
[LLM/RAG] LLM Application - 4. LLM을 위한 임베딩
개요
1. 문장 임베딩
최근 여러 태스크에서는 단어 임베딩뿐만 아니라 문장의 의미를 나타내는 문장 임베딩의 필요가 증가하였습니다. 그러므로 문장 임베딩의 원리부터 파악해 보고, 오픈소스 문장 임베딩 모델을 쉽게 활용할 수 있도록 도와주는 Sentence-Transformers 라이브러리를 통해 문장 임베딩 모델의 구조를 살펴보고 그 사용법을 익혀보도록 하겠습니다.
1.1 문장 임베딩을 생성하는 두 가지 방법
BERT 모델이 출시되기 이전에는 워드투벡과 같은 단어를 벡터화 시킨 단어 임베딩을 활용하다가, 문장 전체의 의미를 나타내기 위해서 단어 임베딩을 사용했지만 단어 임베딩은 문장이 가지는 문맥의 정보까지는 담지 못하는 한계가 존재했습니다. 하지만 BERT 모델에서는 태스크 중 두 문장이 이어진 문장인지 별개의 문장인지를 구분하는 태스크가 있었고, 이를 위한 데이터를 학습한 BERT 모델의 출력 벡터는 문장 임베딩으로 사용이 가능해졌습니다.
BERT 모델을 사용해 문장과 문장 사이의 관계를 계산하는 방법은 크게 두 가지로 나눌 수 있습니다. 첫 번째 방식은 바이 인코더(bi-encoder) 방식입니다. 이 방식에서는 각각의 문장(문장 A와 B)을 독립적으로 BERT 모델에 입력으로 넣고, 모델의 출력 결과인 문장 임베딩 벡터 사이의 유사도를 코사인 유사도와 같은 별도의 계산을 통해 구합니다. 두 번째 방식은 교차 인코더(cross-encoder) 방식입니다. 이 방식에서는 두 문장을 함께 BERT 모델에 입력으로 넣고, 모델이 직접 두 문장 사이의 관계를 0에서 1 사이의 값으로 출력합니다. 교차 인코더 방식은 바이 인코더 방식에 비해 계산량이 많지만, 두 문장의 상호작용을 고려할 수 있어 좀 더 정확한 관계 예측이 가능합니다.
그러면 먼저 고안된 교차 인코더 방식에 대해서 알아보도록 하겠습니다. 교차 인코더 방식은 하나의 BERT 모델에 검색 쿼리 문장과 검색 대상 문장을 함께 입력으로 넣고 텍스트 사이의 유사도 점수를 계산합니다. 그렇기 때문에 두 텍스트의 유사도를 정확히 계산할 수 있다는 장점이 있습니다. 다만 단점으로는 입력으로 넣은 두 문장의 유사도만 계산하기 때문에 다른 문장과 검색 쿼리의 유사도를 알고 싶으면 다시 동일한 연산을 반복해야 한다는 단점이 있습니다.
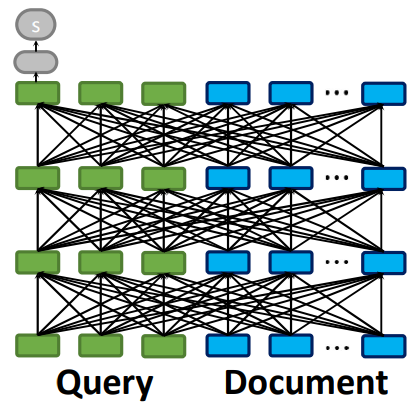
교차 인코더는 모든 문장 조합에 대해 유사도를 계산해야 가장 유사한 문장을 검색할 수 있어 확장성이 떨어집니다. 이런 문제를 극복하기 위해 검색 쿼리 문장과 검색 대상 문장을 각각의 모델에 입력하는 바이 인코더 방식이 개발 되었습니다. 각 문장은 동일한 모델을 통과해 각 문장에 대한 임베딩으로 변환됩니다. 그리고 두 문장 사이의 유사도는 각 문장 임베딩을 코사인 유사도와 같은 유사도 계산 방식을 통해 최종적인 유사도 점수를 산출합니다. 즉 바이 인코더 방식은 모델에 독립된 문장을 넣어서 추출된 문장 임베딩을 계산량이 적은 코사인 유사도를 진행하는 방식입니다.
1.2 BERT 모델을 이용한 문장 임베딩
바이 인코더 모델은 사전 학습된 BERT 모델을 이용해 BERT 모델의 출력 벡터를 문장 임베딩으로 사용하는 것입니다. BERT 모델은 입력 토큰마다 출력 임베딩을 생성합니다. 따라서 입력하는 문장의 길이가 달라질 경우 출력하는 임베딩의 수가 달라집니다. 문장의 길이가 다를 때 서로 다른 개수의 임베딩이 반환된다면, 문장과 문장 사이의 유사도를 쉽게 계산하기가 어렵습니다. 따라서 풀링 층을 사용해 문장을 대표하는 1개의 임베딩으로 통합합니다. 풀링 층을 통해 문장의 길이가 달라져도 1개의 고정된 차원의 임베딩이 반환되기 때문에 코사인 유사도와 같은 거리 계산 방식을 활용해 두 문장 임베딩 사이의 거리를 쉽게 계산할 수 있습니다.
Sentence-Transformers 라이브러리를 사용하면 쉽게 바이 인코더를 사용할 수 있습니다. 아래 예제는 허깅페이스 모델 허브에서 모델을 불러와 바이 인코더를 만들 수 있습니다. Sentence-Transformer 라이브러리에서 제공하는 models 모듈의 Transformer 클래스를 사용하면 허깅 페이스 모델 허브의 모델을 불러올 수 있습니다. 아래 예제에서는 klue/roberta-base 저장소에서 모델을 불러옵니다. 기본 언어 모델에 앞서 설명한 풀링 층을 models.Pooling 클래스를 활용해 생성합니다. 풀링 층에 입력으로 들어오는 토큰 임베딩의 차원을 알려주기 위해 기본 언어 모델의 get_word_embedding_dimension() 메서드를 사용합니다. 마지막으로 SentenceTransformer 클래스에 모듈로 언어 모델인 word_embedding_model과 풀링 층인 pooling_model을 리스트 형태로 입력해 바이 인코더를 생성합니다.
