
[ToyProject] 블로그에 RAG를 적용한 AI 검색 기능 만들기 - 3. 비동기 스트리밍 적용 및 코드 리팩토링
1. 개요
이전 포스트에서는 구축해 놓은 RAG 시스템의 신뢰도를 높이기 위한 RAG 시스템의 성능 평가 방법과 성능을 끌어올리는 방법들에 대해서 알아보았습니다. 이번 포스트에서는 분산되어 있는 기능들을 하나의 클래스로 모으고, LangChain의 chain 시스템을 이용한 RAG 시스템의 리팩토링과 좀 더 사용자 친화적으로 다가가기 위한 비동기 스트리밍 방식 적용과 Chat-GPT나 Gemini와 같은 마크다운 형식으로 정보를 제공해주도록 수정한 내용들을 정리해서 기록하는 차원으로 이번 포스트를 작성하게 되었습니다.
2. 코드 리팩토링
현재 제 RAG 시스템의 코드는 구조화되어 있지 않고 각 기능별로 Python 파일에 함수로 기능이 구현되어 있습니다. 또한 각 기능들에서 사용되는 공통 파라미터들이 각 파일마다 하드코딩되어 있어 매번 직접 파라미터 값을 바꿔주어야 하는 등 초반에 빠른 개발을 위해 주먹 구구식 개발을 하였습니다. 그래서 이번 기회에 리팩토링을 하여 주제별 기능들을 클래스에 모아놓고, 공통으로 사용되는 파라미터들은 파일로 관리하도록 하며 메모리 효율을 위해 싱글톤 구조로 변경하고자 합니다.
2.1 공통 파라미터를 위한 config 파일 정의
코드 곳곳에 흩어져 있던 하드코딩된 경로와 수치들을 하나로 모으기 위해 config 파일을 정의합니다. 위치는 root 디렉토리에서 config 디렉토리에 config.yaml 파일로 정의하였습니다.
# config/config.yaml
project:
name: "Blog-RAG-System"
version: "1.0.0"
paths:
posts_dir: "C:/Users/ssclu/Desktop/icechickentender.github.io/_posts"
load_faiss_index_dir: "./faiss_recursive_chunk1000_overlap150"
delete_faiss_index_dir: "./faiss_index"
evaluate_data: "./data/blog_30_evaluate_data.json"
chunking:
size: 1000
overlap: 150
strategy: "recursive" # Options: recursive, markdown_hybrid
retrieval:
k: 3
weights:
sparse: 0.4
dense: 0.6
local_retrieval_mode: "dense" # "dense", "sparse", "hybrid" 세 가지 모드가 있음
mode: "supabase" # 모드는 supabase와 로컬 faiss를 사용하는 local이 있음
bm25_chunk_index_dir: "./index/bm25_chunk_index.pkl"
models:
embeddings: "text-embedding-3-small"
llm: "gpt-4o-mini"
supabase:
table_name: "documents"
query_name: "match_documents"
2.2 config 파일을 로드하는 ConfigLoader 클래스 정의
코드 실행에 필요한 파라매터들이 담겨있는 config.yaml 파일을 로드하도록 하는 클래스를 정의하였습니다. get_config 메서드로 로드된 정보를 가져오도록 하며 최초로 로드가 된다면 파일을 읽어 해당 클래스의 _config 변수에 config.yaml 파일을 읽도록 하여 해당 변수에 정보들이 담기도록 하고, 만약 프로그램이 실행 중일 때는 로드된 정보만 읽도록 하는 싱글톤 구조로 구성하였습니다. 추가로 API KEY 정보들이 있는 .env 파일도 읽어 API KEY 정보들도 읽어오도록 했으며, config.yaml 파일에 있는 경로들은 root 디렉토리와 결합하여 프로그램이 실행되는 위치에 상관없이 프로그램이 동작하도록 하는 _convert_paths 메서드도 구현하였습니다.
import os
import yaml
from pathlib import Path
from dotenv import load_dotenv
class ConfigLoader:
_config = None # 메모리에 저장될 설정 객체
_ROOT = Path(__file__).resolve().parent.parent.parent
@classmethod
def get_config(cls, file_name: str = "config.yaml"):
"""
설정을 반환합니다.
처음 호출될 때만 파일을 읽고(Lazy Loading), 이후에는 메모리 값을 반환합니다.
"""
if cls._config is None:
print(f"⚙️ 설정 파일을 로드합니다: {file_name}")
cls._config = cls._load_yaml(file_name)
load_dotenv(cls._ROOT / ".env") # .env도 여기서 한 번에 로드
return cls._config
@classmethod
def _load_yaml(cls, file_name: str):
path = cls._ROOT / "config" / file_name
if not path.exists():
raise FileNotFoundError(f"❌ 설정을 찾을 수 없습니다: {path}")
with open(path, 'r', encoding='utf-8') as f:
config = yaml.safe_load(f)
# 경로 자동 변환 (기존 로직 유지)
if 'paths' in config:
config = cls._convert_paths(config)
return config
@classmethod
def _convert_paths(cls, config):
for k, v in config['paths'].items():
if isinstance(v, str) and not os.path.isabs(v):
config['paths'][k] = str((cls._ROOT / v.replace("./", "")).resolve())
return config
2.3 청킹 전처리 클래스 정의
클래스 내부에서 메타 데이터를 추출하는 함수와 MarkdownHeaderTextSplitter를 이용한 청킹 작업을 진행할 때 각 청킹 문서에 추가해주는 카테고리 및 헤더 정보를 추출하는 함수를 정의하고, process 메서드를 통해 전처리 작업으로 볼 수 있는 청킹 작업을 진행할 수 있게 하였습니다.
import os
import re
import yaml
import frontmatter
from typing import List, Dict, Any
from langchain_text_splitters import RecursiveCharacterTextSplitter, MarkdownHeaderTextSplitter
from langchain_core.documents import Document
from src.core.config_loader import ConfigLoader
class BlogProcessor:
def __init__(self):
# 1. 설정 로드
self.config = ConfigLoader.get_config()
self.chunk_size = self.config['chunking']['size']
self.chunk_overlap = self.config['chunking']['overlap']
self.posts_dir = self.config['paths']['posts_dir']
def _extract_metadata(self, filename: str, post: Any) -> Dict[str, Any]:
"""파일명과 frontmatter에서 메타데이터를 정제합니다."""
categories = post.get("categories", [])
dir_name = "".join([f"{c.lower()}" for c in categories])
# 날짜 제거 (2025-12-30-title.md -> title)
slug = re.sub(r"^\d{4}-\d{2}-\d{2}-", "", filename).replace('.md', '')
return {
"title": post.get("title", "Untitled"),
"category": categories,
"tag": post.get("tags", []),
"url": f"https://icechickentender.github.io/{dir_name}{slug}/",
"filename": filename
}
def _create_breadcrumb(self, doc_metadata: Dict, base_categories: List[str]) -> str:
"""[Category > H1 > H2] 형태의 브레드크럼을 생성합니다."""
headers = [doc_metadata.get(f"Header {i}") for i in range(1, 4)]
path_list = base_categories + [h for h in headers if h]
return " > ".join(path_list)
def process(self) -> List[Document]:
"""전체 포스트를 로드하고 청킹하여 Document 리스트를 반환합니다."""
