼성전자, 美 빅테크 길 따라간다\n 삼성, 인도 릴라이언스와 전사 협력 확대\n SKT-삼성 \'AI-RAN 동맹\'…6G 핵심기술 공동 연구 착수\n 박용인 삼성전자 사장, 반도체공학회 수석부회장 사임..."회장직 거절"\n ‘독자 AI’ 5사5색 채용...AI모델 방향성도 보인다\n\n이석진 기자 sj7334@thelec.kr\n\n다른기사 보기\n\n키워드\n\n#삼성전자 #삼성리서치 #AI모델 #LLM #멀티모달 #이미지생성모델 #가우스\n\n저작권자 © 디일렉(THE ELEC) 무단전재 및 재배포, AI학습 및 활용 금지\n\n개의 댓글\n\n댓글 정렬\n\nBEST댓글\n\nBEST 댓글 답글과 추천수를 합산하여 자동으로 노출됩니다.\n\n내 댓글 모음\n\n모바일버전', 'score': 0.998259}]
[도구 호출]
Tool: read_file
file_path: report.md
Log:
Invoking: `read_file` with `{'file_path': 'report.md'}`
[도구 호출]
Tool: write_file
file_path: report.md
text: ## 삼성전자 생성형 AI 관련 최신 정보
- 출처: https://www.finance-scope.com/article/view/scp202502070005
삼성전자가 외부 AI 활용 고도화 방안을 검토중이며, ‘가우스’와 함께 외부 AI를 도입하라는 지시를 내림.
- 삼성전자의 AI 전략이 폐쇄성에서 개방성으로 전환되었으며, 외부 AI를 반도체 사업부에서 먼저 도입할 계획.
- 외부 AI 솔루션을 활용해 제조·개발 공정을 혁신할 전망.
- 출처: https://namu.wiki/w/Galaxy%20AI
삼성 갤럭시의 Galaxy AI는 온디바이스와 클라우드 모델이 결합된 하이브리드 생성형 AI 세트를 제공.
- 갤럭시 S24 시리즈와 함께 공개된 이 AI는 One UI와 앱에서 다양한 기능을 활용할 수 있도록 설계됨.
- 인텔리전스 UX 개념을 통해 자주 사용하는 앱에 특화된 AI 경험을 제공.
- 출처: https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html
생성형 AI 기술에 대한 기업들의 실험이 진행 중이나 실제 배포는 신중한 접근이 요구됨.
- 생성형 AI 솔루션의 품질과 정확성을 높이는 것이 중요하며, 다양한 기업들이 ROI 입증에 심혈을 기울이고 있음.
- 출처: https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/
온디바이스 AI 기술이 개인 기기에서 직접 구동 가능하게 하여, AI 활용 방식에서 혁신적인 전환점을 의미함.
- 개인정보 보호와 클라우드 비용 절감을 가능하게 하는 이점이 있음.
- 출처: https://www.thelec.kr/news/articleView.html?idxno=44288
삼성은 자연어와 참조 이미지를 입력할 수 있는 이미지 생성 모델을 개발함.
- 이 모델은 참조 이미지의 시각적 정보를 유지하며, 요청에 따라 객체를 변형할 수 있는 기능을 갖춤.
- 삼성리서치의 AI 내재화 정책이 전략적으로 AI를 조직의 핵심 경쟁력으로 안내하고 있음.
Log:
Invoking: `write_file` with `{'file_path': 'report.md', 'text': '## 삼성전자 생성형 AI 관련 최신 정보\n- 출처: https://www.finance-scope.com/article/view/scp202502070005 \n 삼성전자가 외부 AI 활용 고도화 방안을 검토중이며, ‘가우스’와 함께 외부 AI를 도입하라는 지시를 내림. \n - 삼성전자의 AI 전략이 폐쇄성에서 개방성으로 전환되었으며, 외부 AI를 반도체 사업부에서 먼저 도입할 계획. \n - 외부 AI 솔루션을 활용해 제조·개발 공정을 혁신할 전망. \n\n- 출처: https://namu.wiki/w/Galaxy%20AI \n 삼성 갤럭시의 Galaxy AI는 온디바이스와 클라우드 모델이 결합된 하이브리드 생성형 AI 세트를 제공. \n - 갤럭시 S24 시리즈와 함께 공개된 이 AI는 One UI와 앱에서 다양한 기능을 활용할 수 있도록 설계됨. \n - 인텔리전스 UX 개념을 통해 자주 사용하는 앱에 특화된 AI 경험을 제공.\n\n- 출처: https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html \n 생성형 AI 기술에 대한 기업들의 실험이 진행 중이나 실제 배포는 신중한 접근이 요구됨. \n - 생성형 AI 솔루션의 품질과 정확성을 높이는 것이 중요하며, 다양한 기업들이 ROI 입증에 심혈을 기울이고 있음.\n\n- 출처: https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/ \n 온디바이스 AI 기술이 개인 기기에서 직접 구동 가능하게 하여, AI 활용 방식에서 혁신적인 전환점을 의미함. \n - 개인정보 보호와 클라우드 비용 절감을 가능하게 하는 이점이 있음. \n\n- 출처: https://www.thelec.kr/news/articleView.html?idxno=44288 \n 삼성은 자연어와 참조 이미지를 입력할 수 있는 이미지 생성 모델을 개발함.\n - 이 모델은 참조 이미지의 시각적 정보를 유지하며, 요청에 따라 객체를 변형할 수 있는 기능을 갖춤. \n - 삼성리서치의 AI 내재화 정책이 전략적으로 AI를 조직의 핵심 경쟁력으로 안내하고 있음.'}`
[관찰 내용]
Observation: ## 삼성전자 생성형 AI '삼성 가우스' 관련 정보
- 발췌한 PDF 문서: page 10, filename: SPRI_AI_Brief_2023년12월호_F.pdf
- 삼성전자가 개발한 생성형 AI '삼성 가우스'는 온디바이스에서 작동 가능하며, 언어, 코드, 이미지의 3개 모델로 구성됨.
- 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획이며, 사용자의 정보 유출 위험이 없는 점이 장점임.
- '삼성 가우스'는 자체 안전한 데이터로 학습되었으며, 정규분포 이론을 정립한 수학자 가우스의 이름을 본뜸.
- 언어 모델은 메일 작성, 문서 요약, 번역 업무를 지원하며, 클라우드와 온디바이스에서 사용할 수 있음.
- 코드 생성 모델인 '코드아이'는 대화형 인터페이스로 제공되어 사내 소프트웨어 개발에 최적화됨.
- 이미지 모델은 창의적인 이미지 생성 및 저해상도 이미지를 고해상도로 전환하는 기능을 지원함.
- IT 전문지에 따르면, 온디바이스 AI 기술이 중요한 트렌드로 부상하고 있으며, 삼성 스마트폰은 경쟁력을 강화할 것으로 예상됨.
[관찰 내용]
Observation: File written successfully to report.md.
[도구 호출]
Tool: read_file
file_path: report.md
Log:
Invoking: `read_file` with `{'file_path': 'report.md'}`
[관찰 내용]
Observation: ## 삼성전자 생성형 AI 관련 최신 정보
- 출처: https://www.finance-scope.com/article/view/scp202502070005
삼성전자가 외부 AI 활용 고도화 방안을 검토중이며, ‘가우스’와 함께 외부 AI를 도입하라는 지시를 내림.
- 삼성전자의 AI 전략이 폐쇄성에서 개방성으로 전환되었으며, 외부 AI를 반도체 사업부에서 먼저 도입할 계획.
- 외부 AI 솔루션을 활용해 제조·개발 공정을 혁신할 전망.
- 출처: https://namu.wiki/w/Galaxy%20AI
삼성 갤럭시의 Galaxy AI는 온디바이스와 클라우드 모델이 결합된 하이브리드 생성형 AI 세트를 제공.
- 갤럭시 S24 시리즈와 함께 공개된 이 AI는 One UI와 앱에서 다양한 기능을 활용할 수 있도록 설계됨.
- 인텔리전스 UX 개념을 통해 자주 사용하는 앱에 특화된 AI 경험을 제공.
- 출처: https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html
생성형 AI 기술에 대한 기업들의 실험이 진행 중이나 실제 배포는 신중한 접근이 요구됨.
- 생성형 AI 솔루션의 품질과 정확성을 높이는 것이 중요하며, 다양한 기업들이 ROI 입증에 심혈을 기울이고 있음.
- 출처: https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/
온디바이스 AI 기술이 개인 기기에서 직접 구동 가능하게 하여, AI 활용 방식에서 혁신적인 전환점을 의미함.
- 개인정보 보호와 클라우드 비용 절감을 가능하게 하는 이점이 있음.
- 출처: https://www.thelec.kr/news/articleView.html?idxno=44288
삼성은 자연어와 참조 이미지를 입력할 수 있는 이미지 생성 모델을 개발함.
- 이 모델은 참조 이미지의 시각적 정보를 유지하며, 요청에 따라 객체를 변형할 수 있는 기능을 갖춤.
- 삼성리서치의 AI 내재화 정책이 전략적으로 AI를 조직의 핵심 경쟁력으로 안내하고 있음.
[최종 답변]
다음은 'report.md' 파일의 내용입니다:
## 삼성전자 생성형 AI 관련 최신 정보
- 출처: https://www.finance-scope.com/article/view/scp202502070005
삼성전자가 외부 AI 활용 고도화 방안을 검토중이며, ‘가우스’와 함께 외부 AI를 도입하라는 지시를 내림.
- 삼성전자의 AI 전략이 폐쇄성에서 개방성으로 전환되었으며, 외부 AI를 반도체 사업부에서 먼저 도입할 계획.
- 외부 AI 솔루션을 활용해 제조·개발 공정을 혁신할 전망.
- 출처: https://namu.wiki/w/Galaxy%20AI
삼성 갤럭시의 Galaxy AI는 온디바이스와 클라우드 모델이 결합된 하이브리드 생성형 AI 세트를 제공.
- 갤럭시 S24 시리즈와 함께 공개된 이 AI는 One UI와 앱에서 다양한 기능을 활용할 수 있도록 설계됨.
- 인텔리전스 UX 개념을 통해 자주 사용하는 앱에 특화된 AI 경험을 제공.
- 출처: https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html
생성형 AI 기술에 대한 기업들의 실험이 진행 중이나 실제 배포는 신중한 접근이 요구됨.
- 생성형 AI 솔루션의 품질과 정확성을 높이는 것이 중요하며, 다양한 기업들이 ROI 입증에 심혈을 기울이고 있음.
- 출처: https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/
온디바이스 AI 기술이 개인 기기에서 직접 구동 가능하게 하여, AI 활용 방식에서 혁신적인 전환점을 의미함.
- 개인정보 보호와 클라우드 비용 절감을 가능하게 하는 이점이 있음.
- 출처: https://www.thelec.kr/news/articleView.html?idxno=44288
삼성은 자연어와 참조 이미지를 입력할 수 있는 이미지 생성 모델을 개발함.
- 이 모델은 참조 이미지의 시각적 정보를 유지하며, 요청에 따라 객체를 변형할 수 있는 기능을 갖춤.
- 삼성리서치의 AI 내재화 정책이 전략적으로 AI를 조직의 핵심 경쟁력으로 안내하고 있음.
저장된 내용을 확인하고 싶으신 다른 사항이 있으면 말씀해 주세요!
업데이트 된 보고서 파일의 내용을 확인하면 다음과 같이 출력됩니다.
그러면 이제 좀 더 전문적인 보고서를 작성해보도록 하겠습니다.
result = agent_with_chat_history.stream(
{
"input": "'report.md' 파일을 열어서 안의 내용을 출력하세요."
"출력된 내용을 바탕으로, 전문적인 수준의 보고서를 작성하세요."
"보고서는 총 3개의 섹션으로 구성되어야 합니다: \n"
"1. 개요: 보고서 abstract를 300자 내외로 작성하세요.\n"
"2. 핵심내용: 보고서의 핵심 내용을 작성하세요. 정리된 표를 markdown 형식으로 작성하여 추가하세요."
"3. 최종결론: 보고서의 최종 결론을 작성하세요. 출처(파일명, url 등)을 표시하세요."
"마지막으로 작성된 결과물을 'report-2.md' 파일에 저장하세요."
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)
Output:
Agent 실행 결과:
[도구 호출]
Tool: read_file
file_path: report.md
Log:
Invoking: `read_file` with `{'file_path': 'report.md'}`
[관찰 내용]
Observation: ## 삼성전자 생성형 AI 관련 최신 정보
- 출처: https://www.finance-scope.com/article/view/scp202502070005
삼성전자가 외부 AI 활용 고도화 방안을 검토중이며, ‘가우스’와 함께 외부 AI를 도입하라는 지시를 내림.
- 삼성전자의 AI 전략이 폐쇄성에서 개방성으로 전환되었으며, 외부 AI를 반도체 사업부에서 먼저 도입할 계획.
- 외부 AI 솔루션을 활용해 제조·개발 공정을 혁신할 전망.
- 출처: https://namu.wiki/w/Galaxy%20AI
삼성 갤럭시의 Galaxy AI는 온디바이스와 클라우드 모델이 결합된 하이브리드 생성형 AI 세트를 제공.
- 갤럭시 S24 시리즈와 함께 공개된 이 AI는 One UI와 앱에서 다양한 기능을 활용할 수 있도록 설계됨.
- 인텔리전스 UX 개념을 통해 자주 사용하는 앱에 특화된 AI 경험을 제공.
- 출처: https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html
생성형 AI 기술에 대한 기업들의 실험이 진행 중이나 실제 배포는 신중한 접근이 요구됨.
- 생성형 AI 솔루션의 품질과 정확성을 높이는 것이 중요하며, 다양한 기업들이 ROI 입증에 심혈을 기울이고 있음.
- 출처: https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/
온디바이스 AI 기술이 개인 기기에서 직접 구동 가능하게 하여, AI 활용 방식에서 혁신적인 전환점을 의미함.
- 개인정보 보호와 클라우드 비용 절감을 가능하게 하는 이점이 있음.
- 출처: https://www.thelec.kr/news/articleView.html?idxno=44288
삼성은 자연어와 참조 이미지를 입력할 수 있는 이미지 생성 모델을 개발함.
- 이 모델은 참조 이미지의 시각적 정보를 유지하며, 요청에 따라 객체를 변형할 수 있는 기능을 갖춤.
- 삼성리서치의 AI 내재화 정책이 전략적으로 AI를 조직의 핵심 경쟁력으로 안내하고 있음.
[도구 호출]
Tool: write_file
file_path: report-2.md
text: ## 개요
삼성전자가 개발한 생성형 AI, 특히 '가우스'는 현대 AI 기술의 가장 앞선 예시로서, 외부 AI의 통합을 검토하고 있으며 제조 및 개발 공정의 혁신을 목표로 하고 있습니다. 또한, Galaxy AI와 함께 온디바이스 및 클라우드 모델을 결합하여 사용자 경험을 최적화하는 방향으로 나아가고 있습니다. 이러한 추세는 개인정보 보호와 비용 절감의 측면에서도 중요한 의미를 가지고 있습니다.
## 핵심내용
아래 표는 삼성전자가 개발한 생성형 AI와 관련된 최신 정보를 요약한 것입니다.
| 출처 | 내용 |
| -------- | ----------------------------------------------------------- |
| [Finance Scope](https://www.finance-scope.com/article/view/scp202502070005) | 외부 AI 활용 고도화 방안 검토 및 반도체 사업 도입 계획 |
| [Namu Wiki](https://namu.wiki/w/Galaxy%20AI) | Galaxy AI는 하이브리드 생성형 AI로, 갤럭시 S24 시리즈와 함께 제공됨 |
| [Samsung SDS](https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html) | 생성형 AI의 품질 및 정확성을 높이기 위한 신중한 접근 필요 |
| [Samsung Semiconductor](https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/) | 온디바이스 AI가 개인정보 보호 및 클라우드 비용 절감 가능하게 함 |
| [Thelec](https://www.thelec.kr/news/articleView.html?idxno=44288) | 자연어 및 이미지 입력 가능한 모델 개발, AI 내재화 정책 강화 |
## 최종결론
삼성전자의 생성형 AI 개발 전략은 외부 AI 도입을 통해 내부 공정을 혁신하고, 소비자에게 최적화된 사용자 경험을 제공하기 위한 것입니다. 이를 통해 삼성전자는 지속 가능한 기술 발전을 이루고 있으며, 개인정보 보호와 비용 효율을 동시에 고려한 기술 혁신을 이루고 있습니다. 이러한 모든 노력은 향후 AI 기술 시장에서 삼성전자의 경쟁력을 강화할 것으로 기대됩니다.
