
[LLM/RAG] LLM Application - 5. RAG 성능 향상
개요
이번 포스트에서는 이전 포스트에서 알아 보았던 문장 임베딩을 생성하는 교차 인코더와 바이 인코더를 어떻게 활용하면 RAG 모델의 성능을 향상 시킬 수 있는지에 대해서 알아보도록 하겠습니다. 이번 포스트에서는 모델들을 직접 학습까지 시켜보도록 하겠습니다. 즉, 한국어 데이터를 이용해 문장 임베딩 모델의 미세 조정하는 실습까지 진행하도록 하겠습니다. 이번에 사용할 교차 인코더 모델은 느리기 때문에 대규모 데이터의 유사도를 계산하는 데 사용하지 않고 바이 인코더를 통해 선별된 소수의 데이터를 대상으로 더 정확한 유사도 계산을 위해 사용합니다. 교차 인코더를 활용해 필터링된 문장 사이의 유사도를 계산하고 순위를 변경하는 것을 순위 재정렬(re-rank)이라고 합니다. 교차 인코더를 사용해 문장 사이의 유사도를 계산하는 방법을 알아보고, 한국어 데이터를 활용해 실습을 진행합니다. 마지막으로, 실습을 통해 만든 바이 인코더와 교차 인코더를 결합해 RAG의 검색 성능을 높여 보는 실습을 통해 더 발전된 RAG를 구성하는 방법에 대해서도 알아보도록 하겠습니다.
실습에 들어가기 전에 사용하는 라이브러리 들은 다음과 같습니다. pip 명령어를 이용해 설치를 진행해 주시기 바랍니다. 버전은 가장 최신 버전을 사용했습니다.
sentence-transformers, datasets, huggingface_hub, faiss-cpu
1. 검색 성능을 높이기 위한 두 가지 방법
문장의 유사도를 계산할 때 바이 인코더와 교차 인코더를 사용할 수 있습니다. 교차 인코더는 비교하려는 두 문장을 직접 입력으로 받아 비교하기 때문에 유사도를 더 정확하게 계산할 순 있지만, 유사도를 계산하려는 조합의 수만큼 모두 모델의 내부 계산을 진행해야 하기 때문에 속도가 매우 느려 학습과 서비스 제공에 큰 차질이 있습니다. 바이 인코더를 사용하면 독립적인 문장 임베딩 사이의 유사도를 가벼운 벡터 연산을 통해 계산하기 때문에 빠른 검색이 가능합니다. 하지만 바이 인코더는 교차 인코더만큼 정확하게 유사도를 계산하기 어렵습니다. 하지만 두 모델을 결합해서 사용한다면 교차 인코더의 장점과 바이 인코더의 장점을 모두 사용할 수 있습니다.
아래 그림과 같이 바이 인코더와 교차 인코더를 결합해 사용할 수 있습니다. 바이 인코더는 대규모 문서에서 검색 쿼리와 유사한 소수의 문서를 선별 합니다. 선별된 문서는 유사도를 더 정확히 계산할 수 있는 교차 인코더를 사용해 유사한 순서대로 재정렬합니다. 교차 인코더는 계산량이 많지만 소수의 선별된 문서를 대상으로 계산하기 때문에 정확하면서도 빠르게 계산할 수 있습니다.
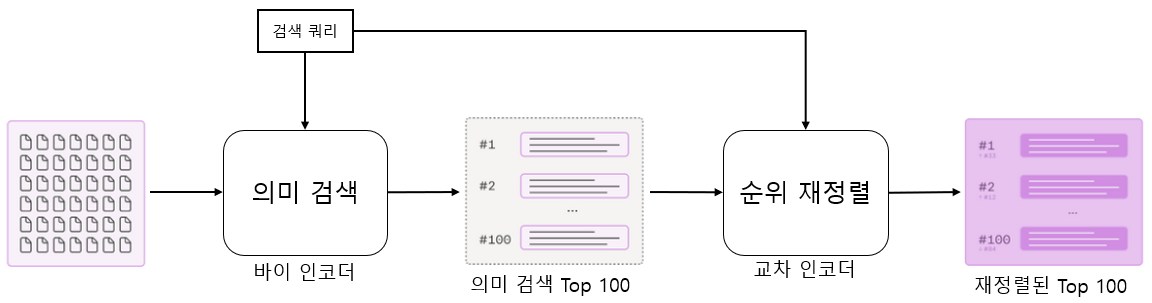
그리고 이번에는 사용하는 모델에 미세 조정을 해 좀 더 성능을 높여보고자 합니다. 이전 포스트에서는 허깅페이스 모델 허브에서 사전 학습된 문장 임베딩 모델을 불러와 그대로 사용했습니다. 이번엔 사용하는 데이터셋으로 추가 학습해 검색 성능을 더 높일 수 있습니다. 그럼 이제부터 언어 모델을 문장 임베딩 모델로 변환하는 방법과 문장 임베딩 모델을 추가 학습하는 방법에 대해서 알아보도록 하겠습니다.
2. 언어 모델을 임베딩 모델로 만들기
2.1 대조 학습
문장 임베딩 모델을 학습시킬 때는 일반적으로 대조 학습(contrastive learning)을 사용합니다. 대조 학습이란, 관련이 있거나 유사한 데이터는 더 가까워지도록 하고 관련이 없거나 유사하지 않은 데이터는 더 멀어지도록 하는 학습 방식입니다. 대조 학습을 통해 임베딩 모델을 학습시킬 때 다양한 데이터를 사용할 수 있습니다. 예를 들면 임베딩 모델에 두 개의 문장을 각각 입력하고 서로 유사한 데이터인 경우는 가깝게, 서로 유사하지 않은 경우는 멀게 만들 수 있습니다. 마지막으로 두 문장이 서로 질문과 답변 관계인 경우 가깝도록, 아닌 경우 멀도록 학습시킬 수도 있습니다.