우선 예제 코드 실행에 필요한 라이브러리 설치부터 진행해 줍니다.
!pip install transformers==4.40.1 datasets==2.19.0 sentence-transformers==2.7.0 faiss-cpu llama-index==0.10.34 llama-index-embeddings-huggingface==0.2.0 -qqq
# sentence-transformers 라이브러리로 바이 인코더 생성하기
from sentence_transformers import SentenceTransformer, models
# 사용할 BERT 모델
word_embedding_model = models.Transformer('klue/roberta-base')
# 풀링 층 차원 입력하기
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
# 두 모델 결합하기
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
sentence_list = ['잠이 안 옵니다','졸음이 옵니다','기차가 옵니다']
embedding = model.encode(sentence_list)
print(embedding.shape)
예시 문장 세 개로 구성된 리스트를 model.encoder() 함수의 입력으로 넣고 문장 임베딩을 생성할 경우 768 차원의 3개의 벡터가 생성된 것을 확인할 수 있습니다.
Output:
(3, 768)
그리고 생성한 모델을 출력해 보면 바이 인코더 구조를 확인할 수 있습니다. 그리고 출력된 결과를 자세히 보면 세 가지의 풀링 모드(pooling_mode)가 있음을 확인할 수 있습니다. 풀링 모드에는 pooling_mode_cls_tokens, pooling_mode_mean_tokens, pooling_mode_max_tokens 세 가지 설정이 있고 이 중에서 pooling_mode_mean_tokens 가 True로 설정돼 있습니다.
print(model)
Output:
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False, 'architecture': 'RobertaModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
풀링 모드란, 언어 모델이 출력한 결과 임베딩을 고정된 크기의 문장 임베딩으로 통합 할 때 통합하는 방식입니다. 세 가지 방식을 설명하면 다음과 같습니다.
- 클래스 모드(pooling_mode_cls_tokens) : BERT 모델의 첫 번째 토큰인 [CLS] 토큰의 출력 임베딩을 문장 임베딩으로 사용합니다.
- 평균 모드(pooling_mode_mean_tokens) : BERT 모델에서 모든 입력 토큰의 출력 임베딩을 평균한 값을 문장 임베딩으로 사용합니다.
- 최대 모드(pooling_mode_max_tokens) : BERT 모델의 모든 입력 토큰의 출력 임베딩에서 문장 길이(sequence) 방향에서 최댓값을 찾아 문장 임베딩으로 사용합니다.
각 방식을 더 정확히 이해 하기 위해 코드를 통해 구현 방식을 살펴 보도록 하겠습니다. 우선 평균 모드는 model_output[0]로 언어 모델의 출력 중 마지막 층의 출력만 사용합니다. input_mask_expanded 는 입력이 패딩 토큰인 부분은 평균 계산에서 무시하도록 한 것이며, 이를 출력 임베딩에 곱해 줍니다. 마지막으로 출력 임베딩의 합을 패딩 토큰이 아닌 실제 토큰 입력의 수로 나눠줍니다.
# 평균 모드
import torch
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
최대 모드는 패딩 토큰인 부분에 아주 작은 값(-1e9)을 대입해 최댓값이 될 수 없도록 설정하고, 출력 임베딩의 토큰 길이 차원에서 가장 큰 값을 찾습니다.
# 최대 모드
import torch
def max_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
token_embeddings[input_mask_expanded == 0] = -1e9
return torch.max(token_embeddings, 1)[0]
1.3 Sentence-Transformers로 텍스트와 이미지 임베딩 생성해 보기
Sentence-Transformers 라이브러리는 허깅 페이스 모델을 불러와 쉽게 사용할 수 있도록 지원합니다. 따라서 허깅페이스 모델 허브에서 제공하는 모델이라면 텍스트뿐만 아니라 이미지 모델도 불러와 사용할 수 있습니다. 먼저 테스트 모델을 불러와 활용하는 예시를 살펴 보도록 하겠습니다. 한국어 문장 임베딩 모델인 snunlp/KR-SBERT-V40K-klueNLI-augSTS 저장소의 모델을 불러옵니다. 그리고 세 개의 예제 문장이 담긴 리스트를 model.encode() 함수에 입력으로 넣어 임베딩을 생성합니다. 그리고 util.cos_sim() 함수를 이용해 임베딩 사이의 코사인 유사도를 구해봅니다.
# 한국어 문장 임베딩 모델로 입력 문장 사이의 유사도 계산
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
embs = model.encode(['잠이 안 옵니다','졸음이 옵니다','기차가 옵니다'])
cos_scores = util.cos_sim(embs, embs)
print(cos_scores)
출력된 유사도 계산 결과를 보면 ‘잠’과 ‘졸음’에 관련된 첫 두 문장 사이의 유사도는 0.641로 비교적 높게 나오고, ‘잠’과 ‘기차’로 주제가 다른 첫 번째 문장과 세 번째 문장은 0.1887, ‘졸음’과 ‘기차’로 주제가 다른 첫 번째 문장과 세 번째 문장은 0.273으로 비교적 낮은 유사도 점수를 보이는 것을 확인할 수 있습니다.
Output:
tensor([[1.0000, 0.6410, 0.1887],
[0.6410, 1.0000, 0.2730],
[0.1887, 0.2730, 1.0000]])
허깅페이스 모델 허브에서 제공하는 이미지 모델을 활용하면 이미지도 이미지 임베딩으로 쉽게 변환할 수 있습니다. 이제 살펴볼 예제는 이미지와 텍스트를 모두 임베딩으로 변환할 수 있는 모델을 사용해 이미지 임베딩을 만들어 보도록 하겠습니다. 아래 이미지는 예시로 사용할 이미지로 잔디에 앉아 있는 강아지와 노란 배경에 있는 고양이 사진입니다.

