
[LLM/RAG] LLM Application - 1. 트랜스포머 모델 사용을 위한 허깅페이스 라이브러리 사용법 알아보기
최근 ChatGPT를 시작으로 Gemini, Claude 등 다양한 LLM(대규모 언어 모델)이 등장하며 전 세계적으로 큰 반향을 일으키고 있습니다. 이에 따라 여러 기업들이 LLM 기술을 주목하고, 자사 비즈니스에 적합한 모델을 확보하기 위해 적극적으로 연구·투자하고 있습니다.
그러나 LLM을 직접 학습하기 위해서는 막대한 GPU 자원과 고품질 데이터셋이 필요하기 때문에, 현실적으로 대기업이 아닌 이상 자체 학습은 어렵습니다. 특히 데이터 구축에도 많은 비용과 시간이 소요되는 만큼, 대다수 기업은 메타(Meta)가 제안한 RAG(Retrieval-Augmented Generation) 기술을 활용해 모델을 직접 학습하지 않고도 원하는 태스크를 수행할 수 있는 방식을 채택하고 있습니다.
저 역시 이러한 산업적 흐름에 발맞추어 LLM과 RAG 기술을 심층적으로 학습하고 정리하고자 합니다. 이전에는 LangChain을 활용한 RAG 실습을 중심으로 공부했지만, 이번에는 LLM의 구조와 원리까지 포함한 보다 확장된 관점에서 학습을 진행할 계획입니다.
개요
2017년 트랜스포머 아키텍처가 공개된 이후 2018년 구글의 BERT 등 모델이 발표될 당시만 해도 모델을 개발하는 조직마다 각자의 방식으로 모델을 구현하고 공개했습니다. 핵심적인 아키텍처를 공유함에도 구현 방식에 차이가 있어 모델마다 활용법을 익혀야 하는 문제가 있었고, 구현을 한다고 해도 발표된 논문의 벤치마크 데이터를 이용해 학습과 평가를 진행했을 때 전혀 다른 성능을 기록하는 등의 여러 문제가 존재했습니다. 그러다 허깅페이스(Huggingface) 팀이 개발한 트랜스포머 라이브러리는 공통된 인터페이스로 트랜스포머 모델을 활용할 수 있도록 지원함으로써 이런 문제를 해결했고, 현재는 딥러닝 분야의 핵심 라이브러리가 되었습니다.
이번 포스트에서는 허깅페이스 트랜스포머 라이브러리에 친숙해질 수 있도록 실습을 포함해 라이브러리의 구성요소를 살펴보도록 하겠습니다. 우선 허깅페이스 트랜스포머 라이브러리가 무엇이며, 왜 많은 사용자가 허깅페이스를 사용하는지 알아보고, 다음으로 다양한 모델, 데이터셋, 모델 데모를 쉽게 공유하고 사용할 수 있도록 제공하는 허깅페이스 허브를 알아보도록 하겠습니다. 그리고 모델 학습과 활용에 꼭 필요한 데이터셋, 모델, 토크나이저를 각각 살펴보도록 하겠습니다. 마지막으로 한국어 데이터셋을 활용해 텍스트 분류 모델을 만들고 활용하는 실습을 진행하도록 하겠습니다.
1. 허깅페이스 트랜스포머란?
허깅페이스 트랜스포머는 다양한 트랜스포머 모델을 통일된 인터페이스로 사용할 수 있도록 지원하는 오픈소스 라이브러리입니다. 만약 허깅페이스 트랜스포머가 없었다면 사람들은 새로운 모델이 공개될 때마다 그 모델을 어떻게 불러올 수 있는지, 모델이 어떤 함수를 갖고 있는지, 어떻게 학습시킬 수 있는지 파악하는 데 많은 시간을 써야 했을 것입니다. 실제로 2017년도 이전에 발표된 딥러닝을 사용하는 논문들의 경우 모델 공유를 해주는 논문이 드물었으며, 공유를 한다고 해도 논문에 없는 여러 핵심적인 내용을 뺀 모델을 공유하거나, 모델을 실제로 구현했을 때 논문에 있는 모델과는 구현에 차이가 있어 성능차이가 나는 것이 일상 다반사 였습니다.
허깅페이스는 크게 트랜스포머 모델과 토크나이저를 활용할 때 사용하는 transformers 라이브러리와 데이터셋을 공개하고 쉽게 가져다 쓸 수 있도록 지원하는 datasets 라이브러리를 제공해 트랜스포머 모델을 쉽게 학습하고 추론에 활용할 수 있도록 돕습니다.
2. 허깅페이스 허브 알아보기
허깅페이스의 허브는 다양한 사전 학습 모델과 데이터셋을 탐색하고 쉽게 불러와 사용할 수 있도록 제공하는 온라인 플랫폼입니다. 또한 간단하게 자신의 모델 데모를 제공하고 다른 사람의 모델을 사용해 볼 수 있는 스페이스도 있습니다. 이번 항목에서는 허깅페이스 허브의 모델, 데이터셋, 스페이스에 대해 알아보고 탐색하는 방법에 대해 살펴보도록 하겠습니다.
2.1 모델 허브
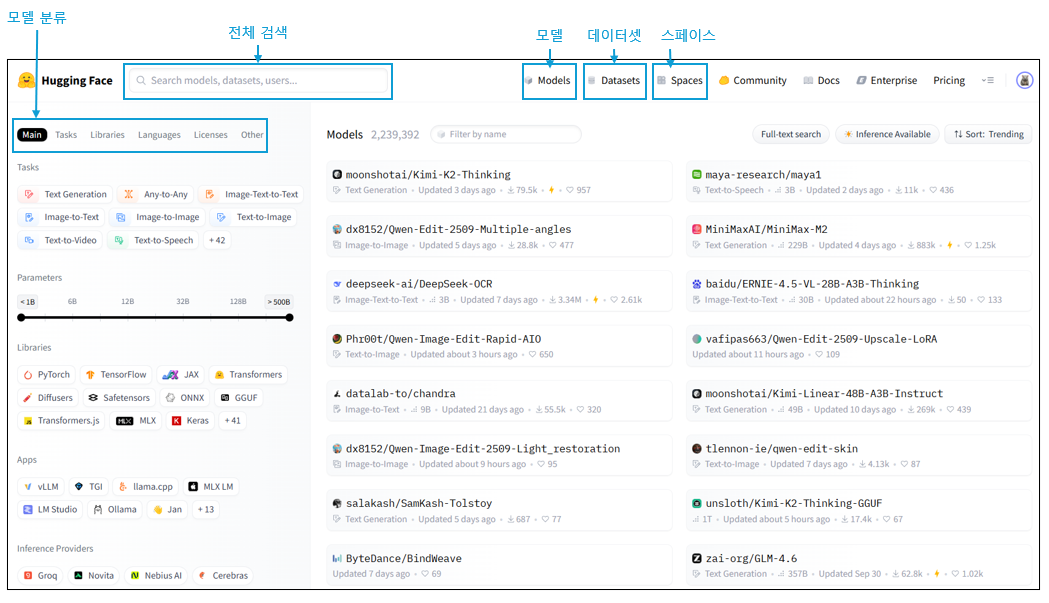
모델 허브에는 그림 1과 같이 어떤 태스크에 사용하는지, 어떤 언어로 학습된 모델인지 등 다양한 기준으로 모델이 분류되어 있습니다. 그림에서 ‘모델 분류’로 강조한 표시 박스 안에서 Tasks를 선택하면 작업 종류에 따라 모델을 필터링할 수 있습니다. 모델 허브를 통해 사용자는 자신이 필요한 작업 분야와 언어 등에 따라 활용할 수 있는 사전 학습 모델이 있는지 탐색할 수 있고 해당 분야에서 어떤 모델이 많이 사용되는지 확인할 수 있습니다. 또한 ‘전체 검색’으로 강조 표시한 박스에서 검색하면 모델, 데이터셋, 스페이스, 사용자 등을 검색할 수 있습니다.
