
[LLM/RAG] 효율적으로 GPU를 사용하기 위한 기술
머리말
이번엔 GPU를 효율적으로 사용해 모델을 학습시키는 다양한 기술을 살펴보도록 하겠습니다. 먼저 딥러닝 모델의 저장과 연산에 사용하는 데이터 타입에 대해 알아보고, GPU에서 딥러닝 연산을 수행할 경우 어떤 데이터가 메모리를 사용하는지도 살펴보도록 하겠습니다. 다음으로 GPU를 1개 사용할 때도 메모리를 효율적으로 활용할 수 있는 방법인 그레디언트 누적(gradient accumulation)과 그레디언트 체크포인팅(gradient checkpointing)을 알아보도록 하겠습니다. GPU를 여러 개 사용하는 분산 학습에 대해 알아보고, 분산 학습 시 같은 데이터가 여러 GPU에 저장돼 비효율적으로 사용되는 문제를 해결한 마이크로소프트의 딥스피드 제로(Deepspeed ZeRO)에 대해서도 살펴보도록 하겠습니다.
LLM 모델은 파라미터가 많아 모델 전체를 학습시킬 경우 GPU 메모리가 많이 필요한데, 모델을 학습시킬 때 전체 모델을 업데이트하지 않고 모델의 일부만 업데이트 하면서도 뛰어난 학습 성능을 보이는 LoRA(Low Rank Adaptation)에 대해 알아보도록 하겠습니다. 마지막으로 LoRA에서 한 발 더 나아가 모델을 적은 비트를 사용하는 데이터 타입으로 저장해 메모리 효율성을 높인 QLoRA(Quantized LoRA)에 대해서도 알아보도록 하겠습니다.
다음은 이번 포스트에서 사용한 예제 실행에 필요한 라이브러리들입니다. 설치를 먼저 진행해 주시기 바랍니다.
pip install transformers datasets accelerate peft bitsandbytes -qqq
1. GPU에 올라가는 데이터에 대해서 알아보기
우리는 여태까지 딥러닝 모델 학습에는 CPU보단 GPU를 사용하는 것이 훨씬 효율적이라고 배웠습니다. 하지만 실제로 모델을 이용해 학습을 하거나 서빙을 할 때 GPU에 어떤 데이터가 올라가는지에 대해서는 크게 다뤄보진 않았습니다. 그렇다면 GPU 메모리에는 어떤 데이터가 올라가는지 이번 기회에 한 번 알아보도록 하겠습니다. 기본적으로 GPU에는 딥러닝 모델 자체가 올라갑니다. 딥러닝 모델은 수많은 행렬 곱셈을 위한 파라미터의 집합입니다. 각각의 파라미터는 소수 또는 정수 형식의 숫자인데, 어떤 형식의 숫자로 모델을 구성하는지 살펴봅니다. 또한 모델의 용량을 줄이기 위한 방법인 양자화에 대해서도 알아보도록 하겠습니다. 모델 이외에 어떤 데이터가 GPU에 올라가는지 살펴본 다음, 허깅페이스에서 필요한 메모리 사용량을 계산해 제공하는 모델 메모리 계산기 기능을 알아보고, 모델의 학습과 추론에 필요한 메모리를 코드로 확인하는 방법을 알아보도록 하겠습니다.
1.1 딥러닝 모델의 데이터 타입
컴퓨터에서는 일반적으로 소수 연산을 위해 32비트 부동소수점(float32)을 사용합니다. 만약 더 세밀한 계산이 필요하다면 64비트 부동소수점(float64)을 사용합니다. 부동소수점을 나타내는 비트의 수가 커질수록 표현할 수 있는 수의 범위나 세밀한 정보가 달라집니다. 딥러닝 모델은 입력한 데이터를 최종 결과로 산출할 때까지 많은 행렬 곱셈에 사용하는 파라미터로 구성됩니다. 예를 들면, 파라미터가 70억 개인 LLM에는 행렬 연산에 사용되는 70억 개의 수가 저장돼 있습니다. 따라서 LLM 모델의 용량은 모델을 몇 비트의 데이터 형식으로 표현하는지에 따라 달라집니다.
과거에는 딥러닝 모델을 32비트(4바이트) 부동소수점 형식을 사용해 저장했습니다. 하지만 성능을 높이기 위해 점점 더 파라미터가 많은 모델을 사용하기 시작했고 모델의 용량이 너무 커 하나의 GPU에 올리지 못하거나 계산이 너무 오래 걸리는 문제가 발생했습니다. 이런 문제를 해결하기 위해 성능은 유지하면서 점점 더 적은 비트의 데이터 타입을 사용하는 방향으로 딥러닝 분야가 발전했습니다. 최근에는 주로 16비트로 수를 표현하는 fp16 또는 bf16(brain float 16)을 주로 사용합니다.
아래 그림은 fp32, fp16, bf16에 대해서 비교하고 있습니다. bf16은 fp16이 표현할 수 있는 수의 범위가 좁아 딥러닝 연산 과정에서 수를 제대로 표현하지 못하는 문제를 해결하고자 지수에 fp32와 같이 8비트를 사용하고 가수에 7비트만 사용하도록 개발되었습니다.

딥러닝 모델은 학습과 추론 같은 모델 모델 연산 과정에서 GPU 메모리에 올라가기 때문에, 모델의 용량이 얼마인지가 GPU 메모리 사용량을 체크할 때 중요합니다. 딥러닝 모델의 용량은 파라미터의 수에 파라미터당 비트(또는 바이트) 수를 곱하면 됩니다. 예를 들어, 파라미터가 10억 개인 모델이 fp16 형식으로 저장돼 있다면 총 20억 바이트가 됩니다. 20억 바이트를 기가바이트 단위로 표현하려면 1024로 세 번 나눠줘야 하는데, 10억이 1024를 세 번 곱한 값과 가깝기 때문에 간단히 계산하면 모델의 용량은 2GB라고 할 수 있습니다. 최근 LLM은 모델이 커지면서 ‘7B 모델’과 같이 10억을 의미하는 B(billion)를 단위로 사용하는데, B를 지우고 모델의 데이터 타입 바이트 수를 곱하면 모델의 용량이 됩니다. 예를 들어, 파라미터가 70억 개인 7B 모델이 16비트(2바이트) 데이터 형식으로 저장된다면 모델의 용량은 7x2 = 14GB가 됩니다.
1.2 양자화로 모델 용량 줄이기
모델 파라미터의 데이터 타입이 더 많은 비트를 사용할수록 모델의 용량이 커지기 때문에 더 적은 비트로 모델을 표현하는 양자화(quantization) 기술이 개발됐습니다. 여기서 딥러닝에서의 양자화란 모델의 가중치와 활성화 값을 높은 정밀도(FP32)에서 낮은 정밀도(INT8 등)의 불연속적인 값으로 변환하는 과정입니다. 이를 통해 모델의 파라미터 크기를 줄여 메모리 점유율을 획기적으로 낮추고, 연산이 가벼운 정수 연산을 활용해 추론 속도를 가속화합니다. 신호처리의 이산화 원리를 계승하여 연속적인 수치를 특정 간격의 격자에 매핑하는 공학적 최적화 기법입니다. 정보 손실로 인한 정확도 하락을 최소화하면서 하드웨어 자원의 효율성을 극대화하는 것이 핵심 목표입니다.
양자화를 진행하면 높은 정밀도에서 낮은 정밀도로 바꾸는 과정에서 정보가 소실되어 모델의 성능이 저하될 수 있습니다. 따라서 이러한 문제를 발생시키지 않도록 하려면 원본 데이터의 정보를 최대한 유지하면서 더 적은 용량의 데이터 형식으로 변환하려면, 변환하려는 데이터 형식의 수를 최대한 낭비하지 않고 사용해야 합니다.
