
[PaperReview] BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 논문 리뷰
개요
이전 직장을 퇴사하고 이전 직장에서 업무로써 맡아왔던 전통적인 사전 및 규칙 기반 언어 분석기를 넘어 LLM 및 RAG 기반의 제품을 서비스하는 곳에 취직하고자 LLM과 RAG 위주로 나름 공부를 진행해 왔습니다. 하지만 4년 동안 이전 직장에서 일하면서 석사 때 했었던 최신 연구 트렌드 파악과 최근 4~5년간 나온 최신 딥러닝 모델들을 다루는 것들이 무뎌져 단순히 취업만을 위해 겉핥기 식으로 공부를 하다가는 이도 저도 안될 것 같다고 생각했습니다. 그래서 논문 위주로 LLM의 기초를 쌓기 위해 LLM의 기초가 되는 논문들을 읽고 논문 리뷰를 포스트로 작성하는 형식으로 공부를 해보고자 이 포스트를 작성하게 되었습니다.
1. Introduction: Context & Motivation
1.1 BERT 이전 모델들의 한계점
-
GPT-1의 한계 (Undirectionality): GPT-1은 Transformer의 Decoder 구조를 사용하여 왼쪽에서 오른쪽으로(Left-to-Right) 단어를 예측하며 학습합니다. 이 방식은 문장을 생성하는 데는 유리하지만, 특정 단어의 의미를 파악할 때 오른쪽의 문맥을 전혀 활용할 수 없습니다. 예를 들어 “bank”라는 단어가 “계좌”인지 “강둑”인지 판단하려면 뒤에 오는 문장을 봐야 하는데, GPT는 구조적으로 이를 보지 못하는 ‘외눈박이’와 같았습니다.
-
ELMo의 한계 (Shallow Bidirectionality): ELMo는 왼쪽에서 오른쪽으로 가는 LSTM과 오른쪽에서 왼쪽으로 가는 LSTM을 각각 학습시킨 뒤, 단순히 두 벡터를 이어 붙이는 (Concatenate) 방식을 취합니다. 이는 진정한 의미의 결합이 아니며, 두 방향의 문맥이 모델 내부의 깊은 레이어에서 서로 상호작용(Interaction)하지 못하는 얕은 구조였습니다. 또한 ELMo는 LSTM 모델을 사용하기 때문에 아무리 성능이 좋은 GPU를 쓴다고 해도 순차 구조이기 때문에 현재 token을 처리하기 위해선 이전 token의 처리를 기다려야 하므로 속도가 굉장히 느리다는 문제 또한 가지고 있었습니다.
-
기타 모델의 한계: ULMFiT 같은 모델 역시 기본적으로 단방향 LM에 기반하고 있었으며, Word2Vec이나 GloVe 같은 Static Embedding은 문맥에 따라 단어의 의미가 변하는 Polysemy(다의어) 문제를 전혀 해결하지 못했습니다.
1.2 이전 모델들의 핵심 문제를 해결하기 위한 BERT의 아이디어
BERT가 해결하고자 했던 핵심 문제는 어떻게 하면 아키텍처 내부에서 왼쪽과 오른쪽 문맥을 동시에 고려하여 깊은 표상을 학습할 수 있을까?였습니다. 이를 위한 아이디어는 다음과 같습니다.
-
혁신적인 아이디어: Masked Language Model(MLM): 기존의 LM 방식(다음 단어 맞추기)으로는 양방향 학습이 불가능했습니다. 양방향을 다 보여주면 모델이 정답 단어를 미리 ‘컨닝’하게 되는 것이기 때문입니다. BERT는 이를 해결하기 위해 입력 토큰의 일부(15%)를
\[\mathcal{L}_{\text{MLM}} = - \log P(w_i | w_1, \dots, w_{i-1}, w_{i+1}, \dots, w_n)\][MASK]로 가리고, 이를 주변 문맥으로 예측하게 하는 방식을 도입했습니다.위 수식에서 볼 수 있듯, $w_i$를 예측하기 위해 이전 단어들($w_{1 \dots i-1}$)과 이후 단어들($w_{i+1 \dots n}$)을 모두 조건부 확률에 포함시킵니다.
-
보조 태스크: Next Sentence Prediction (NSP): 단어 수준을 넘어 문장 간의 관계를 학습하기 위해, 두 문장이 이어지는 문장인지 아닌지를 맞추는 이진 분류 태스크를 추가했습니다. 이는 QA(질의 응답)나 NLI(자연어 추론) 태스크에서 압도적인 성능을 내는 기반이 됩니다.
2. Architecture & Objective
BERT는 3개의 개별 임베딩 룩업 테이블을 합산하여 구성하며, 사전 학습(Pre-training)에서는 대규모 비라벨 데이터로 언어의 구조를 배우고, 미세 조정(File-tuning)에서는 최상단에 최소한의 레이어(Task-specific head)를 추가하여 특정 목적에 맞게 가중치를 업데이트합니다.