2.2 학습 준비하기
언어 모델을 임베딩 모델로 만들기 전에, 허깅페이스 모델 허브의 언어 모델을 그대로 불러와 사용해도 문장의 의미를 반영한 문장 임베딩을 잘 만들 수 있는지 확인해 보도록 하겠습니다.
언어 모델을 임베딩 모델로 만들기 전에, 허깅페이스 모델 허브의 언어 모델을 그대로 불러와 사용해도 문장의 의미를 반영한 문장 임베딩을 잘 만드는지 한 번 확인해 보도록 하겠습니다. 아래 예제는 Sentence-Transformers 라이브러리의 models 모듈을 활용해 klue/roberta-base 모델을 불러오고, 평균 풀링 층을 만들었습니다. 마지막으로 SentenceTransformer 클래스로도 모듈을 결합해 문장 임베딩 모델을 만들었습니다. 현재는 언어 모델을 학습시키지 않았기 때문에 지금의 문장 임베딩 모델은 언어 모델의 출력을 단순히 평균 내어 차원의 벡터로 만들 뿐입니다.
# 사전 학습된 언어 모델을 불러와 문장 임베딩 모델 만들기
from sentence_transformers import SentenceTransformer, models
transformer_model = models.Transformer('klue/roberta-base')
pooling_layer = models.Pooling(
transformer_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True
)
embedding_model = SentenceTransformer(
modules=[transformer_model, pooling_layer]
)
이제 문장 임베딩 모델이 의미를 담아 임베딩을 잘 생성하는지 확인하는데 사용할 데이터셋을 불러오도록 하겠습니다. 이번 실습에서는 KLUE의 STS(Sentence Textual Similarity) 데이터셋을 사용합니다. KLUE STS 데이터셋은 2개의 문장이 서로 얼마나 유사한지 점수를 매긴 데이터셋입니다. 데이터의 형태를 확인하면 sentence1과 sentence2 컬럼에 문장이 있고, labels 컬럼에 두 문장이 얼마나 유사한지를 나타내는 다양한 형식의 레이블이 있습니다. 이번 실습에서는 소수점 한 자리까지 나타낸 label 점수를 사용합니다.
# 실습 데이터셋 다운로드 및 확인
from datasets import load_dataset
klue_sts_train = load_dataset('klue', 'sts', split='train')
klue_sts_test = load_dataset('klue', 'sts', split='validation')
print(klue_sts_train[0])
Output:
{'guid': 'klue-sts-v1_train_00000', 'source': 'airbnb-rtt', 'sentence1': '숙소 위치는 찾기 쉽고 일반적인 한국의 반지하 숙소입니다.', 'sentence2': '숙박시설의 위치는 쉽게 찾을 수 있고 한국의 대표적인 반지하 숙박시설입니다.', 'labels': {'label': 3.7, 'real-label': 3.714285714285714, 'binary-label': 1}}
이번 실습에서는 세 가지 데이터 전처리를 수행합니다.
- 학습 데이터의 일부를 검증하기 위한 데이터셋으로 분리합니다.
- 유사도 점수를 0~1 사이로 정규화합니다.
- torch.utils.data.DataLoader를 사용해 배치 데이터로 만듭니다.
먼저 학습 데이터 중 10%를 학습이 잘 진행되는지 확인할 때 사용할 검증 데이터로 분리합니다. 학습 데이터와 검증 데이터를 동일하게 분리할 수 있도록 seed=42로 설정했습니다.
# 학습 데이터셋의 10%를 검증 데이터셋으로 구성한다.
klue_sts_train = klue_sts_train.train_test_split(test_size=0.1, seed=42)
klue_sts_train, klue_sts_eval = klue_sts_train['train'], klue_sts_train['test']
print(f"학습 데이터의 크기 : {len(klue_sts_train)}")
print(f"검증 데이터의 크기 : {len(klue_sts_eval)}")
Output:
학습 데이터의 크기 : 10501
검증 데이터의 크기 : 1167
이제 유사도 점수를 0~1 사이로 정규화하고 Sentence-Transformers에서 데이터를 관리하는 형식인 InputExample 클래스를 사용해 데이터를 준비합니다. prepare_sts_examples 함수는 데이터셋을 입력으로 받아 데이터셋을 순회하면서 InputExample 클래스에 텍스트 쌍을 리스트 형태로 입력하고 원본 데이터셋에는 0~5점 척도로 되어 있는 label 점수를 5로 나눠 0~1 범위로 정규화합니다.
# label 정규화하기
from sentence_transformers import InputExample
# 유사도 점수를 0~1 사이로 정규화하고 InputExample 객체에 담는다.
def prepare_sts_examples(dataset):
examples = []
for data in dataset:
examples.append(
InputExample(
texts = [data['sentence1'], data['sentence2']],
label=data['labels']['label'] / 5.0
)
)
return examples
print(klue_sts_train[0]['labels'])
klue_sts_train_examples = prepare_sts_examples(klue_sts_train)
print(klue_sts_train_examples[0].label)
Output:
{'label': 3.4, 'real-label': 3.428571428571428, 'binary-label': 1}
0.6799999999999999
train_examples = prepare_sts_examples(klue_sts_train)
eval_examples = prepare_sts_examples(klue_sts_eval)
test_examples = prepare_sts_examples(klue_sts_test)
이제 학습 데이터셋은 파이토치의 DataLoder 클래스를 사용해 배치 데이터로 만들어줍니다.
# 학습에 사용할 배치 데이터셋 만들기
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
남은 검증 데이터셋과 평가 데이터셋은 Sentence-Transformers 라이브러리에서 제공하는 EmbeddingSimilarityEvaluator 클래스를 사용해 임베딩 모델의 성능을 평가할 때 사용할 수 있도록 준비합니다. 아래 예제에서는 EmbeddingSimilarityEvaluator 클래스의 from_input_examples 메서드를 사용해 검증 데이터셋과 평가 데이터셋을 사용하는 평가 객체를 생성합니다.
