
[Python] 효율적이고 빠른 Python 프로그래밍 방법들
Python 은 이례적으로 개발 시간을 줄일 수 있는 프로그래밍 기법을 많이 가지고 있습니다. 이번엔 효율적이고 빠른 Python 프로그래밍 방법들에 대해서 알아보고자 합니다. “파이썬 스킬업” 이라는 책을 참고해서 이 포스트를 작성하였습니다.
1. 여러가지 Python 프로그래밍 지름길
“파이썬 스킬업” 이라는 책에서 소개하는 22가지 Python 프로그래밍 지름길 방법들 중에서 제가 봤을 때 유용하다고 판단이 되는 것들만 추려보았습니다.
1.1 for 루프는 현명하게 사용한다.
C 와 같은 언어에 익숙하다면 리스트 항목을 출력하는데 range 함수를 남용하는 경향이 있을 수 있습니다. 다음 예시는 range 와 인덱스를 사용한 C 언어 스타일의 for 루프입니다.
beat_list = ['John', 'Paul', 'George', 'Ringo']
for i in range(len(beat_list)):
print(beat_list[i])
Python 에서 위와 같은 방식으로 for 루프를 사용하고 있다면 다음과 같이 리스트나 이터레이터의 내용을 직접 출력하는 것이 더 좋습니다.
beat_list = ['John', 'Paul', 'George', 'Ringo']
for guy in beat_list:
print(guy)
만약 번호까지 생성하려고 한다면 enumerate 함수를 사용하는 것이 더 좋습니다.
beat_list = ['John', 'Paul', 'George', 'Ringo']
for i, name in enumerate(beat_list, 1):
print(i, '.', name, sep='')
출력 결과
1.John
2.Paul
3.George
4.Ringo
이렇게 사용해야 하는 이유는 다음과 같습니다.
-
의도 전달과 가독성
파이썬의
for시퀀스의 요소를 직접 순회하도록 설계 되어 있습니다. 따라서 리스트나 이터레이터의 내용을 직접 사용하는 것이 “요소를 하나씩 처리하겠다”라는 의도가 명확하기 때문에 리스트의 요소를 인덱스로 접근하는 것보다 더 좋습니다. -
버그를 줄일 수 있음(오프바이원, 잘못된 인덱싱)
인덱스를 직접 접근할 경우 인덱스 연산을 매번 하므로 오프바이원 같은 실수를 하기 쉽습니다.
-
더 파이써닉하고, 더 일반적임
파이썬의 반복은 이터페이터 프로토콜을 따릅니다. 즉, 리스트 뿐만 아니라 제너레이터, 파일 객체 등 인덱스가 없는 이터러블도 그대로 순회할 수 있습니다. 하지만
range를 이용한 인덱싱 방식은 인덱싱 가능한 시퀀스에만 자연스럽고, 스트림형 이터러블엔 맞지 않습니다. -
성능, 메모리 관점에서도 이점
직접 순회는 C 레벨의 이터레이터가 요소를 바로 건네주므로, 매 반복마다 인덱싱하는 것보다 불필요한 조회를 줄일 수 있습니다. 또 이터레이터는 데이터를 복사하지 않고 흘려보내며 순회하기 때문에 패턴 자체가 더 메모리 친화적입니다.
1.2 다중 대입을 사용한다
다중 대입은 파이썬에서 가장 널리 사용되는 코딩 지름길 기법입니다. 다음 예제와 같이 주로 사용됩니다.
a = b = c = d = e = 0
1.3 튜플 대입을 사용한다
다중 대입은 여러 변수에 동일한 초깃값을 대입할 때 유용합니다. 하지만 서로 다른 값을 각각 다른 변수에 대입하고 싶을 경우에는 다중 대입을 사용할 수 없고 다음과 같이 해야 합니다.
a = 1
b = 0
하지만 튜플 대입을 사용하면 1줄로 위 코드를 작성할 수 있습니다.
a, b = 1, 0
이 방법은 대입 연산자(=) 좌측에 변수를 나열하고, 우측에 같은 숫자의 값을 나열합니다. 양쪽 개수가 반드시 동일해야 하지만, 한 가지 예외가 있습니다. 여러 단일 값을 하나의 튜플에 대입할 수 있습니다.
a = 4, 8, 12
프로그래밍 언어 대부분은 a 와 b 를 동시에 설정하는 방법을 제공하지 않습니다. b 에 넣을 값이 변경되는 동시에, a 에 넣을 값도 변경되기 때문에 값을 설정할 수 없습니다. 그래서 일반적으로 임시 변수가 필요합니다. Python 에서도 원한다면 다음과 같이 코드를 작성할 수 있습니다.