2.1 Model Architecture
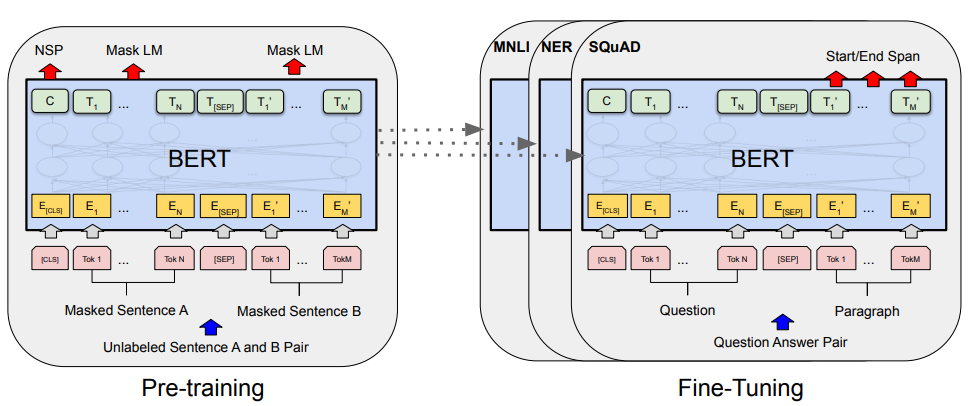
BERT 모델의 구조는 Transformer 모델의 Encoder, Decoder에서 Encoder 부분만 가져와서 사용하는 구조입니다. 그리고 아래 이미지에서와 같이 Unlabeled Sentence 데이터와 NSP 데이터를 이용해 사전 학습을 먼저 진행하고, 각 downstream 태스크에 맞는 데이터와 레이어를 추가해 fine-tuning을 진행하는 구조입니다.
2.2 BERT 모델의 입력 임베딩
-
3개의 입력 임베딩 레이어
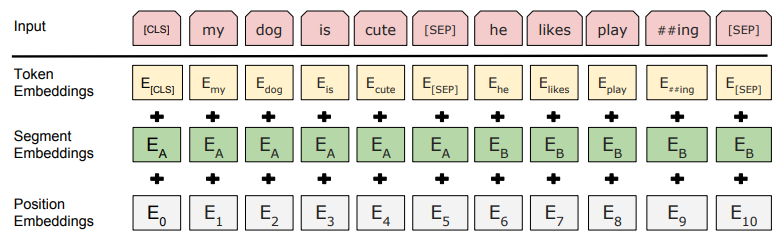
BERT는 내부적으로 3개의 독립적인 Embedding Layer를 가지고 있습니다. 트랜스포머 인코더로 들어가기 전, 각 토큰에 대해 세 가지 임베딩을 찾아낸 뒤 이를 요소별 합산(Element-wise sum)을 진행합니다.
- Token Embeddings: 단어(WordPiece)를 $H$ 차원의 벡터로 매핑.
- Segment Embeddings: 문장 A인지 B인지(0 또는 1)를 $H$ 차원의 벡터로 매핑.
- Position Embeddings: 위치 정보(0~511)를 $H$ 차원의 벡터로 매핑
아래는 BERT 모델 내부에 있는 입력 임베딩 레이어 이미지 입니다.
-
Segment Embedding의 구분 원리
- 구현 방식: 모델은 보통
sentence_id(0 또는 1)를 입력받습니다. 내부적으로는 $2 \times H$ 크기의 임베딩 테이블이 있어, 0이면EA벡터를, 1이면EB벡터를 가져옵니다. - 구분 기준:
[SEP]토큰은 문장을 물리적으로 나누는 역할을 하며, 실제 Segment Embeddings는[SEP]를 포함하여 첫 번째 문장에 속하는 모든 토큰에는EA를, 두 번째 문장에는EB를 더해줍니다.
- 구현 방식: 모델은 보통
-
입력 임베딩 레이어의 학습
이전 Word2Vec이나 GloVe에서 학습한 Static Embedding 벡터를 사용하던 LSTM 모델과는 달리 Transformer 모델을 사용한 BERT 모델은 내부적으로 임베딩 레이어도 함께 학습이 진행됩니다. 임베딩 레이어는 내부적으로 $V \times H$ (V: 단어 사전 크기, H: Hidden Size) 크기의 가중치 행렬 $W_{emb}$를 가진 하나의 신경망 레이어와 같습니다.
-
순전파(Forward): 입력된 인덱스 $i$에 대해 원-핫 벡터 $x_i$와 가중치 행렬 $W_{emb}$를 곱하여 임베딩 벡터 $e_i$를 얻습니다.
\[e_i = x_i \cdot W_{emb}\] -
역전파(Backward): 손실 함수 $\mathcal{L}$에서 계산된 그래디언트가 모든 트랜스포머 블록을 타고 내려와 최종적으로 이 $W_{emb}$에 도달합니다.
\[W_{emb} \leftarrow W_{emb} - \eta \frac{\partial \mathcal{L}}{\partial W_{emb}}\]
이 과정을 통해 Token, Segment, Position 임베딩 테이블의 수치들이 조금씩 수정되며, 모델이 문맥을 가장 잘 파악할 수 있는 최적의 ‘좌표’를 찾아가게 됩니다.
