
[ToyProject] 블로그에 RAG를 적용한 AI 검색 기능 만들기 1. 블로그에 간단한 RAG를 적용한 AI 검색기 만들기
머리말
최근 대학원생 때 했던 딥러닝 공부를 다시 시작하면서 LLM과 RAG에 대한 공부를 하는 와중에 여러 기업에 지원을 해보았습니다. 서류 통과 후 이어진 면접에서 공통적으로 받은 피드백은 ‘개념 이해와 단순 구현 경험은 충분하나, 실제 데이터를 활용해 실서비스 수준으로 구축해 본 경험이 부족하다’는 점이었습니다. 이론과 실무 사이의 간극을 메우기 위해, 단순한 학습을 넘어 실제 운영 중인 환경에 RAG를 직접 적용해 보기로 결심했습니다. 그래서 LLM과 RAG를 이용해 간단하게라도 실서비스 환경에서 구현을 해보자고 생각을 하게 되었고, 자체적인 LLM 학습이나 운영은 개인 차원에서 비용 부담이 크기 때문에, 비용 효율적이면서도 외부 지식을 유연하게 활용할 수 있는 RAG(Retrieval-Augmented Generation) 시스템을 실서비스 환경에 구현하기로 결정했습니다. 그리고 RAG를 현재 나의 상황에서 어떻게 하면 실서비스 환경과 가장 유사한 환경에서 구현할 수 있을까 생각을 하다보니 제가 운영하고 있는 블로그에 RAG를 이용한 검색 기능을 구현해 보는 것이 실서비스 환경에서의 RAG 구현과 가장 비슷하다고 생각하였습니다. 기존 블로그들의 검색 기능은 대부분 단순 키워드 매칭(Lexical Search) 방식입니다. 이로 인해 사용자의 의도를 정확히 파악하지 못하거나, 유사한 맥락의 콘텐츠를 찾아주지 못하는 한계가 있었습니다. 저는 이를 개선하기 위해 의미론적 탐색이 가능한 RAG 기반 검색 기능을 도입하고자 합니다 그래서 저는 RAG를 이용한 검색 기능을 제공하여 단순히 문자열 매칭이 아닌 질문에 대해서 블로그 내용을 위주로 답변을 해주고, 질문과 연관이 있는 다른 포스트를 추천해주는 검색 기능을 구현하기로 하였습니다. 그리고 이렇게 제 블로그에 RAG를 직접 구현하면서 실무에서 겪는 성능 문제나 프롬프트 엔지니어링 그리고 AI Agent와 관련된 문제를 경험해볼 수 있는 좋은 기회라고 생각해 이러한 토이 프로젝트를 기획하고 진행하였습니다.
이번 포스트에서는 단순한 RAG 시스템을 구현하여 블로그 포스트 내용에 기반한 답변을 제공해 주는 AI 검색기를 만들어 보는 내용입니다. 이번 포스트에서 진행하는 프로젝트의 구성은 블로그 포스트들의 전처리(청킹, 임베딩), 벡터 DB 구축과 전처리된 데이터를 벡터 DB에 적재하기, 백엔드 서버를 이용해 쿼리를 임베딩화하고, 벡터 DB에서 쿼리가 가장 유사한 문서를 가져와 OpenAI의 gpt-4o-mini 모델에게 쿼리와 함께 쿼리와 가장 유사한 문서를 함께 보내 답변을 받아오기, 마지막으로 github 블로그의 github 저장소에 포스트가 추가, 삭제, 수정될 때마다 벡터 DB에서 추가, 삭제, 수정이 되도록하는 자동화 과정까지입니다. 전체 시스템 아키텍처는 아래 이미지와 같습니다.
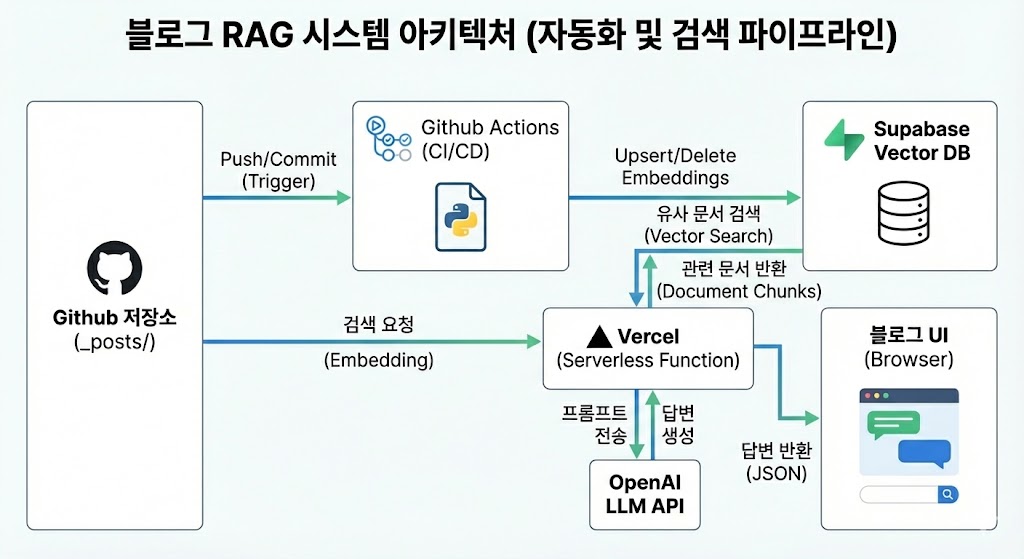
1. 데이터(블로그 포스트) 전처리
저는 우선 첫 번째 과정으로 데이터 전처리를 진행하기로 하였습니다. 초기에는 벡터 DB에 아무런 데이터가 없기 때문에 현재까지 작성된 포스트들을 이용해 한 번에 적재하는 과정이 필요합니다. 또한 이 과정에서 만들어진 전처리 코드는 이후 자동화 과정에서도 사용이 되므로 미리 구현해 놓는 것이 좋겠다는 생각이 들었습니다. 이번에는 아주 간단한 RAG 시스템을 직접 구현해보는 것이 목적이기 때문에 복잡한 전처리는 진행하지 않았습니다. LangChain의 text splitters의 RecursiveCharacterTextSplitter를 이용해 청킹을 진행하고, LangChain Core의 Document 객체에 전처리한 정보를 담기로 하였습니다. 그리고 각 청킹된 문서의 metadata로는 포스트의 제목인 title, 제가 정한 포스트의 분류인 category, 제가 정한 포스트의 태그인 tag, 마지막으로 해당 포스트로 접근할 수 있는 url을 metadata로 사용하기로 하였습니다. url은 현재 제가 사용하고 있는 github 블로그의 테마인 minimal-mistakes 기준 “자신의 블로그 주소/카테고리/날짜 정보와 확장자를 제외한 포스트의 파일이름”으로 구성됩니다. 또한 카테고리 정보가 2개 이상일 경우에는 categories 항목에 추가한 순서대로 카테고리 정보가 적용됩니다. 그리고 카테고리 정보는 모두 소문자로 변경되어 적용됩니다. 예시로 좀 더 자세히 보도록 하겠습니다.
- 깃허브 주소 : https://example.github.io
- 카테고리 정보
- 첫 번째 카테고리 : Algorithm
- 두 번째 카테고리 : Python
- 파일 이름 : 2025-12-30-sort_algorithm.md
위 예시일 경우에는 url이 https://example.github.io/algorithm/python/sort-algorithm/으로 만들어집니다. 따라서 이를 위해 저는 카테고리 정보와, 정규표현식을 이용해 파일 이름에서 날짜 정보를 제거하도록 하였습니다.
실습에 들어가기에 앞서 실행에 필요한 라이브러리 설치부터 진행해 줍니다. 먼저 저의 환경을 알려드리면 저는 PyCharm을 이용해 가상환경을 구축해 그 가상환경에 필요한 라이브러리들을 설치해 진행했습니다.
pip install langchain langchain-openai unstructured python-frontmatter supabase
그럼 이러한 작업을 진행하는 코드에 대해서 알아보도록 하겠습니다. 코드는 다음과 같습니다.
import os
import frontmatter
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
import re
def load_and_chunk_posts(posts_dir):
documents = []
# 1. 파일 순회 (운영체제 독립적 경로 처리)
for root, dirs, files in os.walk(posts_dir):
for filename in files:
if filename.endswith(".md"):
file_path = os.path.join(root, filename)
with open(file_path, 'r', encoding='utf-8') as f:
post = frontmatter.load(f)
# 카테고리 경로 생성 (예: llm/rag/)
categories = post.get("categories", [])
dir_name = "".join([f"{c.lower()}/" for c in categories])
# 파일명에서 날짜 제거 (2025-12-30-title.md -> title.md)
url_name = re.sub(r"^\d{4}-\d{2}-\d{2}-", "", filename)
slug = url_name.replace('.md', '')
# 최종 메타데이터 구성
metadata = {
"title": post.get("title", "Untitled"),
"category": categories,
"tag": post.get("tags", []),
"url": f"https://icechickentender.github.io/{dir_name}{slug}/"
}
# 2. Chunking 설정
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=150,
separators=["\n\n", "\n", " ", ""]
)
chunks = text_splitter.split_text(post.content)
# 3. Document 객체 생성
for chunk in chunks:
documents.append(Document(page_content=chunk, metadata=metadata))
print(f"✅ 총 {len(documents)}개의 청크가 생성되었습니다.")
return documents
다음과 같은 실행 코드를 추가한 뒤 실행해 보도록 하겠습니다.
posts_path = r"C:\Users\ssclu\Desktop\github_blog\_posts"
all_chunks = load_and_chunk_posts(posts_path)
print(f"총 {len(all_chunks)}개의 청크가 생성되었습니다.\n")
print(all_chunks[0].page_content)
print(all_chunks[0].metadata)
아래와 같이 청킹된 문서와 그 문서의 metadata가 제대로 만들어진 것을 확인할 수 있습니다.
Output:
총 1550개의 청크가 생성되었습니다.