temp = a
a = a + b
b = temp
하지만 튜플 대입을 사용하면 임시 변수가 필요 없습니다. 특히 두 값을 변경할 때 유용하게 사용됩니다.
a, b = a+ b, a
x, y = 1, 25
x, y = y, x
1.4 고급 튜플 대입을 사용한다
튜플 대입은 정제 기능을 제공합니다. 다음과 같이 여러 변수에 튜플의 항목을 하나씩 대입하는 튜플 언팩(unpack)을 할 수 있습니다. 다만 주의할 점은 튜플 언팩을 시도할 때는 대입 연산자 좌측의 변수 개수와 우측의 값 개수가 반드시 동일해야 합니다.
tup = 10, 20, 30
a, b, c = tup
print(a, b, c) # 10 20 30
# 런타임 에러 발생
a, b = tup
별표 기호(*)를 사용하면 튜플 대입에 추가적인 유연성을 더할 수 있습니다. 튜플을 활용하면 한 변수는 나머지 항목들을 담는 리스트가 될 수 있습니다. 이해를 돕기 위해 다음 예시를 살펴보도록 하겠습니다.
a, *b = 2, 4, 6, 8
print(a) # 2
print(b) # [4, 6, 8]
별표 기호는 좌측 변수 중 어떤 곳으로도 옮길 수 있지만, 1개 이상 사용할 수 없습니다. 별표 기호가 붙은 변수는 나머지 항목들을 모두 품는 리스트를 갖게 됩니다. 예시를 보도록 하겠습니다.
a, *b, c = 10, 20, 30, 40, 50
print(a) # 10
print(b) # [20, 30, 40]
print(c) # 50
1.5 IDLE 안에서 비효율적인 print 함수 사용을 줄인다
IDLE 안에서 호출한 print 문 실행 속도는 굉장히 느립니다. 이런 경우 print 호출 빈도수를 줄이면 놀라울 정도로 처리 속도를 개선할 수 있습니다.
예를 들어 별표 기호(*)fh 40x20 블록을 출력하고 싶다고 한다면, 가장 느린 방법은 개별적으로 출력하는 것입니다. 만약 한 번에 한 행의 별표 기호를 출력하면 훨씬 성능이 좋아집니다.
# 실행 속도가 느린 코드
for i in range(20):
for j in range(40):
print('*', end=' ')
print()
# 실행 속도를 개선한 방법
row_of_asterisks = '*' * 40
for i in range(20):
print(row_of_asterisks)
하지만 최고 성능을 확보하는 방법은 여러 줄의 큰 문자열을 미리 만들고 나서 print 함수를 한 번만 호출하게 코드를 변경하는 것입니다.
row_of_asterisks = '*' * 40
s = ''
for i in range(20):
s += row_of_asterisks + '\n'
print(s)
문자열 클래스의 join 메서드를 사용하면 성능을 더 개선할 수 있습니다. 매번 새로운 문자열 생성하여 추가하는 것보다 메모리상의 동일 리스트에 값을 추가하기 때문입니다.
print('\n'.join(['*' * 40] * 20))
1.6 큰 번호 안에 언더스코어(_)를 넣는다
프로그래밍을 하다 보면 큰 리터럴 숫자를 다루는 경우가 종종 있습니다.
CEO_salary = 1500000
이런 숫자는 프로그래밍 코드에서 제대로 읽기가 어렵습니다. 콤마 기호를 사용하고 싶지만, 리스트나 튜플을 만들 때 사용되기 때문에 사용할 수 없습니다. 다행히 파이썬은 다른 기법을 제공하는데 파이썬은 리터럴 숫자 안에 언더스코어 기호를 사용할 수 있습니다.
CEO_salary = 1_500_000
다음 규칙에 따라 언더스코어 기호는 숫자 안에 어디로든지 위치할 수 있습니다. 파이썬은 숫자를 읽을 때 언더스코어 없이 숫자를 읽게 됩니다.
- 한 번에 언더스코어를 2개 사용할 수 없다
- 언더스코어를 맨 앞 혹은 맨 뒤에 사용할 수 없다, 맨 앞에 언더스코어를 사용하면 숫자 값이 아니라 변수 이름으로 여긴다
- 언더스코어는 실수의 정수나 소수점 양쪽에 모두 사용할 수 있다.
이 기법은 코드 안에서 보여지는 숫자에만 영향을 미치며, 추력할 때는 영향을 미치지 않습니다. 숫자를 천 단위로 구분하여 출력하는 방법은 5장에서 설명하는 format 함수를 사용하면 됩니다.