-
2.3 MLM(Masked LM)과 학습 데이터 구성
MLM은 오직 사전 학습(Pre-training) 단계에서만 사용됩니다.
- Pre-training 데이터: 라벨이 없는 거대 코퍼스(BooksCorpus 8억 단어, Wikipedia 25억 단어)를 사용합니다. 특정 태스크(분류, QA등)에 대한 정답 없이, 순수하게 언어의 통계적 패턴을 학습합니다.
- Fine-tuning 데이터: 특정 목적(Downstream task)을 위해 사람이 라벨링한 데이터를 사용합니다.
- MLM의 80-10-10 트릭: Pre-trainig 시 15%를 마스킹하되, 그 중 80%는
[MASK], 10%는 무작위 단어, 10%는 실제 단어를 그대로 둡니다. 이는 Fine-tuning 시에는[MASK]라는 토큰이 나타나지 않으므로, 모델이 실제 단어에 대해서도 문맥을 파악하는 능력을 유지하게 하려는 의도입니다. -
손실 함수(Loss Function):
\[\mathcal{L}_{\text{MLM}} = - \sum_{\hat{x} \in m(x)} \log P(\hat{x} | x_{\setminus m(x)})\]여기서 $m(x)$는 마스킹된 토큰들의 집합이며, 주변 문맥($x_{\setminus m(x)}$)을 통해 마스킹된 토큰($\hat{x}$)의 로그 우도(Log-likelihood)를 최대화하는 과정임을 설명합니다.
2.4 NSP(Next Sentence Prediction)의 학습 유도
- NSP의 목적: BERT는 사전 학습 시 두 문장이 이어지는 여부를
[CLS]토큰의 출력값만 사용하여 판단하며, 사전 학습의 입력으로 주어진 두 문장이 이어지는지 이어지지 않는지를 이용해 BERT 모델은 문장 단위로 진행되는 태스크에서도 사전 학습의 영향력을 미치고자 NSP를 적용하였습니다. -
NSP와 자가 지도 학습(Self-Supervised Learning)
NSP를 적용하기 위해서 학습 데이터가 필요합니다. 하지만 논문에서는 지도 학습 방식이긴 하지만 Self라는 용어를 앞에 붙이고 있습니다. 이에 대한 이유로는 우선 NSP의 학습 데이터를 만드는 과정을 살펴보도록 하겠습니다.
- 위키피디아 텍스트에서 문장 A를 뽑습니다.
- 50% 확률로 그다음에 바로 붙어 있는 문장 B를 가져오면, 전처리 스크립트가 자동으로 라벨을 ‘1’ 혹은 ‘TRUE’로 할당합니다.
- 50% 확률로 전혀 다른 문서에서 문장 C를 무작위로 가져오면, 스크립트가 자동으로 라벨을 ‘0’ 혹은 ‘FALSE’로 할당합니다.
즉 레이블을 사람이 직접 다는 것이 아닌 확률에 따라 자동으로 태깅하도록 하기 때문에 Self-Supervised Learning 이라고 하는 것입니다.
-
[CLS]토큰을 이용한 예측: BERT 모델에서 사전 학습 시 NSP 태스크의 예측에는[CLS]토큰을 사용한다고 합니다. BERT 모델에서[CLS]토큰 벡터는 다른 토큰 벡터들과 동일한 Attention 연산을 진행한다고 합니다. 하지만[CLS]토큰이 특별한 이유는 아래 손실 함수를 계산 할 때 사용하는 출력 벡터로[CLS]토큰 벡터를 사용하고 모델이 NSP 태스크에서 정답을 맞추어 Loss를 줄이려면,[CLS]토큰 벡터 안에 두 문장 간의 관계와 개별 문장의 주제를 효과적으로 압축해서 저장해야만 합니다. 이 과정이 반복되면서[CLS]토큰 벡터는 자연스럽게 문장 임베딩으로서의 성격을 띠게 됩니다. -
손실 함수(Loss Function): 자동으로 생성된 라벨을 정답으로 간주하고
\[\mathcal{L}_{NSP} = -[y \log(\hat{y}) + (1-y) \log(1-\hat{y})]\][CLS]토큰의 출력 벡터 위에 레이어를 쌓고 Softmax를 적용해 Binary Cross Entropy(BCE) 손실을 계산합니다.