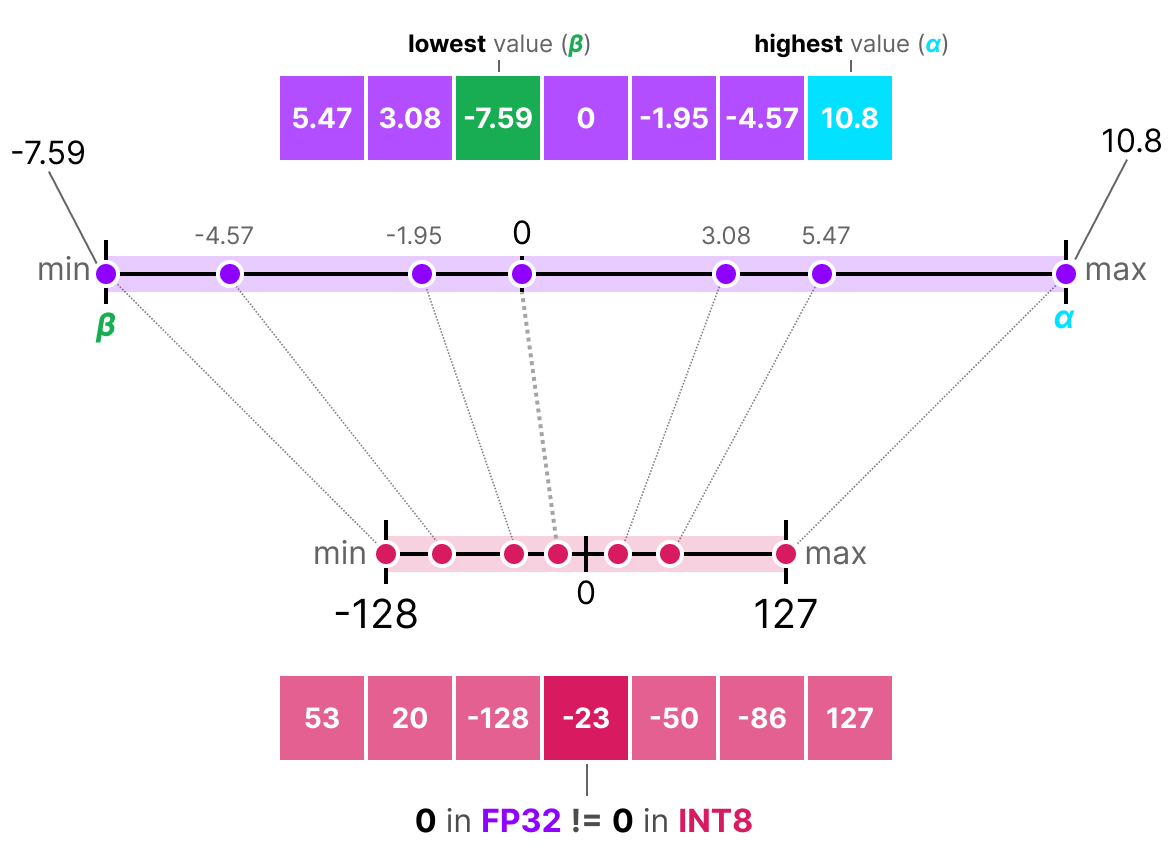
아래 그림은 Min-Max 양자화로 FP32 분포의 최솟값과 최댓값을 INT8의 [-128, 127]에 강제로 대응시켰을 때를 보여줍니다. 소수의 극단값(outlier) 때문에 스케일이 넓어지면, 대부분의 값이 좁은 구간에 몰려 INT8 단계가 충분히 활용되지 않습니다. 그 결과, 많은 INT8 레벨이 비어 있거나 거의 사용되지 않아 표현 해상도(유효 정밀도)가 낭비됩니다. 이 낭비는 반올림 오차 증가 -> 정보 손실 증가로 이어집니다.
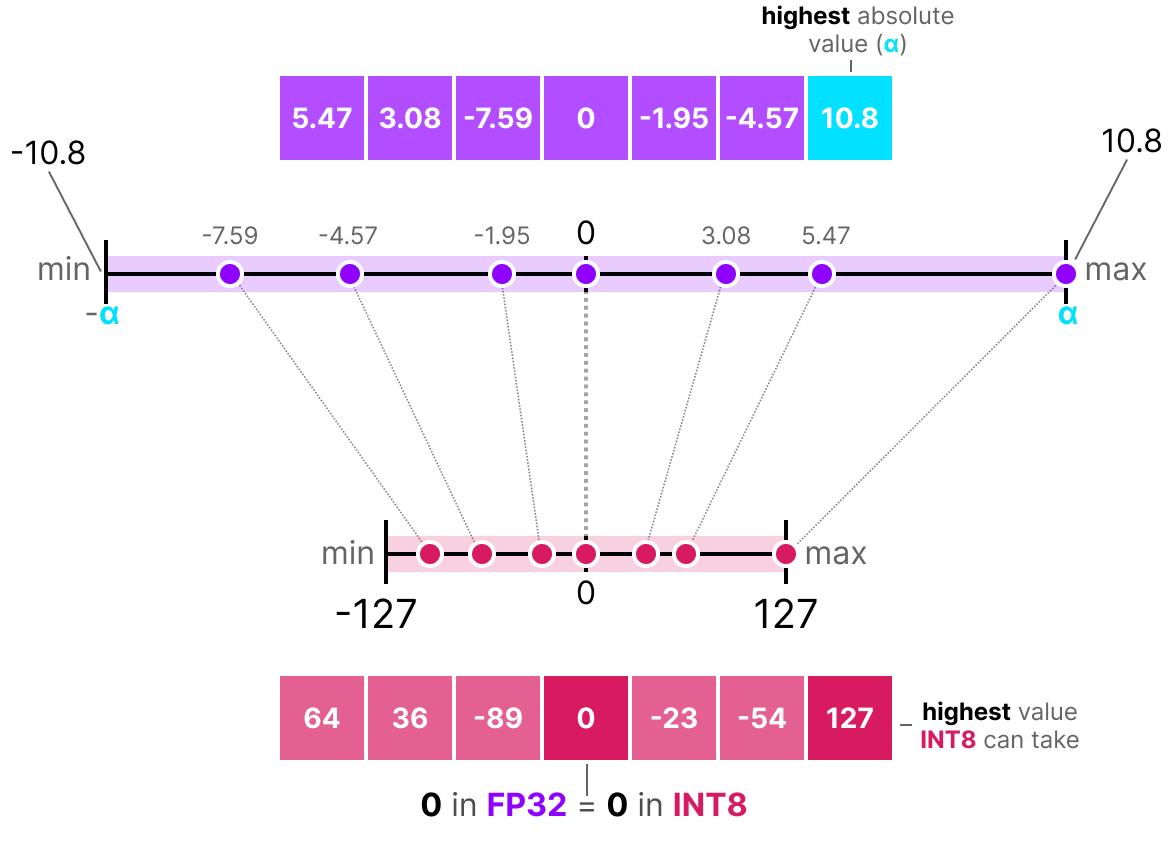
Min-Max 양자화로 발생하는 낭비를 줄이기 위해 아래 그림과 같이 데이터 형식 자체의 최대/최소를 대응시키는 것이 아니라 존재하는 데이터의 최댓값 범위로 양자화하는 방법도 있습니다. 이러한 방식을 AbsMax 양자화 방식이라고 합니다. 하지만 AbsMax 양자화 방식도 소수의 극단값에는 여전히 민감합니다.
그렇다면 이상치의 영향을 최대한 줄이면서 int8 형식으로의 양자화를 진행할 때 낭비를 줄일 수 있는 또 다른 방법은 무엇이 있을까요? 먼저, 전체 데이터에 동일한 변환을 수행하는 것이 아니라 K개의 데이터를 묶은 블록(block) 단위로 양자화를 수행하는 방법이 있습니다. 예를 들면 3개씩 데이터를 묶어 그 안에서 절대 최댓값을 구하고 변환을 수행한다면, 이상치와 함께 블록으로 묶인 3개의 데이터에만 이상치의 영향이 미치게 됩니다. 중앙에 모여 있는 대부분의 데이터는 int8 형식을 낭비하지 않고 양자화를 수행하게 됩니다.
또 다른 방법으로는 퀀타일(quantile) 방식이 있습니다. 절대 최댓값만 보는 것이 아니라 입력 데이터를 크기순으로 등수를 매겨 int8 값에 동일한 개수의 fp32 값이 대응되도록 배치하는 방식입니다. 이 방식은 int8 값의 낭비는 없지만 매번 모든 입력 데이터의 등수를 확인하고 배치해야 하기 때문에 계산량도 많고 그 순서를 기억해야 하기 때문에 별도로 메모리를 사용해야 한다는 단점이 있습니다.
1.3 GPU 메모리 분해하기
GPU를 효율적으로 사용하는 방법에 대해서 알아보기 전에 GPU에 어떤 데이터가 올라가서 메모리를 차지하는지 알아보도록 하겠습니다. 메모리에는 크게 다음과 같은 데이터가 저장됩니다.
- 모델 파라미터
- 그레디언트(gradient)
- 옵티마이저 상태(optimizer state)
- 순전파 상태(forward activation)
딥러닝 학습 과정을 간단히 요약하면, 먼저 순전파를 수행하고 그때 계산한 손실로부터 역전파를 수행하고 마지막으로 옵티마이저를 통해 모델을 업데이트합니다. 역전파는 순전파의 결과를 바탕으로 수행하는데, 이때 역전파를 수행하기 위해 저장하고 있는 값들이 순전파 상태 값입니다. 그레디언트는 역전파 결과로 생성됩니다.
fp16 모델을 기준으로 하고 AdamW와 같은 옵티마이저를 사용한다고 할 때 학습에 필요한 최소의 메모리는 다음과 같습니다. 이때 모델의 용량을 N(GB)이라고 하겠습니다.