이미지와 텍스트를 임베딩을 변환하기 위해 허깅페이스 허브에 있는 clip-ViT-B-32 모델을 사용했습니다. CLIP(Contrastive Language-Image Pre-training) 모델은 OpenAI가 개발한 텍스트-이미지 멀티 모달 모델로 이미지와 텍스트의 임베딩을 동일한 벡터 공간상에 배치해 유사한 텍스트와 이미지를 찾을 수 있습니다. model.encode()로 이미지와 텍스트를 임베딩화 시킵니다. 그리고 텍스트와 이미지 임베딩의 코사인 유사도를 구해봅니다.
# CLIP 모델을 활용한 이미지와 텍스트 임베딩 유사도 계산
from PIL import Image
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('clip-Vit-B-32')
dog_file_path = "/content/drive/MyDrive/LLM_RAG_Application/embedding/dog.jpg"
cat_file_path = "/content/drive/MyDrive/LLM_RAG_Application/embedding/cat.jpg"
img_embs = model.encode([Image.open(dog_file_path), Image.open(cat_file_path)])
text_embs = model.encode(['A dog on grass', 'Brown cat on yellow background'])
cos_scores = util.cos_sim(img_embs, text_embs)
print(cos_scores)
이미지와 텍스트 임베딩의 코사인 유사도를 구해보면 강아지 이미지와 ‘A dog on grass’ 문장이 높은 유사도를 고양이 이미지와 ‘Brown cat on yellow background’ 문장이 높은 유사도를 보이는 것을 확인할 수 있습니다.
Output:
tensor([[0.2771, 0.1554],
[0.2071, 0.2878]])
2. 의미 검색 구현해 보기
이제 임베딩을 사용하기 위한 sentence-transformers에 대해서 알게 되었으니 이를 이용해 의미 검색을 직접 구현해 보도록 하겠습니다. 여기서 의미 검색이란 단순히 키워드 매칭을 통한 검색이 아니라 밀집 임베딩을 이용해 문장이나 문서의 의미를 고려한 검색을 수행하는 것을 말합니다. 그리고 검색을 해야하기 때문에 임베딩을 담아둘 벡터 DB가 필요 합니다. 이번에는 메타에서 개발한 벡터 연산 라이브러리인 faiss를 사용해 보도록 하겠습니다. faiss는 코사인 유사도, 유클리드 거리 등 가장 기본적인 벡터 거리 계산 방법을 지원할 뿐만 아니라, 벡터 검색 속도를 향상해 주는 ANN(Approximate Nearst Neighbor) 알고리즘도 다양하게 제공하고 있습니다.
2.1 의미 검색 구현하기
실습을 위해서 이전에 보았던 KLUE의 데이터셋 MRC(Machine Reading Comprehension) 데이터를 활용합니다. 우선 아래 코드를 실행해 데이터와 모델을 불러오도록 하겠습니다.
# 의미 검색 실습에 사용할 모델과 데이터셋 불러오기
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
klue_mrc_dataset = load_dataset('klue', 'mrc', split='train')
sentence_model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
KLUE MRC 데이터셋의 앞에서부터 1,000개의 데이터만 추출하고 텍스트 임베딩으로 변환합니다. 임베딩할 때 사용할 텍스트는 본문 데이터를 사용합니다. 그러므로 본문 데이터가 있는 context 컬럼을 문장 임베딩 모델에 입력으로 넣어 문장 임베딩으로 변환합니다.
# 실습 데이터에서 1,000개만 선택하고 문장 임베딩으로 전환
klue_mrc_dataset = klue_mrc_dataset.train_test_split(train_size=1000, shuffle=False)['train']
embeddings = sentence_model.encode(klue_mrc_dataset['context'])
print(embeddings.shape)
출력 결과를 보면 1,000개의 문장 임베딩이 잘 생성된 것을 확인할 수 있습니다.
Output:
(1000, 768)
그렇다면 이제 임베딩을 이용한 의미 검색을 한 번 진행해 보도록 하겠습니다. “이번 연도에는 언제 비가 많이 올까?”라는 검색 쿼리 문장을 문장 임베딩 모델의 encode 메서드를 사용해 문장 임베딩으로 변환하고 인덱스의 search 메서드로 검색을 수행합니다. 이때 search 메서드의 두 번째 인자로 3을 입력했을 때, 쿼리 임베딩과 가장 가까운 3개의 문서를 반환 받겠다는 의미입니다.
query = "이번 연도에는 언제 비가 많이 올까?"
query_embedding = sentence_model.encode([query])
distances, indices = index.search(query_embedding, 3)
for idx in indices[0]:
print(idx)
print(klue_mrc_dataset['context'][int(idx)][:50]) # idx 값을 int로 해주지 않으면 idx 는 numpy.int 라 에러가 발생함
출력 결과를 보면 가장 먼저 올여름 장마에 대한 기사 본문이 검색 됐고, 다음으로 오리너구리에 대한 기사가 검색된 것을 확인할 수 있습니다. 가장 먼저 출력된 “올 여름 장마가…” 기사는 실습 데이터셋의 첫 번째 데이터인데, 검색 쿼리 문장과 겹치는 단어가 거의 없음에도 가장 가까운 문서로 검색됐습니다. 의미 검색은 키워드 검색과 달리 동일한 키워드가 사용되지 않아도 의미적으로 유사성이 있다면 가깝게 평가한다는 장점이 있습니다.