3. Deep Dive: BERT는 왜 강력한가?
3.1 Context-Free vs. Contextualized Representations
BERT 이전의 모델들(Word2Vec, GloVe)은 단어당 하나의 고정된 벡터를 가졌습니다.(Context-Free). 반면 BERT는 문맥에 따라 단어의 의미가 실시간으로 변하는 Contextualized Representation을 생성합니다.
-
수학적 이해: 특정 단어 $w_i$에 대한 BERT의 최종 출력 $h_i$는 단순히 해당 단어의 임베딩이 아니라, 전체 시퀀스 $X = {x_1, \dots, x_n}$에 대한 복잡한 함수입니다.
\[h_i = \text{Encoder}(x_i | x_1, \dots, x_{i-1}, x_{i+1}, \dots, x_n)\]즉 ‘bank’라는 단어가 ‘river bank’에 있는지 ‘investment bank’에 있는지에 따라 $h_i$의 좌표값은 완전히 달라집니다. 이것이 다의어(Polysemy) 문제를 완벽하게 해결한 핵심입니다.
3.2 Deep Bidirectionality (깊은 양방향성)
ELMo 역시 양방향을 지향했지만, 왼쪽에서 오는 정보와 오른쪽에서 오는 정보를 독립적으로 처리한 뒤 마지막에 이어 붙였습니다. 하지만 BERT는 좀 더 확실한 양방향성을 적용했습니다. 우선 Self-Attention 기법을 사용하는 Transformer 모델을 사용하며, Attention 연산으로 각 토큰이 입력으로 들어온 모든 토큰의 정보를 학습하도록 하였습니다.
3.3 범용적 전이 학습의 극대화
BERT는 방대한 위키피디아 데이터를 통해 언어 그 자체의 구조를 먼저 배웁니다.
- Inductive Bias: Transformer 아키텍처는 시퀀스 내의 장거리 의존성(Long-range dependency)을 포착하는 데 매우 유리한 구조적 편향(Inductive Bias)을 가집니다.
- 사전 학습된 ‘언어의 문법과 상식’은 아주 적은 양의 하위 태스크 데이터(Fine-tuning)만으로도 모델이 해당 태스크의 전문가가 되도록 돕습니다.
4. Engineering & Implementation Details
4.1 MLM 사전 학습 시 전체 데이터의 15%의 토큰에만 [MASK]를 단다는 것의 명확한 의미
BERT 논문에 보면 전체 데이터 중 15%의 토큰에만 [MASK] 토큰을 부착한다고 되어 있습니다. 저는 설명을 곧이 곧대로 보는 경향이 있어 이 이 설명만 봤을 때 “확률적으로 [MASK] 토큰을 부착하는 것이라면 어떤 문장에는 [MASK] 토큰이 부착이 안되는 것이 아닌가?” 하는 의구심과 또한 논문에서는 “MLM 기법에는 80-10-10 트릭을 적용해 전체 [MASK]를 부착하고자 하는 토큰 중 80%는 [MASK] 토큰을 나머지 10%에는 다른 의미를 지니는 토큰을 나머지 10%의 토큰에는 원본 토큰을 그대로 유지함”이라고 되어 있었습니다. 여기서 저는 [MASK] 규칙을 이용해 판별할 수 있지만 다른 의미를 지니는 토큰과 원본 토큰을 그대로 유지하는 경우에는 어떻게 찾아내는 거지라는 의구심이 들었습니다.
이에 대한 답으로 BERT 모델의 코드를 보면 사전 학습을 진행할 때 입력 문장이 들어오게 되면 입력 문장의 각 토큰에서 15% 확률로 [MASK] 토큰을 바꾸며, 이렇게 [MASK]로 바뀌거나 다른 토큰으로 바뀌거나 원본 토큰을 유지하는 경우에도 선별할 수 있게 15% 확률로 선택한 토큰의 index를 이용해 해당 토큰이 MASK된 토큰이며 해당 토큰 index에서 MLM 학습을 진행하도록 되어 있다는 것을 알게 되었고, 이럴 경우에는 무조건 입력 문장이 들어오면 15% 확률로 학습에 사용할 MASK 토큰을 선정하고, index를 이용하므로 어떤 토큰에서 학습이 진행되도록 해야 하는지도 판별할 수 있다는 것을 알 수 있었습니다.
4.2 사전 학습 시의 정확한 손실 함수의 계산
저는 BERT 논문을 읽으며 논문에서는 사전 학습 시 MLM Loss와 NSP Loss는 병렬로 동시에 계산이 된다고 하였습니다. 그렇다면 이 때 NSP는 두 문장이 이어지는 문장인지 아닌지를 판별하는 이진 분류기 때문에 한 번의 Loss 값만 계산하면 되는데 MLM의 경우 입력 문장의 길이에 따라 여러 토큰이 생성될 것이고 각 토큰 별로 Loss 값이 계산될 텐데 최종적으로 학습에 사용되는 Loss 값은 어떻게 계산되는지가 궁금했습니다. 이에 대한 답으로 BERT 모델의 코드를 보면 MLM Loss는 각 토큰별로 구해지는 Loss 값의 평균을 사용하는 것으로 되어 있는 것을 확인하였습니다.