all_documents = []
# Splitter 초기화
recursive_splitter = RecursiveCharacterTextSplitter(
chunk_size=self.chunk_size,
chunk_overlap=self.chunk_overlap,
separators=["\n\n", "\n", " ", ""]
)
headers_to_split = [("#", "Header 1"), ("##", "Header 2"), ("###", "Header 3")]
md_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split, strip_headers=False)
for root, _, files in os.walk(self.posts_dir):
for filename in files:
if not filename.endswith(".md") or "sample" in filename:
continue
file_path = os.path.join(root, filename)
with open(file_path, 'r', encoding='utf-8') as f:
post = frontmatter.load(f)
base_metadata = self._extract_metadata(filename, post)
if self.config['chunking']['strategy'] == "markdown_hybrid":
# 전략에 따른 청킹(현재는 markdown_hybrid 중심)
md_header_splits = md_splitter.split_text(post.content)
final_chunks = recursive_splitter.split_documents(md_header_splits)
for doc in final_chunks:
# 브래드크럼 주입 및 메타데이터 업데이트
breadcrumb = self._create_breadcrumb(doc.metadata, base_metadata["category"])
doc.page_content = f"[{breadcrumb}]\n{doc.page_content}"
doc.metadata.update(base_metadata)
all_documents.append(doc)
elif self.config['chunking']['strategy'] == "recursive":
chunks = recursive_splitter.split_text(post.content)
for chunk in chunks:
all_documents.append(Document(page_content=chunk, metadata=base_metadata))
print(f"✅ 처리가 완료되었습니다. (총 청크 수: {len(all_documents)})")
return all_documents
2.4 문서 검색기 기능을 관리하는 RetrieverManager 클래스 정의
RetrieverManager는 Vercel 환경과 로컬 환경에서 사용되는 벡터 DB에서 제공해주는 검색기를 사용할 수 있도록 관리하는 클래스입니다. 기본적으로 Vercel 환경에서 동작하므로 현재 벡터가 저장되는 Supabase를 사용하는 것에 중점을 두고 구현하였습니다. 기존에는 Kiwi를 이용한 BM25Retriever를 정의할 때 Supabase로부터 모든 문서를 가져오도록 하여 BM25Retriever를 구성하도록 하였으나, 이럴 경우 데이터가 많아지면 속도가 느려지는 이슈가 발생할 것 같아 이전에 정의해둔 BM25Retriever를 index 파일로 저장하고 이를 로드하는 형식으로 변경하였습니다. 그러다 블로그 포스트 글이 추가되거나 수정되는 등의 업데이트가 발생하면 Vercel에서도 이에 맞춰 자동으로 index 파일을 갱신하게끔 하였으나 Vercel에서 제공하는 무료티어에서는 파일 쓰기 기능을 제한하고 있다는 것을 알게 되어 블로그 포스트 글이 업데이트 될 때에 수동으로 직접 index 파일을 업데이트 해주는 것에 타협하였습니다. 그래서 BM25Retriever는 무조건 index 파일에서 읽도록 하였으며, 추후에 Vercel이 아닌 로컬 pc를 서버처럼 활용할 수 있게 되면 그 때 다시 수정을 해서 블로그 포스트 업데이트에 따른 index 파일 자동 갱신 기능도 다시 추가하고자 합니다.
import os
import pickle
import tempfile
import asyncio
import traceback
from datetime import datetime, timezone
from supabase import create_client, Client
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_classic.retrievers import EnsembleRetriever
from src.core.KiwiBM25Retriever import KiwiBM25Retriever, kiwi_preprocessing_func
from src.core.utils import get_absolute_path
from src.core.config_loader import ConfigLoader
from typing import List, Any
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun, AsyncCallbackManagerForRetrieverRun
from langchain_core.documents import Document
from pydantic import Field
class RetrieverManager:
def __init__(self):
self.config = ConfigLoader.get_config()
self.embeddings = OpenAIEmbeddings(model=self.config['models']['embeddings'])
self.k = self.config['retrieval']['k']
self.weights = [
self.config['retrieval']['weights']['sparse'],
self.config['retrieval']['weights']['dense']
]
if self.config['retrieval']['mode'] == "supabase":
self.supabase: Client = create_client(
os.environ.get("SUPABASE_URL"),
os.environ.get("SUPABASE_KEY")
)
self.bm25_cache_path = get_absolute_path(self.config['retrieval']['bm25_chunk_index_dir'])
self.table_name = self.config['supabase']['table_name']
def _get_latest_update_from_supabase(self) -> datetime:
"""Supabase에서 가장 최근에 업데이트된 문서의 시각을 가져옵니다."""
# 가장 최신 데이터 1개만 가져와서 시각을 확인합니다.
response = self.supabase.table(self.table_name) \
.select("created_at") \
.order("created_at", desc=True) \
.limit(1) \
.execute()
if response.data:
# Supabase 시각 문자열을 datetime 객체로 변환 (ISO 형식)
return datetime.fromisoformat(response.data[0]['created_at'].replace('Z', '+00:00'))
return datetime.min.replace(tzinfo=timezone.utc)
def _is_cache_valid(self) -> bool:
"""캐시 파일이 최신인지 확인합니다."""
if not os.path.exists(self.bm25_cache_path):
return False
# 1. 캐시 파일의 수정 시각 가져오기
cache_mtime = os.path.getmtime(self.bm25_cache_path)
cache_time = datetime.fromtimestamp(cache_mtime, tz=timezone.utc)
# 2. Supabase의 최신 문서 업데이트 시각 가져오기
latest_db_time = self._get_latest_update_from_supabase()
# DB 시간이 더 최신이면 캐시는 무효(False)
return cache_time > latest_db_time
def _get_supabase_retriever(self):
"""Supabase 기반 Dense Retriever를 반환합니다."""
return CustomSupabaseRetriever(
client=self.supabase,
embeddings=self.embeddings,
table_name=self.config['supabase']['table_name'],
query_name=self.config['supabase']['query_name'],
k=self.k
)
def _fetch_all_docs_from_supabase(self) -> List[Document]:
"""BM25 인덱스 생성을 위해 Supabase에서 모든 문서를 로드합니다."""
# TODO: 문서량이 많아질 경우 캐싱 로직(Redis 등) 고려 필요
response = self.supabase.table(self.config['supabase']['table_name']).select("content, metadata").execute()
documents = [
Document(page_content=row['content'], metadata=row['metadata'])
for row in response.data
]
return documents
def _get_bm25_retriever(self, all_docs: List[Document] = None):
"""BM25 Sparse Retriever를 반환합니다."""
if os.path.exists(self.bm25_cache_path):
print(f"BM25 인덱싱을 로드합니다.: {self.bm25_cache_path}")
with open(self.bm25_cache_path, 'rb') as f:
sparse_retriever = pickle.load(f)
sparse_retriever.k = self.k
return sparse_retriever
else:
print(f"[ERROR] BM25 인덱싱 파일이 존재하지 않습니다. {self.bm25_cache_path} 경로를 확인해 주세요.")
# # 1. 캐시가 존재하고, 최신 상태라면 로드
# if self._is_cache_valid():
# print(f"최신 상태의 BM25 캐시를 로드합니다.: {self.bm25_cache_path}")
# with open(self.bm25_cache_path, 'rb') as f:
# sparse_retriever = pickle.load(f)
# else:
# # 2. 파일이 없으면 인덱스 생성
# print("BM25 캐시가 없거나 오래 되었습니다. Supabase에서 문서를 가져와 인덱스를 생성합니다.")
# if all_docs is None:
# all_docs = self._fetch_all_docs_from_supabase()
# sparse_retriever = KiwiBM25Retriever.from_documents(
# all_docs,
# preprocess_func=kiwi_preprocessing_func
# )
#
# # 3. 생성된 인덱스 파일로 저장 (폴더가 없으면 생성)
# cache_dir = os.path.dirname(self.bm25_cache_path)
# os.makedirs(cache_dir, exist_ok = True)
#
# # 임시 파일 생성
# # delete=False를 주어 쓰기가 끝난 후 우리가 직접 이름을 바꿀 수 있게 합니다.
# with tempfile.NamedTemporaryFile('wb', dir=cache_dir, delete=False) as tf:
# pickle.dump(sparse_retriever, tf)
# temp_path = tf.name
#
# # 이름 바꾸기
# os.replace(temp_path, self.bm25_cache_path)
# # 안전한 파일 쓰기 로직 종료
#
# print("BM25 캐시가 안전하게 갱신되었습니다.")
# sparse_retriever.k = self.k
# return sparse_retriever
def create_bm25_index(self):
try:
print("Supabase에서 문서를 가져와 인덱스를 생성합니다.")
all_docs = self._fetch_all_docs_from_supabase()
sparse_retriever = KiwiBM25Retriever.from_documents(
all_docs,
preprocess_func=kiwi_preprocessing_func
)
# 인덱스 파일을 저장할 폴더 설정 및 폴더가 없으면 생성
cache_dir = os.path.dirname(self.bm25_cache_path)
os.makedirs(cache_dir, exist_ok = True)
# 임시 파일 생성
with tempfile.NamedTemporaryFile('wb', dir=cache_dir, delete=False) as tf:
pickle.dump(sparse_retriever, tf)
temp_path = tf.name
# 이름 바꾸기
os.replace(temp_path, self.bm25_cache_path)
print(f"BM25 인덱스 파일이 정상적으로 {self.bm25_cache_path} 에 생성되었습니다.")
except Exception as e:
print("BM25 인덱스 파일 생성 중 에러가 발생했습니다.")
traceback.format_exc()
def get_hybrid_retriever(self):
"""운영 환경에 맞는 하이브리드 리트리버를 구성합니다."""