- 모델 파라미터: 2바이트 x 파라미터 수(B, 10억 개) = N
- 그레디언트: 2바이트 x 파라미터 수(B, 10억 개) = N
- 옵티마이저 상태: 2바이트 x 파라미터 수(B, 10억 개) x 2(상태 수) = 2N
모두 합치면 대략 4N의 메모리가 기본적으로 필요하고, 이 외에도 순전파 상태(배치 크기, 시퀀스 길이, 잠재 상태 크기에 따라 달라짐)를 저장하기 위한 메모리가 추가로 필요합니다.
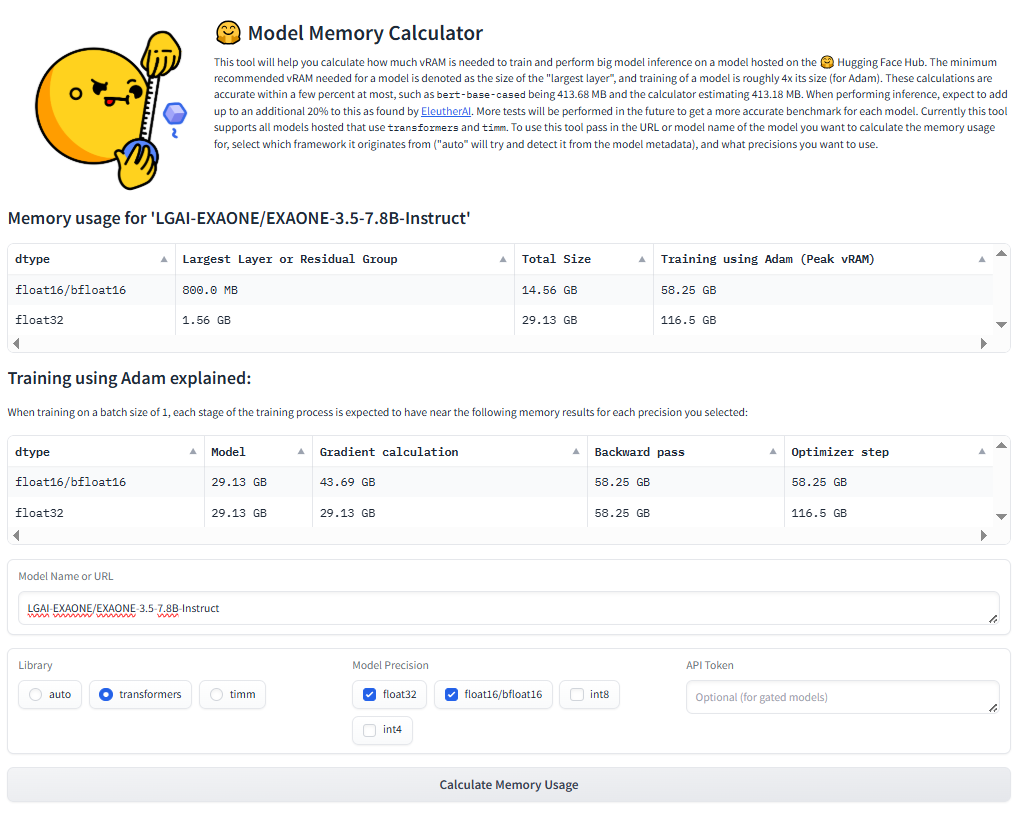
사용하려는 모델마다 학습과 추론에 어느 정도의 GPU 메모리가 필요한지 계산하기 어려울 수 있는데, 허깅페이스는 모델 메모리 계산기(https://huggingface.co/spaces/hf-accelerate/model-memory-usage)를 제공해 허깅페이스 모델 허브의 모델을 활용할 때 GPU 메모리가 얼마나 필요한지 알려주고 있습니다. 아래 그림과 같이 사용하려는 모델을 입력하고 모델의 데이터 타입을 설정하면 모델의 파라미터 수에 따라 모델의 크기, 학습에 필요한 메모리를 제공해 줍니다.
그렇다면 이제 실제 모델을 구현하면서 GPU 메모리 사용량을 확인하기 위해 실제 코드를 통해 모델을 불러오고 학습을 수행하면서 얼마나 많은 GPU 메모리를 사용하는지 확인해 보도록 하겠습니다. 우선 메모리 확인을 위해 torch.cuda.memory_allocated()를 사용해 메모리 사용량을 기가바이트 단위로 변환하는 함수인 print_gpu_utilization 함수를 정의해 주도록 하겠습니다. 함수를 정의한 뒤 실행시켜보면 GPU 메모리를 사용하고 있지 않다는 것을 확인할 수 있습니다.
# 메모리 사용량 측정을 위한 함수 구현
import torch
def print_gpu_utilization():
if torch.cuda.is_available():
used_memory = torch.cuda.memory_allocated() / 1024**3
print(f"GPU 메모리 사용량 : {used_memory:.3f}GB")
else:
print("런타임 유형을 GPU로 변경하세요.")
print_gpu_utilization()
Output:
GPU 메모리 사용량 : 0.000GB
이제 모델과 토크나이저를 불러오는 load_model_and_tokenizer 함수를 정의해 보도록 하겠습니다. 이 함수는 사용할 모델과 토크나이저의 아이디(model_id)와 효율적인 모델 학습을 사용할지와 어떤 방식을 사용할지 입력받는 peft 인자를 받습니다. 받은 model_id를 통해 AutoTokenizer와 AutoModelForCausalLM 클래스의 from_pretrained() 메서드로 대응하는 모델과 토크나이저를 내려받습니다. 아래 코드를 실행시키면 GPU 메모리 사용량은 2.599GB이고 모델 파라미터의 데이터 타입은 torch.float16임을 알 수 있습니다.
# 모델을 불러오고 GPU 메모리와 데이터 타입 확인
from transformers import AutoModelForCausalLM, AutoTokenizer
def load_model_and_tokenizer(model_id, peft=None):
tokenizer = AutoTokenizer.from_pretrained(model_id)
if peft is None:
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
print_gpu_utilization()
return model, tokenizer
model_id = "EleutherAI/polyglot-ko-1.3b"
model, tokenizer = load_model_and_tokenizer(model_id) # GPU 메모리 사용량: 2.599GB
print("모델 파라미터 데이터 타입: ", model.dtype) # torch.float16
Output:
GPU 메모리 사용량 : 2.481GB
모델 파라미터 데이터 타입: torch.float16
그럼 이제 그레디언트와 옵티마이저의 메모리 사용량을 확인하는 두 함수를 정의해 보도록 하겠습니다. 그레디언트 메모리 사용량을 확인하는 함수는 estimate_memory_of_gradients, 옵티마이저의 메모리 사용량을 확인하는 함수는 estimate_memory_of_optimizer로 정의하였습니다. estimate_memory_of_gradients 함수는 인자로 모델을 받아 모델에 저장된 그레디언트 값의 수(param.grad.nelement)와 값의 데이터 크기(param.grad.element_size)를 통해 전체 메모리 사용량을 계산합니다. estimate_memory_of_optimizer 함수는 인자로 옵티마이저를 받아 옵티마이저에 저장된 값의 수(v.nelement)와 값의 데이터 크기(v.element_size)를 곱해 전체 메모리 사용량을 계산합니다.
# 그레디언트와 옵티마이저 상태의 메모리 사용량을 계산하는 함수
from torch.optim import AdamW
from torch.utils.data import DataLoader
def estimate_memory_of_gradients(model):
total_memory = 0
for param in model.parameters():
if param.grad is not None:
total_memory += param.grad.nelement() * param.grad.element_size()
return total_memory
def estimate_memory_of_optimizer(optimizer):
total_memory = 0
for state in optimizer.state.values():
for k, v in state.items():
if torch.is_tensor(v):
total_memory += v.nelement() * v.element_size()
return total_memory
다음으로 모델을 학습시키며 중간에 메모리 사용량을 확인하는 train_model 함수를 정의합니다. 함수에서 training_args.gradient_checkpointing 설정이 있는데, 이 부분은 이후에 다룰 그레디언트 체크포인팅 기능을 사용할지 설정하는 부분으로 설정에 True 또는 False를 입력해 켜고 끌 수 있습니다. 기본값은 False입니다. training_args.gradient_accumulation_steps 설정은 그레디언트 누적 기능을 사용할지 결정하는 설정인데, 누적할 스텝 수에 따라 2 또는 4 등으로 설정하면 됩니다. 우선 기본값인 1로 진행하도록 하겠습니다.