**출처:**
- 파일명: report.md
- URL: 각 링크별로 기재됨.
append: False
Log:
Invoking: `write_file` with `{'file_path': 'report-2.md', 'text': "## 개요 \n삼성전자가 개발한 생성형 AI, 특히 '가우스'는 현대 AI 기술의 가장 앞선 예시로서, 외부 AI의 통합을 검토하고 있으며 제조 및 개발 공정의 혁신을 목표로 하고 있습니다. 또한, Galaxy AI와 함께 온디바이스 및 클라우드 모델을 결합하여 사용자 경험을 최적화하는 방향으로 나아가고 있습니다. 이러한 추세는 개인정보 보호와 비용 절감의 측면에서도 중요한 의미를 가지고 있습니다. \n\n## 핵심내용 \n아래 표는 삼성전자가 개발한 생성형 AI와 관련된 최신 정보를 요약한 것입니다. \n\n| 출처 | 내용 | \n| -------- | ----------------------------------------------------------- | \n| [Finance Scope](https://www.finance-scope.com/article/view/scp202502070005) | 외부 AI 활용 고도화 방안 검토 및 반도체 사업 도입 계획 | \n| [Namu Wiki](https://namu.wiki/w/Galaxy%20AI) | Galaxy AI는 하이브리드 생성형 AI로, 갤럭시 S24 시리즈와 함께 제공됨 | \n| [Samsung SDS](https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html) | 생성형 AI의 품질 및 정확성을 높이기 위한 신중한 접근 필요 | \n| [Samsung Semiconductor](https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/) | 온디바이스 AI가 개인정보 보호 및 클라우드 비용 절감 가능하게 함 | \n| [Thelec](https://www.thelec.kr/news/articleView.html?idxno=44288) | 자연어 및 이미지 입력 가능한 모델 개발, AI 내재화 정책 강화 | \n\n## 최종결론 \n삼성전자의 생성형 AI 개발 전략은 외부 AI 도입을 통해 내부 공정을 혁신하고, 소비자에게 최적화된 사용자 경험을 제공하기 위한 것입니다. 이를 통해 삼성전자는 지속 가능한 기술 발전을 이루고 있으며, 개인정보 보호와 비용 효율을 동시에 고려한 기술 혁신을 이루고 있습니다. 이러한 모든 노력은 향후 AI 기술 시장에서 삼성전자의 경쟁력을 강화할 것으로 기대됩니다. \n\n**출처:** \n- 파일명: report.md \n- URL: 각 링크별로 기재됨.", 'append': False}`
[관찰 내용]
Observation: File written successfully to report-2.md.
[도구 호출]
Tool: read_file
file_path: report-2.md
Log:
Invoking: `read_file` with `{'file_path': 'report-2.md'}`
[관찰 내용]
Observation: ## 개요
삼성전자가 개발한 생성형 AI, 특히 '가우스'는 현대 AI 기술의 가장 앞선 예시로서, 외부 AI의 통합을 검토하고 있으며 제조 및 개발 공정의 혁신을 목표로 하고 있습니다. 또한, Galaxy AI와 함께 온디바이스 및 클라우드 모델을 결합하여 사용자 경험을 최적화하는 방향으로 나아가고 있습니다. 이러한 추세는 개인정보 보호와 비용 절감의 측면에서도 중요한 의미를 가지고 있습니다.
## 핵심내용
아래 표는 삼성전자가 개발한 생성형 AI와 관련된 최신 정보를 요약한 것입니다.
| 출처 | 내용 |
| -------- | ----------------------------------------------------------- |
| [Finance Scope](https://www.finance-scope.com/article/view/scp202502070005) | 외부 AI 활용 고도화 방안 검토 및 반도체 사업 도입 계획 |
| [Namu Wiki](https://namu.wiki/w/Galaxy%20AI) | Galaxy AI는 하이브리드 생성형 AI로, 갤럭시 S24 시리즈와 함께 제공됨 |
| [Samsung SDS](https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html) | 생성형 AI의 품질 및 정확성을 높이기 위한 신중한 접근 필요 |
| [Samsung Semiconductor](https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/) | 온디바이스 AI가 개인정보 보호 및 클라우드 비용 절감 가능하게 함 |
| [Thelec](https://www.thelec.kr/news/articleView.html?idxno=44288) | 자연어 및 이미지 입력 가능한 모델 개발, AI 내재화 정책 강화 |
## 최종결론
삼성전자의 생성형 AI 개발 전략은 외부 AI 도입을 통해 내부 공정을 혁신하고, 소비자에게 최적화된 사용자 경험을 제공하기 위한 것입니다. 이를 통해 삼성전자는 지속 가능한 기술 발전을 이루고 있으며, 개인정보 보호와 비용 효율을 동시에 고려한 기술 혁신을 이루고 있습니다. 이러한 모든 노력은 향후 AI 기술 시장에서 삼성전자의 경쟁력을 강화할 것으로 기대됩니다.
**출처:**
- 파일명: report.md
- URL: 각 링크별로 기재됨.
[최종 답변]
보고서가 성공적으로 작성되었습니다. 여기 보고서의 전체 내용입니다:
## 개요
삼성전자가 개발한 생성형 AI, 특히 '가우스'는 현대 AI 기술의 가장 앞선 예시로서, 외부 AI의 통합을 검토하고 있으며 제조 및 개발 공정의 혁신을 목표로 하고 있습니다. 또한, Galaxy AI와 함께 온디바이스 및 클라우드 모델을 결합하여 사용자 경험을 최적화하는 방향으로 나아가고 있습니다. 이러한 추세는 개인정보 보호와 비용 절감의 측면에서도 중요한 의미를 가지고 있습니다.
## 핵심내용
아래 표는 삼성전자가 개발한 생성형 AI와 관련된 최신 정보를 요약한 것입니다.
| 출처 | 내용 |
| -------- | ----------------------------------------------------------- |
| [Finance Scope](https://www.finance-scope.com/article/view/scp202502070005) | 외부 AI 활용 고도화 방안 검토 및 반도체 사업 도입 계획 |
| [Namu Wiki](https://namu.wiki/w/Galaxy%20AI) | Galaxy AI는 하이브리드 생성형 AI로, 갤럭시 S24 시리즈와 함께 제공됨 |
| [Samsung SDS](https://www.samsungsds.com/kr/insights/expections-and-reality-in-generative-ai.html) | 생성형 AI의 품질 및 정확성을 높이기 위한 신중한 접근 필요 |
| [Samsung Semiconductor](https://semiconductor.samsung.com/kr/news-events/tech-blog/samsungs-pivotal-role-in-pioneering-on-device-generative-ai/) | 온디바이스 AI가 개인정보 보호 및 클라우드 비용 절감 가능하게 함 |
| [Thelec](https://www.thelec.kr/news/articleView.html?idxno=44288) | 자연어 및 이미지 입력 가능한 모델 개발, AI 내재화 정책 강화 |
## 최종결론
삼성전자의 생성형 AI 개발 전략은 외부 AI 도입을 통해 내부 공정을 혁신하고, 소비자에게 최적화된 사용자 경험을 제공하기 위한 것입니다. 이를 통해 삼성전자는 지속 가능한 기술 발전을 이루고 있으며, 개인정보 보호와 비용 효율을 동시에 고려한 기술 혁신을 이루고 있습니다. 이러한 모든 노력은 향후 AI 기술 시장에서 삼성전자의 경쟁력을 강화할 것으로 기대됩니다.
**출처:**
- 파일명: report.md
- URL: 각 링크별로 기재됨.
이 보고서는 'report-2.md' 파일에 저장되었습니다. 추가적으로 궁금하신 점이 있으면 언제든지 말씀해 주세요!
생성된 보고서 파일(report-2.md)의 내용을 확인하면 아래와 같습니다.
마지막으로, 보고서 내용을 기반으로 이미지 생성을 요청해 보도록 하겠습니다.
# 이미지 생성을 요청합니다.
result = agent_with_chat_history.stream(
{
"input": "'report-2.md' 파일을 열어서 안의 내용을 출력하세요."
"출력된 내용에 어울리는 이미지를 생성하세요."
"생성한 이미지의 url을 markdown 형식으로 보고서의 가장 상단에 추가하세요."
"마지막으로 작성된 결과물을 'report-3.md' 파일에 저장하세요."
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)

9. 도구를 활용한 토론 에이전트(Two Agent Debates with Tools)
이 예제는 에이전트가 도구에 접근할 수 있는 다중 에이전트 대화를 시뮬레이션하는 방법을 보여줍니다.
9.1 DialogueAgent 및 DialogueSimulator
9.1.1 DialogueAgent
DialogueAgent는 특정 페르소나(Persona)를 가진 개별 에이전트를 정의하는 클래스입니다. 단순히 메시지를 주고받는 것을 넘어, 자신이 누구인지(Identity)와 지금까지 무슨 대화가 오갔는지(Memory)를 스스로 관리합니다.
-
정의: LLM을 감싸는 래퍼(Wrapper)로, 에이전트의 이름, 시스템 메시지(역할 정의), 그리고 대화 기록을 하나의 단위로 묶은 것.
-
핵심 기능:
- 역할 고수: 부여된 페르소나를 유지하며 답변을 생성합니다.
- 기록 관리: 자신이 보낸 메시지와 상대방으로부터 받은 메시지를 순서대로 저장합니다.
- 메시지 수신(receive): 외부의 메시지를 자신의 메모리에 추가합니다.
- 메시지 전송: 자신의 페르소나와 메모리를 바탕으로 답변을 생성하여 보냅니다.
from typing import Callable, List
from langchain_classic.schema import(
AIMessage,
HumanMessage,
SystemMessage,
)
from langchain_openai import ChatOpenAI
class DialogueAgent:
def __init__(
self,
name: str,
system_message: SystemMessage,
model: ChatOpenAI,) -> None:
# 에이전트의 이름을 설정합니다.
self.name = name
# 시스템 메시지를 설정합니다.
self.system_message = system_message
# LLM 모델을 설정합니다.
self.model = model
# 에이전트 이름을 지정합니다.
self.prefix = f"{self.name}: "
# 에이전트를 초기화합니다.
self.reset()
def reset(self):
"""
대화 내역을 초기화합니다.
"""
self.message_history = ["Here is the conversation so far."]
def send(self) -> str:
"""
메시지에 시스템 메시지 + 대화내용과 마지막으로 에이전트의 이름을 추가합니다.
"""
message = self.model(
[
self.system_message,
HumanMessage(content="\n".join(
[self.prefix] + self.message_history
)),
]
)
return message.content
def receive(self, name: str, message: str) -> None:
"""
name 이 말한 message를 메시지 내역에 추가합니다.
"""
self.message_history.append(f"{name}: {message}")
9.1.2 DialogueSimulator
DialogueSimulator는 여러 명의 DialogueAgent 사이에서 대화가 원활하게 흐르도록 제어하는 오케스트레이터입니다. 누가 언제 말할지, 그리고 그 말을 누구에게 전달할지를 결정합니다.
- 정의: 여러 DialogueAgent 객체들을 관리하며, 대화의 순서(Turn-taking)와 메시지 중계(Broadcasting)를 담당하는 실행 제어기.
- 핵심 기능:
- 순서 결정(select_next_speaker): 다음 대화 주자를 결정합니다. (순차적, 랜덤, 혹은 사회적 맥락에 따른 선택 등)
- 메시지 중계: 한 에이전트가 내뱉은 말을 다른 모든 에이전트(혹은 특정 대상)에게 전달하여 메모리를 동기화합니다.
- 진행 루프: 설정된 종료 조건(예: 대화 횟수 제한)까지 대화를 반복 실행합니다.
- inject 메서드는 주어진 이름(
name)과 메시지(message)로 대화를 시작하고, 모든 에이전트가 해당 메시지를 받도록 합니다. - step 메서드는 다음 발언자를 선택하고, 해당 발언자가 메시지를 보내면 모든 에이전트가 메시지를 받도록 합니다. 그리고 현재 단계를 증가시킵니다.
class DialogueSimulator:
def __init__(self, agents: List[DialogueAgent], selection_function: Callable[[int, List[DialogueAgent]], int],) -> None:
# 에이전트 목록을 설정합니다.
self.agents = agents
# 시뮬레이션 단계를 초기화합니다.
self._step = 0
# 다음 발언자를 선택하는 함수를 설정합니다.
self.select_next_speaker = selection_function
def reset(self):
# 모든 에이전트를 초기화합니다.
for agent in self.agents:
agent.reset()
def inject(self, name:str, message: str):
"""
name의 message로 대화를 시작합니다.
"""
# 모든 에이전트가 메시지를 받습니다.
for agent in self.agents:
agent.receive(name, message)
# 시뮬레이션 단계를 증가시킵니다.
self._step += 1
def step(self) -> tuple[str, str]:
# 1. 다음 발언자를 선택합니다.
speaker_idx = self.select_next_speaker(self._step, self.agents)
speaker = self.agents[speaker_idx]
# 2. 다음 발언자에게 메시지를 전송합니다.
message = speaker.send()
# 3. 모든 에이전트가 메시지를 받습니다.
for receiver in self.agents:
receiver.receive(speaker.name, message)
# 4. 시뮬레이션 단계를 증가시킵니다.
self._step += 1
# 발언자의 이름과 메시지를 반환합니다.
return speaker.name, message
9.1.3 DialogueAgentWithTools
DialogueAgent를 확장하여 도구를 사용할 수 있도록 DialogueAgentWithTools 클래스를 정의합니다.
DialogueAgentWithTools클래스는DialogueAgent클래스를 상속받아 구현되었습니다.send메서드는 에이전트가 메시지를 생성하고 반환하는 역할을 합니다.create_openai_tools_agent함수를 사용하여 에이전트 체인을 초기화합니다.- 초기화시 에이전트가 사용할 도구(tools)를 정의합니다.
from langchain_classic.agents import AgentExecutor, create_openai_tools_agent
from langchain_classic import hub
class DialogueAgentWithTools(DialogueAgent):
def __init__(self, name: str, system_message: SystemMessage, model: ChatOpenAI, tools,) -> None:
# 부모 클래스의 생성자를 호출합니다.
super().__init__(name, system_message, model)
# 주어진 도구 이름과 인자를 사용하여 도구를 로드합니다.
self.tools = tools
def send(self) -> str:
"""
메시지 기록에 챗 모델을 적용하고 문자열을 반환합니다.
"""
prompt = hub.pull("hwchase17/openai-functions-agent")
agent = create_openai_tools_agent(self.model, self.tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=self.tools, verbose=True)
# AI 메시지를 생성합니다.
message = AIMessage(
content=agent_executor.invoke(
{
"input": "\n".join(
[self.system_message.content] + [self.prefix] + self.message_history
)
}
)["output"]
)
# 생성된 메시지의 내용을 반환합니다.
return message.content
9.2 도구 설정
9.2.1 문서 검색 도구 정의
문서 검색 도구(Retrieval Tool)를 정의합니다.
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
# PDF 파일 로드 파일의 경로 입력
loader1 = TextLoader("/content/drive/MyDrive/LangChain/의대증원찬성.txt")
loader2 = TextLoader("/content/drive/MyDrive/LangChain/의대증원반대.txt")
# 텍스트 분할기를 사용하여 문서를 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
# 문서를 로드하고 분할합니다.
docs1 = loader1.load_and_split(text_splitter)
docs2 = loader2.load_and_split(text_splitter)
# VectorStore를 생성합니다.
vector1 = FAISS.from_documents(docs1, OpenAIEmbeddings())
vector2 = FAISS.from_documents(docs2, OpenAIEmbeddings())
# Retriever를 생성합니다.
doctor_retriever = vector2.as_retriever(search_kwargs={"k": 3})
gov_retriever = vector1.as_retriever(search_kwargs={"k":3})
from langchain_classic.tools.retriever import create_retriever_tool
doctor_retriever_tool = create_retriever_tool(
doctor_retriever,
name = "document_search",
description="This is a document about the Korean Medical Association's opposition to the expansion of university medical schools."
"Refer to this document when you want to present a rebuttal to the proponents of medical school expansion."
)
gov_retriever_tool = create_retriever_tool(
gov_retriever,
name="document_search",
description="This is a document about the Korean government's support for the expansion of university medical schools."
"Refer to this document when you want to provide a rebuttal to the opposition to medical school expansion."
)
9.2.2 웹 검색 도구 정의
웹에서 검색할 수 있는 도구를 생성합니다.
from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults(k=3)
9.2.3 각 에이전트가 활용할 수 있는 도구를 설정합니다.
retriever_names = {
"Doctor Union(의사협회)": [doctor_retriever_tool], # 의사협회 에이전트 도구 목록
"Government(대한민국 정부)": [gov_retriever_tool], # 정부 에이전트 도구 목록
}
# 토론 주제 선정
topic = "2024 현재, 대한민국 대학교 의대 정원 확대 충원은 필요한가?"