총 1550개의 청크가 생성되었습니다.
이제부터 제대로된 알고리즘 공부를 시작해 보고자 합니다. 그래서 첫 번째로 공부할 알고리즘은 탐욕(Greedy) 알고리즘에 대해서 공부를 해보도록 하겠습니다.
# 탐욕(Greedy) 알고리즘이란?
탐욕(Greedy, 앞으로는 그리디라는 용어로 사용하도록 하겠습니다) 알고리즘이란 이름에서 알 수 있듯이 어떠한 문제가 있을 때 단순 무식하게, 탐욕적으로 문제를 푸는 알고리즘 입니다. 탐욕적이라는 의미는 `현재 상화에서 지금 당장 좋은 것만 고르는 방법`을 의미합니다. 그리디 알고리즘을 이용하면 매 순간 가장 좋아 보이는 것을 선택하며, 현재의 선택이 나중에 미칠 영향에 대해서는 고려하지 않습니다.
코딩 테스트에서 만나게될 그리디 알고리즘의 문제 유형은 앞으로 다루게 될 알고리즘과 비교했을 때 `사전에 외우고 있지 않아도 풀 수 있을 가능성이 높은 문제 유형`이라는 특징이 있습니다. 그리디 알고리즘 유형의 문제는 매우 다양하기 때문에 다른 암기해야 하는 알고리즘들과는 다르게 암기한다고 해서 항상 잘 풀 수 있는 알고리즘 유형이 아닙니다. 그리디 알고리즘은 사전 지식이 없어도 풀 수는 있지만 많은 유형을 접해보고 문제를 풀어보며 훈련을 해야 합니다.
보통 코딩 테스트에서 출제되는 그리디 알고리즘 유형의 문제는 창의력, 즉 문제를 풀기 위한 최소한의 아이디어를 떠올릴 수 있는 능력을 요구합니다. 다시 말해 특정한 문제를 만났을 때 단순히 현재 상황에서 가장 좋아 보이는 것만을 선택해도 문제를 풀 수 있는지 파악할 수 있어야 합니다. 그래서 이번 그리디 알고리즘의 경우에는 여러 문제를 다뤄보면서 그리디 알고리즘 문제는 어떻게 다루어야 하는지 알아보도록 하겠습니다.
## 큰 수의 법칙 문제
{'title': '[Algorithm][Python] 탐욕(Greedy) 알고리즘', 'category': ['Algorithm', 'Python'], 'tag': ['Algorithm', 'Python'], 'url': 'https://icechickentender.github.io/algorithm/python/1-greedy-algorithm-post/'}
2. 벡터 DB 구축과 데이터 적재
2.1 벡터 DB 구축
현재 제가 사용하고 있는 PC는 거의 10년이 다 되어 가고 있어 벡터 DB를 운용할 수 있을 정도로 성능이 나오지 않는다고 판단하였습니다. 그래서 벡터 DB를 사용할 수 있는 여러 플랫폼을 찾아보다가 Supabase라고 현재 제 상황에서 무료로 벡터 DB를 사용할 수 있는 플랫폼을 알게 되었습니다. 그래서 제 github 아이디를 연동했고, 새로운 프로젝트를 만들어 제가 사용할 벡터 DB 환경을 구축하였습니다. 새로운 프로젝트를 만들고 첫 화면인 “Project Overview” 화면에서 아래로 내리면 자신의 프로젝트에 연동할 수 있는 url과 api key가 있습니다. 나중에 이 정보를 사용해야 되니 위치를 잘 기억해 두시길 바랍니다.
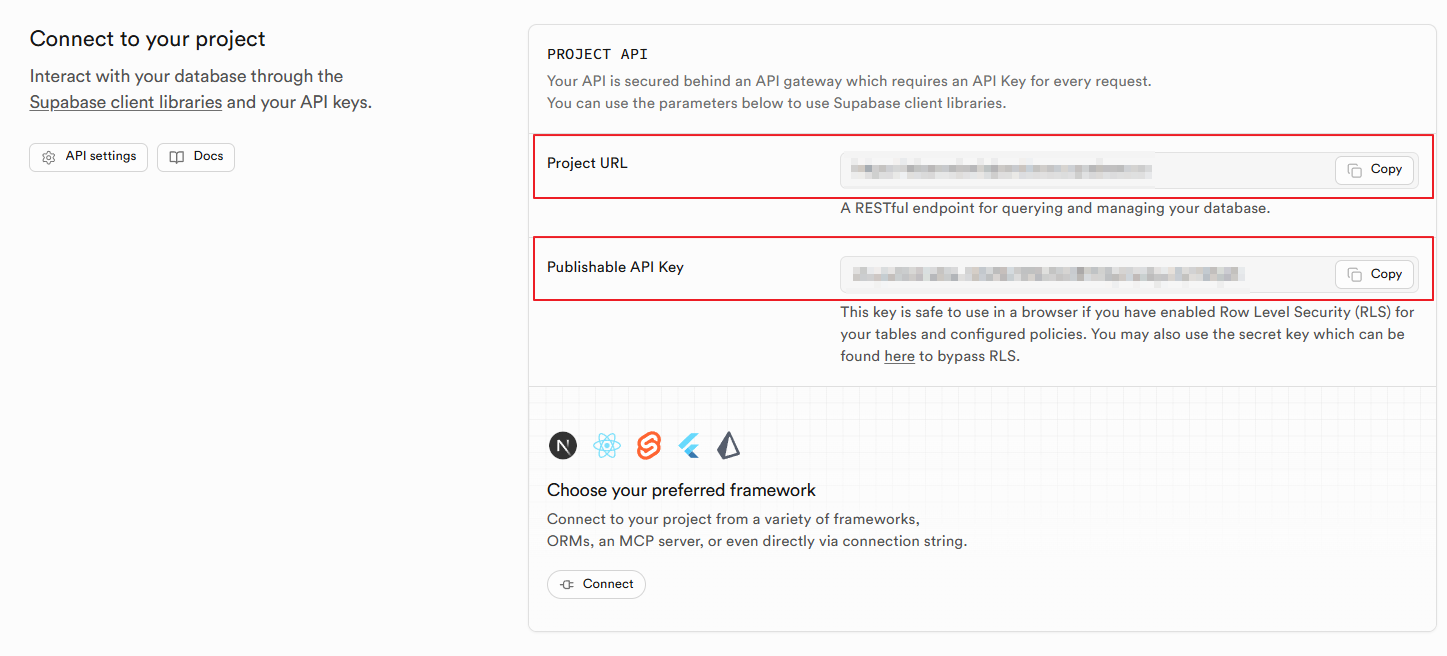
이제 데이터 적재에 사용할 테이블 생성과 supabase의 여러 설정을 진행하도록 하겠습니다. supabase 프로젝트의 왼쪽 사이드 메뉴에서 SQL Editor로 들어갑니다. 여기서는 SQL 구문으로 DB에서와 같이 테이블을 생성하거나 데이터 작업을 진행할 수 있습니다. 우선 SQL Editor에서 New Query를 생성한 뒤 vector 확장 기능을 활성화시키고 임베딩 데이터와 메타데이터를 저장할 테이블을 생성하고, 빠른 검색을 위한 인덱스를 생성하도록 하겠습니다.
-- 1. vector 확장 기능 활성화
create extension if not exists vector;
-- 2. 임베딩 데이터와 메타데이터를 저장할 테이블 생성
create table documents (
id uuid primary key default gen_random_uuid(),
content text,
metadata jsonb,
embedding vector(1536)
);
-- 3. 빠른 검색을 위한 인덱스 생성
create index on documents using ivfflat (embedding vector_cosine_ops)
with (lists = 100);
그리고 나중에 웹에서 “검색” 요청을 보낼 때, DB 내부에서 유사도 계산을 수행할 수 있도록 SQL Editor 다음 쿼리도 실행해 주시기 바랍니다.
create or replace function match_documents (
query_embedding vector(1536),
match_threshold float,
match_count int
)
returns table (
id uuid, -- 이 부분을 uuid로 수정
content text,
metadata jsonb,
similarity float
)
language sql stable
as $$
select
documents.id,
documents.content,
documents.metadata,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where 1 - (documents.embedding <=> query_embedding) > match_threshold
order by similarity desc
limit match_count;
$$;
이로써 우리가 사용할 벡터 DB의 구축은 끝났습니다. 그럼 이제 데이터를 DB에 적재하는 방법에 대해서 알아보도록 하겠습니다.
2.2 데이터 적재
초기에 기존에 있던 모든 데이터들을 DB에 적재를 해주어야 합니다. 이 작업은 데이터 전처리를 포함하여 데이터 전처리를 하고 전처리된 데이터를 OpenAI의 text-embedding-3-small 모델을 이용해 임베딩화하고, 이 정보들을 우리가 구축한 supabase의 DB에 적재해보도록 하겠습니다. 이러한 과정을 진행하는 코드는 다음과 같습니다.
from chunk_post import load_and_chunk_posts
from supabase import create_client
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import SupabaseVectorStore
# 1. 설정 정보(Supabase 대시보드 -> Settings -> API에서 확인 가능)
SUPABASE_URL = "자신의 supabase 프로젝트에 있는 url"
SUPABASE_KEY = "자신의 supabase 프로젝트에 있는 api key"
OPENAI_API_KEY = "자신의 openai api key"
# 2. Supabase 클라이언트 및 임베딩 모델 초기화
supabase = create_client(SUPABASE_URL, SUPABASE_KEY)
embeddings = OpenAIEmbeddings(
model = "text-embedding-3-small",
openai_api_key = OPENAI_API_KEY
)
posts_path = r"C:\Users\ssclu\Desktop\github_blog\_posts"
chunks = load_and_chunk_posts(posts_path)
# 3. 데이터를 Supabase에 적재
vector_store = SupabaseVectorStore.from_documents(
chunks,
embeddings,
client=supabase,
table_name="documents",
query_name="match_documents"
)
print("성공적으로 모든 임베딩이 업로드되었습니다!")