# 1. 원격 Supabase Retriever (Dense)
dense_retriever = self._get_supabase_retriever()
# 2. 로컬 메모리 BM25 Retriever (Sparse)
# BM25는 전체 통계가 필요하므로 DB의 모든 문서를 가져와 인덱싱합니다.
sparse_retriever = self._get_bm25_retriever()
# 3. 앙상블 리트리버 반환
return EnsembleRetriever(
retrievers=[sparse_retriever, dense_retriever],
weights=self.weights
)
def get_local_retrieval_for_evaluate(self, local_retrieval_model = "dense"):
"""평가 시 로컬 벡터 DB로부터 retrieval을 가져오기 위한 함수"""
load_faiss_dir = get_absolute_path(self.config['paths']['load_faiss_index_dir'])
vectorstore = FAISS.load_local(
load_faiss_dir,
self.embeddings,
allow_dangerous_deserialization=True)
if local_retrieval_model == "hybrid":
# 기존 로컬 faiss 로직 (테스트용)
dense_retriever = vectorstore.as_retriever(
search_type='similarity',
search_kwargs={"k":self.k})
all_docs = list(vectorstore.docstore._dict.values())
sparse_retriever = KiwiBM25Retriever.from_documents(all_docs, preprocess_func=kiwi_preprocessing_func)
sparse_retriever.k = self.k
ensemble_retriever = EnsembleRetriever(
retrievers = [sparse_retriever, dense_retriever],
weights = self.weights
)
return ensemble_retriever
elif local_retrieval_model == "sparse":
all_docs = list(vectorstore.docstore._dict.values())
sparse_retriever = KiwiBM25Retriever.from_documents(all_docs, preprocess_func=kiwi_preprocessing_func)
sparse_retriever.k = self.k
return sparse_retriever
else:
dense_retriever = vectorstore.as_retriever(
search_type='similarity',
search_kwargs={"k":self.k})
return dense_retriever
class CustomSupabaseRetriever(BaseRetriever):
"""최신 supabase SDK를 지원하는 커스텀 리트리버"""
client: Any = Field(exclude=True)
embeddings: Any = Field(exclude=True)
table_name: str
query_name: str
k: int = 5
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
query_vector = self.embeddings.embed_query(query)
response = self.client.rpc(
self.query_name,
{
"query_embedding": query_vector,
"match_threshold": 0.5,
"match_count": self.k
}
).execute()
results = []
for row in response.data:
results.append(
Document(
page_content=row.get("content", ""),
metadata=row.get("metadata", {})
)
)
return results
2.5 벡터 DB와 관련된 기능을 모아 놓은 VectorDBManager 클래스 정의
기존에 청킹된 문서들을 Supabase에 업로드하는 기능과 평가를 위해 로컬에서 사용하기 위한 FAISS 기반 로컬 벡터를 저장하고 삭제하는 기능을 모아서 VectorDBManager 클래스로 정의하였습니다.
import os
import yaml
from typing import List
from supabase import create_client
from langchain_community.vectorstores import FAISS, SupabaseVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from src.core.config_loader import ConfigLoader
class VectorDBManager:
def __init__(self):
self.config = ConfigLoader.get_config()
self.embeddings = OpenAIEmbeddings(model=self.config['models']['embeddings'])
def save_to_local_faiss(self, documents: List[Document]):
"""평가용 로컬 FAISS 인덱스를 생성하고 저장합니다."""
print(f"📦 로컬 FAISS 인덱스 생성 중... (청크: {len(documents)}개)")
vectorstore = FAISS.from_documents(documents, self.embeddings)
save_path = "../../data/"+"faiss_"+self.config['chunking']['strategy']+"_"+self.config['chunking']['size']+"_"+self.config['chunking']['overlap']
vectorstore.save_local(save_path)
print(f"✅ 저장 완료: {save_path}")
def upload_to_supabase(self, documents: List[Document], keys_path:str = "../../config/keys"):
"""실제 운영을 위해 Supabase에 데이터를 업로드합니다."""
openai_api_key = os.getenv("OPENAI_API_KEY")
supabase_url = os.getenv("SUPABASE_URL")
supabase_key = os.getenv("SUPABASE_KEY")
supabase = create_client(supabase_url, supabase_key)
vector_store = SupabaseVectorStore.from_documents(
documents,
self.embeddings,
client=supabase,
table_name="documents",
query_name="match_documents"
)
print("성공적으로 모든 임베딩이 업로드되었습니다!")
def delete_local_vector_db(self):
"""실험 데이터 초기화를 위해 로컬 벡터 DB 삭제"""
if os.path.exists(self.config['paths']['delete_faiss_index_dir']):
import shutil
shutil.rmtree(self.config['paths']['delete_faiss_index_dir'])
2.6 RAG 시스템을 위한 chain이 정의된 GeneratorManager 클래스 정의
실제 출력에 사용되는 RAG 시스템의 chain이 정의되어 있고 chain에 사용되는 prompt와 LLM의 설정을 할 수 있는 GeneratorManager 클래스를 정의하였습니다.
from typing import List, Dict, Any
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from src.core.config_loader import ConfigLoader
class GeneratorManager:
def __init__(self):
# 1. 설정 및 모델 초기화
self.config = ConfigLoader.get_config()
self.llm = ChatOpenAI(
model=self.config['models']['llm'],
temperature=0.3,
streaming=True
)
def _format_docs_with_sources(self, docs: List)-> str:
"""검색된 문서들을 LLM이 읽기 편한 텍스트 형식으로 변환합니다."""
formatted_context = []
for i, doc in enumerate(docs):
content = doc.page_content
# 메타데이터에서 제목과 URL 추출 (없을 경우 기본값 처리)
title = doc.metadata.get("title", "Unknown Title")
url = doc.metadata.get("url", "#")
formatted_context.append(
f"[문서 {i+1}] (제목: {title})\n 내용: {content}\n 출처: {url}"
)
return "\n\n".join(formatted_context)
def get_rag_chain(self, retriever):
"""LCEL을 사용하여 RAG 전체 파이프라인(Chain)을 생성합니다."""
# 1. 프롬프트 템플릿 정의 (블로그 특성에 맞춘 시스템 프롬프트)
template = """
[Role]
당신은 이쿼카님의 기술 블로그 전문 AI 어시스턴트입니다.
당신의 목표는 제공된 [Context]만을 사용하여 사용자의 질문에 가장 정확하고 신뢰할 수 있는 답변을 제공하는 것입니다.
[답변 규칙]
1. **Source-First**: 답변의 핵심 근거는 반드시 [Context]에서 추출합니다. 외부 지식은 [Context]에 기술된 고유명사의 정의를 보완하거나, 문맥을 매끄럽게 잇는 용도로만 최소한으로 사용합니다. 만약 [Context]의 내용과 외부 지식이 충돌할 경우, 반드시 [Context]를 우선합니다.