# 토론자를 설명하는 문구의 단어 제한
word_limit = 50
search_names = {
"Doctor Union(의사협회)": [search],
"Government(대한민국 정부)" : [search],
}
# 토론 주제 선정
topic = "2024년 현재, 대한민국 대학교 의대 정원 확대 충원은 필요한가?"
word_limit = 50 # 작업 브레인스토밍을 위한 단어 제한
9.3 LLM을 활용하여 주제 설명에 세부 내용 추가하기
LLM을 사용하여 주어진 주제에 대한 설명을 보다 상세하게 만들 수 있습니다.
이를 위해서는 먼저 주제에 대한 간단한 설명이나 개요를 LLM에 입력으로 제공합니다. 그런 다음 LLM에게 해당 주제에 대해 더 자세히 설명해줄 것을 요청합니다.
LLM은 방대한 양의 텍스트 데이터를 학습했기 때문에, 주어진 주제와 관련된 추가적인 정보와 세부 사항을 생성해낼 수 있습니다. 이를 통해 초기의 간단한 설명을 보다 풍부하고 상세한 내용으로 확장할 수 있습니다.
- 주어진 대화 주제(topic)와 참가자(names)를 기반으로 대화에 대한 설명(
conversation_description)을 생성합니다. agent_descriptor_system_message는 대화 참가자에 대한 설명을 추가할 수 있다는 내용의 SystemMessage입니다.generate_agent_description함수는 각 참가자(name)에 대하여 LLM이 생성한 설명을 생성합니다.agent_specifier_prompt는 대화 설명과 참가자 이름, 단어 제한(word_limit)을 포함하는 HumanMessage로 구성됩니다.- ChatOpenAI 모델을 사용하여
agent_sepcifier_prompt를 기반으로 참가자에 대한 설명(agent_description)을 생성합니다.
conversation_description = f"""Here is the topic of conversation: {topic} The participants are: {', '.join(search_names.keys())}"""
agent_descriptor_system_message = SystemMessage(
content="You can add detail to the description of the conversation participant."
)
def generate_agent_description(name):
agent_specifier_prompt = [
agent_descriptor_system_message,
HumanMessage(
content=f"""{conversation_description}
Please reply with a description of {name}, in {word_limit} words or less in expert tone.
Speak directly to {name}.
Give them a point of view.
Do not add anything els. Answer in KOREAN.
"""
),
]
# ChatOpenAI를 사용하여 에이전트 설명을 생성합니다.
llm = ChatOpenAI(temperature=0)
agent_description = llm.invoke(agent_specifier_prompt).content
return agent_description
# 각 참가자의 이름에 대한 에이전트 설명을 생성합니다
agent_descriptions = {name: generate_agent_description(name) for name in search_names}
# 생성한 에이전트 설명을 출력합니다.
agent_descriptions
Output:
{'Doctor Union(의사협회)': '의사협회는 의료계의 전문가들로 구성된 단체로, 의사들의 권익을 보호하고 의료 현실에 대한 전문적인 견해를 제시합니다. 의사협회는 의대 정원 확대에 대해 현재 의료체계의 상황과 의사들의 업무 부담을 고려하여 신중한 접근이 필요하다는 입장을 가지고 있습니다.',
'Government(대한민국 정부)': '대한민국 정부는 국가의 행정을 책임지는 주체로서, 국민의 복지와 발전을 책임져야 합니다. 의대 정원 확대 충원은 국가의 의료 인프라 강화와 국민 건강 증진을 위해 필수적인 조치로 고려되어야 합니다. 이에 대한 적절한 정책과 투자가 요구됩니다.'}
9.4 전역 System Message 설정
System message는 대화형 AI 시스템에서 사용자의 입력에 앞서 시스템이 생성하는 메시지입니다. 이러한 메시지는 대화의 맥락을 설정하고, 사용자에게 각 에이전트의 입장과 목적을 알려주는 역할을 합니다. 효과적인 system message를 작성하면 사용자와의 상호작용을 원활하게 하고, 대화의 질을 높일 수 있습니다.
프롬프트 설명
- 에이전트의 이름과 설명을 알립니다.
- 에이전트는 도구를 사용하여 정보를 찾고 대화 상대방의 주장을 반박해야 합니다.
- 에이전트는 출처를 인용해야 하며, 가짜 인용을 하거나 찾아보지 않은 출처를 인용해서는 안됩니다.
- 에이전트는 자신의 관점에서 말을 마치는 즉시 대화를 중단해야 합니다.
def generate_system_message(name, description, tools):
return f"""{conversation_description}
Your name is {name}.
Your description is as follows: {description}
Your goal is to persuade your conversation partner of your point of view.
DO look up information with your tool to refute your partner's claims.
DO cite your sources.
DO NOT fabricate fake citations.
DO NOT cite any source that you did not look up.
Do not add anything else.
Stop speaking the moment you finish speaking from your perspective.
Answer in KOREAN.
"""
agent_system_messages = {
name: generate_system_message(name, description, tools)
for (name, tools), description in zip(search_names.items(), agent_descriptions.values())
}
# 에이전트 시스템 메시지를 순회합니다.
for name, system_message in agent_system_messages.items():
# 에이전트의 이름을 출력합니다.
print(name)
# 에이전트의 시스템 메시지를 출력합니다.
print(system_message)
Output:
Doctor Union(의사협회)
Here is the topic of conversation: 2024 현재, 대한민국 대학교 의대 정원 확대 충원은 필요한가? The participants are: Doctor Union(의사협회), Government(대한민국 정부)
Your name is Doctor Union(의사협회).
Your description is as follows: 의사협회는 의료계의 전문가들로 구성된 단체로, 의사들의 권익을 보호하고 의료 현실에 대한 전문적인 견해를 제시합니다. 의사협회는 의대 정원 확대에 대해 현재 의료체계의 상황과 의사들의 업무 부담을 고려하여 신중한 접근이 필요하다는 입장을 가지고 있습니다.
Your goal is to persuade your conversation partner of your point of view.
DO look up information with your tool to refute your partner's claims.
DO cite your sources.
DO NOT fabricate fake citations.
DO NOT cite any source that you did not look up.
Do not add anything else.
Stop speaking the moment you finish speaking from your perspective.
Answer in KOREAN.
Government(대한민국 정부)
Here is the topic of conversation: 2024 현재, 대한민국 대학교 의대 정원 확대 충원은 필요한가? The participants are: Doctor Union(의사협회), Government(대한민국 정부)
Your name is Government(대한민국 정부).
Your description is as follows: 대한민국 정부는 국가의 행정을 책임지는 주체로서, 국민의 복지와 발전을 책임져야 합니다. 의대 정원 확대 충원은 국가의 의료 인프라 강화와 국민 건강 증진을 위해 필수적인 조치로 고려되어야 합니다. 이에 대한 적절한 정책과 투자가 요구됩니다.
Your goal is to persuade your conversation partner of your point of view.
DO look up information with your tool to refute your partner's claims.
DO cite your sources.
DO NOT fabricate fake citations.
DO NOT cite any source that you did not look up.
Do not add anything else.
Stop speaking the moment you finish speaking from your perspective.
Answer in KOREAN.
topic_specifier_prompt를 정의하여 주어진 주제를 더 구체화하는 프롬프트를 생성합니다.
topic_specifier_prompt = [
# 주제를 더 구체적으로 만들 수 있습니다.
SystemMessage(content="You can make a topic more specific."),
HumanMessage(
content=f"""{topic}
You are the moderator.
Please make the topic more specific.
Please reply with the specified quest in 100 words or less.
Speak directly to the participants: {*search_names,}.
Do not add anythin else.
Answer in KOREAN.
"""
),
]
# 구체화된 주제를 생성합니다.
llm = ChatOpenAI(temperature=1.0)
specified_topic = llm.invoke(topic_specifier_prompt).content
print(f"Original topic:\n{topic}\n") # 원래 주제를 출력합니다.
print(f"Detailed topic:\n{specified_topic}\n") # 구체화된 주제를 출력합니다.
Output:
Original topic:
2024 현재, 대한민국 대학교 의대 정원 확대 충원은 필요한가?
Detailed topic:
의사협회와 정부의 입장 차이와 함께 2024년 대한민국 대학교 의대 정원 확대 및 충원에 대한 영향에 대해 논의하시겠습니까?
9.5 토론 Loop
토론 Loop는 프로그램의 핵심 실행 부분으로, 주요 작업이 반복적으로 수행되는 곳입니다. 여기서 주요 작업은 각 에이전트의 메시지 청취 -> 도구를 활용하여 근거 탐색 -> 반박 의견 제시 등을 포함합니다.
agents = [
DialogueAgentWithTools(
name=name,
system_message=SystemMessage(content=system_message),
model=ChatOpenAI(model_name="gpt-4-turbo-preview", temperature=0.2),
tools=tools,
)
for (name, tools), system_message in zip(search_names.items(), agent_system_messages.values())
]
select_next_speaker 함수는 다음 발언자를 선택하는 역할을 합니다.
def select_next_speaker(step: int, agents: List[DialogueAgent]) -> int:
# 다음 발언자를 선택합니다.
# step을 에이전트 수로 나눈 나머지를 인덱스로 사용하여 다음 발언자를 순환적으로 선택합니다.
idx = (step) % len(agents)
return idx
이번 예제에서는 최대 6번의 토론을 실행합니다. (max_iters=6)
DialogueSimulator클래스의 인스턴스인simulator를 생성하며,agents와select_next_speaker함수를 매개변수로 전달합니다.simulator.reset()메서드를 호출하여 시뮬레이터를 초기화합니다.simulator.inject()메서드를 사용하여 “Moderator” 에이전트에게sepcified_topic을 주입합니다.- “Moderator”가 말한
specified_topic을 출력합니다. n이max_iters보다 작은 동안 반복합니다.simulator.step()메서드를 호출하여 다음 에이전트의 이름과 메시지를 가져옵니다.- 에이전트의 이름과 메시지를 출력합니다.
n을 1 증가시킵니다.
max_iters = 6 # 최대 반복 횟수를 6으로 설정합니다.
n = 0 # 반복 횟수를 추적하는 변수를 0으로 초기화합니다.
# DialogueSimulator 객체를 생성하고, agents와 select_next_speaker 함수를 전달합니다.
simulator = DialogueSimulator(agents=agents, selection_function=select_next_speaker)
# 시뮬레이터를 초기 상태로 리셋합니다.
simulator.reset()
# Moderator가 지정된 주제를 제시합니다.
simulator.inject("Moderator", specified_topic)
# Moderator가 제시한 주제를 출력합니다
print(f"(Moderator): {specified_topic}")
print("\n")
while n < max_iters:
name, message = (
simulator.step()
) # 시뮬레이터의 다음 단계를 실행하고 발언자와 메시지를 받아옵니다.
print(f"({name}): {message}")
print("\n")
n+=1 # 반복 횟수를 1 증가시킵니다.
Output:
(Moderator): 의사협회와 정부의 입장 차이와 함께 2024년 대한민국 대학교 의대 정원 확대 및 충원에 대한 영향에 대해 논의하시겠습니까?
> Entering new AgentExecutor chain...
Government(대한민국 정부): 네, 논의하겠습니다. 우리 정부는 의대 정원 확대 및 충원을 통해 국가의 의료 인프라를 강화하고 국민 건강을 증진시키는 것을 목표로 하고 있습니다. 현재 대한민국은 의료 서비스에 대한 수요가 지속적으로 증가하고 있으며, 특히 지방의 의료 접근성 문제는 심각한 상황입니다. 의대 정원을 확대함으로써 더 많은 의료 인력을 양성하여 이러한 문제를 해결하고자 합니다.
또한, 고령화 사회로의 진입과 함께 노인 인구가 증가하고 있어, 이에 따른 건강 관리와 의료 서비스의 수요도 급증하고 있습니다. 이러한 상황에서 의료 인력의 부족은 국민 건강에 직접적인 영향을 미칠 수 있으며, 이를 방지하기 위해서는 의대 정원의 확대가 필수적입니다.
정부는 이러한 정책을 통해 장기적으로 의료 인력의 분포를 균형 있게 조정하고, 의료 서비스의 질을 향상시키며, 국민의 건강을 증진시키는 것을 목표로 하고 있습니다. 의사협회와의 협력을 통해 이러한 목표를 달성할 수 있도록 노력하겠습니다.
> Finished chain.
(Government(대한민국 정부)): Government(대한민국 정부): 네, 논의하겠습니다. 우리 정부는 의대 정원 확대 및 충원을 통해 국가의 의료 인프라를 강화하고 국민 건강을 증진시키는 것을 목표로 하고 있습니다. 현재 대한민국은 의료 서비스에 대한 수요가 지속적으로 증가하고 있으며, 특히 지방의 의료 접근성 문제는 심각한 상황입니다. 의대 정원을 확대함으로써 더 많은 의료 인력을 양성하여 이러한 문제를 해결하고자 합니다.
또한, 고령화 사회로의 진입과 함께 노인 인구가 증가하고 있어, 이에 따른 건강 관리와 의료 서비스의 수요도 급증하고 있습니다. 이러한 상황에서 의료 인력의 부족은 국민 건강에 직접적인 영향을 미칠 수 있으며, 이를 방지하기 위해서는 의대 정원의 확대가 필수적입니다.
정부는 이러한 정책을 통해 장기적으로 의료 인력의 분포를 균형 있게 조정하고, 의료 서비스의 질을 향상시키며, 국민의 건강을 증진시키는 것을 목표로 하고 있습니다. 의사협회와의 협력을 통해 이러한 목표를 달성할 수 있도록 노력하겠습니다.
> Entering new AgentExecutor chain...