위 코드를 실행하면 다음과 같이 supabase 프로젝트의 Table Editor에 보시면 아래 이미지와 같이 데이터가 정상적으로 적재된 것을 확인할 수 있습니다.
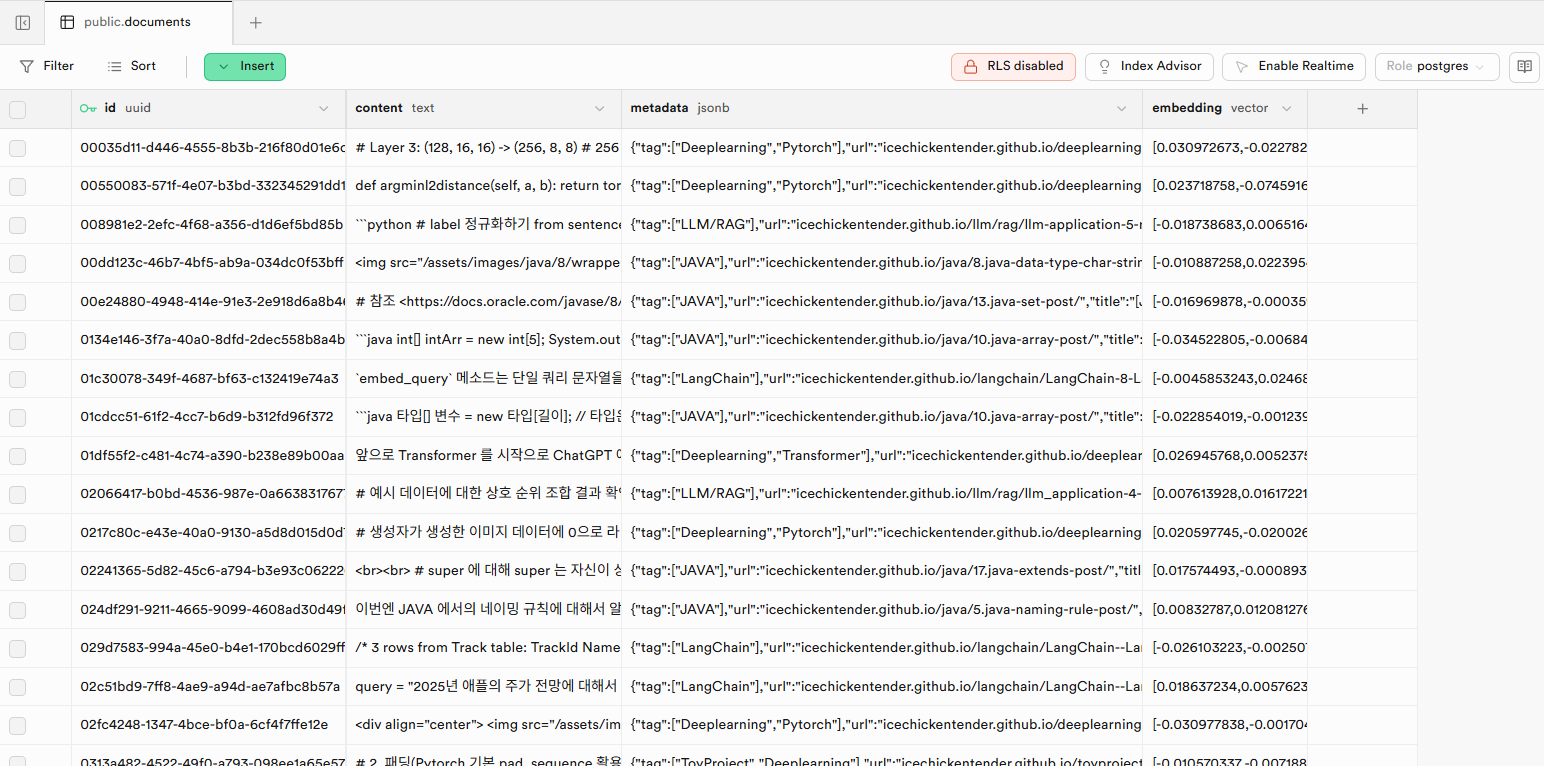
혹시 모르니 적재된 벡터 DB와 연동해 query와 연관성이 높은 문서를 가져오도록 하는 테스트 코드를 만들고 실행해 보도록 하겠습니다.
from supabase import create_client
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import SupabaseVectorStore
# 1. 설정 정보(Supabase 대시보드 -> Settings -> API에서 확인 가능)
SUPABASE_URL = "자신의 supabase 프로젝트에 있는 url"
SUPABASE_KEY = "자신의 supabase 프로젝트에 있는 api key"
OPENAI_API_KEY = "자신의 openai api key"
# 2. 초기화
supabase = create_client(SUPABASE_URL, SUPABASE_KEY)
embeddings = OpenAIEmbeddings(
model = "text-embedding-3-small",
openai_api_key = OPENAI_API_KEY
)
# 3. 직접 검색 수행
query = "딥러닝 모델에서의 QLoRA란 무엇인가?"
# 쿼리를 벡터로 변환
query_vector = embeddings.embed_query(query)
# Supabase RPC(match_documents 함수) 호출
response = supabase.rpc(
"match_documents",
{
"query_embedding": query_vector,
"match_threshold": 0.5,
"match_count": 3
}
).execute()
vector_store = SupabaseVectorStore(
client=supabase,
embedding=embeddings,
table_name="documents",
query_name="match_documents"
)
# 4. 결과 출력
print(f"\n[질문]: {query}")
print("-"*50)
for i, row in enumerate(response.data):
print(f"[{i+1}번째 결과] (유사도: {row['similarity']:.4f})")
# metadata 필드에서 제목 추출
title = row['metadata'].get('title', '제목 없음')
print(f"출처: {title}")
print(f"내용: {row['content'][:150]}...")
print("-" * 50)
코드 실행 결과로 아래와 같은 결과를 얻었습니다. 제 블로그에는 LoRA와 QLoRA에 대한 내용이 있는 포스트가 있으며, 쿼리인 “딥러닝 모델에서의 QLoRA란 무엇인가?” 와 관련성이 높은 3개의 문서가 출력되는 것을 확인할 수 있습니다.
Output:
[질문]: 딥러닝 모델에서의 QLoRA란 무엇인가?
--------------------------------------------------
[1번째 결과] (유사도: 0.6463)
출처: [LLM/RAG] 효율적으로 GPU를 사용하기 위한 기술
내용: # 4. 효율적인 학습 방법(PEFT): QLoRA
2023년 5월 워싱턴대학교의; 팀 데트머스(Tim Dettmers)와 알티도로 팩노니(Artidoro Pagnoni)가 발표한 QLoRA(QLORA: Efficient Finetuning of Quantized L...
--------------------------------------------------
[2번째 결과] (유사도: 0.6075)
출처: [LLM/RAG] 효율적으로 GPU를 사용하기 위한 기술
내용: ## 4.3 코드로 QLoRA 모델 활용하기
이제 허깅페이스 코드를 통해 QLoRA 학습을 진행하는 방법을 알아보도록 하겠습니다. 아래 예제와 같이 허깅페이스와 통합돼 있는 bitsandbytes 라이브러리를 활용하면 모델을 불러올 때 4비트 양자화를 간단히 수행할 ...
--------------------------------------------------
[3번째 결과] (유사도: 0.5765)
출처: [LLM/RAG] 효율적으로 GPU를 사용하기 위한 기술
내용: model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
```
마지막으로 QLoRA 모델을 불러오는 부분도 추가하면 아래 예제와 같습니다. 예제에서는 4비트 양...
3 Vercel을 이용한 RAG 시스템 구현
우리는 데이터 전처리와 벡터 DB를 구축해 RAG 시스템에 사용될 블로그 포스트 문서들을 임베딩화하여 Supabase 벡터 DB에 적재까지 하였습니다. 그럼 이제 질문을 받고 그 질문과 가장 유사한 문서를 벡터 DB로부터 찾고, 질문과 문서를 함께 LLM 모델에 전달하여 LLM으로부터 답변을 받아오는 시스템을 만들기만 하면 됩니다. 하지만 그 전에 이 시스템이 동작할 서버부터 마련해야 합니다. 이 시스템은 단순히 Supabase와 OpenAI로의 통신만 하면 되기 때문에 큰 리소스를 먹지 않습니다. 그래서 제 PC를 이용해 볼까 했지만 제 PC가 꺼지게 되면 질문에 대한 응답을 해줄 수가 없게 되니 실무에서와 같이 상용 중인 서비스라고 볼 수 없게 됩니다. 그렇기 때문에 무료로 이러한 기능을 사용할 수 있는 플랫폼을 찾아보았습니다. 이런 기능을 제공하는 플랫폼 중에 Vercel이라고 무료로 서버리스 기능을 제공하는 플랫폼을 찾았습니다. 하지만 실제로 시스템이 동작하도록 하기 위해선 Vercel에서의 환경을 구축해야 합니다. 그렇다면 Vercel의 환경을 구축하고, 구축된 환경을 통해 제가 계획한 시스템이 잘 동작하는지 확인해 보도록 하겠습니다.
우선 Vercel의 경우 자신의 github 저장소와 연동이 가능합니다. 그래서 저는 Vercel의 환경에서 실행될 코드를 제 github 저장소를 통해 관리하고자 합니다. 그래서 제 github에 새로운 저장소를 만들어 주고 코드 실행에 필요한 라이브러리 정보를 모아둔 “requirements.txt” 파일과 Vercel의 설정 파일인 vercel.json 그리고 실제로 실행될 코드 파일인 index.py 를 api 폴더 아래에 두도록 하였습니다. 각 파일의 구성은 다음과 같습니다.
requirements.txt 파일입니다.
fastapi
uvicorn
supabase
openai
langchain-openai
langchain-community
vercel.json 파일입니다.
{
"rewrites": [
{"source": "/api/(.*)", "destination": "/api/index.py"}
]
}
index.py 파일입니다.