Output:
0
올여름 장마가 17일 제주도에서 시작됐다. 서울 등 중부지방은 예년보다 사나흘 정도 늦은 (정답)
920
연구 결과에 따르면, 오리너구리의 눈은 대부분의 포유류보다는 어류인 칠성장어나 먹장어, 그 (오답)
921
연구 결과에 따르면, 오리너구리의 눈은 대부분의 포유류보다는 어류인 칠성장어나 먹장어, 그 (오답)
그렇다면 이제 의미 검색의 한계에 대한 예제를 한 번 살펴보도록 하겠습니다. 검색 쿼리로 사용한 문장은 로버트 헨리 딕이 개발한 것을 묻는 질문입니다. 로버트 헨리 딕은 레이더를 개발한 사람으로, 의미 검색이 잘 작동한다면 매사추세츠 연구소에서 레이더를 개발한 기사 본문이 가장 먼저 검색돼야 합니다. 하지만 아래 예제를 실행하면 태평양 전쟁에 대한 기사가 가장 먼저 검색 됩니다. 태평양 전쟁에 대한 데이터는 실습 데이터셋의 79, 80번째 데이터에 있는데, 전문을 출력해 읽어보면 로버트 헨리 딕이나 매사추세츠 연구소와 관련된 내용이 전혀 없습니다. 이처럼 의미 검색은 키워드가 동일하지 않아도 의미가 유사하다면 찾을 수 있다는 장점이 있는 반면, 관련성이 떨어지는 검색 결과가 나오기도 한다는 단점이 있습니다.
query = klue_mrc_dataset[3]['question']
print(f"query : {query}")
query_embedding = sentence_model.encode([query])
distances, indices = index.search(query_embedding, 3)
for idx in indices[0]:
print(klue_mrc_dataset['context'][int(idx)][:50])
Output:
0
올여름 장마가 17일 제주도에서 시작됐다. 서울 등 중부지방은 예년보다 사나흘 정도 늦은
920
연구 결과에 따르면, 오리너구리의 눈은 대부분의 포유류보다는 어류인 칠성장어나 먹장어, 그
921
연구 결과에 따르면, 오리너구리의 눈은 대부분의 포유류보다는 어류인 칠성장어나 먹장어, 그
2.2 라마인덱스에서 Sentence-Transformers 모델 사용하기
RAG 구현에 사용한 라마인덱스에 Sentence-Transformers 를 사용해보도록 하겠습니다. 라마인덱스는 기본적으로 OpenAI의 text-embedding-ada-002를 사용하기 때문에 OpenAI API 키만 설정하면 라마인덱스에서 내부적으로 임베딩 API를 호출해 변환을 수행합니다. 그렇다면 이번 장에서 알아본 Sentence-Transformers 라이브러리를 활용해 임베딩을 수행하려면 어떻게 해야하는지 알아보도록 하겠습니다.
라마인덱스는 아래 예제와 같이 간단하게 Sentence-Transformers의 임베딩 모델을 통합할 수 있는 기능을 지원합니다. 허깅페이스 허브에 모델이 저장된 경우, HuggingFaceEmbedding 클래스에 모델 이름으로 모델 저장소 이름을 입력하면 해당 저장소의 모델을 불러옵니다. 만약 로컬에 저장된 모델을 활용하고 싶다면, 주석 처리된 내용과 같이 ServiceContext에서 로컬 모델의 경로를 설정해 주면 됩니다.
# 라마인덱스에서 Sentence-Transformers 임베딩 모델 활용
from llama_index.core import VectorStoreIndex, ServiceContext
from llama_index.core import Document
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="snunlp/KR-SBERT-V40K-klueNLI-augSTS")
service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=None)
# 로컬 모델 활용하기
# service_context = ServiceContext.from_defaults(embed_model="local")
text_list = klue_mrc_dataset[:100]['context']
documents = [Document(text=t) for t in text_list]
index_llama = VectorStoreIndex.from_documents(
documents,
service_context=service_context,
)
3. 검색 방식을 조합해 의미 검색 성능 높이기
이전 항목에서 의미 검색은 똑같은 키워드가 없어도 의미가 유사한 키워드나 문장을 찾아준다는 장점이 있었습니다. 하지만 한계로 전혀 유사해 보이지 않아도 조금이라도 의미가 유사하다는 이유만으로 전혀 엉뚱한 대답을 내놓곤 합니다. 이러한 의미 검색의 한계를 해결하기 위해 옛날부터 쓰이던 키워드 검색 방식과 의미 검색 방식을 조합한 방식을 알아보도록 하겠습니다. 그 전에 먼저 여태까지 성능이 높아 자주 사용되던 키워드 검색 방식에 대해서 자세히 먼저 알아본 다음 의미 검색과 키워드 검색을 조합한 방식을 알아보도록 하겠습니다.
3.1 키워드 검색 방식: BM25
BM25는 TD-IDF와 유사한 통계 기반 스코어링 방법으로, TF-IDF에 문서의 길이에 대한 가중치를 추가한 알고리즘입니다. BM25는 간단하고 계산량이 적으면서도 뛰어난 성능을 보여 대표적인 검색 엔진인 엘라스틱서치(Elasticsearch)의 기본 알고리즘으로 사용됩니다. 이전까지 많은 임베딩 기반 검색 방법이 BM25의 성능을 넘지 못했고, 비교적 최근에 와서야 BM25를 넘어섰을 정도로 강력한 알고리즘입니다.
BM25의 수식은 아래와 같습니다.
\[\text{Score}(D, Q) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot \left(1 - b + b \cdot \frac{|D|}{\text{avgdl}}\right)}\]그럼 수식을 좀 더 상세히 하나 하나 해체해서 보도록 하겠습니다. IDF 부분을 먼저 보면 IDF는 특정 단어가 얼마나 희귀한지를 나타냅니다. 즉 특정 단어가 전체 문서에서 얼마나 많이 혹은 적게 등장하는지에 대한 척도를 나타내는 것으로 예를 들어 영어 문장에서 굉장히 많이 등장하는 is나 the와 같은 단어들은 전체 문서에서도 똑같이 굉장히 자주 등장하기 때문에 점수를 낮게, 그 외에 특정 문서에서만 굉장히 높게 등장하고 전체 문서에서는 거의 등장하지 않는 단어들에는 높은 점수를 부여하기 위해 고안되었습니다.
\[\text{IDF}(q_i) = \ln \left( \frac{N - n(q_i) + 0.5}{n(q_i) + 0.5} + 1 \right)\]- $N$ : 전체 문서의 수
- $n(q_i)$ : 단어 $q_i$가 포함된 문서의 수
- 0.5 : 스무딩(Smoothing) 값으로, 특정 단어가 포함된 문서가 없거나 모든 문서에 포함될 때 계산 오류를 방지합니다.