Invoking: `tavily_search_results_json` with `{'query': '대한민국 의대 정원 확대 반대 의사협회 입장'}`
[{'title': '정부 의대정원 확대 방침에 의사회원 81.7% "반대" - 의협신문', 'url': 'https://www.doctorsnews.co.kr/news/articleView.html?idxno=153311', 'content': '조사는 대한의사협회 회원을 대상으로 2023년 11월 10일부터 11월 17일까지 1주간 진행됐으며, 총 4010명이 조사에 응답했다.\n\n정부가 추진 중인 의과대학 정원 확대 방안에 대한 의사 회원들의 찬반 입장을 조사한 결과, 전체 응답자(4010명) 중 81.7%(3277명)가 의과대학 정원 확대를 반대한다고 응답했다.\n\n의과대학 정원 확대를 반대하는 이유로는, \'이미 의사 수가 충분하다\'는 의견이 가장 많았고(49.9%), \'향후 인구감소로 인한 의사 수요 역시 감소 될 것이기 때문에\'(16.3%), \'의료비용의 증가 우려\'(15.0%), \'의료서비스 질 저하 우려\'(14.4%), \'과다한 경쟁 우려\'(4.4%) 등의 순을 보였다.\n\n정원 확대 찬성 입장(733명)의 이유로는, \'필수의료 분야 공백 해소를 위해\'(49.0%), \'지역 간 의료격차 해소를 위해\'(24.4%), \'의사가 부족해 환자가 진료를 받지 못해서\'(7.9%) 등의 순을 보였다.\n\n일각에서 제기되고 있는 한의과대학 정원을 의과대학 정원으로 전환하자는 의견에 대해서는 응답자의 76.5%(2,508명)가 반대한다고 응답했다.\n\n지역의료 확충을 위한 현행 \'지방대학 및 지역균형인재 육성에 관한 법률\'의 지역인재전형 확대 방침에 대한 의견에 대해서는 반대 51.5%(2064명)가 찬성 48.5%(1946명)보다 근소하고 높았다. [...] ## 정부 의대정원 확대 방침에 의사회원 81.7% "반대"\n\n페이스북\n트위터\n네이버밴드\n카카오톡\n\n### 의정연, \'의과대학 정원 및 관련 현안에 대한 의사 인식 조사\' 자료 발간 의사수 1만 5천명 부족 근거 미비…섣부른 정원 확대 의료 질 저하 우려 "단순 수요조사 아닌 과학적·객관적 근거에 따른 수급 정책이 이뤄져야"\n\n![의과대학 정원 확대 방안에 대한 의사 회원들의 찬반 입장을 조사한 결과, 전체 응답자(4010명) 중 81.7%(3277명)가 의과대학 정원 확대를 반대한다고 응답했다. [그래픽=윤세호기자 seho3@kma.org] ⓒ의협신문](/news/photo/202402/153311_119692_342.jpg)\n\n의과대학 정원 확대 방안에 대한 의사 회원들의 찬반 입장을 조사한 결과, 전체 응답자(4010명) 중 81.7%(3277명)가 의과대학 정원 확대를 반대한다고 응답했다. [그래픽=윤세호기자 seho3@kma.org] ⓒ의협신문\n\nⓒ의협신문\n\nⓒ의협신문\n\n정부가 의과대학 정원 규모 발표를 앞두고 있는 가운데, 의사회원 81.7%가 의대정원 확대 방침을 반대한다는 조사결과가 나왔다.\n\n대한의사협회 의료정책연구원은 5일 \'의과대학 정원 및 관련 현안에 대한 의사 인식 조사\' 정책현안분석을 발간했다.\n\n이 연구는 의사 회원을 대상으로 현재 정부가 밝힌 의과대학 정원 확대와 관련한 인력 정책, 필수·지역의료 해결을 위한 정책 방안에 대한 인식을 확인하고, 바람직한 정책 방안을 모색하기 위해 수행됐다. [...] 지역인재전형 확대를 반대하는 이유는 \'지역의 의료 질 차이를 초래\'(28.1%), \'일반 졸업생들과의 이질감으로 인해 의사 사회에서 갈등을 유발\'(15.6%), \'지역인재 전형 인재에 대한 환자의 선호도 저하 가능성\'(9.4%) 등의 의견이 있었다.\n\n지역의사제 정원을 통해 장학금을 지급하고 10년간 의무복무 하도록 하는 일명 \'지역의사제\' 도입에 대한 인식을 조사한 결과, 전체 응답자의 62.2%가 부정적이라고 답했고, 35.6%만이 긍정적으로 응답했다.\n\n의사들이 생각하는 필수의료 분야 기피현상에 대한 원인으로는, 낮은 수가(45.4%, 1,826명), 의료사고에 대한 법적 보호 부재(36.0%, 1,445명), 과도한 업무부담(7.9%, 317명) 순으로 나타났다.\n\n\'응급실 뺑뺑이\' 사태의 해결방안으로는 경증 환자의 응급실 이용 제한(36.2%), 응급환자 분류 및 후송체계 강화(27.5%), 의료전달체계 확립(22.6%) 등의 의견이 있었다.\n\n\'소아과 오픈런\' 사태의 해결방안으로는, 소아청소년과 운영 관련 지원(47.2%), 소비자들의 의료 이용행태 개선 캠페인(14.0%), 조조·야간·휴일 진료 확대 지원(8.1%), 실시간 예약관리 시스템 개발 및 보급, 특정 시간대 파트타임 의사 고용 지원 등이 제안됐다.\n\n한편, 정부가 발표한 국립대병원 중심 육성, 중증·응급의료, 소아 진료 지원을 핵심으로 하는 지역·필수의료 관련 정책 방향에 대한 의사 회원들의 평가는 \'못하고 있다\'는 부정 평가(62.3%)가 \'잘하고 있다\'는 긍정 평가(11.9%)보다 높았다.', 'score': 0.92794675}, {'title': '윤석열 정부 의과대학 정원 대폭 확대 지침 - 나무위키', 'url': 'https://namu.wiki/w/%EC%9C%A4%EC%84%9D%EC%97%B4%20%EC%A0%95%EB%B6%80%20%EC%9D%98%EA%B3%BC%EB%8C%80%ED%95%99%20%EC%A0%95%EC%9B%90%20%EB%8C%80%ED%8F%AD%20%ED%99%95%EB%8C%80%20%EC%A7%80%EC%B9%A8', 'content': '조선일보는 지금도 인구 대비 의사 수가 OECD 최하 수준인데, 앞으로 급속한 고령화로 의사 수요가 늘어날 것이 분명하기 때문에 의사들이 의대 증원의 대폭 확대가 불가피하다는 명백한 현실을 인정해야 한다고 주장했다. [[사설] 어떤 경우에도 응급실과 수술실은 정상 가동돼야]( " \n \n중앙일보에 따르면 대한민국은 인구 1,000명당 의사 수가 2.6명으로 경제협력개발기구(OECD) 국가(#fn-8 "OECD 평균은 3.7명이다.") 중 멕시코(2.5명) 다음으로 적으며 독일은 여전히 의대 정원이 충분하지 않아 연내 5,000명 이상 늘리고, 추가 증원을 논의 중”임에도 불구하고 정원 확대에 반대하는 의사는 없다고 밝혔다. 지난 20년간 의대 정원을 2배로 늘려 온 영국이나 38% 늘린 미국에서도 의사의 집단행동은 없었고 2008년부터 의대 정원을 23.1% 늘려 온 일본의 경우 의사회가 정책에 반대 의견은 내도 파업은 하지 않았는데 유독 대한민국에서만 의대 증원 얘기가 나오면 의사들이 집단행동을 서슴지 않는다고 강도 높게 비판했다. [[사설] 의사들, 환자 건강 최우선이라는 선서 되새겨야]( " \n \nTV조선은 의료계 내부에서도 개원의, 전공의, 의대가 서로 입장이 다르다 보니 정부가 누구와 협상을 해야 하는지도 애매하다고 지적했다. # \n \n디지털타임스는 의대 증원에 반대하는 의사들 주장을 상세히 정리한 기사를 내면서도, 사설에서는 의대 증원에 찬성하고# 전공의 등의 집단행동은 강력히 비판했다. # \n \n일요신문은 역사는 반복된다라고 지적했다. # [...] 2023년 12월 17일 전국보건의료산업노동조합(보건의료노조)가 국회 앞에서 발표한 여론조사 결과에 따르면 응답자의 85.6%가 "의협이 진료 거부 또는 집단 휴업에 나서는 것을 지지하지 않는다"고 답했다. 국민 10명 중 8명 이상이 의사 진료거부투쟁에 반대하는 것. 10명 중 9명 이상인 93.4%는 "필수진료과 의사가 부족한 현실을 개선해야 한다"고 응답했다. "의대정원 확대에 찬성한다"는 답변은 89.3%였다. 또 응답자의 71.9%는 "정부의 의대증원에 반대하는 의협의 입장을 지지하지 않는다"고 밝혔다. \n \n의대정원의 증원 규모에는 "1,000명 이상"이라고 답한 응답 비율이 47.4%로 가장 많았다. "2,000명 이상 늘려야 한다"는 응답은 28.7%였으며 "100명과 1,000명 사이"라고 답한 응답자는 32.7%였다. 주로 제주(95.7%), 대구·경북(93.8%), 대전·세종·충청(91.6%), 부산·울산·경남(91.2%), 광주·전라(91.0%) 등 지방에서 의대증원에 찬성한다는 응답이 압도적이었다. 서울(82.8%)과 경기·인천(86.6%)의 찬성 비율과 대조적이다. 응답자의 87.3%는 의대정원 확대 결정권이 "국민과 정부에 있다"고 생각했다. 반면 "의대증원의 결정권이 의협에 있다"고 응답한 비율은 10.5%에 불과했다. 이번 설문조사는 12월 12일 전국 18세 이상 성인남녀 1,016명을 대상으로 진행했다. #1, #2, #3, #4, #5 \n \n2024년 2월 이후 여론조사는 2024년 의료정책 추진 반대 집단행동 문서 참고. [...] 수련업무 유관단체인 사단법인 대한병원협회는 필수 및 응급의료 붕괴를 막기위한 의사인력 증원의 필요성은 공감하는 입장이나, 전공의 이탈 사태가 장기화될 경우 결국 그 피해는 국민에게 고스란히 돌아갈 것이니 교육과정을 수용할 수 있는 충분한 인프라 확충 등을 염두에 두고 충분한 대화로 문제를 풀어야 한다는 입장을 밝혔다. #\n\n#### 4.1.2. 전국보건의료산업노동조합(/edit/%EC%9C%A4%EC%84%9D%EC%97%B4%20%EC%A0%95%EB%B6%80%20%EC%9D%98%EA%B3%BC%EB%8C%80%ED%95%99%20%EC%A0%95%EC%9B%90%20%EB%8C%80%ED%8F%AD%20%ED%99%95%EB%8C%80%20%EC%A7%80%EC%B9%A8?section=25)\n\n2024년 1월 23일, 전국보건의료산업노동조합은 의대 정원 증원은 의사 단체 빼고는 모든 국민이 찬성하는 국가 정책이라는 내용의 성명을 냈다. \n \n또한 대한의사협회는 국민을 협박해서는 안 되며 설문조사 참여 비율이 전체 전공의 수에 비해 28%, 전체 수련병원 200곳 중에서도 27.5%에 불과하다며 통계에 신뢰성에 대해 의문을 표했다. 보건의료노조, \'증원 반대\' 전공의 단체행동 조짐에 "국민협박"', 'score': 0.82186085}, {'title': '의대 증원 - 정부 vs 의료계...의료개혁 둘러싼 주요 쟁점은? - BBC', 'url': 'https://www.bbc.com/korean/articles/cjrkkpkdl8ko', 'content': "End of TOP 뉴스\n\nEnd of content\n\n## '연 2000명' 증원 근거는?\n\n현재 전국 40개 의과대학 입학정원은 총 3058명으로, 2006년 이후 19년째 동결 상태다.\n\n이전 정부에서도 의대 입학 정원을 확충하려는 시도는 여러 차례 있었지만, 의사들의 반발에 부딪혀 무산됐다. 2020년 문재인 정부는 매년 400명씩, 10년간 총 4000명을 증원하는 방안을 제안한 바 있다.\n\n증원을 얘기할 때 가장 흔히 인용되는 수치는 경제협력개발기구(OECD) 회원국 기준 의사 수다. 2021년 기준 국내 인구 1000명당 임상 의사 수는 2.6명(한의사 포함)으로, 30개 회원국(평균 3.7명) 중 멕시코(2.5명) 다음으로 가장 적다.\n\n하지만 대한의사협회(의협)는 한국과 의료체계가 비슷한 일본(2.6명)이나 미국(2.7명)과 비슷한 수준이기 때문에 문제가 없다는 입장이다. 또 의료접근성이나 1인당 외래 진료 횟수 및 입원 일수 등 다른 지표의 경우 OECD 상위권이라고 주장한다.\n\n2000명을 ‘단번에’ 증원한다는 점에서도 반발이 거세다.\n\n정부는 국책연구기관인 한국개발연구원(KDI), 한국보건사회연구원, 서울대학교 연구 등을 토대로 의대 증원을 하지 않으면 오는 2035년에는 의사 1만 명이 부족하다고 판단했다.\n\n정부는 의대 교육 기간(6년)과 전공의 수련 기간(4~5년)을 고려할 때 2025년 의대 증원 효과는 빠르면 2031년, 늦으면 2036년 이후에 나타난다고 설명한다. 이 때문에 연간 2000명보다 더 적은 숫자로 증원할 경우 의료 공백기가 길어진다는 것이다. [...] # 정부 vs 의료계...의료개혁 둘러싼 주요 쟁점은?\n\n의협 긴급 총회에 참석한 의사들\n\n사진 출처, EPA-EFE/REX/Shutterstock\n\n의대 입학 정원 확대를 포함한 의료개혁안을 두고 정부와 의사들이 강 대 강 대치를 이어가고 있다.\n\n정부는 지난 6일 의과대학 입학 정원 증원 계획을 발표했다. 오는 2025학년도부터 5년 동안 의대 입학정원을 2000명 늘려 연간 총 5058명을 선발하겠다는 방안이다.\n\n정부가 발표한 '필수의료 정책 패키지’에는 의료인력 확충안뿐만 아니라 지역의료 강화, 의료사고 안전망 구축, 보상체계 공정성 제고 등 크게 네 가지 의료개혁안이 담겼다.\n\n의사들은 정부 정책에 강하게 반발하고 있다. 다음 달 전국 집회를 계획하는 등 정부 압박에 물러서지 않겠다는 입장이다.\n\n보건복지부에 따르면 21일 오후 10시 기준 주요 100개 수련병원 점검 결과 사직서 제출자는 소속 전공의의 약 74% 수준인 9275명이다.\n\n아직 사직서 수리가 이뤄진 사례가 없는 것으로 파악되는 상황에서 근무지를 이탈한 이들은 이 중 8000명을 넘었다. 정부는 근무지 이탈이 확인된 전공의에게 업무개시명령을 발령했다.\n\n의대생들도 휴학으로 반대 의사를 표하고 있다. 교육부에 따르면 지난 21일 기준 22개 의과대학에서 3025명이 휴학을 신청했다.\n\n정부와 의사들의 입장이 이렇게 강하게 충돌하는 이유는 무엇일까?\n\n시장 매대에 진열된 란마오아 아시아티카 버섯\nMusk, Mandelson and Epstein\n중국 국기 앞에 놓여 있는 법봉\n멋진 풍경을 배경으로 자전거 탄 3명이 다리를 지나는 모습", 'score': 0.7913865}, {'title': '의료계 "준비되지 않은 의대증원 멈춰야…보정심 결과따라 대응"(종합)', 'url': 'https://www.yna.co.kr/view/AKR20260131040151530', 'content': '의협은 31일 서울 용산구 의협회관에서 \'합리적 의대 정원 정책을 촉구하는 전국의사대표자회의\'를 열어 결의문을 발표하고 "정부는 앞으로 다가올 2027년 의학교육 현장의 현실을 인정하고 졸속 증원을 즉각 중단하라"고 촉구했다.\n\n정부는 의과대학 증원 규모를 논의 중인 보정심이 늦어도 설 이전까지 2027학년도 의대 정원에 대한 결론을 내릴 것으로 보고 있지만, 의료계에서는 의학교육 현장의 상황을 생각하지 않고 시간에 쫓긴 졸속 결정이 될 것이라며 반발하고 있다.\n\n의협은 "강의실도, 교수도 없는 현장에서 수천 명의 학생을 한데 몰아넣는 것은 정상적인 교육이라 할 수 없다"며 "현장이 수용할 수 없는 그 어떤 숫자도 결코 용납하지 않을 것"이라고 강조했다.\n\n이어 "준비되지 않은 의대 증원은 수백조 재정 재앙을 미래세대에 물려줄 것"이라며 "정부는 증원의 허울 좋은 명분 뒤에 숨겨진 건보료 폭탄의 실체를 국민 앞에 정직하게 공개해야 한다"고 덧붙였다.\n\n김택우 의협 회장도 "정부는 2027학년도 의대 정원 확정을 위해 무리하게 시간에 쫓기며 또다시 \'숫자놀음\'을 반복하려 하고 있다"며 "과학적이고 객관적인 지표와 절차를 통해 신중하게 검토해야 하고, 준비가 되지 않았다며 억지로 증원하지 말라"고 촉구했다.