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from supabase import create_client
import openai
from langchain_openai import OpenAIEmbeddings
import os
app = FastAPI()
origins = [
"http://localhost:4000",
"http://127.0.0.1:4000",
"https://icechickentender.github.io",
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 환경 변수는 나중에 Vercel 대시보드에서 설정
SUPABASE_URL = os.environ.get("SUPABASE_URL")
SUPABASE_KEY = os.environ.get("SUPABASE_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
supabase = create_client(SUPABASE_URL, SUPABASE_KEY)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small", openai_api_key=OPENAI_API_KEY)
client = openai.OpenAI(api_key=OPENAI_API_KEY)
class QueryRequest(BaseModel):
query: str
@app.post("/api/chat")
async def chat(request: QueryRequest):
query = request.query
# 1. 검색
query_vector = embeddings.embed_query(query)
response = supabase.rpc("match_documents", {
"query_embedding": query_vector,
"match_threshold": 0.5,
"match_count": 3
}).execute()
context = "\n".join([row['content'] for row in response.data])
# 2. 답변 생성
messages = [
{"role": "system", "content": "블로그 내용을 바탕으로 답변하고 출처를 명시해줘."},
{"role": "user", "content": f"Context: {context}\n\nQuestion: {query}"}
]
completion = client.chat.completions.create(model="gpt-4o-mini", messages=messages)
return {"answer": completion.choices[0].message.content}
위 파일들을 새로 생성한 github 저장소에 push를 해주고 Vercel 사이트에 가서 github 아이디로 회원가입을 한 뒤 Add New -> Project 클릭 후 방금 만든 Github 저장소를 Import 해줍니다.
그러면 배포 화면이 뜨는데 화면 아래쪽의 Environment Variables 섹션에서 우리가 사용할 OPENAI_API_KEY, SUPABASE_URL, SUPABASE_KEY를 각각 이름과 값에 맞춰 등록해 줍니다. 이는 보안을 위한 것으로 코드 상에 API KEY 값을 넣은채 배포를 하게 된다면 누군가 여러분들의 API KEY를 이용해 비용이 발생하는 것을 방지하기 위함입니다.
그리고 이제 Deploy 버튼을 눌러 배포를 진행해 줍니다. 배포가 정상적으로 완료가 된다면 아래 이미지와 같은 화면이 뜹니다.
4. 블로그 검색 기능 UI 구현
이제 백엔드 엔진이 준비 되었습니다. 이제 블로그에 이 엔진을 호출할 검색 버튼과 대화창을 달기만 합니다. 저는 이런 디자인과 관련된 프론트엔드쪽으로는 지식이 없어 가장 무난하다고 볼 수 있는 플로팅 비서(Floating AI Assistant) 화면을 사용하고자 하였으며, 위치는 우측 하단에 위치하도록 하였습니다. 그리고 Gemini를 이용한 바이브 코딩(vibe coding)으로 기능 구현을 진행하였습니다.
4.1 ai-widget.css
ai-widget.css는 채팅창의 시각적 레이아웃과 사용자 경험(UX)를 정의하기 위해 만들었습니다. ai-widget.css에 정의한 내용들은 다음과 같습니다.
- 화면 고정(Fixed positioning):
#ai-widget-container에position: fixed를 적용하여 사용자가 블로그 글을 아래로 길게 읽더라도 채팅 버튼이 항상 우측 하단에 머물게 합니다. - 말풍선 가이드(
#ai-welcome-bubble): 사용자가 이 기능이 무엇인지 바로 인지할 수 있도록 유도합니다.animation: bounce를 추가해 시각적으로 주의를 끌어 참여율을 높이는 심리적 장치를 두었습니다. - 버튼 펄스 효과(
.pulse-effect): 버튼 뒤에서 은은하게 퍼지는 애니메이션은 시스템이 ‘살아있다’는 느낌을 주어 인터랙티브한 분위기를 조성합니다. - 다크 모드 테마:
#ai-chat-window의 배경색(#1e1e1e)과 테두리 설정을 통해 기술 블로그에 어울리는 현대적이고 눈이 편안한 개발자 도구 느낌의 디자인을 완성했습니다. - 로딩 애니메이션(
.dot-flashing): LLM이 답변을 생성하는 동안(RAG 검색 및 생성 시간) 사용자가 지루함을 느끼지 않도록 ‘생각 중’이라는 시각적 피드백을 실시간으로 제공합니다.
코드는 다음과 같습니다.
/* AI 비서 전체 컨테이너 (항상 우측 하단 고정) */
#ai-widget-container {
position: fixed; /* 화면에 고정 */
bottom: 30px; /* 하단에서 30px 띄움 */
right: 30px; /* 우측에서 30px 띄움 */
z-index: 9999; /* 가장 위에 오도록 */
font-family: var(--main-font-family, sans-serif); /* 블로그 폰트 상속 */
}
/* 채팅창 (기본은 숨김 상태) */
#ai-chat-window {
display: none; /* 초기엔 안 보이게 */
width: 450px; /* 너비 450px (요청하신 와이드 크기) */
height: 600px; /* 높이 600px */
background: #1e1e1e; /* 다크 모드 배경색 */
border: 1px solid #444;
border-radius: 15px;
box-shadow: 0 10px 30px rgba(0,0,0,0.5); /* 그림자 효과 */
flex-direction: column;
overflow: hidden;
margin-bottom: 15px;
}
/* 쿼카 아이콘 버튼 (우측 하단에 둥글게) */
#ai-widget-button {
width: 70px; /* 버튼 크기 */
height: 70px;
background: #333; /* 버튼 배경색 */
border-radius: 50%; /* 동그랗게 */
cursor: pointer;
display: flex;
align-items: center;
justify-content: center;
transition: transform 0.3s, box-shadow 0.3s;
float: right;
border: 2px solid #555; /* 테두리 추가 */
}
#ai-widget-button:hover {
transform: scale(1.1); /* 마우스 올리면 살짝 커짐 */
box-shadow: 0 0 15px rgba(255,255,255,0.2);
}
4.2 ai-widget.js(Interactive Logic)
채팅창의 두뇌 역할을 하며, Vercel 백엔드 API와의 통신을 담당합니다. ai-widget.js에 정의한 내용들은 다음과 같습니다.
- 상태 제어(Toggle): 버튼 클릭 시 채팅창을 열고 닫는 논리적 흐름을 관리합니다. 특히 창이 열릴 때 자동으로 입력창에 포커스(
input.focus())가 가도록 하여 바로 질문할 수 있는 편의성을 제공합니다. - 비동기 통신(Async/Fetch):
fetchAPI를 통해 Vercel에 구축된 파이썬 API로 사용자의 질문을 보냅니다.async/await를 사용하여 브라우저가 멈추지 않고 배경에서 답변을 기다리도록 구현되었습니다. - 지능형 엔터키 제어:
onkeydown이벤트를 통해 단순 엔터는 ‘전송’,Shift + Enter는 ‘줄바꿈`이 되도록 하여 기술 블로그 사용자들이 긴 문장이나 코드를 입력하기 최적화된 환경을 만들었습니다. - 동적 DOM 조작: API로부터 답변이 오면 실시간으로 새로운 메시지 박스를 생성하여 화면에 추가하고, 항상 최신 메시지가 보이도록 자동으로 스크롤을 맨 아래로 내리는(
msgBox.scrollTop=msgBox.scrollHeight) 기능을 수행합니다.
코드는 다음과 같습니다.
const chatButton = document.getElementById('ai-widget-button');
const chatWindow = document.getElementById('ai-chat-window');
const chatClose = document.getElementById('ai-chat-close');
const chatInput = document.getElementById('ai-chat-input');
const chatMessages = document.getElementById('ai-chat-messages');
// 버튼 클릭 시 채팅창 토글
chatButton.onclick = () => {
chatWindow.style.display = chatWindow.style.display === 'none' ? 'flex' : 'none';
};
// 닫기 버튼 클릭 시 숨김
chatClose.onclick = () => {
chatWindow.style.display = 'none';
};
// ... (나머지 엔터키 전송 로직은 기존과 동일) ...
4.3 default.html (Structure & Multi-line Input)
default.html 파일은 minimal-mistakes 테마에서 뼈대가 되는 HTML이 있는 파일로 우리는 이 파일에 우리가 구현한 ai-widget.js, ai-widget.css 파일에 정의된 내용을 이용해 실제로 화면상에 뿌려주는 코드를 이 파일에 적용할 예정입니다. default.html 파일에 적용된 내용은 다음과 같습니다.
- 메시지 컨테이너 분리: 사용자(user)와 AI(
ai)의 메시지를 클래스로 구분하여, 나중에 스타일을 각각 다르게 적용하거나 위치를 좌우로 정렬할 수 있는 유연한 구조를 잡았습니다. - Textarea 도입(Soft-wrap): 일반적인
<input>태크 대신<textarea>를 사용하여 사용자가 긴 코드나 복잡한 NLP 관련 질문을 입력할 때 자동으로 줄바꿈(Soft-wrap)이 일어나도록 했습니다. - 스크롤 자동화:
#ai-chat-messages에overflow-y: auto를 설정하여 대화 내용이 길어지면 내부에서 스크롤이 발생하도록 했고, 커스텀 스크롤바 디자인으로 깔끔함을 유지했습니다.