# 검증을 위한 평가 객체 준비
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
eval_evaluator = EmbeddingSimilarityEvaluator.from_input_examples(eval_examples)
test_evaluator = EmbeddingSimilarityEvaluator.from_input_examples(test_examples)
이제 아무런 학습을 하지 않은 기본 언어모델로 만든 embedding_model이 얼마나 문장의 의미를 잘 반영해 문장 임베딩을 생성하는지 확인해 보도록 하겠습니다. test_evaluator을 이용해 아까 정의해둔 embedding_model을 평가해 보았습니다. 평가는 데이터셋의 정답 유사도 점수와 embedding_model을 사용해 측정한 유사도 점수를 비교해 문장 임베딩 모델이 얼마나 잘 작동하는지 평가합니다.
# 언어 모델을 그대로 활용할 경우 문장 임베딩 모델의 성능
test_evaluator(embedding_model)
출력 결과로 pearson_cosine 값은 대략 0.34, spearman_cosine 값은 대략 0.35값이 나옵니다. 여기서 pearson_cosine은 피어슨 상관계수를 이용한 것으로 현재 데이터 구성은 문장A와 문장B 그리고 사람이 매긴 값으로 구성되어 있습니다. 여기서 모델의 성능 평가를 진행할 때 모델이 만든 문장A와 문장B의 임베딩 값을 이용해 유사도 값을 구합니다. 그리고 사람이 매긴 유사도 값과 모델이 만든 유사도 값을 피어슨 상관계수를 이용해 계산된 값입니다. 두 번째로 spearman_cosine은 pearson_cosine과 동일하게 우선 모델을 이용해 유사도 값을 구합니다. 그리고 사람이 매긴 유사도 값으로 순위를 세우고, 모델이 만든 값으로도 순위를 세웁니다. 그리고 사람이 매긴 값으로 세운 순위와 모델이 만든 값으로 세운 순위가 얼마나 비슷한지를 가지고 점수를 계산한 값입니다. 일반적으로 이런 문장 유사도(STS) 태스크에서는 보통 피어슨 보다 스피어만 상관꼐수를 더 중요한 지표로 본다고 합니다.
Output:
{'pearson_cosine': 0.347707041961158, 'spearman_cosine': 0.35560473197486514}
2.3 유사한 문장 데이터로 임베딩 모델 학습하기
이제 언어모델 학습을 진행해 보도록 하겠습니다. 학습 방법은 CosineSimilarityLoss를 사용하는데, 학습 데이터를 문장 임베딩으로 변환하고 두 문장 사이의 코사인 유사도와 정답 유사도를 비교해 학습을 수행하는 방식으로 학습을 진행합니다. fit() 메서드에 앞서 준비한 학습 데이터셋과 손실 함수, 검증에 사용할 평가 객체(eval_evaluator) 등 인자를 전달하면 학습이 진행됩니다.
# 임베딩 모델 학습
from sentence_transformers import losses
num_epochs = 4
model_name = 'klue/roberta-base'
model_save_path = '/content/drive/MyDrive/LLM_RAG_Application/models/training_sts_' + model_name.replace("/", "-")
train_loss = losses.CosineSimilarityLoss(model=embedding_model)
# 임베딩 모델 학습
embedding_model.fit(
train_objectives=[(train_dataloader, train_loss)],
evaluator=eval_evaluator,
epochs=num_epochs,
evaluation_steps=1000,
warmup_steps=100,
output_path=model_save_path
)
학습이 끝나면 아래 코드를 실행해 학습한 모델의 성능을 확인해 봅니다. 출력 결과를 확인하면 학습 전에 대략 0.35 였던 점수가 0.89로 크게 향상된 것을 볼 수 있습니다.
# 학습한 임베딩 모델의 성능 평가
trained_embedding_model = SentenceTransformer(model_save_path)
test_evaluator(trained_embedding_model)
Output:
{'pearson_cosine': 0.8905083131274608, 'spearman_cosine': 0.8905864813839348}
학습한 모델은 나중에 다시 불러와 사용할 수 있도록 본인의 허깅페이스 허브에 저장합니다.
# 허깅페이스 허브에 모델 저장
from huggingface_hub import HfApi
api = HfApi()
repo_id = "klue-roberta-base-klue-sts"
api.create_repo(repo_id=repo_id)
api.upload_folder(
folder_path=model_save_path,
repo_id=f"본인의 허깅페이스 아이디 입력/{repo_id}",
repo_type="model"
)
지금까지 사전 학습된 언어 모델을 불러와 KLUE STS 데이터셋을 사용해 문장 임베딩 모델로 잘 동작하도록 하기 위해 학습까지 하는 실습을 진행했습니다. 그럼 이제 의미 검색을 좀 더 잘하도록 하기 위해 KLUE의 MRC 데이터를 이용해 미세 조정하는 실습을 진행해 보도록 하겠습니다.
3. 임베딩 모델 미세 조정하기
RAG는 검색 쿼리와 관련된 문서를 찾아 LLM 프롬프트에 맥락 데이터로 추가 할 때 임베딩 모델을 활용합니다. 그렇기 때문에 좋은 임베딩 모델이라면 검색 쿼리와 관련이 있는 문서는 유사도가 높게 나오고 관련이 없는 문서는 유사도가 낮게 나와야 합니다. 그러므로 이전에 KLUE STS 데이터로 학습을 진행한 임베딩 모델에 KLUE의 MRC 데이터셋으로 추가 학습시켜, 실습 데이터의 문장 사이의 유사도를 더 잘 계산할 수 있도록 만들어 보도록 하겠습니다.