\n\n그는 "전국 의대의 67.5%가 강의실 수용 능력을 초과했고, 의평원 기준에 맞는 기초의학 교수는 구할 수도 없는 실정"이라며 준비되지 않은 증원은 임상 역량을 갖추지 못한 의사를 양산해 의료 서비스의 질을 저하시킬 것"이라고 지적했다.\n\n전국의사대표자회의 [...] 전국의사대표자회의\n\n(서울=연합뉴스) 김택우 대한의사협회장이 31일 서울 의협회관에서 열린 전국의사대표자회의에서 결의문을 낭독하고 있다. 2026.1.31 [대한의사협회 제공. 재판매 및 DB금지] \n photo@yna.co.kr\n\n이날 회의에는 전국광역시도의사회장협의회와 대한개원의협의회 관계자, 대한의과대학·의학전문대학원학생협회(의대협) 산하 \'24·25학번 대표자단체\' 대표 등 약 300명의 의료계 관계자들이 참석했다.\n\n참석자들은 결의문 채택 후 비공개 토론회를 열어 정부의 의대 정원 증원 추진 상황을 공유하고 대응방식을 논의했다.\n\n토론회에서는 의협 집행부의 투쟁위 전환, 총파업을 포함한 단체행동, 의협의 한계점을 고려한 의사노조의 필요성 등을 언급한 의견이 나온 것으로 전해졌다.\n\n의협은 3일께 열릴 것으로 보이는 보정심 논의 결과에 따라 세부적인 대응 방침을 정할 계획이다.\n\n정부에 의료계의 입장을 지속적으로 전달하되 집회와 총파업 등 다양한 가능성을 열어놓고, 총파업 수준의 대응방안이 수면 위로 부상할 경우 전 회원 투표를 통해 최종 결정할 예정이다.\n\n김성근 의협 대변인은 "단체행동으로 국민에게 불편 끼치는 일이 생기지 않기를 바라고 있다"며 "그런 식의 행동을 주장하는 사람도 있지만 반대 의견도 많기 때문에 심사숙고해서 방향성을 만들어 가겠다"고 말했다.\n\n이어 "다음 보정심 결과를 보고 (단체행동 여부를) 결정하게 될 것 같다"라며 "총파업을 하는 게 좋은 모습은 아니지만 정말로 받아들일 수 없는 숫자를 받아 든다면 그런 행동을 할 수 있는 가능성도 열려있다"고 말했다. [...] # 의료계 "준비되지 않은 의대증원 멈춰야…보정심 결과따라 대응"(종합)\n\n송고2026-01-31 20:23\n\n송고 2026년01월31일 20시23분\n\n정부가 2027학년도 의과대학 정원 증원에 대한 논의를 이어가는 가운데 대한의사협회가 다음 달 초 열릴 보건의료정책심의위원회 결과에 따라 단체행동 등 대응 수위를 결정하기로 했다.\n\n의협은 31일 서울 용산구 의협회관에서 \'합리적 의대 정원 정책을 촉구하는 전국의사대표자회의\'를 열어 결의문을 발표하고 "정부는 앞으로 다가올 2027년 의학교육 현장의 현실을 인정하고 졸속 증원을 즉각 중단하라"고 촉구했다.\n\n정부는 의과대학 증원 규모를 논의 중인 보정심이 늦어도 설 이전까지 2027학년도 의대 정원에 대한 결론을 내릴 것으로 보고 있지만, 의료계에서는 의학교육 현장의 상황을 생각하지 않고 시간에 쫓긴 졸속 결정이 될 것이라며 반발하고 있다.\n\n고유선\n\n## 전국의사대표자회의…의협 "단체행동으로 국민께 불편 끼치는 일이 없길 바라"\n\n(서울=연합뉴스) 고유선 기자 = 정부가 2027학년도 의과대학 정원 증원에 대한 논의를 이어가는 가운데 대한의사협회가 다음 달 초 열릴 보건의료정책심의위원회(보정심) 결과에 따라 단체행동 등 대응 수위를 결정하기로 했다.\n\n전국의사대표자회의\n\n(서울=연합뉴스) 31일 서울 용산구 의협회관에서 열린 전국의사대표자회의에서 참석자들이 의대증원 중단을 촉구하는 피켓을 들고 있다. 2026.1.31 [대한의사협회 제공. 재판매 및 DB금지] \n photo@yna.co.kr', 'score': 0.78214747}, {'title': '2024년 의료정책 추진 반대 집단행동 - 나무위키', 'url': 'https://namu.wiki/w/2024%EB%85%84%20%EC%9D%98%EB%A3%8C%EC%A0%95%EC%B1%85%20%EC%B6%94%EC%A7%84%20%EB%B0%98%EB%8C%80%20%EC%A7%91%EB%8B%A8%ED%96%89%EB%8F%99', 'content': '| 원인 | 윤석열 정부의 의대 증원 강행(#fn-14 "대한의사협회와 따로 타협안을 끝맺지 않고 계획을 추진했다. ##")(#fn-15 "4년 예고제를 어기고 2025학년도 의대 입학정원을 2024년 2월에 결정한 것은 비판받아 마땅하다. 현 의대 정원 확대는 대학 구조 개혁을 위한 정원 조정에 해당하지 않기 때문에 4년 예고제 예외 사항에 속하지 않는다.")(#fn-16 "의학 계열 학과의 정원을 정하는 것은 교육부장관의 소관이며 직권이다(고등교육법 시행령 제28조 3항, 제33조 3항). 게다가 문정권에서 합의한 사항은 기속되지 않아, 윤정부는 관련 논의기구의 의사 비율을 줄여 의사의 입김을 줄였다. 정부는 2024년 1월 15일 공문을 통해 의협에 의대 정원안 규모에 대한 의견을 요청하였으나, 의협은 논의 중인 협의체 내에서 끝장토론을 해서라도 합의를 통해 도출하자는 의견이였다. ## 그러나 정부는 1시간 뒤 기자회견에서 발표를 준비해놓고 1시간 전 시작한 회의에서 형식적 의결절차를 숫자로 밀어부친 뒤 독단적 발표를 하였다.")을 비롯한 필수의료 정책 패키지 추진(#fn-17 "##"), 그에 따른 의료민영화 추진 우려(#fn-18 "###") | [...] "대학병원 측은 수술 및 진료 감소에 기인한 재정 악화로 인해 코로나 19 사태 때보다 경영이 어렵다고 주장했으나, 김윤 의원 및 의협 관계자들은 법인세 회피 목적의 거짓이며, 실제 타격은 그렇게 큰 편이 아니라고 반박했다. # 다만 비영리법인은 수익 사업을 영위하여 남는 이익만큼만 법인세 납부 의무를 지며, 병원 고유목적사업에 쓰이는 비용은 애초에 법인소득세 납부 대상이 아니다. 충남대병원(본분원 포함)과 강원대병원은 자본잠식 상태에 놓여있어 정부의 지원이 없다면 국립대병원의 역할을 수행하기 어려울 것이라고 밝혔다. #1, #2 경상국립대병원은 부채 비율이 자그마치 296,836.13%에 달했고, 충북대병원도 1,878.47%에 달했다. #") 3조원 이상(#fn-%ea%b1%b4%eb%b3%b4%ec%9e%ac%ec%a0%95 "2024년 2월부터 2025년 5월까지 3조 5,000억 원 이상이 투입됨. #")의 건강보험 재정 투입&지자체 재난관리기금 투입(#fn-25 "#") 2025학년도 의대정원 1,509명 증원 확정(#fn-26 "본래 2,000명 증원 계획이었으나, 2025학년도 대입 한정으로 각 대학의 총장들이 자율적으로 증원할 수 있게 교육부에 요청했고, 교육부가 이를 허락하면서 각 대학별로 50~100%까지 자율적으로 결정한 결과 1,509명으로 결정되었음. ##") 2026학년도 의대 모집 인원 3,058명 동결 간호법 제정(#fn-27 "PA간호사 등 간호법에서 허용하는 내용들은 법 시행 이전에는 의료법 등에 막혀 불가능했다. # 신법 우선의 원칙에 의거해 두 법 모두 일반법으로 [...] | 기타 관련 기관 대한간호협회(간협)(#fn-46 "전공의들의 집단 이탈 이후, 암묵적으로 PA간호사 등을 통해 의료공백 사태로 인한 피해를 최소화하였다. # 자세한 내용은 간호법 제정 배경 확인.") 대한한의사협회(한의협)(#fn-47 "2024/9/15 ~ 9/18 간의 추석연휴 기간 동안 연장진료 등을 통해 명절 기간 동안의 의료공백을 막는 데 협조했다. #") 전국보건의료산업노동조합(민주노총)(#fn-48 "전공의들의 의료파업 행위에 대해 \\"국민을 협박하는 행위\\"라고 비판했다. #") 전국의료산업노동조합연맹(한국노총)(#fn-49 "정부의 의대증원 정책안은 타당하며, 전공의들이 무조건적으로 의료현장에 복귀해야 한다는 입장을 밝혔다. #")(#fn-50 "2024년 말이 되자 스탠스를 바꿔 의료 민영화 정책을 폐기하고 의개특위도 해체하라고 요구했다. #") 경제정의실천시민연합(경실련)(#fn-51 "의사들의 의대 증원 반대 집단행동 등을 정부에 대한 월권적 행위라고 규탄했다. #") 한국환자단체연합회(#fn-52 "의사들의 집단 휴진 및 정부와의 갈등으로 인한 의료공백 상황을 멈춰달라는 시위를 열었으며, 의료파업 재발방지법 등을 촉구했다. #") |', 'score': 0.73207545}]대한민국 정부의 의대 정원 확대 및 충원 정책에 대해, 의사협회는 신중한 접근이 필요하다는 입장입니다. 의사협회는 의료계의 전문가들로 구성된 단체로서, 의료 현실에 대한 전문적인 견해를 제시합니다. 의사협회의 주된 우려는 의대 정원 확대가 의료 서비스의 질 저하, 의료비용의 증가, 과도한 경쟁, 그리고 인구 감소에 따른 의사 수요 감소를 초래할 수 있다는 점입니다.
대한의사협회가 실시한 조사에 따르면, 의사 회원들 중 81.7%가 의과대학 정원 확대를 반대하고 있습니다. 반대 이유로는 이미 의사 수가 충분하다는 의견이 가장 많았으며, 향후 인구감소로 인한 의사 수요 역시 감소될 것이기 때문에, 의료비용의 증가 우려, 의료서비스 질 저하 우려 등이 있었습니다("정부 의대정원 확대 방침에 의사회원 81.7% '반대' - 의협신문", [의협신문](https://www.doctorsnews.co.kr/news/articleView.html?idxno=153311)).
또한, 의사협회는 의대 정원 확대가 단순히 의사 수를 늘리는 것에 초점을 맞추는 것이 아니라, 의료 서비스의 질을 유지하고 향상시키는 방향으로 이루어져야 한다고 주장합니다. 의료계 내부에서도 의대 증원에 대한 반대 의견이 다수 존재하며, 이는 의료 서비스의 질 저하와 의료비용 증가로 이어질 수 있는 심각한 문제입니다.
정부의 의대 정원 확대 정책은 장기적으로 의료 인력의 분포를 균형 있게 조정하고, 의료 서비스의 질을 향상시키며, 국민의 건강을 증진시키는 목표를 가지고 있지만, 현재 의료계의 상황과 의사들의 업무 부담을 고려할 때, 신중한 접근과 충분한 논의가 필요합니다. 의사협회는 정부와의 협력을 통해 바람직한 정책 방안을 모색하길 희망합니다.
> Finished chain.
(Doctor Union(의사협회)): 대한민국 정부의 의대 정원 확대 및 충원 정책에 대해, 의사협회는 신중한 접근이 필요하다는 입장입니다. 의사협회는 의료계의 전문가들로 구성된 단체로서, 의료 현실에 대한 전문적인 견해를 제시합니다. 의사협회의 주된 우려는 의대 정원 확대가 의료 서비스의 질 저하, 의료비용의 증가, 과도한 경쟁, 그리고 인구 감소에 따른 의사 수요 감소를 초래할 수 있다는 점입니다.
대한의사협회가 실시한 조사에 따르면, 의사 회원들 중 81.7%가 의과대학 정원 확대를 반대하고 있습니다. 반대 이유로는 이미 의사 수가 충분하다는 의견이 가장 많았으며, 향후 인구감소로 인한 의사 수요 역시 감소될 것이기 때문에, 의료비용의 증가 우려, 의료서비스 질 저하 우려 등이 있었습니다("정부 의대정원 확대 방침에 의사회원 81.7% '반대' - 의협신문", [의협신문](https://www.doctorsnews.co.kr/news/articleView.html?idxno=153311)).
또한, 의사협회는 의대 정원 확대가 단순히 의사 수를 늘리는 것에 초점을 맞추는 것이 아니라, 의료 서비스의 질을 유지하고 향상시키는 방향으로 이루어져야 한다고 주장합니다. 의료계 내부에서도 의대 증원에 대한 반대 의견이 다수 존재하며, 이는 의료 서비스의 질 저하와 의료비용 증가로 이어질 수 있는 심각한 문제입니다.
정부의 의대 정원 확대 정책은 장기적으로 의료 인력의 분포를 균형 있게 조정하고, 의료 서비스의 질을 향상시키며, 국민의 건강을 증진시키는 목표를 가지고 있지만, 현재 의료계의 상황과 의사들의 업무 부담을 고려할 때, 신중한 접근과 충분한 논의가 필요합니다. 의사협회는 정부와의 협력을 통해 바람직한 정책 방안을 모색하길 희망합니다.
> Entering new AgentExecutor chain...
의사협회의 우려에 대해 이해하고 있으며, 의료 서비스의 질 저하나 의료비용 증가와 같은 문제를 방지하기 위한 방안을 마련하는 것이 중요하다는 점에 동의합니다. 그러나 의대 정원 확대가 단순히 의사 수를 늘리는 것이 아니라, 의료 서비스의 질을 향상시키고, 국민의 건강을 증진시키는 데 필수적인 조치라는 점을 강조하고 싶습니다.
우선, 의료 인력의 지역적 불균형 문제를 해결하기 위해서는 의대 정원의 확대가 필요합니다. 현재 대한민국의 의료 인력은 대도시에 집중되어 있으며, 이로 인해 지방의 의료 접근성이 낮아지고 있습니다. 의대 정원을 확대하여 더 많은 의료 인력을 양성함으로써, 지방에도 충분한 의료 인력을 배치할 수 있게 되어 의료 서비스의 질을 전국적으로 향상시킬 수 있습니다.
또한, 고령화 사회로의 진입으로 인한 노인 인구의 증가는 의료 서비스에 대한 수요를 급증시키고 있습니다. 이에 따라, 의료 인력의 수요 역시 증가하고 있으며, 이러한 수요를 충족시키기 위해서는 의대 정원의 확대가 필요합니다. 의료 인력 부족 문제를 해결함으로써, 노인 인구를 포함한 모든 국민이 필요한 의료 서비스를 적시에 받을 수 있게 됩니다.
정부는 의대 정원 확대와 함께 의료 인력의 질적 향상을 위한 교육 프로그램 개발 및 지원을 강화할 계획입니다. 이를 통해 의료 서비스의 질을 유지하고 향상시키며, 의료비용 증가를 최소화할 수 있을 것입니다. 의료 인력의 양적 확대와 질적 향상이 동시에 이루어질 때, 국민 건강 증진과 의료 서비스의 질 향상을 실현할 수 있을 것입니다.
정부는 의사협회와의 지속적인 대화와 협력을 통해 의대 정원 확대 정책을 신중하게 추진하고, 의료계의 우려를 해소하기 위한 방안을 모색할 것입니다. 함께 협력하여 국민의 건강과 의료 서비스의 질을 향상시키는 것이 우리 모두의 목표입니다.
> Finished chain.
(Government(대한민국 정부)): 의사협회의 우려에 대해 이해하고 있으며, 의료 서비스의 질 저하나 의료비용 증가와 같은 문제를 방지하기 위한 방안을 마련하는 것이 중요하다는 점에 동의합니다. 그러나 의대 정원 확대가 단순히 의사 수를 늘리는 것이 아니라, 의료 서비스의 질을 향상시키고, 국민의 건강을 증진시키는 데 필수적인 조치라는 점을 강조하고 싶습니다.
우선, 의료 인력의 지역적 불균형 문제를 해결하기 위해서는 의대 정원의 확대가 필요합니다. 현재 대한민국의 의료 인력은 대도시에 집중되어 있으며, 이로 인해 지방의 의료 접근성이 낮아지고 있습니다. 의대 정원을 확대하여 더 많은 의료 인력을 양성함으로써, 지방에도 충분한 의료 인력을 배치할 수 있게 되어 의료 서비스의 질을 전국적으로 향상시킬 수 있습니다.
또한, 고령화 사회로의 진입으로 인한 노인 인구의 증가는 의료 서비스에 대한 수요를 급증시키고 있습니다. 이에 따라, 의료 인력의 수요 역시 증가하고 있으며, 이러한 수요를 충족시키기 위해서는 의대 정원의 확대가 필요합니다. 의료 인력 부족 문제를 해결함으로써, 노인 인구를 포함한 모든 국민이 필요한 의료 서비스를 적시에 받을 수 있게 됩니다.
정부는 의대 정원 확대와 함께 의료 인력의 질적 향상을 위한 교육 프로그램 개발 및 지원을 강화할 계획입니다. 이를 통해 의료 서비스의 질을 유지하고 향상시키며, 의료비용 증가를 최소화할 수 있을 것입니다. 의료 인력의 양적 확대와 질적 향상이 동시에 이루어질 때, 국민 건강 증진과 의료 서비스의 질 향상을 실현할 수 있을 것입니다.
정부는 의사협회와의 지속적인 대화와 협력을 통해 의대 정원 확대 정책을 신중하게 추진하고, 의료계의 우려를 해소하기 위한 방안을 모색할 것입니다. 함께 협력하여 국민의 건강과 의료 서비스의 질을 향상시키는 것이 우리 모두의 목표입니다.
> Entering new AgentExecutor chain...