검색창 오른쪽에는 여러 아이콘이 있는데, 모델을 클릭하면 모델을 탐색할 수 있는 화면이 나오고, 데이터셋을 클릭하면 허깅페이스의 datasets 라이브러리에서 제공하는 데이터셋을 탐색할 수 있는 화면으로 이동합니다. 스페이스를 누르면 공개된 스페이스를 탐색할 수 있는 화면으로 이동합니다.
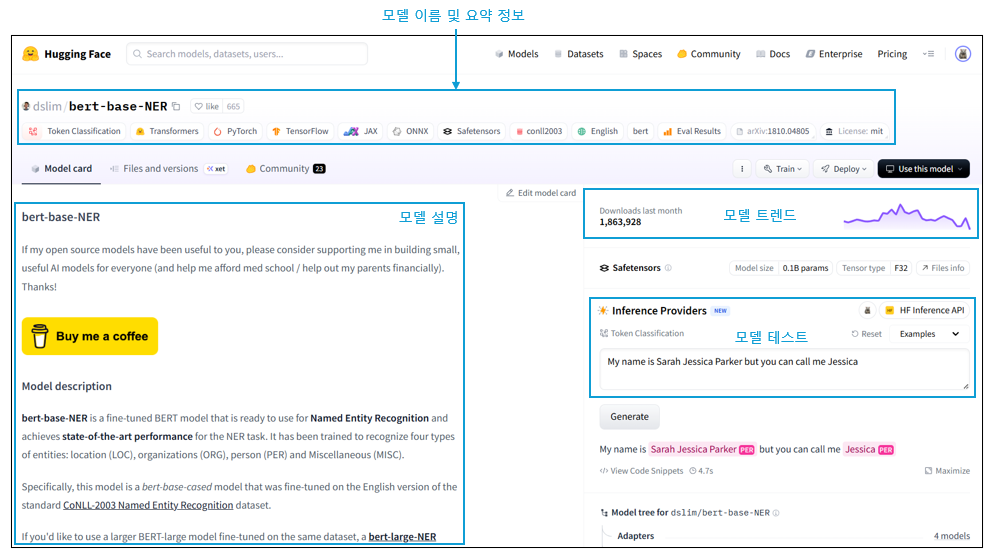
아래 그림 2는 BERT 기반 개체명 인식기 모델의 화면입니다. 상단에서 모델의 이름과 요약된 정보를 아이콘 형태로 확인할 수 있습니다. 어떤 작업을 위한 모델인지, 라이선스 유형 등을 확인할 수 있습니다. 왼쪽 아래에는 모델에 대한 설명이 있습니다. 필수사항은 아니기 때문에 모든 모델에 설명이 적혀 있는 것은 아니나, 잘 작성된 모델 카드의 경우 모델의 성능, 관련 있는 논문 소개, 사용 방법 등의 정보를 제공합니다. 오른쪽의 위에는 모델의 다운로드 수 추이를 볼 수 있는 모델 트렌드 그래프가 있고, 그 아래쪽에는 모델을 간단히 테스트해 볼 수 있습니다.
2.2 데이터셋 허브
데이터셋 허브 화면은 모델 허브와 달리 분류 기준에 데이터셋 크기(size), 데이터 유형(format) 등이 추가로 있고, 선택한 기준에 맞는 데이터셋을 보여준다는 점이 다릅니다.
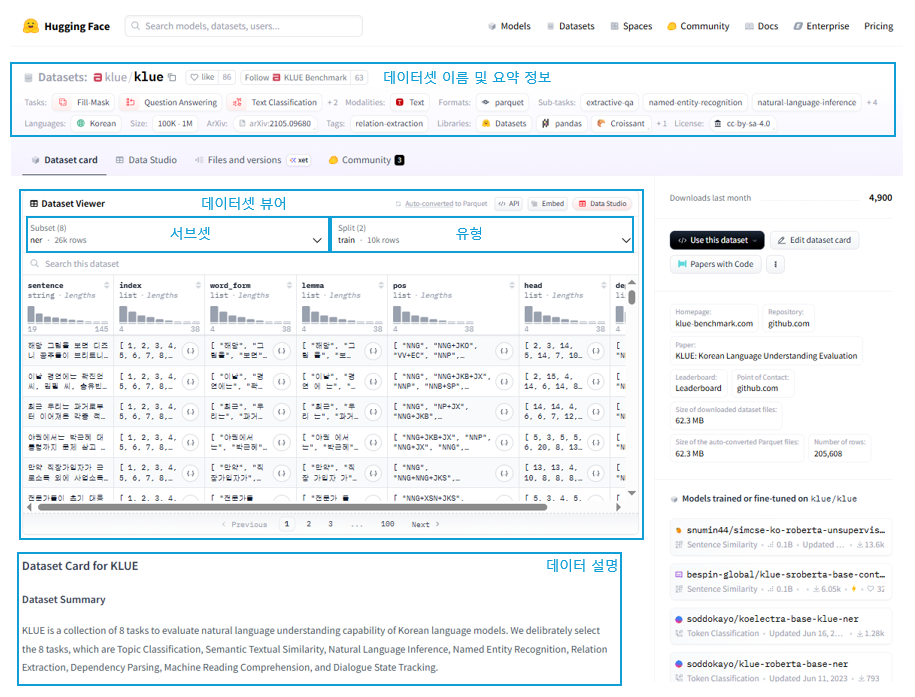
아래 그림 3은 이번에 실습에 사용할 KLUE 데이터셋 페이지입니다https://huggingface.co/datasets/klue. 데이터셋 페이지의 상단에서는 데이터셋의 이름과 작업 종류, 크기, 언어, 라이선스 등 요약 정보를 확인할 수 있고, 화면 중앙과 같이 데이터셋을 바로 확인할 수 있는 데이터셋 뷰어 기능을 제공합니다. 데이터셋 뷰어 아래로 데이터셋에 대한 설명을 제공합니다. 데이터셋에 대한 설명은 필수사항이 아니기 때문에 제공하지 않는 데이터셋도 있습니다.
대표적인 한국어 데이터셋 중 하나인 KLUE는 한국어 언어 이해 평가(Korean Language Understanding Evaluation)의 약자로 텍스트 분류, 기계 독해, 문장 유사도 판단 등 다양한 작업에서 모델의 성능을 평가하기 위해 개발된 벤치마크 데이터셋입니다. KLUE에는 기계 독해 능력 평가를 위한 MRC(Machine Reading Comprehension) 데이터, 토픽 분류 능력 평가를 위한 YNAT(Younhap News Agency news headlines for Topic Classification) 데이터 등 8개의 데이터가 포함돼 있습니다. 하나의 데이터셋에 여러 데이터셋이 포함된 경우 그림 3과 과 같이 서브셋(subset)으로 구분합니다. 유형(split)은 일반적으로 학습용, 검증용, 테스트용으로 구분되는, 정해진 것은 아니고 데이터셋에 따라 다른 이름을 사용하거나 다른 구분이 있기도 합니다.