우리는 RAG를 이용해 LLM의 성능을 높여야 합니다. 그렇다면 RAG의 성능을 향상시켜야 합니다. 그러기 위해선 의미 검색을 수행하는 임베딩 모델의 성능을 향상시켜야 합니다. 임베딩 모델도 다른 딥러닝 모델과 마찬가지로 학습 데이터와 유사한 데이터에서 가장 잘 동작합니다. 만약 사전 학습된 임베딩 모델을 그대로 사용하는 경우 사전 학습에 사용된 데이터셋이 실습에 사용하는 데이터셋과 단어, 주제 등이 다르면 성능이 낮아집니다. 그렇기 때문에 MRC 데이터셋에 임베딩 모델을 활용하려는 경우 그 목적에 맞게 MRC 데이터셋으로 미세 조정해 주어야 합니다.
3.1 학습 준비
KLUE의 MRC 데이터셋을 사용해 실습을 진행해 보도록 하겠습니다. KLUE의 MRC 데이터셋은 기사 본문 및 해당 기사와 관련된 질문을 수집한 데이터셋입니다. 그럼 데이터셋을 내려받고 데이터셋의 구성을 한 번 살펴보도록 하겠습니다.
# 실습 데이터를 내려받고 예시 데이터 확인
from datasets import load_dataset
klue_mrc_train = load_dataset('klue', 'mrc', split='train')
klue_mrc_train[0]
첫 번째 데이터를 한 번 출력해 보면 기사 제목은 title 컬럼에 기사 본문은 context 기사와 관련된 질문은 question 컬럼에 있는 것을 확인할 수 있습니다.
Output:
{'title': '제주도 장마 시작 … 중부는 이달 말부터',
'context': '올여름 장마가 17일 제주도에서 시작됐다. 서울 등 중부지방은 예년보다 사나흘 정도 늦은 이달 말께 장마가 시작될 전망이다.17일 기상청에 따르면 제주도 남쪽 먼바다에 있는 장마전선의 영향으로 이날 제주도 산간 및 내륙지역에 호우주의보가 내려지면서 곳곳에 100㎜에 육박하는 많은 비가 내렸다. 제주의 장마는 평년보다 2~3일, 지난해보다는 하루 일찍 시작됐다. 장마는 고온다습한 북태평양 기단과 한랭 습윤한 오호츠크해 기단이 만나 형성되는 장마전선에서 내리는 비를 뜻한다.장마전선은 18일 제주도 먼 남쪽 해상으로 내려갔다가 20일께 다시 북상해 전남 남해안까지 영향을 줄 것으로 보인다. 이에 따라 20~21일 남부지방에도 예년보다 사흘 정도 장마가 일찍 찾아올 전망이다. 그러나 장마전선을 밀어올리는 북태평양 고기압 세력이 약해 서울 등 중부지방은 평년보다 사나흘가량 늦은 이달 말부터 장마가 시작될 것이라는 게 기상청의 설명이다. 장마전선은 이후 한 달가량 한반도 중남부를 오르내리며 곳곳에 비를 뿌릴 전망이다. 최근 30년간 평균치에 따르면 중부지방의 장마 시작일은 6월24~25일이었으며 장마기간은 32일, 강수일수는 17.2일이었다.기상청은 올해 장마기간의 평균 강수량이 350~400㎜로 평년과 비슷하거나 적을 것으로 내다봤다. 브라질 월드컵 한국과 러시아의 경기가 열리는 18일 오전 서울은 대체로 구름이 많이 끼지만 비는 오지 않을 것으로 예상돼 거리 응원에는 지장이 없을 전망이다.',
'news_category': '종합',
'source': 'hankyung',
'guid': 'klue-mrc-v1_train_12759',
'is_impossible': False,
'question_type': 1,
'question': '북태평양 기단과 오호츠크해 기단이 만나 국내에 머무르는 기간은?',
'answers': {'answer_start': [478, 478], 'text': ['한 달가량', '한 달']}}
방금 전 KLUE STS 데이터셋으로 학습한 임베딩 모델을 불러옵니다.
# 기본 임베딩 모델 불러오기
from sentence_transformers import SentenceTransformer
sentence_model = SentenceTransformer('Laseung/klue-roberta-base-klue-sts')
실습에 사용할 KLUE의 MRC 데이터셋을 불러옵니다. 전처리 하기 쉽도록 to_pandas 메서드를 사용해 판다스 데이터프레임으로 변환합니다. 그리고 필요한 3개의 컬럼(title, question, context)을 제외한 나머지 컬럼을 제거 합니다.
#데이터 전처리
from datasets import load_dataset
klue_mrc_train = load_dataset('klue', 'mrc', split='train')
klue_mrc_test = load_dataset('klue', 'mrc', split='validation')
df_train = klue_mrc_train.to_pandas()
df_test = klue_mrc_test.to_pandas()
df_train = df_train[['title', 'question', 'context']]
df_test = df_test[['title', 'question', 'context']]
다음으로 데이터프레임에 질문과 관련이 없는 임의의 텍스트를 추가하는 add_ir_context 함수를 정의합니다. MRC 데이터셋에는 서로 대응되는 질문-내용 쌍만 있기 때문에 문장의 유사도를 잘 계산하는지 평가할 때 사용하기 위해 MRC 데이터셋의 질문과 관련이 없는 임의의 텍스트를 irrelevant_context 컬럼에 추가합니다. add_ir_context 함수는 데이터셋을 입력으로 받아 데이터를 순회하면서 질문과 관련이 없는 기사 본문을 찾습니다. MRC 데이터셋에는 동일한 기사 본문에 여러 개의 질문이 대응되어 있는데, 질문과 관련 없는 기사 본문을 가져오기 위해 데이터의 title 컬럼을 확인해 제목이 다른 경우 데이터를 랜덤으로 선택합니다.
# 질문과 관련이 없는 기사를 irrelevant context 컬럼에 추가
def add_ir_context(df):
irrelevant_contexts = []
for idx, row in df.iterrows():
title = row['title']
irrelevant_contexts.append(df.query(f"title != '{title}'").sample(n=1)['context'].values[0])
df['irrelevant_context'] = irrelevant_contexts
return df
df_train_ir = add_ir_context(df_train)
df_test_ir = add_ir_context(df_test)
이제 irrelevant_context 컬럼에 질문과 관련 없는 기사 본문을 추가한 데이터셋을 활용해 임베딩 모델의 성능 평가에 사용할 데이터를 만듭니다. 이 코드에서는 동일한 질문-내용 데이터에 해당하는 question과 context 컬럼은 관련이 있기 때문에 label을 1로 지정하고 서로 관련이 없는 question과 irrelevant_context 컬럼의 텍스트는 label을 0으로 지정합니다.