Invoking: `tavily_search_results_json` with `{'query': '대한민국 의대 정원 확대 반대 의견 2024'}`
[{'title': '2024년 의료정책 추진 반대 집단행동 - 나무위키', 'url': 'https://namu.wiki/w/2024%EB%85%84%20%EC%9D%98%EB%A3%8C%EC%A0%95%EC%B1%85%20%EC%B6%94%EC%A7%84%20%EB%B0%98%EB%8C%80%20%EC%A7%91%EB%8B%A8%ED%96%89%EB%8F%99', 'content': '| 원인 | 윤석열 정부의 의대 증원 강행(#fn-14 "대한의사협회와 따로 타협안을 끝맺지 않고 계획을 추진했다. ##")(#fn-15 "4년 예고제를 어기고 2025학년도 의대 입학정원을 2024년 2월에 결정한 것은 비판받아 마땅하다. 현 의대 정원 확대는 대학 구조 개혁을 위한 정원 조정에 해당하지 않기 때문에 4년 예고제 예외 사항에 속하지 않는다.")(#fn-16 "의학 계열 학과의 정원을 정하는 것은 교육부장관의 소관이며 직권이다(고등교육법 시행령 제28조 3항, 제33조 3항). 게다가 문정권에서 합의한 사항은 기속되지 않아, 윤정부는 관련 논의기구의 의사 비율을 줄여 의사의 입김을 줄였다. 정부는 2024년 1월 15일 공문을 통해 의협에 의대 정원안 규모에 대한 의견을 요청하였으나, 의협은 논의 중인 협의체 내에서 끝장토론을 해서라도 합의를 통해 도출하자는 의견이였다. ## 그러나 정부는 1시간 뒤 기자회견에서 발표를 준비해놓고 1시간 전 시작한 회의에서 형식적 의결절차를 숫자로 밀어부친 뒤 독단적 발표를 하였다.")을 비롯한 필수의료 정책 패키지 추진(#fn-17 "##"), 그에 따른 의료민영화 추진 우려(#fn-18 "###") | [...] | 대한민국의 교육 관련 사건 사고 | [...] | 2020년대 | | | --- | | 2020년 | 울산 초등교사 아동학대 사건T 2020년 대학교 집단 부정행위 사태C S 인천영종고등학교 집단폭행 사건B 코로나바이러스감염증-19/영향/교육/등교 관련P 온라인 개학P 수능 시험장 방역용 책상 칸막이 논란P 2020년 의대정원 확대 반대 집단행동G P | | 2021년 | 2021년 학교폭력 폭로 사건B 이재영-이다영 학교폭력 사건B 송명근-심경섭-배홍희 학교폭력 사건B 기성용 학교폭력 및 성폭력 의혹 사건B 이영하-김대현 학교폭력 가해 누명 사건B ? 진달래 학교폭력 가해 사건B 김소혜 학교폭력 논란B 수진 학교폭력 가해 논란B 박혜수 학교폭력 가해 논란B 2021년 양산 여중생 폭행사건B 일산 마두역 사건B 익산 남고생 집단폭행 사건B 제천 남중생 집단폭행 사건B 마포 오피스텔 감금 살인 사건B 보성고등학교 교사 페미니즘 사상 강요 및 갑질 사건T 페미니스트 교사조직의 아동 학대 및 세뇌 의혹G T 여성 사감장 남학생 기숙사 침입 사건T 2022학년도 수능 생명과학 II 출제 오류 사태A 박광일 불법 댓글조작 사건? | | 2022년 | 의령 초등교사 막말 사건T 윤석열 정부 초등학교 입학 연령 하향 추진 논란G P 대구 여교사 남학생 성관계 사건T 정호영 자녀 경북대학교 특혜 논란A 김가람 학교폭력 논란B 남주혁 학교폭력 논란B 익산 초등학생 학교폭력 사건B 서울대학교 2023학년도 정시 내신 반영 논란A 진명여고 군인 조롱 위문편지 작성 사건G S 속초 초등학생 교통사고 사망 사건S T | | 2023년 | 대구 중학생 학교폭력 생중계', 'score': 0.99929035}, {'title': '대한민국의 의과대학 - 위키백과, 우리 모두의 백과사전', 'url': 'https://ko.wikipedia.org/wiki/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD%EC%9D%98_%EC%9D%98%EA%B3%BC%EB%8C%80%ED%95%99', 'content': "13. ↑ “서남대 재정지원 대상자로 선정된 명지병원의 과제는?”. 《연합뉴스》. 2015년 2월 25일.\n14. ↑ 김기중/유대근 기자 (2017년 8월 2일). [“[단독] 교육부 “서남대 폐교”…부실사학 구조조정 신호탄”]( 《서울신문》.\n15. ↑ 박형우/박윤재 연세대 교수 (2009년 8월 21일). “광복 64년…의대가 6개에서 41개로 늘어난 까닭은?”. 《프레시안》.\n16. ↑ 장덕수 기자 (2002년 8월 8일). “의대 입학정원 내년부터 10% 감축… 학부모 반발 예상”. 《국민일보》.\n17. ↑ 조찬제 기자 (2005년 1월 25일). “‘의대편입’ 내년부터 폐지”. 《경향신문》.\n18. ↑ 양민철 기자 (2020년 7월 23일). “의대 정원 10년간 4천 명 증원…‘지역의사’는 해당 지역서 10년 의무 복무”. 《KBS 9시뉴스》.\n19. ↑ 이세영 기자 (2020년 9월 4일). [“정부-의협, 합의문 서명.. 전공의들 “합의 안해, 파업계속” [전문]”]( 《조선일보》.\n20. ↑ 김병규 기자 (2023년 10월 14일). “의대정원 확대 '파격 규모' 예상…확대폭 '1천명' 훌쩍 넘을수도”. 《연합뉴스》.\n21. ↑ 김병규, 오진송, 권지현 기자 (2024년 2월 6일). “의대 정원 2천명 늘린다…2035년까지 의사인력 1만명 확충(종합2보)”. 《연합뉴스》. CS1 관리 - 여러 이름 (링크) [...] 2020년 코로나19 여파로 의료인력 부족해지자, 문재인 정부는 2022학년도부터 10년간 한시적으로 의과대학 학부 신입생을 매년 400명씩, 모두 4천 명을 더 늘리기로 발표했다. 그러다가 의료계에서는 집단행동의 일환으로서, 의협은 전국의사총진료거부를, 대전협은 전공의 총진료거부로 대표되는 '젊은의사단체행동'을, 의대협은 의사 국가시험 응시 거부와 동맹 휴학을 주도하였다. 결국 정부는 9월 4일 의대 입학정원 확대를 철회했다.\n\n2023년 10월 윤석열 정부에서 의과대학 정원 폭을 대폭 늘릴 것이라는 예고를 하며 이 발표는 대통령이 직접 할 것이라는 대통령실 입장을 냈다. 2024년 2월 6일 내년 대학입시부터 의과대학 입학 정원을 최대 2천명으로 증원하기로 발표했다.\n\n## 같이 보기\n\n[편집]\n\n 의과대학\n 대한민국의 의학전문대학원\n\n## 각주\n\n[편집] [...] 마땅한 인수 협상 대상자를 찾지 못하자 다음으로 삼육대, 서울시립대, 온종합병원, 서남대의 구 재단이 인수전에 나서 삼육대와 서울시립대가 우선 협상 대상자로 선정되었으나, 교육의 질적 개선과 서남대 설립자의 횡령액 변제를 요구했지만 적극적이지 않았고, 의대 인수에만 초점을 두었다며 교육부는 서남대의 인수를 수용하지 않았다. 이로써 사실상 서남대와 서남대 의대는 폐교 수순을 밟게 되었으며, 서남대 의대의 정원을 어떻게 배정할지에 대한 논의가 진행되었다. 그 결과 2018학년도부터 서남대학교는 의예과 신입생을 모집하지 않으며, 기존 재학생들은 전북대학교와 원광대학교로 배정 편입되었다.\n\n### 의과대학 입학정원 조정 논란\n\n[편집]\n\n우리나라 의과대학은 1945년 8.15 광복이후 남한지역 기준으로 국립 서울대학교 의과대학을 포함해서 6개 밖에 없었다. 그러다가, 경제개발 5개년 계획으로 한국경제가 고도성장하면서 의과대학 입학정원이 빠른 속도로 늘어났다. 1998년 제주대학교 의과대학이 개교이후 더이상의 의과대학 신규신설이 없었다.\n\n2002년 8월8일 2007년 이후에는 인구 10만명당 활동의사수가 경제협력개발기구(OECD)국가(150명)나 미국(145∼150명)의 적정의사수를 초과,불가피하게 정원을 축소하게 됐다. 2006학년도부터 의대 학사편입학을 전격 폐지했다. 그 이후로 2006년도부터 입학정원 3,058명으로 계속 유지해왔다.", 'score': 0.99701905}, {'title': '의대 증원 - 정부 vs 의료계...의료개혁 둘러싼 주요 쟁점은? - BBC', 'url': 'https://www.bbc.com/korean/articles/cjrkkpkdl8ko', 'content': '정부는 지난 6일 의과대학 입학 정원 증원 계획을 발표했다. 오는 2025학년도부터 5년 동안 의대 입학정원을 2000명 늘려 연간 총 5058명을 선발하겠다는', 'score': 0.9656413}, {'title': '2025년 대한민국 의대 순위 TOP10: 입시와 세계평가로 본 최강 의과 ...', 'url': 'https://hopenfreedomsite.com/entry/2025%EB%85%84-%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD-%EC%9D%98%EB%8C%80-%EC%88%9C%EC%9C%84-TOP10-%EC%9E%85%EC%8B%9C%EC%99%80-%EC%84%B8%EA%B3%84%ED%8F%89%EA%B0%80%EB%A1%9C-%EB%B3%B8-%EC%B5%9C%EA%B0%95-%EC%9D%98%EA%B3%BC%EB%8C%80%ED%95%99', 'content': '### 모든 영역\n\n| | |\n --- |\n| 이 페이지의 URL 복사 | `S` |\n| 맨 위로 이동 | `T` |\n| 티스토리 홈 이동 | `H` |\n| 단축키 안내 | `Shift` + `/` `⇧` + `/` |\n\n\\ 단축키는 한글/영문 대소문자로 이용 가능하며, 티스토리 기본 도메인에서만 동작합니다. [...] ## 태그\n\n국내대학순위, 부속병원, 세계대학평가, 의과대학, 의대진학, 입시컷\n\n## 관련글\n\n 울산대학교 의과대학 장학금 혜택 완전 정리: 등록금·기숙사·해외연수까지\n 2025년 독일 의대 TOP10: 임상과 연구 모두 강한 명문 의과대학은?\n 2025년 영국 의대 순위 TOP10: 세계 명문대의 의료 교육 경쟁력\n 2024년 일본 의대 순위 TOP 10 정밀 분석\n\n희망과자유의대 진학을 꿈꾸는 이들을 위한 정보와 인사이트를 전하는 공간입니다.\n희망을 품고, 자유롭게 도전하는 여러분의 여정을 응원합니다.\n입시 전략부터 학과별 정보, 실전 경험까지 —\n\'희망과 자유 블로그\'에서 진짜 도움이 되는 이야기를 만나보세요.\n\n댓글2\n\n 약선\n\n 희망과자유님 깔끔한 구성과 내용이 인상적이에요. 구독 완료! 📚\n\n 2025. 5. 26. 03:10답글\n\n + 신고\n + 링크복사\n 슈슈아띠\n\n 희망과자유님 좋은 글이네요 ㅎㅎ 잘 보고 갑니다~\n\n 2025. 5. 26. 08:51답글\n\n + 신고\n + 링크복사\n\n## 티스토리툴바\n\n## 단축키\n\n### 내 블로그\n\n| | |\n --- |\n| 내 블로그 - 관리자 홈 전환 | `Q` `Q` |\n| 새 글 쓰기 | `W` |\n\n### 블로그 게시글\n\n| | |\n --- |\n| 글 수정 (권한 있는 경우) | `E` |\n| 댓글 영역으로 이동 | `C` |\n\n### 모든 영역 [...] ### 비교 표로 보는 입시와 진로 경쟁력\n\n항목 서울대 성균관대 연세대 울산대\n\n| | | | | |\n --- --- \n| 수능 커트라인 | 최고 | 상위권 | 상위권 | 상위권 |\n| 주 병원 | 서울대병원 | 삼성서울병원 | 세브란스병원 | 아산병원 |\n| 연구 성과 | 최상위 | 최상위 | 상위권 | 상위권 |\n| 취업·진로 | 전공 다양 | 병원 우선 | 연구·진료 | 임상 강세 |\n\n### 인용 중심 설명: 전문가의 시선\n\n"서울대 의대는 연구 역량만 봐도 단연 독보적입니다. 하지만 최근 3~5년간은 \n삼성서울병원 기반의 성균관대, 아산병원 기반의 울산대도 \n의료 실습이나 임상 현장에서는 탁월한 경쟁력을 보여주고 있습니다." \n(2025년 대한의학평가협회 이사 인터뷰 중)\n\n### 타임라인 중심: 최근 5년간 상승폭 높은 대학\n\n2023년 \n→ 성균관대와 울산대, 세계 순위 100위권 진입 \n2024~2025년 \n→ 성균관대 국내 2위 고정, 아주대·중앙대도 Top10 진입\n\n### 의대 선택 시 고려해야 할 요소 3가지\n\n기준 설명\n\n| | |\n --- |\n| 부속병원 규모 | 진료 케이스와 실습 수준에 직접적 영향 |\n| 연구 성과 | 세계 순위와 장학·진학 기회에 영향 |\n| 입시 경쟁률 | 높은 순위일수록 커트라인도 상향 |\n\n### 종합 결론: 서울대는 여전히 최상위, 그러나 선택지는 다양해졌다', 'score': 0.004248079}, {'title': '의과대학 - 나무위키', 'url': 'https://namu.wiki/w/%EC%9D%98%EA%B3%BC%EB%8C%80%ED%95%99', 'content': '여담으로, 해부실습의 경우 가톨릭대학교와 연세대학교가 한국 내 의대 중에 카데바를 가장 많이 기증받는 학교들이다. 천주교인의 경우 가톨릭대학교에, 개신교인의 경우', 'score': 0.0010403185}]정부의 의대 정원 확대 계획에 대해 의사협회는 여전히 우려를 표합니다. 정부가 의료 인력의 지역적 불균형 해소와 고령화 사회 대응을 위해 의대 정원 확대를 추진하는 것에 대해 이해하지만, 이러한 정책이 실제로 의료 서비스의 질 향상과 국민 건강 증진에 기여할 수 있을지에 대한 의문이 있습니다.
최근 나무위키에 따르면, 윤석열 정부의 의대 증원 강행은 대한의사협회와의 충분한 협의 없이 이루어졌으며, 이는 의료계 내부의 심각한 반대와 우려를 불러일으키고 있습니다("2024년 의료정책 추진 반대 집단행동 - 나무위키", [나무위키](https://namu.wiki/w/2024%EB%85%84%20%EC%9D%98%EB%A3%8C%EC%A0%95%EC%B1%85%20%EC%B6%94%EC%A7%84%20%EB%B0%98%EB%8C%80%20%EC%A7%91%EB%8B%A8%ED%96%89%EB%8F%99)). 이는 의대 정원 확대가 단순히 의사 수를 늘리는 것에 초점을 맞추고 있으며, 의료 서비스의 질적 향상이나 의료비용 증가 방지에 대한 구체적인 계획이 부족함을 시사합니다.
또한, 의대 정원 확대는 장기적으로 의료 인력의 과잉을 초래할 수 있으며, 이는 의료계 내에서의 과도한 경쟁과 의료 서비스 질 저하로 이어질 수 있습니다. 특히, 인구 감소가 예상되는 상황에서 의사의 수요와 공급을 정확히 예측하고, 이에 기반한 정책을 수립하는 것이 중요합니다.
의사협회는 정부와의 지속적인 대화와 협력을 통해 의료 인력의 질적 향상과 의료 서비스의 질을 유지하며 국민 건강을 증진시킬 수 있는 방안을 모색할 것을 제안합니다. 의대 정원 확대 정책의 신중한 재검토와 함께, 의료 인프라 개선, 의료 서비스 질 관리, 그리고 의료비용 통제에 대한 구체적인 계획이 수립되어야 할 것입니다.
> Finished chain.
(Doctor Union(의사협회)): 정부의 의대 정원 확대 계획에 대해 의사협회는 여전히 우려를 표합니다. 정부가 의료 인력의 지역적 불균형 해소와 고령화 사회 대응을 위해 의대 정원 확대를 추진하는 것에 대해 이해하지만, 이러한 정책이 실제로 의료 서비스의 질 향상과 국민 건강 증진에 기여할 수 있을지에 대한 의문이 있습니다.
최근 나무위키에 따르면, 윤석열 정부의 의대 증원 강행은 대한의사협회와의 충분한 협의 없이 이루어졌으며, 이는 의료계 내부의 심각한 반대와 우려를 불러일으키고 있습니다("2024년 의료정책 추진 반대 집단행동 - 나무위키", [나무위키](https://namu.wiki/w/2024%EB%85%84%20%EC%9D%98%EB%A3%8C%EC%A0%95%EC%B1%85%20%EC%B6%94%EC%A7%84%20%EB%B0%98%EB%8C%80%20%EC%A7%91%EB%8B%A8%ED%96%89%EB%8F%99)). 이는 의대 정원 확대가 단순히 의사 수를 늘리는 것에 초점을 맞추고 있으며, 의료 서비스의 질적 향상이나 의료비용 증가 방지에 대한 구체적인 계획이 부족함을 시사합니다.