2.3 모델 데모를 공개하고 사용할 수 있는 스페이스
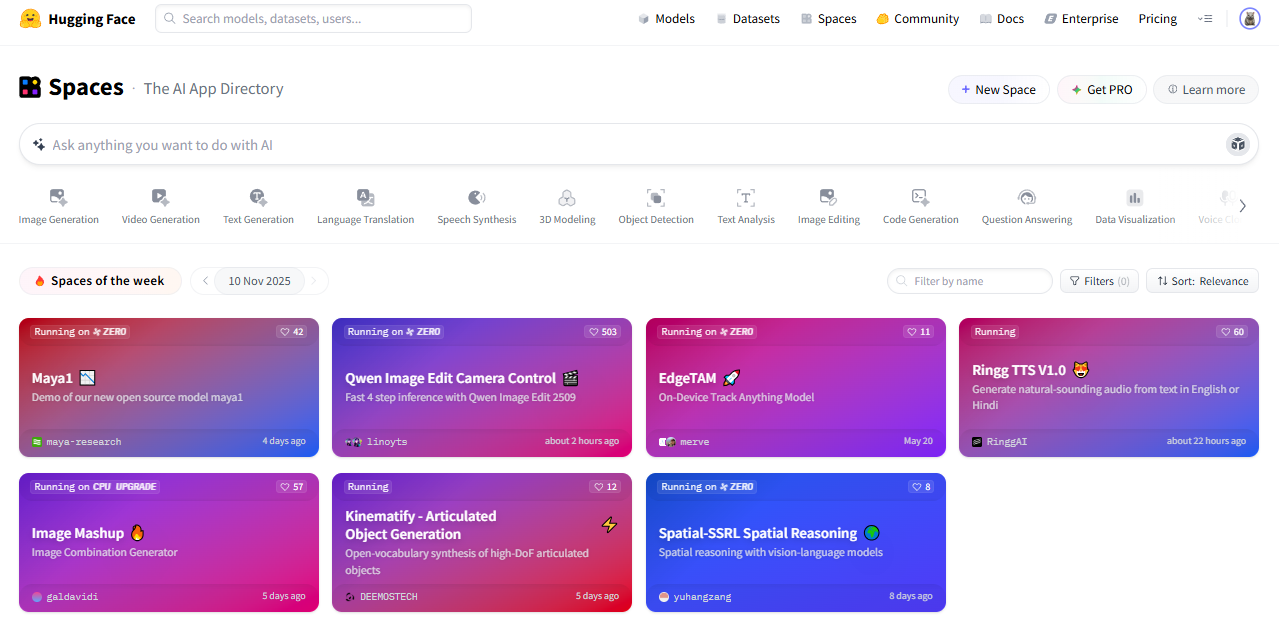
마지막으로 스페이스는 사용자가 자신의 모델 데모를 간편하게 공개할 수 있는 기능이 있습니다. 모델을 개발하다 보면, 동료에게 모델 데모를 보여줘야 하는 경우도 있고, 수업이나 발표를 위해 모델이 실행되는 화면이 필요한 경우도 있습니다. 이때 로컬에서 실행되는 주피터 노트북보다는 웹 페이지로 공유하는 것이 훨씬 편리한데, 스페이스를 사용하면 별도의 복잡한 웹 페이지 개발 없이 모델 데모를 공유할 수 있습니다. 스페이스 화면에 들어가면 그림 4와 같이 다양한 모델이 공개된 것을 확인할 수 있습니다.
3. 허깅페이스 라이브러리 사용법 익히기
허깅페이스 허브를 통해 자신에게 맞는 모델과 데이터셋을 찾았다면, 이제는 코드를 통해 모델과 데이터셋을 활용하는 방법에 대해서 알아보도록 하겠습니다. 모델을 학습시키거나 추론하기 위해서는 모델, 토크나이저, 데이터셋이 필요한데, 이번 절에서는 하나씩 코드를 통해 사용하는 방법을 익혀보도록 하겠습니다.
그리고 코드를 실행하기 전에 아래 라이브러리들 인스톨부터 진행해 주시기 바랍니다.
!pip install transformers datasets huggingface_hub -qqq
3.1 모델 활용하기
허깅페이스 트랜스포머 라이브러리를 사용하면 허깅페이스 모델 허브의 모델을 쉽게 불러와 사용할 수 있습니다. 허깅페이스 모델을 불러오기 전에 꼭 알아야 하는 사실이 있는데, 허깅페이스에서는 모델을 바디(body)와 헤드(head)로 구분한다는 점입니다. 이렇게 구분하는 이유는 같은 바디를 사용하면서 다른 작업에 사용할 수 있도록 만들기 위해서입니다. 바디는 모두 구글에서 개발한 BERT 모델을 사용하지만 사용하려는 작업에 따라 서로 다른 헤드를 사용할 수 있습니다. 즉 바디는 트랜스포머 구조에서 사전학습만 진행한 인코더 부분이며, 다운스트림 태스크에 따른 헤드를 가져와서 각 태스크별로 동작하도록 할 수 있습니다.
허깅페이스 트랜스포머 라이브러리에서는 모델의 바디만 불러올 수도 있고, 헤드와 함께 불러올 수도 있습니다. 앞으로 모델을 세 번 불러와 볼 텐데, 첫 번째로는 바디만 불러오고, 두 번째로는 헤드와 함께 불러오고, 마지막으로 헤드가 함께 있는 모델에 바디만 불러옵니다. 각각의 경우를 비교해 보도록 하겠습니다.
# 모델 아이디로 모델 불러오기
from transformers import AutoModel
model_id = 'klue/roberta-base'
model = AutoModel.from_pretrained(model_id)
AutoModel 은 모델의 바디를 불러오는 클래스로, from_pretrained() 메서드에서 인자로 받는 model_id에 맞춰 적절한 클래스를 가져옵니다. model_id가 허깅페이스 모델 허브의 저장소 경로인 경우 모델 허브에서 모델을 다운로드하고, 로컬 경로인 경우 지정한 로컬 경로에서 모델을 불러옵니다. 해당 모델은 RoBERTa 모델을 한국어로 학습한 모델입니다.
그렇다면 AutoModel 클래스는 어떻게 klue/roberta-base 저장소의 모델이 RoBERTa 계열의 모델인지 알 수 있을까요? 허깅페이스 모델을 저장할 때 config.json 파일이 함께 저장되는데, 해당 설정 파일에는 모델의 종류(model_type), 여러 설정 파라미터(num_attention_heads, num_hidden_layer 등), 어휘 사전 크기(vocab_size), 토크나이저 클래스(tokenizer_class) 등이 저장됩니다. AutoModel 과 AutoTokenizer 클래스는 config.json 파일을 참고해 적절한 모델과 토크나이저를 불러옵니다.
model.config
Output:
RobertaConfig {
"_attn_implementation_autoset": true,
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"classifier_dropout": null,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"tokenizer_class": "BertTokenizer",
"torch_dtype": "float32",
"transformers_version": "4.50.0",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 32000
}
이번에는 텍스트 분류 헤드가 붙은 모델을 불러와 보도록 하겠습니다. 아래 예제를 실행하면, 모델 허브의 SamLowe/roberta-base-go_emotions 저장소에서 텍스트 분류 모델을 내려받아 classification_model 변수에 저장합니다. 이전 모델 바디만 불러올 때와 달리 AutoModelForSequenceClassification 클래스를 사용했는데, 이름에서도 알 수 있듯이 텍스트 시퀀스 분류를 위한 헤드가 포함된 모델을 불러올 때 사용하는 클래스입니다.
# 텍스트 분류 헤드가 포함된 모델 불러오기
from transformers import AutoModelForSequenceClassification
model_id = 'SamLowe/roberta-base-go_emotions'
classification_model = AutoModelForSequenceClassification.from_pretrained(model_id)
그리고 이 모델의 json 을 확인해 보면 이전과 달리 config.json 에 모델 아키텍처가 ‘~ForSequenceClassification’으로서 분류를 위한 모델임을 알 수 있습니다. 또 헤드의 분류 결과가 어떤 의미인지 확인할 수 있는 id2label 을 갖고 있습니다.
Output:
RobertaConfig {
"_attn_implementation_autoset": true,
"architectures": [
"RobertaForSequenceClassification"
],
...
"id2label": {
"0": "admiration",
"1": "amusement",
"2": "anger",
...}
}
이제 마지막으로 텍스트 분류를 위한 아키텍처에 모델 바디만 불러와 보도록 하겠습니다. 앞서 살펴본 대로 AutoModelForSequenceClassification 클래스를 사용하면 분류 헤드가 붙은 모델을 불러올 수 있습니다. 이 클래스를 사용해 모델 바디 부분의 파라미터만 있는 klue/roberta-base 저장소의 모델을 불러오면 어떻게 될지 한 번 보도록 하겠습니다.