# 모델의 학습 과정에서 메모리 사용량을 확인하는 train_model 정의
def train_model(model, dataset, training_args):
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
train_dataloader = DataLoader(dataset, batch_size=training_args.per_device_train_batch_size)
optimizer = AdamW(model.parameters())
model.train()
gpu_utilization_printed = False
for step, batch in enumerate(train_dataloader, start=1):
batch = {k: v.to(model.device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss = loss / training_args.gradient_accumulation_steps
loss.backward()
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
gradients_memory = estimate_memory_of_gradients(model)
optimizer_memory = estimate_memory_of_optimizer(optimizer)
if not gpu_utilization_printed:
print_gpu_utilization()
gpu_utilization_printed = True
optimizer.zero_grad()
print(f"옵티마이저 상태의 메모리 사용량 : {optimizer_memory / (1024**3):.3f}GB")
print(f"그레디언트 메모리 사용량 : {gradients_memory / (1024**3):.3f}GB")
모델을 학습시키기 위해서는 데이터가 필요한데, 학습 과정에서 필요한 메모리 사용량에 집중하기 위해 랜덤 데이터를 생성하는 make_dummy_dataset 함수를 정의합니다. make_dummy_dataset 함수에서는 텍스트의 길이가 256이고 데이터가 64개인 더미 데이터를 생성하고 datasets 라이브러리의 Dataset 형태로 변환해 반환합니다.
# 랜덤 데이터셋을 생성하는 make_dummy_dataset 정의
import numpy as np
from datasets import Dataset
def make_dummy_dataset():
seq_len, dataset_size = 256, 64
dummy_data = {
"input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
"labels": np.random.randint(100, 30000, (dataset_size, seq_len)),
}
dataset = Dataset.from_dict(dummy_data)
dataset.set_format("pt")
return dataset
다음으로 GPU 메모리의 데이터를 삭제하는 cleanup 함수를 정의합니다. cleanup 함수에서는 전역 변수 중 GPU 메모리에 올라가는 모델의 변수와 데이터셋 변수를 삭제하고 gc.collect 함수를 통해 사용하지 않는 메모리를 회수하는 garbage collection을 수동으로 수행합니다. torch.cuda.empty_cache() 함수는 더 이상 사용하지 않는 GPU 메모리를 반환합니다.
# 사용하지 않는 GPU 메모리를 반환하는 cleanup 함수
import gc
def cleanup():
if 'model' in globals():
del globals()['model']
if 'dataset' in globals():
del globals()['dataset']
gc.collect()
torch.cuda.empty_cache()
마지막으로 앞서 정의한 함수를 종합해 배치 크기, 그레디언트 누적, 그레디언트 체크포인팅, peft 설정 등에 따라 GPU 사용량을 확인하는 gpu_memory_experiment 함수를 정의합니다. 먼저, load_model_and_tokenizer 함수와 make_dummy_dataset 함수로 모델, 토크나이저, 데이터셋을 불러옵니다. 다음으로 실험하려는 설정에 따라 학습에 사용할 인자를 설정합니다. 모델, 데이터셋, 학습 인자 준비를 마쳤으니 train_model 함수를 통해 학습을 진행하면서 GPU 메모리 사용량을 확인합니다. 마지막으로 실험이 끝난 모델과 데이터셋을 삭제하고 사용하지 않는 GPU 메모리를 반환합니다.
# GPU 사용량을 확인하는 gpu_memory_experiment 함수 정의
from transformers import TrainingArguments, Trainer
def gpu_memory_experiment(batch_size,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
model_id="EleutherAI/polyglot-ko-1.3b",
peft=None):
print(f"배치 크기: {batch_size}")
model, tokenizer = load_model_and_tokenizer(model_id, peft=peft)
if gradient_checkpointing == True or peft == 'qlora':
model.config.use_cache = False
dataset = make_dummy_dataset()
training_args = TrainingArguments(
per_device_train_batch_size = batch_size,
gradient_accumulation_steps = gradient_accumulation_steps,
gradient_checkpointing=gradient_checkpointing,
output_dir = "./result",
num_train_epochs=1
)
try:
train_model(model, dataset, training_args)
except RuntimeError as e:
if "CUDA out of memory" in str(e):
print(e)
else:
raise e
finally:
del model, dataset
gc.collect()
torch.cuda.empty_cache()
print_gpu_utilization()
아래 배치 코드를 실행해 배치 크기를 4부터 8, 16까지 늘리면서 GPU 메모리 사용량이 어떻게 변하는지 확인해 보도록 하겠습니다. 실행에 앞서 cleanup 함수와 print_gpu_utilization 함수로 GPU에서 불필요한 데이터를 삭제하고 메모리를 사용하지 않고 있음을 확인합니다.
cleanup()
print_gpu_utilization()
for batch_size in [4, 8, 16]:
gpu_memory_experiment(batch_size)
torch.cuda.empty_cache()
배치 크기를 변경하면서 실행했을 때 출력된 결과를 보면 아래와 같습니다. 이를 보기 쉽게 표로 정리해 보도록 하겠습니다.
Output:
GPU 메모리 사용량 : 0.000GB
배치 크기: 4
GPU 메모리 사용량 : 2.481GB
GPU 메모리 사용량 : 10.186GB
옵티마이저 상태의 메모리 사용량 : 4.961GB
그레디언트 메모리 사용량 : 2.481GB
배치 크기: 8
GPU 메모리 사용량 : 2.497GB
GPU 메모리 사용량 : 10.432GB
옵티마이저 상태의 메모리 사용량 : 4.961GB
그레디언트 메모리 사용량 : 2.481GB
배치 크기: 16
GPU 메모리 사용량 : 2.497GB
GPU 메모리 사용량 : 10.921GB
옵티마이저 상태의 메모리 사용량 : 4.961GB
그레디언트 메모리 사용량 : 2.481GB
배치 크기가 증가해도 모델, 그레디언트, 옵티마이저 상태를 저장하는 데 필요한 GPU 메모리는 동일합니다. 총 메모리가 증가하는 것을 통해 순전파 상태의 계산에 필요한 메모리가 증가한다는 사실을 확인할 수 있습니다.
| 배치크기 | 모델크기(GB) | 그레디언트(GB) | 옵티마이저 상태(GB) | 총 메모리(GB) |
|---|---|---|---|---|
| 4 | 2.497 | 2.481 | 4.961 | 10.186 |
| 8 | 2.497 | 2.481 | 4.961 | 10.432 |
| 16 | 2.497 | 2.481 | 4.961 | 10.921 |
2. 단일 GPU 효율적으로 활용하기
GPU 메모리는 크기가 제한적이기 때문에 올릴 수 있는 모델의 크기도, 학습에 사용할 수 있는 배치 크기도 제한됩니다. 이번엔 GPU를 1개만 사용할 때도 GPU의 메모리를 효율적으로 사용할 수 있는 그레디언트 누적과 그레디언트 체크포인팅에 대해 살펴보도록 하겠습니다. 그레디언트 누적이란, 딥러닝 모델을 학습시킬 때 각 배치마다 모델을 업데이트하지 않고 여러 배치의 학습 데이터를 연산한 후 모델을 업데이트 해 마치 더 큰 배치 크기를 사용하는 것 같은 효과를 내는 방법을 말합니다. 다음으로 그레디언트 체크포인팅은 순전파의 계산 결과를 모두 저장하지 않고 일부만 저장해 학습 중 GPU 메모리의 사용량을 줄이는 학습 방법입니다. 두 방법 모두 모델 학습 시에 배치 크기를 키워 모델의 학습을 더 빠르고 안정적으로 만들어 줍니다.
2.1 그레디언트 누적
학습 과정에서 배치 크기를 크게 가져가면 더 빠르게 수렴해 학습 속도가 빨라집니다. 하지만 배치 크기를 키우면 순전파 상태 저장에 필요한 메모리가 증가하면서 OOM 에러가 발생할 수 있습니다. 그레디언트 누적(gradient accumulation)은 제한된 메모리 안에서 배치 크기를 키우는 것과 동일한 효과를 얻는 방법입니다. train_model 함수에서 학습 인자(training_args)의 그레디언트 누적 횟수(gradient_accumulation_steps) 설정을 4로 두면, 손실을 4로 나눠서 역전파를 수행하고, 4번의 스텝마다 모델을 업데이트 합니다. 이를 통해 마치 배치 크기가 4로 커진 것과 동일한 효과를 얻을 수 있습니다.
그렇다면 배치 크기를 4로, 그레디언트 누적 스텝 수를 4로 설정해 실행해 보도록 하겠습니다. 출력 결과를 보면 GPU 메모리 사용량은 10.186GB로 사용하는 GPU 메모리가 줄든 것을 확인할 수 있습니다. 이렇게 되면 배치 크기가 16일 때와 같은 효과를 얻을 수 있습니다. 그레디언트 누적을 사용하는 경우 적은 GPU 메모리로도 더 큰 배치 크기와 같은 효과를 얻을 수 있지만, 추가적인 순전파 및 역전파 연산을 수행하기 때문에 학습 시간이 증가합니다.