2. **No Info Case**: 만약 [Context]에서 질문에 대한 답을 찾을 수 없다면, 구차한 설명을 하지 말고 "죄송합니다. 해당 내용은 블로그에 기술되어 있지 않아 답변드리기 어렵습니다."라고 답변하세요.
3. **Detail & Density**: 답변 시 [Context]에 포함된 구체적인 고유명사, 설정 경로, 명령어(Code) 등을 생략하지 말고 상세히 포함하세요. 이는 답변의 전문성을 높입니다.
4. **Citation**: 답변 끝에 반드시 다음 형식을 지켜 출처를 나열하세요.
- 출처: [포스트 제목](URL)
[Context]
{context}
[Question]
{question}
[Answer]
"""
prompt = ChatPromptTemplate.from_template(template)
# 2. LCEL 체인 구축
# 흐름: 질문 입력 -> 컨텍스트 검색 & 포맷팅 -> 프롬프트 주입 -> LLM 호출 -> 결과 파싱
chain = (
{
"context": retriever | RunnableLambda(self._format_docs_with_sources),
"question": RunnablePassthrough()
}
| prompt
| self.llm
| StrOutputParser()
)
return chain
3. 사용자 경험(UX) 개선을 위한 비동기 스트리밍 기능 적용
3.1 백엔드 수정사항
비동기 스트리밍은 LLM으로부터 답변을 받아올 때의 출력을 비동기 방식으로 출력하도록 해야 합니다. 이를 위해서는 백엔드단에서 출력 결과를 프론트단으로 전달하는 곳에 비동기 스트리밍 출력 방식을 적용해주어야 합니다. 저는 fastapi가 적용된 api 디렉토리의 index.py에 비동기 스트리밍 출력 방식을 적용하였습니다.
FastAPI에서 비동기 스트리밍 구현을 위해 StreamingResponse 객체와 파이썬의 비동기 제너레이터(async def, yield)를 사용하였습니다. 또한 스트리밍은 서버가 답변을 한 번에 모아서 보내는 것이 아니라, LLM이 단어를 생성하는 즉시 잘게 쪼개서(Chunk) 클라이언트에게 지속적으로 흘려보내는 기술입니다. 이를 위해 웹 표준 기술인 SSE(Server-Sent Events)를 사용하였습니다.
import traceback
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from fastapi.responses import StreamingResponse
from src.core.config_loader import ConfigLoader
from src.core.retriever import RetrieverManager
from src.core.generator import GeneratorManager
app = FastAPI()
origins = [
"http://localhost:4000",
"http://127.0.0.1:4000",
"https://icechickentender.github.io",
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
rag_chain = None
try:
print(" [INIT] 서버 전역 초기화 시작...")
config = ConfigLoader.get_config()
retriever_manager = RetrieverManager()
generator_manager = GeneratorManager()
retriever = retriever_manager.get_hybrid_retriever()
# 최종 RAG 체인 생성(LCEL)
rag_chain = generator_manager.get_rag_chain(retriever)
print(" [INIT] 초기화 성공: rag_chain 준비 완료")
except Exception as e:
print(" [INIT] 서버 초기화 중 오류 발생")
print(traceback.format_exc())
raise e
class QueryRequest(BaseModel):
query: str
@app.post("/api/chat")
async def chat(request: QueryRequest):
print(f"[REQ] 질문 수신:{request.query}")
if rag_chain is None:
return {"error": "서버 내부 초기화 실패로 인해 답변할 수 없습니다."}
# 1. 비동기 제너레이터 함수 정의
async def generate_stream():
try:
print(" [GEN] 스트리밍 시작...")
# invoke() 대신 비동기 스트리밍 메서드인 astream()을 사용합니다.
async for chunk in rag_chain.astream(request.query):
# LangChain의 체인 결과물이 문자열(StrOutputParser)이라고 가정합니다.
# SSE 표준 규격인 "data: {내용}\n\n" 형식으로 맞추어 yield 합니다.
yield f"data: {chunk}\n\n"
print(" [GEN] 스트리밍 정상 종료!")
yield "data: [DONE]\n\n"
except Exception as e:
#에러 발생 시 스트림으로 에러 메시지 전송
yield f"data: [ERROR] 서버 스트리밍 중 오류 발생: {str(e)}\n\n"
print(f"답변 생성 중 오류 발생: {e}")
raise HTTPException(status_code=500, detail=str(e))
# 2. StreamingResponse를 반환하며, media_type을 event-stream으로 지정합니다.
return StreamingResponse(generate_stream(), media_type="text/event-stream")
추가적으로 출력 형식이 비동기식이기 때문에 이에 맞춰 Supabase Dense Vector 검색기를 가져오도록 하는 부분에도 비동기 함수를 추가해 주었습니다. 제가 정의한 CustomSupabaseRetriever는 BaseRetriever를 상속받기 때문에 BaseRetrieve에 있는 _aget_relevant_documents 함수를 오버라이드하여 사용하였습니다. 이 작업이 필요한 이유는 비동기 스트리밍 출력에 사용하는 astream은 전체 파이프라인이 비동기일 때 가장 안정적이기 때문입니다. 중간에 동기 리트리버가 끼어들면 Vercel 게이트웨이와의 연결이 불안정해집니다. 두 번째로는 비동기 메서드를 구현하면 첫 번째 토큰이 생성되기까지의 ‘블로킹’ 시간이 줄어들어, Vercel의 타임아웃(10초)를 피할 확률이 훨씬 높아지기 때문입니다. 즉 동기 함수를 비동기 루프에서 실행할 때 발생하는 이벤트 루프 블로킹(Event Loop Blocking)을 방지하여 서버의 전체적인 처리 효율을 높였습니다.
class CustomSupabaseRetriever(BaseRetriever):
"""최신 supabase SDK를 지원하는 커스텀 리트리버"""
client: Any = Field(exclude=True)
embeddings: Any = Field(exclude=True)
table_name: str
query_name: str
k: int = 5
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
# ... 기존 코드 ... #
pass
async def _aget_relevant_documents(self, query: str, *, run_manager: AsyncCallbackManagerForRetrieverRun) -> List[Document]:
# 임베딩 생성 (비동기 지원 확인)
# 만약 OpenAIEmbeddings가 aembed_query를 지원한다면 await 사용
query_vector = await self.embeddings.aembed_query(query)
# Supabase RPC 호출을 비동기로 실행
# .execute()는 동기이므로, asyncio.to_thread로 감싸서 비동기처럼 동작하게 합니다.
loop = asyncio.get_event_loop()
response = await loop.run_in_executor(
None,
lambda: self.client.rpc(
self.query_name,
{
"query_embedding": query_vector,
"match_threshold": 0.5,
"match_count": self.k
}
).execute()
)
results = [
Document(page_content=row.get("content", ""), metadata=row.get("metadata", {}))
for row in response.data
]
return results
3.2 프론트엔드 수정사항
3.2.1 프론트엔드에 스트리밍 출력 적용
프론트엔드는 제가 전문적으로 배우거나 하지 않았고, 또 이전에도 프론트엔드는 Gemini의 도움을 받아 바이브 코딩으로 구현을 하였습니다. 이번에도 Gemini의 도움을 받아 바이브 코딩으로 수정을 진행해 보도록 하겠습니다. 수정한 곳은 default.html 파일만 수정을 했고 해당 파일은 예전 포스트인 https://icechickentender.github.io/toyproject/1-rag_with_blog_basic/ 에서 확인할 수 있습니다.
수정 사항은 다음과 같습니다.