2. 파이썬의 패키지들
python.org 에는 무료로 사용할 수 있는 수천 개의 패키지가 존재합니다. re, math, random, array, deciaml, fractions 패키지는 파이썬 3을 내려받을 때 포함되어 있기 때문에 따로 패키지를 내려받아 설치할 필요가 없습니다. 반면 numpy, matplotlib, pandas 패키지는 pip 나 pip3 를 사용하여 별도로 사용할 패키지를 설치해야 합니다. 이러한 패키지들을 표로 정리해 보았습니다.
| 탑재 모듈 이름 | 상세 설명 |
|---|---|
| re | - 정규표현식 패키지 이 패키지로 많은 단어, 구문 혹은 문장과 일치하는 텍스트 패턴을 만들 수 있다. 이 패턴-사양(pattern-specification) 언어는 매우 효율적으로 섬세한 검색을 할 수 있게 해준다 |
| math | - 수학 패키지, 유용한 표준 수학 함수들을 포함하고 있어 직접 만들 필요가 없다. 삼각함수, 쌍곡선 함수, 지수 함수, 로그 함수, 상수 e, pi(원주율) 등을 포함한다. |
| random | - 무작위 값을 생성하는 함수들의 집합이다. 무작위 숫자는 현실적으로 사용자가 예측하는 것이 불가능한 숫자를 의미한다. - 무작위 생성 패키지는 요청하는 범위 내에 임의 정수나 부동소수점, 정규 분포 등을 생성할 수 있다. 정규 분포는 평균값을 중심으로 군집화하여 빈도수의 “종형 곡선”을 형성한다. |
| decimal | - 이 패키지는 Decimal 데이터 타입을 지원하는데, (float 타입과는 달리) 반올림 오류 없이 달러와 센트 수치를 정확하게 나타낼 수 있다. Decimal 은 회계나 금융 애플리케이션에서 자주 사용된다. |
| fractions | - 이 패키지는 두 정수의 비율로 절대 정밀도를 소수점으로 저장하는 Fraction 데이터 타입을 지원한다. 예를 들어 이 데이터 타입은 float 타입이나 Deciaml 타입으로는 반올림 오류가 발생하는 1/3 의 비율을 절댓값으로 표현할 수 있다. |
| array | - 이 패키지는 리스트와는 다르게 원천(raw) 데이터를 연속적인 공간에 저장하는 array 클래스를 지원한다. 이 방식이 항상 빠른 것은 아니지만, 다른 프로세스와 상호 작용할 때 연속적인 공간에 데이터를 넣어야 하는 경우 필요하다. 반면 이 패키지의 장점은 비슷하지만 더 많은 기능을 제공하는 numpy 패키지에 의해서 훨씬 더 확장된다. |
| numpy | - 이 패키지는 1차, 2차 및 다차원 배열의 고성능 배치 처리를 지원하는 numpy(numeric python) 클래스를 제공한다. 이 클래스는 그 자체만으로도 대량 데이터를 다루는 초고속 프로그램을 만들 때 유용하지만, 다른 클래스의 기초 패키지로도 활용된다. - numpy 는 pip 혹은 pip3로 설치해야 한다. |
| matplotlib.pyplot | - 이 패키지는 파이썬에서 섬세한 그래프를 그릴 수 있도록 도와준다. 이 기능을 사용하면 심지어 3차원 데이터의 아름다운 도표와 그래프를 만들 수 있다. - 이 패키지는 pip 나 pip3 로 설치해야 한다. |
| pandas | - 이 패키지는 다양한 정보를 담고 있는 테이블 형태의 데이터 프레임을 제공하며, 인터넷으로부터 정보를 수집하여 적재하는 기능을 제공합니다. 이렇게 수집하여 적재한 정보는 numpy 와 조합할 수 있으며, 인상적인 그래프를 손쉽게 그릴 수 있습니다. |
3. 함수는 일급(first-class) 객체이다.
Python 의 함수는 일급 객체입니다. 여기서 일급(first-class) 객체란 어떤 값이 변수에 담기고, 다른 함수의 인자로 전달되고, 반환값으로 돌아오고, 자료구조(리스트/딕셔너리)에 저장될 수 있으면 “일급”입니다. 즉 Python 에서는 함수가 이러한 취급을 받습니다. Python 의 함수를 일급 객체로 다루면 디버깅, 프로파일링, 그리고 관련 작업 수행 시 무척 유용한 또 하나의 생산적인 도구를 갖게 되는 셈입니다. 이 방법으로 런타임 시 함수 관련 정보를 확보하는 장점을 취할 수 있습니다. 함수가 일급 객체인 것을 예제로 통해 알아보고 추후에 이러한 Python 의 함수의 성질을 이용한 여러 다른 기능들에 대해서도 알아보도록 하겠습니다. 우선 예를 들어 아래와 같이 avg 함수를 정의했다고 하겠습니다.
def avg(a_list):
'''리스트 항목들의 평균값을 반환한다.'''