4.3 MLM 기법이 왜 Bidirectional인가?
BERT 논문만 본다면 MLM 기법을 쓴다고 해서 왜 양방향인지 명확하게는 설명하고 있지 않습니다. 논문에서는 첫째 Self-Attention 기법을 사용하는 Transformer 모델을 사용했기 때문에 모든 토큰 벡터들은 입력 문장의 모든 토큰의 영향을 받기 때문이고 두 번째로는 단순히 MLM 기법을 사용하기 때문에 양방향성을 얻는다고만 나오고 있습니다. 그렇다면 MLM 기법이 왜 양방향성을 가지게 하는 것일까요? 그 이유는 BERT 모델은 Transformer 모델의 Encoder를 사용하기 때문이며, Encoder 모델은 다음 단어를 예측해야 하는 Decoder 모델과는 다르게 Self-Attention Mask가 적용되지 않습니다. 그래서 BERT 논문의 저자들은 인코더 구조를 그대로 사용하면서 전통적인 언어 모델링(다음 단어 맞추기)을 하면 정답이 유출되므로, 이를 우회하여 양방향성을 유지한 채 학습할 수 있도록 입력단에 [MASK]를 도입한 것입니다. 여기에 BERT 모델은 Encoder만 사용하기 때문에 Decoder만 사용한 LM 모델인 GPT-1과는 다르게 MASK를 적용한 토큰 외에는 굳이 MASK를 주지 않아도 되므로 MASK로 변경한 토큰을 예측할 때 이전 토큰들과 이후 토큰들의 출력 벡터를 모두 사용할 수 있기 때문에 BERT 모델의 MLM은 GPT-1과 다르게 양방향성을 갖는 것입니다.
4.4 BERT 모델에 사용된 WordPiece Tokenizer에 대하여
BERT 모델에서 언급한 WordPiece Tokenizer는 BERT 모델 내부에 있는 Tokenizer 모델이라기 보다는 전처리의 한 과정이라고 봐야한다고 생각합니다. 저는 BERT 논문을 읽으면 Tokenizer 도 BERT 모델의 일부라고 생각했고, Tokenizer도 같이 학습한다고 하여 BERT 모델 사전 학습 시 Toeknizer 도 같이 학습을 시키는 것으로 이해를 했습니다만, 정확하게는 BERT 모델의 동작 전에 미리 수행해 놓는 전처리의 일종입니다.
BERT에 사용된 WordPiece Tokenizer는 BERT 모델 이전 LSTM 모델에서 사용되는 vocabulary 파일인 vocab.txt 파일을 직접 생성해 주는 모듈입니다. LSTM에서 사용되는 vocab.txt 파일은 특별한 처리 없이 단순히 학습 데이터에서 등장한 토큰을 기반으로 만들어진 일종의 단어 사전으로 이렇게 생성된 사전 파일은 오로지 학습 데이터에 의존하고 있기 때문에 평가 데이터를 이용한 평가나 실제 서비스를 진행할 때 OOV(Out Of Vocabulary) 문제가 굉장히 빈번하게 발생했습니다. WordPiece Tokenizer는 OOV 문제를 해결하기 위해 고안된 방법으로 vocab.txt 파일을 생성할 때 미리 지정한 개수의 병합쌍으로 이루어진 토큰 개수 만큼 생성하며, 토큰을 생성할 때에는 말뭉치를 기준으로 언어 모델의 우도를 가장 많이 증가 시키는 병합쌍을 선택하도록 합니다. 병합쌍을 선택할 때에는 말뭉치 전체를 보고 병합쌍 후보들을 만든 후 전체 후보들 중에서 확률값이 가장 높은 후보를 선택합니다. 이 과정을 지정한 토큰의 수 BERT 논문에서는 30,000개가 될 때까지 반복합니다. 그리고 이렇게 생성된 vocab.txt 파일을 이용해 실제 BERT 모델에서 사용할 때에는 MaxMatch(Longest Match First) 방식을 적용해 vocab.txt 사전 파일로부터 입력 문장에 대한 토큰을 가져옵니다.
5. Experiment & Conclusion
5.1 주요 벤치마크 결과
BERT는 당시 자연어 이해의 척도였던 주요 벤치마크에서 기존 기록을 처참히 깨부수며 등장했습니다.