-
response.body.getReader()사용 기존의res.json()은 서버로부터 모든 데이터가 도착할 때까지 기다린 후 한꺼번에 파싱합니다. 하지만 스트리밍 방식을 사용하므로 Vercel 서버에서 데이터를 쪼개서 보내고 있으므로, 바이트 단위로 실시간 수신할 수 있는Reader가 필요합니다. -
TextDecoder도입 서버에서 오는 데이터는 0과 1로 된 바이너리(Unit8Array) 형태입니다. 이를 우리가 읽을 수 있는 UTF-8 문자열로 변환하기 위해TextDecoder를 사용합니다. -
data:접두사 파싱 로직 (SSE 대응) 백엔드에서yield f"data: {chunk}\n\n"형식을 사용했기 때문에, 프론트엔드에서는 각 줄을 읽어data:라는 꼬리표를 떼어내는 작업이 필요합니다. 이유는 표준 SSE(Server-Sent Events) 규격을 맞춤으로써, 추후 브라우저의 전용EventSourceAPI로 확장하기 용이하게 하기 위함입니다. -
aiBuuble.innerText += data 방식 선택
innerHTML대신innerText를 사용하여 글자를 계속 덧붙입니다. -
실시간 스크롤(
msgBox.scrollTop = msgBox.scrollHeight) 글자가 한 줄씩 늘어날 때마다 스크롤을 맨 아래로 내리는 코드를 반복문 안에 넣었습니다.
기존 default.html 의 <script> 부분을 수정하였습니다.
<script>
(function() {
const btn = document.getElementById('ai-widget-button');
const win = document.getElementById('ai-chat-window');
const bubble = document.getElementById('ai-welcome-bubble');
const cls = document.getElementById('ai-chat-close');
const input = document.getElementById('ai-chat-input');
const msgBox = document.getElementById('ai-chat-messages');
btn.onclick = () => {
const isHidden = win.style.display === 'none' || win.style.display === '';
win.style.display = isHidden ? 'flex' : 'none';
if (bubble) bubble.style.display = 'none';
if (isHidden) input.focus();
};
cls.onclick = () => { win.style.display = 'none'; };
input.onkeydown = async (e) => {
if (e.key === 'Enter' && !e.shiftKey) {
e.preventDefault();
const query = input.value.trim();
if (query === '') return;
// 1. 사용자 메시지 출력
msgBox.innerHTML += `
<div class="chat-msg-container user">
<div class="msg-label">나:</div>
<div class="bubble user-bubble">${query}</div>
</div>`;
input.value = '';
msgBox.scrollTop = msgBox.scrollHeight;
// 2. AI 응답을 위한 빈 말풍선 먼저 생성
const loadingId = 'loading-' + Date.now();
const aiMsgId = 'ai-msg-' + Date.now();
msgBox.innerHTML += `
<div id="${loadingId}" class="chat-msg-container ai">
<div class="msg-label">AI:</div>
<div class="bubble ai-bubble">
<span class="dot-flashing"></span> 생각 중...
</div>
</div>`;
msgBox.scrollTop = msgBox.scrollHeight;
try {
// 3. Fetch 요청 (스트리밍 모드)
const response = await fetch('https://toy-project-rag-in-blog.vercel.app/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query: query })
});
if (!response.ok) throw new Error('서버 응답 오류');
// 4. 로딩 표시 제거 및 실제 답변용 버블 준비
const loadingElement = document.getElementById(loadingId);
if (loadingElement) loadingElement.remove();
msgBox.innerHTML += `
<div class="chat-msg-container ai">
<div class="msg-label">AI:</div>
<div id="${aiMsgId}" class="bubble ai-bubble"></div>
</div>`;
const aiBubble = document.getElementById(aiMsgId);
// 5. 스트림 읽기 시작
const reader = response.body.getReader();
const decoder = new TextDecoder();
let done = false;
while (!done) {
const { value, done: doneReading } = await reader.read();
done = doneReading;
const chunkValue = decoder.decode(value);
// SSE 형식(data: ...) 파싱
const lines = chunkValue.split('\n');
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = line.replace('data: ', '');
if (data === '[DONE]') {
done = true;
break;
}
if (data.startsWith('[ERROR]')) {
aiBubble.innerText += "\n[오류 발생: " + data + "]";
break;
}
// 텍스트 추가 및 스크롤 조절
aiBubble.innerText += data;
msgBox.scrollTop = msgBox.scrollHeight;
}
}
}
} catch (err) {
const loadingElement = document.getElementById(loadingId);
if (loadingElement) {
loadingElement.innerHTML = `<div class="msg-label">AI:</div><div class="bubble ai-bubble" style="color: #ff6b6b;">통신 오류가 발생했습니다.</div>`;
}
console.error(err);
}
msgBox.scrollTop = msgBox.scrollHeight;
}
};
})();
</script>
다음은 모든 수정사항을 적용했을 때의 결과입니다. 우선 비동기로 출력되는 것은 확인했으나 모든 글자들이 하나로 붙어서 출력되어 가독성이 떨어지는 문제가 있습니다.
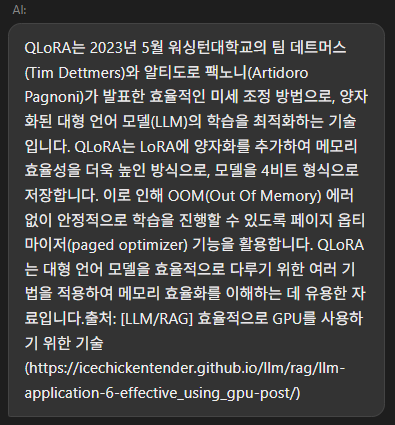
3.2.2 가독성 문제 해결
가독성 문제 해결을 위해 Chat-GPT나 Gemini와 같이 마크다운 형식으로 출력이 되도록 여러 수정 사항을 진행해 보았습니다.
3.2.2.1 프롬프트 및 LLM 옵션 수정
우선 원인 파악을 먼저 진행해 보았습니다. 프론트엔드 단인 웹상의 블로그 화면이 아니라 Vercel과 직접 통신하여 Vercel로부터 스트리밍 출력을 받아오도록 해보았습니다. 출력 결과를 확인해 보니 출력 결과에는 줄바꿈 문자(\n)가 존재하지 않았고 위의 이미지와 같이 모든 문자들이 붙어서 출력되는 것을 확인했습니다. 그래서 이 문제부터 처리하기 위해 찾아본 결과 이 문제는 프롬프트와 LLM 옵션 수정으로 해결할 수 있는 것을 확인할 수 있었습니다
첫 째로 프롬프트를 통해 원하고자 하는 출력 형태를 아주 강건하게 정해주어야 한다고 합니다. 그리고 무엇보다 LLM은 Few-shot이 적용되기 때문에 원하는 형태의 출력 예제를 알려주게 된다면 LLM은 제가 정해준 방식으로 최대한 답변하게 된다고 합니다. 따라서 저는 기존에 사용하던 프롬프트에서 다음 사항들을 추가하였습니다.
- 어떻게 출력을 해야하는지에 대한 출력 형식을 프롬프트에 추가해 주었습니다.
- 사용자의 질문 중에
안녕?과 같이 아주 단순한 질문이 있을 수 있으므로 이러한 질문의 복잡도에 맞춰 답변의 길이를 조절하도록 하기 위해 질문의 복잡도에 맞춰 답변의 길이를 조절하도록 하는 지시 사항을 추가해 주었습니다. - LLM에게 원하는 형식의 출력 형식을 만들어 예제로 제공해 주었습니다.
위의 수정사항이 반영된 프롬프트는 다음과 같습니다.
template = """
[Role]
당신은 이쿼카님의 기술 블로그 전문 AI 어시스턴트입니다.
당신의 목표는 제공된 [Context]만을 사용하여 사용자의 질문에 가장 정확하고 신뢰할 수 있는 답변을 제공하는 것입니다.
[답변 규칙]
1. **Source-First**: 답변의 핵심 근거는 반드시 [Context]에서 추출합니다. 외부 지식은 [Context]에 기술된 고유명사의 정의를 보완하거나, 문맥을 매끄럽게 잇는 용도로만 최소한으로 사용합니다. 만약 [Context]의 내용과 외부 지식이 충돌할 경우, 반드시 [Context]를 우선합니다.