<style>
#ai-widget-container {
position: fixed !important;
bottom: 30px !important;
right: 30px !important;
z-index: 99999 !important;
display: flex !important;
flex-direction: column !important;
align-items: flex-end !important;
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, sans-serif !important;
}
/* 말풍선 가이드 */
#ai-welcome-bubble {
background: #007bff !important;
color: white !important;
padding: 10px 15px !important;
border-radius: 12px !important;
margin-bottom: 12px !important;
font-size: 14px !important;
font-weight: 500 !important;
box-shadow: 0 4px 15px rgba(0,0,0,0.3) !important;
position: relative !important;
animation: bounce 2s infinite;
display: block;
}
#ai-welcome-bubble::after {
content: '';
position: absolute;
bottom: -8px;
right: 25px;
border-left: 8px solid transparent;
border-right: 8px solid transparent;
border-top: 8px solid #007bff;
}
@keyframes bounce {
0%, 20%, 50%, 80%, 100% {transform: translateY(0);}
40% {transform: translateY(-5px);}
60% {transform: translateY(-3px);}
}
/* 버튼 펄스 효과 */
.pulse-effect {
position: absolute;
width: 100%;
height: 100%;
border-radius: 50%;
background: rgba(0, 123, 255, 0.4);
animation: pulse 2s infinite;
z-index: -1;
}
@keyframes pulse {
0% { transform: scale(1); opacity: 0.8; }
100% { transform: scale(1.5); opacity: 0; }
}
#ai-chat-window {
display: none;
width: 450px;
max-width: 90vw;
height: 600px;
background: #1e1e1e !important;
border: 1px solid #444 !important;
border-radius: 15px !important;
box-shadow: 0 10px 30px rgba(0,0,0,0.5) !important;
flex-direction: column !important;
overflow: hidden !important;
margin-bottom: 15px !important;
}
#ai-widget-button {
width: 65px !important;
height: 65px !important;
background: #333 !important;
border-radius: 50% !important;
cursor: pointer !important;
display: flex !important;
align-items: center !important;
justify-content: center !important;
position: relative !important;
border: 2px solid #555 !important;
}
/* 메시지 박스 스크롤바 디자인 */
#ai-chat-messages::-webkit-scrollbar { width: 6px; }
#ai-chat-messages::-webkit-scrollbar-thumb { background: #444; border-radius: 10px; }
/* 입력창 (Textarea) 스타일 */
#ai-chat-input {
width: 100% !important;
background: #333 !important;
color: white !important;
border: 1px solid #555 !important;
padding: 12px !important;
border-radius: 8px !important;
outline: none !important;
resize: none !important;
font-family: inherit !important;
font-size: 14px !important;
line-height: 1.5 !important;
white-space: pre-wrap !important;
word-wrap: break-word !important;
}
/* --- 메시지 정렬 및 말풍선 스타일 수정 --- */
.chat-msg-container {
margin-bottom: 15px;
width: 100%;
display: block;
}
/* AI 메시지는 왼쪽 정렬 */
.chat-msg-container.ai { text-align: left; }
/* 사용자 메시지는 오른쪽 정렬 */
.chat-msg-container.user { text-align: right; }
.msg-label {
font-size: 11px;
color: #888;
margin-bottom: 4px;
display: block;
}
.ai .msg-label { margin-left: 4px; }
.user .msg-label { margin-right: 4px; }
.bubble {
display: inline-block;
padding: 10px 14px;
border-radius: 12px;
max-width: 85%;
font-size: 14px;
line-height: 1.6;
white-space: pre-wrap;
word-wrap: break-word;
text-align: left; /* 말풍선 내부 텍스트는 왼쪽 정렬 유지 */
}
.user-bubble {
background: #007bff;
color: white;
border-bottom-right-radius: 2px; /* 오른쪽 하단 뾰족한 효과 */
}
.ai-bubble {
background: #333;
color: #eee;
border: 1px solid #444;
border-bottom-left-radius: 2px; /* 왼쪽 하단 뾰족한 효과 */
}
/* 로딩 애니메이션 (기존과 동일) */
.dot-flashing {
position: relative;
display: inline-block;
width: 7px;
height: 7px;
border-radius: 5px;
background-color: #007bff;
animation: dot-flashing 1s infinite linear alternate;
animation-delay: 0.5s;
margin: 0 15px;
}
.dot-flashing::before, .dot-flashing::after {
content: "";
display: inline-block;
position: absolute;
top: 0;
width: 7px;
height: 7px;
border-radius: 5px;
background-color: #007bff;
animation: dot-flashing 1s infinite linear alternate;
}
.dot-flashing::before { left: -12px; animation-delay: 0s; }
.dot-flashing::after { left: 12px; animation-delay: 1s; }
@keyframes dot-flashing {
0% { background-color: #007bff; }
50%, 100% { background-color: rgba(0, 123, 255, 0.2); }
}
</style>
<div id="ai-widget-container">
<div id="ai-welcome-bubble">
블로그 지식 검색, AI에게 물어보세요! 🔍
</div>
<div id="ai-chat-window">
<div style="padding: 15px 20px; background: #252525; border-bottom: 1px solid #444; display: flex; justify-content: space-between; align-items: center;">
<span style="color: white; font-weight: bold;">쿼카 AI 지식 비서 (LLM)</span>
<span id="ai-chat-close" style="cursor: pointer; color: #888; font-size: 24px;">×</span>
</div>
<div id="ai-chat-messages" style="flex: 1; overflow-y: auto; padding: 20px; background: #1e1e1e;">
<div class="chat-msg-container ai">
<div class="msg-label">AI:</div>
<div class="ai-bubble">안녕하세요! 쿼카 AI입니다. 🦫<br>이 블로그에 작성된 포스트 내용을 바탕으로 답변해 드립니다.</div>
</div>
</div>
<div style="padding: 15px; background: #252525; border-top: 1px solid #444;">
<textarea id="ai-chat-input" rows="2" placeholder="질문을 입력하세요... (Enter로 전송)"></textarea>
<div style="font-size: 10px; color: #666; margin-top: 4px; text-align: right;">Shift + Enter로 줄바꿈</div>
</div>
</div>
<div id="ai-widget-button">
<div class="pulse-effect"></div>
<img src="/assets/images/profile_image.png" alt="AI" style="width: 45px; height: 45px; border-radius: 50%; object-fit: cover;">
</div>
</div>
<script>
(function() {
const btn = document.getElementById('ai-widget-button');
const win = document.getElementById('ai-chat-window');
const bubble = document.getElementById('ai-welcome-bubble');
const cls = document.getElementById('ai-chat-close');
const input = document.getElementById('ai-chat-input');
const msgBox = document.getElementById('ai-chat-messages');
btn.onclick = () => {
const isHidden = win.style.display === 'none' || win.style.display === '';
win.style.display = isHidden ? 'flex' : 'none';
if (bubble) bubble.style.display = 'none';
if (isHidden) input.focus();
};
cls.onclick = () => { win.style.display = 'none'; };
input.onkeydown = async (e) => {
if (e.key === 'Enter' && !e.shiftKey) {
e.preventDefault();
const query = input.value.trim();
if (query === '') return;
// [사용자 메시지 출력] .user 클래스 추가하여 오른쪽 정렬
msgBox.innerHTML += `
<div class="chat-msg-container user">
<div class="msg-label">나:</div>
<div class="bubble user-bubble">${query}</div>
</div>`;
input.value = '';
msgBox.scrollTop = msgBox.scrollHeight;
const loadingId = 'loading-' + Date.now();
msgBox.innerHTML += `
<div id="${loadingId}" class="chat-msg-container ai">
<div class="msg-label">AI:</div>
<div class="bubble ai-bubble">
<span class="dot-flashing"></span> 생각 중...
</div>
</div>`;
msgBox.scrollTop = msgBox.scrollHeight;
try {
const res = await fetch('https://toy-project-rag-in-blog.vercel.app/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query: query })
});
const data = await res.json();
const loadingElement = document.getElementById(loadingId);
if (loadingElement) loadingElement.remove();
msgBox.innerHTML += `
<div class="chat-msg-container ai">
<div class="msg-label">AI:</div>
<div class="bubble ai-bubble">${data.answer}</div>
</div>`;
} catch (err) {
const loadingElement = document.getElementById(loadingId);
if (loadingElement) {
loadingElement.innerHTML = `<div class="msg-label">AI:</div><div class="bubble ai-bubble" style="color: #ff6b6b;">통신 오류가 발생했습니다.</div>`;
}
}
msgBox.scrollTop = msgBox.scrollHeight;
}
};
})();
</script>
5. Github Actions를 이용한 자동화 구현
블로그에 구현한 검색 기능 UI를 이용해 Vercel에 구현한 백엔드 엔진이 정상적으로 동작해 RAG를 적용한 AI 정보 검색 기능을 구현을 완료하였습니다. 하지만 이제 마지막 단계가 남았습니다. 마지막 단계는 블로그에 새로운 포스트가 추가 되거나 삭제, 수정될 때에 이를 포착하여 정보 검색에 사용되는 문서 정보를 Supabase의 벡터 DB에 자동으로 업데이트 해주도록 하는 것입니다. 여태까지 진행한 상태에서 마무리 지으면 아마도 처음에 적재한 데이터를 기준으로만 대답을 해줄 것입니다. 그래서 포스트가 새로 추가됐음에도 불구하고 우리가 구현한 RAG 기반 AI 정보 검색기는 새로운 포스트 내용에 대한 답변을 해주지 못할 것입니다. 이러한 문제를 방지하기 위해 Github에서 제공하는 Actions 기능을 이용해 github 블로그의 저장소에서 push가 일어나면 자동으로 데이터를 전처리하고 임베딩해서 Supabase의 벡터 DB에 업데이트 하는 과정을 자동화하도록 할 예정입니다.