x = (sum(a_list) / len(a_list))
print('The averate is ', x)
return x
avg 는 이 함수를 참조하는 심벌릭 이름이며, Python 언어 안에서 호출될 수 있는 콜러블(callable) 이기도 합니다. 우리는 avg 의 타입이 function 인 것을 검증하는 것과 같이 avg 와 함께 여러 작업을 수행할 수 있습니다.
def avg(a_list):
'''리스트 항목들의 평균값을 반환한다.'''
x = (sum(a_list) / len(a_list))
print('The averate is ', x)
return x
print(type(avg)) # <class 'function'>
우리는 함수의 이름이 avg인 것을 알고 있기 때문에 전혀 새로운 정보라고 볼 수 없습니다. 하지만 한 가지 재미있는 기능은 새로운 이름을 부여할 수 있다는 것입니다. 서로 다른 함수들을 모두 심벌릭 이름 avg 로 지정할 수도 있습니다.
def avg(a_list):
'''리스트 항목들의 평균값을 반환한다.'''
x = (sum(a_list) / len(a_list))
print('The averate is ', x)
return x
def new_func(a_list):
return (sum(a_list) / len(a_list))
old_avg = avg
avg = new_func
앞으로 심벌릭 이름 old_avg 는 우리가 앞서 선언한 더 오래되고 긴 함수를 참조하게 되며, 심벌릭 이름 avg 는 이제 막 정의된 신규 함수를 참조하게 됩니다.
이제 이름 old_avg 는 우리의 첫 평균 함수를 참조하게 되었고, avg 를 호출했던 방식과 똑같이 호출할 수 있게 되었습니다.
old_avg([4, 6])
실행 결과
The averate is 5.0
5.0
평범하지만 메타함수(metafunction)라고도 부를 수 있는 다음 함수는 인수로 전달받은 다른 함수의 정보를 출력하고 있습니다.
def func_info(func):
print('Function name:', func.__name__)
print('Function documentation:')
help(func)
이 함수에 인수로 old_avg 넣어서 실행하면 다음과 같이 실행 결과가 출력됩니다.
def avg(a_list):
'''리스트 항목들의 평균값을 반환한다.'''
x = (sum(a_list) / len(a_list))
print('The averate is ', x)
return x
def new_func(a_list):
return (sum(a_list) / len(a_list))
def func_info(func):
print('Function name:', func.__name__)
print('Function documentation:')
help(func)
old_avg = avg
avg = new_func
func_info(old_avg)
실행 결과
Function name: avg
Function documentation:
Help on function avg in module __main__:
avg(a_list)
리스트 항목들의 평균값을 반환한다.
4. 가변 길이 인수 리스트
파이썬에서 가변 길이 인수 리스트는 다양한 용도로 사용할 수 있습니다. 여기서 말하는 가변 길이 인수 리스트란, 파이썬에서 함수 정의시 * 또는 ** 표기를 사용해 호출 시 전달되는 임의 개수의 인수를 한데 모아 받는 매개변수 구문을 말합니다. 가변 길이 인수 리스트는 ‘키워드 인수’라고도 불리는 명명 인수를 사용하는 것으로 기능이 확장됩니다.
4.1 *args 리스트
*args 문법은 모든 길이의 인수 리스트에 접근하는 데 사용됩니다.
def 함수_이름([일반_인수,] *args):
dosomething
대괄호 기호 안에 위치한 여러 ‘일반_인수’는 선택적으로 추가할 수 있는 위치 인수(positional argument)들이며, 그 뒤로 *args 가 뒤따릅니다. 이 모든 인수는 항상 선택적으로 추가할 수 있는 것들입니다.
위 문법에서 이름 args 는 사실 어떤 심벌릭 이름이 와도 상관없습니다. 관습적으로 Python 은 args 를 인수 리스트를 표현하는 데 사용됩니다.
심벌릭 이름 args 는 Python 리스트로 인식되며, 인덱스로 항목을 검색하거나 for 루프 안에서 사용될 수 있습니다. 길이도 확인할 수 있습니다. 예제로 좀 더 구체적으로 살펴 보도록 하겠습니다.
def my_var_func(*args):
print(type(args))
print('The number of args is', len(args))
for item in args:
print(item)
my_var_func(10, 20, 30, 40)
실행 결과
<class 'tuple'>
The number of args is 4
10
20
30
40
이 예제에서 한 가지 이상한 점이 있습니다. *args 의 type 을 출력해 보니 <class 'tuple'> 이라고 출력됩니다. 여기서 우리는 한 가지 짚고 넘어가야 할 것이 있습니다. 바로 인수 리스트라고 하는 것은 실제로 Python 에서 사용하는 list 가 아니라 단순히 개념적으로써 ‘목록’ 이라는 영어 표현을 위해 리스트라는 표현을 사용하는 것이고 Python 내부에서는 tuple 형태로 함수에 제공하게 됩니다.