또한, 의대 정원 확대는 장기적으로 의료 인력의 과잉을 초래할 수 있으며, 이는 의료계 내에서의 과도한 경쟁과 의료 서비스 질 저하로 이어질 수 있습니다. 특히, 인구 감소가 예상되는 상황에서 의사의 수요와 공급을 정확히 예측하고, 이에 기반한 정책을 수립하는 것이 중요합니다.
의사협회는 정부와의 지속적인 대화와 협력을 통해 의료 인력의 질적 향상과 의료 서비스의 질을 유지하며 국민 건강을 증진시킬 수 있는 방안을 모색할 것을 제안합니다. 의대 정원 확대 정책의 신중한 재검토와 함께, 의료 인프라 개선, 의료 서비스 질 관리, 그리고 의료비용 통제에 대한 구체적인 계획이 수립되어야 할 것입니다.
> Entering new AgentExecutor chain...
Invoking: `tavily_search_results_json` with `{'query': '대한민국 의료 인력 부족 현황 2024'}`
[{'title': '2024년 의료인력 분포 현황과 시사점: 지역별 의료 접근성 격차를 중심 ...', 'url': 'https://contents.premium.naver.com/aatto/smart/contents/241204221527357nb', 'content': '○ 통계표ID\n\n① DT\\_HIRA4T, ② DT\\_1B040A3\n\n○ 통계표명\n\n① 시군구별 의료인력현황(의사,간호사 등), ② 행정구역(시군구)별, 성별 인구수\n\n○ 조회기간\n\n① [2024년 1/4분기] 202403~202403 , ② [월] 202409~202411\n\n○ 출처\n\n① 국민건강보험공단, 건강보험심사평가원, ② 행정안전부\n\n[목차]\n\n1부. 시도별 인구대비 의사, 간호사 분포 통계 및 분석\n\nⅠ. 시도별 인구, 의사, 간호사 분포 (2024년)\n\nⅡ. 의료인력 분포 현황에 대한 분석 결과\n\n#표) 시도별 의료인력 현황 (2024년 1/4분기)\n\n\u200b\n\n2부. 의료인력 불균형 실태와 개선과제\n\nⅠ. 수도권 의료인력 집중 현상과 그 영향\n\nⅡ. 지방 중소도시의 의료인력 부족 실태\n\nⅢ. 간호 인력의 지역별 분포와 의료서비스 접근성\n\nⅣ. 의료인력 지역 불균형 해소를 위한 정책 제언과 발전방향\n\n#첨부) 본문 내 시각화 자료 - 시도별 인구대비 의사, 간호사 분포\n\n\u200b\n\n1부. 시도별 인구대비 의사, 간호사 분포 통계 및 분석\n\n\u200b\n\nⅠ. 시도별 인구, 의사, 간호사 분포 (2024년)\n\n\u200b\n\n1. 인구 분포 현황\n\n수도권: 전체 인구의 50.8% (26,044,729명)\n\n지방: 전체 인구의 49.2% (25,182,028명)\n\n인구 분포는 수도권과 지방이 비교적 균등한 상태입니다.\n\n\u200b\n\n2. 의사 인력 분포\n\n수도권: 전체 의사의 55.4% (59,991명)\n\n지방: 전체 의사의 44.6% (48,318명)\n\n인구 비율 대비 약 4.6%p의 수도권 편중 현상이 나타납니다.\n\n\u200b [...] # Premium Contents\n\n## 스마트 병원경영\n\n2024년 의료인력 분포 현황과 시사점: 지역별 의료 접근성 격차를 중심으로\n\n의료서비스의 지역별 균형과 접근성은 국민의 기본적 건강권을 보장하는 핵심 요소입니다. 특히 고령화가 가속화되고 만성질환이 증가하는 현시점에서 의료서비스의 지역 간 격차는 시급히 해결해야 할 사회적 과제로 대두되고 있습니다.\n\n2024년 1/4분기 기준으로 최근(2024.11) 공개된 의료인력 분포 현황 데이터를 분석한 결과, 우리나라의 의료인력은 수도권과 대도시에 심각하게 편중되어 있음이 확인되었고, 이러한 불균형은 지역주민의 의료서비스 접근성을 제한하고, 의료의 질적 격차를 심화시키는 주요 원인이 되고 있습니다.\n\n\u200b\n\n아래 내용은 지역별 의료인력 분포 현황을 체계적으로 분석하고, 의료서비스 불균형 해소를 위한 정책적 방향성과 나날이 진화하는 디지털 헬스케어 등 혁신적 기술을 활용한 새로운 해결 방안도 함께 생각해 봅니다.\n\n| | |\n --- |\n| ○ 통계표ID | ① DT\\_HIRA4T, ② DT\\_1B040A3 |\n| ○ 통계표명 | ① 시군구별 의료인력현황(의사,간호사 등), ② 행정구역(시군구)별, 성별 인구수 |\n| ○ 조회기간 | ① [2024년 1/4분기] 202403~202403 , ② [월] 202409~202411 |\n| ○ 출처 | ① 국민건강보험공단, 건강보험심사평가원, ② 행정안전부 |\n\n○ 통계표ID\n\n① DT\\_HIRA4T, ② DT\\_1B040A3\n\n○ 통계표명 [...] 인구 비율 대비 약 4.6%p의 수도권 편중 현상이 나타납니다.\n\n\u200b\n\n3. 간호사 인력 분포\n\n수도권: 전체 간호사의 48.9% (136,828명)\n\n지방: 전체 간호사의 51.1% (143,620명)\n\n간호사는 오히려 지방이 더 높은 비율을 보입니다.\n\n\u200b\n\n\u200b\n\nⅡ. 의료인력 분포 현황에 대한 분석 결과\n\n\u200b\n\n1. 수도권과 광역시의 의료인력 집중도\n\n의사 인력 집중도\n\n서울이 인구 1000명당 3.25명으로 압도적 1위입니다.\n\n광주(2.55명), 부산(2.46명), 대구(2.46명)가 그 뒤를 따릅니다.\n\n수도권 내에서도 서울과 인천/경기도의 격차가 매우 큽니다.\n\n간호사 인력 집중도\n\n광주가 8.16명으로 가장 높은 수준입니다.\n\n부산(7.21명), 대구(7.14명), 서울(6.94명) 순입니다.\n\n대체로 광역시가 높은 수준을 보입니다.\n\n\u200b\n\n짙은 색 컬러(강조) : 수도권(서울, 경기, 인천)\n\n\u200b\n\n2. 지역별 의료 취약성 분석\n\n심각한 의료 취약지역:\n\n세종: 의사(1.40명), 간호사(2.74명) 모두 최하위\n\n충남: 의사(1.50명), 간호사(3.67명)으로 하위권\n\n충북: 의사(1.57명), 간호사(3.98명)으로 하위권\n\n경북: 의사(1.43명), 간호사(4.61명)으로 의사 인력 특히 부족\n\n\u200b\n\n3. 의사-간호사 비율의 지역별 특성\n\n높은 간호사 비율 지역\n\n광주: 의사 대비 간호사 비율이 3.2:1로 가장 높음\n\n전남: 3.37:1의 비율로 두 번째\n\n부산: 2.93:1의 비율\n\n상대적으로 낮은 간호사 비율 지역\n\n서울: 2.13:1로 가장 낮은 비율\n\n경기: 2.37:1', 'score': 0.8674071}, {'title': '전진숙 의원, 공공·지역의료 의사 5,270명 부족 2024년보다 972명 더 ...', 'url': 'http://m.sisatotalnews.com/article.php?aid=1760489087406324002', 'content': 'ֱ, ̷ ȯ \n\nֽñû, 5 ۷ι \n\n\U000f3cb5, \uf864ϡϵ -ñ \n\nƯġ, ī ݻ ģȯ ȭǰ \n\nֱ, Ư ġ Ư \n\n\U000f3cb5û, Ư ġ Ư \n\n ) [...] # \n\n### αⴺ\n\nֺϱü, ޡ \uf86f ϱ\n\nƯġ, ӻ깰 ǥ ܼ \n\nֺȯ濬, ȯо ȸ \n\nƯġ, οݰܰ ع\n\nֱ, 2026 ι ˽ \n\nƯġ, 2026 .Ƶ.о ΰü\n\nõ, Ư . ΰûȸ ֡\n\nƯġ, λǰ Ǹ \n\nƯġ, յΰ 깰 Ű˻ ǰ \n\nƯġ, 2026 1ȸ -ñ δü ȸ\n\n### ְ ִ\n\n, ȸ Ҿִ ʴǥ ⸶ڡ\n\nڼ \u05f8 ο \n\n ǥ Ư, ϱ 弭 \n\n , \n\nֱ, ̷ ȯ ', 'score': 0.78572035}, {'title': '대한민국/의료 - 나무위키', 'url': 'https://namu.wiki/w/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD/%EC%9D%98%EB%A3%8C', 'content': '최근 변경최근 토론\n\n특수 기능\n\n# 대한민국/의료\n\n최근 수정 시각:\n\n편집토론역사\n\n분류\n\n 대한민국\n 의료\n\n상위 문서: 대한민국\n\n1. 개요2. 역사3. 대한민국의 병원4. 의료전달체계5. 대한민국 의료 체계의 장점\n\n5.1. 보편건강보험과 저렴한 본인부담5.2. 신속하면서도 저렴한 의료5.3. 검사 등 높은 수준의 의료 인프라5.4. 국가적 재난 대응 능력\n\n6. 대한민국 의료 체계의 문제점\n\n6.1. 필수의료 인력 부족\n\n6.1.1. 소아청소년과 기피 현상\n\n6.2. 부족한 간호 인력6.3. 응급 이송 체계의 문제점6.4. 과도한 인턴·레지던트 의존6.5. 국민건강보험의 어두운 미래\n\n## 1. 개요(/edit/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD/%EC%9D%98%EB%A3%8C?section=1)\n\n대한민국의 의료 체계를 정리한 문서이다. \n \n2024년 2월 이전까지의 대한민국은 서울아산병원, 삼성서울병원, 서울대학교병원, 신촌세브란스병원, 가톨릭대학교 서울성모병원 등 빅 5이라 불리는 메이져 5대 병원이 세계 병원 순위 30위권에 모두 이름을 올리고 있고, 2019년 코로나바이러스감염증-19 사태에도 체계적으로 대응할 정도의 높은 의료수준을 갖춘 국가였다.(#fn-1 "다만 코로나바이러스의 경우 정부의 발빠른 대처, 전산화되고 디지털화된 방역대책, 평균적으로 높은 국민의 시민의식 등도 동시에 영향을 미쳤음을 고려해야 한다.") [...] ### 6.2. 부족한 간호 인력(/edit/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD/%EC%9D%98%EB%A3%8C?section=13)\n\n대학병원과 같은 큰 규모의 병원에서 일하는 임상 간호사들은 앉지 못하는 건 기본이고, 물을 마시는 것도, 점심을 먹는 것도, 화장실에 가는 것도 불가하다. 또한 업무 특성상 3교대를 해야하는 간호사들은 엄청난 체력적 부담을 안게 된다. 이러한 열악한 노동환경과 노동에 비해 적은 보수로 인해 신규 간호사의 1년 내 사직률은 지난 2014년 28.7%에서 2021년 52.8%로 증가했다. 인건비 쥐어짜기의 일환으로 전문의를 고용하지 않고 간호사들이 의사의 업무를 보게 하는 불법을 저지르지만, 현재 대한민국엔 이들을 보호해줄 어떠한 제도적 장치도 존재하지 않는다. \n \n결국 전문 간호인력들이 해외로 빠져나가거나 ## 간호사가 아닌 다른 직업을 선택하는 경우가 많아졌다. 간호 인력이 줄어들면서 수도권 집중화 현상은 당연하게도 일어났고 지방 병원과 중소 병원들은 간호 인력이 절대적으로 부족한 상황에 놓였다.####\n\n### 6.3. 응급 이송 체계의 문제점(/edit/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD/%EC%9D%98%EB%A3%8C?section=14) [...] ### 5.4. 국가적 재난 대응 능력(/edit/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD/%EC%9D%98%EB%A3%8C?section=9)\n\n대한민국은 병역의무를 지는 미필 남성 의료인을 군의관 및 공중보건의로 배속하여, 필요할 때 신속하게 국가가 원하는 바대로 인력을 동원할 수 있는 시스템을 갖추고 있다. 이는 주요 대규모 판데믹인 사스, 메르스, 그리고 코로나바이러스감염증-19에서 큰 역할을 했다. 일반적으로 국가의료인력을 갖춘 국가들은 양성 비용의 한계상 많은 숫자를 꾸리진 못하거나, 꾸려도 처우가 좋지 않아 대부분 근로 의욕이 없는 것에 비해 한국은 단기간에 끝나는 병역의무라는 특성상 근무 열성을 기대할 수 있었다. 다만 근본적인 문제로, 병역의무로 비군사적인 일에 동원하는것이 합당한지에 대한 논란은 있다. 해당 문단 참조.\n\n## 6. 대한민국 의료 체계의 문제점(/edit/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD/%EC%9D%98%EB%A3%8C?section=10)\n\n### 6.1. 필수의료 인력 부족(/edit/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD/%EC%9D%98%EB%A3%8C?section=11)', 'score': 0.7171114}, {'title': '[2024 보건복지위 국감 주요이슈 8] ①의료공백 벌써 반년…의정갈등 ...', 'url': 'https://www.k-health.com/news/articleView.html?idxno=74872', 'content': '■지방의료원 기능보강 및 경영효율화\n\n코로나19를 거치면서 지역공공병원의 의료인프라와 공공의료인력문제가 대두되면서 지역공공의료 활성화를 위한 구체적인 방안 마련이 시급한 상황이다. 특히 ▲전문진료 강화(노인성질환‧재활) ▲응급‧필수의료역량 확대 ▲공공의료기능 강화(전염병 대응‧의료취약계층지원) 등 지방의료원의 기능보강이 절실하다. 또 지방의료원 활성화를 위해 ▲지방의료원법 개정 ▲정부‧지방자치단제 재정지원 ▲재정운용방식 개편 ▲예비타당성조사제도 등도 검토해야 한다는 지적이다.\n\n■국가건강검진체계 통합관리\n\n국가건강검진은 생애주기에 따라 ‘영유아보육법’에 따른 영유아건강검진, ‘학교보건법’에 따른 학생건강검사, ‘국민건강보험법’에 따른 국민건강검진 등이 포함된다. 이 중 학생건강검사는 검사결과가 건강보험공단이 관리하는 영유아・성인 등 생애주기별 건강정보와 연계되지 않아 제도개선이 필요하다. 복지부와 교육부가 연계해 올해 시행하는 시범사업 결과를 바탕으로 국가건강검진체계의 통합관리방안을 구체화해 전국단위 사업을 추진할 필요가 있고 법·제도적 정비도 함께 이뤄져야 한다.\n\n■마약중독치료 전담병원 설치\n\n최근 마약중독이 심각해지면서 마약중독치료 전담병원의 중요성도 높아지고 있다. 마약중독은 치료‧재활이 필요한 질환인데도 전문치료병원이나 시설이 턱없이 부족한 상황이다. 이는 마약중독자의 치료접근성을 낮춰 국민건강을 저해하고 마약재범 및 범죄를 증가시켜 사회안전망을 붕괴시키는 요인이 된다. 따라서 마약치료‧재활 전담병원을 구축하고 중독전문인력 확보하는 한편 이를 위한 법적 기반을 확보할 필요가 있다. [...] 헬스경향\n헬스경향\n올해 국정감사에서는 장기간 해결되지 못하고 있는 여러 보건복지 이슈들이 다뤄질 전망이다. 사진은\n\n국회 보건복지위원회는 10월 7일 보건복지부와 질병관리청을 시작으로 국정감사에 돌입한다. 올해 국정감사를 앞두고 보건복지위 국정감사 주요이슈 8가지를 정리했다.\n\n■의정갈등 해결방안 마련\n\n전문의 사직으로 인한 의료공백이 반년 넘게 이어지면서 의료진과 환자 모두 버티기 힘든 상황이다. 국회 보건복지위는 두 차례에 걸쳐 청문회를 개최했지만 해결의 실마리가 여전히 풀리지 않고 있다. 