-
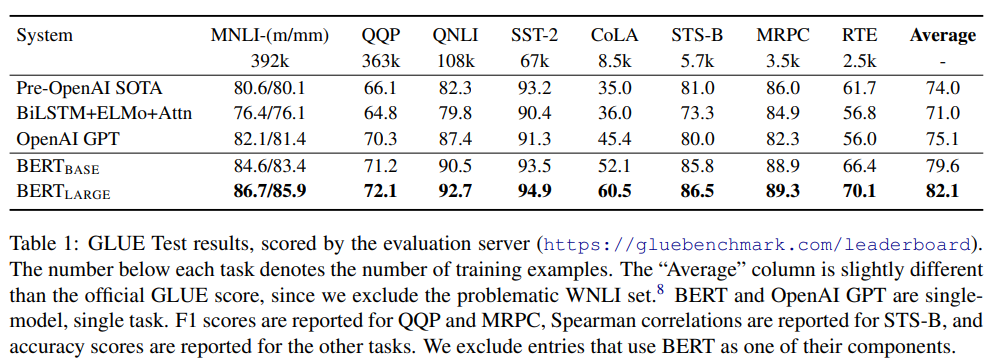
GLUE(General Language Understanding Evaluation)
자연어 이해 능력을 측정하는 9개의 다양한 태스크 모음집입니다.
- 결과: BERT-large 모델은 기존 SOTA 대비 7.0%의 압도적인 성능 향상을 기록하며 평균 80.5점을 달성했습니다.
- 의미: 특정 태스크에 특화된 아키텍처 없이, 단일 모델로 모든 태스크를 정복했다는 점에서 범용 전이 학습의 시대를 열었습니다.
-
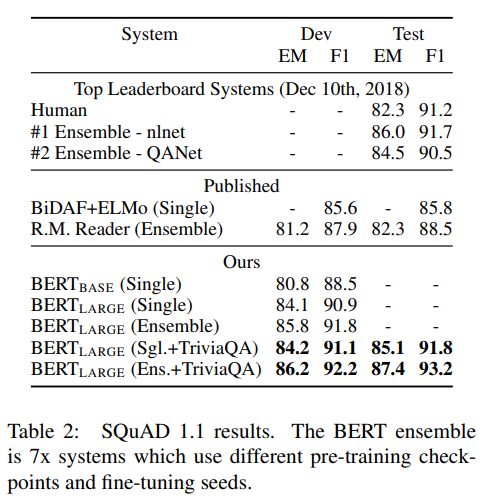
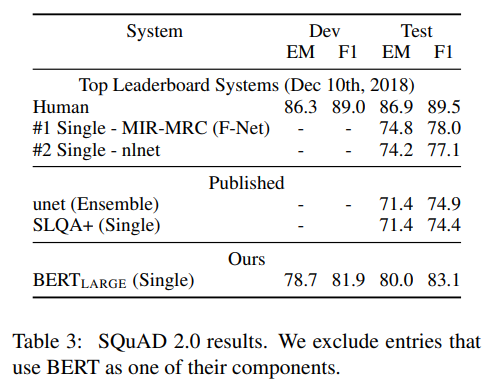
SQuAD (Stanford Question Answering Dataset) v1.1 & 2.0
질문과 지문이 주어졌을 때 정답 구간을 찾아내는 질의응답 태스크입니다.
- 결과: BERT-Large는 인간의 성능(Human Performance)을 뛰어넘는 수치를 기록했습니다.
- 특징: 특히 v2.0에서는 “지문에 정답이 없는 경우”까지 정확히 판단해 내며 문맥 파악의 정밀함을 증명했습니다.
5.2 아블레이션 스터디 (Ablation Study: 왜 잘 되는가?)
“어떤 기능을 뺏을 때 성능이 얼마나 떨어지는가”를 통해 BERT의 핵심 요소를 증명합니다.
-
사전 학습 태스크의 영향 (MLM vs LTR)
- 비교: BERT(양방향) vs No NSP vs LTR(단방향, GPT 방식)
- 결과: LTR 방식은 SQuAD 같은 문맥이 중요한 태스크에서 성능이 급격히 하락했습니다.
- 결론: 양방향성 이야말로 BERT의 강력함의 근원임을 데이터로 입증했습니다.

-
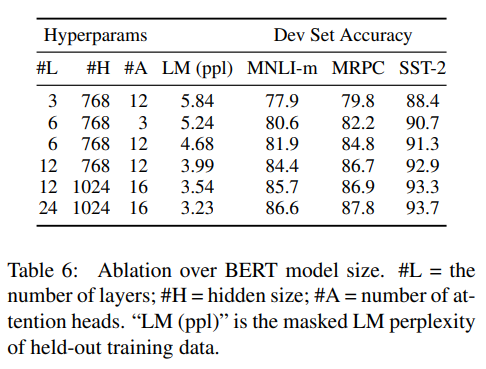
모델 사이즈의 영향 (Scale Matters)
- 실험: 레이어 수($L$), 히든 유닛 크기($H$), 어텐션 헤드 수($A$)를 늘려보았습니다.
- 결과: 모델이 커질수록 성능은 계속해서 우상향했습니다. 특히 아주 작은 데이터셋에서도 모델이 클수록 성능이 좋았는데, 이는 거대 모델의 사전 학습이 강력한 규제(Regularization) 효과를 준다는 것을 시사합니다.