# 모델의 바디만 불러오기와 보기
from transformers import AutoModelForSequenceClassification
model_id = 'klue/roberta-base'
classification_model = AutoModelForSequenceClassification.from_pretrained(model_id)
모델을 불러올 때 에러는 발생하지 않지만, 아래와 같은 경고가 나타납니다. 경고의 내용은 모델의 바디 부분은 klue/roberta-base 의 사전 학습된 파라미터를 불러왔지만 klue/roberta-base 모델 허브에서는 분류 헤드에 대한 파라미터를 찾을 수 없어 랜덤으로 초기화 했다는 것입니다. 분류 헤드는 랜덤으로 초기화됐기 때문에 그대로 사용해서는 안 되고 추가 학습 이후에 사용하라고 안내하고 있습니다.
Output:
Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at klue/roberta-base and are newly initialized: ['classifier.dense.bias', 'classifier.dense.weight', 'classifier.out_proj.bias', 'classifier.out_proj.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
3.2 토크나이저 활용하기
토크나이저는 텍스트를 토큰 단위로 나누고 각 토큰을 대응하는 토큰 아이디로 변환합니다. 필요한 경우 특수 토큰을 추가하는 역할도 합니다. 토크나이저도 학습 데이터를 통해 어휘 사전을 구축하기 때문에 일반적으로 모델과 함께 저장합니다. 토크나이저도 모델을 불러올 때와 마찬가지로 허깅페이스 모델 저장소 아이디를 통해 불러올 수 있습니다. 허깅페이스 허브에서 모델과 토크나이저를 불러오는 경우 동일한 모델 아이디로 맞춰야 합니다.
아래 예제를 실행하면 AutoTokenizer 클래스를 통해 앞서 모델을 불러올 때도 사용한 klue/roberta-base 저장소의 토크나이저를 불러옵니다. 모델 저장소(https://huggingface.co/klue/roberta-base/tree/main)를 확인하면 tokenizer_config.json 과 tokenizer.json 2개의 파일을 확인할 수 있는데, 모델에 대한 정보가 config.json 파일에 저장돼 있던 것처럼 토크나이저에 대한 정보를 저장하고 있습니다. tokenizer_config.json 은 토크나이저의 종류나 설정에 대한 정보를 가지고 있고 tokenizer.json 파일은 실제 어휘 사전 정보를 가지고 있습니다.
# 토크나이저 불러오기
from transformers import AutoTokenizer
model_id = 'klue/roberta-base'
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer
Output:
BertTokenizerFast(name_or_path='klue/roberta-base', vocab_size=32000, model_max_length=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': '[CLS]', 'eos_token': '[SEP]', 'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=False, added_tokens_decoder={
0: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
1: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
2: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
3: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
4: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
)
tokenizer에 텍스트를 이볅하면 토큰 아이디의 리스트인 input_ids, 토큰이 실제 텍스트인지 아니면 길이를 맞추기 위해 추가한 패딩(padding)인지 알려주는 attention_mask, 토큰이 속한 문장의 아이디를 알려주는 token_type_ids를 반환합니다.
input_ids는 토큰화했을 때 각 토큰이 토크나이저 사전의 몇 번째 항목인지를 나타냅니다. input_ids의 첫 번째 항목은 0이고 두 번째 항목은 9157인데, 각각 [CLS]와 ‘토크’에 대응되는 것을 확인할 수 있습니다.
attention_mask는 해당 토큰이 패딩인지 아닌지 알려주는 것으로 값이 1이면 패딩이 아닌 실제 토큰임을 의미합니다.
token_type_ids는 해당 토큰이 몇 번째 문장에 속하는지를 알려줍니다.
토큰 아이디를 다시 텍스트로 돌리고 싶다면 토크나이저의 decode 메서드를 사용하면 됩니다. 이때 [CLS]나 [SEP] 같은 특수 토큰이 추가된 것을 확인할 수 있는데 만약 특수 토큰을 제외하고 싶다면 skip_sepcial_tokens인자를 True로 설정하면 됩니다.
tokenized = tokenizer("토크나이저는 텍스트를 토큰 단위로 나눈다")
print(f"input_ids: {tokenized['input_ids']}")
print(f"token_type_ids: {tokenized['token_type_ids']}")
print(f"attention_mask: {tokenized['attention_mask']}\n")
print(tokenizer.convert_ids_to_tokens(tokenized['input_ids']))
print()
print(tokenizer.decode(tokenized['input_ids']))
print()
print(tokenizer.decode(tokenized['input_ids'], skip_special_tokens=True))
Output:
input_ids: [0, 9157, 7461, 2190, 2259, 8509, 2138, 1793, 2855, 5385, 2200, 20950, 2]
token_type_ids: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
['[CLS]', '토크', '##나이', '##저', '##는', '텍스트', '##를', '토', '##큰', '단위', '##로', '나눈다', '[SEP]']
[CLS] 토크나이저는 텍스트를 토큰 단위로 나눈다 [SEP]
토크나이저는 텍스트를 토큰 단위로 나눈다
토크나이저는 한 번에 여러 문장을 처리할 수도 있습니다. 아래 예제를 보도록 하겠습니다.
# 토크나이저에 여러 문장 넣기
tokenized = tokenizer(['첫 번째 문장', '두 번째 문장'])
print(f"input_ids: {tokenized['input_ids']}")
print(f"token_type_ids: {tokenized['token_type_ids']}")
print(f"attention_mask: {tokenized['attention_mask']}\n")
Output:
input_ids: [[0, 1656, 1141, 3135, 6265, 2], [0, 864, 1141, 3135, 6265, 2]]
token_type_ids: [[0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0]]
attention_mask: [[1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1]]
토크나이저의 batch_decode() 메서드를 사용하면 input_ids 부분의 토큰 아이디를 문자열로 복원할 수 있는데, 기본적으로 토큰화를 하면 [CLS] 토큰으로 문장을 시작하고 [SEP]으로 문장을 끝내는데, 2개의 문장을 한 번에 토큰화하면 [SEP]으로 두 문장을 구분합니다. 특수 토큰은 모델의 아키텍처에 따라 달라질 수 있으니 사용하려는 토크나이저가 어떤 특수 토큰을 사용하는지 확인해 볼 필요가 있습니다.
first_tokenized_result = tokenizer(['첫 번째 문장', '두 번째 문장'])['input_ids']
print(tokenizer.batch_decode(first_tokenized_result))
second_tokenized_result = tokenizer([['첫 번째 문장', '두 번째 문장']])['input_ids']
print(tokenizer.batch_decode(second_tokenized_result))
Output:
['[CLS] 첫 번째 문장 [SEP]', '[CLS] 두 번째 문장 [SEP]']
['[CLS] 첫 번째 문장 [SEP] 두 번째 문장 [SEP]']
토큰화 결과 중 token_type_ids는 문장을 구분하는 역할을 합니다. BERT는 학습할 때 2개의 문장이 서로 이어지는지 맞추는 NSP(Next Sentence Prediction) 작업을 활용하는데, 이를 위해 문장을 구분하는 토큰 타입 아이디를 만들었습니다. 그래서 BERT 모델의 토크나이저를 불러오면 아래 예제와 같이 문장에 따라 토큰 타입 아이디를 구분합니다.
아래 코드에서 klue/bert-base 토크나이저를 사용하는 경우 첫 번째 문장의 토큰 타입 아이디는 0, 두 번째 문장의 토큰 타입 아이디는 1입니다. 하지만 klue/roberta-base의 경우 token_type_ids가 모두 0인 것을 볼 수 있는데, RoBERTa 계열 모델의 경우 NSP 작업을 학습 과정에서 제거했기 때문에 문장 토큰 구분이 필요 없기 때문입니다. 영어 버전의 원본 roberta-base 토크나이저로 영어 문장을 토큰화하면 결과에 token_type_ids 항목 자체가 없는 것을 확인할 수 있습니다.