다음으로 TF 부분을 보도록 하겠습니다. TF는 단어가 문서 내에서 얼마나 자주 등장하는지를 나타내지만, 무작정 비례해서 점수가 오르지 않도록 $k1$ 파라미터로 제한을 둡니다.
\[f(q_i, D) \cdot (k_1 + 1)\]- $f(q_i, D)$ : 문서 D 내에서 단어 $q_i$의 출현 빈도
- $k_1$ : 단어 빈도의 포화 지점을 결정하는 파라미터(보통 1.2~2.0 사이 사용) 단어가 아무리 많이 나와도 점수가 무한정 오르지 않게 제어하는 역할을 합니다.
이제 마지막으로 문서 길이 정규화 부분을 보도록 하겠습니다. 전체 수식의 분모에서 $f(q_i, D)$ 와 함께 더해지는 수식으로 이 수식의 역할은 문서 길이에 대한 가중치로, 긴 문서는 당연히 단어가 많이 포함되므로, 단순히 길이가 길어서 점수가 높아지는 것을 방지하기 위해 패널티를 주는 부분입니다. 수식은 아래와 같습니다.
\[k_1 \cdot \left(1 - b + b \cdot \frac{|D|}{\text{avgdl}}\right)\]- $ |D| $ : 현재 문서 $D$의 길이 (단어 수)
- $avgdl$ : 전체 문서들의 평균 길이
- $b$ : 문서 길이 정규화의 강도를 결정하는 파라미터 (0~1사이 값, 보통 0.75사용)
- $b$ = 1이면 문서 길이에 따라 점수를 완전히 보정합니다.
- $b$ = 0이면 문서 길이를 전혀 고려하지 않습니다.
BM25를 정리 하자면 “BM25는 희귀한 단어(IDF)가 포함되어 있는가?”를 기본으로 하되, “문서 내에 얼마나 자주 등장하는가(TF)”를 $k_1$으로 조절하고, “문서가 원래 긴 편인가(Length Normalization)”를 $b$로 보정하여 최종 점수를 산출하는 방식이라고 정리할 수 있습니다.
3.2 상호 순위 조합
하이브리드 검색을 위해서는 통계 기반 점수와 임베딩 유사도 점수를 하나로 합쳐야 합니다. 하지만 점수마다 분포가 다르기 때문에 두 점수를 그대로 더하면 둘 중 하나의 영향을 더 크게 반영하게 됩니다. 예를 들면 A와 B 점수를 결합해 사용하는데 A 점수는 0~100점으로 분포하고 B 점수는 1~10점으로 분포할 때 그대로 더할 경우 A 점수의 영향이 더 크게 반영됩니다.
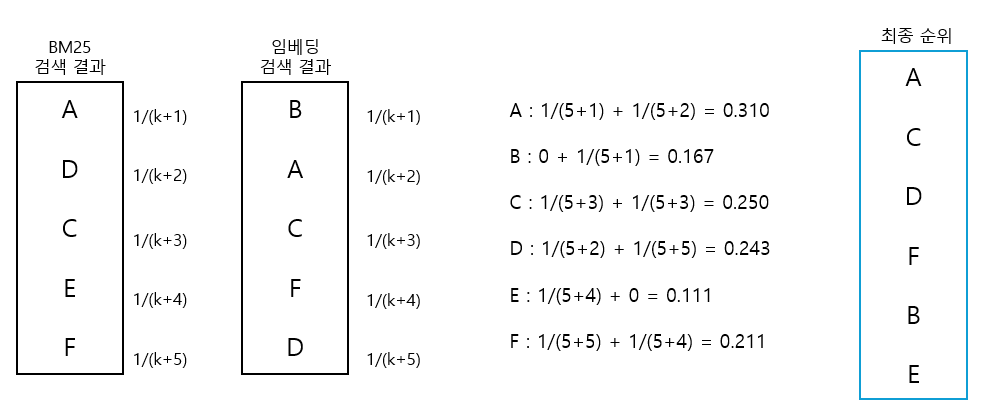
이런 문제를 해결하기 위해 상호 순위 조합(Reciprocal Rank Fusion)은 각 점수에서의 순위를 활용해 점수를 산출합니다. 원리는 우선 각각의 점수 산정 방식에 따라 순위를 정합니다. 그리고 순위에 따라 점수(1/(k+순위))를 부여합니다. 여기서 k는 조절 가능한 인자입니다. 아래 예시를 보면 좀 더 쉽게 이해가 가능합니다.
4. 하이브리드 검색 구현 실습
이제 앞서 이론적으로 알아본 임베딩 기반의 의미 검색과 BM25 기반의 키워드 검색을 혼합한 하이브리드 검색을 실제로 구현해 보도록 하겠습니다.
4.1 BM25 구현하기
import math
import numpy as np
from typing import List
from transformers import PreTrainedTokenizer
from collections import defaultdict
class BM25:
"""
BM25 검색 알고리즘 구현 클래스
HuggingFace의 Tokenizer를 활용하여 텍스트를 토큰화하고,
BM25 수식을 적용하여 문서와 쿼리 간의 연관성 점수를 계산합니다.