-
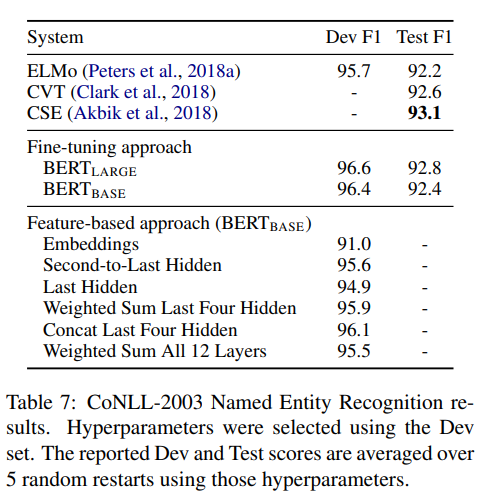
Feature-based vs Fine-tuning
-
실험: BERT를 고정된 임베딩(ELMo 방식)으로 쓸 때와 전체를 미세 조정(Fine-tuning)할 때를 비교했습니다.
-
실험 모델 및 데이터셋
- Task: CoNLL-2003 개체명 인식
- Dataset: CoNLL-2003 (Dev dataset 기준 평가)
- Classifier: 768차원(BERT-Base 기준)의 벡터를 입력으로 받는 2-layer BiLSTM을 사용했습니다.
-
적용된 6가지 특징 추출 전략 (Feature Extraction Strategies)
논문에서는 단순히 레이어 하나만 쓴 것이 아니라, 하위 레이어부터 상위 레이어까지 어떻게 조합했을 때 가장 성능이 좋은지 6가지 케이스를 비교했습니다.
-
- 결과: Fine-tuning이 성능이 더 좋긴 하지만, Feature-based 방식(임베딩만 추출)도 성능이 매우 훌륭했습니다.
- 의미: BERT는 특정 태스크에 맞춰 학습하지 않아도, 그 자체로 이미 압도적인 언어 표상을 만들어낸다는 뜻입니다.
-
6. Critical Review & Follow-up
6.1 [CLS] 토큰은 문장 임베딩으로써의 가치가 충분한지?
-
문제점:
-
NLSP 태스크의 한계: “너무 쉬운 문제”
[CLS] 토큰이 문장의 의미를 응축하도록 학습되는 유일한 통로는 NSP 태스크를 통한 학습입니다.
- 비판: 두 문장이 이어지는지 맞추는 NSP는 생각보다 너무 단순한 태스크입니다. 모델은 문장의 깊은 의미를 이해하기보다, 두 문장 사이의 단어 겹침이나 특정 키워드의 등장 여부만으로도 이 문제를 풀 수 있습니다.
- 결과: 이로 인해 [CLS] 토큰에는 문장의 정교한 의미 정보보다는 “두 문장이 논리적으로 연결되는 가”에 대한 이진적인 정보만 강하게 남게 됩니다.
-
이방성(Anisotropy) 문제: “좁은 원뿔안에 갇힌 벡터들”
연구자들은 BERT의 문장 벡터들이 벡터 공간상에서 매우 좁은 범위에 몰려 있는 이방성(Anisotropy) 현상을 발견했습니다.
- 현상: 서로 다른 의미를 가진 문장들의 [CLS] 벡터를 뽑아 코사인 유사도(Cosine Similarity)를 구해보면, 대부분 0.9 이상의 높은 값을 가집니다.
- 문제: 벡터들이 공간 전체를 넓게 쓰지 못하고 한쪽으로 치우쳐(Biased) 있기 때문에, [CLS] 벡터만으로는 두 문장이 얼마나 비슷한지 분별해내기가 매우 어렵습니다.
-
-
평균(Mean Pooling)보다 못한 성능
- 실험: 문장 유사도(STS) 태스크에서 [CLS] 토큰 하나만 쓴 것과, 문장 내 모든 토큰의 벡터를 평균(Mean Pooling) 낸 것을 비교했습니다.
- 결과: 놀랍게도 모든 토큰의 평균을 내거나 최대값(Max Pooling)을 취한 결과가 [CLS] 하나를 쓴 것보다 압도적으로 높았습니다. 이는 [CLS] 토큰이 문장의 모든 정보를 충분히 담아내지 못하고 있음을 시사합니다.
-
Follow-up:
- Sentence-BERT (SBERT, 2019): 두 개의 BERT를 나란히 세운 샴 네트워크(Siamese Network) 구조를 도입했습니다.
- SimCSE (Contrastive Learning, 2021): 대조 학습(Contrastive Learning)을 통해 벡터 공간을 교정했습니다.
6.2 [MASK] 토큰의 불일치 (Pre-train/Fine-tune Discrepancy)
BERT의 가장 큰 특징인 MLM 기법 자체가 역설적으로 한계를 만듭니다.