# 성능 평가에 사용할 데이터 생성
from sentence_transformers import InputExample
examples = []
for idx, row in df_test_ir.iterrows():
examples.append(InputExample(texts=[row['question'], row['context']], label=1))
examples.append(InputExample(texts=[row['question'], row['irrelevant_context']], label=0))
우선 이전에 KLUE STS 데이터로 학습을 진행했던 임베딩 모델로 평가를 먼저 진행해 보도록 하겠습니다. 평가에 사용한 클래스는 이전에 사용했던 EmbeddingSimilarityEvaluator 클래스를 사용해 임베딩 모델의 성능을 측정해 보았습니다.
#기본 임베딩 모델의 성능 평가 결과 확인
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
evaluator = EmbeddingSimilarityEvaluator.from_input_examples(examples)
evaluator(sentence_model)
성능을 보면 pearson_cosine 값은 대략 0.8, spearman_cosine 은 0.81 이 출력되는 것을 확인할 수 있습니다.
Output:
{'pearson_cosine': 0.8061132881580035, 'spearman_cosine': 0.8162661499831387}
3.2 MNR 손실을 활용해 미세 조정하기
이전에 임베딩 모델을 학습 시킬 때는 입력 문장과 더 유사한 임베딩을 만들도록 하기 위해 코사인 유사도 손실을 활용해 모델을 학습시켰습니다. 이번에는 새로운 학습 손실인 MNR(Multiple Negatives Ranking) 손실 함수를 사용해 모델을 미세 조정해 봅니다. MNR 손실은 MRC 데이터셋과 같이 데이터셋에 서로 관련이 있는 문장만 있는 경우 사용하기 좋은 손실 함수입니다. 우리는 앞서 임베딩 모델의 성능 평가를 위해 인위적으로 서로 관련이 없는 질문과 기사 본문을 뽑아 irrelevant_context 컬럼에 추가했었습니다. 하지만 MNR 손실을 사용하면 하나의 배치 데이터 안에서 다른 데이터의 기사 본문을 관련이 없는 데이터로 사용해 모델을 학습시킵니다. 그러므로 서로 관련이 있는 데이터만으로 학습 데이터를 구성하면 됩니다.
# 긍정 데이터만으로 학습 데이터 구성
train_samples = []
for idx, row in df_train_ir.iterrows():
train_samples.append(InputExample(texts=[row['question'], row['context']]))
학습 데이터에 중복 데이터가 포함될 수도 있기 때문에 Sentence-Transformers 라이브러리에서 제공하는 NoDuplicationDataLoader 클래스를 활용해 배치 데이터 안에 중복 데이터를 제거하도록 했습니다. 배치 사이즈는 16으로 하였습니다.
# 중복 학습 데이터 제거
from sentence_transformers import datasets
batch_size = 16
loader = datasets.NoDuplicatesDataLoader(train_samples, batch_size=batch_size)
이제 학습에 사용할 MNR 손실 함수를 불러와 줍니다. Sentence-Transformers 라이브러리에서는 MultipleNegativesRankingLoss 클래스를 통해 MNR 손실을 사용할 수 있습니다.
# MNR 손실 함수 불러오기
from sentence_transformers import losses
loss = losses.MultipleNegativesRankingLoss(sentence_model)
이제 여태까지 준비한 것을 이용해 미세 조정을 진행해 줍니다.
# MRC 데이터셋으로 미세 조정
epochs = 1
save_path = 'output/klue_mrc_mnr'
sentence_model.fit(
train_objectives=[(loader, loss)],
epochs=epochs,
warmup_steps=100,
output_path=save_path,
show_progress_bar=True
)
미세 조정이 끝난 후 다시 성능 평가를 진행해 보았습니다.
# 미세 조정한 모델 성능 평가 확인
evaluator(sentence_model)
pearson_cosine 값은 0.91로 미세 조정 전보다 0.1이 올랐고, spearman_cosine은 0.85로 약 0.04 정도 성능이 오른 것을 확인할 수 있습니다.
Output:
{'pearson_cosine': 0.9123990551586284, 'spearman_cosine': 0.8597953145983039}
미세 조정한 모델은 이후에도 사용할 수 있게 허깅페이스 허브에 업로드 해 둡니다.
# 허깅페이스 허브에 미세 조정한 모델 업로드
from huggingface_hub import HfApi
api = HfApi()
repo_id = "klue-roberta-base-klue-sts-mrc-mnr-finetuned"
api.create_repo(repo_id=repo_id)
api.upload_folder(
folder_path=save_path,
repo_id=f"본인의 허깅페이스 사용자 이름/{repo_id}",
repo_type="model",
)
4. 교차 인코더 학습하기
우리는 문서로부터 검색 쿼리와 가장 유사한 Top 100개의 문장을 찾도록 하기 위해 Bi-Encoder 역할을 하는 언어 모델을 우리가 원하는 태스크에 더 잘 동작하도록 하기 위해 KLUE STS 데이터와 코사인 유사도 손실 함수로 학습을 진행해 임베딩 모델로 만들었고, 우리가 진행하고자 하는 태스크의 학습 데이터인 KLUE MRC 데이터를 이용해 미세 조정까지 진행했습니다. 그렇다면 이제 Bi-Encoder 모델로 뽑은 Top 100개의 문장에서 더 성능을 높이기 위해서 재정렬을 진행할 교차 인코더의 학습을 진행해 보도록 하겠습니다.