이제 조금 더 유용한 함수 예제를 살펴보도록 합시다. 원하는 개수의 숫자를 인수 리스트로 입력하여 입력한 모든 숫자의 평균값을 구하는 함수 예제입니다.
def avg(*args):
return sum(args)/len(args)
print(avg(11, 22, 33)) # 22.0
print(avg(1, 2)) # 1.5
이런 함수의 장점은 함수를 호출할 때 인수에 대괄호 기호를 사용하지 않아도 된다는 것입니다.
이번에는 ‘일반_인수’에 대해 이야기해 보도록 하겠습니다. *args 에 포함되지 않는 추가 인수는 반드시 *args 앞에 위치하거나 키워드 인수이어야 합니다.
앞서 살펴본 avg 예시를 다시 보도록 하겠습니다. 평균 산출 시 사용할 단위(units)를 별도의 인수로 추가한다고 가정해 보도록 하겠습니다. 단위를 나타내는 인수 units 는 키워드 인수가 아니기 때문에 반드시 *args 보다 앞에 위치해야 합니다.
def avg(units, *args):
print(sum(args)/len(args), units)
avg('inches', 11, 22, 33) # 22.0 inches
4.2 **kwargs 리스트
키워드 인수를 지원하는 조금 더 복잡한 문법은 함수 호출 시 인수에 이름을 지정하는 것입니다. 예를 들어 다음 코드에서 print 함수를 호출할 때 end 와 sep 인수에 이름을 지정했습니다.
print(10, 20, 30, end='.', sep=',') # 10,20,30.
**kwargs 리스트를 사용한 함수의 형태는 다음과 같습니다.
def 함수_이름([일반_인수,] *args, **kwargs):
dosomething
심벌릭 이름 args 와 마찬가지로 심벌릭 이름 kwargs 는 사실 어떤 이름을 사용해도 상관없지만, Python 에서는 관습상 kwargs 를 사용하고 있습니다.
함수 정의 안에서 kwargs 는 키-값 쌍으로 구성된 딕셔너리 형태의 인수를 의미합니다. 문자열 키는 인수의 이름이 되며, 값은 인수로 전달됩니다. 예제를 통해 구체적으로 확인해 보도록 하겠습니다.
def pr_named_vals(**kwargs):
print(type(kwargs))
for k in kwargs:
print(k, ':', kwargs[k])
pr_named_vals(a=10, b=20, c=30)
실행 결과
<class 'dict'>
a : 10
b : 20
c : 30
실행 결과 중 kwargs 의 type 을 확인해 보면 <class 'dict'> 로 출력되는 것을 확인할 수 있습니다. 그리고 위 함수는 kwargs 를 통해 인수로 넘겨받은 딕셔너리를 순회하면서 키와 값을 함께 출력하고 있습니다.
5. 데코레이터와 함수 프로파일러
Python 의 함수는 first-class 객체이기 때문에 데코레이터 함수(decorator functions)는 코드의 실행 속도를 측정하거나 다른 정보들을 제공할 수 있습니다.
여기서 말하는 데코레이터란 다른 함수(또는 클래스)를 인자로 받아, 그 객체를 대체할 새 객체를 반환하는 호출가능 객체(callable)입니다.
이 데코레이터가 중요한 이유는 데코레이터는 DRY, 일관성, 선언성, 확장성을 한꺼버너에 가져오는 파이썬의 핵심 기능입니다. 호출자 코드를 건드리지 않고 정책을 주입/교체/조합할 수 있다는 점이, 규모가 커질수록 가치가 기하급수적으로 커집니다.
(여기서 말하는 DRY 는 “Don’t Repeat Yourself 의 약자로 시스템 안의 하나의 지식/규칙은 단 한 곳에만 존재해야 한다는 원칙을 가리킵니다.”)
아래 그림은 Python 의 데코레이터를 설명한 그림입니다.
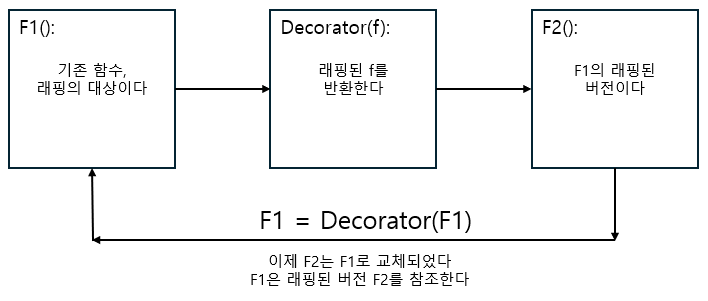
다음 예제에서 함수를 인수로 받아 time.time 함수 호출 코드를 추가하여 래핑하는 데코레이터 함수를 확인할 수 있습니다. time 은 패키지이므로 time.time 함수가 호출되기 전에 반드시 탑재되어야 한다는 것을 잊으면 안됩니다.
import time
def make_timer(func):
def wrapper():
t1 = time.time()
ret_val = func()
t2 = time.time()
print('소요 시간 : ', t2 - t1)
return ret_val
return wrapper
이 예시는 여러 함수를 포함하고 있으니 하나씩 살펴보도록 하겠습니다.