# BERT 토크나이저와 RoBERTa 토크나이저
bert_tokenizer = AutoTokenizer.from_pretrained('klue/bert-base')
bert_tokenized = bert_tokenizer([['첫 번째 문장', '두 번째 문장']])
print(f'input_ids: {bert_tokenized['input_ids']}')
print(f'token_type_ids: {bert_tokenized['token_type_ids']}')
print(f'attention_mask: {bert_tokenized['attention_mask']}')
print()
roberta_tokenizer = AutoTokenizer.from_pretrained('klue/roberta-base')
roberta_tokenized = roberta_tokenizer([['첫 번째 문장', '두 번째 문장']])
print(f'input_ids: {roberta_tokenized['input_ids']}')
print(f'token_type_ids: {roberta_tokenized['token_type_ids']}')
print(f'attention_mask: {roberta_tokenized['attention_mask']}')
print()
en_roberta_tokenizer = AutoTokenizer.from_pretrained('roberta-base')
en_roberta_tokenized = en_roberta_tokenizer([['first_sentence', 'second sentence']])
print(f'input_ids: {en_roberta_tokenized['input_ids']}')
print(f'attention_mask: {en_roberta_tokenized['attention_mask']}')
Output:
input_ids: [[2, 1656, 1141, 3135, 6265, 3, 864, 1141, 3135, 6265, 3]]
token_type_ids: [[0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]]
attention_mask: [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
input_ids: [[0, 1656, 1141, 3135, 6265, 2, 864, 1141, 3135, 6265, 2]]
token_type_ids: [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
attention_mask: [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
input_ids: [[0, 9502, 1215, 19530, 4086, 2, 2, 10815, 3645, 2]]
attention_mask: [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
마지막으로 attention_mask는 해당 토큰이 패딩 토큰인지 실제 데이터인지에 대한 정보를 담고 있습니다. 패딩은 모델에 입력하는 토큰 아이디의 길이를 맞추기 위해 추가하는 특수 토큰입니다. 아래 예제에서와 같이 토크나이저의 padding 인자에 ‘longest’를 입력하면 입력한 문장 중 가장 긴 문장에 맞춰 패딩 토큰을 추가합니다. 예시 문장을 보면 두 번째 문장인 ‘두 번째 문장은 첫 번째 문장보다 더 길다.’가 첫 번째 문장보다 더 깁니다. 따라서 더 긴 문장에 맞춰 패딩 토큰을 추가한다면 첫 번째 문장에 패딩이 추가될 것입니다. 아래 예제에서는 padding 인자를 사용했을 때와 사용하지 않았을 때 두 경우를 비교하고 있는데 padding 인자를 사용하지 않았을 경우에는 패딩 토큰이 추가되지 않은 것을 확인할 수 있습니다. 하지만 padding 인자에 ‘longest’를 넣어줬을 경우에 짧은 문장인 첫 번째 문장에 패딩 토큰이 추가된 것을 확인할 수 있습니다.
tokenizer = AutoTokenizer.from_pretrained('klue/roberta-base')
tokenized = tokenizer(['첫 번째 문장은 짧다', '두 번째 문장은 첫 번째 문장보다 더 길다.'])
print(f"input_ids: {tokenized['input_ids']}")
print(f"token_type_ids: {tokenized['token_type_ids']}")
print(f"attention_mask: {tokenized['attention_mask']}\n")
tokenized = tokenizer(['첫 번째 문장은 짧다', '두 번째 문장은 첫 번째 문장보다 더 길다.'], padding='longest')
print(f"input_ids: {tokenized['input_ids']}")
print(f"token_type_ids: {tokenized['token_type_ids']}")
print(f"attention_mask: {tokenized['attention_mask']}\n")
Output:
input_ids: [[0, 1656, 1141, 3135, 6265, 2073, 1599, 2062, 2], [0, 864, 1141, 3135, 6265, 2073, 1656, 1141, 3135, 6265, 2178, 2062, 831, 647, 2062, 18, 2]]
token_type_ids: [[0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
attention_mask: [[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
input_ids: [[0, 1656, 1141, 3135, 6265, 2073, 1599, 2062, 2, 1, 1, 1, 1, 1, 1, 1, 1], [0, 864, 1141, 3135, 6265, 2073, 1656, 1141, 3135, 6265, 2178, 2062, 831, 647, 2062, 18, 2]]
token_type_ids: [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
attention_mask: [[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
3.3 데이터셋 활용하기
datasets 라이브러리를 사용하면 앞서 허깅페이스 허브에서 살펴봤던 데이터셋을 코드로 불러올 수 있습니다. 아래 예제를 실행해 KLUE 데이터셋의 서브셋 중 하나인 MRC 데이터셋을 내려받아 봅시다.
# KLUE MRC 데이터셋 다운로드
from datasets import load_dataset
klue_mrc_dataset = load_dataset('klue', 'mrc')
print(klue_mrc_dataset)
#klue_mrc_dataset_only_train = load_dataset('klue', 'mrc', split='train')
데이터셋을 불러오는 함수는 load_dataset으로써, 데이터셋의 이름인 klue와 서브셋 이름인 mrc를 load_dataset 함수에 인자로 전달해서 MRC 데이텃세을 내려받았습니다. klue_mrc_dataset의 내용을 확인하면 아래와 같이 출력됩니다. 데이터셋에는 학습과 검증 유형의 데이터가 각각 17,554개, 5,841개 있으며 제목(title), 내용(context)과 질문(question), 정답(answer) 등의 컬럼이 있습니다.
Output:
DatasetDict({
train: Dataset({
features: ['title', 'context', 'news_category', 'source', 'guid', 'is_impossible', 'question_type', 'question', 'answers'],
num_rows: 17554
})
validation: Dataset({
features: ['title', 'context', 'news_category', 'source', 'guid', 'is_impossible', 'question_type', 'question', 'answers'],
num_rows: 5841
})
})
만약 유형이 train인 데이터만 받고 싶다면 주석처리된 코드와 같이 load_dataset 함수에 split=’train’ 인자를 입력하면 됩니다.
load_dataset 함수는 데이터셋 저장소에 있는 데이터만 불러올 수 있는 것은 아니고 아래 코드와 같이 로컬에 있는 파일이나 파이썬 객체를 받아 데이터셋으로 사용할 수 있습니다. 코드를 보면 로컬에 저장된 csv 파일을 불러오기 위해 load_dataset에 데이터의 형식인 csv를 지정하고 파일 경로를 data_files의 인자로 전달했습니다. 파이썬 딕셔너리를 데이터셋으로 변환하고 싶은 경우 Datset 클래스의 from_dict 메서드를 사용해 데이터셋으로 변환할 수 있습니다. 데이터 처리에서 많이 사용하는 판다스 데이터프레임을 데이터셋으로 변환하고 싶은 경우 Dataset 클래스의 from_pandas 메서드를 사용하면 됩니다. 더 다양한 데이터 형식을 다루는 방법에 대한 자세한 사항은 Datasets 불러오기 공식 문서(https://huggingface.co/docs/datasets/loading)에서 확인할 수 있습니다.
4. 모델 학습시키기
이제부터 한국어 기사 제목을 바탕으로 기사의 카테고리를 분류하는 텍스트 분류 모델 학습 실습을 진행해 보도록 하겠습니다. 먼저 실습에 사용할 데이터셋을 준비하고 모델과 토크나이저를 불러와 모델을 학습 시킵니다. 허깅페이스 트랜스포머에서는 간편하게 모델 학습을 수행할 수 있도록 학습 과정을 추상화한 트레이너(Trainer) API를 제공합니다. 트레이너 API를 사용하면, 학습을 간편하게 할 수 있다는 장점이 있지만 내부에서 어떤 과정을 거치는지 알기 어렵다는 단점도 있습니다. 따라서 이번 실습에서는 먼저 전체적인 흐름을 이해하기 위해 트레이너 API를 사용하지 않고 모델을 학습시키는 실습도 진행합니다. 마지막으로, 학습을 마친 모델을 저장하거나 공유할 수 있도록 허깅페이스 허브에 업로드하는 방법에 대해서도 간단히 알아보도록 하겠습니다.