교차 인코더의 학습은 문장 분류 모델을 활용합니다. 유사도를 계산하는 2개의 문장을 입력으로 받아 ‘관련이 있는지’, ‘관련이 없는지’로 분류하는 문제로 볼 수 있기 때문입니다. 문장 분류 문제이므로 허깅페이스 transformers 라이브러리로 모델을 직접 학습하는 방식도 가능하긴 하지만 sentence-transformers에서 제공하는 CrossEncoder와 미세 조정 메서드를 사용합니다.
실습을 진행하기 위해 아래와 같이 허깅페이스 허브에서 모델을 불러옵니다. 지금까지 사용한 SentenceTransformer 클래스를 사용하지 않고 교차 인코더를 위한 CrossEncoder 클래스를 사용합니다. 교차 인코더는 많은 계산을 해야 하기 때문에 파라미터 수가 작은 klue/roberta-small 모델을 사용합니다.
# 교차 인코더 사용할 사전 학습 모델 불러오기
from sentence_transformers import CrossEncoder
cross_model = CrossEncoder('klue/roberta-small', num_labels=1)
klue/roberta-small 모델은 분류 헤드가 없는 언어 모델이기 때문에 교차 인코더로 불러오면 분류 헤드는 랜덤으로 초기화됩니다. 그렇다면 학습을 하지 않고 초기 벡터 값이 랜덤일 때 성능이 어떤지 확인하기 위해 이전에 미세 조정한 임베딩 모델을 평가할 때 사용한 KLUE MRC 데이터셋으로 만든 평가 데이터를 이용해 평가를 진행해 보도록 하겠습니다.
# 미세 조정하지 않은 교차 인코더의 성능 평가 결과
from sentence_transformers.cross_encoder.evaluation import CECorrelationEvaluator
ce_evaluator = CECorrelationEvaluator.from_input_examples(examples)
ce_evaluator(cross_model)
평가 결과로 pearson_cosine은 -0.011, spearman_cosine은 -0.0119인 것을 확인할 수 있습니다. 여기서 중요한 것은 음수값 보다는 음수값이지만 그 값이 0에 아주 가깝기 때문에 현재 모델의 출력은 무의미한 출력이라는 것을 볼 수 있습니다.
Output:
{'pearson': -0.011721197787276438, 'spearman': -0.011960149730928602}
평가 결과로 랜덤 벡터 값을 가지는 초기 모델은 사용할 수 없다는 것을 확인했습니다. 그렇다면 먼저 학습에 사용할 학습 데이터셋을 만들어 보도록 하겠습니다. 교차 인코더는 관련이 있는 질문-내용 쌍과 관련이 없는 질문-내용 쌍을 구분해야 하기 때문에 임베딩 모델 미세 조정할 때와 다르게 학습 데이터셋에 관련이 있는 질문-내용 쌍과 관련이 없는 질문-내용 쌍이 모두 포함돼야 합니다. 이를 위해 서로 대응되는 질문-내용 쌍에는 label을 1로 지정하고 서로 대응되지 않는 질문-내용 쌍에는 label을 0으로 지정합니다.
# 교차 인코더 학습 데이터셋 준비
train_samples = []
for idx, row in df_train_ir.iterrows():
train_samples.append(InputExample(texts=[row['question'], row['context']], label=1))
train_samples.append(InputExample(texts=[row['question'], row['irrelevant_context']], label=0))
그러면 이제 준비한 학습 데이터셋을 이용해 교차 인코더의 학습을 진행합니다.
# 교차 인코더 학습 수행
from torch.utils.data import DataLoader
train_batch_size = 16
num_epochs = 1
model_save_path = 'output/training_mrc'
train_dataloader = DataLoader(train_samples, shuffle=True, batch_size=train_batch_size)
cross_model.fit(
train_dataloader=train_dataloader,
epochs=num_epochs,
warmup_steps=100,
output_path=model_save_path
)
학습한 모델로 평가를 진행해 봅니다.
# 학습한 교차 인코더 평가 결과
ce_evaluator(cross_model)
학습한 모델로 다시 평가를 진행하면 이전과 비교할 수 없을 정도로 성능이 향상된 것을 확인할 수 있습니다.
Output:
{'pearson': 0.9829889024183588, 'spearman': 0.8649663083582729}
학습한 교차 인코더 모델도 이후에 사용해야 하니 허깅페이스 허브에 업로드 해둡니다.
# 학습을 마친 교차 인코더를 허깅페이스 허브에 업로드
from huggingface_hub import HfApi
api = HfApi()
repo_id = "klue-roberta-small-klue-mrc-cross-encoder-finetuned"
api.create_repo(repo_id=repo_id)
api.upload_folder(
folder_path=model_save_path,
repo_id=f"본인의 허깅페이스 사용자 이름/{repo_id}",
repo_type="model",
)
5. 바이 인코더와 교차 인코더로 개선된 RAG 구현하기
여태까지 우리는 언어 모델을 임베딩 모델로 변환한 기본 임베딩 모델과 기본 임베딩 모델을 MRC 데이터셋으로 미세 조정한 임베딩 모델, MRC 데이터셋으로 학습시킨 교차 인코더까지 총 3개의 모델을 학습시켰습니다. 이제부터 학습한 모델을 조합해 더 개선된 RAG를 구현하고 각각의 성능과 시간을 비교해 보도록 하겠습니다.
- 기본 임베딩 모델로 검색하기
- 미세 조정한 임베딩 모델로 검색하기
- 미세 조정한 모델과 교차 인코더를 결합해 검색하기
데이터셋은 KLUE MRC 서브셋 중 검증 데이터를 활용합니다. 질문 컬럼을 입력했을 때 검색된 상위 10개의 기사 본문에 정답이 있는 비율(HitRate@10)을 성능 지표로 사용하고 전체 검색을 수행하는 데 걸리는 시간도 비교합니다.
검증 데이터셋이 많으면 더 정확한 성능 평가를 수행할 수 있지만 평가에 더 오랜 시간이 걸립니다. 더 원활한 실습 진행을 위해 검증 데이터셋에서 1,000개의 데이터를 선별합니다.