-
문제점: 사전 학습(Pre-trainig) 시에는 모델이
[MASK]토큰을 보며 학습하지만, 실제 우리가 사용하는 미세 조정(Fine-tuning)이나 추론(Inference) 단계에서는 입력 데이터에[MASK]토큰이 전혀 등장하지 않습니다. -
영향: 모델이 학습 때 보았던 입력 분포와 실제 사용 시의 입력 분포가 달라지는 ‘데이터 불일치’ 문제가 발생합니다.
6.3 토큰 간 독립성 가정 (Conditional Independence Assumption)
BERT의 Loss 계산 방식에는 수학적 맹점이 하나 있습니다.
-
문제점: 한 문장에서 여러 개의 토큰을 마스킹했을 때, BERT는 각 마스크($m1$, $m2$)를 서로 독립적이라고 가정하고 예측합니다.
-
예시: “New York is a big city”에서 [New, York]을 마스킹했다면, 모델은 원래 P(New, York context) 를 학습해야 합니다. 하지만 BERT는 P(New context) + P(York context)로 나누어 계산합니다. -
영향: “New”와 “York” 사이의 강력한 상관관계를 학습할 기회를 놓치게 됩니다.
- Follow-up: SpanBERT는 단일 토큰이 아닌 연속된 덩어리(Span)를 마스킹하여 이 관계를 더 잘 파악하도록 개선했습니다.
6.4 NSP(Next Sentence Prediction)의 실효성 논란
BERT가 야심 차게 내놓았던 두 번째 학습 목표인 NSP는 이후 연구에서 ‘계륵’ 같은 존재가 되었습니다.
-
문제점: 두 문장의 관계를 파악하는 NSP 태스크가 생각보다 모델 성능 향상에 크게 기여하지 않는다는 것이 밝혀졌습니다. 오히려 너무 쉬운 문제라 모델이 깊은 추론을 하지 않게 만든다는 비판이 있었습니다.
-
Follow-up: RoBERTa는 대규모 실험을 통해 “NSP를 제거하고 더 긴 시퀀스로 MLM만 학습 시키는 것이 성능이 더 좋다”는 것을 증명했습니다. 반면 ALBERT는 NSP대신 문장의 순서를 맞추는 SOP(Sentence Order Prediction)로 태스크를 난이도 높게 변경하여 효과를 보았습니다.
6.5 ‘이해’는 잘하지만 ‘생성’은 못하는 구조 (NLU vs NLG)
BERT는 태생적으로 인코더(Encoder) 구조입니다.
-
문제점: 문맥을 파악하는 자연어 이해(NLU)에는 최강이지만, 문장을 한 글자씩 생성해야 하는 자연어 생성(NLG) 태스크(예: 챗봇, 요약)에는 적합하지 않습니다.
-
영향: 양방향 정보를 모두 참조하기 때문에, 다음에 올 단어를 예측하며 순차적으로 나아가는 Autogressive 방식의 생성 속도가 매우 느리고 비효율적입니다.
-
Follow-up: 이를 보완하기 위해 인코더와 디코더를 결합한 T5나 BART 같은 모델들이 등장하여 이해와 생성의 균형을 맞추기 시작했습니다.
6.6 고정된 입력 길이와 연산 복잡도
Transformer 아키텍처의 고질적인 문제입니다.
-
문제점: Self-Attention의 연산 복잡도는 시퀀스 길이($n$)의 제곱인 $O(n^2)$입니다.
-
영향: BERT의 기본 입력 길이는 512 토큰으로 제한됩니다. 수십 페이지짜리 논문이나 책 한권을 통째로 넣어서 처리하기에는 메모리 비용이 너무 큽니다.
-
Follow-up: Longformer나 BigBird 같은 모델들은 Attention 범위를 희소하게(Sparse) 가져가는 방식으로 이 길이를 4,096개 이상으로 확장했습니다.
마무리
BERT 모델은 Transformer 모델의 인코더만을 사용하고, 현재 LLM 모델의 일반적인 학습인 사전 학습과 미세조정 학습의 개념을 정립해 적용한 모델로 한 번의 사전학습으로 여러 NLP 태스크에 영향을 줄 수 있고, 각 태스크별 학습 데이터와 미세조정 학습을 통해 하나의 모델에서 단 한 번의 사전 학습을 통해 여러 NLP 태스크에 영향을 끼칠 수 있도록 하는 획기적인 모델이었습니다. 비록 위와 같은 한계점들이 지적되긴 했습니만 BERT가 위대한 이유는 표준화된 사전 학습 모델 하나가 모든 NLP 태스크의 베이스라인을 갈아치울 수 있다는 패러다임을 증명했기 때문입니다. 위의 한계점들은 BERT 이후 등장한 수 많은 BERT-variants들의 훌륭한 먹거리가 되었고, 결과적으로 지금의 거대 언어 모델(LLM) 시대를 여는 밑거름이 되었습니다.
참조
- [https://arxiv.org/pdf/1810.04805]
Comments