"""
def __init__(self, corpus: List[List[str]], tokenizer: PreTrainedTokenizer):
"""
클래스 초기화 및 필수 통계값 미리 계산
Args:
corpus: 검색 대상이 될 문서들의 리스트 (예: ["문서1 내용", "문서2 내용", ...])
tokenizer: 텍스트를 토큰 ID로 변환해줄 HuggingFace Tokenizer
"""
self.tokenizer = tokenizer
self.corpus = corpus
# 1. 전처리: 모든 문서를 토큰화하여 정수 ID 리스트로 변환
# add_special_tokens=False: [CLS], [SEP] 같은 BERT 특수 토큰은 검색에 불필요하므로 제외
self.tokenized_corpus = self.tokenizer(corpus, add_special_tokens=False)['input_ids']
# 2. 문서 통계 계산 (BM25 수식의 파라미터로 사용됨)
self.n_docs = len(self.tokenized_corpus) # 전체 문서의 개수 (N)
# 평균 문서 길이 (avgdl) 계산
# 모든 문서의 길이를 합친 후 문서 개수로 나눔
self.avg_doc_lens = sum(len(lst) for lst in self.tokenized_corpus) / len(self.tokenized_corpus)
# 3. 성능 최적화: 매번 계산하지 않도록 IDF와 TF를 미리 계산(Caching)해 둠
self.idf = self._calculate_idf()
self.term_freqs = self._calculate_term_freqs()
def _calculate_idf(self):
"""
IDF (Inverse Document Frequency, 역문서 빈도) 계산
목표: 흔한 단어(예: 'the', 'is')는 가중치를 낮추고,
희귀한 단어(특정 키워드)는 가중치를 높임.
"""
idf = defaultdict(float)
# 1단계: 각 단어가 몇 개의 문서에 등장했는지 카운트 (Document Frequency)
for doc in self.tokenized_corpus:
# set(doc)을 사용하는 이유:
# 한 문서에 같은 단어가 여러 번 나와도 '1개 문서에서 등장함'으로 치기 위함
for token_id in set(doc):
idf[token_id] += 1
# 2단계: IDF 공식 적용 (Probabilistic IDF)
# 수식: log( (N - n + 0.5) / (n + 0.5) + 1 )
# N = 전체 문서 수(self.n_docs), n = 단어가 등장한 문서 수(doc_frequency)
# +0.5 = 스무딩(Smoothing) 처리를 통해 분모가 0이 되거나 음수가 되는 것을 방지
for token_id, doc_frequency in idf.items():
idf[token_id] = math.log(((self.n_docs - doc_frequency + 0.5) / (doc_frequency + 0.5)) + 1)
return idf
def _calculate_term_freqs(self):
"""
TF (Term Frequency, 단어 빈도) 미리 계산
목표: 각 문서 내에서 특정 단어가 몇 번 등장했는지를 미리 세어둠.
결과: term_freqs[문서인덱스][단어ID] = 등장횟수
"""
term_freqs = [defaultdict(int) for _ in range(self.n_docs)]
for i, doc in enumerate(self.tokenized_corpus):
for token_id in doc:
term_freqs[i][token_id] += 1
return term_freqs
def get_scores(self, query: str, k1: float = 1.2, b: float = 0.75):
"""
주어진 쿼리에 대해 모든 문서의 BM25 점수를 계산
Args:
query: 검색할 질문 문자열
k1: 단어 빈도 포화(Saturation) 파라미터 (보통 1.2 ~ 2.0).
값이 클수록 단어 빈도가 점수에 미치는 영향이 커짐.
b: 문서 길이 정규화 파라미터 (보통 0.75).
1에 가까울수록 긴 문서에 대한 페널티가 강해짐.
Returns:
scores: 각 문서의 BM25 점수가 담긴 numpy 배열
"""
# 1. 쿼리 토큰화 (문서 토큰화와 동일한 방식 적용)
query = self.tokenizer([query], add_special_tokens=False)['input_ids'][0]
# 점수를 저장할 배열 초기화 (문서 개수만큼 0으로 채움)
scores = np.zeros(self.n_docs)
# 2. 쿼리에 포함된 각 단어(q)에 대해 점수 계산
for q in query:
# 해당 단어의 IDF 값 가져오기
idf = self.idf[q]
# 모든 문서를 순회하며 점수 누적 (실제 검색엔진에서는 Inverted Index로 최적화함)
for i, term_freq in enumerate(self.term_freqs):
# TF: 현재 문서(i)에서 쿼리 단어(q)가 몇 번 나왔는가?
q_frequency = term_freq[q]
# 문서 길이(|D|)
doc_len = len(self.tokenized_corpus[i])
# --- [BM25 핵심 수식 적용] ---
# 분자(Numerator): TF * (k1 + 1)
numerator = q_frequency * (k1 + 1)
# 분모(Denominator): TF + k1 * (1 - b + b * (|D| / avgdl))
# 길이가 평균보다 긴 문서는 분모가 커져서 점수가 깎임 (Length Penalty)
denominator = q_frequency + k1 * (1 - b + b * (doc_len / self.avg_doc_lens))
# 최종 점수 누적: IDF * (분자 / 분모)
score_q = idf * (numerator / denominator)
scores[i] += score_q
return scores
def get_top_k(self, query: str, k: int):
"""
상위 k개의 관련 문서를 반환
"""
# 전체 문서의 점수 계산
scores = self.get_scores(query)
# 점수가 높은 순서대로 정렬하여 상위 k개의 인덱스 추출
# argsort: 오름차순 정렬 인덱스 반환 -> [-k:]: 뒤에서 k개 -> [::-1]: 뒤집어서 내림차순으로 만듦
top_k_indices = np.argsort(scores)[-k:][::-1]
# 해당 인덱스의 점수 추출
top_k_scores = scores[top_k_indices]
return top_k_scores, top_k_indices
그럼 이제 구현한 BM25 클래스를 이용해 BM25 스코어 계산을 해보도록 하겠습니다. BM25 계산을 위해서는 토크나이저가 필요한데, 이번 실습에서는 허깅페이스의 사전 학습된 토크나이저를 활용합니다. “안녕하세요”, “반갑습니다”, “안녕 서울” 이라는 3개의 문서가 있을 때 “안녕”이라는 문서는 첫 번째, 세 번째 문서와는 0.512, 0.6으로 유사도가 계산되지만 두 번째 문서인 “반갑습니다”와는 일치하는 토큰이 없어 유사도가 0이 됩니다.