4.1 데이터 준비
실습 데이터는 KLUE 데이터셋의 YNAT 서브셋을 활용합니다. YNAT에는 연합 뉴스 기사의 제목과 기사가 속한 카테고리 정보가 있습니다. 이번 실습에서는 연합 뉴스 기사의 제목을 바탕으로 카테고리를 예측하는 모델을 만들어 봅니다. 실습을 준비하기 위해 아래 예제를 실행해 봅시다. KLUE의 YNAT 학습 및 검증 데이터셋을 다운로드해 각각 klue_tc_train, klue_tc_eval 변수에 저장합니다.
# 모델 학습에 사용할 연합 뉴스 데이터셋 다운로드
from datasets import load_dataset
klue_tc_train = load_dataset('klue', 'ynat', split='train')
klue_tc_eval = load_dataset('klue', 'ynat', split='validation')
print(klue_tc_train)
다운로드가 진행된 이후 klue_tc_train 을 출력해보면 아래와 같이 출력되는 것을 확인해 볼 수 있습니다. 뉴스 제목(title), 뉴스가 속한 카테고리(label) 등의 컬럼으로 이뤄진 총 45,678개의 데이터가 있습니다.
Output:
Dataset({
features: ['guid', 'title', 'label', 'url', 'date'],
num_rows: 45678
})
개별 데이터의 형태를 보기위해 첫 번째 데이터를 살펴보도록 하겠습니다. klue_tc_train[0] 의 데이터를 확인하면 제목으로 ‘유튜브 내달 2일까지 크리에이터 지원 공간 운영’이라는 뉴스 제목이 있고, 레이블은 3으로 되어 있습니다.
# 데이터 확인
data = klue_tc_train[0]
for key in data.keys():
print(f"{key} : {data[key]}")
Output:
guid : ynat-v1_train_00000
title : 유튜브 내달 2일까지 크리에이터 지원 공간 운영
label : 3
url : https://news.naver.com/main/read.nhn?mode=LS2D&mid=shm&sid1=105&sid2=227&oid=001&aid=0008508947
date : 2016.06.30. 오전 10:36
데이터에는 레이블 값이 숫자로 되어 있어 어떤 카테고리인지 알기 어려운데, 다음과 같이 해서 카테고리를 확인할 수 있습니다. 이 코드에서는 데이터셋의 정보를 저장하고 있는 features 속성에서 label 컬럼의 항목별 이름을 확인합니다. 그리고 추후에 모델 학습에도 레이블을 사용하기 위해 id2label, label2id 작업을 진행해 놓습니다. 이 작업을 진행하는 이유는 학습하는 모델에 id2label, label2id 정보를 주지 않으면 모델은 LABEL_1, LABEL_2 와 같은 형태로 학습을 진행하고, 모델 추론때도 이러한 형태로 결과값을 내놓기 때문입니다. 하지만 우리는 우리가 지정한 레이블로 출력되고자 하기 때문에 이러한 작업을 진행합니다.
# 레이블 이름 확인
label_names = klue_tc_train.features['label'].names
print(label_names)
# 모델에 사용할 레이블 정리
# 이렇게 하지 않으면 학습된 모델에서 우리가 사용하고 싶은 레이블이 아닌 LABEL_1 이런 형식으로 나옴
id2label = {i:name for i, name in enumerate(label_names)}
label2id = {name:i for i, name in enumerate(label_names)}
['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치']
분류 모델을 학습시킬 때, guid, url, date 컬럼은 필요하지 않기 때문에 아래 코드로 데이터에서 제거합니다. remove_columns 메서드에 제거할 컬럼의 이름(guid, url, date)을 리스트 형태로 전달하면 데이터셋에서 지정한 컬럼을 삭제합니다. 예제 코드의 출력 결과를 보면 title과 label 컬럼만 남은 것을 확인할 수 있습니다.
# 사용하지 않는 데이터열 제거
klue_tc_train = klue_tc_train.remove_columns(['guid', 'url', 'date'])
klue_tc_eval = klue_tc_eval.remove_columns(['guid', 'url', 'date'])
klue_tc_train
klue_tc_eval
Output:
Dataset({
features: ['title', 'label'],
num_rows: 9107
})
이제 카테고리 확인하기 쉽도록 label_str 컬럼을 추가해 보도록 하겠습니다. 데이터셋의 정보를 갖고 있는 features 속성에서 label 컬럼을 확인하면, 레이블 ID와 카테고리를 연결할 수 있는 ClassLabel 객체가 있습니다. 해당 객체는 ID를 카테고리로 변환하는 init2str 이라는 메서드가 있습니다. init2str 메서드에 아이디 1을 입력하면 ‘경제’ 카테고리를 반환하는 것을 확인할 수 있습니다. 이를 활용해 label 컬럼의 숫자형 아이디를 카테고리 이름으로 변환하는 make_str_label 함수를 정의하고 데이터셋의 map 메서드를 사용해 label_str 컬럼을 추가합니다.
print(klue_tc_train.features['label'].int2str(1))
klue_tc_label = klue_tc_train.features['label']
def make_str_label(batch):
batch['label_str'] = klue_tc_label.int2str(batch['label'])
return batch
klue_tc_train = klue_tc_train.map(make_str_label, batched=True, batch_size=1000)
data = klue_tc_train[0]
for key in data.keys():
print(f"{key} : {data[key]}")
Output:
경제
Map: 100%
45678/45678 [00:00<00:00, 438153.46 examples/s]
title : 유튜브 내달 2일까지 크리에이터 지원 공간 운영
label : 3
label_str : 생활문화
빠른 실습 진행을 위해 학습 데이터는 모두 사용하지 않고 10,000개만 추출해서 사용합니다. 데이터셋에서 train_test_split 메서드를 사용하면 입력한 test_size 값에 맞춰 학습 데이터셋과 테스트 데이터셋으로 분리합니다. klue_tc_train에서 test_size를 10,000으로 지정해 랜덤으로 10,000개의 데이터를 추출합니다. 학습이 잘되고 있는지 확인할 검증 데이터와 성능 확인에 사용할 테스트 데이터는 검증 데이터셋에서 각각 1,000개씩 뽑아 사용합니다.
train_dataset = klue_tc_train.train_test_split(test_size=10000, shuffle=True, seed=42)['test']
dataset = klue_tc_eval.train_test_split(test_size=1000, shuffle=True, seed=42)
test_dataset = dataset['test']
valid_dataset = dataset['train'].train_test_split(test_size=1000, shuffle=True, seed=42)['test']
4.2 트레이너 API를 사용해 학습하기
허깅페이스는 학습에 필요한 다양한 기능(데이터로더 준비, 로깅, 평가, 저장 등)을 학습 인자(TrainingArguments)만으로 쉽게 활용할 수 있는 트레이너 API를 제공합니다. 먼저 트레이너 API를 사용해 학습을 수행하는 코드를 작성해 보도록 하겠습니다. 아래 예제는 필요한 라이브러리를 불러오고 모델과 토크나이저를 불러와 데이터셋에 토큰화를 수행합니다.
tokenize_function은 데이터의 title 컬럼의 토큰화를 수행합니다. 학습에 사용할 분류 모델을 불러오기 위해 AutoModelForSequenceClassification 클래스로 klue/roberta-base 모델을 불러옵니다. 앞서 살펴본 대로 모델 바디의 파라미터만 있는 klue/roberta-base 모델을 불러오면 분류 헤드 부분은 램덤으로 초기화됩니다. 이 코드에서는 분류 헤더의 분류 클래스 수를 지정하기 위해 num_labels 인자에 데이터셋의 레이블 수인 len(label_names)를 전달했고, 추후에 결과 레이블을 숫자가 아닌 실제 분류값으로 보기 위해 id2label 과 label2id 도 인자로 전달했습니다.
import torch
import numpy as np
from transformers import (
Trainer,
TrainingArguments,
AutoModelForSequenceClassification,
AutoTokenizer
)
def tokenize_function(examples):
return tokenizer(examples["title"], padding="max_length", truncation=True)
model_id = "klue/roberta-base"
model = AutoModelForSequenceClassification.from_pretrained(model_id,
num_labels=len(label_names),
id2label=id2label,
label2id=label2id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
train_dataset_1 = train_dataset.map(tokenize_function, batched=True)
valid_dataset_1 = valid_dataset.map(tokenize_function, batched=True)
test_dataset_1 = test_dataset.map(tokenize_function, batched=True)
이제 학습에 사용할 인자를 설정하는 TrainingArguments에 학습 인자를 입력합니다. 학습 인자에 들어가는 인자들은 다음과 같습니다.