따라서 이번 복지위 국정감사에서는 의정갈등 해결을 위한 여야의정협의체 구성과 함께 의사단체 참여를 이끌어 낼 대책 마련이 절실한 상황이다.\n\n■1·2·3차 의료체계 확립\n\n국내 의료전달체계는 1·2·3차 의료기관으로 구성돼 있지만 그야말로 유명무실하다. 1·2·3차 의료기관의 상호경쟁구조로 인해 만성질환자가 상급종합병원에서 진료받고 있는 실정. 우리나라에서는 1차 의료기관에서 곧바로 3차 의료기관을 이용할 수 있어 허리 격인 2차 의료기관의 역할이 무너지면서 3차 의료기관의 쏠림현상을 심화시키고 있다. 또 의료전달체계에 대한 법적 규정도 미흡해 이를 마련하는 것도 시급하다.\n\n■지역 공공의료인력 양성\n\n지역 공공의료인력 양성은 지역 간 의료불균형 해소와 공공의료서비스의 질 향상을 위한 중요한 과제이다. 이를 위해 ▲지역의료인력 교육 및 양성체계 구축 ▲지역의료인력 지원체계 확대 ▲의료인 지역의무근무 ▲의료인프라 확대 등 구체적인 대안이 절실하다. 또 필수의료확충을 위해 제도적‧재정적 지원도 적극적으로 이뤄져야 한다. [...] ■간병비 급여화 도입\n\n간병비 부담이 턱없이 높아지고 있다. 특히 저소득층의 가계부담을 낮추고 향후 체계적인 간병서비스를 제공하기 위해선 간병비 급여화 도입이 시급하다. 하지만 간병비를 급여화하기 위해서는 넘어야 할 산이 많다. 정부의 재정문제를 비롯해 국민부담이 가중된다는 우려가 있는 만큼 국민과 정부, 관련기관 간의 긴밀한 사회적 합의가 필요한 상황이다.\n\n■야간·휴일 소아의료체계(달빛어린이병원) 개선\n\n월요일에 환자가 몰리는 소아과 ‘오픈런 현상’이 일어나는 등 소아청소년 의료체계가 붕괴되고 있다. 이를 극복하기 위해 정부는 달빛어린이병원제도를 도입했지만 의료기관 참여가 저조한 데다(2024년 9월 기준 전국 94곳) 참여기관이 수도권에 편중돼 있고 휴일 야간진료는 여전히 공백이 있는가 하면 달빛어린이병원 1차 진료 후 연계체계가 미비하다는 점 등이 문제로 지적되면서 제도를 보강해야 한다는 지적이 일고 있다.\n\n한정선·안훈영 기자\n헬스경향\n인신위\nND소프트', 'score': 0.6836946}, {'title': '대한민국의 의료 - 위키백과, 우리 모두의 백과사전', 'url': 'https://ko.wikipedia.org/wiki/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD%EC%9D%98_%EC%9D%98%EB%A3%8C', 'content': '대한민국의 저수가 정책은 의료기관 경영을 매우 어렵게 만들고, 진료행태가 왜곡되고 의료인의 배출 및 분포에도 악영향을 미치고 있으며, 수가구조와 개정 과정의 합리성이 미흡하여 수가조정이 체계적이지 못하며 관련 전문단체의 참여가 어렵다는 지적이 있다. 정부실패는 의료 종사자들의 반대를 촉발했고 파업과 공개 토론으로 이어졌다. 의료종사자들에게 충분한 의료 수가와 근로조건을 주지 않는 의료정책은 특정 분야 전문의들의 부족현상을 초래했다. 대한민국의 의료산업은 전 국민 건강보험가입에 기반을 둔 보장성 위주의 정책을 통해 발전해왔다. 다른 나라의 벤치마크 대상이 될 정도로 좋은 성과를 보였으나, 낮은 의료수가로 인하여 의료기관의 수익성 악화로 인해 의료기관간의 출혈경쟁, 과다진료 등의 특징도 있다. 건강보험 재정 부담을 국민과 정부가 분담하기 위해 법으로 정한 국고 지원 기준은 지켜지지 않는다.\n\n## 지방의료원\n\n대한민국의 의료 시스템은 도시와 농촌 간의 건강 격차, 잘 정립된 1차 의료 시스템의 부족, 만성 질환의 더 큰 부담을 가져올 가능성이 높은 인구 고령화, 병원의 과밀 및 긴 대기 시간을 포함하여 여러 가지 문제에 직면해 있다. 정부는 도농 간 건강 격차를 제대로 해소하지 못했다. 시골 거주자는 도시 거주자보다 노쇠와 노화 관련 건강 문제에 대해 불균형적으로 더 큰 부담을 가지고 있다. 이는 농촌 지역의 민간 의료 시설에 대한 접근성 부족을 포함하여 여러 가지 요인 때문이다. 정부는 의료 격차를 해소하기 위해 의사들에게 적절한 근무 조건을 제공하지 못했다. [...] 지방의료원은 비급여 진료의 비중이 작고, 저수익의 필수의료 및 취약계층에 대한 진료 비중이 높기 때문에, 그리고 적정 규모와 인력, 시설, 장비 등을 갖추지 못하였기 때문에, 수입보다 비용이 더 많이 발생한다.\n\n## 병원\n\n인구 1000명당 병상 수는 10개로 OECD 국가 평균 5개보다 훨씬 많다. Mark Britnell에 따르면 병원이 의료 시스템을 지배하고 있다. 병원의 94% (병상의 88%)가 개인 소유이고 43개의 대형 병원 중 30개는 사립 대학에서 운영하고 10 개 이상의 공립 대학이 운영한다. 지불은 서비스 당 요금으로 이루어지고 병원에 대한 직접적인 정부 보조금은 없다. 이것은 병원이 지역 사회 서비스를 확장하고 억제하도록 장려한다.\n\n## 같이 보기\n\n## 각주\n\n`|이름1=`\n`|성1=`\n`|access-date=`\n\nWikimedia Foundation\nPowered by MediaWiki [...] ## 비교\n\n한국 의료의 질은 세계 최고로 꼽힌다. OECD에서 가장 높은 72.8 %의 대장 암 생존율을 자랑한다. 다른 나라의 대장 암 생존율은 덴마크는 55.5%, 영국은 54.5 %이다. 출혈성 뇌졸중 은 100건당 30 건의 병원 내 사망률로 OECD에서 세 번째로 낮은 사망자 수인 13.7 명을 기록하고있다. 이와 같은 기록으로 미국은 22.3 명, 프랑스는 24명이며, 이는 사망자의 절반에 가까운 수치이다. 또한 뇌졸중에서는 3,4명으로 두번째 순위를 기록하고 있으며, 호주 9.4 명 또는 캐나다 9.7 명 사망의 거의 1/3에 해당한다. 한국의 병원은 OECD에서 1 인당 MRI 단위에서 4 위, 1인당 CT 스캐너에서 6위를 차지했다. 또한 OECD에서 두 번째로 많은 병상 수인 9.56 개로 스웨덴의 2.71 개, 캐나다의 2.75 개, 영국의 2.95 개, 미국의 3.05 개로 3배가 넘었다.\n\n## 의료정책의 거버넌스', 'score': 0.42133808}]의사협회의 우려에 대해 충분히 이해하고 있으며, 의료 서비스의 질 저하나 의료비용 증가와 같은 문제를 방지하기 위한 방안을 마련하는 것이 중요하다는 점에 동의합니다. 그러나 의대 정원 확대가 단순히 의사 수를 늘리는 것이 아니라, 의료 서비스의 질을 향상시키고, 국민의 건강을 증진시키는 데 필수적인 조치라는 점을 강조하고 싶습니다.
2024년 1/4분기 기준으로 최근 공개된 의료인력 분포 현황 데이터를 분석한 결과, 우리나라의 의료인력은 수도권과 대도시에 심각하게 편중되어 있음이 확인되었습니다. 이러한 불균형은 지역주민의 의료서비스 접근성을 제한하고, 의료의 질적 격차를 심화시키는 주요 원인이 되고 있습니다([출처](https://contents.premium.naver.com/aatto/smart/contents/241204221527357nb)). 이는 의료 인력의 지역적 불균형 문제를 해결하기 위해서는 의대 정원의 확대가 필요함을 시사합니다.
또한, 공공·지역의료 의사 부족 현황에 대한 최근 보고에 따르면, 2024년 현재 공공·지역의료에 필요한 의사가 5,270명 부족한 상태로, 이는 2024년보다 972명 더 증가한 수치입니다([출처](http://m.sisatotalnews.com/article.php?aid=1760489087406324002)). 이는 의료 인력 부족 문제가 심각하며, 특히 지역 공공의료 분야에서 더욱 두드러지고 있음을 보여줍니다.
정부는 의대 정원 확대와 함께 의료 인력의 질적 향상을 위한 교육 프로그램 개발 및 지원을 강화할 계획입니다. 이를 통해 의료 서비스의 질을 유지하고 향상시키며, 의료비용 증가를 최소화할 수 있을 것입니다. 의료 인력의 양적 확대와 질적 향상이 동시에 이루어질 때, 국민 건강 증진과 의료 서비스의 질 향상을 실현할 수 있을 것입니다.
정부는 의사협회와의 지속적인 대화와 협력을 통해 의대 정원 확대 정책을 신중하게 추진하고, 의료계의 우려를 해소하기 위한 방안을 모색할 것입니다. 함께 협력하여 국민의 건강과 의료 서비스의 질을 향상시키는 것이 우리 모두의 목표입니다.
> Finished chain.
(Government(대한민국 정부)): 의사협회의 우려에 대해 충분히 이해하고 있으며, 의료 서비스의 질 저하나 의료비용 증가와 같은 문제를 방지하기 위한 방안을 마련하는 것이 중요하다는 점에 동의합니다. 그러나 의대 정원 확대가 단순히 의사 수를 늘리는 것이 아니라, 의료 서비스의 질을 향상시키고, 국민의 건강을 증진시키는 데 필수적인 조치라는 점을 강조하고 싶습니다.
2024년 1/4분기 기준으로 최근 공개된 의료인력 분포 현황 데이터를 분석한 결과, 우리나라의 의료인력은 수도권과 대도시에 심각하게 편중되어 있음이 확인되었습니다. 이러한 불균형은 지역주민의 의료서비스 접근성을 제한하고, 의료의 질적 격차를 심화시키는 주요 원인이 되고 있습니다([출처](https://contents.premium.naver.com/aatto/smart/contents/241204221527357nb)). 이는 의료 인력의 지역적 불균형 문제를 해결하기 위해서는 의대 정원의 확대가 필요함을 시사합니다.
또한, 공공·지역의료 의사 부족 현황에 대한 최근 보고에 따르면, 2024년 현재 공공·지역의료에 필요한 의사가 5,270명 부족한 상태로, 이는 2024년보다 972명 더 증가한 수치입니다([출처](http://m.sisatotalnews.com/article.php?aid=1760489087406324002)). 이는 의료 인력 부족 문제가 심각하며, 특히 지역 공공의료 분야에서 더욱 두드러지고 있음을 보여줍니다.
정부는 의대 정원 확대와 함께 의료 인력의 질적 향상을 위한 교육 프로그램 개발 및 지원을 강화할 계획입니다. 이를 통해 의료 서비스의 질을 유지하고 향상시키며, 의료비용 증가를 최소화할 수 있을 것입니다. 의료 인력의 양적 확대와 질적 향상이 동시에 이루어질 때, 국민 건강 증진과 의료 서비스의 질 향상을 실현할 수 있을 것입니다.
정부는 의사협회와의 지속적인 대화와 협력을 통해 의대 정원 확대 정책을 신중하게 추진하고, 의료계의 우려를 해소하기 위한 방안을 모색할 것입니다. 함께 협력하여 국민의 건강과 의료 서비스의 질을 향상시키는 것이 우리 모두의 목표입니다.
> Entering new AgentExecutor chain...
정부의 의견에 대해 의사협회는 여전히 의료 인력의 지역적 불균형과 고령화 사회 대응을 위한 의대 정원 확대의 필요성을 인정하면서도, 이러한 정책이 실제로 의료 서비스의 질을 향상시키고 국민 건강을 증진시킬 수 있는지에 대한 근본적인 의문을 제기합니다. 의사협회는 의료 인력의 양적 확대만이 아니라, 질적 향상에도 중점을 둔 정책이 필요하다고 강조합니다.
의료 인력의 지역적 불균형 문제는 단순히 의대 정원을 확대하는 것만으로 해결될 수 있는 문제가 아닙니다. 의료 인력이 지방으로 분산되도록 유도하는 정책, 지방에서의 의료 활동에 대한 인센티브 제공, 지방 의료 기관의 인프라 개선 등 다각적인 접근이 필요합니다. 의대 정원을 확대한다 하더라도, 졸업 후 의사들이 여전히 대도시로 집중되는 현상을 방지할 수 있는 구체적인 대책이 마련되어야 합니다.
또한, 의료 서비스의 질적 향상을 위해서는 의료 교육의 질을 높이고, 실제 의료 현장에서 필요한 역량을 갖춘 의사를 양성하는 것이 중요합니다. 이를 위해 의료 교육 과정의 개선, 임상 실습의 질 관리 강화, 지속적인 전문 교육의 제공 등이 필요합니다.
의사협회는 정부와의 지속적인 대화를 통해 의료 인력의 양적 확대뿐만 아니라 질적 향상을 위한 구체적이고 실질적인 방안을 모색하고, 의료 서비스의 질을 유지하고 향상시키며 국민 건강을 증진시킬 수 있는 정책을 함께 개발해 나가길 희망합니다. 의대 정원 확대 정책의 신중한 재검토와 함께, 의료 인프라 개선, 의료 서비스 질 관리, 그리고 의료비용 통제에 대한 구체적인 계획이 수립되어야 할 것입니다.
> Finished chain.
(Doctor Union(의사협회)): 정부의 의견에 대해 의사협회는 여전히 의료 인력의 지역적 불균형과 고령화 사회 대응을 위한 의대 정원 확대의 필요성을 인정하면서도, 이러한 정책이 실제로 의료 서비스의 질을 향상시키고 국민 건강을 증진시킬 수 있는지에 대한 근본적인 의문을 제기합니다. 의사협회는 의료 인력의 양적 확대만이 아니라, 질적 향상에도 중점을 둔 정책이 필요하다고 강조합니다.
의료 인력의 지역적 불균형 문제는 단순히 의대 정원을 확대하는 것만으로 해결될 수 있는 문제가 아닙니다. 의료 인력이 지방으로 분산되도록 유도하는 정책, 지방에서의 의료 활동에 대한 인센티브 제공, 지방 의료 기관의 인프라 개선 등 다각적인 접근이 필요합니다. 의대 정원을 확대한다 하더라도, 졸업 후 의사들이 여전히 대도시로 집중되는 현상을 방지할 수 있는 구체적인 대책이 마련되어야 합니다.
또한, 의료 서비스의 질적 향상을 위해서는 의료 교육의 질을 높이고, 실제 의료 현장에서 필요한 역량을 갖춘 의사를 양성하는 것이 중요합니다. 이를 위해 의료 교육 과정의 개선, 임상 실습의 질 관리 강화, 지속적인 전문 교육의 제공 등이 필요합니다.
의사협회는 정부와의 지속적인 대화를 통해 의료 인력의 양적 확대뿐만 아니라 질적 향상을 위한 구체적이고 실질적인 방안을 모색하고, 의료 서비스의 질을 유지하고 향상시키며 국민 건강을 증진시킬 수 있는 정책을 함께 개발해 나가길 희망합니다. 의대 정원 확대 정책의 신중한 재검토와 함께, 의료 인프라 개선, 의료 서비스 질 관리, 그리고 의료비용 통제에 대한 구체적인 계획이 수립되어야 할 것입니다.
마무리
이번 포스트에서는 LangChain을 이용한 AI Agent에 대해서 알아보았습니다. AI Agent는 이전에 배웠던 RAG의 파이프라인 넘어서 여러 도구(Tools)를 정의해 LLM에게 사용자가 원하는 답변을 유도하도록 하거나, 벡터 DB에 저장한 검색 문서와 함께 웹 상에서 입력 쿼리와 연관된 문서도 함께 LLM에 전달하여 좀 더 퀄리티 높은 답변을 유도하도록 할 수 있다는 것을 알 수 있었고, Agent를 이용하면 단순히 텍스트 답변만이 아닌 이미지, 그리고 보고서와 같은 텍스트 파일도 결과물로 도출하게 할 수 있다는 것을 알 수 있었습니다. 이번엔 간단히 Agent가 무엇인지 대략적으로 알아보는 시간으로 간단한 예제만 알아보았지만 이후에는 구현하고자 하는 목표를 정해 그에 맞는 도구와 Agent를 정의하여 특수한 목적에 맞는 AI Agent를 만들어 보도록 하겠습니다.
긴 글 읽어주셔서 감사드리며, 본문 내용 중에 잘못된 내용이나 오타 궁금하신 사항이 있으실 경우 댓글 남겨주시기 바랍니다.
참조
- 테디노트 - LangChain 한국어 튜토리얼KR(https://wikidocs.net/book/14314)
Comments