- 인수로 입력되는 함수, 이 함수를 기존 함수(F1)로 부르자. 이 함수에 우리가 원하는 문장을 추가(decorated)하고 싶다고 해보자.
- 래퍼 함수는 우리가 원하는 문장을 추가한 결과다. 이 코드는 기존 함수가 실행되면서 걸린 시간을 초 단위로 반환하는 문장을 추가했다.
- 데코레이터는 래퍼 함수를 생성하여 반환하는 작업을 수행한다. 이 데코레이터는 함수 내부에
def키워드로 신규 함수를 정의하기 때문에 이 작업이 가능해진다. - 결국 함수 이름을 재대입하면서 기존 버전이 래핑된 버전으로 교체된다.
이 데코레이터 함수를 보면 중요한 부분이 누락된 것을 볼 수 있습니다. 바로 기존 함수 func 의 인수가 보이지 않습니다. func 함수에 인수가 있다면 래퍼 함수는 함수 func 를 제대로 호출할 수 없게 됩니다.
해결책은 앞 절에서 소개한 *args 와 **kwargs 기능을 포함하는 것입니다. 완전한 데코레이터 예제를 보도록 하겠습니다.
def make_timer(func):
def wrapper(*args, **kwargs):
t1 = time.time()
ret_val = func(*args, **kwargs)
t2 = time.time()
print('소요 시간 : ', t2 - t1)
return ret_val
return wrapper
여기서 신규 함수가 래퍼인 것을 기억해야합니다. 임시로 wrapper 로 명명한 래퍼 함수는 결국 func 대신 호출될 것입니다. 이 래퍼 함수는 어떤 숫자의 인수나 키워드 인수를 취할 수 있게 됩니다.
이제 데코레이터 make_timer 를 정의하고 나면 어떤 함수라도 make_timer 로 래핑된 버전을 만들 수 있습니다. 그렇게 되면 함수 이름을 재대입하여 함수의 래핑된 버전을 참조하게 됩니다.
def count_nums(n):
for i in range(n):
for j in range(1000):
pass
count_nums = make_timer(count_nums)
래퍼 함수는 make_timer 에 의해서 다음과 같은 코드를 생산합니다.
def wrapper(*args, **kwargs):
t1 = time.time()
ret_val = func(*args, **kwargs)
t2 = time.time()
print('소요 시간 : ', t2 - t1)
return ret_val
이제 (래핑된 버전의 함수를 참조하고 있는) count_nums 를 실행하면 다음과 같이 실행 시간이 출력될 것입니다.
import time
def make_timer(func):
def wrapper(*args, **kwargs):
t1 = time.time()
ret_val = func(*args, **kwargs)
t2 = time.time()
print('소요 시간 : ', t2 - t1)
return ret_val
return wrapper
def count_nums(n):
for i in range(n):
for j in range(1000):
pass
count_nums = make_timer(count_nums)
count_nums(33000)
실행 결과
소요 시간 : 0.7183389663696289
기존 버전의 count_nums 는 숫자를 세는 것 이외의 작업은 하지 않지만, 래핑된 버전은 기존 버전의 count_nums 를 호출하여 수행되는 시간을 보고합니다.
마지막 단계로 Python 은 함수 이름을 재대입하는 것을 자동화하기 위해 작지만 편리한 문법을 제공합니다.
@데코레이터
def 함수(인수):
dosomething
위 문법은 다음과 같이 인식 됩니다.
def 함수(인수):
dosomething
func = 데코레이터(함수)
두 경우 모두 데코레이터는 이미 정의된 함수로 가정합니다. 데코레이터는 반드시 함수를 인수로 받아야 하며, 래핑된 버전의 함수를 반환해야 합니다. 이 규칙을 제대로 지켰다고 가정해 보고, 다음 예제에서 @ 기호를 활용한 완전한 예시를 살펴보도록 하겠습니다.
import time
def make_timer(func):
def wrapper(*args, **kwargs):
t1 = time.time()
ret_val = func(*args, **kwargs)
t2 = time.time()
print('소요 시간 : ', t2 - t1)
return ret_val
return wrapper
@make_timer
def count_nums(n):
for i in range(n):
for j in range(1000):
pass
count_nums(33000)
실행 결과
소요 시간 : 0.7140281200408936
@ 기호를 사용한 데코레이터를 사용하면 이전 코드에서와 같이 굳이 count_nums 함수에 데코레이터를 래핑할 필요 없이 바로 래핑되어 실행 시간을 출력하는 부분도 함께 추가됩니다.