- num_train_epoch : 학습 에폭 수
- per_device_train_batch_size : 배치 크기
- output_dir : 결과를 저장할 폴더
- eval_strategy : 평가를 수행할 빈도
- learning_rate : 학습률
- push_to_hub : 학습이 끝난 후 허깅페이스에 업로드 결정
예제에서는 에폭 수는 3으로, 배치 크기는 8로, 결과는 results 폴더에 저장하고 한 에폭 학습이 끝날 때마다 검증 데이터셋에 대한 평가를 수행하도록 eval_strategy 인자를 “epoch”으로 설정했습니다. 다음으로 학습이 잘 이뤄지고 있는지 확인할 때 사용할 평가 지표를 정의합니다(compute_metrics). 모델의 예측 결과인 eval_pred를 입력으로 받아 예측 결과 중 가장 큰 값을 갖는 클래스를 np.argmax 함수로 뽑아 predictions 변수에 저장하고, predictions와 정답이 저장된 labels가 같은 갖는 겨과의 비율을 정확도(accuracy)로 결과 딕셔너리에 저장해 반환합니다.
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
eval_strategy="epoch",
learning_rate=5e-5,
push_to_hub=False
)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"accuracy" : (predictions == labels).mean()}
마지막으로 Trainer에 앞서 준비한 데이터셋과 설정을 인자로 전달하고 train() 메서드로 학습을 진행합니다. 학습이 끝나면 evaluate() 메서드로 테스트 데이터셋에 대한 성능 평가를 수행합니다.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset_1,
eval_dataset=valid_dataset_1,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.evaluate(test_dataset_1)
학습이 끝나면 아래와 같이 출력됩니다. 정확도는 86.4% 정도 됩니다.
Output:
{'eval_loss': 0.44438067078590393,
'eval_accuracy': 0.864,
'eval_runtime': 27.0098,
'eval_samples_per_second': 37.024,
'eval_steps_per_second': 4.628,
'epoch': 1.0}
4.3 트레이너 API를 사용하지 않고 학습하기
트레이너 API를 사용할 때와 같이 모델과 토크나이저를 불러옵니다.
import torch
from tqdm.auto import tqdm
from torch.utils.data import DataLoader
from torch.optim import AdamW
import numpy as np
from transformers import (
Trainer,
TrainingArguments,
AutoModelForSequenceClassification,
AutoTokenizer
)
# 제목(title) 컬럼에 대한 토큰화
def tokenize_function(examples):
return tokenizer(examples["title"], padding="max_length", truncation=True)
# 모델과 토크나이저 불러오기
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_id = "klue/roberta-base"
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=len(train_dataset.features['label'].names))
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.to(device)
다음으로 데이터 전처리를 수행합니다. 전처리를 위해 make_dataloader 함수를 정의했는데 함수 내부에서 toeknize_function 함수를 사용해 토큰화를 수행하고, rename_column 메서드를 통해 기존에 “label”이었던 컬럼 이름을 “labels”로 변경합니다. title 컬럼의 토큰화를 수행했기 때문에 이제는 불필요해진 title 컬럼을 remove_columns 메서드를 사용해 제거합니다. 마지막으로 파이토치에서 제공하는 DataLoader 클래스를 사용해 데이터셋을 배치로 데이터로 만듭니다. Trainer를 사용하면 예제의 코드 중 토큰화를 제외한 나머지를 알아서 처리해 주는데, 그런 점에서 트레이너 API 가 편리한 점이 많은 것 같습니다.
# 학습을 위한 데이터 준비
def make_dataloader(dataset, batch_size, shuffle=True):
dataset = dataset.map(tokenize_function, batched=True).with_format("torch")
dataset = dataset.rename_column("label", "labels")
dataset = dataset.remove_columns(column_names=['title'])
return DataLoader(dataset, batch_size=batch_size, shuffle=shuffle)
train_dataloader = make_dataloader(train_dataset, batch_size=8, shuffle=True)
valid_dataloader = make_dataloader(valid_dataset, batch_size=8, shuffle=False)
test_dataloader = make_dataloader(test_dataset, batch_size=8, shuffle=False)
이제 학습과 평가에 사용할 함수를 만들어보도록 하겠습니다. 학습을 수행하는 train_epoch 함수에서는 먼저, train() 메서드를 사용해 모델을 학습 모드로 변경하고, 앞서 생성한 데이터로더에서 배치 데이터를 가져와 모델에 입력으로 전달합니다. 배치 데이터 안에는 토큰 아이드를 담고 있는 input_ids, 어텐션 마스크를 갖고 있는 attention_mask, 정답 레이블을 가진 labels 키가 있는데, 각각 model에 인자로 전달해 모델 계산을 수행합니다.
def train_epoch(model, data_loader, optimizer):
model.train()
total_loss = 0
for batch in tqdm(data_loader):
optimizer.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
total_loss += loss.item()
avg_loss = total_loss / len(data_loader)
return avg_loss
평가에 사용할 evaluate 함수를 정의합니다. evaluate 함수는 모델 계산을 수행하고, 손실을 집계하는 등 많은 부분에서 train_epoch 함수와 비슷합니다. 하지만 모델을 학습 모드가 아닌 추론 모드로 설정하고, 모델 계산 결과의 logits 속성을 가져와 torch.argmax 함수를 사용해 가장 큰 값으로 예측한 카테고리 정보를 찾고, 실제 정답과 비교해 정확도를 계산하는 부분이 추가돼 있습니다. 이를 통해 손실뿐만 아니라 정확도를 직접 확인할 수 있습니다.
def evaluate(model, data_loader):
model.eval()
total_loss = 0
predictions = []
true_labels = []
with torch.no_grad():
for batch in tqdm(data_loader):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
logits = outputs.logits
loss = outputs.loss
total_loss += loss.item()
preds = torch.argmax(logits, dim=-1)
predictions.extend(preds.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
avg_loss = total_loss / len(data_loader)
accuracy = np.mean(np.array(predictions) == np.array(true_labels))
return avg_loss, accuracy
이제 정의한 두 개의 함수를 이용해 학습과 평가를 진행해 보도록 하겠습니다.
num_epochs = 1
optimizer = AdamW(model.parameters(), lr=5e-5)
for epoch in range(num_epochs):
print(f"Epoch {epoch+1}/{num_epochs}")
train_loss = train_epoch(model, train_dataloader, optimizer)
print(f"Training loss: {train_loss}")
valid_loss, valid_accuracy = evaluate(model, valid_dataloader)
print(f"Validation loss: {valid_loss}")
print(f"Validation accuracy: {valid_accuracy}")
Output:
Training loss: 0.30773107492476703
Validation loss: 0.5261382934451103
Validation accuracy: 0.84
지금까지 Trainer를 사용했을 때와 사용하지 않았을 때 모델을 학습 시키는 방법에 대해서 알아보았습니다. Trainer를 사용하면 간편하다는 장점이 있고, Trainer를 사용하지 않으면 내부 동작을 명확히 확인할 수 있고, 직접 학습 과정을 조절할 수 있다는 각각의 장점이 있습니다.