# 그레디언트 누적을 적용했을 때의 메모리 사용량
cleanup()
print_gpu_utilization()
gpu_memory_experiment(batch_size=4, gradient_accumulation_steps=4)
torch.cuda.empty_cache()
Output:
GPU 메모리 사용량 : 0.016GB
배치 크기: 4
GPU 메모리 사용량 : 2.497GB
GPU 메모리 사용량 : 10.186GB
옵티마이저 상태의 메모리 사용량 : 4.961GB
그레디언트 메모리 사용량 : 2.481GB
2.2 그레디언트 체크포인팅
딥러닝 모델에서는 모델 업데이트를 위한 그레디언트를 계산하기 위해 순전파와 역전파를 수행하는데 이때 역전파 계산을 위해 순전파의 결과를 저장하고 있어야 합니다. 가장 기본적인 저장 방식은 “모두” 저장하는 것입니다. 아래 이미지를 보면 오른쪽으로 진행하는 순전파와 왼쪽으로 진행하는 역전파가 있는데, 보라색이 값을 저장하고 있는 상태이고 흰 색이 저장하지 않은 상태입니다. 이미지에서는 역전파 계산을 위해 순전파 데이터를 모두 저장하고 있는데 이렇게 되면 GPU 메모리를 많이 차지하게 됩니다.
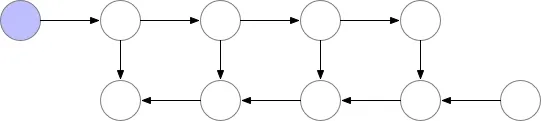
다음으로 메모리를 절약하는 방법은 아래 그림과 같이 역전파를 계산할 때 필요한 최소 데이터만 저장하고 나머지는 필요할 때 다시 계산하는 방식입니다. 메모리 효율성을 높이기 위해 순전파 과정에서는 중간 데이터를 삭제하면서 진행합니다. 결국 마지막 데이터만 남긴 상태로 손실을 계산합니다. 그리고 역전파 계산을 위해 순전파 상태가 필요해지면 다시 순전파를 처음부터 계산합니다. 이 방식은 메모리를 효율적으로 쓸 수 있다는 장점이 있지만 한 번의 역전파를 위해 순전파를 반복적으로 계산해야 한다는 단점이 있습니다.
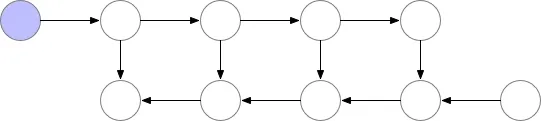
앞에서 설명한 두 가지 방식을 절충한 방법이 그레디언트 체크포인팅(gradient checkpointing)입니다. 순전파의 전체를 저장하거나 마지막만 저장하는게 아니라, 중간 중간에 값들을 저장(체크포인트)해서 메모리 사용을 줄이고 필요한 경우 체크포인트부터 다시 계산해 순전파 계산량도 줄입니다. 아래 그림에서와 같이 세 번째 노드마다 순전파 데이터를 저장한다고 가정하겠습니다.
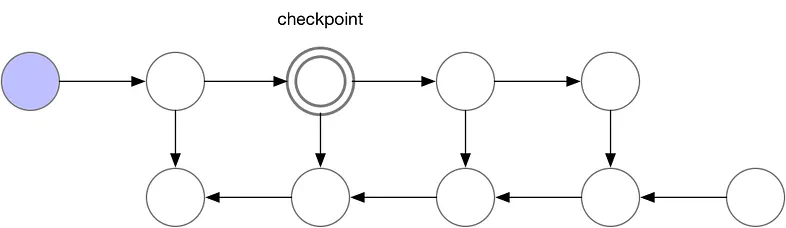
그러면 아래 그림과 같이 세 번째 노드마다 순전파가 저장이 되며, 역전파 계산을 위해 특정 노드의 값이 필요해지면 체크 포인팅한 노드에서 순전파를 계산합니다.
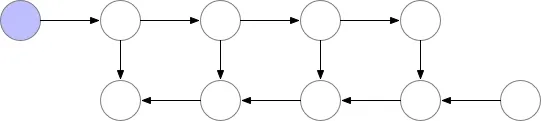
그레디언트 체크포인팅은 추가적은 순전파 계산이 필요하기 때문에 메모리 사용량은 줄지만 학습 시간이 증가한다는 단점이 있습니다. 그레디언트 체크포인트는 체크포인트 사용 설정만 변경해 줌으로써 활용할 수 있습니다.
# 그레디언트 체크포인팅 사용 시 메모리 사용량
cleanup()
print_gpu_utilization()
gpu_memory_experiment(batch_size=16, gradient_checkpointing=True)
torch.cuda.empty_cache()
그레디언트 체크포인팅을 사용하도록 한 경우 이전 배치 크기가 16일 때 10.921GB 사용되던 것과 달리 10.171GB로 메모리 사용량이 줄어든 것을 확인할 수 있습니다.
Output:
GPU 메모리 사용량 : 0.016GB
배치 크기: 16
GPU 메모리 사용량 : 2.497GB
GPU 메모리 사용량 : 10.171GB
옵티마이저 상태의 메모리 사용량 : 4.961GB
그레디언트 메모리 사용량 : 2.481GB
3. 효율적인 학습 방법(PEFT): LoRA
LLM과 같은 기반 모델의 크기가 커지면서 하나의 GPU를 사용해 모든 파라미터를 학습하는 전체 미세 조정(full fine-tuning)을 수행하기 어려워졌습니다. 하지만 대부분의 개인과 조직은 여러 GPU를 사용해 모델을 학습시키기 어렵기 때문에 일부 파라미터만 학습하는 PEFT(Parameter Efficient Fine-Tuning) 방법 연구가 활발히 이뤄지고 있습니다. 그중에서도 오픈소스 LLM 학습에서 가장 주목받고 많이 활용되는 학습 방법은 모델에 일부 파라미터를 추가하고 그 부분만 학습하는 LoRA(Low-RAnk Adaption) 학습 방식입니다. 이번 절에서는 LoRA 학습 방법에 대해 알아보고, 이어지는 절에서 LoRA에서 한 발 더 나아가 모델 파라미터를 양자화하는 QLoRA(Quantized LoRA)에 대해 알아보도록 하겠습니다.
3.1 모델 파라미터의 일부만 재구성해 학습하는 LoRA
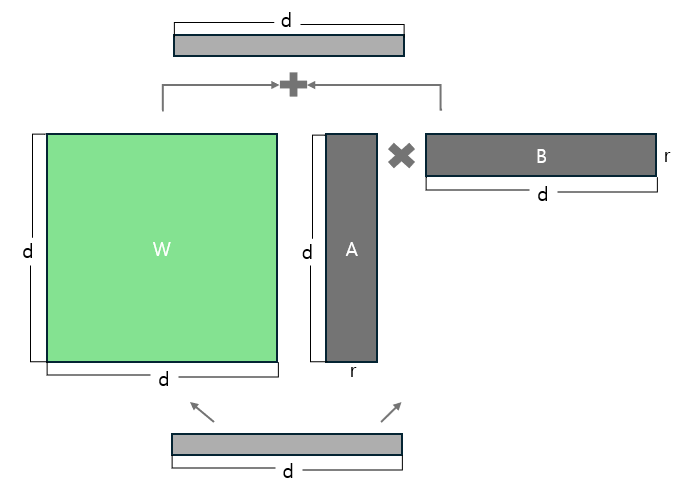
LoRA는 큰 모델을 학습시켜야 하는 LLM 시대에 가장 사랑받는 PEFT 방법 중 하나입니다. LoRA는 모델 파라미터를 재구성(reparameterization)해 더 적은 파라미터를 학습함으로써 GPU 메모리 사용량을 줄입니다. LoRA에서 파라미터 재구성은 행렬을 더 작은 2개의 행렬의 곱으로 표현해 전체 파라미터를 수정하는 것이 아니라 더 작은 2개의 행렬을 수정하는 것을 의미합니다. 예를 들어 아래 그림에서 파라미터 $W$로 구성된 딥러닝 모델을 학습시킨다고 가정해 보겠습니다. 이 딥러닝 모델은 d차원적인 입력 $X$와 파라미터 $W$를 곱해 최종적으로 $d$차원인 출력 $h$를 생성합니다. 그리고 파라미터 $W$는 $d$ x $d$차원입니다. 만약 $d$가 100이라면, 전체 파라미터 $W$를 학습시키기 위해서는 10,000개의 파라미터를 학습시켜야 합니다.