# 평가를 위한 데이터셋을 불러와 1,000개만 선별
from datasets import load_dataset
klue_mrc_test = load_dataset('klue', 'mrc', split='validation')
klue_mrc_test = klue_mrc_test.train_test_split(test_size=1000, seed=42)['test']
검증 데이터셋에 대한 평가를 수행하기 위해서 검증 데이터셋을 문장 임베딩으로 변환하고 벡터 검색을 수행해야 합니다. 아래 예제는 검증 데이터셋을 임베딩 모델을 통해 문장 임베딩으로 변환하고 faiss의 인덱스에 저장하는 make_embedding_index 함수와 인덱스에서 검색 쿼리와 유사한 k개의 문서를 검색하는 find_embedding_top_k 함수를 정의합니다.
# 임베딩을 저장하고 검색하는 함수 구현
import faiss
def make_embedding_index(sentence_model, corpus):
embeddings = sentence_model.encode(corpus)
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)
return index
def find_embedding_top_k(query, sentence_model, index, k):
embedding = sentence_model.encode([query])
distances, indices = index.search(embedding, k)
return indices
교차 인코더로 순위 재정렬을 수행하기 위해서는 검색 쿼리 문장과 유사도를 계산할 모든 기사 본문의 쌍을 교차 인코더의 입력 데이터로 만들어야 합니다. 이를 위해 아래 예제에서는 make_question_context_pairs 함수를 만들었고 이 함수는 질문의 인덱스(question_idx)와 기사 본문의 인덱스 리스트(indices)를 입력으로 받는데, 질문의 인덱스는 고정한 상태로 기사 본문 리스트를 순회하면서 모든 질문-내용 쌍을 생성합니다.
다음으로 교차 인코더에 질문-내용 쌍을 입력하고 교차 인코더의 유사도 점수 계산 결과에 따라 순위를 재정렬하는 rerank_top_k 함수를 정의합니다. 이 함수는 생성한 질문-내용 쌍을 교차 인코더의 predict() 메서드에 입력해 관련도 점수(relevance_socres)를 계산하고 유사도 점수가 높은 순으로 기사 본문의 인덱스를 재정렬 합니다.
# 교차 인코더를 활용한 순위 재정렬 함수 정의
import numpy as np
def make_question_context_pairs(question_idx, indices):
return [[klue_mrc_test['question'][question_idx], klue_mrc_test['context'][idx]] for idx in indices]
def rerank_top_k(cross_model, question_idx, indices, k):
input_examples = make_question_context_pairs(question_idx, indices)
relevance_scores = cross_model.predict(input_examples)
reranked_indices = indices[np.argsort(relevance_scores)[::-1]]
return reranked_indices[:k]
이제 마지막으로 실제 성능 지표인 히트율(hit rate)을 계산하는 함수를 정의합니다. evaluate_hit_rate 함수 내에서는 먼저 각 질문별로 k개의 유사 문서를 검색하고 해당 검색 결과 내에 정답 데이터가 포함돼 있는 경우 정답을 맞췄다고 계산합니다. 그리고 전체 평가 데이터 중 맞춘 데이터의 수와 평가에 걸린 시간을 결과로 반환합니다. 사실 좀더 신뢰성 높은 히트율 평가를 위해서는 KLUE MRC 데이터셋의 train, validation, test에 있는 모든 context를 임베딩으로 변환 후 벡터 DB에 저장한 이후에 평가 데이터셋으로 히트율을 구하는 것이 신뢰성이 훨씬 더 높습니다. 이번에는 간단하게만 알아보기 위해 평가 데이터셋에 있는 context만 임베딩으로 변환해 벡터 DB에 넣고 평가를 진행했습니다. 이는 자가 재현율(self recall)로써 신뢰성이 떨어질 수 있다고 볼 순 있지만 히트율과 논리적으로는 비슷하기 때문에 히트율이라고 표기하였습니다.
# 성능 지표(히트율)와 평가에 걸린 시간을 반환하는 함수 정의
import time
def evaluate_hit_rate(datasets, embedding_model, index, k=10):
start_time = time.time()
predictions = []
for question in datasets['question']:
predictions.append(find_embedding_top_k(question, embedding_model, index, k)[0])
total_prediction_count = len(predictions)
hit_count = 0
questions = datasets['question']
contexts = datasets['context']
for idx, prediction in enumerate(predictions):
for pred in prediction:
if contexts[pred] == contexts[idx]:
hit_count += 1
break
end_time = time.time()
return hit_count / total_prediction_count, end_time - start_time
5.1 기본 임베딩 모델로 검색하기
먼저 기본 임베딩 모델의 성능을 평가해 보도록 하겠습니다. 일단 저는 제 허깅페이스 허브에 모델을 저장해 놨기 때문에 제 허깅페이스 허브로부터 기본 임베딩 모델을 불러왔습니다. 그리고 make_embedding_index를 이용해 평가 데이터에 있는 모든 context 를 임베딩화 하고 index로 저장해 두었습니다. 그리고 평가 데이터셋과, 기본 임베딩 모델, 벡터 DB를 evaluate_hit_rate 함수에 인자로 주었습니다.
# 기본 임베딩 모델로 평가
from sentence_transformers import SentenceTransformer
base_embedding_model = SentenceTransformer('Laseung/klue-roberta-base-klue-sts')
base_index = make_embedding_index(base_embedding_model, klue_mrc_test['context'])
evaluate_hit_rate(klue_mrc_test, base_embedding_model, base_index, 10)
히트율은 0.875가 나왔고, 걸린 시간은 대략 4초 정도 걸렸습니다.
Output:
(0.875, 3.865145683288574)
5.2 미세 조정한 임베딩 모델로 검색하기
이번엔 KLUE MRC 학습 데이터셋으로 미세 조정한 모델의 성능 평가를 진행해 보도록 하겠습니다.