# 구현한 BM25 클래스로 BM25 점수 확인해 보기
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('klue/roberta-base')
bm25 = BM25(['안녕하세요', '반갑습니다', '안녕 서울'], tokenizer)
print(bm25.get_scores('안녕'))
Output:
[0.51277505 0. 0.60040117]
이제 구현한 BM25 클래스를 이전에 임베딩을 이용한 의미 검색을 진행했던 쿼리로 검색을 진행해 보도록 하겠습니다. 이전에 사용했던 “이번 연도에는 언제 비가 많이 올까?”를 검색 쿼리 문장으로 사용해 BM25 검색을 수행합니다. 먼저 BM25 검색을 준비하기 위해 실습 데이터셋과 토크나이저를 BM25 클래스에 입력합니다. 그리고 검색 쿼리 문장을 get_top_k 메서드에 입력하고 상위 100개의 문서를 찾습니다. 검색 결과를 확인하기 위해 3개의 검색 결과를 출력합니다.
# BM25 검색 결과의 한계
bm25 = BM25(list(klue_mrc_dataset['context']), tokenizer)
query = "이번 연도에는 언제 비가 많이 올까?"
_, bm25_search_ranking = bm25.get_top_k(query, 100)
for idx in bm25_search_ranking[:3]:
print(klue_mrc_dataset['context'][int(idx)][:50])
출력된 결과를 보면 “올여름 장마가…“로 시작하는 정답 기사는 세 번째 검색 결과로 등장한 것을 확인할 수 있습니다. 검색 쿼리 문장과 정답 기사 사이에 일치하는 키워드가 적어 가장 먼저 검색되지 않은 것입니다.
Output:
갤럭시S5 언제 발매한다는 건지언제는 “27일 판매한다”고 했다가 “이르면 26일 판매한다
인구 비율당 노벨상을 세계에서 가장 많이 받은 나라, 과학 논문을 가장 많이 쓰고 의료 특
올여름 장마가 17일 제주도에서 시작됐다. 서울 등 중부지방은 예년보다 사나흘 정도 늦은
다음으로 레이더를 개발한 로버트 헨리 딕에 대한 검색 쿼리 문장으로 BM25 검색을 진행해 보도록 하겠습니다. “로버트 헨리 딕이 1946년에 매사추세츠 연구소에서 개발한 것은 무엇인가?”라는 검색 쿼리 문장을 입력하면 검색 결과 정답 기사인 “미국 세인트루이스…“를 잘 찾은 것을 확인할 수 있습니다. 기사 본문을 출력해 보면 “매사추세츠 연구소”라는 표현이 많이 등장하는데, BM25는 일치하는 키워드를 바탕으로 관련된 기사를 잘 찾았습니다 .
# BM25 검색 결과의 장점
query = klue_mrc_dataset[3]['question']
print(f"query : {query}")
_, bm25_search_ranking = bm25.get_top_k(query, 100)
for idx in bm25_search_ranking[:3]:
print(klue_mrc_dataset['context'][int(idx)][:50])
Output:
query : 로버트 헨리 딕이 1946년에 매사추세츠 연구소에서 개발한 것은 무엇인가?
미국 세인트루이스에서 태어났고, 프린스턴 대학교에서 학사 학위를 마치고 1939년에 로체스
비상식과 판타지는, 때로는 서로 닮는 경우도 있지만, 그러나 양자는 분명히 구별된다. 판타
에릭 레이먼드가 쓴 〈성당과 시장〉(The Cathedral and the Bazaar)은
4.2 상호 순위 조합 구현해 보기
그럼 이제 BM25의 순위와 의미 검색 순위를 조합하는 상호 순위 조합 함수를 구현해 보도록 하겠습니다. 아래 코드의 reciprocal_rank_fusion 함수는 각 검색 방식으로 계산해 정해진 문서의 순위를 입력으로 받아 상호 순위 조합 점수가 높은 순서대로 정렬해서 반환합니다. 이 함수는 입력으로 여러 검색 방식에서 정해진 유사한 문서의 인덱스 리스트를 입력으로 받습니다. 그런 다음 각각의 순위 리스트를 순회하면서 각각의 문서 인덱스(doc_id)에 1/(k+순위)의 점수를 더합니다. 마지막으로, 점수를 종합한 딕셔너리를 점수에 따라 높은 순으로 정렬해 반환합니다. 즉, 상호 순위 조합을 통해 여러 검색 방식의 점수를 종합하고, 높은 점수를 받은 순서대로 다시 정렬합니다.
# 상호 순위 조합 함수 구현
from collections import defaultdict
def reciprocal_rank_fusion(rankings:List[List[int]], k=5):
rrf = defaultdict(float)
for ranking in rankings:
for i, doc_id in enumerate(ranking, 1):
rrf[doc_id] += 1.0 / (k+i)
return sorted(rrf.items(), key=lambda x: x[1], reverse=True)
# 예시 데이터에 대한 상호 순위 조합 결과 확인하기
rankings = [[1, 4, 3, 5, 6], [2, 1, 3, 6, 4]]
reciprocal_rank_fusion(rankings)
위 코드를 실행하면 아래와 같은 결과가 출력됩니다. 두 리스트에서 doc_id가 ‘1’인 문서는 결국 순위가 1이 되고, 두 번째 리스트에서 순위가 1위인 doc_id가 ‘2’인 문서는 첫 번째 리스트에는 존재하지 않아 결국 순위가 5번째로 밀려난 것을 확인할 수 있습니다.