4.4 학습한 모델 업로드 하기
학습한 모델은 아래 코드로 허깅펭스 허브에 업로드할 수 있습니다. huggingface_hub 라이브러리는 허깅페이스에 프로그래밍 방식으로 접근할 수 있는 기능을 지원하는데, 허깅페이스의 계정 토큰을 통해 로그인할 수 있습니다. 계정의 access token 을 생성할 때는 write 로 생성해야 합니다. 업로드 방법은 크게 Trainer를 사용했을 때와 사용하지 않았을 때로 나뉘는데, Trainer를 사용한 경우 Trainer 인스턴스에서 push_to_hub() 메서드를 사용하면 학습 모델과 토크나이저를 함께 모델 허브에 업로드합니다. 직접 학습한 경우 모델과 토크나이저를 각각 push_to_hub() 메서드로 업로드 할 수 있습니다.
from huggingface_hub import login
login(token="본인의 허깅페이스 토큰 입력")
repo_id = f"본인의 계정 이름/roberta-base-klue-ynat-classification"
# 트레이너를 사용했을 때 모델 업로드 방법
trainer.push_to_hub(repo_id)
# 트레이너를 사용하지 않고 직접 학습했을 때 모델 업로드 방법
model.push_to_hub(repo_id)
tokenizer.push_to_hub(repo_id)
5. 모델 추론하기
이번엔 학습한 모델로 추론하는 방법에 대해서 알아봅니다. 모델을 학습시킬 때 허깅페이스에서 제공하는 트레이너 API를 활용하는 방법과 직접 학습을 수행하는 방법이 있었습니다. 추론을 할 때도 마찬가지로 모델을 활용하기 쉽도록 추상화한 파이프라인을 활용하는 방법이 있고, 직접 모델과 토크나이저를 불러와 활용하는 방법이 있습니다. 먼저 파이프라인을 사용해 간단히 모델을 활용하는 방법에 대해서 알아보도록 하겠습니다.
5.1 파이프라인을 활용한 추론
허깅페이스는 아래 예제와 같이 토크나이저와 모델을 결합해 데이터의 전후처리와 모델 추론을 간단하게 수행하는 pipeline을 제공합니다. 파이프라인은 크게 작업 종류, 모델, 설정을 입력으로 받습니다. 작업 종류는 텍스트 분류, 토큰 분류 등 작업에 맞춰 설정 하고 모델에 저장소 아이디를 설정하면 됩니다. 아래 예제는 텍스트 분류 작업을 위한 모델을 불러오기 위해 pipeline에 인자로 text-classification과 모델 아이디를 전달합니다. 사용하는 모델은 이전에 우리가 업로드 했던 모델을 불러와 사용합니다.
#실습을 새롭게 시작하는 경우 데이터셋 다시 불러오기 실행
import torch
import torch.nn.functional as F
from datasets import load_dataset
dataset = load_dataset("klue", "ynat", split="validation")
모델 업로드 시 본인 계정의 Models 를 보면 업로드가 되어 있는데 이 때 아마도 output_dir 때문인지 저장되는 경로가 ‘본인계정이름/results’가 되어 버립니다. 따라서 model_id 를 아래와 같이 설정을 해주어야 합니다.
from transformers import pipeline
model_id = f"본인 계정 이름/results"
model_pipeline = pipeline("text-classification", model=model_id)
model_pipeline(dataset["title"][:5])
Output:
[{'label': '경제', 'score': 0.976737916469574},
{'label': '사회', 'score': 0.9186277985572815},
{'label': 'IT과학', 'score': 0.9550740122795105},
{'label': '경제', 'score': 0.9750317931175232},
{'label': '사회', 'score': 0.9680737853050232}]
5.2 직접 추론하기
직접 모델과 토크나이저를 불러와 pipeline과 유사하게 추론을 구현한다면 아래와 같이 구현할 수 있습니다. ini 메서드에서 입력받은 모델 아이디에 맞는 모델과 토크나이저를 불러옵니다. CustomPipeline의 인스턴스를 호출할 때 내부적으로 call 메서드를 사용하는데, tokenizer를 통해 토큰화를 수행하고 모델 추론을 수행하고 가장 큰 예측 확률을 갖는 클래스를 추출해 결과로 반환합니다.
import torch
from torch.nn.functional import softmax
from transformers import AutoModelForSequenceClassification, AutoTokenizer
class CustomPipeline:
def __init__(self, model_id):
self.model = AutoModelForSequenceClassification.from_pretrained(model_id)
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
self.model.eval()
def __call__(self, texts):
tokenized = self.tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = self.model(**tokenized)
logits = outputs.logits
probabilities = softmax(logits, dim=-1)
scores, labels = torch.max(probabilities, dim=-1)
labels_str = [self.model.config.id2label[label_idx] for label_idx in labels.tolist()]
return [{"label":label, "score":score.item()} for label, score in zip(labels_str, scores) ]
custom_pipeline = CustomPipeline(model_id)
custom_pipeline(dataset['title'][:5])
Output:
[{'label': '경제', 'score': 0.976737916469574},
{'label': '사회', 'score': 0.918627917766571},
{'label': 'IT과학', 'score': 0.9550740122795105},
{'label': '경제', 'score': 0.9750317931175232},
{'label': '사회', 'score': 0.9680737853050232}]
정리
트랜스포머 모델을 쉽게 활용할 수 있도록 통합된 인터페이스를 제공하는 허깅페이스 트랜스포머 라이브러리에 대해서 알아보았습니다. 허깅페이스 라이브러리는 크게 모델 허브, 토크나이저와 데이터셋 기능을 제공하고 간단하게 학습을 수행할 수 있는 Trainer 클래스와 간단하게 추론을 진행할 수 있는 pipeline 기능을 제공했습니다. 여기서 더 나아가 직접 학습과 추론을 구현해 보면서 세부적인 작동 방식도 살펴보았습니다.
마치며
간단하게 허깅페이스와 허깅페이스에서 제공하는 라이브러리들에 대해서 알아보았습니다. 허깅페이스를 통해 이전에는 사용하기 어려웠던 딥러닝 모델들을 이제는 누구나 학습시켜서 오픈해 사용할 수 있게 되었다는 것을 알게 되었고, 여건만 된다면 허깅페이스를 이용해 개인 프로젝트도 쉽게 진행할 수 있겠구나 하고 생각하였습니다. 이 포스트를 준비하면서 허깅페이스에 대해 좀 더 자세히 알아보고 싶었지만 일단은 LLM 과 RAG 에 대한 공부가 우선이기에 허깅페이스에 대한 것은 추후에 따로 다시 정리하고자 합니다.
이 포스트는 2025년 11월 11일에 작성된 포스트로 당시 최신 버전인 허깅페이스의 transformers, datasets, huggingface_hub 라이브러리를 사용했습니다. 제가 사용한 라이브러리의 버전은 다음과 같습니다.
- transformers : 4.57.1
- datasets : 4.0.0
- huggingface_hub : 0.36.0
이러한 딥러닝 모델의 라이브러리나 프레임워크 등은 변화가 빨라 버전이 수시로 바뀌며 내부 기능들도 수시로 바뀌게 됩니다. 그래서 버전끼리 호환이 안되는 경우가 많습니다. 혹시나 제 포스트를 참고하여 실습을 진행하시게 될 때 위 버전을 참고해서 진행해 주시길 바랍니다.
긴 글 읽어주셔서 감사드리며, 본문에 잘못된 내용이나, 오타, 궁금하신 사항이 있으신 경우 댓글 달아주시기 바랍니다.
참조
허정준 저, LLM 을 활용한 실전 AI 어플리케이션 개발
Comments