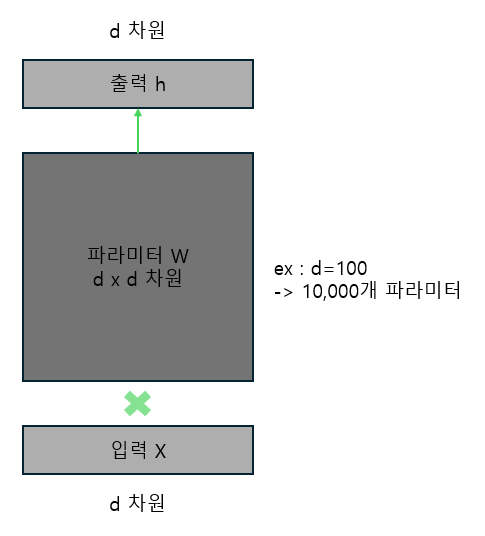
하지만 파라미터 $W$를 학습시키는 것이 아니라 파라미터 $W$는 고정하고 차원이 ($d$, $r$)인 행렬 $A$와 차원이 ($r$, $d$)인 행렬 $B$의 곱을 학습시킬 수 있습니다. 행렬의 곱셈에서 ($d$, $r$)차원인 행렬과 ($r$, $d$)차원인 행렬이 곱해지면 ($d$, $d$)차원이 됩니다. 행렬을 2개 학습하지만 $r$을 $d$보다 작은 수로 설정하는 경우 파라미터 $W$를 학습시킬 때보다 훨씬 적은 파라미터 업데이트로 모델을 학습시킬 수 있습니다. 예를 들어 $r$이 4라면, 행렬 $A$의 파라미터 400개(100x4), 행렬 B의 파라미터 400개(100x4)로 총 800개의 파라미터만 학습시키면서도 파라미터 $W$를 변경하는 것 같은 효과를 얻을 수 있습니다. 파라미터 재구성을 통해 학습할 파라미터 수를 8% 수준으로 낮춘 것입니다. 일반적으로 100보다 더 큰 $d$값을 사용하기 때문에 실제로는 1% 미만의 파라미터를 학습하는 경우도 많습니다.
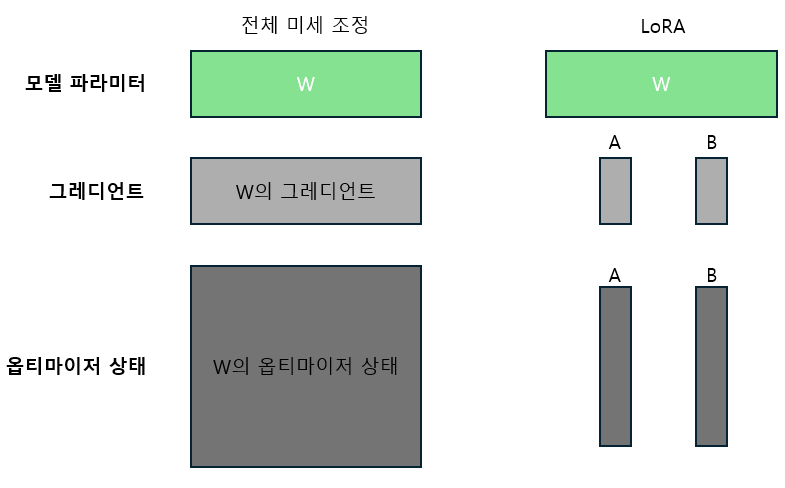
아래 그림에서 기존 파라미터 $W$에 새로운 행렬 $A$와 $B$를 추가해 학습하는데 왜 GPU 메모리 사용량이 줄어드는지 궁금할 수 있습니다. 행렬 $A$와 $B$가 파라미터 $W$에 비해 훨씬 작다고는 하더라도 파라미터가 추가되는 것이기 때문에 모델 파라미터 용량 자체는 아주 작게 증가합니다. 하지만 앞서 GPU 메모리에는 모델 파라미터뿐만 아니라, 그레디언트와 옵티마이저 상태가 저장된다고 설명했었습니다. 그 아래 “전체 미세 조정과 LoRA에서 저장하는 데이터 비교” 그림은 전체 미세 조정과 LoRA를 비교한 그림인데, 오른쪽의 LoRA에는 왼쪽에 없는 어댑터가 추가된 것을 확인할 수 있습니다. 여기서 어댑터가 그 위의 그림의 행렬 $A$와 $B$인데, 행렬 $A$와 $B$는 파라미터 $W$에 비해 훨씬 작기 때문에 그림에서 어댑터가 작게 표현된 것을 확인할 수 있습니다. 학습하는 파라미터의 수가 줄어들면 모델 업데이트에 사용하는 옵티마이저 상태의 데이터가 줄어드는데, LoRA를 통해 GPU 메모리 사용량이 줄어드는 부분은 바로 그레디언트와 옵티마이저 상태를 저장하는 데 필요한 메모리가 줄어들기 때문입니다.
3.2 LoRA 설정 살펴보기
모델 학습에 LoRA를 적용할 때 결정해야 할 사항은 크게 세 가지입니다. 먼저 “파라미터 재구성을 통해 더 적은 파라미터 학습” 그림에서 파라미터 $W$에 더한 행렬 $A$와 $B$를 만들 때 차원 $r$을 몇으로 할지 정해야 합니다. $r$을 작게 설정하면 학습시켜야 하는 파라미터의 수가 줄어들기 때문에 GPU 메모리 사용량을 더 줄일 수 있습니다. 하지만 $r$이 작아질 경우 그만큼 모델이 학습할 수 있는 용량(capacity)이 작아지기 때문에 학습 데이터의 패턴을 충분히 학습하지 못할 수 있습니다. 따라서 실험을 통해 적절한 $r$값을 설정해야 합니다.
다음으로 추가한 파라미터를 기존 파라미터에 얼마나 많이 반영할 지결정하는 알파(alpha)가 있습니다. “파라미터 재구성을 통해 더 적은 파라미터 학습” 그림에서 행렬 $A$와 $B$를 추가한 상태에서 추론할 때 행렬 $A$와 $B$를 곱한 부분을 기존 파라미터 $W$와 동일하게 더해줄 수도 있지만, 행렬 $A$와 $B$를 더 중요하게 고려할 수도 있습니다. LoRA에서는 행렬 $A$와 $B$ 부분을 (알파/$r$)만큼의 비중으로 기존 파라미터 $W$에 더해줍니다. 즉 알파가 커질수록 새롭게 학습한 파라미터의 중요성을 크게 고려한다고 볼 수 있습니다. 학습 데이터에 따라 적절한 알파 값도 달라지기 때문에 실험을 통해 $r$값과 함께 적절히 설정해야 합니다.
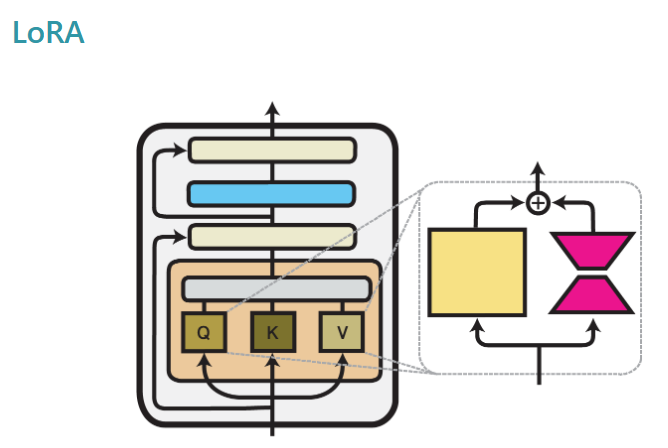
마지막으로, 모델에 있는 많은 파라미터 중에서 어떤 파라미터를 재구성할지 결정해야 합니다. 일반적으로 아래 그림에서 표시한 것과 같이 세레프 어텐션 연산의 Q, K, V 가중치와 피드 포워드 층의 가중치와 같이 선형 연산의 가중치를 재구성합니다. 이 중에서 특정 가중치에만 LoRA를 적용할 수도 있습니다. 보통 전체 선형 층에 LoRA를 적용한 경우 성능이 가장 좋다고 알려져 있는데, 이 부분 또한 실험을 통해 적절히 선택해야 합니다.
3.3 코드로 LoRA 학습하기
지금까지 파라미터 재구성을 통해 GPU 메모리 사용량을 줄이면서도 전체 미세 조정과 거의 동일한 성능을 내는 LoRA 학습 방법에 대해 알아보았습니다. 허깅페이스는 peft 라이브러리를 통해 LoRA와 같은 효율적인 학습 방식을 쉽게 활용할 수 있는 기능을 제공합니다. 이전에 정의했던 load_model_and_tokenizer 함수에 peft 인자를 ‘lora’로 설정할 경우 모델에 LoRA를 적용하는 부분을 추가했습니다. peft 라이브러리에서 LoraConfig 클래스를 사용하면 LoRA를 적용할 때 사용할 설정을 정의할 수 있습니다. 그림을 통해서 살펴보았던 $r$ 값을 8로, 알파 값을 32로, LoRA를 어떤 가중치에 적용할지 정하는 target_modules는 Q, K, V 가중치로 설정했습니다. 다음으로 불러온 모델에 lora_config를 적용해 파라미터를 재구성하는 get_peft_model 함수를 호출하고 모델 재구성 후에 학습 파라미터의 수와 비중을 확인하는 print_trainable_parameters() 메서드를 호출합니다.
# 모델을 불러오면서 LoRA 적용하기
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
def load_model_and_tokenizer(model_id, peft=None):
tokenizer = AutoTokenizer.from_pretrained(model_id)
if peft is None:
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
elif peft == 'lora':
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
print_gpu_utilization()
return model, tokenizer
이제 LoRA를 적용했을 때 GPU 메모리 사용량이 어떻게 달라지는지 확인해 보도록 하겠습니다.