# 미세 조정한 임베딩 모델로 평가
finetuned_embedding_model = SentenceTransformer('Laseung/klue-roberta-base-klue-sts-mrc-mnr-finetuned')
finetuned_index = make_embedding_index(finetuned_embedding_model, klue_mrc_test['context'])
evaluate_hit_rate(klue_mrc_test, finetuned_embedding_model, finetuned_index, 10)
확실히 평가 데이터로 사용하는 KLUE MRC 데이터셋으로 미세조정을 하였기 때문에 기본 임베딩 모델 보다 훨씬 좋은 성능을 보이고 있습니다.
Output:
(0.951, 3.526569366455078)
5.3 미세 조정한 임베딩 모델과 교차 인코더 조합하기
우선 허깅페이스 허브에 저장돼 있는 교차 인코더 모델을 불러와 줍니다.
# Cross Encder 모델 불러오기
from sentence_transformers import CrossEncoder
cross_model = CrossEncoder('Laseung/klue-roberta-small-klue-mrc-cross-encoder-finetuned')
이전 기본 임베딩과 미세 조정 임베딩에 사용했던 evaluate_hit_rate 함수에 교차 인코더를 이용한 rerank 함수를 추가해 준 evalute_hit_rate_with_rerank 함수를 재정의 해주었습니다. 이 함수는 현재 검색 쿼리와 유사한 30개의 데이터를 뽑아 교차 인코더로 전달합니다. 그리고 rerank_top_k 함수에서는 검색 쿼리와 바이 인코더 임베딩 모델로 추려준 30개의 context index를 이용해 질문-내용 쌍을 구성합니다. 그리고 이렇게 구성된 질문-내용 쌍은 교차 인코더의 입력으로 들어가게 되고, 출력으로 30개의 유사도 점수가 나오게 됩니다. 그리고 이를 다시 정렬을 하고 reranked_indices 에는 정렬의 기준이 된 값이 아닌 정렬이 된 index 값이 담기게 numpy 의 argsort를 사용해 정렬을 해줍니다. 그리고 최종적으로 상위 k개만 추출되도록 reranked_indices 에서 10개까지만 뽑아 반환하도록 합니다.
# 순위 재정렬을 포함한 평가 함수
import time
import numpy as np
from tqdm.auto import tqdm
def evaluate_hit_rate_with_rerank(datasets, embedding_model, cross_model, index, bi_k=30, cross_k=10):
start_time = time.time()
predictions = []
for question_idx, question in enumerate(tqdm(datasets['question'])):
indices = find_embedding_top_k(question, embedding_model, index, bi_k)[0]
predictions.append(rerank_top_k(cross_model, question_idx, indices, k=cross_k))
total_prediction_count = len(predictions)
hit_count = 0
questions = datasets['question']
contexts = datasets['context']
for idx, prediction in enumerate(predictions):
for pred in prediction:
if contexts[pred] == contexts[idx]:
hit_count += 1
break
end_time = time.time()
return hit_count / total_prediction_count, end_time - start_time, predictions
미세 조정한 모델만 썻을 때 비해서 히트율이 소폭 상승한 것을 확인할 수 있습니다. 하지만 걸리는 시간은 미세 조정한 모델만 썻을 때에 비해서 24배 증가한 72초가 걸린 것을 확인할 수 있습니다.
Output:
(0.977, 72.47190618515015)
정리
이번 포스트에서는 RAG의 성능 향상을 위한 바이 인코더와 교차 인코더를 결합한 모델에 대해서 알아보았습니다. 그리고 사전 학습된 언어 모델을 좀 더 잘 동작하도록 하기 위해 코사인 유사도 손실 함수와 STS 데이터로 학습 시키는 것과 실제 사용할 데이터셋을 이용해 미세 조정을 했을 때 성능이 대폭 상승한다는 것을 알 수 있었습니다. 또한 바이 인코더보다 속도는 느리지만 성능은 더 느린 교차 인코더를 이용해 재정렬을 진행했을 때 성능이 소폭 상향되는 것과 모델의 전체적인 속도가 느려진다는 것을 확인했습니다. 이를 통해 이론적으로 교차 인코더가 느리지만 성능이 높다는 것을 간접적으로 알수 있었습니다. 그리고 전체적으로 RAG의 성능을 향상 시키기 위해서 어떠한 방향으로 진행해야 하는지 어느 정도 감을 잡을 수 있었습니다.
마치며
언어 모델을 이용해 특정 태스크를 위해서 데이터와 손실 함수를 이용해 학습을 진행해 성능을 대략적으로 향상 시킬 수 있다는 것을 알게 되었고, RAG의 검색 성능을 높이기 위한 방법 중 하나인 교차 인코더를 이용한 재정렬 방법에 대해서 알게 되었습니다. 하지만 교차 인코더를 추가했을 때 속도가 굉장히 느려지는 것을 보고 과연 이 정도의 성능 향상을 위해서 교차 인코더를 넣는게 맞는건가 하는 생각도 했었습니다. 이번 포스트 이후에는 포스트에서 알아본 방법 외에도 RAG의 성능을 올릴 수 있는 방법들이 무엇이 있는지 알아보고 싶다는 생각을 하게 되었습니다.
다음 포스트에는 여태까지 알아보았던 방법을 총 동원해 실제 서비스 되는 RAG를 직접 구현해 보고자 합니다. 이전에 RAG에 대해서 소개하고자 다루었던 포스트에서는 정말 간단하게 RAG는 대충 이렇게 돌아간다고만 알아보았습니다만, 이제 실제 서비스되는 RAG 시스템에 대해서 알아보고 구현도 해보고자 합니다.
긴 글 읽어주셔서 감사드리며, 본문 내용 중에 잘못된 내용이나 오타, 궁금하신 것이 있으시다면 댓글 달아주시기 바랍니다.
참조
- 허정준 저, LLM 을 활용한 실전 AI 어플리케이션 개발
Comments