6. 제너레이터
제너레이터는 시퀀스(sequence)를 다룰 때 한 번에 한 항목씨 처리할 수 있게 해주는 방법을 제공합니다.
여러분이 시퀀스를 한꺼번에 메모리에 적재하여 오랜 시간 동안 데이터를 처리한다고 가정해 보겠습니다. 가령 피보나치 수열을 10에서 50까지 확인하고 싶다면 전체 데이터를 계산하기 위해 많은 시간과 메모리 공간이 필요할 것입니다. 무한으로 반복되는 시퀀스의 짝수만 처리하는 것도 마찬가지입니다.
제너레이터의 장점은 한 번에 시퀀스의 한 항목만 다룰 수 있게 해준다는 것입니다. 마치 실제로는 존재하지 않는 가상 시퀀스를 만드는 것과 비슷합니다. 즉 핵심만 요약하자면
- 메모리, 시간 효율성 증가(지연평가 + 조기 종료)
- 필요한 순간에 값 하나씩 생성하니 대용량/무한 시퀀스도 안전하게 처리합니다.
any/next/break가 곧바로 계산 중단으로 이어져 불필요한 작업을 피합니다.
- 간단한 상태 유지로 맞춤 이터러블 제공
- 반환값을 리스트가 아닌 제너레이터로 설계하면 호출자가 메모리 흐름을 더 잘 통제합니다.
- 스트리밍 파이프라인 구성(조합 가능성 증가)
- “생성->변환->필터->집계”를 중간 자료구조 없이 단계별로 잇기 쉽습니다.
- 파일/네트워크 I/O와 자연스럽게 맞물려, 처리량이 커질수록 효과가 큽니다.
6.1 이터레이터란?
Python 의 중심 개념 중에 이터레이터(iterator) 가 있습니다. 이터레이터는 한 번에 하나씩 값을 생산하여 결국 나열된 값의 묶음(stream) 을 제공하는 객체입니다.
모든 리스트는 이터레이터이지만, 모든 이터레이터가 리스트인 것은 아닙니다. reserved 와 같은 많은 함수가 리스트가 아닌 이터레이터를 생산합니다. 이 이터레이터는 바로 접근하거나 출력할 수 없습니다. 예시를 보도록 하겠습니다.
iter1 = reversed([1, 2, 3, 4])
print(iter1) # <list_reverseiterator object at 0x7efc5e9679a0>
하지만 이터레이터를 리스트로 변환하여 출력하고 인덱스로 값에 접근하거나 슬라이스 할 수 있습니다.
iter1 = reversed([1, 2, 3, 4])
print(list(iter1)) # [4, 3, 2, 1]
이터레이터는 상태 정보를 가지고 있습니다. 시퀀스의 끝에 도달하면 종료됩니다. iter1 을 재설정 하지 않고 다시 사용하려고 해도 어떤 값도 반환하지 않습니다.
6.2 제너레이터
제너레이터는 이터레이터를 만드는 가장 쉬운 방법입니다. 하지만 제너레이터 함수 그 자체가 이터레이터는 아닙니다. 제너레이터의 기본 생성 절차를 살펴보도록 하겠습니다.
- 제너레이터 함수를 생성한다. 정의문제
yield문장을 사용하면 어디에서나 제너레이터를 만들 수 있다. - 1단계에서 만든 ㅎ마수를 호출하여 이터레이터 객체를 확보한다.
- 2단계에서 생성한 이터레이터는
next함수가 반환한yield값이다. 이 객체는 상태 정보를 지니고 있으며, 필요하면 재설정 할 수 있다.
그러면 제너레이터를 예제로 한 번 살펴보도록 하겠습니다. 우선 2에서 10까지 짝수만 출력하는 함수를 작성해보도록 하겠습니다.
def print_evens():
for n in range(2, 11, 2):
print(n)
이제 print(n) 을 yield n으로 변경해보도록 하겠습니다. 그러면 함수 본연의 동작 방식이 바뀌게 됩니다. 함수 이름도 make_evens_gen 으로 변경하여 조금 더 명확하게 함수를 표현하도록 하겠습니다.
def make_evens_gen():
for n in range(2, 11, 2):
yield n
이제 이 함수는 어떤 값도 반환하지 않습니다. 대신 값 n 을 산출하고, 실행을 보류하고, 내부 상태를 저장합니다. 하지만 변경된 함수 make_evens_gen은 반환값을 가지고 있습니다. 반환값은 n 이 아니라 제너레이터 객체라고 불리는 이터레이터 객체입니다. make_evens_gen을 호출하면 반환값이 다음과 같이 출력됩니다.