# LoRA를 적용했을 때 GPU 메모리 사용량 확인
cleanup()
print_gpu_utilization()
gpu_memory_experiment(batch_size=16, peft='lora')
torch.cuda.empty_cache()
출력 결과를 보면 LoRA를 적용하면서 학습 가능한 파라미터가 전체 파라미터 대비 0.118%로 훨씬 줄어든 것을 확인할 수 있습니다. 모델을 불러왔을 때 메모리 사용량은 2.502GB로 이전과 비슷한데 옵티마이저 상태의 메모리 사용량과 그레디언트 메모리 사용량이 각각 0.012GB, 0.006GB로 현저히 줄어들었습니다. 전체 파라미터를 학습하는 것이 아니라 전체의 0.118%만 학습하기 때문입니다.
Output:
GPU 메모리 사용량 : 0.016GB
배치 크기: 16
trainable params: 1,572,864 || all params: 1,333,383,168 || trainable%: 0.1180
GPU 메모리 사용량 : 2.502GB
GPU 메모리 사용량 : 3.501GB
옵티마이저 상태의 메모리 사용량 : 0.012GB
그레디언트 메모리 사용량 : 0.006GB
4. 효율적인 학습 방법(PEFT): QLoRA
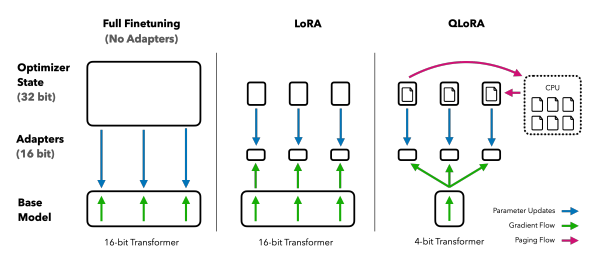
2023년 5월 워싱턴대학교의; 팀 데트머스(Tim Dettmers)와 알티도로 팩노니(Artidoro Pagnoni)가 발표한 QLoRA(QLORA: Efficient Finetuning of Quantized LLMs(QLORA: 양자화된 LLM의 효율적인 미세 조정, https://arxiv.org/pdf/2305.14314.pdf))는 LoRA에 양자화를 추가해 메모리 효율성을 한 번 더 높인 학습 방법입니다. 아래 그림에서 QLoRA와 LoRA를 비교하고 있는데, 16비트로 모델을 저장하고 있는 LoRA와 달리 QLoRA는 4비트 형식으로 모델을 저장합니다. 또한 그림 오른쪽에 CPU 메모리가 함께 표시되어 있는데 QLoRA는 학습 도중 OOM(Out Of Memory) 에러가 발생하지 않고 안정적으로 진행할 수 있도록 페이지 옵티마이저(paged optimizer) 기능을 활용했습니다. QLoRA는 대형 언어 모델을 최대한 효율적으로 다룰 수 있도록 여러 기법을 적용했기 때문에 메모리 효율화를 이해하기 위한 좋은 참고 자료이기도 합니다. 그렇다면 QLoRA를 이해하기 위한 개념을 하나씩 살펴보도록 하겠습니다.
4.1 4비트 양자화와 2차 양자화
앞에서 여러 양자화 방식을 살펴보았습니다. 양자화의 핵심 과제는 기존 데이터의 정보를 최대한 유지하면서 더 적은 비트를 사용하는 데이터 형식으로 변환하는 것입니다. 특히 변환하려는 데이터 타입의 경우 적은 비트 수를 사용하기 때문에 하나하나의 수가 낭비되지 않고 사용되는 것이 좋은데, 이를 위해 기존 데이터의 순위대로 새로운 데이터 형식에 매핑하는 방법을 사용할 수 있었습니다. 하지만 데이터의 순서를 사용하는 경우 데이터를 정렬해야 하고 어떤 데이터가 몇 번째 순위에 있었는지 저장해야 하기 때문에 연산량이 많고 순위를 저장하기 위해 메모리를 사용한다는 단점이 있습니다.
만약 기존 데이터의 분포를 알고 있다면 많은 연산이나 메모리 사용 없이도 빠르게 데이터의 순위를 정할 수 있습니다. 예를 들어, 입력 데이터가 정규 분포를 따른다는 걸 알고 있다면 데이터를 균등하게 분리하기 위해 사용할 경곗값을 아래 그림과 같이 쉽게 계산할 수 있습니다. 아래 그림에서는 정규 분포를 따르는 데이터를 균등하게 10등분할 수 있는 경곗값을 찾아 분할 했습니다. 만약 변환하려는 데이터 타입이 4비트만 사용해 16개의 수를 사용한다면, 아래 그림에서 면접을 16등분할 수 있는 경곗값을 찾고 입력 데이터가 경곗값을 기준으로 큰지 작은지에 따라 0~15까지 적절히 배정하면 됩니다.
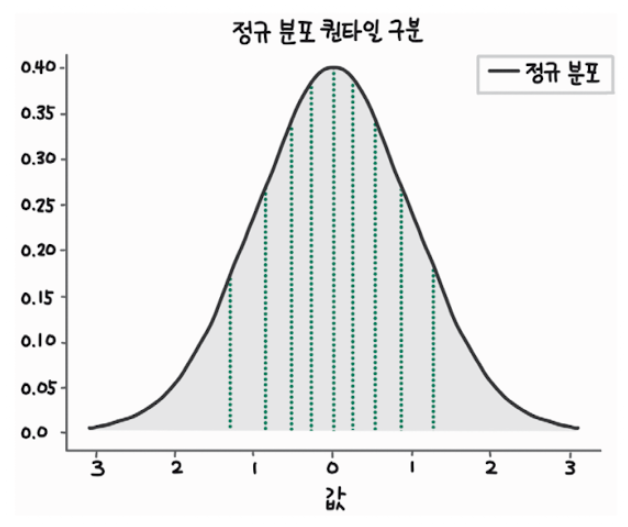
정규 분포에서 영역을 구분하는 경곗값은 다음과 같은 코드로 간단히 구할 수 있습니다. 코드에서 quantile_normal 함수는 정규 분포 그래프 아래 면적의 $p$%가 몇 이하에 존재하는지 구합니다. 예를 들어 quantile_normal에 0.5를 입력하면 0을 출력하는데, 정규 분포의 50%의 데이터가 0보다 작은 영역에 있다는 의미입니다. 0.6을 입력하면 0.2533을 출력하는데, 60%의 데이터가 0.2533보다 작은 영역에 있습니다. 두 값의 차이를 통해 10%의 데이터가 (0, 0.2533)의 범위에 있다는 사실을 알 수 있습니다.
from scipy.stats import norm
def quantile_normal(p):
return norm.ppf(p)
print(quantile_normal(0.5)) # 0
print(quantile_normal(0.6)) # 0.25334710313579971
앞서 데이터가 정규 분포를 따른다면 이런 계산이 가능하다고 했는데, 학습된 모델 파라미터는 거의 정규 분포에 가깝다고 알려져 있습니다. 실제로 QLoRA 논문을 쓴 팀 데트머스와 알티도로 팩노니가 메타의 라마(LLaMa) 모델을 확인했을 때 92.5% 정도의 모델 파라미터가 정규 분포를 따랐습니다. 따라서 입력이 중규 분포라는 가정을 활용하면 모델의 성능을 거의 유지하면서도 빠른 양자화가 가능해집니다. QLoRA 논문에서는 위에서 설명한 방식에 따라 양자화를 수행한 4비트 부동소수점 데이터 형식인 NF4(Normal Float 4-bit)를 제안했습니다.
논문에서는 4비트 양자화에서 한 발 더 나아가 2차 양자화(double quantization)도 수행합니다. 2차 양자화는 NF4 양자화 과정에서 생기는 32비트 상수도 효율적으로 저장하고자 합니다. NF4는 아래 그림과 같이 64개의 모델 파라미터를 하나의 블록으로 묶어 양자화를 수행합니다. 따라서 64개의 모델 파라미터마다 1개의 상수(정규 분포의 표준편차)를 저장해야 합니다. 이때 다시 256개의 양자화 상수를 하나의 블록으로 묶어 8비트 양자화를 수행하면 상수 저장에 필요한 메모리도 절약할 수 있습니다. 2차 양자화를 수행하면 이전에는 양자화 상수를 저장하기 위해 32비트 데이터 256개를 저장했지만 이후에는 8비트 데이터 256개와 양자화 상수 c를 저장하기 위한 32비트 데이터 1개만 저장하면 됩니다.