5.1 자동화에 사용될 실행 파일 구현
우선 Github Actions에서 사용할 추가, 수정, 삭제된 문서를 Supabase의 벡터 DB에 업데이트하는 코드를 먼저 작성해 보도록 하겠습니다. 이 코드는 자신의 github 블로그 저장소의 root 디렉토리의 scripts 라는 폴더를 새로 생성해 주시고 그 폴더 안에 넣어주어야 합니다. 저는 파일 이름으로 sync_to_supabase.py 라고 지었습니다. 이 코드는 추후에 다루겠지만 Github Actions에서 동작하는 yml로부터 push가 일어났을 때 파일 추가 및 수정이 일어났을 때는 push로 추가 및 수정된 파일들을 공백을 기준으로 added_modified 라는 매개변수의 값으로 넘겨줍니다. 삭제가 일어났을 경우에는 deleted 라는 매개변수의 값으로 넘겨줍니다. 넘겨 받은 값들 중에서 “.md”가 들어간 파일인 경우에는 우리가 이전에 진행했던 데이터 전처리와 Supabase의 벡터 DB에 값을 추가하거나 삭제합니다. Supabase의 벡터 DB의 데이터를 삭제하거나 수정하기 위해서 데이터를 검색하는 조건으로는 metadata에 있는 url을 사용합니다.
import os
import re
import argparse
import frontmatter
from supabase import create_client
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import SupabaseVectorStore
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
# 1. 환경 변수 및 설정
URL = os.environ.get("SUPABASE_URL")
KEY = os.environ.get("SUPABASE_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
# supabase 클라이언트 및 임베딩 모델 초기화
supabase = create_client(URL, KEY)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small", openai_api_key=OPENAI_API_KEY)
def generate_blog_url(filename, categories):
"""Minimal Mistakes 테마 규칙에 따른 URL 생성"""
# 카테고리 경로 생성 (예: llm/rag/)
dir_name = "".join([f"{c.lower()}/"for c in categories])
# 파일명에서 날짜 제거 (YYYY-MM-DD-)
url_name = re.sub(r"^\d{4}-\d{2}-\d{2}-", "", filename)
slug = url_name.replace('.md', '')
return f"https://icechickentender.github.io/{dir_name}{slug}/"
def process_sync(added_modified_files, deleted_files):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=150,
separators=["\n\n", "\n", " ", ""]
)
# 삭제된 파일 처리
for file_path in deleted_files:
if not file_path.endswith(".md"): continue
# 삭제 시에는 카테고리 정보를 알기 어렵기 때문에,
# 파일명 기반의 slug가 포함된 URL 패턴으로 DB에서 검색하여 삭제하는 것이 안전
filename = os.path.basename(file_path)
url_slug = re.sub(r"^\d{4}-\d{2}-\d{2}-", "", filename).replace('.md', '')
# 해당 slug가 포함된 모든 URL 데이터 삭제
supabase.table("documents").delete().filter("metadata->>url", "ilike", f"%{url_slug}%").execute()
print(f"데이터 삭제 완료(파일 제거됨): {file_path}")
all_docs = []
for file_path in added_modified_files:
if not file_path.endswith(".md") or not os.path.exists(file_path):
continue
with open(file_path, 'r', encoding='utf-8') as f:
post = frontmatter.load(f)
# 1. URL 생성
filename = os.path.basename(file_path)
categories = post.get("categories", [])
blog_url = generate_blog_url(filename, categories)
# 2. 중복 방지: 기존에 저장된 동일 URL 데이터 먼저 삭제 (Upsert 효과)
supabase.table("documents").delete().filter("metadata->>url", "eq", blog_url).execute()
# 3. 메타데이터 구성
metadata = {
"title": post.get("title", "Untitled"),
"category": categories,
"tag": post.get("tags", []),
"url": blog_url
}
# 4. 청킹 및 도큐먼트 객체 생성
chunks = text_splitter.split_text(post.content)
for chunk in chunks:
all_docs.append(Document(page_content=chunk, metadata=metadata))
print(f"갱신 준비 (추가/수정): {blog_url}")
if all_docs:
SupabaseVectorStore.from_documents(
all_docs,
embeddings,
client=supabase,
table_name="documents",
query_name="match_documents"
)
print(f"성공적으로 {len(all_docs)}개의 청크를 업데이트 했습니다.")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--added_modified", help="공백으로 구분된 추가/수정 파일 목록")
parser.add_argument("--deleted", help="공백으로 구분된 삭제된 파일 목록")
args = parser.parse_args()
am_files = args.added_modified.split() if args.added_modified else []
d_files = args.deleted.split() if args.deleted else []
process_sync(am_files, d_files)
그럼 이제 위 코드가 정상적으로 잘 동작하는지 한 번 테스트 해보도록 하겠습니다. 우선 테스트는 총 세 가지를 진행하고자 합니다. 첫 째 push로 새로운 파일이 추가되어 해당 파일이 added_modified 매개변수로 주어졌을 때 실제로 Supabase의 벡터 DB에 잘 추가가 되는지 두 번째 테스트를 위해 추가한 파일에 내용을 수정한 후에 코드를 돌렸을 때 Supabase의 벡터 DB의 데이터에도 반영이 되는지 마지막으로 push로 파일 삭제가 일어났을 경우 삭제한 파일의 내용도 Supabase의 벡터 DB에서 삭제가 되는지입니다. 테스트에 사용할 파일의 구성은 다음과 같습니다.
파일이름은 “2026-01-15-local-test.md”로 안의 내용은 대충 아무 내용이나 가져왔습니다.
---
title: "[Algorithm] 매개변수 탐색 알고리즘에 대해서 알아보자"
categories:
- Algorithm
tags:
- Algorithm
toc: true
toc_sticky: true
toc_label: ""
---
매개 변수 탐색(Parametric Search)
매개변수 탐색은 조건을 만족하는 최댓값을 구할 때 쓸 수 있는 탐색 방법이다.
매개변수 탐색은 이분 탐색을 통해 최종 답안에 가까워져 가는 방식으로 문제를 해결한다.
이분 탐색의 mid의 값이 바로 정답이 되지는 않지만, 정답이 될 수 있는지 없는지 여부는 판단할 수 있다.
이제 문제를 통해 알아보자.
백준의 대표적인 매개 변수 탐색 문제인 랜선 자르기 문제이다.
로컬에서 테스트하기 위해서 저는 PyCharm을 이용해 가상환경을 만들어 주었고, 다음 라이브러리들을 설치하여 진행했습니다.
pip install langchain langchain-openai langchain-community supabase python-frontmatter
그리고 코드 상에 보시면 설정 값들을 환경 변수로 가져오고 있기 때문에 저는 가상환경의 환경변수로 등록해 주는 방식으로 진행했습니다.
# Windows
$env:OPENAI_API_KEY="your_api_key_here"
$env:SUPABASE_URL="your_project_url_here"
$env:SUPABASE_KEY="your_service_role_key_here"
# Mac/Linux
export OPENAI_API_KEY="your_api_key_here"
export SUPABASE_URL="your_project_url_here"
export SUPABASE_KEY="your_service_role_key_here"
저는 윈도우 환경이기 때문에 윈도우 환경의 환경 변수 등록 방법을 사용했습니다. 그리고 저와 같이 윈도우 환경이신 경우 등록이 된 환경 변수를 확인 하고 싶으시다면 echo $env:OPENAI_API_KEY를 사용하면 자신이 등록한 환경 변수의 값을 확인하실 수 있으실 겁니다.
그럼 이제 파이썬 파일을 직접 실행시켜 추가한 포스트 파일의 내용이 Supabase의 벡터 DB에 적재되는지 확인해 보도록 하겠습니다. 실행은 다음과 같이 진행하면 됩니다.
python .\sync_to_supabase.py --added_modified "../_posts/Algorithm/2026-01-15-local-test.md"
그럼 출력으로 다음과 같은 출력이 터미널에 출력됩니다.
갱신 준비 (추가/수정): https://icechickentender.github.io/algorithm/local-test/
성공적으로 1개의 청크를 업데이트 했습니다.
그리고 Supabase에서 자신의 프로젝트의 SQL Editor로 가서 다음 쿼리를 실행해 봅니다. 이 쿼리는 metadata에 있는 url 정보 중에 local이 포함된 데이터가 있다면 조회하도록 하는 쿼리입니다.
SELECT * FROM documents
WHERE metadata->>'url' LIKE '%local%';
쿼리를 실행하면 SQL Editor 화면의 아래쪽에 아래 그림과 같이 결과가 출력되는 것을 확인할 수 있습니다. 이 결과를 보아 추가한 파일이 Supabase의 벡터 DB에 정상적으로 잘 적재되는 것을 확인할 수 있습니다.

그럼 이제 파일의 수정이 일어났을 경우 어떻게 되는지 한 번 보도록 하겠습니다. 파일의 수정이 일어난 경우는 파일의 내용이 변경된 것이므로 확실하게 확인하기 위해 테스트 파일의 내용을 완전 다른 내용으로 바꾼 다음에 파이썬 파일을 실행해 보도록 하겠습니다. 테스트 파일의 전체 내용을 다음과 같이 모두 변경하였습니다.
---
title: "[Algorithm] 동적계획법에 대해서 알아보자"
categories:
- Algorithm
tags:
- Algorithm
toc: true
toc_sticky: true
toc_label: ""
---
최적화 이론의 한 기술이며, 특정 범위까지의 값을 구하기 위해서 그것과 다른 범위까지의 값을 이용하여 효율적으로 값을 구하는 알고리즘 설계 기법이다.
다르게 표현하면, 사전 계산된(pre-computed) 값들을 재활용하는 방법이다. 앞에서 구했던 답을 뒤에서도 이용하고, 옆에서도 이용하고...엄밀히 말해 동적 계획법은 구체적인 알고리즘이라기보다는 문제해결 패러다임에 가깝다. 동적 계획법은 "어떤 문제를 풀기 위해 그 문제를 더 작은 문제의 연장선으로 생각하고, 과거에 구한 해를 활용하는" 방식의 알고리즘을 총칭한다.[1]
답을 구하기 위해서 했던 계산을 또 하고 또 하고 계속해야 하는 종류의 문제의 구조를 최적 부분 구조(Optimal Substructure)라고 부른다. 동적 계획법은 이런 문제에서 효과를 발휘한다.
동적 계획법을 영문으로는 다이나믹 프로그래밍(dynamic programming)이라 표기하는데, 이름과는 달리 딱히 다이나믹하지도 않고 프로그래밍이라는 단어와도 큰 연관이 없다.[2][3] 이에 대해 이광근 교수의 저서 "컴퓨터 과학이 여는 세계"에서는 다이나믹 프로그래밍을 본질적인 의미를 더 살려서 기억하며 풀기로 더욱 적절하게 번역하였다.