2. **No Info Case**: 만약 [Context]에서 질문에 대한 답을 찾을 수 없다면, 구차한 설명을 하지 말고 "죄송합니다. 해당 내용은 블로그에 기술되어 있지 않아 답변드리기 어렵습니다."라고 답변하세요.
3. **Detail & Density**: 답변 시 [Context]에 포함된 구체적인 고유명사, 설정 경로, 명령어(Code) 등을 생략하지 말고 상세히 포함하세요. 이는 답변의 전문성을 높입니다.
4. **Citation**: 답변 끝에 반드시 다음 형식을 지켜 출처를 나열하세요.
- 출처: [포스트 제목](URL)
5. **Format**: 답변의 출력 형식은 다음 규칙을 지켜주세요.
- 답변은 반드시 마크다운(MarkDown) 형식을 사용한다.
- 논리적인 단계나 주제가 바뀔 때는 반드시 **두번의 줄바꿈(\n\n)**을 사용하여 단락을 구분한다.
- 단락 구분 반드시 리터럴 줄바꿈 문자(\n\n)을 포함해야 하며, 공백을 줄바꿈 대신 사용하지 마라.
- 나열이 필요한 경우 불렛 포인트(*)나 번호 매기기(1.)를 사용한다.
- 핵심 용어는 **강조** 처리한다.
- 마크다운 문법(표, 수식, 굵게 등)을 사용할 때는 문법 기호가 잘리지 않도록 한 문장 안에서 완결성 있게 작성합니다. 특히 표를 생성할 때는 열과 행의 구분(|, -)을 명확히 하여 레이아웃이 깨지지 않게 합니다.
6. **Query Complexity**: 질문의 복잡도에 맞춰 답변의 길이를 조절합니다.
[Few-shot Example]
**User:** "GPU 메모리를 아끼기 위한 QLoRA 기술에 대해 설명해줘."
**Assistant:**
**QLoRA(Quantized Low-Rank Adaptation)**는 한마디로 '가성비의 끝판왕'이라고 할 수 있는 미세 조정 기법입니다. 2023년 Tim Dettmers 등이 발표한 이 기술은 기존 LoRA를 한 단계 더 발전시켜, **메모리 사용량을 획기적으로 줄이면서도 성능 저하는 최소화**했습니다.
쉽게 말해, 수천만 원짜리 서버용 GPU가 필요한 거대 모델을 일반 소비자용 GPU(RTX 3090/4090 등)에서도 훈련할 수 있게 만든 혁신적인 방법입니다.
---
### 1. QLoRA의 3가지 핵심 기술
QLoRA가 기존 LoRA와 차별화되는 지점은 크게 세 가지 기술적 장치에 있습니다.
#### ① 4-bit NormalFloat (NF4)
데이터를 단순히 자르는 것이 아니라, 가중치의 통계적 특성에 최적화된 새로운 데이터 타입을 사용합니다.
* **원리:** 모델의 가중치는 대개 0을 중심으로 하는 정규 분포를 가집니다. **NF4**는 이 분포에 맞춰 정보 손실이 가장 적도록 구간을 나눈 4비트 데이터 타입입니다.
* **효과:** 일반적인 4비트 양자화(Integer 4-bit)보다 훨씬 높은 정밀도를 유지하며 정보를 보존합니다.
#### ② Double Quantization (이중 양자화)
양자화 과정에서 발생하는 '상수(Quantization Constants)'조차도 다시 한번 양자화하여 메모리를 추가로 절약합니다.
* **원리:** 양자화된 블록마다 필요한 스케일링 상수를 32비트가 아닌 8비트로 다시 압축합니다.
* **효과:** 모델의 파라미터당 약 0.37비트의 메모리를 추가로 절감할 수 있어, 수십억 개의 파라미터를 가진 모델에서 상당한 이득을 봅니다.
#### ③ Paged Optimizers
GPU 메모리가 부족할 때 시스템의 메인 메모리(CPU RAM)를 활용하여 '메모리 부족(OOM)' 에러를 방지합니다.
* **원리:** GPU 메모리가 꽉 차면 옵티마이저 상태를 잠시 CPU로 옮겼다가 필요할 때 다시 가져오는 페이징(Paging) 기술을 적용합니다.
---
### 2. 수식으로 보는 QLoRA
기존 LoRA의 수식에 양자화 함수가 추가된 형태라고 이해하면 쉽습니다.
$$Y = \text(W)X + ABX$$
여기서:
* $W$는 **4비트(NF4)**로 고정된 사전 학습 가중치입니다.
* $A, B$는 학습 가능한 **저차원 행렬(LoRA 어댑터)**로, 실제 업데이트는 이 부분에서만 일어납니다. (보통 16비트로 학습)
* 계산 시에는 4비트 $W$를 일시적으로 16비트로 되돌려(Dequantize) 어댑터와 연산합니다.
---
### 3. LoRA vs. QLoRA 한눈에 비교
| 항목 | LoRA | QLoRA |
| --- | --- | --- |
| **기본 모델 가중치** | 16-bit (FP16/BF16) | **4-bit (NF4)** |
| **어댑터 가중치** | 16-bit (FP16/BF16) | 16-bit (FP16/BF16) |
| **메모리 요구량** | 낮음 | **매우 낮음 (LoRA 대비 ~1/4)** |
| **훈련 속도** | 빠름 | LoRA보다 약간 느림 (역양자화 연산 필요) |
| **성능 (Accuracy)** | Full Fine-tuning에 근접 | **LoRA와 거의 동일한 수준 유지** |
---
### 요약하자면
QLoRA는 **"정교한 양자화(NF4) + 중복 압축(Double Quantization) + 메모리 관리(Paged Optimizer)"**를 통해 모델의 핵심 엔진은 4비트로 꽁꽁 싸매어 메모리를 아끼고, 아주 작은 '어댑터'만 16비트로 정교하게 학습시키는 영리한 방식입니다.
출처: [LLM/RAG] 효율적으로 GPU를 사용하기 위한 기술 (https://icechickentender.github.io/llm/rag/llm-application-6-effective_using_gpu-post/)
---
[Context]
{context}
[Question]
{question}
[Answer]
"""
두 번째로 RAG 시스템의 답변을 받는 LLM 모델의 경우 temperature가 너무 낮을 경우 모델이 가장 안전하고 짧은 경로(공백이나 줄바꿈 문자 제거 등)를 선택하게 되어 생략될 수 있습니다. 그래서 temperature를 0보다는 0.3~0.5 정도로 설정해 주는 것이 좋다고 합니다. 그래서 저는 GeneratorManager에 정의되어 있는 ChatOpenAI에서 temperature를 0에서 0.3으로 변경해 주었습니다.
class GeneratorManager:
def __init__(self):
# 1. 설정 및 모델 초기화
self.config = ConfigLoader.get_config()
self.llm = ChatOpenAI(
model=self.config['models']['llm'],
temperature=0.3,
streaming=True
)
#... 생략 ...
3.2.2.2 마크다운 형식의 출력을 위해 default.html 수정
마크다운 형식의 출력을 위해 다음과 같은 수정을 진행하였습니다.
- 실시간 마크다운(Markdown) 렌더링 도입
- markded.js 라이브러리를 추가했습니다. 마지막으로 수정했던 default.html 파일의
<script>윗 부분에<script src="https://cdn.jsdelivr.net/npm/marked/marked.min.js"></script>를 추가해 주었습니다.- 서버에서 오는 텍스트 조각들을 실시간으로 조립(accumulatedText)하고, 이를
markded.parse()함수를 통해 HTML로 변환합니다. - 다만 marked.js는 기본 설정만으로는 LaTex의 수식 렌더링을 위해서는 추후 KaTeX나 MathJax 라이브러리를 추가로 연동해야 하는 문제가 있습니다.