def make_evens_gen():
for n in range(2, 11, 2):
yield n
make_evens_gen() # <generator object make_evens_gen at 0x7c36800a3850>
이제 우리는 이터레이터 객체(혹은 제너레이터 객체)를 변수에 저장하여 next 에 넘겨줄 수 있습니다.
def make_evens_gen():
for n in range(2, 11, 2):
yield n
my_gen = make_evens_gen()
next(my_gen) # 2
next(my_gen) # 4
next(my_gen) # 6
시퀀스의 끝에 도달하면 StopIteration 예외가 발생합니다. 만약 시퀀스의 처음으로 되돌아가고 싶다면 어떻게 해야 할까요? 바로 make_evens_gen을 다시 호출한 후 신규 이터레이션 인스턴스를 생산하면 됩니다. 그렇게 되면 처음부터 다시 시작하게 됩니다.
def make_evens_gen():
for n in range(2, 11, 2):
yield n
my_gen = make_evens_gen()
next(my_gen) # 2
next(my_gen) # 4
next(my_gen) # 6
my_gen = make_evens_gen() # 다시 시작
next(my_gen) # 2
next(my_gen) # 4
next(my_gen) # 6
만약 make_evnes_gen을 매번 호출하면 매번 신규 제너레이터 객체가 생성되기 때문에 항상 처음부터 다시 시작하게 됩니다. 그렇기 때문에 제너레이터를 사용할 때는 주의 해야 합니다.
def make_evens_gen():
for n in range(2, 11, 2):
yield n
next(make_evens_gen()) # 2
next(make_evens_gen()) # 2
next(make_evens_gen()) # 2
제너레이터는 for문에서 사용할 수 있으며, 빈번하게 사용됩니다. 다음과 같이 for문을 이용해 make_evens_gen을 호출할 수 있습니다.
for i in make_evens_gen:
print(i, end=' ')
실행 결과
2 4 6 8 10
제너레이터 함수가 반환하는 객체라 이터레이터라고 불리는 제너레이터 객체라는 것을 이해하고 있으면 문법적으로 이터러블 혹은 이터레이터를 넣을 수 있는 곳 어디든 호출할 수 있게 됩니다. 가령 제너레이터 객체를 다음과 같이 리스트로 변환할 수도 있습니다.
def make_evens_gen():
for n in range(2, 11, 2):
yield n
my_gen = make_evens_gen()
a_list = list(my_gen)
print(a_list) # [2, 4, 6, 8, 10]
물론 함수 호출과 리스트 변환을 동시에 할 수도 있습니다. 리스트는 (제너레이터 객체와는 다르게) 그 자체만으로도 안정적이며, 값을 반환합니다.
def make_evens_gen():
for n in range(2, 11, 2):
yield n
a_list = list(make_evens_gen())
print(a_list) # [2, 4, 6, 8, 10]
이터레이터의 가장 실용적인 사용 방법은 in과 not in 키워드와 함께 사용하는 것입니다. 예를 들어 다음과 같이 n 이하(작거나 같은)의 피보나치 수열을 생성하는 이터레이터를 만들어보도록 하겠습니다.
def make_fibo_gen(n):
a, b = 1, 1
while a<= n:
yield a
a, b = a+b, a
yield 문은 기본 함수를 제너레이터 함수로 변경하기 때문에 제너레이터 객체를 반환합니다. 이제 다음과 같이 입력한 숫자가 피보나이칭ㄴ지 아닌지 테스트할 수 있습니다.
def make_fibo_gen(n):
a, b = 1, 1
while a<= n:
yield a
a, b = a+b, a
n = int(input('Enter number:'))
if n in make_fibo_gen(n):
print('number is a Fibonacci.')
else:
print('number is not a Fibonacci. ')
이 예시는 생산된 이터레이터가 문제를 일으킬 수도 있는 무한 시퀀스를 산출하지 않기 때문에 제대로 동작합니다. 대신 이터레이터는 n 이 피보나치 숫자가 아니면 스스로 종료됩니다.
마치며
이번엔 Python 프로그래밍을 하면서 좀 더 유능한 프로그래머가 될 수 있는 여러가지 기능들에 대해 알게 되었습니다. 오늘 정리한 내용들을 토대로 추후에 좀 더 파이써닉한 코드들을 더 쉽게 이해할 수 있을 것 같고, 유능한 프로그래머로 한 발 더 나아간 것 같습니다. 긴 글 읽어주셔서 감사드리며, 내용 중에 잘못된 내용이나 오타, 궁금하신게 있으시다면 댓글 달아주시기 바랍니다.
Comments