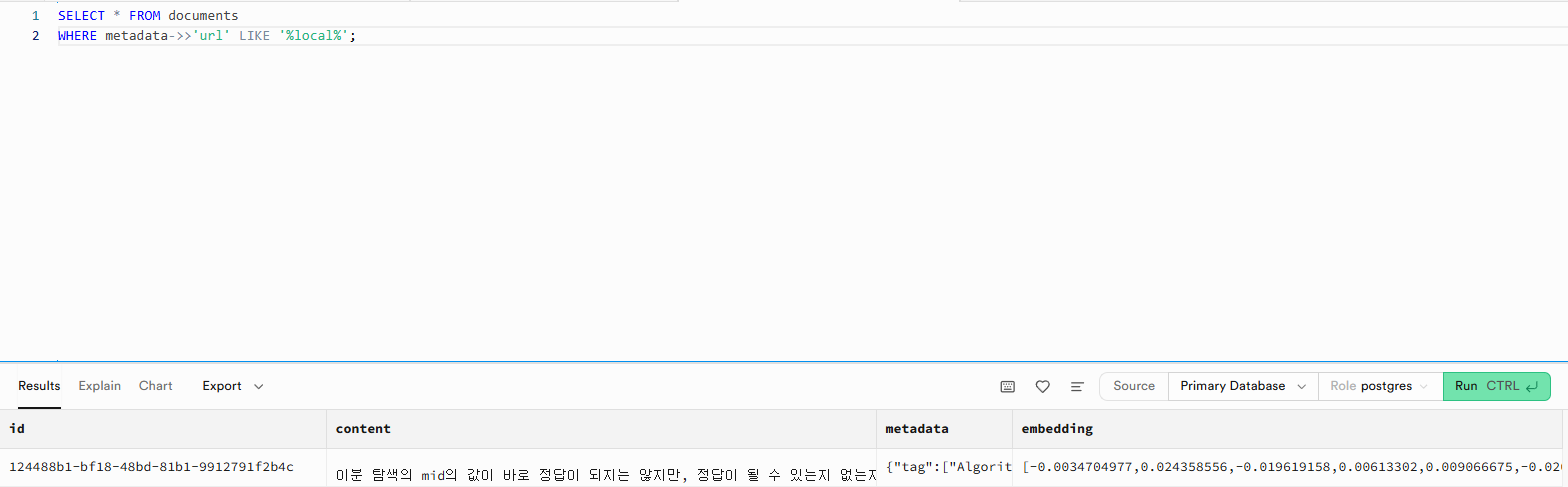
위 이미지를 보면 content 열에 매개변수라는 내용이 들어있는 것을 확인할 수 있습니다. 그렇다면 이전과 같이 파이썬 파일을 실행한 후 어떻게 되는지 확인해 보도록 하겠습니다.
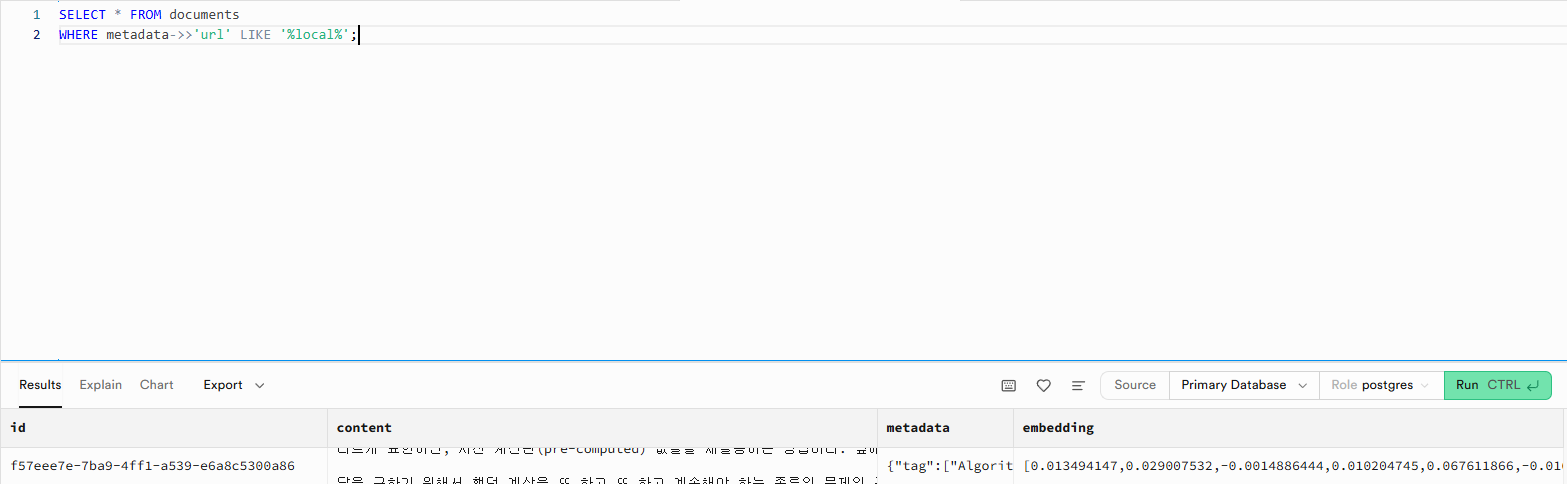
파이썬 파일을 실행한 후 SQL Editor에서 쿼리를 실행하면 아래 이미지에서와 같이 기존의 데이터가 바뀐 것을 확인할 수 있습니다.


그럼 이제 마지막으로 파일이 삭제되었을 경우에 대한 테스트를 진행해 보도록 하겠습니다. 파이썬 파일 실행 명령은 다음과 같습니다.
python .\sync_to_supabase.py --deleted "../_posts/Algorithm/2026-01-15-local-test.md"
실행 후 Supabase에서 SQL로 확인을 해보면 아래 이미지와 같이 결과가 조회되지 않는다고 나옵니다. 즉 로컬에서 삭제를 했을 시에 대한 테스트도 성공한 것으로 볼 수 있습니다.
5.2 자동화에 사용될 yml 파일 구현
yml 파일은 Github Actions에서 사용되는 파일로 저장소에 push가 일어날 때를 포착해 여러 작업을 수행하도록 할 수 있습니다. 제가 구현한 yml 파일에서는 push가 일어나 파일이 추가, 수정되었거나 삭제되었을 경우 이전에 구현해 놓은 sync_to_supabase.py를 실행하도록 합니다. yml 파일의 내용은 다음과 같습니다.
name: Update RAG Vector Store
on:
push:
paths:
# _posts 폴더 및 그 하위의 모든 폴더(**) 내의 .md 파일을 감시합니다.
- '_posts/**/*.md'
branches:
- main
- feature/retriever_with_rag
jobs:
update-vectors:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
with:
fetch-depth: 0
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: Install dependencies
run: |
pip install langchain langchain-openai langchain-community supabase python-frontmatter
# [수정된 부분] files 패턴을 재귀적 패턴(**)으로 변경합니다.
- name: Get changed files
id: changed-files
uses: tj-actions/changed-files@v41
with:
files: |
_posts/**/*.md
- name: Run Update Script
env:
OPENAI_API_KEY: $
SUPABASE_URL: $
SUPABASE_KEY: $
run: |
# 인자로 전달되는 파일 경로들이 이제 'category/post.md' 형태로 전달됩니다.
python scripts/sync_to_supabase.py \
--added_modified "$" \
--deleted "$"
그럼 이제 테스트를 위해 yml 파일과 sync_to_supabase.py 파일을 먼저 push 해줍니다. 그리고 저는 현재 테스트를 위해 main 브랜치가 아닌 다른 브랜치를 사용하고 있습니다. 저와 같이 다른 브랜치에서 작업하고 있고 테스트를 해야 한다면 yml 파일에 아래와 같이 추가해 주세요.
on:
push:
paths:
- '_posts/**'
branches:
- main
- feature/retriever_with_rag # 테스트를 위해 현재 브랜치 추가
이제 Github Actions에서 코드를 구동하도록 하기 위한 환경변수를 추가해 주어야 합니다. 자신의 github 저장소의 Settings->Secrets and variables의 Actions에 New repository secret을 이용해 환경 변수 값을 추가해 줍니다.
그럼 이제 테스트를 진행해 보도록 하겠습니다. 우선 이전에 sync_to_supabase.py 테스트를 위해 생성해두었던 md 파일을 이용해 테스트를 진행해 보겠습니다. 생성된 md 파일을 push해 보도록 하겠습니다. push 후에 github 사이트에서 자신의 저장소의 Actions를 가보면 아래 그림과 같이 push와 동시에 yml 파일로 인해 무엇인가가 동작하게 됩니다.

그리고 Supabase에 가서 벡터 DB에 해당 내용이 추가되었는지 확인을 해보면 아래 그림과 같이 추가된 것을 확인할 수 있습니다.
새로운 md 파일이 추가 되었을 때의 테스트를 진행했을 때 별 문제 없이 잘 동작하는 것을 확인하였습니다. 그렇다면 md 파일에 수정이 일어났을 경우에 대한 테스트를 진행해 보도록 하겠습니다. 이전 sync_to_supabase.py를 테스트할 때와 동일하게 테스트에 사용 중인 md 파일의 내용을 동적계획법 내용으로 바꾸어 보도록 하겠습니다. push를 하면 이전과 동일하게 Actions 항목에서 작업이 진행 중인 것을 확인할 수 있습니다.

Supabase에 가서 확인을 해보면 아래 이미지에서와 같이 content의 내용이 매개변수 탐색에서 동적계획법으로 바뀐 것을 확인할 수 있습니다.

이제 마지막으로 삭제 테스트를 진행해 보도록 하겠습니다. 테스트용 md 파일을 삭제한 이후 push를 하면 Actions에서 아래 이미지와 같은 이름으로 작업이 진행이 됩니다.

그리고 Supabase에서 확인을 해보면 정상적으로 삭제가 된 것을 확인할 수 있습니다.