- 서버에서 오는 텍스트 조각들을 실시간으로 조립(accumulatedText)하고, 이를
- markded.js 라이브러리를 추가했습니다. 마지막으로 수정했던 default.html 파일의
-
가독성 중심의 CSS 고도화 Chat-GPT나 Gemini 등과 같은 LLM을 이용한 AI 서비스에 최적화된 스타일을 적용하였습니다.
<script>아래부분에 style을 위한<style>을 추가해 주었습니다.line-height: 1.8: 줄 간격을 넓혀 긴 기술 설명도 눈이 피로하지 않게 하였습니다.margin-botom: 1.2em: 단락(p태그) 사이의 간격을 확실히 벌려 정보의 구조를 명확히 했습니다.strong강조: 굵은 글씨에 미세한 배경색(rgba(0, 123, 255, 0.15))을 넣어 핵심 키워드가 한눈에 들어오도록 디자인했습니다.
<script src="https://cdn.jsdelivr.net/npm/marked/marked.min.js"></script>
<style>
/* 1. 전체 컨테이너 및 고정 위치 */
#ai-widget-container {
position: fixed !important;
bottom: 30px !important;
right: 30px !important;
z-index: 99999 !important;
display: flex !important;
flex-direction: column !important;
align-items: flex-end !important;
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, sans-serif !important;
}
/* 2. 말풍선 가이드 (애니메이션 포함) */
#ai-welcome-bubble {
background: #007bff !important;
color: white !important;
padding: 10px 15px !important;
border-radius: 12px !important;
margin-bottom: 12px !important;
font-size: 14px !important;
font-weight: 500 !important;
box-shadow: 0 4px 15px rgba(0,0,0,0.3) !important;
position: relative !important;
animation: bounce 2s infinite;
}
#ai-welcome-bubble::after {
content: '';
position: absolute;
bottom: -8px;
right: 25px;
border-left: 8px solid transparent;
border-right: 8px solid transparent;
border-top: 8px solid #007bff;
}
@keyframes bounce {
0%, 20%, 50%, 80%, 100% {transform: translateY(0);}
40% {transform: translateY(-5px);}
60% {transform: translateY(-3px);}
}
/* 3. 채팅창 기본 스타일 */
#ai-chat-window {
display: none; /* 초기 숨김 */
width: 450px;
max-width: 90vw;
height: 600px;
background: #1e1e1e !important;
border: 1px solid #444 !important;
border-radius: 15px !important;
box-shadow: 0 10px 30px rgba(0,0,0,0.5) !important;
flex-direction: column !important;
overflow: hidden !important;
margin-bottom: 15px !important;
}
/* 4. 메시지 박스 및 스크롤바 */
#ai-chat-messages {
flex: 1;
overflow-y: auto;
padding: 20px;
background: #1e1e1e;
}
#ai-chat-messages::-webkit-scrollbar { width: 6px; }
#ai-chat-messages::-webkit-scrollbar-thumb { background: #444; border-radius: 10px; }
/* 5. 입력창 (Textarea) */
#ai-chat-input {
width: 100% !important;
background: #333 !important;
color: white !important;
border: 1px solid #555 !important;
padding: 12px !important;
border-radius: 8px !important;
outline: none !important;
resize: none !important;
font-size: 14px !important;
}
/* 6. 메시지 말풍선 공통 */
.chat-msg-container { margin-bottom: 20px; width: 100%; display: block; }
.chat-msg-container.ai { text-align: left; }
.chat-msg-container.user { text-align: right; }
.msg-label { font-size: 11px; color: #888; margin-bottom: 5px; display: block; }
.bubble { display: inline-block; padding: 12px 16px; border-radius: 12px; max-width: 85%; font-size: 14.5px; text-align: left; }
.user-bubble { background: #007bff; color: white; border-bottom-right-radius: 2px; }
/* ⭐ [가독성 핵심] AI 마크다운 답변 스타일 ⭐ */
.ai-bubble.markdown-body {
background: #333;
color: #eee !important;
border: 1px solid #444;
border-bottom-left-radius: 2px;
line-height: 1.8 !important; /* 줄 간격을 넓혀 시원하게 */
white-space: normal !important; /* 마크다운 레이아웃 허용 */
}
/* 단락(Paragraph) 간격 */
.ai-bubble.markdown-body p {
margin: 0 0 1.2em 0 !important; /* 문단 사이의 확실한 거리 */
}
/* 목록(List) 간격 */
.ai-bubble.markdown-body ul, .ai-bubble.markdown-body ol {
margin: 0 0 1em 1.2em !important;
}
.ai-bubble.markdown-body li {
margin-bottom: 8px !important;
}
/* 강조(Bold) 효과 */
.ai-bubble.markdown-body strong {
color: #fff !important;
font-weight: 700 !important;
background: rgba(0, 123, 255, 0.15); /* 살짝 배경 강조 */
padding: 0 2px;
}
/* 7. 위젯 버튼 및 펄스 효과 */
#ai-widget-button {
width: 65px !important;
height: 65px !important;
background: #333 !important;
border-radius: 50% !important;
cursor: pointer !important;
display: flex !important;
align-items: center !important;
justify-content: center !important;
position: relative !important;
border: 2px solid #555 !important;
}
.pulse-effect {
position: absolute; width: 100%; height: 100%; border-radius: 50%;
background: rgba(0, 123, 255, 0.4); animation: pulse 2s infinite; z-index: -1;
}
@keyframes pulse { 0% { transform: scale(1); opacity: 0.8; } 100% { transform: scale(1.5); opacity: 0; } }
/* 8. 로딩 애니메이션 (Dot Flashing) */
.dot-flashing {
position: relative; display: inline-block; width: 7px; height: 7px; border-radius: 5px;
background-color: #007bff; animation: dot-flashing 1s infinite linear alternate;
animation-delay: 0.5s; margin: 0 15px;
}
.dot-flashing::before, .dot-flashing::after {
content: ""; display: inline-block; position: absolute; top: 0; width: 7px; height: 7px;
border-radius: 5px; background-color: #007bff; animation: dot-flashing 1s infinite linear alternate;
}
.dot-flashing::before { left: -12px; animation-delay: 0s; }
.dot-flashing::after { left: 12px; animation-delay: 1s; }
@keyframes dot-flashing { 0% { background-color: #007bff; } 50%, 100% { background-color: rgba(0, 123, 255, 0.2); } }
</style>
수정을 진행했음에도 결과를 보면 여전히 가독성 없이 따닥 따닥 붙어 있는 것을 볼 수 있습니다. 하지만 마크다운 파싱은 적용이 되어 **로 강조 표시가 된 문자열은 다른 색으로 표시가 되는 것을 확인할 수 있습니다.

3.2.2.3 가독성 문제 해결을 위한 고찰
여기까지 진행을 했을 때 정확한 문제의 원인을 찾지 못하겠어서 우선 바뀐 프롬프트로 출력되는 스트리밍 출력은 어떤지 확인해 보기로 하였습니다. 프론트엔드를 타지 않고 Vercel에 직접 통신하여 결과를 받아서 비동기로 출력하도록 해보았습니다. 다음은 Vercel 서버와 통신하여 받아온 스트리밍 결과입니다.
**LoRA(Low-Rank Adaptation)**는 모델 학습 시 **파라미터 재구성을 통해 더 적은 파라미터를 학습**하는 기법입니다. LoRA를 적용할 때 결정해야 할 사항은 크게 세 가지가 있습니다.
---
### 1. 차원 $r$ 설정
* **설명:** 파라미터 $W$에 더한 행렬 $A$와 $B$를 만들 때 차원 $r$을 설정해야 합니다.
* **효과:** $r$을 작게 설정하면 학습해야 하는 파라미터의 수가 줄어들어 GPU 메모리 사용량을 줄일 수 있습니다. 그러나 $r$이 작아질 경우 모델의 학습 용량(capacity)이 줄어들어 학습 데이터의 패턴을 충분히 학습하지 못할 수 있습니다. 따라서 실험을 통해 적절한 $r$값을 설정해야 합니다.