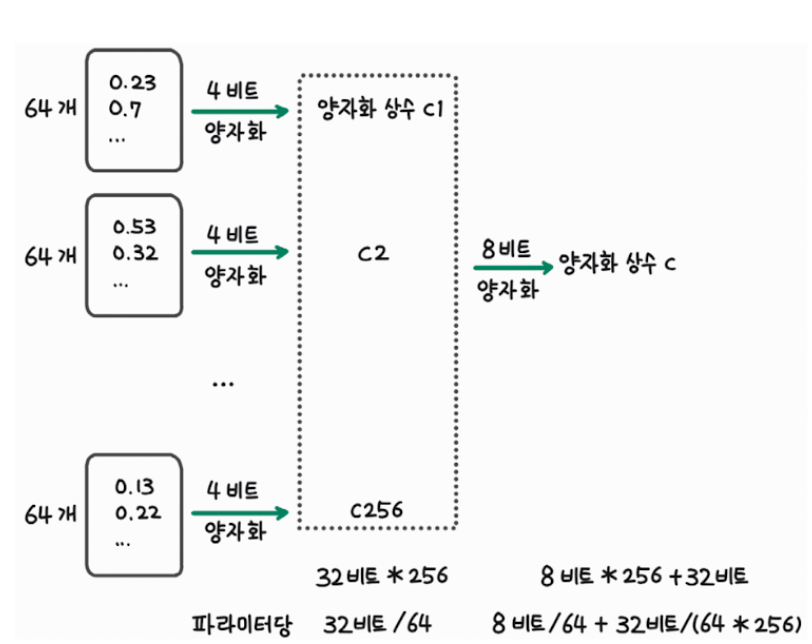
4.2 페이지 옵티마이저
QLoRA 논문에서는 그레디언트 체크포인팅 과정에서 발생할 수 있는 OOM 에러를 방지하기 위해 페이지 옵티마이저(paged optimizer)를 활용합니다. 이 부분을 이해하기 위해 앞에서 본 그레디언트 체크포인팅 그림을 다시 살펴보고, 엔비디아의 통합 메모리(unified memory)에 대해서 알아보도록 하겠습니다.
그레디언트 체크포인팅을 사용하는 아래 그림의 (a)에서 순전파를 수행할 때는 3개의 노드 데이터만 저장하고 있지만, (b)에서 역전파를 수행할 때는 5개의 노드 데이터를 저장해야 합니다. 이렇게 일시적으로 메모리 사용량이 커지는 지점들이 생기는데, 이때 OOm 에러가 발생할 수 있습니다. 이런 순간에 대응하기 위해 QLoRA 논문에서는 페이지 옵티마이저를 사용합니다.

페이지 옵티마이저란, 엔비디아의 통합 메모리를 통해 GPU가 CPU 메모리를 공유하는 것을 말합니다. 엔비디아의 통합 메모리는 컴퓨터의 가상 메모리 시스템과 유사한 개념을 GPU 메모리 관리에 적용한 기술입니다. 가상 메모리는 램과 디스크를 사용해 컴퓨터가 더 많은 메모리를 가진 것처럼 작동하게 해줍니다. 마찬가지로, 통합 메모리는 CPU와 GPU가 메모리를 공유해 더 많은 GPU 메모리가 있는 것처럼 동작합니다.
가상 메모리에서 운영체제는 램이 가득차면 일부 데이터를 디스크로 옮기고 필요할 때 다시 램으로 데이터를 불러오는데, 이 과정을 페이징(paging)이라고 합니다. 엔비디아의 통합 메모리도 이와 유사하게 작동합니다. GPU가 처리해야 할 데이터가 많을 때 모든 데이터를 GPU 메모리에 담을 수 없다면, 일부 데이터를 CPU의 메모리에 보관합니다. CPU에 있는 데이터가 필요해지면, 그때 해당 데이터를 CPU 메모리에서 GPU 메모리로 옮겨 처리합니다.
4.3 코드로 QLoRA 모델 활용하기
이제 허깅페이스 코드를 통해 QLoRA 학습을 진행하는 방법을 알아보도록 하겠습니다. 아래 예제와 같이 허깅페이스와 통합돼 있는 bitsandbytes 라이브러리를 활용하면 모델을 불러올 때 4비트 양자화를 간단히 수행할 수 있습니다. BitsAndBytesConfig 클래스에 4비트로 불러올지 여부(load_in_4bit), 4비트 데이터 타입(bnb_4bit_quant_type), 2차 양자화를 수행할지 여부(bnb_4bit_use_double_quant), 계산할 때 사용할 데이터 형식(bnb_4bit_compute_dtype)을 지정하면 됩니다. 우리는 논문의 내용을 이해했기 때문에 코드를 보면 각각의 설정이 어떤 의미인지 쉽게 이해할 수 있습니다.
# 4비트 양자화 모델 불러오기
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit = True,
bnb_4bit_quant_type = "nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
마지막으로 QLoRA 모델을 불러오는 부분도 추가하면 아래 예제와 같습니다. 예제에서는 4비트 양자화와 2차 양자화를 수행하기 위해 BitsAndBytesConfig 클래스를 사용해 양자화 설정을 정의했습니다. 다음으로 양자화 설정인 bnb_config를 사용해 모델을 불러오고 모델을 학습시키기 위한 준비 과정으로 prepare_model_for_kbit_training 함수를 호출합니다. 마지막으로 LoRA 설정을 적용하기 위해 get_peft_model 함수를 호출하고, 학습 가능한 파라미터 수를 확인하기 위해 print_trainable_parameters() 메서드를 사용합니다.
# QLoRA 모델을 불러오는 부분 추가
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
def load_model_and_tokenizer(model_id, peft=None):
tokenizer = AutoTokenizer.from_pretrained(model_id)
if peft is None:
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
elif peft == 'lora':
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map={"":0})
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
elif peft == 'qlora':
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type = "CAUSAL_LM"
)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
print_gpu_utilization()
return model, tokenizer
이제 아래 예제를 실행해 새롭게 추가한 load_model_and_tokenizer 함수로 QLoRA 모델을 불러와 배치 크기 16일 때 메모리 사용량을 확인해 보도록 하겠습니다.
# QLoRA를 적용했을 때의 GPU 메모리 사용량 확인
cleanup()
print_gpu_utilization()
gpu_memory_experiment(batch_size=16, peft='qlora')
torch.cuda.empty_cache()
LoRA만 사용했을 때는 GPU 메모리 사용량이 2.502GB, 3.502GB였던 것에 비해 QLoRA를 적용하고 난뒤 1.876GB, 2.415GB로 메모리 사용량이 줄어든 것을 확인할 수 있습니다.
Output:
GPU 메모리 사용량 : 0.828GB
배치 크기: 16
trainable params: 1,572,864 || all params: 1,333,383,168 || trainable%: 0.1180
GPU 메모리 사용량 : 1.876GB
GPU 메모리 사용량 : 2.415GB
옵티마이저 상태의 메모리 사용량 : 0.012GB
그레디언트 메모리 사용량 : 0.006GB
마치며
이번에 GPU 메모리를 효율적으로 사용하는 학습 방법에 대해서 알아보았습니다. 먼저 GPU 메모리에 올라가는 데이터의 종류와 데이터 타입, 양자화에 대해 알아보았습니다. 크게 모델 파라미터, 그레디언트, 옵티마이저 상태, 순전파 상태를 저장하는데 GPU 메모리를 사용합니다. 모델 파라미터를 저장하기 위해 일반적으로 16비트의 소수 데이터 형식인 fp16과 bf16을 주로 사용하지만, 더 큰 모델을 다루기 위해 8비트 또는 4비트 모델을 저장하는 방식도 최근에는 많이 사용하고 있습니다.
다음으로 단일 GPU에서 모델을 효율적으로 학습시킬 수 있는 그레디언트 누적과 그레디언트 체크포인팅에 대해 알아보았습니다. 그레디언트 누적을 사용하는 경우 제한된 GPU 메모리로도 큰 배치 크기로 학습하는 것과 같은 효과를 얻을 수 있고, 그레디언트 체크포인팅을 사용하면 순전파 상태를 모두 저장하지 않음으로써 GPU 메모리 사용량을 줄일 수 있습니다.
모델이 커지면서 모델 전체를 업데이트하는 전체 미세 조정이 어려워졌는데, 이런 문제를 해결하기 위해 모델의 일부만 학습하는 PEFT 방식이 활발히 연구되고 있습니다. 특히 그 중에서도 모델 파라미터를 재구성해 적은 학습 파라미터를 추가하는 LoRA와 LoRA에 모델의 4비트 양자화를 추가한 QLoRA 방법을 살펴보았습니다.
이번 포스트를 준비하며 딥러닝 모델의 양자화와 PEFT를 위한 LoRA와 QLoRA 방법에 대해서는 책 내용만으로는 조금 부족하다는 생각을 갖게 되어 추후에는 딥러닝에서의 양자화와 LoRA, QLoRA의 논문을 위주로 논문 리뷰 형식으로 포스트를 작성하며 제대로 한 번 알아보고자 합니다. 이번엔 대략적으로 이러한 기법들이 있다는 것만 대략적으로 정리하는 시간이었던 것 같습니다.
긴 글 읽어주셔서 감사드리며, 본문 내용 중에 잘못된 내용 혹은 오타, 궁금하신 것들이 있으시다면 댓글 달아주시기 바랍니다.
Comments