6. master 브랜치에서의 테스트
이제 마지막으로 여태까지 구현한 기능들이 master 브랜치에 반영했을 때 실제로 잘 동작하는지 확인만 해보면 됩니다.
6.1 UI/UX 기능 테스트
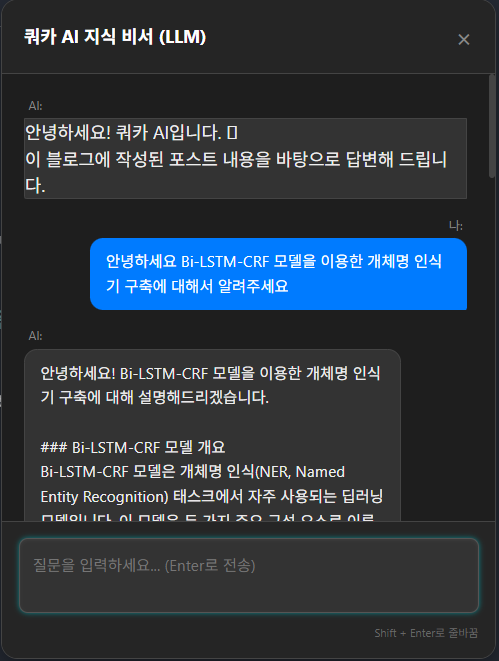
구현한 UI/UX 기능 테스트를 먼저 진행해 보겠습니다. 아래 이미지들을 보면 로컬 환경이 아닌 온라인으로 접속 가능한 블로그에 구현한 정보 검색 기능이 구현된 것을 확인할 수 있으며, 질문을 했을 때 답변을 해주는 것도 확인할 수 있습니다.

6.2 포스트 추가 테스트
그럼 이제 master 브랜치에 새로 작성한 포스트를 추가했을 때 실제로 Supabase의 벡터 DB에 관련 내용들이 자동으로 추가 되는지 테스트 해보도록 하겠습니다.
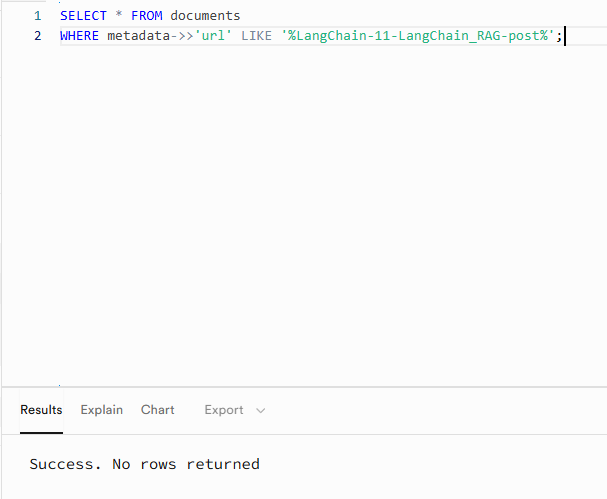
기존 작성 중이던 “11.LangChain을 이용한 RAG”라는 포스트를 업로드하여 우리가 구축한 것과 같이 자동으로 해당 포스트의 내용이 벡터 DB에 추가되는지 확인을 해보도록 하겠습니다. 먼저 포스트 파일 이름으로 벡터 DB에서 조회가 되는지 확인을 해보도록 하겠습니다.
아래 이미지와 같이 “LangChain-11-LangChain_RAG-post”로 조회를 해보면 아무런 결과가 없는 것을 확인할 수 있습니다. 그렇다면 작성된 “11.LangChain을 이용한 RAG” 포스트를 master 브랜치에 push 해보도록 하겠습니다.
포스트 push 후에 Github의 Actions에서 우리가 구축한 update-rag.yml에 의해 배포 시스템이 동작하는 것을 확인할 수 있었고

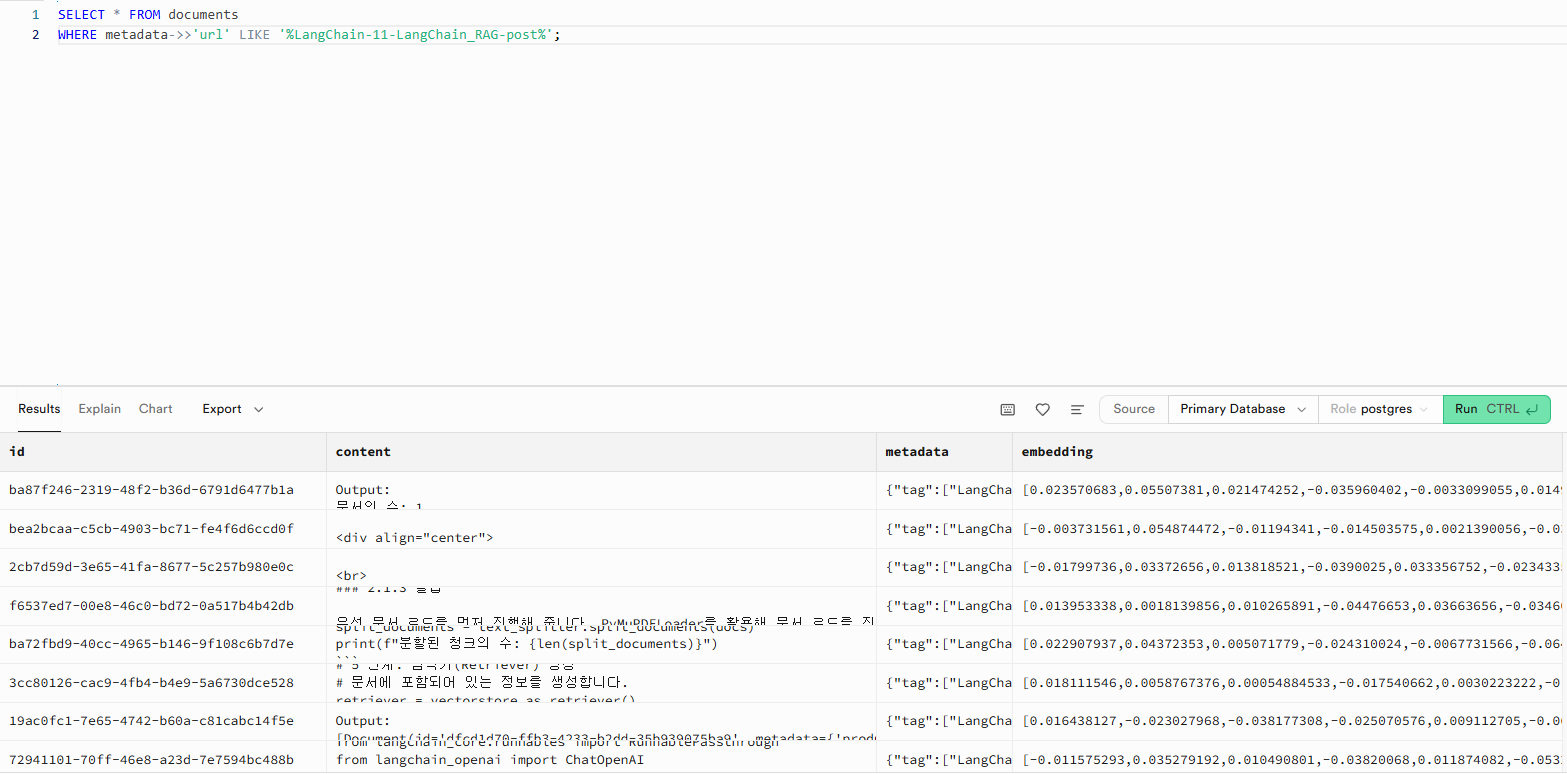
Supabase의 벡터 DB를 확인해 보면 아래 이미지와 같이 “LangChain-11-LangChain_RAG-post”로 조회를 했을 때 새로운 데이터들이 추가된 것을 확인할 수 있었습니다. 이를 통해 Github Actions를 이용한 포스트 데이터의 자동 전처리 및 임베딩화 그리고 벡터 DB에 적재되는 것까지 정상적으로 동작하는 것을 확인할 수 있었습니다.
마치며
블로그에 RAG 기반 AI 정보 검색기능 만들기의 첫 단계를 끝냈습니다. 이번에 RAG 시스템 구현을 위해 실무에서와 같이 프론트엔드와 백엔드도 서버 구축부터 백엔드 엔진 그리고 바이브 코딩이지만 프론트 엔드로 UI/UX도 직접 구현해보았습니다. 다만 이번 포스트에서는 RAG의 성능은 고려하지 않고 가장 단순한 RAG 시스템만 구현해 놓았기 때문에 백엔드 엔진에 있는 RAG 시스템의 성능은 매우 낮은 것을 확인할 수 있습니다. 실제로 제가 의도한 것과 달리 질문과 관련된 내용은 어느 정도 알려주지만 중간 중간 내용이 빠져있고, 특히나 질문과 관련된 포스트가 있음에도 불구하고 그 포스트의 url과 또 다른 관련 포스트의 url은 알려주지 않고 있습니다. 이후에는 RAG 시스템의 성능을 끌어올리기 위한 AI Agent와 LangChain의 LangGraph 그리고 RAG 시스템의 성능 평가 방법 등을 좀 더 공부하고 그 내용들을 바탕으로 블로그에 구현한 RAG 기반 정보 검색기의 성능을 좀 더 끌어올려보고, 또 원하는 대로 질문과 관련된 url과 또 다른 관련된 포스트를 url로 추천하도록 수정해 보도록 하겠습니다. 또한 ChatGPT나 Gemini와 같이 사용자 관점에서 읽기 편한 마크다운 형태로 정보를 제공하도록 하는 기능들도 알아보고 구현이 가능하면 구현하고 그 내용을 포스트로 작성해 보도록 하겠습니다.
긴 글 읽어주셔서 감사드리며, 본문 내용 중에 잘못된 내용이나 오타, 궁금하신 사항이 있으신 경우 댓글 달아주시기 바랍니다.
Comments