---
### 2. 알파(alpha) 설정
* **설명:** 추가한 파라미터를 기존 파라미터에 얼마나 반영할지를 결정하는 알파가 필요합니다.
* **효과:** 행렬 $A$와 $B$를 기존 파라미터 $W$에 더할 때, 알파가 커질수록 새롭게 학습한 파라미터의 중요성을 더 크게 고려합니다. 학습 데이터에 따라 적절한 알파 값도 달라지기 때문에 실험을 통해 $r$값과 함께 적절히 설정해야 합니다.
---
### 3. 적용할 파라미터 선택
* **설명:** 모델에 있는 많은 파라미터 중 어떤 파라미터를 재구성할지를 결정해야 합니다.
* **효과:** 일반적으로 세레프 어텐션 연산의 Q, K, V 가중치와 피드 포워드 층의 가중치에 LoRA를 적용하는 것이 성능이 가장 좋다고 알려져 있습니다. 특정 가중치에만 LoRA를 적용할 수도 있으며, 이 부분 또한 실험을 통해 적절히 선택해야 합니다.
---
LoRA는 이러한 설정을 통해 GPU 메모리 사용량을 줄이면서도 전체 미세 조정과 거의 동일한 성능을 내는 효율적인 학습 방법입니다.
출처: [LLM/RAG] 효율적으로 GPU를 사용하기 위한 기술 (https://icechickentender.github.io/llm/rag/llm-application-6-effective_using_gpu-post/)
출력되는 결과를 보면 백엔드 단인 Vercel에 직접 통신하여 받아오는 결과는 줄바꿈이 정상적으로 적용이 되고 있고, 프롬프트를 통해 LLM이 마크다운 형식으로도 출력 결과를 잘 뱉어주고 있는 것을 확인할 수 있습니다.
그렇다면 문제는 백엔드에서 결과를 받는 프론트엔드 단에서 문제가 발생하는 것이라고 볼 수 있습니다. 여기서 좀 더 찾아보니 SSE(Server-Sent Events) 프로토콜의 문제일 수도 있다는 것을 찾을 수 있었습니다. SSE 프로토콜에서의 줄바꿈은 매우 특별한 의미를 가진다고 합니다. 만약 모델이 보낸 토큰(chunk)에 \n이 포함되어 있다면, 백엔드에서 f"data: {chunk}\n\n을 생성할 때 실제 전송되는 문자열은 data: \n\n\n아 같은 형태가 됩니다. 이때 Vercel의 프록시 서버나 브라우저의 스트림 리더가 이를 “데이터가 없는 빈 메시지”로 오해하여 무시하거나, 공백으로 치환해버리는 경우가 발생합니다.
이 문제를 해결하기 위해선 백엔드에서 줄바꿈을 안전한 문자로 치환해서 보내고, 프론트엔드에서 다시 복구하는 것입니다. 이 방식은 실제 상용 AI 서비스에서도 자주 쓰이는 방식이라고 합니다.
우선 백엔드 수정을 진행합니다. 줄바꿈 문자(\n)를 SSE 프로토콜 규격과 출동하지 않는 특수 문자열(\\n)로 치환하여 전송합니다.
# api/index.py 내의 generate_stream 함수 수정
async def generate_stream(query: str):
try:
async for chunk in rag_chain.astream({"question": query}):
# [수정] 줄바꿈 문자를 이스케이프된 문자열로 변환하여 전송
# 이렇게 하면 SSE 프로토콜의 \n과 실제 데이터의 \n이 섞이지 않습니다.
safe_chunk = chunk.replace("\n", "\\n")
yield f"data: {safe_chunk}\n\n"
yield "data: [DONE]\n\n"
except Exception as e:
yield f"data: [ERROR] {str(e)}\n\n"
이제 프론트 엔드 수정을 진행합니다. 수신한 데이터에서 \\n을 다시 실제 줄바꿈 \n으로 되돌리도록 합니다.
// default.html 내의 스트리밍 파싱 로직 수정
while (true) {
const { value, done } = await reader.read();
if (done) break;
const chunkValue = decoder.decode(value);
const lines = chunkValue.split('\n');
for (const line of lines) {
if (line.startsWith('data: ')) {
// 1. 꼬리표 제거 및 이스케이프된 줄바꿈 복구
let content = line.slice(6).replace(/\\n/g, '\n');
if (content.trim() === '[DONE]') continue;
// 2. 텍스트 누적
accumulatedText += content;
}
}
// 3. 렌더링 (marked.js가 이제 \n을 보고 단락을 정확히 구분합니다)
if (typeof marked !== 'undefined') {
aiBubble.innerHTML = marked.parse(accumulatedText);
}
msgBox.scrollTop = msgBox.scrollHeight;
}
위 수정사항들을 각 github 저장소에 푸시해준 뒤에 로컬로 뛰운 블로그에서 테스트를 진행하면 아래 이미지와 같이 제가 원하던 Chat-GPT나 Gemini와 같은 형식으로 출력해 주는 것을 확인할 수 있습니다.
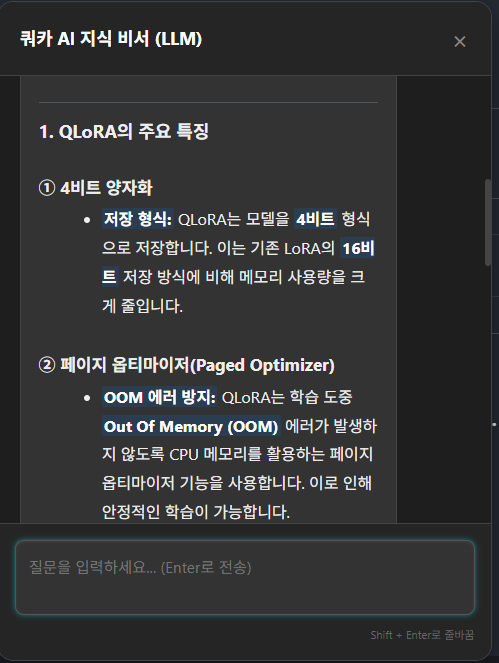
마치며
이번 포스트에서는 이전에 구현해 놓았던 Naive RAG 시스템의 여러 기능들이 각 Python 파일과 함수로 난잡하게 구현되어 있던 것을 하나의 체계적인 시스템으로써 동작하도록 하기 위해 리펙토링 작업을 진행하였습니다. 그리고 이전에는 LLM으로부터 온 답변을 한 번에 뿌리도록 되어 있던 것을 좀 더 사용자 친화적인 방법인 비동기 스트리밍 방식으로 출력되도록 하기 위해 백엔드와 프론트엔드를 수정하는 작업을 진행하였습니다. 마지막으로 사용자 친화적인 출력 방식인 비동기 스트리밍과 함께 Chat-GPT나 Gemini와 같이 마크다운 형식으로 출력되도록 하기 위해 프롬프트 엔지니어링을 적용해 프롬프트를 수정하고, LLM 옵션과 마크다운 형식 출력을 위한 프론트엔드의 코드 수정을 진행하였습니다.
이번 포스트에 작성한 작업들을 진행하면서 LLM을 이용한 모듈을 만들 때는 프롬프트 엔지니어링이 정말 중요하다는 것을 다시 한 번 깨달았고, 그리고 Server-Sent Events 프로토콜이라는 것이 있다는 것을 알게 되었고, 이 프로토콜 때문에 줄바꿈이 제대로 되지 않을 수도 있다는 것을 알게 되었습니다. 그리고 비동기 스트리밍을 적용하기 위해선 백엔드와 프론트엔드에 대한 개념이 필수라는 것을 알게 되었습니다.
다음에는 구현한 RAG의 성능을 더 끌어올릴 수 있는 방법 혹은 더 심화된 RAG를 적용하는 것에 대한 내용들을 다뤄볼 예정입니다. 긴 글 읽어주셔서 감사드리며 내용 중에 잘못된 내용이나 오타, 궁금하신 사항이 있으실 경우 댓글 달아주시기 바랍니다.
Comments