Output:
[(1, 0.30952380952380953),
(3, 0.25),
(4, 0.24285714285714285),
(6, 0.2111111111111111),
(2, 0.16666666666666666),
(5, 0.1111111111111111)]
상호 조합 순위 코드까지 구현을 했습니다. 그렇다면 이제 BM25로 검색된 문서와, 임베딩 의미 검색으로 검색된 문서에 상호 순위 조합을 적용해 보도록 하겠습니다. 아래 코드에서 hybrid_search 함수를 구현했고, dense_vector_search 함수는 의미 검색에서 반복적으로 수행하던 검색 쿼리 문장 임베딩 변환과 인덱스 검색 부분을 한 번에 수행할 수 있도록 정의했습니다. hybrid_search 함수는 검색 쿼리 문장과 상호 순위 조합에 사용할 파라미터 k를 입력으로 받습니다. 입력으로 받은 쿼리 문장으로 의미 검색과 BM25 키워드 검색을 수행합니다. 마지막으로 상호 순위 조합을 사용해 두 검색 방식의 순위를 조합하고 결과를 반환합니다.
# 하이브리드 검색 구현하기
def dense_vector(query:str, k:int):
query_embedding = sentence_model.encode([query])
distances, indices = index.search(query_embedding, k)
return distances[0], indices[0]
def hybrid_search(query, k=20):
_, dense_search_ranking = dense_vector(query, 100)
_, bm25_search_ranking = bm25.get_top_k(query, 100)
results = reciprocal_rank_fusion([dense_search_ranking, bm25_search_ranking], k=k)
return results
앞의 예제에서 사용했던 두 문장 “이번 연도에는…” 과 “로버트 헨리 딕…” 문장으로 하이브리드 검색을 진행해 보았습니다.
# 예시 데이터에 대한 하이브리드 검색 결과 확인
query = "이번 연도에는 언제 비가 많이 올까?"
print("검색 쿼리 문장 : ", query)
results = hybrid_search(query)
for idx, score in results[:3]:
print(klue_mrc_dataset['context'][int(idx)][:50])
print("="*80)
query = klue_mrc_dataset[3]['question']
print("검색 쿼리 문장 : ", query)
results = hybrid_search(query)
for idx, score in results[:3]:
print(klue_mrc_dataset['context'][int(idx)][:50])
결과를 보면 BM25와 임베딩 의미 검색만 사용했을 때는 한계가 있어 실제로는 1순위로 올라와야 했던 문장들이 후순위로 잡히던 문제들이 하이브리드 방식을 사용했을 때는 두 문장 모두에서 가장 연관이 높은 문장이 1순위로 잡히는 것을 확인할 수 있었습니다.
Output:
검색 쿼리 문장 : 이번 연도에는 언제 비가 많이 올까?
올여름 장마가 17일 제주도에서 시작됐다. 서울 등 중부지방은 예년보다 사나흘 정도 늦은
연구 결과에 따르면, 오리너구리의 눈은 대부분의 포유류보다는 어류인 칠성장어나 먹장어, 그
정부가 올 12월부터 난방 에너지를 구입할 수 있는 카드 형태의 바우처(이용권)를 매년 저
================================================================================
검색 쿼리 문장 : 로버트 헨리 딕이 1946년에 매사추세츠 연구소에서 개발한 것은 무엇인가?
미국 세인트루이스에서 태어났고, 프린스턴 대학교에서 학사 학위를 마치고 1939년에 로체스
태평양 전쟁 중 뉴기니 방면에서 진공 작전을 실시해 온 더글러스 맥아더 장군을 사령관으로
태평양 전쟁 중 뉴기니 방면에서 진공 작전을 실시해 온 더글러스 맥아더 장군을 사령관으로
정리
이번 포스트에서는 의미 검색에 사용하는 문장 임베딩 방식이 개발될 때까지 자연어 처리 분야에서 텍스트의 의미를 담아 숫자로 변환하기 위해 개발됐던 다양한 기술을 살펴봤습니다. 기존에 알고 있던 단어 임베딩 방식을 넘어 문장 임베딩에 대해서 알게 됐고, 문장 임베딩 생성 원리에 대해서도 알아보았습니다. 또한 문장 임베딩을 사용하기 위한 Sentence-Transformer 와 그 사용 방법에 대해서도 알게 되었습니다. 그리고 TF-IDF보다 성능이 높은 BM25에 대해서 구체적으로 알게 되었고, 실제 코드까지 구현해 보기도 하였습니다. 마지막으로 임베딩을 이용한 의미 검색과 BM25를 이용한 키워드 검색 그리고 최종적으로 성능 향상을 위해 두 가지 방식을 합친 상호 순위 조합이라는 개념과 실제 코드까지 구현해 보면서 이론을 넘어 실제 구현해 보기도 하였습니다.
마치며
이번 포스트를 준비하면서 정보 검색에서의 기초적인 개념인 TF-IDF에서 BM25라는 개념까지 알게 되었습니다. 하지만 BM25외에도 여러 성능이 높은 키워드 방식이 있다고 어렴풋이 알고 있습니다. 추후에 시간이 나면 여러 키워드 검색 방식에 대해서도 알아보도록 하고자 합니다. 또한 임베딩을 이용한 의미 검색 방식의 기초적인 방식에 대해서 다루었는데 이후에는 좀 더 심화 개념이 있는지 살펴보고, 또 새로운 임베딩 방식 그리고 BERT 외의 다른 모델을 이용한 임베딩 방식이 있는지도 알아보고자 합니다.
이제 다음 포스트는 문장 임베딩 모델을 추가 학습해 검색 증강 생성의 성능을 높이는 방법에 대해서 알아보도록 하겠습니다.
긴 글 읽어주셔서 감사드리며, 본문 중에 잘못된 내용이나 오타, 궁금하신 사항이 있으신 경우 댓글 달아주시기 바랍니다.
참조
- 허정준 저, LLM 을 활용한 실전 AI 어플리케이션 개발
- ColBERT:Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
Comments